Знание Zookeeper: подробное объяснение всего процесса развертывания распределенного кластера, освоение согласованности данных, механизма выборов и отказоустойчивости кластера.
В этой статье рассказывается, как настроить кластер Zookeeper. В главе 5 подробно описан метод установки распределенного кластера. Для получения информации о Zookeeper вы можете просмотреть этот ресурс.
1. Основные понятия
Zookeeper — это программное обеспечение, обеспечивающее согласованность распределенных приложений. Это реализация Google Chubby с открытым исходным кодом и важный компонент Hadoop и Hbase. В основном он используется для решения проблемы согласованности систем приложений в распределенных кластерах. Предоставляемые функции включают обслуживание конфигурации, службы доменных имен, распределенную синхронизацию, групповые службы и т. д.
2. Характеристики
- Эффективный и надежный:ZookeeperкFast На основе алгоритма Paxos,Лидер избирается для обеспечения порядка обработки транзакций и согласованности данных. в то же время,Обеспечивает высокую надежность и гарантии последовательности.,Убедитесь, что данные обновленыатомарностьи в режиме реального времени。
- Глобальные данные согласованы:каждыйServerСохраните идентичную копию данных,Независимо от того, к какому серверу подключается клиент,Данные все совпадают.
- Богатые структуры данных:ZookeeperМодель данных по структуре очень похожа на модель стандартной файловой системы.,Иметь иерархическое пространство имен,Все используют древовидную иерархическую структуру.,Каждый узел называется Znode. Znode имеет характеристики как файлов, так и каталогов.,Может хранить данные,Также может использоваться как контейнер для дочерних узлов.
- Наблюдательный механизм:ZookeeperРазрешить клиенту зарегистрироватьWatcherмонитор,Когда некоторые события на сервере запускают этот наблюдатель,Уведомление о событии будет отправлено указанному клиенту для реализации функции распределенного уведомления.
3. Сценарии применения
Zookeeper имеет множество сценариев применения в распределенных системах, включая, помимо прочего:
- Управление конфигурацией:управлятьраспределенный Информация о конфигурации системы,Каждый узел может получить информацию о конфигурации от Zookeeper.,при изменении конфигурации,Все узлы могут чувствовать время и соответствующим образом корректировать его.
- служба имен:используется какслужба имен,Файловая система аналогична распределенной,Позволяет приложениям создавать, удалять и находить узлы в Zookeeper.,Реализуйте простое управление пространством имен.
- Распределенная блокировка:поставлять Распределенная Поддержка от блокировки,Позволяет нескольким узлам координировать свои действия на общих ресурсах.,Избегайте конфликтов одновременного доступа.
- распределенная очередь:выполнитьраспределенная в свою очередь, используется для передачи сообщений и задач между несколькими узлами.
- Распределенные выборы:избирательный механизм可к用来выполнитьраспределенныйв системеLeaderвыборы,Убедитесь, что в случае сбоя или изменения узла,Новый Лидер может быть переизбран в кластере.
4. Принцип внутренней реализации
- избирательный механизм:Zookeeperкластер Все узлы пройдут черезLeaderвыборы过程来выборы出一个节点作为“лидер”(Leader),Отвечает за обработку клиентских запросов и поддержание согласованности между различными узлами в кластере. Алгоритм выборов основан на протоколе Zab протокола Paxos (ZooKeeper Atomic Широковещательный).
- согласованность данных:ZooKeeperза счет последовательной согласованности、атомарность、Для обеспечения согласованности данных используется единый механизм просмотра и синхронизации. Он использует протокол Zab, основанный на протоколе Paxos, чтобы гарантировать согласованность копий данных на всех узлах.
5. Распределенная установка
1. Кластерное планирование
Разверните Zookeeper на трех узлах Hadoop102, Hadoop103 и Hadoop104.
2. Разархивируйте и установите
Загрузите установочный пакет в каталог /opt/software.
(1) Разархивируйте установочный пакет Zookeeper в каталог /opt/module/.
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/(2) Синхронизируйте содержимое каталога /opt/module/zookeeper-3.4.10 с Hadoop103 и Hadoop104.
xsync zookeeper-3.4.10/3. Настроить номер сервера
(1) Создайте zkData в каталоге /opt/module/zookeeper-3.4.10/.
[atguigu@hadoop102 zookeeper-3.4.10]$ mkdir -p zkData(2) Создайте файл myid в каталоге /opt/module/zookeeper-3.4.10/zkData.
[atguigu@hadoop102 zookeeper-3.4.10]$ cd zkData
[atguigu@hadoop102 zkData]$ touch myidДобавьте файл myid. Обратите внимание, что он должен быть создан в Linux. В Notepad++ он может быть искажен.
(3) Отредактируйте файл myid.
[atguigu@hadoop102 zkData]$ vi myidДобавьте в файл номер, соответствующий серверу: (Просто напишите 2 напрямую)
2(4) Скопируйте настроенный Zookeeper на другие машины.
[atguigu@hadoop102 zkData]$ xsync myidИ измените содержимое файла myid на 3 и 4 на Hadoop102 и Hadoop103 соответственно.
4. Настройте файл Zoo.cfg
(1) Переименуйте Zoo_sample.cfg в каталоге /opt/module/zookeeper-3.4.10/conf в Zoo.cfg.
Войдите в каталог /opt/module/zookeeper-3.4.10/conf.
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg(2) Откройте файл Zoo.cfg.
