Взорваться! Легкий YOLO | ShuffleNetv2 в сочетании с Transformer изменяет форму YOLOv7 и обеспечивает сверхлегкий и сверхбыстрый YOLO

В условиях быстрого развития технологий мобильных вычислений внедрение эффективных алгоритмов обнаружения целей на мобильных устройствах стало ключевым моментом исследований в области компьютерного зрения. Это исследование сосредоточено на оптимизации алгоритма YOLOv7 с целью повышения эффективности и скорости его работы на мобильных платформах при обеспечении высокой точности. Объединив передовые технологии, такие как групповая свертка, ShuffleNetV2 и визуальный преобразователь, это исследование эффективно уменьшает количество параметров и использование памяти модели, упрощает сетевую архитектуру и расширяет возможности обнаружения целей в реальном времени на устройствах с ограниченными ресурсами. Результаты экспериментов показывают, что улучшенная модель YOLO работает хорошо, значительно увеличивая скорость обработки при сохранении превосходной точности обнаружения.
1 Introduction
С быстрым развитием области компьютерного зрения обнаружение объектов стало иметь решающее значение в различных приложениях, включая, помимо прочего, мониторинг безопасности, автономное вождение и интеллектуальное медицинское обслуживание. Хотя традиционные методы обнаружения целей имеют проблемы, связанные с высокой вычислительной сложностью и недостаточной производительностью в реальном времени, алгоритмы глубокого обучения совершили значительный прорыв в точности и производительности в реальном времени. Среди них YOLO стал классическим алгоритмом обнаружения целей в реальном времени, который обеспечивает баланс между скоростью вычислений и точностью обнаружения. Однако мобильные устройства часто ограничены с точки зрения вычислительной мощности, объема памяти и энергопотребления, что усложняет развертывание моделей глубокого обучения.
Чтобы адаптировать эти модели YOLO к этим средам, необходимы дальнейшие улучшения и оптимизации. В этой статье будут подробно рассмотрены исследования расширенной модели YOLO, оптимизированной для мобильного развертывания, с упором на оптимизацию сетевой структуры, сжатие и ускорение модели, повышение надежности и оценку производительности в различных сценариях приложений.
Основные цели этого исследования включают изучение и понимание сути алгоритма YOLO и его вариантов в задачах обнаружения объектов. Основное внимание в этой работе будет уделено освоению основных принципов и основных механизмов алгоритма YOLO, а также его эффективности в различных задачах и сценариях. Это включает, помимо прочего, углубленное исследование сетевой архитектуры YOLO, функции потерь, стратегии обучения и сравнительный анализ с другими алгоритмами обнаружения целей.
Учитывая характеристики мобильных устройств, данное исследование направлено на разработку и реализацию усовершенствований модели YOLO. Учитывая ограничения вычислительной мощности и памяти мобильных устройств, исследования будут направлены на оптимизацию структуры и алгоритма модели YOLO. Это может включать в себя упрощенную конструкцию модели, эффективную реализацию алгоритмов и специальную оптимизацию оборудования, и все это направлено на значительное улучшение производительности и эффективности модели на мобильных устройствах при сохранении точности обнаружения. Также будет важно проверить и оценить производительность улучшенной модели на стандартных наборах данных, а также ее эффективность на реальных мобильных устройствах.
В ходе исследования будет дополнительно оценена производительность и эффективность расширенной модели YOLO посредством экспериментальной проверки на стандартных наборах данных и тестирования развертывания в реальных средах мобильных устройств. Эта комплексная оценка поможет гарантировать, что улучшенные модели не только будут развиваться теоретически, но и продемонстрируют осуществимость и эффективность в практическом применении.
Основные положения данной статьи резюмируются следующим образом:
- В улучшенной YOLOМодель,Тщательно используйте и используйте концепцию дизайна ShuffleNet v2. в частности,Сочетание перетасовки каналов и групповой свертки эффективно балансирует сложность модели с производительностью. Этот дизайн не только повышает эффективность модели.,Он также поддерживает сильные возможности извлечения функций.,Обеспечивает обнаружение целей в реальном времени на мобильных устройствах. также,За счет использования таких методов, как пропуск соединений и отделимые по глубине извилины.,Надежность и точность модели еще больше повышаются.
- Среди доработок для YOLOМодель,Использование Трансформатора Зрения (ViT) в качестве основного компонента извлечения признаков,Не только расширяет возможности Модели захватывать общую контекстную информацию изображения.,А это существенно повышает точность обнаружения целей и эффективность. Способность ViT фиксировать зависимости на больших расстояниях и отличные характеристики трансферного обучения.,Сделайте модель более эффективной при работе со сложными сценами.,Особенно в приложениях на мобильных устройствах,Демонстрация значительных преимуществ производительности в реальном времени.
2 Related Work
ShuffleNet v2
ShuffleNet v2 направлен на достижение эффективных вычислений и снижение сложности модели при сохранении высокой производительности, что является сложной задачей, поскольку снижение сложности часто рискует пожертвовать точностью. Однако ShuffleNet v2 успешно решает эту проблему благодаря нескольким ключевым нововведениям. В отличие от своих предшественников, которые использовали групповую свертку для сокращения параметров и вычислений, ShuffleNet v2 улучшает взаимодействие функций внутри каждой группы, чтобы улучшить возможности представления модели.
