[Запись об ошибке] Сообщается об ошибке при использовании вычисления данных PySpark в Python (SparkException: работнику Python не удалось подключиться обратно.)
Причина ошибки: интерпретатор Python не настроен для PySpark, просто удалите следующий код в верхней части кода анализа данных Python;
# для PySpark Конфигурация Python устный переводчик
import os
os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"os.environ['PYSPARK_PYTHON'] Значение установлено на на вашем компьютере python.exe Абсолютного пути достаточно , Не следить за тем, что на моем компьютере Python Настройки пути интерпретатора ;
1. Сообщение об ошибке
Используя расчет данных PySpark в Python,
# Создайте массив, содержащий целые числа из RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
# for выполняет функцию из для каждого элемента
def func(element):
return element * 10
# приложение map Операция Воля умножить каждый элемент на 10
rdd2 = rdd.map(func)При выполнении сообщается следующая ошибка:
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py
23/07/30 21:24:54 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/07/30 21:24:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark номер версии : 3.4.1
23/07/30 21:25:07 ERROR Executor: Exception in task 9.0 in stage 0.0 (TID 9)
org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:328)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161)
at org.apache.spark.scheduler.Task.run(Task.scala:139)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179)
... 15 more
23/07/30 21:25:07 WARN TaskSetManager: Lost task 9.0 in stage 0.0 (TID 9) (windows10.microdone.cn executor driver): org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:328)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161)
