YOLO & GhostNet | Достижение точного позиционирования и классификации при одновременном обеспечении точности и производительности модели в сложных средах!

Защитные каски играют жизненно важную роль в защите рабочих от травм головы в таких средах, как строительные площадки, где преобладают потенциальные опасности. Однако в настоящее время не существует метода, который одновременно обеспечивает точность и производительность модели в сложных средах. В этом исследовании автор использовал модель на основе YOLO для обнаружения защитных шлемов, которая улучшила производительность mAP (средняя средняя точность) на 2%, одновременно сократив количество параметров и операций с плавающей запятой более чем на 25%. YOLO — это широко используемая высокопроизводительная легкая модельная архитектура, которая хорошо подходит для сложных сред. Авторы предлагают новый метод путем интеграции облегченной сети извлечения признаков на основе GhostNetv2, сети внимания пространственных каналов (SCNet) и сети координированного внимания (CANet) и использования оптимизатора восприятия с нормализацией градиента (GAM). В критически важных для безопасности средах точное и быстрое обнаружение защитных касок играет жизненно важную роль в предотвращении профессиональных рисков и обеспечении соблюдения правил техники безопасности. Эта работа направлена на острую потребность в надежных и эффективных методах обнаружения шлемов, обеспечивая комплексную основу, которая не только повышает точность, но и улучшает адаптируемость моделей обнаружения к реальным условиям. Экспериментальные результаты автора подчеркивают синергетический эффект GhostNetv2, модуля внимания и оптимизатора GAM, обеспечивая решение для обнаружения защитных шлемов, которое хорошо работает с точки зрения точности, способности к обобщению и эффективности.
I Introduction
Правильное использование касок имеет решающее значение для здоровья работников в различных промышленных и строительных условиях. Точное и эффективное обнаружение касок играет ключевую роль в обеспечении безопасности труда и соблюдении протоколов безопасности. Традиционные методы ручного контроля и мониторинга зачастую отнимают много времени, подвержены ошибкам и непригодны для крупномасштабных операций. В ответ на эти проблемы компьютерное зрение и технологии глубокого обучения стали мощными инструментами для автоматического обнаружения защитных касок.
Хотя существующие методы обнаружения объектов достигли значительного прогресса в различных областях, обнаружение касок остается сложной задачей из-за ряда присущих им ограничений. Традиционные подходы, основанные на ручных проверках и системах, основанных на правилах, часто не справляются со сложностями динамичной рабочей среды. Эти методы склонны к ложноположительным и ложноотрицательным результатам, что приводит к плохому обеспечению безопасности и, таким образом, увеличивает риск несчастных случаев на производстве. Руководствуясь общей целью — устранить пробел в существующих средствах обнаружения касок, авторы предлагают решение, которое устраняет ограничения существующих методов. Используя возможности GhostNetv2, модуля внимания и оптимизатора GAM в архитектуре YOLOv5, авторы стремятся предоставить новый и эффективный метод обнаружения каски, который поможет сделать рабочее место более безопасным и эффективным.
В основе метода авторов лежит известный алгоритм YOLO — система обнаружения объектов в реальном времени, известная своей скоростью и точностью. YOLO делит изображение на сетку, и каждая ячейка сетки прогнозирует ограничивающие рамки и вероятности классов. Авторы выбрали вариант YOLOv5 из-за его гибкости и простоты интеграции для адаптации к условиям обнаружения в каске.
Для повышения точности обнаружения целей автор вводит механизм внимания. В области глубокого обучения механизмы внимания получили широкое внимание благодаря их способности выборочно сосредотачиваться на соответствующих частях входных данных, тем самым улучшая производительность модели в различных задачах.
В контексте обнаружения объектов механизмы внимания обеспечивают ценные улучшения для сверточных нейронных сетей (CNN), позволяя моделям динамически регулировать внимание к различным пространственным областям, функциям или каналам в зависимости от их важности.