В частности, он отказывается от ограничений группировки при поточечной свертке, позволяя всем каналам участвовать в свертке 1x1, упрощая структуру сети, снижая затраты на доступ к памяти и улучшая поток информации. Кроме того, за счет уменьшения сегментации каналов в структуре узких мест он позволяет избежать потенциальных информационных узких мест, связанных с сгруппированными свертками, достигая более сбалансированного распределения вычислительной нагрузки и повышая эффективность модели.
Кроме того, ShuffleNet v2 оптимизирует механизм перетасовки каналов, представленный в ShuffleNet v1, используя разгруппированную поточечную свертку, сегментацию каналов и улучшенные стратегии объединения функций для достижения более эффективного обмена информацией между группами за счет реорганизации входных функций. Упорядочение каналов графа, тем самым обогащая представление функции.
Vision Transformer (ViT)
Vision Transformer (ViT) — это инновационная архитектура глубокого обучения, разработанная для задач компьютерного зрения, которая знаменует собой серьезный сдвиг за счет адаптации структуры Transformer, первоначально разработанной для обработки естественного языка, к области зрения. ViT сначала сегментирует входное изображение на серию фрагментов и преобразует эти фрагменты в многомерные векторы внедрения, которые фиксируют локальные особенности изображения.
Чтобы компенсировать отсутствие присущих Трансформатору возможностей обработки последовательностей, к этим векторам внедрения добавляется кодирование позиции, что позволяет механизму самообслуживания в ViT фиксировать зависимости на больших расстояниях между различными сегментами изображения. Кодеры-трансформеры обрабатывают эти внедрения, фокусируясь на различных аспектах изображения, чтобы обеспечить надежное представление функций для различных задач машинного зрения. Преобразованные векторы, в частности, с помощью специального вектора внедрения «классификации» для задач классификации, затем используются для вывода окончательных результатов для конкретной задачи, демонстрируя адаптируемость и эффективность ViT при обработке сложной визуальной информации.
You Only Look Once (YOLO)
На протяжении многих лет серия YOLO была одной из лучших категорий одноступенчатых детекторов объектов в реальном времени. YOLO преобразует задачу обнаружения целей в задачу регрессии, прогнозирует положения и категории нескольких целей за одно прямое распространение и обеспечивает высокоскоростное обнаружение целей. После многих лет разработки YOLO превратилась в серию быстрых моделей с хорошей производительностью.
Методы YOLO на основе поля привязки включают YOLOv4, YOLOv5 и YOLOv7, а методы без поля привязки включают YOLOX и YOLOv6. Учитывая производительность этих детекторов, методы без якорного ящика работают так же хорошо, как и методы на основе якорного ящика, и якорные ящики больше не являются основным фактором, ограничивающим развитие YOLO.
Однако все варианты YOLO генерируют множество избыточных ограничивающих рамок, которые необходимо отфильтровывать с помощью NMS (немаксимальное подавление) на этапе прогнозирования, что существенно влияет на точность и скорость детектора по сравнению с детекторами объектов в реальном времени. конфликт.
3 YOLO Model Architecture
Model Overview
В этой главе основное внимание уделяется двум ключевым модулям: модулю динамического группового перемешивания свертки (DGSM) и преобразователю динамического группового перемешивания свертки (DGST).
Модуль DGSM используется для оптимизации магистральной сети и значительно повышает эффективность вычислений, сохраняя при этом отличную производительность за счет сочетания технологии групповой свертки и перетасовки каналов. Модуль DGST, используемый для оптимизации сети Neck, дополнительно объединяет технологии Visual Transformer, Group Convolution и Channel Shuffle для достижения более высокой эффективности вычислений и адаптивности. Этот модуль также упрощает структуру сети и повышает эффективность обнаружения.
Dynamic Group Convolution Shuffle Module (DGSM)
В DGSM введение групповой свертки, показанное на рисунке 1, уменьшает количество параметров и вычислительных требований модели, одновременно предотвращая переобучение, тем самым сохраняя надежность и способность к обобщению сети. Кроме того, технология перетасовки каналов ShuffleNetV2 облегчает эффективный обмен информацией о функциях между группами, что имеет решающее значение для поддержания всеобъемлющих выразительных возможностей сети. Стоит отметить, что этот механизм обмена помогает сохранить разнообразие и богатство функций при сокращении количества параметров.
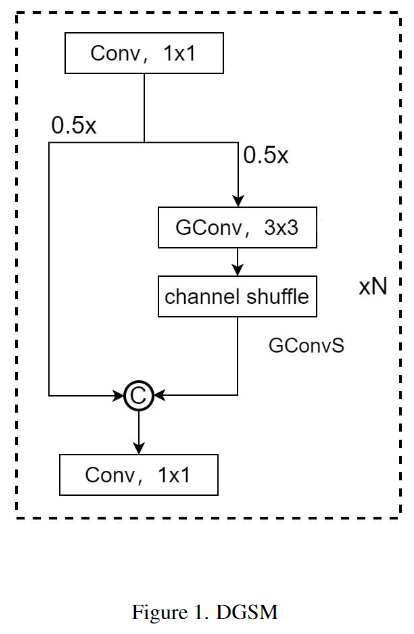
Как показано в таблице 1, новый модуль DGSM может точно регулировать количество блоков стекирования и количество каналов в соответствии с различными уровнями требований, заменяя исходный модуль ELAN для формирования новой магистральной сети. Этот точно настроенный метод управления и оптимизации позволяет модели более эффективно обрабатывать функции различных масштабов, сохраняя при этом вычислительную эффективность, что значительно улучшает применимость и производительность модели в практических приложениях.

