YOLO-ELA эффективное локальное моделирование внимания для высокопроизводительного обнаружения дефектов в реальном времени!

Существующие методы идентификации дефектов изоляторов с беспилотных летательных аппаратов (БПЛА) имеют низкую точность и множество ложных срабатываний при работе со сложными фоновыми сценами и небольшими объектами. Для решения этой проблемы в данной статье предлагается новая инфраструктура внимания, основанная на моделировании локального внимания, а именно YOLO-ELA. Модуль Efficient Local Attention (ELA) добавлен в часть шеи одноэтапной архитектуры YOLOv8, чтобы переключить внимание модели с фоновых функций на дефектные функции изолятора. Используйте стандартную функцию SCYLLA Intersection and Union (SIoU), чтобы уменьшить потери обнаружения, ускорить сходимость модели и повысить чувствительность модели к небольшим дефектам изолятора, что приведет к более высоким истинно положительным результатам. Поскольку набор данных ограничен, для увеличения разнообразия набора данных используются методы увеличения данных. Кроме того, авторы также использовали стратегии трансферного обучения для улучшения производительности модели. Экспериментальные результаты на изображениях дронов с высоким разрешением показывают, что авторский метод достигает самых современных результатов со средней точностью 96,9% и скоростью обнаружения в реальном времени 74,63 кадра в секунду, что лучше, чем базовая модель. Это еще раз демонстрирует эффективность сверточных нейронных сетей, основанных на внимании (CNN), в задачах обнаружения объектов.
1 Introduction
Обеспечение надежной работы инфраструктуры линий электропередачи имеет решающее значение для обеспечения стабильных поставок электроэнергии для удовлетворения энергетических потребностей частных лиц и предприятий. Поэтому проверка и техническое обслуживание компонентов опоры электропередачи, таких как изоляторы, на наличие дефектов имеет решающее значение для обеспечения безопасной работы энергосистемы. Изоляторы обеспечивают изоляцию проводников и опорных кабелей и подвержены повреждениям в результате суровых погодных условий или электромагнитного воздействия (Sanyal et al., 2020). Это может нарушить бесперебойную работу сети передачи, поэтому необходимы регулярные проверки и техническое обслуживание для выявления и замены поврежденных изоляторов.
Методы ручного контроля обычно включают визуальный осмотр линий электропередачи пешеходами на опорах. Однако из-за большого количества опор ЛЭП и их большого расстояния друг от друга этот метод является трудоемким, и работникам обычно приходится подниматься на высокие опоры (Wei et al. 2024). Полуавтоматические альтернативы предполагают использование традиционных алгоритмов обработки изображений для анализа изображений, сделанных дронами или вертолетами.
Однако эти методы отнимают много времени и подвержены ошибкам неправильного считывания из-за необходимости обработки большого количества изображений с высоким разрешением (Лю и др., 2023a). Кроме того, на эти методы влияет чувствительность сложного фона и возникают трудности с выявлением небольших дефектов изолятора. Это вызвало острую необходимость в полностью автоматизированном решении.
За последние несколько десятилетий компьютерное зрение и методы глубокого обучения все чаще используются для автоматизации различных задач по обнаружению объектов. В частности, широкое внедрение глубоких сверточных нейронных сетей (DCNN) привело к значительному улучшению как точности, так и скорости благодаря их способности извлекать и изучать функции высокого и низкого уровня из данных изображений, таких как изолированные наборы данных. Кроме того, они получают выгоду от стратегий трансферного обучения для повышения производительности за счет использования предварительно обученных весов (Liu et al., 2021).
В текущих исследованиях по обнаружению дефектов изоляторов на основе глубокого обучения в основном используются два типа детекторов DCNN. В одну категорию входят популярные двухэтапные алгоритмы обнаружения, такие как R-CNN, Fast-RCNN и Faster-RCNN (Ren et al., 2016), которые основаны на принципах, предложенных регионами-кандидатами, с последующей доработкой и выявлением дефектных регионы. Например, Вен и др. предложили два метода, основанных на Faster R-CNN, а именно Exact R-CNN (сверточная нейронная сеть точного региона) и CME-CNN (каскадное извлечение маски и сверточная нейронная сеть точного региона). Эти методы объединяют передовые методы. такие технологии, как FPN, Generalized IoU (GIoU) и извлечение маски, для повышения точности обнаружения дефектов изолятора на сложном фоне и небольших целях (до 88,7%).