Интеграция механизмов внимания, таких как SCNet и Координация внимания, в архитектуру YOLOv5 позволяет авторам смягчить потенциальные недостатки, одновременно уменьшая преимущества выбора функций на основе внимания. Тщательно разрабатывая и интегрируя эти механизмы внимания, авторы стремятся улучшить способность модели фиксировать пространственные отношения и повысить производительность обнаружения объектов в задаче обнаружения каски.
Достижение сильных способностей к обобщению затруднено из-за различий в освещении, фоне и позе объекта. Авторы решили реализовать градиентный оптимизатор с учетом норм (GAM) [12] из-за его способности сглаживать ландшафт оптимизации, способствовать более быстрой сходимости и увеличивать возможности обобщения. Улучшенное обобщение снижает вероятность переобучения, обеспечивая эффективность модели на новых и ранее неизвестных данных.
Основные результаты исследования автора заключаются в следующем:
- Авторы решают проблему обнаружения касок, предлагая новую структуру.,Платформа сочетает в себе YOLOv5 с механизмом внимания и магистральной сетью на основе GhostNetv2. Это нововведение привело к созданию высокоэффективной модели.,существующие поддерживают конкурентоспособную среднюю точность (mAP) при значительном снижении параметров,Достигнуто точное позиционирование и классификация шлемов.
- Отличается от предыдущих методов, которые игнорируют информацию о глобальном контексте.,Авторские исследования существуют представили механизм внимания в архитектуре YOLOv5.,Специальное внимание к пространственным каналам (SCNet) и координация внимания. Эта интеграция учитывает глобальные и локальные функции.,Улучшена способность модели точно обнаруживать шлемы.
- Авторские исследования не только представили инновационную модель архитектуры.,Ключевые аспекты обобщения также имеют приоритет. Тщательно разрабатывая различные варианты моделей разной ширины и глубины.,Подход авторов обеспечивает адаптируемость к различным сценариям обнаружения касок. Экспериментальные оценки, выполненные на существующем наборе данных конкретного каски и общем эталонном наборе данных, последовательно демонстрируют улучшенные возможности обобщения авторской модели.
II Related Works
YOLO Architecture
В области обнаружения целей в центре внимания исследований находилась серия алгоритмов YOLO (You Only Look Once) [13] и их улучшенные версии. Многочисленные исследования посвящены оптимизации и инновациям различных аспектов обнаружения целей на основе платформы YOLO. Основанный на YOLOv4, YOLOv5 включает в себя несколько улучшений, в том числе использование трех технологий улучшения данных в процессе загрузки данных, объединение функций активации CSPNet, Leaky ReLU и Sigmoid в Backbone, а также интеграцию SPP-Net и SPP-Net в шейной части. структура. Кроме того, в YOLOv5 также представлен адаптивный блок привязки для повышения скорости сходимости и способности модели к обобщению. В области восприятия автономного вождения компания MCS-YOLO [14] разработала многомасштабную структуру обнаружения небольших целей, чтобы улучшить чувствительность распознавания и преодолеть проблемы, присущие обнаружению небольших целей. YOLO-Z[15] фокусируется на улучшении возможностей обнаружения небольших целей беспилотными транспортными средствами. Внедряя новый механизм внимания и стратегию объединения функций, YOLO-Z значительно повышает точность обнаружения небольших целей, сохраняя при этом высокую скорость. Являясь инновационной версией серии YOLO, YOLOX[16] отказывается от традиционной концепции якорного ящика. Благодаря сквозному обучению процесс обнаружения целей упрощается и расширяется способность модели к обобщению. LF-YOLO [17] включает в себя усиленный модуль многомасштабных функций (RMF) для эффективного извлечения многомасштабной информации посредством комбинации параметризованных и безпараметрических операций.
