Взгляд на Recall Augmented Generation (RAG) в langchain
Обзор[2]
Что такое РАГ? [3]
RAG — это метод, который расширяет знания LLM с помощью дополнительных, часто частных данных или данных в реальном времени. LLM способны рассуждать на самые разные темы, но их знания ограничены общедоступными данными, на которых они обучались, вплоть до конкретного момента времени. Если вы хотите создать приложение ИИ, которое может анализировать частные данные или данные, представленные после крайнего срока модели, вам необходимо дополнить знания модели конкретной информацией. Процесс внесения и вставки соответствующей информации в сигналы модели называется генерацией поискового расширения (RAG).
Что содержит это руководство? [4]
В LangChain есть некоторые компоненты, специально разработанные для создания приложений RAG. Чтобы ознакомиться с этими компонентами, мы создадим простое приложение вопросов и ответов на основе текстового источника данных. В частности,мы будем использовать Лилиан Вэн измагистр права Powered Autonomous Создайте робота для контроля качества на основе статьи в блоге Agents[5]. Попутно мы представим типичную архитектуру контроля качества, обсудим соответствующие компоненты LangChain и выделим дополнительные ресурсы для более продвинутых методов контроля качества. Мы также увидим, как LangSmith может помочь нам отслеживать и понимать наши приложения. По мере усложнения наших приложений LangSmith будет становиться все более полезным. Уведомление Здесь мы ориентируемся на неструктурированные данные Тряпка. Два, которые мы рассмотрели в другом месте RAG Сценарии применения:
• Структурированные данные QA[6] (например, SQL) • Код QA[7] (например, Python)
Архитектура[8]
типичный RAG Приложение состоит из двух основных компонентов: Индексирование:взять из источникаданныеи продолжайтеиндекспроцесс。
Обычно делается офлайн.
Получить и сгенерировать:действительныйRAGцепь,Получайте запросы пользователей во время выполнения и извлекайте соответствующую информацию из индекса.,Затем передайте его Модель.
Наиболее распространенная полная последовательность перехода от необработанных данных к ответу выглядит следующим образом:
Индексирование[9]"
1.нагрузка:первый,мы должнынагрузкаданные。мы будем использоватьDocumentLoaders[10] осознать这一点。2.разделение:текстразделениеустройство[11] необъятностьDocumentsразделениедля более мелких кусков。Это полезно дляиндексданныеиперешел к Модель Очень полезно,Поскольку большие фрагменты данных сложнее найти,и не может быть в Модель Используется в ограниченном контекстном окне。3.хранилище:мы должны一индивидуальный地方来хранилищеииндекснашразделениеданные,После дефекации вы можете выполнить дефекацию. Обычно это достигается с помощью VectorStore[12]иEmbeddings[13]Модель.
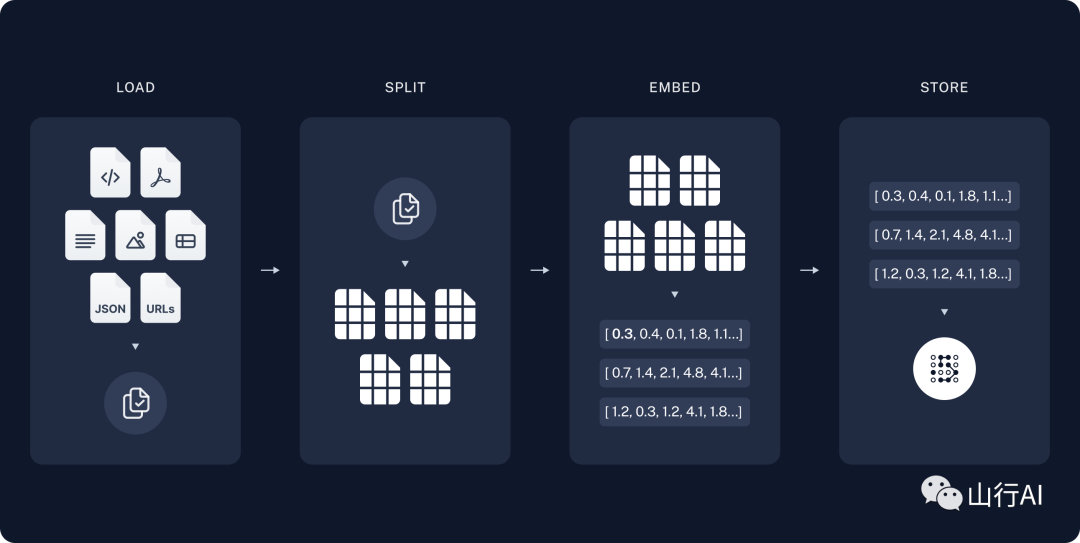
indexdiagram
Поиск и генерация[14]
1.Поиск:на основе пользовательского ввода,использоватьRetriever[15]отхранилищесередина Поиск Связанные разделения。2.генерировать:использовать包含问题и Поискданныесоветы,ChatModel[16] / LLM [17] генерирует ответы.