Аналогично, Тан и др. (2022) реализовали улучшенную модель Faster R-CNN для обнаружения дефектов изолятора на аэрофотоснимках БПЛА, заменив VGGNet16 на ResNet50, интегрировав сеть пирамиды функций для объединения функций и используя сеть RoIAlign, минимизируя эффект квантования. тем самым достигается точность обнаружения 84,37%. Хотя эти методы могут обеспечить высокую точность в сложных сценах, их глубокая сеть приводит к низкой скорости обработки и часто не может удовлетворить требования обнаружения в реальном времени.
Чтобы устранить это ограничение, были разработаны одноступенчатые детекторы, такие как серии SSD и YOLO. Эти модели значительно увеличивают скорость обнаружения, сохраняя при этом высокую точность, что делает их более подходящими для приложений в реальном времени. Например, Аду и др. (2019) использовали YOLOv3 для обнаружения изоляторов и выявления дефектов, достигнув скорости проверки 45 кадров в секунду (FPS), что соответствует требованиям проверки в реальном времени. Аналогичным образом, Ли и др. предложили быстрый и точный метод обнаружения изоляторов и дефектов на основе YOLOv5, достигнув точности 97,82% при скорости 43,2 кадра в секунду при обнаружении в реальном времени. Это еще раз подчеркивает высокую точность и скорость YOLOv5 при обнаружении повреждений изолятора в сложных условиях, а его легкая архитектура делает его идеальным для развертывания дронов, тем самым повышая эффективность обнаружения. Однако Ding et al (2022) отметили, что из-за настройки опорной точки базовый уровень YOLOv5 все еще может страдать от фоновых помех, что приводит к ложноположительным обнаружениям. Кроме того, расстояние аэрофотосъемки с БПЛА обычно приводит к уменьшению количества пиксельной информации о дефектах изолятора на изображении (Ху и др., 2023). Это привело к более широкому внедрению Anchor-Free YOLOv8, который имеет улучшенную архитектуру, включающую модули внимания для повышения точности и скорости обнаружения дефектов. Интеграция модуля внимания в модель YOLOv8 на основе свертки направлена на то, чтобы переключить внимание модели с изучения общих характеристик на конкретные особенности дефектов изолятора, тем самым обеспечивая более высокие истинно положительные прогнозы.
В этой статье авторы предлагают новую архитектуру YOLOv8, основанную на модуле Efficient Local Attention (ELA; Xu and Wan, 2024), для повышения точности и скорости обнаружения дефектов изолятора на аэрофотоснимках дронов с высоким разрешением.
Авторы интегрировали базовый вариант ELA в компонент Neck архитектуры YOLOv8, чтобы обнаружить особенности, связанные с дефектами изолятора.
Помимо ELA, авторы также протестировали другие модули внимания, такие как модуль внимания сверточных блоков (CBAM; Woo et al., 2018), эффективное внимание к каналам и внимание к смешанным локальным каналам (MLCA; Wan et al., 2023).
Авторы реализовали стандартную функцию SIoU, чтобы уменьшить потери прогнозирования и повысить более высокое истинное положительное обнаружение в сценах с небольшой информацией о пикселях.
Авторы провели эксперимент по абляции, чтобы сравнить производительность базового YOLOv8 с улучшенной архитектурой.
Тестовая архитектура YOLOv8
YOLOv8 (Jocher et al., 2023) — это базовая модель зрения на основе свертки, используемая для решения различных задач компьютерного зрения, включая обнаружение целей. Он поставляется в пяти вариантах с одинаковой архитектурой, но различающихся количеством параметров, общей производительностью и вычислительными требованиями. Более крупные варианты работают лучше с точки зрения вычислительной нагрузки, но за счет более высокой вычислительной нагрузки. В этом исследовании авторы использовали меньший вариант YOLOv8. Как и другие варианты YOLOv8, архитектура YOLOv8 состоит из компонентов магистральной сети, шеи и головы. Магистральная сеть включает в себя сверточный модуль и модуль C2f, который сам по себе основан на модуле C3 YOLOv5 и расширенной сети ELAN (эффективной сети агрегации уровней) YOLOv7 (Wang et al., 2023). C2f состоит из двух сверточных модулей с несколькими узкими местами даркнета. Они действуют как экстракторы функций, где модуль C2f снижает вычислительную сложность за счет разделения и объединения размеров канала. Магистральная сеть подключена к компоненту Neck через уровень Spatial Pyramid Pooling Fast (SPPF). В качестве моста между магистральной сетью и Head, Neck сочетает в себе PAN и FPN (Feature Pyramid Network; Liu et al., 2018), что позволяет ему собирать обширные карты объектов, которые затем передаются в отдельный модуль Head, содержащий ветви классификации и обнаружения для Окончательный прогноз ограничивающей рамки.