Attention Mechanisms in Object Detection
Механизмы внимания [18] стали ключевым компонентом улучшения возможностей нейронных сетей, особенно при обнаружении объектов. Нелокальные нейронные сети [19] используют нелокальные операции для фиксации долгосрочных зависимостей в изображениях. Этот механизм позволяет сети лучше понимать глобальный контекст сцены в задачах обнаружения объектов. Сеть закрытого внимания [20] динамически корректирует вес внимания на карте объектов, вводя механизм шлюзования. Эта динамическая регулировка повышает точность и надежность обнаружения целей. Частичные межэтапные связи [21, 22] устанавливают частичные связи между различными этапами и вводят новый механизм внимания для повышения эффективности обнаружения объектов в сценариях обучения с несколькими этапами. Многомасштабное расширение внимания [23, 24] использует конструкцию с несколькими головками для создания скользящих окон с разной скоростью расширения в разных головах [25]. CBAM [25] — это хорошо известный модуль внимания, такой как SENet [26], который сочетает в себе пространственное внимание и внимание к каналам для значительного повышения точности сети.
Gradient Norm Aware Optimizer
Оптимизаторы [27, 28] играют ключевую роль в эффективном обучении моделей глубокого обучения. Стохастический градиентный спуск (SGD) [29, 30] — это базовый алгоритм оптимизации, широко используемый в машинном и глубоком обучении. Он обновляет параметры модели, итеративно используя градиент функции потерь относительно этих параметров, чтобы минимизировать целевую функцию. Адаптивная оценка импульса (Адам) [31] представляет собой алгоритм адаптивной оптимизации скорости обучения, который сочетает в себе идеи импульса и RMSprop. Он регулирует скорость обучения индивидуально для каждого параметра на основе исторических градиентов, обеспечивая эффективную и адаптивную оптимизацию. Минимизация с учетом резкости (SAM) [32] — это недавно разработанный алгоритм оптимизации, целью которого является повышение равномерности ландшафта потерь во время обучения. Он решает проблему переобучения путем штрафования резкости, т. е. нормы градиента по параметрам, что закладывает основу для последующего внедрения интеграции GAM-оптимизаторов [12] и ее влияния на предлагаемые улучшения.
III Methodology
Структура фреймворка, предложенная автором, и исходный YOLOv5 показаны на рисунке 1. По сравнению с исходным YOLOv5, этот документ вносит вклад в следующие три аспекта:
- Используйте GhostNetv2 для замены исходной магистральной сети, чтобы уменьшить сложность параметров и эффективно извлекать карты объектов.
- существоватьмагистральная сетьи Neck В компонент введен механизм внимания, а именно самокалибровка свертки и координация внимания, чтобы Модель могла лучше фокусироваться. Информация о существовании повышает точность при работе с различными средами.
- Существующие Добавить оптимизацию с учетом градиентной нормы к исходному методу оптимизации.,Улучшите способность модели к обобщению.
Lightweight Feature Extraction Network Backbone Based on GhostNetV2
Модуль C3 вводит в магистральную сеть сложную структуру и методы подключения, что может привести к избыточности параметров. Поэтому GhostNet [33, 5] вводит свертку по глубине и свертку точек для уменьшения параметров. Кроме того, он также объединяет внимание DFC [34] на основе полносвязного слоя для решения проблемы небольших сверточных локальных рецептивных полей. GhostNetV2 подчеркивает эффективность параметров с помощью блоков-призраков и хорошо справляется с извлечением признаков в глубоких нейронных сетях. Он предназначен для определения приоритета производительности без ущерба для вычислительных ресурсов. Сетевая основа авторской структуры показана на рисунке 2.
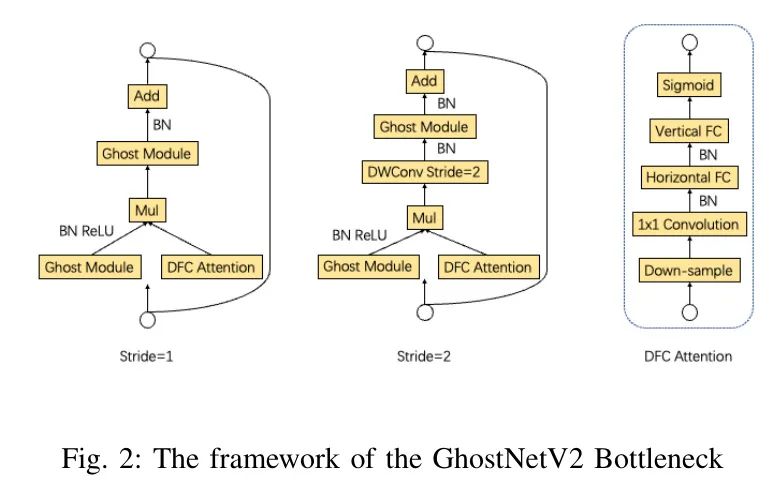
Iii-A1 GhostNet Module
Рисунок 1. На этом рисунке сравнивается улучшенная платформа автора с исходной платформой YOLOv5. В основной части автор заменил модули conv и C3 на GhostConv и GhostC3 соответственно. Кроме того, авторы заменяют исходный SPPF на SPPF, интегрированный в SCNet. В части шеи автор добавляет модуль координации и внимания (CA) после каждого этапа сращивания.