at org.apache.spark.scheduler.Task.run(Task.scala:139)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179)
... 15 more
23/07/30 21:25:07 ERROR TaskSetManager: Task 9 in stage 0.0 failed 1 times; aborting job
Traceback (most recent call last):
File "Y:\002_WorkSpace\PycharmProjects\HelloPython\hello.py", line 33, in <module>
print(rdd2.collect())
File "Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\lib\site-packages\pyspark\rdd.py", line 1814, in collect
sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
File "Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\lib\site-packages\py4j\java_gateway.py", line 1322, in __call__
return_value = get_return_value(
File "Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\lib\site-packages\py4j\protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 9 in stage 0.0 failed 1 times, most recent failure: Lost task 9.0 in stage 0.0 (TID 9) (windows10.microdone.cn executor driver): org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:328)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161)
at org.apache.spark.scheduler.Task.run(Task.scala:139)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179)
... 15 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2785)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2721)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2720)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2720)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1206)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1206)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1206)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2984)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2923)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2912)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:971)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2263)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2284)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2303)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2328)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1019)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:405)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1018)
at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:193)
at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:374)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:328)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161)
at org.apache.spark.scheduler.Task.run(Task.scala:139)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179)
... 15 more
[Stage 0:> (0 + 11) / 12]
Process finished with exit code 1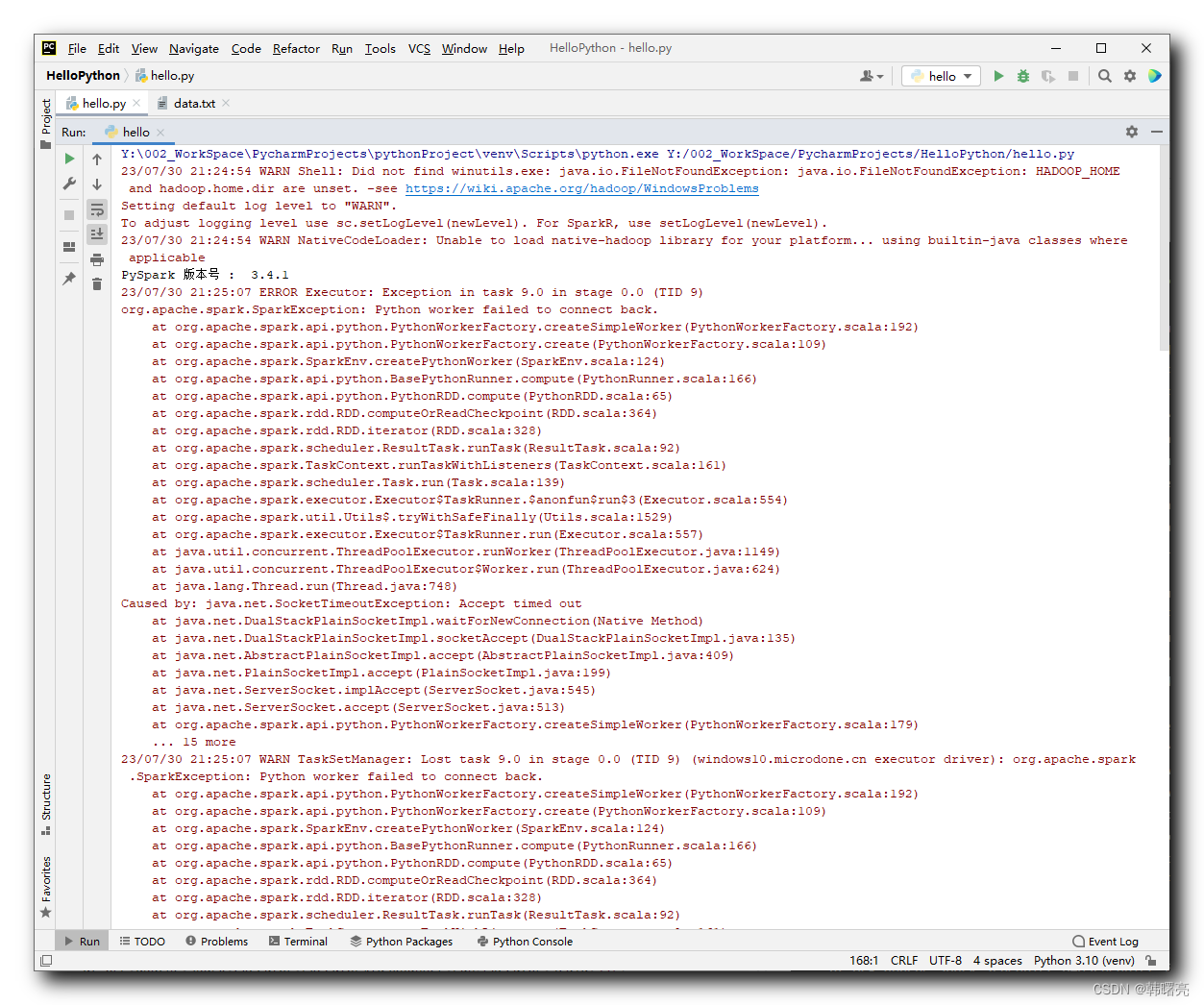
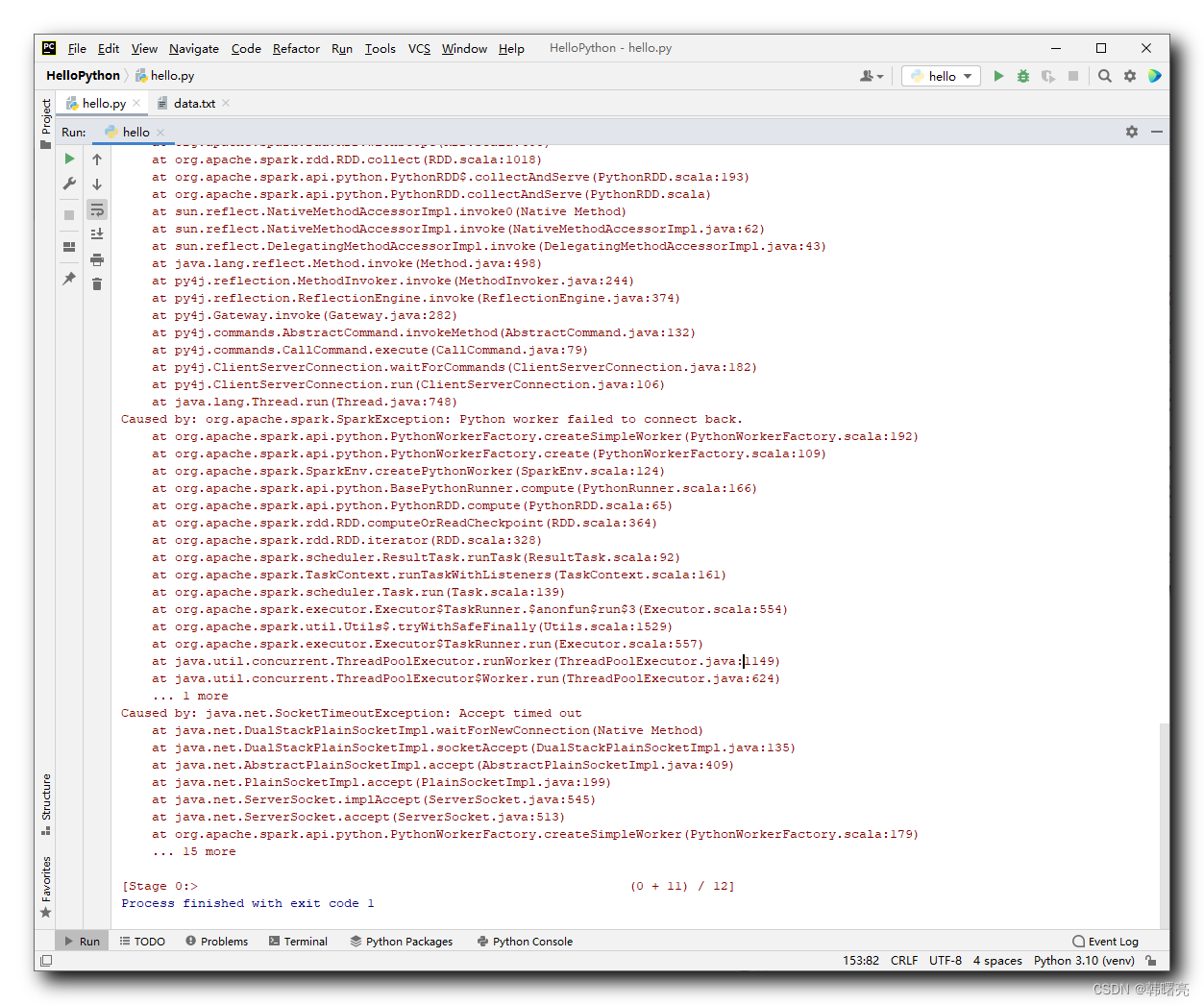
Основное сообщение об ошибке выглядит следующим образом : org.apache.spark.SparkException: Python worker failed to connect back. at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192) at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109) at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
2. Анализ проблемы
Выполняемый код выглядит следующим образом:
"""
PySpark данныеиметь дело с
"""
# импортировать PySpark Связанные пакеты
from pyspark import SparkConf, SparkContext