3 Improved YOLOv8 Architecture
В последние годы последние достижения в базовых моделях на основе свертки привели к появлению концепции механизмов внимания, которые изначально были разработаны в моделях на основе трансформаторов для повышения производительности и точности. Сюда входит пространственное внимание, целью которого является изучение пространственной информации на уровне пикселей, и внимание канала, которое фокусируется на зависимостях на уровне канала. Интеграция этих механизмов внимания в сверточные блоки может привести к более мощному представлению функций, игнорированию некритической информации и, в конечном итоге, повышению точности обнаружения. В этой статье авторы стремятся улучшить способ выявления богатых особенностей, связанных с дефектами изолятора, путем введения модуля ELA (Xu and Wan, 2024) в шейный компонент YOLOv8. Кроме того, автор также принял стандартную функцию потерь SIoU для улучшения сходимости и точности обнаружения модели на дефектных изоляторах.
Efficient Local Attention (ELA)
Существующим модулям внимания не хватает достаточных возможностей обобщения при использовании BatchNorm, они не могут фиксировать долгосрочные зависимости и не могут уменьшить размерность канала карт объектов. Напротив, блок ELA направлен на использование надежной пространственной информации, чтобы помочь DCNN точно локализовать целевые объекты, представляющие интерес, без уменьшения размеров канала или увеличения сложности. В этом блоке используется полосовое объединение (Hou et al., 2020) вместо пространственного глобального объединения — идея, заимствованная из CA и используемая в пространственном измерении для получения богатых векторов признаков и фиксации долгосрочных зависимостей как в горизонтальном, так и в вертикальном направлении. Это гарантирует, что будут сохранены только объекты, соответствующие целевой области, а нерелевантные объекты области будут проигнорированы. Затем одномерные свертки используются для более быстрой и облегченной обработки векторов признаков в каждом направлении, при этом параметры масштабирования ядра контролируют степень локальных взаимодействий. Затем полученная карта признаков уточняется с использованием групповой регуляризации (GN; Wu and He, 2018) и нелинейной функции активации, что дает окончательный прогноз позиционного внимания. Это значительно улучшает общую производительность и способность к обобщению моделей на основе CNN лишь при небольшом увеличении количества параметров.
В этом исследовании авторы интегрировали блок ELA в шейный компонент архитектуры YOLOv8 после каждого модуля C2f (частичные узкие места Cross Stage с двумя извилинами), чтобы улучшить обнаружение дефектов изолятора на аэрофотоснимках БПЛА с высоким разрешением (см. Рисунок 1).
На каждом канале в горизонтальном направлении (H,1) и вертикальном направлении (1,W) выполните объединение полос на выходе C2f (представляющем высоту, ширину и размеры канала), генерируя номер канала _c-1_, высота равна а ширина выражается как.
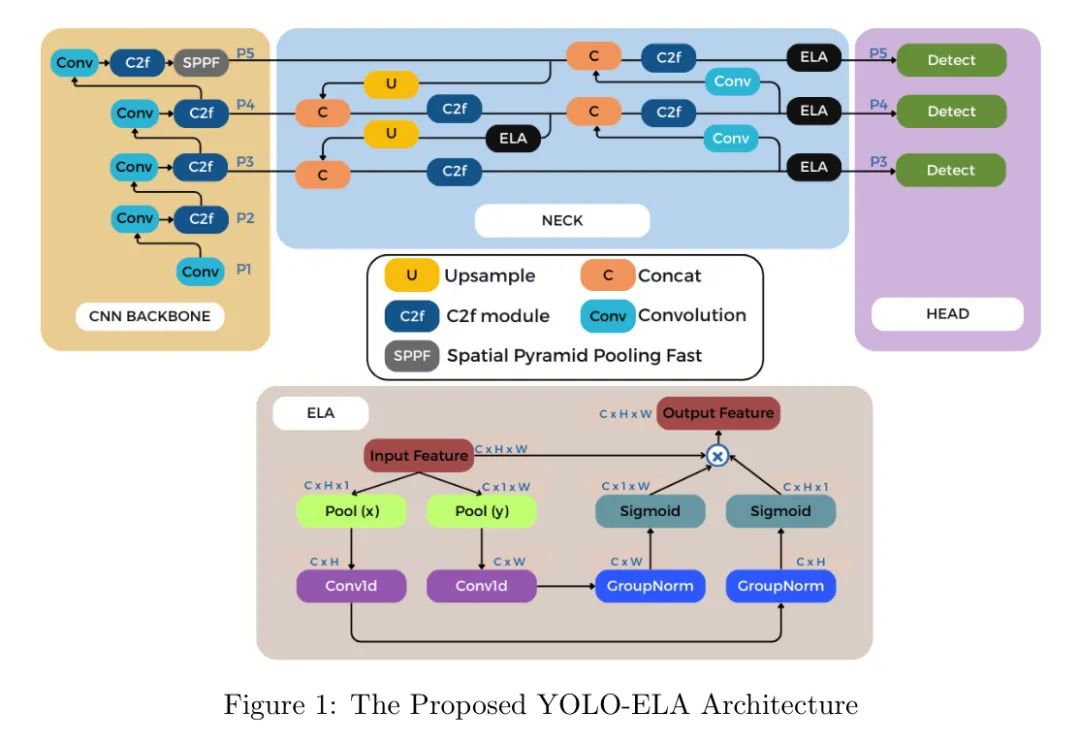
и групповая регуляризация (количество групп = 16) выполняются для улучшения и обработки пространственной информации для создания позиционных карт внимания для горизонтальной и вертикальной ориентации. Функция активации сигмоида с 7 размерами ядра свертки используется для выполнения нелинейного преобразования на графе.