Dynamic Group Convolution Shuffle Transformer (DGST)
Трансформатор динамического группового перемешивания (DGST) — это инновационная структура, как показано на рисунке 2, которая сочетает в себе визуальный преобразователь с модулем DGSM для дальнейшего повышения вычислительной эффективности и производительности модели. Ядром модуля DGST является стратегия разделения 3:1, часть которой выполняет операции групповой свертки и перетасовки каналов, а операция свертки заменяет полностью связанный линейный слой для достижения того же эффекта. Используйте этот модуль для замены исходного модуля Neck. . Такая конструкция не только снижает вычислительные требования, но и лучше адаптируется к характеристикам сверточных нейронных сетей, потенциально обеспечивая превосходную производительность модели.
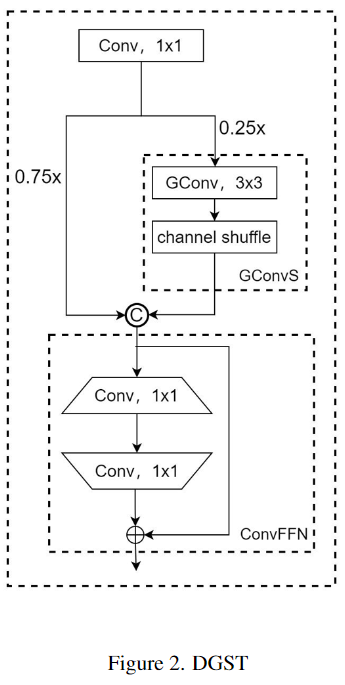
Для дальнейшей оптимизации общей сетевой архитектуры автор скорректировал конфигурацию головок обнаружения и сократил исходные три головки обнаружения до двух, как показано на рисунке 3. Эта модификация не только снижает вычислительную нагрузку модели, но и повышает эффективность обнаружения. Уменьшение количества головок обнаружения означает, что на этапе постобработки требуется обрабатывать меньше данных, что ускоряет вывод всей модели.
4 Experiment
Setups
Набор данных, использованный в этом эксперименте, содержит 1919 личных изображений, включая портреты в масках и без них. Сбор наборов данных охватывает несколько источников:
гугл изображения:Публичные изображения, связанные с ношением масок, были получены через поисковую систему Google.。
Поиск в Bing:использовать Поиск в Движок Bing собирает изображения пешеходов в различных сценах и фонах.
Набор данных Kaggle:отKaggleсуществующий на платформеданные Подмножество соответствующих изображений, подходящих для этого эксперимента, было выбрано централизованно.。
Все изображения аннотированы в формате YOLO, а на метках указано, носит ли пешеход маску. Этот стиль аннотаций делает изображение подходящим для обучения модели обнаружения целей YOLO, обеспечивая удобную основу данных для этого эксперимента.
Стратегия разделения набора данных является ключевым шагом для обеспечения эффективного обучения и справедливой оценки модели. Данные для этого эксперимента разделены следующим образом:
обучающий набор:используется для Модельобучающие изображения,70% сбора данных.
Набор проверки:используется для Модель Настройка изображения и выбор гиперпараметров,15% от набора данных.
тестовый набор:используется дляфинальный Модель Оцененные изображения,Также представляет собой 15% набора данных.
Analysis
Как видно из таблицы 2, модель YOLO7 Tiny показывает лучшую производительность с точки зрения потерь на обучение, но у нее также самое высокое потребление графического процессора. При рассмотрении потребления и потерь графического процессора комбинированная модель DGST+DGSM обеспечивает более сбалансированный выбор.
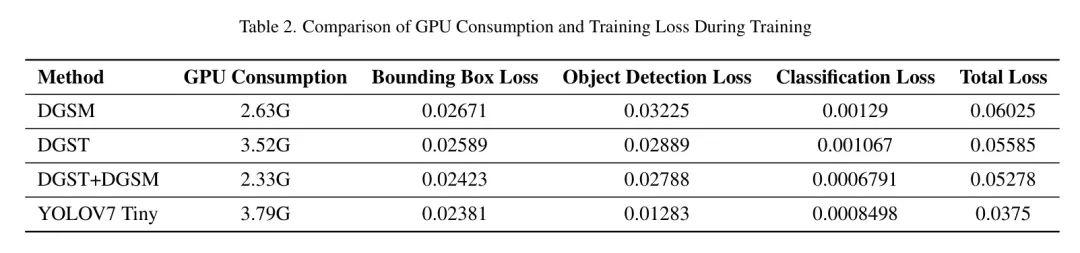