[atguigu@hadoop102 conf]$ vim zoo.cfgИзменить конфигурацию пути хранения данных
dataDir=/opt/module/zookeeper-3.4.10/zkData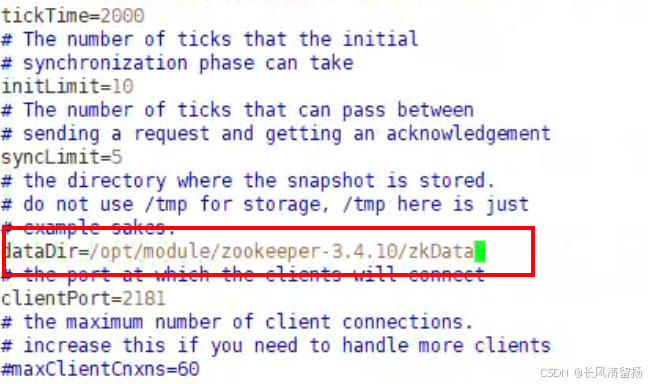
Добавьте следующую конфигурацию
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888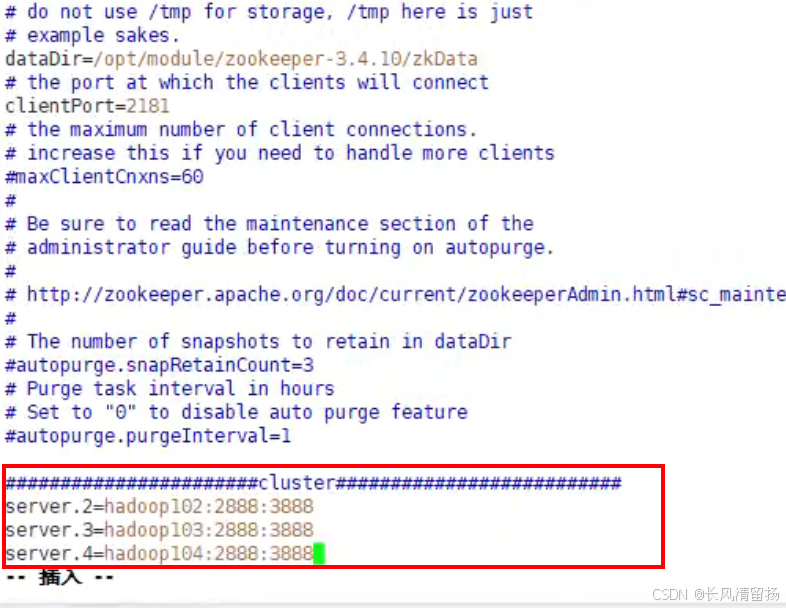
(3) Синхронизируйте файл конфигурации Zoo.cfg.
[atguigu@hadoop102 conf]$ xsync zoo.cfg(4) Интерпретация параметров конфигурации
server.A=B:C:D。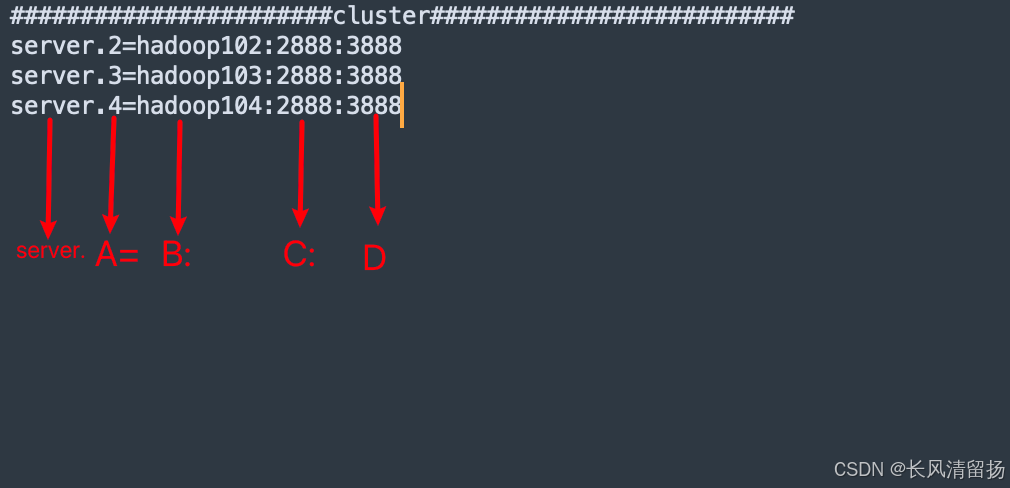
Aэто число,Указывает, какой это номер сервера, файле конфигурации для Hadoop102 установлено значение 2, а для Hadoop103 — значение 3.,Hadoop104 настроен с 4
Настройте файл myid в режиме кластера. Этот файл находится в каталоге dataDir. В этом файле есть данные, имеющие значение A. Zookeeper читает этот файл при запуске и сравнивает содержащиеся в нем данные с информацией о конфигурации в Zoo. cfg, чтобы сделать вывод. Какой это сервер?
BЭто с этого сервераipадрес;
CСвязан ли этот сервер скластервLeaderПорт, используемый сервером для обмена информацией.;
DНа всякий случайкластервLeaderСервер не работает,Для переизбрания нужен порт,Выберите нового лидера,Этот порт используется серверами для связи друг с другом при проведении выборов.
Один из этих трёх серверов будет выбран лидером, а остальные — ведомыми.
5. Кластерная работа
(1) Запустите Zookeeper отдельно.
Обязательно запустите Zookeeper на всех трех серверах, прежде чем проверять статус.
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.4.10]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.4.10]$ bin/zkServer.sh start(2) Проверьте статус
Вы можете видеть, что сервер Hadoop103 выбран лидером.
[atguigu@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[atguigu@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
[atguigu@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