Выходными данными блока ELA является локальная карта внимания, полученная из произведения функций C2f и двух направленных карт внимания, которая фиксирует тонкую пространственную информацию, необходимую для точного обнаружения дефектов изолятора.
SIoU Loss Function
В задачах обнаружения объектов индекс потерь IoU используется для измерения степени перекрытия между полем прогнозирования и целевым полем. По умолчанию YOLOv8 использует объединенную распределенную потерю фокуса (DFLoss) и потерю полного пересечения над объединением (CIoU) в ветви регрессии, чтобы уменьшить потери обнаружения во время обучения. Хотя CIoU учитывает такие факторы, как перекрытие блоков, расстояние до центральной точки и соотношение сторон, он не учитывает совпадающие траектории между блоками регрессии. Это ограничение может привести к замедлению сходимости и ухудшению производительности модели. В этом исследовании авторы заменяют CIoU потерей SIoU (Gevorgyan, 2022), чтобы преодолеть это ограничение. Стандартная функция SIoU улучшает сходимость и производительность модели за счет интеграции четырех потерь: стоимости угла, стоимости расстояния, стоимости формы и стоимости IoU, обеспечивает более мощную оценку соответствия ограничивающей рамки и повышает точность обнаружения.
На рисунке 2 показана схематическая диаграмма функции потерь SIoU. и представляют положения центральной точки прогнозируемого и реального прямоугольника соответственно. Координаты этих центральных точек соответственно представлены как (, ) для истинного блока и (, ) для прогнозируемого блока. Угол и расстояние между центральными точками и определяются значениями и соответственно. и представляют разницу между и в горизонтальных и вертикальных координатах соответственно. В то же время () и () представляют ширину и высоту прогнозируемого и истинного блока соответственно. Параметры регулируют вес потери формы во время тренировки. Математическое выражение ниже представляет функцию потерь.
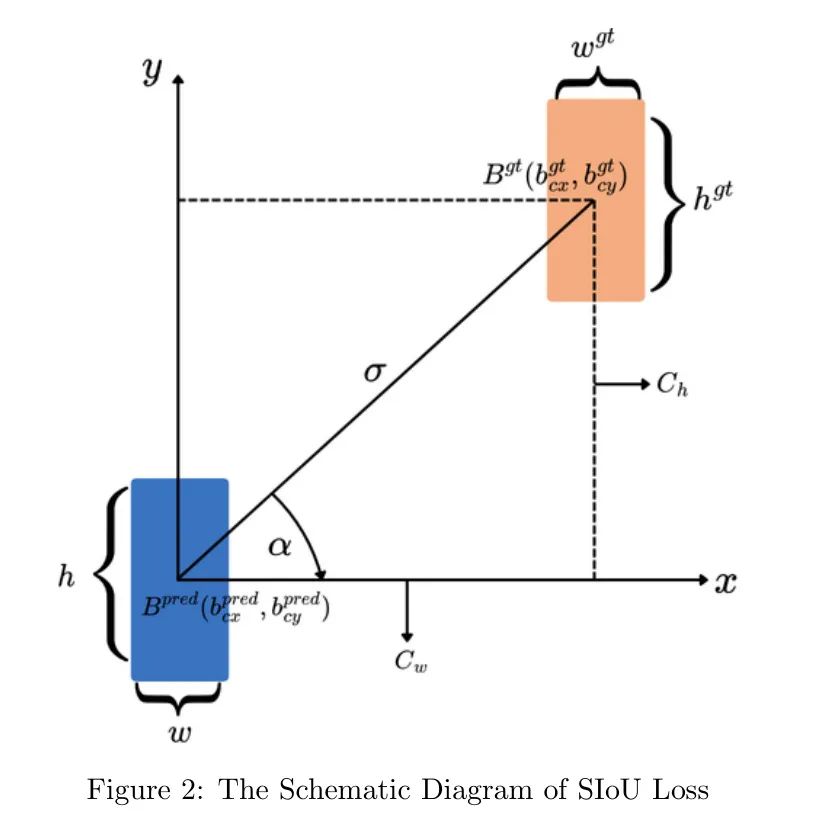
Потеря угла определяется следующим образом:
Потери на расстоянии Δ определяются на основе угловых потерь Λ и могут быть выражены как:
Потеря формы Ω может быть выражена как:
Убыток IOU рассчитывается с помощью простого выражения:
Объединив все эти функции потерь вместе, потери SIoU рассчитываются следующим образом:
4 Experiments
Computing Environment and Model Configuration