Стандартный модуль GhostNet может заменить традиционный блок свертки следующими шагами для функций ввода.
: Сначала используйте свертку глубины, чтобы уменьшить размерность канала входной карты объектов, и результат выражается как
(1). Затем для сбора информации о канале используется поточечная свертка и в сочетании с
(2) Выполните сращивание. Затем внимание DFC умножается для сбора информации о пространственной окрестности, где карта внимания DFC может быть рассчитана как (3).
да
отметка
。
Применяя операции свертки к размерам высоты и ширины соответственно, внимание DFC значительно снижает параметры и вычислительную нагрузку при извлечении объектов на больших расстояниях. На той же входной карте объектов
и соответствующие одинаковые выходные условия
, общие параметры стандартного модуля свертки и модуля GhostNet можно рассчитать следующим образом:
Обычно это половина размера входного канала. Это очевидно,По сравнению со стандартными сверточными модулями,ghostМодулей требуется меньшепараметр。
Iii-A2 GhostNet Bottleneck
Структура узкого места GhostNet состоит из двух модулей GhostNet. Первый модуль Ghost извлекает более глубокую информацию и расширяет возможности, в то время как последующие модули Ghost (без внимания DFC) изменяют количество каналов в соответствии с остаточным путем. Структура узких мест Ghost такова: Благодаря вышеупомянутым преимуществам GhostNet после замены модулей C3 и Conv в магистральной сети на GhostNet объем вычислений и масштаб параметров значительно уменьшаются, что повышает скорость работы сети, но точность теряется.
Attention Modules Integration to Compensate for Accuracy
хотяGhostNetзначительно уменьшено Модельизпараметри Вычислительная нагрузка,Но эффективно уловить пространственные особенности сложно.,Это неизбежно приводит к некоторой потере точности. чтобы компенсировать это,Автор предложил механизм внимания,особенныйдасуществоватьYOLOиз主干и Neck Частично использует самокорректирующуюся свертку и координирует внимание для сохранения информации о положении на большом расстоянии. Механизм внимания позволяет модели выборочно фокусироваться на определенных частях входной последовательности или изображения, изучая веса для распределения внимания по разным местам. Это позволяет модели выборочно фокусироваться на определенных областях входных данных, игнорируя при этом другие шумные или нерелевантные части.
Iii-B1 Self-Calibrated Convolutions (SCNet)
SCNetда Легкий модуль внимания,Его рабочий процесс показан на рисунке 3. существуютSCNet,Вход разделен на две ветви. Они рассчитываются отдельно,Результат каждой ветки склеивается с конечным результатом.