# создавать SparkConf объект экземпляра , Этот объект используется для конфигурации. Spark Задача
# setMaster("local[*]") Указывает существование в автономном режиме Запустить на этой машине
# setAppName("hello_spark") для Spark Дайте программе имя
sparkConf = SparkConf() \
.setMaster("local[*]") \
.setAppName("hello_spark")
# создавать PySpark среда выполнения Входной объект
sparkContext = SparkContext(conf=sparkConf)
# Распечатать PySpark номер версии
print("PySpark номер версии : ", sparkContext.version)
# Создайте массив, содержащий целые числа из RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
# for выполняет функцию из для каждого элемента
def func(element):
return element * 10
# приложение map Операция Воля умножить каждый элемент на 10
rdd2 = rdd.map(func)
# Распечататьновыйиз RDD серединаизсодержание
print(rdd2.collect())
# останавливаться PySpark программа
sparkContext.stop()Код выполняется без ошибок;
Причина ошибки в том, что код Python неточно нашел интерпретатор Python;
В PyCharm настроен интерпретатор версии Python 3.10, который может распознаваться программой Python, но не распознаваться PySpark;
Поэтому вам необходимо вручную настроить интерпретатор Python для PySpark;
Установите переменные среды интерпретатора Python PySpark;
3. Решение
В PyCharm выберите параметр «Строка меню/Файл/Настройки»,
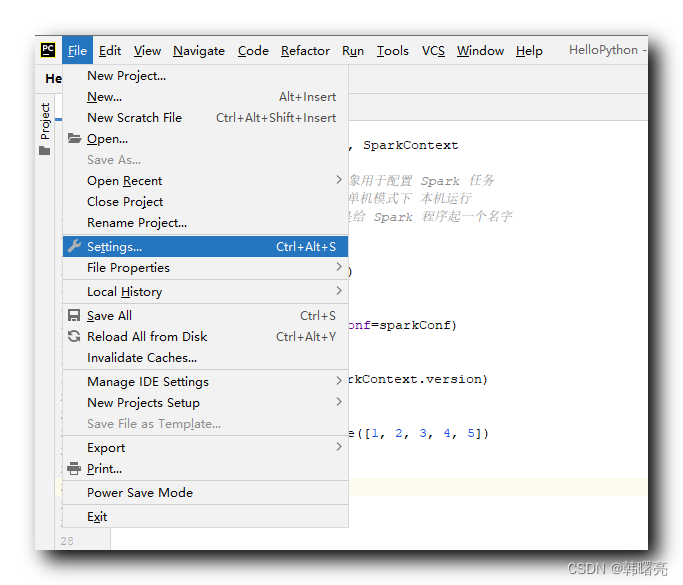
В окне «Настройки» выберите панель «Интерпретатор Python» и просмотрите путь, по которому установлен настроенный интерпретатор Python;
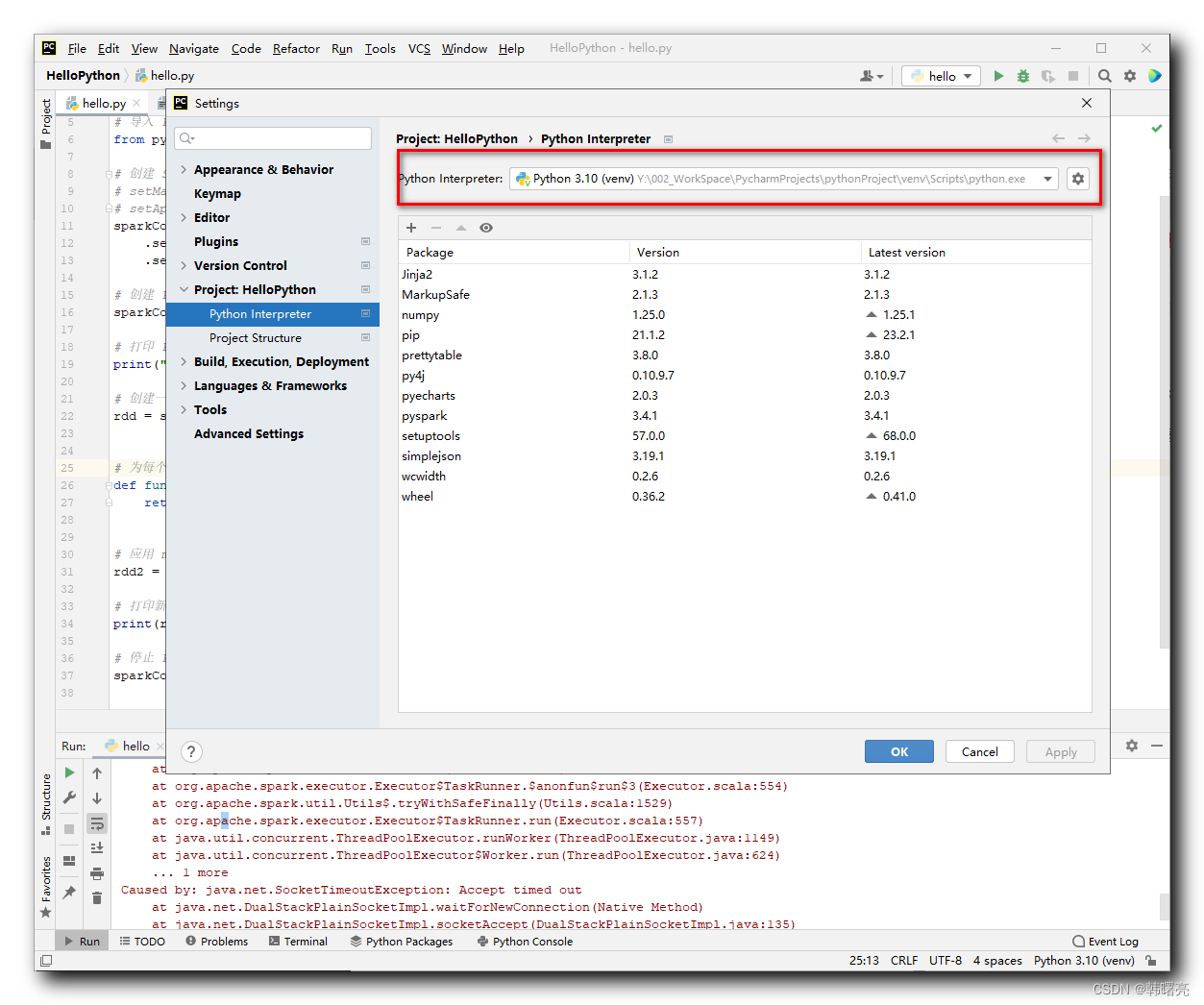
Запишите расположение интерпретатора Python:
Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe
В начале кода добавьте следующий код:
import os