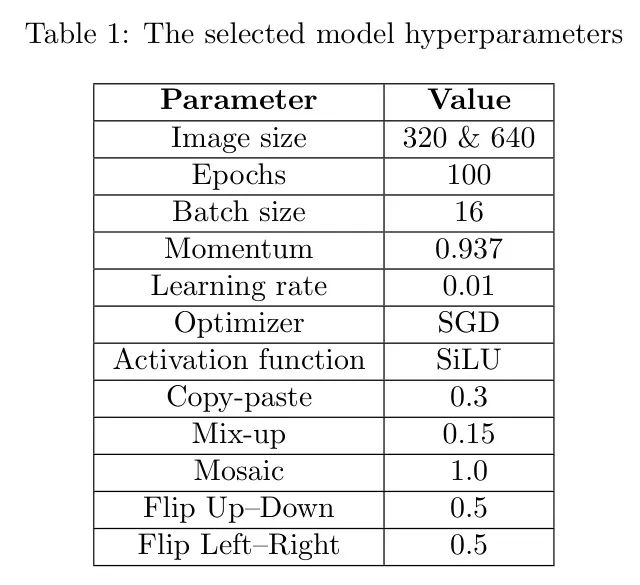
В этом исследовании авторы использовали общедоступную облачную платформу Jupyter Google Colaboratory, которая обеспечивает доступ к графическим процессорам NVIDIA A100-SXM4 и виртуальным машинам с большим объемом памяти до 40 ГБ для обучения моделей и составления прогнозов. Кроме того, архитектура модели была разработана с использованием Python 3.10 и платформы PyTorch. Как показано в таблице 1, конфигурация обучения модели использует оптимизатор стохастического градиентного спуска (SGD) с начальной и конечной скоростью обучения , снижением веса и значением импульса 0,937.
Модель обучалась на 16 изображениях на итерацию в общей сложности 100 эпох, сохраняя все остальные параметры в настройках по умолчанию. Чтобы понять влияние различных размеров обучающего входного изображения на производительность модели, автор попробовал размеры обучающего входного изображения 320 и 640 соответственно. Методы увеличения данных и стратегии трансферного обучения автоматически интегрируются в конвейер обучения для дальнейшего улучшения обучения моделей.
Dataset
Наборы данных, использованные в этой работе, были получены из двух источников:
Наборы для обучения и проверки: команда Neural Eye (Казиахмедов и Копосов, 2023) открыла исходный код самостоятельно собранного набора данных об изоляторах. Этот набор данных состоит из 802 изображений (640 x 640 пикселей) стеклянных изоляторов в форме дисков, снятых с точки зрения снизу. Данные также содержат несоответствующие изображения без соответствующих файлов меток, которые используются в качестве фоновых изображений в процессе обучения и проверки для снижения уровня ложных срабатываний (см. Таблицу 2). Все данные случайным образом делятся на обучающий и проверочный наборы с использованием разделения 8:2, а обучающие изображения содержат более 700 отсутствующих экземпляров изолятора.
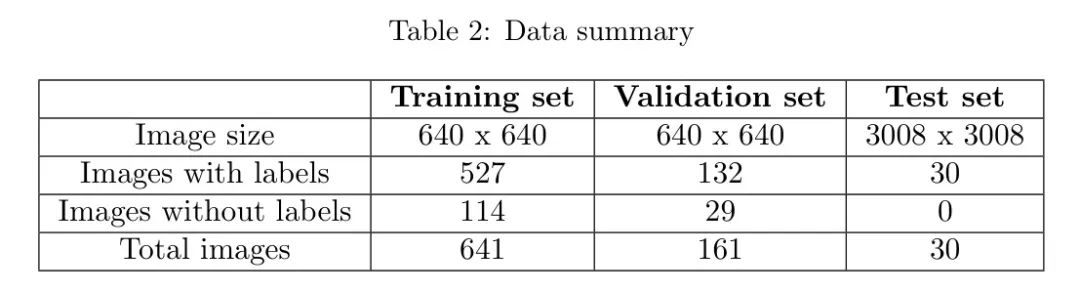
Набор слепых тестов: набор слепых данных получен из Innopolis High Volt Challenge на Kaggle (Новиков и Егоров, 2023). Данные состоят из 30 слепых тестовых изображений высокого разрешения (4000 × 2250 пикселей), снятых с высоты птичьего полета дроном, летящим по оси линии электропередачи, на высоте съемки от 15 до 70 метров и углах наклона камеры. между 45° и между 70°. Для размещения доступных вычислительных ресурсов изображения были масштабированы до 3008×3008 пикселей.