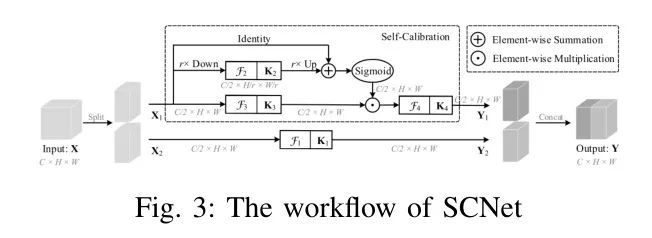
Как показано на картинке выше,SCNet имеет несколько разных размеров остаточных блоков.,Вывод Bootstrap выделяет области интереса. Это встраивание параллельных ветвей также обеспечивает широкий обзор модуля.,Помогите ему изучить свое пространственное окружение. С многомасштабными функциями,Модель может эффективно обнаруживать небольшие цели в шлемах в различных условиях. В модуле, предложенном автором существования,SCNet добавлен в главную ветку блока SPPF.,Как показано на рисунке 7. Блок SPPF также является остаточным блоком.,Но в отличие от SCNet,Особенности сшивания блоков SPPF для каналов разных размеров,SCNet соединяет весы разного разрешения. Добавить SCNet через существующий блок SPPF,SPPF изучит взаимосвязь функций между различными разрешениями,Расширение возможностей обнаружения целей разных размеров. также,Недостатки SCNet,То есть более слабая способность захвата большого рецептивного поля из-за наложения таких сверточных слоев.,существование в основном не подвергается воздействию.
Iii-B2 Coordinate Attention (CA)
В YOLO часть Neck (Шея) играет ключевую роль в развязке и извлечении особенностей карты объектов. Чтобы решить проблему потери точного пространственного соотношения входных данных в процессе повышения дискретизации, было предложено координатное внимание (Coordinate Attention). CA улучшает обучение функциям, включая пространственные отношения на основе координат пикселей. Принципиальная схема модуля CA представлена на рисунке 4.
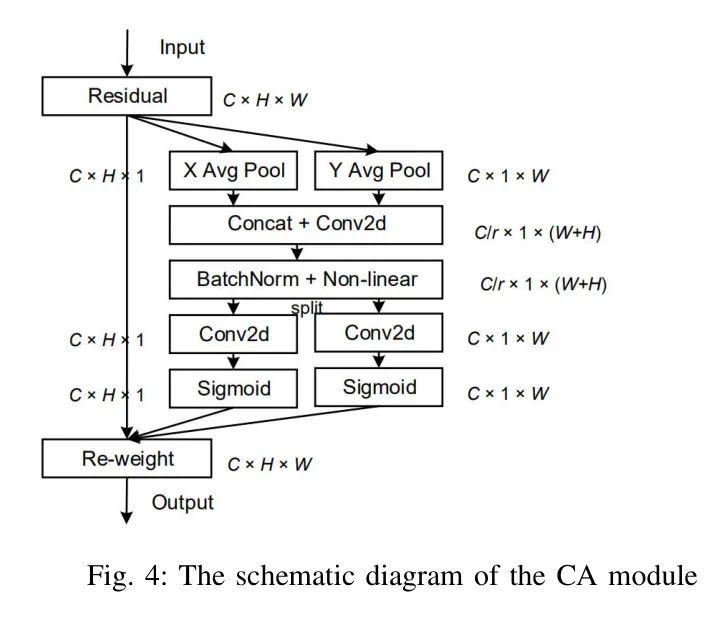
Как показано на рисунке, модуль CA включает в себя два этапа: внедрение координатной информации и генерацию координатного внимания. Встраивание информации о координатах использует глобальное объединение для внедрения пространственных объектов. Для входных функций
, используя два ядра пула соответственно
уменьшить его размерность до
(5) и
(6) Размер
。
результат
и
Представляет взаимосвязь между пикселями и их перекрестными окрестностями, но без точной информации о положении, которая называется генерацией внимания координат. Поэтому в
и
К (8) добавляются еще два
преобразование свертки, где
да
и
(7) выход подключения.
Предлагаемая структура шеи с координатным вниманием показана на рисунке 1. В авторском модуле модуль СА добавлен перед блоком С3 в YOLO Neck по двум причинам:
- Авторы полагают, что GhostNet эффективно кодирует объекты разного размера снизу вверх, в то время как Neck Блок C3 дополнительно интегрирует и расширяет функции. Переоценить отношения положения пикселей через блоки CA, Neck будет больше внимания Самая полезная информация.
- существуют различные размеры и глубина шеи, в настоящее время обрабатываются,Существует 4 разных блока C3.,Добавление CA перед блоком C3 позволит максимально использовать информацию о местоположении и повысить точность.