В качестве облегченного варианта модель YOLOv7 Tiny продемонстрировала в экспериментах свои уникальные эксплуатационные характеристики. Во время обучения потребление графического процессора этой модели составляет 3,79 ГБ, что является самым высоким показателем среди четырех моделей. Размер его параметра также является самым большим — 6,01 М, что указывает на более высокую сложность модели. Время вывода составляет 283,4 мс, а общее время — 284,7 мс, оба из которых являются самыми высокими среди моделей, что может означать, что существует компромисс в скорости вычислений при реализации более сложных или детальных функций.
Модель DGSM показала в экспериментах определенные преимущества. Потребление графического процессора во время обучения составляет 2,63 ГБ, а размер параметра — 4,45 МБ, что указывает на умеренную сложность модели. Время единственного вывода составляет 242,1 мс, что демонстрирует разумную вычислительную эффективность. Хотя общее время немного больше и составляет 243,9 мс, это может отражать его стабильность при обработке сложных ситуаций.
Модель DGST продемонстрировала свои уникальные преимущества в экспериментах. Потребление графического процессора во время обучения составляет 3,52 ГБ, что немного выше, чем у DGSM, но размер его параметра составляет 3,58 МБ, немного меньше, чем у DGSM, что указывает на более высокую эффективность его параметров. Его время одиночного вывода составляет 190,5 мс, а общее время — 191,6 мс, что ниже, чем у DGSM, что показывает, что DGST может поддерживать хорошую скорость вывода, сохраняя при этом низкую вычислительную нагрузку.
Комбинированная модель DGSM+DGST показывает хорошие результаты по нескольким ключевым показателям. Потребление графического процессора во время обучения составляет 2,33 ГБ, что относительно мало, а размер параметра является наименьшим — 2,02 МБ, что демонстрирует отличную эффективность параметров. Время вывода составляет 136,8 мс, а общее время — 137,9 мс, что является самым быстрым показателем среди всех моделей, что подчеркивает его превосходную скорость вычислений и эффективность.
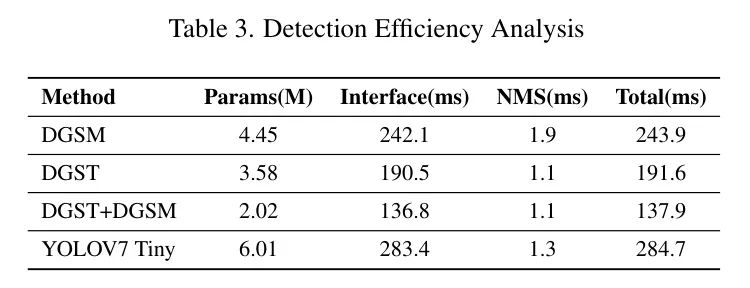
При дальнейшем анализе эффективности обнаружения целей четырех конфигураций модели в таблице 3, включая такие показатели, как точность, полнота и mAP, модель DGST получила наивысший балл F1 (0,8524), что указывает на то, что между точностью и полнотой был достигнут лучший баланс. . Комбинированная модель DGST+DGSM последовала за ней с показателем F1 0,8493, что также демонстрирует хороший баланс.
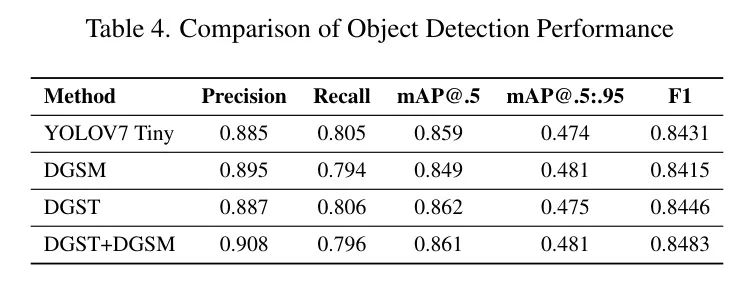
Всестороннее сравнение подчеркивает превосходные характеристики комбинированной модели DGST+DGSM при mAP@.5 и mAP@.5:.95, что означает отличные возможности обнаружения при различных порогах IoU (см. Таблицу 4). Хотя модель DGST показала конкурентоспособные результаты по некоторым показателям, комбинированная модель показала более сбалансированные и превосходные результаты при более строгих критериях оценки.
5 Conclusion
При развертывании моделей обнаружения объектов на мобильных устройствах основные проблемы включают ограниченную вычислительную мощность, ограничения памяти и проблемы с энергопотреблением. В этом исследовании представлен тщательный анализ и обсуждение, определяющее ключевые направления улучшения производительности легких моделей.
ссылка
[1].Lightweight Object Detection: A Study Based on YOLOv7 Integrated with ShuffleNetv2 and Vision Transformer.