Data Augmentation
Учитывая ограниченное количество обучающих изображений, авторы увеличили количество обучающих данных, чтобы увеличить разнообразие набора данных и улучшить способность модели масштабироваться в различных ситуациях. Используемые методы улучшения включают переворачивание изображения по горизонтали (влево-вправо) и по вертикали (вверх-вниз). Он также включает более продвинутые методы улучшения, такие как Mosaic, которая объединяет четыре изображения в новое составное изображение, которое генерирует взвешенную комбинацию случайных пар изображений, и Copy-Paste, которое применяет к изображению случайное масштабирование; Затем вставьте его в другое изображение. Все эти методы повышения являются вероятностно управляемыми, что отражает вероятность применения повышения в обучающем конвейере. Однако улучшение мозаики отключается на 90 эпохах, чтобы улучшить сходимость модели. Стоит отметить, что эти методы дополнения не применялись к данным проверки.
Evaluation metrics
В этой работе авторы рассматривают возможность применения YOLOv8 на основе внимания для обнаружения дефектов изолятора в реальном времени. Основной метрикой оценки, которую рассматривает автор, является количество кадров в секунду (FPS), но есть и другие метрики, такие как количество параметров, скорость отзыва, средняя средняя точность (mAP_0,5) и гига операций с плавающей запятой в секунду (GFLOPs). .
Параметры:Количество параметров зависит от Модельизсложность,Это контролирует вычислительные ресурсы, необходимые для обучения и тренировок. Чем больше количество параметров,Модель более сложная. Это приводит к повышению производительности,Но в то же время необходимо выделить больше вычислительных ресурсов. Обнаружение в режиме реального времени,Крайне важно сбалансировать количество параметров с вычислительными затратами на вывод.
Миллиарды операций с плавающей запятой в секунду (GFLOP):GFLOPsэто метод измерения,Измеряет количество миллиардов операций с плавающей запятой, выполняемых в секунду.,И используется для оценки модели аппаратных систем по сложности и скорости обработки. В задачах обнаружения в реальном времени,GFLOP ниже и больше подходит для быстрого исполнения.,Хотя более высокие GFLOP могут повысить точность за счет увеличения вычислительной сложности.
Кадры в секунду (FPS):В задачах обнаружения целей в реальном времени,FPS Эта метрика идеальна, поскольку она измеряет, насколько быстро модель обрабатывает изображения в секунду. Это контролируется сложностью модели и аппаратным обеспечением. Обычно оно измеряется в миллисекундах как величина, обратная времени вывода. Иметь более высокий FPS Эта модель более популярна в приложениях реального времени, поскольку она может более эффективно обрабатывать больше кадров, обеспечивая более быстрое обнаружение или обработку.
Точность (P), полнота (R) и средняя точность (mAP):Точность измерения Модельделатьизистинное положительное предсказание среди положительных предсказанийиз Пропорция,Указывает на положительную точность прогноза. с другой стороны,Напомним, оценивает чувствительность Модели при обнаружении истинно положительных образцов. Эти показатели объединяются для расчета средней точности (mAP).,Он обеспечивает общую оценку Модели с точки зрения обнаружения дефектов изоляции с порогом перекрытия 0,5 производительности. Более высокий показатель изmAP указывает на то, что производительность лучше обнаруживает дефекты.
Experimental Results
Как упоминалось ранее, мы обучили нашу модель, используя обучающие наборы с размерами входных изображений с разрешением 320 и 640, а затем протестировали ее производительность на тестовом наборе с высоким разрешением и размером входных данных 3008. Целью этого эксперимента является демонстрация предложенной автором модели YOLOv8+ELA при обнаружении дефектов высоковольтных электродов в сравнении с другими моделями YOLOv8, основанными на внимании (такими как YOLOv8+ECA, YOLOv8+MLCA, YOLOv8+CA и YOLOv8+CBAM). Превосходная производительность на изображениях с высоким разрешением после обучения на входных изображениях с низким разрешением.
Как и в других моделях, модуль внимания в YOLOv8 также интегрирован в шейную часть YOLOv8. Как показано в таблице 3, производительность модели, основанной на внимании, обычно улучшается при обучении с использованием размера входных данных 640 по сравнению с использованием размера входных данных 320. Например, YOLOv8+ECA достиг mAP0.5, равного 84,7% и 95,6% при размерах входных данных 320 и 640 соответственно. YOLOv8+MLCA еще больше улучшил производительность, достигнув mAP0,5 84,9% и 96,9% при том же размере ввода. Что касается других показателей, таких как точность и полнота, оценки точности теста YOLOv8+ECA и YOLOv8+MLCA одинаковы, когда размер обучающего изображения равен 640, как и тестовый отзыв, когда размер обучающего изображения равен 320. Однако YOLOv8+MLCA добавляет 0,2 ГБ в FLOP, что приводит к снижению скорости обнаружения на 4,02 кадра в секунду.
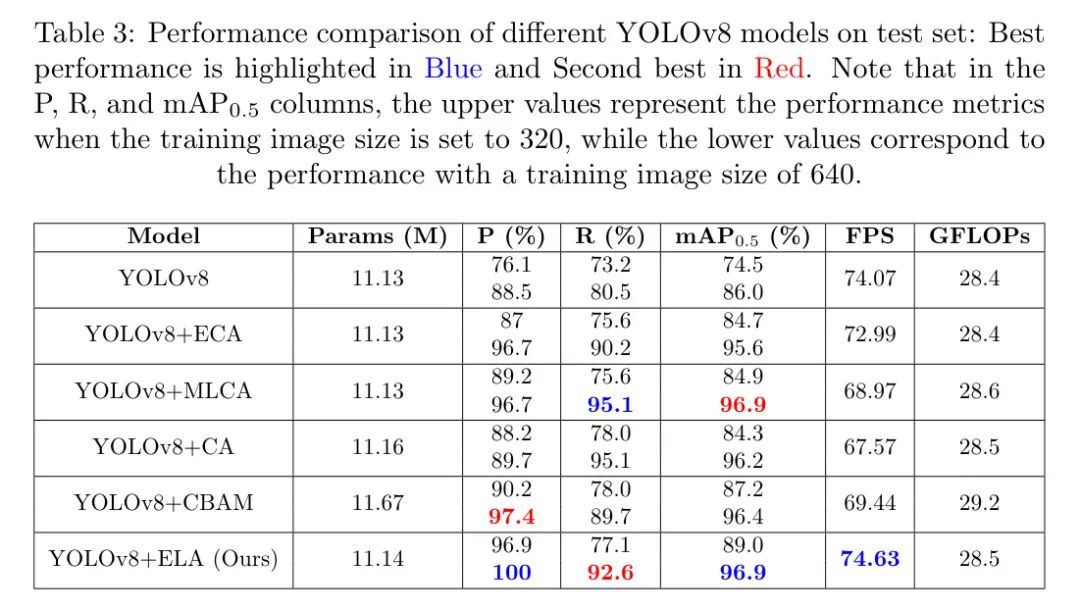
Работа Сюй и Вана (2024) подчеркивает преимущества ELA в улучшении модулей CA и CBAM. Это улучшение особенно заметно при обнаружении дефектов изолятора, когда YOLOv8+ELA достиг лучших результатов теста mAP0.5 — 89% и 96,9% при входных размерах 320 и 640 соответственно — сравнимо с моделями YOLOv8+CA и YOLOv8+CBAM. по сравнению с предыдущим годом средний рост составил 3,3% и 0,6%. Хотя YOLOv8+MLCA и предложенная модель YOLOv8+ELA достигли одинакового показателя mAP0,5, равного 96,9%, при обучении с размером входных данных 640, YOLOv8+ELA продемонстрировала более высокое значение точности — 100%, что указывает на ее точность по отношению к истинным положительным результатам. Превосходная чувствительность. обнаружения. Хотя модели YOLOv8+CA и YOLOv8+CBAM имеют в среднем на 0,28 млн обучаемых параметров больше, чем YOLOv8+ELA, они не могут превзойти скорость и точность YOLOv8+ELA по всем показателям. Примечательно, что хотя обучение на входных данных большего размера увеличивает время обучения, время вывода остается постоянным, поскольку все модели используют один и тот же размер тестового изображения с высоким разрешением. Кроме того, разные размеры обучающих изображений на тестовом наборе не повлияли на параметры, FPS и GLOP модели на тестовом наборе.
Ablation Study
Эта работа направлена на улучшение базовой модели путем интеграции блока ELA в сегмент шеи модели YOLOv8 и замены стандартной функции потерей SIoU. Чтобы оценить эффективность этих двух стратегий увеличения, авторы провели эксперименты по абляции, используя одни и те же настройки конфигурации модели, экспериментальные настройки и условия данных. Эти эксперименты показывают влияние каждого улучшения на производительность модели.