GAM Optimizer Implementation
Чтобы обнаружить защитные шлемы в сложных и меняющихся сценах, крайне важно улучшить способность модели к обобщению. На основе стохастического градиентного спуска (SGD) авторы добавляют в оптимизатор неравномерность первого порядка, чтобы улучшить производительность обобщения. SGD использует технологию стохастической аппроксимации для минимизации функции потерь путем корректировки параметров модели на основе случайно выбранных подмножеств обучающих данных, тем самым способствуя сходимости модели к оптимальному решению. Алгоритм SGD можно выразить следующей формулой (9), где
да скорость обучения,
да шаг по времени,
да градиент потерь.
Чтобы повысить способность Модели к обобщению, автор существующей SGDоптимизация добавил в SGD GAM (минимизацию с учетом градиентной нормы). Максимальное собственное значение гессиана широко считается мерой гладкости и кривизны места сходимости. GAM аппроксимирует максимальное собственное значение гессиана, используя следующую формулу (10):
в
да плоскостность первого порядка можно вычислить в существовании (11):
GAM использует формулу (12) для ограничения диапазона ошибки обобщения. Как показано в формате, оптимизация ключа позволяет контролировать функцию потерь для ошибки обобщения.
Плоскостность первого порядка
。Контролируйте градиент значения потерь, обновляя Плоскостность первого порядкаиз权重,GAM постепенно уменьшает ошибку обобщения.
Поток кода выглядит следующим образом:
Алгоритм 1 Минимизация с учетом градиентной нормы (GAM)

Следовательно, модель сходится в сторону уменьшения ошибки обобщения. Добавив GAM в оптимизатор, можно эффективно улучшить способность модуля к обобщению. ## IV Экспериментальная часть
существоватьв этом разделе,Автор предлагает серию экспериментов.,Цель состоит в том, чтобы проверить улучшения, внесенные в YOLOv5 для обнаружения шлемов. Эксперимент дасуществовать был проведен на основе общедоступного набора данных по обнаружению шлемов, предоставленного Kaggle. Автор всесторонне оценивает оригинальный YOLOv5 и различные его улучшенные версии.,На основе ключевых показателей, таких как средняя точность(mAP)、параметр、GFLOPs、Размер модели и пересечение по объединению (IoU) тщательно сравниваются.
Experimental Design
作者из实验дасуществоватьодин оборудованAMD CPU 5800xиNVIDIA GeForce Проведено на аппаратной платформе RTX4090 с использованием CUDA. 11.7иPyTorch 1.18.1 в качестве базовой структуры глубокого обучения. Все наборы данных, модели нейронных сетей и связанные ресурсы, использованные в этом исследовании, легко доступны и проверены в среде, описанной выше.
Набор данных, использованный в исследовании автора, взят из восьми проектов Kaggle по обнаружению шлемов с открытым исходным кодом, содержащих в общей сложности более 20 000 образцов изображений. Автор использует 90% изображений для обучения и 10% изображений для проверки, чтобы оценить эффективность предложенного автором метода. Помимо изменений, предложенных в этой статье, параметры по умолчанию для всех конфигураций обучения YOLOv5 остаются неизменными (их можно уточнить дополнительно). Помимо модели YOLOv5, для сравнительного анализа с предложенным автором методом автор также выбрал такие варианты, как Faster R-CNN, YOLOv5-L и Yolov3. Сравнительные эксперименты показывают, что предложенная автором модель хорошо работает с точки зрения точности и скорости обнаружения.