.NET Как загрузить файлы через HttpWebRequest

[Веселый проект Docker] Обновленная версия 2023 года! Создайте эксклюзивный инструмент управления паролями за 10 минут — Vaultwarden
Высокопроизводительная библиотека бревен Golang zap + компонент для резки бревен лесоруба подробное объяснение

Концепция и использование Springboot ConstraintValidator

Новые функции Go 1.23: точная настройка основных библиотек, таких как срезы и синхронизация, значительно улучшающая процесс разработки.

[Весна] Введение и базовое использование AOP в Spring, SpringBoot использует AOP.

Чтобы начать работу с рабочим процессом Flowable, этой статьи достаточно.

Байтовое интервью: как решить проблему с задержкой сообщений MQ?
ASP.NET Core использует функциональные переключатели для управления реализацией доступа по маршрутизации.
[Проблема] Решение Невозможно подключиться к Redis; вложенное исключение — io.lettuce.core.RedisConnectionException.
От теории к практике: проектирование чистой архитектуры в проектах Go
Решение проблемы искажения китайских символов при чтении файлов Net Core.
Реализация легких независимых конвейеров с использованием Brighter

Как удалить и вернуть указанную пару ключ-значение из ассоциативного массива в PHP
Feiniu fnos использует Docker для развертывания учебного пособия по AList
Принципы и практика использования многопоточности в различных версиях .NET.
Как использовать PaddleOCRSharp в рамках .NET

CRUD используется уже два или три года. Как читать исходный код Spring?

Устраните проблему совместимости между версией Spring Boot и Gradle Java: возникла проблема при настройке корневого проекта «demo1» > Не удалось.

Научите вас шаг за шагом, как настроить Nginx.
Это руководство — все, что вам нужно для руководства по автономному развертыванию сервера для проектов Python уровня няни (рекомендуемый сборник).

Не удалось запустить docker.service — Подробное объяснение идеального решения ️

Настройка файлового сервера Samba в системе Linux Centos. Анализ NetBIOS (супер подробно)
Как настроить метод ssh в Git, как получить и отправить код через метод ssh

RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем