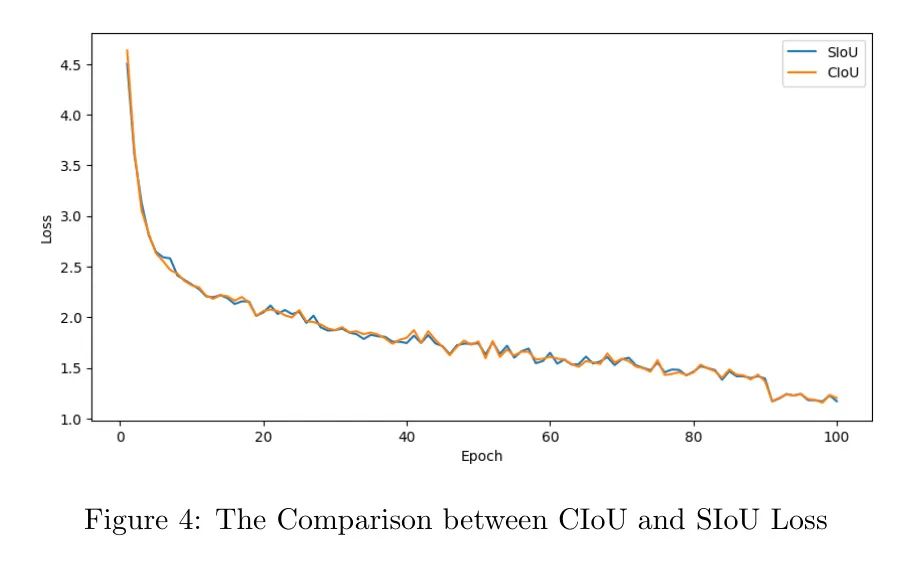
На рисунке 4 показано сравнение кривых потерь при обучении YOLOv8+ELA при функциях потерь SIoU и CIoU. Судя по визуальному анализу, потери на обучение постепенно уменьшаются по мере увеличения количества итераций, что указывает на то, что модель корректирует свои веса и параметры в соответствии с набором данных изолятора. Модель начинает сходиться на пятой эпохе и продолжает уменьшаться на протяжении всего процесса обучения. Стоит отметить, что первоначальные потери модели с использованием функции потерь SIoU значительно ниже, чем у CIoU, и в последнюю эпоху потери SIoU остаются стабильно низкими. Это сокращение потерь приводит к общему улучшению оптимизации модели.
Кроме того, предлагаемая модель YOLOv8 превосходит исходную модель YOLOv8 по всем размерам обучающих входных данных по сравнению с модулем ELA. Как показано в таблице 4, mAP модели YOLOv8+ELA увеличилась на 14,5% и 10,9% соответственно, когда размер обучающих входных данных составлял 320 и 640. Хотя количество параметров и FLOP увеличилось с 11,13M до 11,14M и с 28,4G до 28,5G, модель YOLOv8+ELA по-прежнему может достигать максимальной скорости обработки 74,63 кадра в секунду, что на 0,56 кадра в секунду больше по сравнению с исходным YOLOv8. модель. Это показывает, что предлагаемая модель лучше работает при развертывании в реальном времени, улучшая как скорость, так и точность.
На рисунке 5 показаны тепловые карты базовых моделей YOLOv8 и YOLOv8+ELA, созданные с помощью GradCAM (Gradient Weighted Class Activation Map; Selvaraju et al., 2017). Видно, что модель Baseline специально фокусируется на характеристиках дефектного изолятора и некоторых фоновых особенностях, когда он находится глубже (ближе к выходному слою). Однако по сравнению с YOLOv8+ELA фоновые помехи полностью устранены благодаря способности запоминать только особенности, связанные с дефектными изоляторами. Этот процесс подчеркивает улучшение внимания предлагаемой модели от фоновых особенностей и хороших изоляторов к дефектным изоляторам в линиях электропередачи.

Как показано на рисунке 6, YOLOv8+ELA представляет некоторые результаты обнаружения в сложных фоновых условиях. Изображения включают в себя различные объекты, такие как деревья, башни, пешеходы, дорожные сети, автомобили и дома и т. д. Кроме того, дрон находится дальше от башни, из-за чего изоляционные объекты на изображении становятся меньше, что затрудняет обнаружение. Несмотря на эти трудности, YOLOv8+ELA успешно обнаружил все дефектные изоляторы с уровнем достоверности 80%.

Ссылки
[0]. YOLO-ELA: Efficient Local Attention Modeling for High-Performance Real-Time Insulator Defect Detection.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