Ablation Study and Visualization
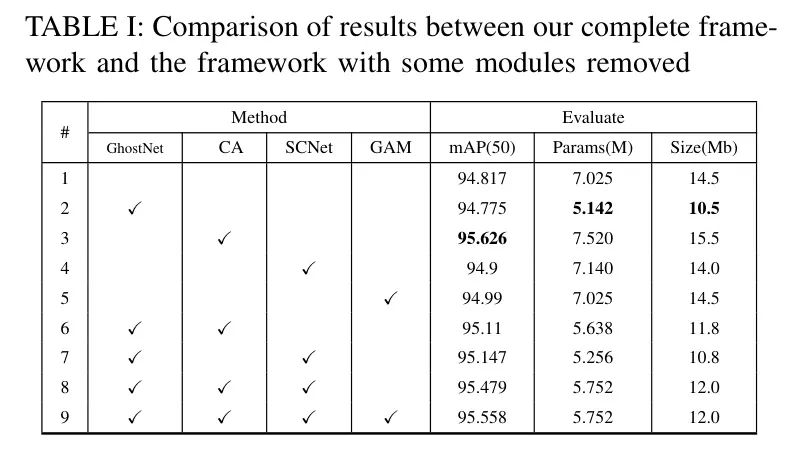
В этом исследовании авторы провели эксперименты по абляции, используя следующие методы: GhostNetV2.、Координация внимания (CA)、самокалибровающаяся свертка(SCNet)иGAMоптимизацияустройство。Автор интегрирует эти методы один за другим вYolov5середина,И протестировано на наборе данных, опубликованном в Alibaba Cloud [35]. На основе результатов, приведенных ниже,Авторы делают следующие выводы:
- Yolo в сочетании с CA получили самый высокий MAP.,Но слепое добавление модуля внимания также увеличит количество параметров.,Привести к красному дублированию модели,Использование GhostNet значительно сократило количество параметров Модели более чем на 25%. в то же время,Непосредственное использование SCNet не может эффективно повысить точность модели.,Однако возможности пространственного захвата SCNet могут эффективно компенсировать потерю точности, вызванную уменьшением размера модели. Суммируя,作者提出из Модель Можетсуществоватьзначительно уменьшенопараметр数量из同时保持高准确度。
- Автор выбрал для сравнения несколько тестовых изображений и тепловые карты, созданные в каждом эксперименте5. На карте объектов, отображаемой существованием,Модель существующего шлема, предложенная автором, работает хорошо и стабильно с точки зрения возможностей захвата функций.,Сохраняет хорошую производительность даже в условиях сложных помех,Существующий конкретный вариант меньше мешает сосредоточению внимания на,Сегментация целей и окружающей среды более совершенна.
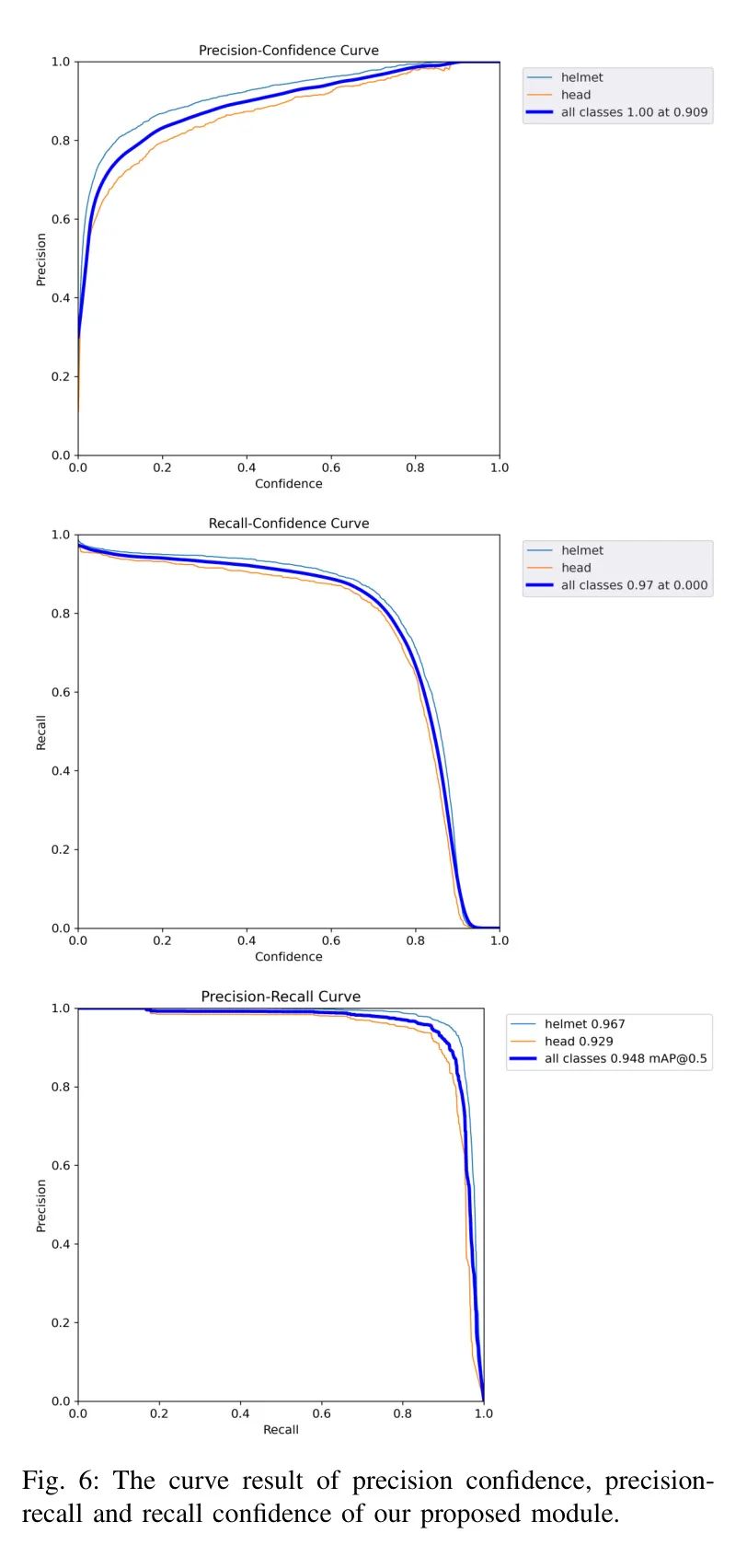
- Кривая окончательного результата показана на рисунке 6. Кривая показывает, что модель сравнения точности обнаружения «шлема» Head » выше. Это может быть связано с тем, что данные появляются концентрированно. Head данные Больше всего страдают шлемы с разной степенью окклюзии. Кривые точности-доверительности обеих категорий достигают максимальной точности при высоких уровнях достоверности. Площадь под кривой P-R (AUC) обеих категорий достаточно велика, что делает их надежными в приложениях, требующих точного и надежного обнаружения целей.