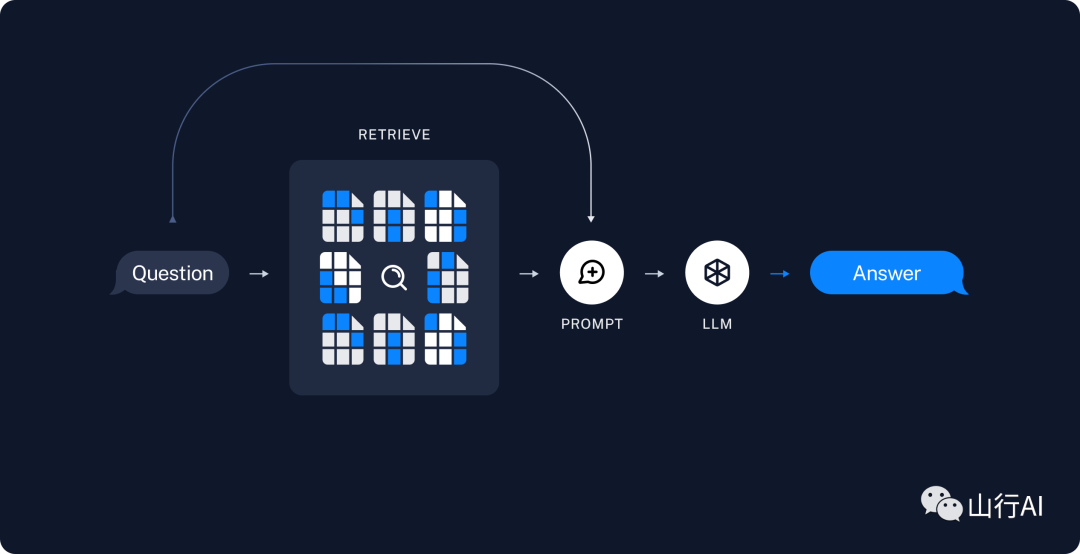
Диаграмма поиска
Установка [18]
зависимость [19]
В этом уроке мы будем использовать модель чата OpenAI, внедрения и хранилища векторов Chroma, но все, что показано здесь, также применимо к любой ChatModel[20] или LLM[21], Embeddings[22] и VectorStore[23] или Retriever [двадцать] четыре].
Мы будем использовать следующие пакеты:
!pip install -U langchain openai chromadb langchainhub bs4мы должны设置环境变量OPENAI_API_KEY,Можетк Установить напрямуюилиот.env文件серединанагрузка,Например:
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()# import dotenv# dotenv.load_dotenv()LangSmith[25]
Многие приложения, созданные с помощью LangChain, будут содержать несколько шагов.,И сделайте несколько звонков LLM. Поскольку эти приложения становятся более сложными,Возможность точно проверить, что происходит внутри цепочки и прокси, становится критически важной. Лучший способ — использовать LangSmith [26]. Пожалуйста, обратите внимание,Лэнг Смит не требуется,Но это очень полезно. Если вы хотите использовать LangSmith,После регистрации по ссылке выше,Обязательно установите переменную среды к, чтобы начать регистрацию информации трассировки: текст:
os.environ ["LANGCHAIN_TRACING_V2"] =“true”os.environ ["LANGCHAIN_API_KEY"] = getpass.getpass()Quickstart
Допустим, мы хотим создать приложение контроля качества на основе записи в блоге Лилиан Венг «Автономные агенты на базе LLM». Мы можем создать простой конвейер примерно из 20 строк кода:
import bs4
from langchain import hub
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chromaloader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))))
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = ({"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())rag_chain.invoke('Что такое декомпозиция задачи?')