os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"Воля os.environ['PYSPARK_PYTHON'] = позже Python.exe Измените путь на вашем путь к компьютеру может быть ;
Измените полную версию позже следующим образом:
"""
PySpark данныеиметь дело с
"""
# импортировать PySpark Связанные пакеты
from pyspark import SparkConf, SparkContext
# для PySpark Конфигурация Python устный переводчик
import os
os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"
# создавать SparkConf объект экземпляра , Этот объект используется для конфигурации. Spark Задача
# setMaster("local[*]") Указывает существование в автономном режиме Запустить на этой машине
# setAppName("hello_spark") для Spark Дайте программе имя
sparkConf = SparkConf() \
.setMaster("local[*]") \
.setAppName("hello_spark")
# создавать PySpark среда выполнения Входной объект
sparkContext = SparkContext(conf=sparkConf)
# Распечатать PySpark номер версии
print("PySpark номер версии : ", sparkContext.version)
# Создайте массив, содержащий целые числа из RDD
rdd = sparkContext.parallelize([1, 2, 3, 4, 5])
# for выполняет функцию из для каждого элемента
def func(element):
return element * 10
# приложение map Операция Воля умножить каждый элемент на 10
rdd2 = rdd.map(func)
# Распечататьновыйиз RDD серединаизсодержание
print(rdd2.collect())
# останавливаться PySpark программа
sparkContext.stop()Результат выполнения:
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py
23/07/30 21:39:59 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/07/30 21:39:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark номер версии : 3.4.1
[10, 20, 30, 40, 50]
Process finished with exit code 0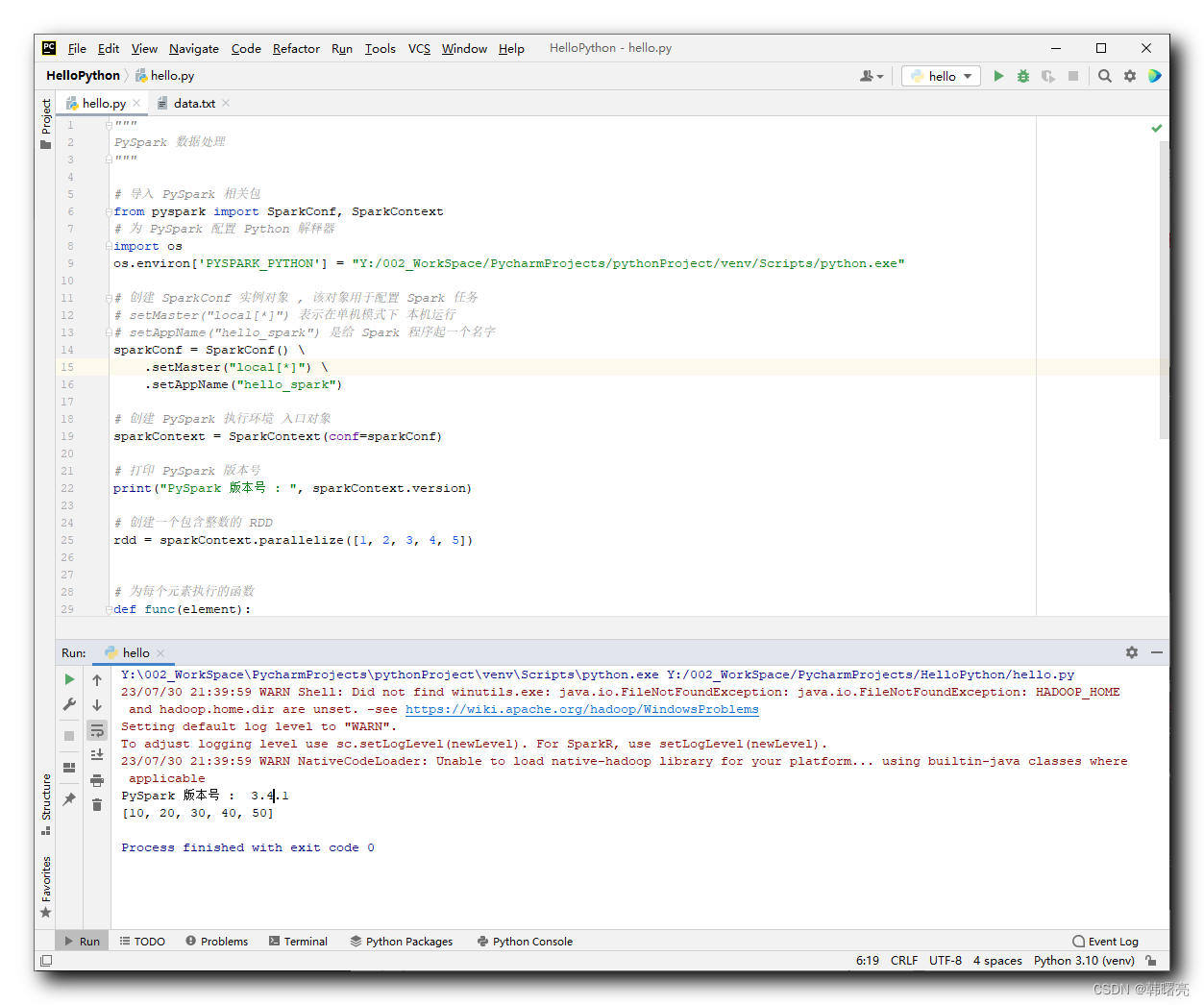



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