Comparative Experiment
существуют во время этого исследования,Автор провел комплексное исследование посредством серии сравнительных экспериментов.,Область действия охватывает различные сети. Основная цель автора – тщательно оценить и оценить эффективность предложенной автором Модели.,Внимательно просмотрите ряд показателей для тщательного анализа. также,Авторы выполнили перекрестное сравнение наборов данных одновременно по нескольким наборам данных.,Идите дальше в зону оценки. Этот стратегический подход имеет решающее значение для измерения общей способности существования к обобщению в рамках Модели, предложенной авторами. Путем применения авторской Модели одновременно к разным наборам данных,Автор ставит цель существования определить его адаптивность и устойчивость в различных ситуациях. Обогатить сравнительный анализ автора.,Автор тщательно отобрал три набора данных шлема с сайта Kaggle.,Эти данные для сбора данных тщательно отбираются.,чтобы охватить различные сценарии и проблемы. посредством строгих экспериментов,Автор постарался сравнить предложенную автором Модель с производительностью на этих различных наборах данных YOLOv5sсуществовать.
V Conclusion and Discussion
Автор предлагает Модель на основе YOLO.,Его характеристики: мало параметров, высокая точность обнаружения и сильная способность к обобщению.,Способен безопасно работать в сложных условиях. Однако,Может ли механизм внимания да существенно повысить точность обнаружения,Степень улучшения всегда ограничена. Как сохранить легкие характеристики Модели, одновременно повышая ее производительность.,да Вопрос, над которым должен задуматься каждый.
ссылка
[1].Better YOLO with Attention-Augmented Networkand Enhanced Generalization Performance forSafety Helmet Detection.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