Декомпозиция задач — это метод разделения сложных задач на более мелкие и простые этапы. Этого можно добиться с помощью методов подсказок, таких как цепочки мыслей или деревья мыслей, или с помощью инструкций для конкретных задач или человеческого вклада. Декомпозиция задач помогает агентам более эффективно планировать сложные задачи и управлять ими.
# cleanupvectorstore.delete_collection()Посмотреть след ЛАНГСМИТ[27]
Подробные шаги
Щелкните ссылку выше, чтобы просмотреть приведенный выше код и по-настоящему понять, как он выполняется.
Шаг 1. Загрузите
Нажмите на ссылку выше Проверять Шаг 1. Загрузите。我们первый需要нагрузка Содержание сообщения в блоге。Мы можем использоватьDocumentLoaderосознать,DocumentLoader是от源нагрузкаданныекакDocumentsобъект。Documentэто человек сpage_content(str)иmetadata(dict)属性объект。в этом случае,Мы будем использовать «WebBaseLoader».,Он использует «urllib» и «BeautifulSoup» для анализа входящих URL-адресов.,Возвращает по одному на каждый URL“Document”。我们Можетк通过将参数перешел к“BeautifulSoup”解析устройство上из“bs_kwargs”настроитьhtml->текст解析(ВидетьBeautifulSoupдокумент[28])。в этом случае,Только с «пост-контентом»,HTML-теги, такие как «post-title» и «post-header», актуальны.,Итак, мы собираемся удалить все остальные теги.
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs={"parse_only": bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))})
docs = loader.load()
len(docs[0].page_content)
42824
print(docs[0].page_content[:500])Расширенный автономный интеллектуальный агент LLM Дата: 23 июня 2023 г. Примерное время чтения: 31 минута Автор: Лилиан Венг |
Создание агентов с LLM (крупномасштабной языковой моделью) в качестве основного контроллера — отличная идея. Несколько демонстраций концепции, таких как AutoGPT, GPT-Engineer и BabyAGI, являются обнадеживающими примерами. Потенциал LLM выходит за рамки способности создавать тексты, рассказы, статьи и программы; его можно рассматривать как мощное средство решения проблем общего назначения;
Идите глубже[29]
DocumentLoader:от源нагрузкаданныекакDocumentsобъект。- документ[30]:有关如何использоватьDocumentLoaderиз进一步документ。- интегрированный[31]:Найдите те, которые соответствуют вашему варианту использованияDocumentLoaderинтегрированный(Превосходить160индивидуальный)。
Шаг 2. Разделить
Загруженный нами документ имеет длину более 42 тысяч символов. Это слишком долго, чтобы поместиться в контекстное окно многих моделей. Даже для тех моделей, которые могут поместиться в полные сообщения, как правило, модели испытывают трудности с поиском соответствующего контекста в очень длинных подсказках.
Поэтому мы разделим «документ» для встраивания и векторного хранения. Таким образом, мы можем получить только самые важные части сообщения блога во время выполнения. В этом случае мы разделим наш документ на фрагменты по 1000 символов каждый с перекрытием в 200 символов между каждым фрагментом. Такое перекрытие помогает снизить вероятность отделения предложения от важного контекста, связанного с ним. Мы разделяем документ с помощью «RecursiveCharacterTextSplitter», который (рекурсивно) разделяет документ, используя общие разделители (например, символы новой строки), пока каждый фрагмент не достигнет соответствующего размера.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200, add_start_index=True)
all_splits = text_splitter.split_documents(docs)
len(all_splits)
66
len(all_splits[0].page_content)
969
all_splits[10].metadata
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 7056}Узнать больше[32]
«DocumentSplitter»: объект, который разбивает список «Документ» на более мелкие фрагменты. Является подклассом DocumentTransformer. - Исследуйте «контекстно-зависимое подразделение», которое сохраняет положение («контекст») каждого подразделения в исходном «Документе»: [Файл уценки] (https://python.langchain.com/docs/use_cases/question_answering/document-context-aware-QA) – [код(pyilijs)](https://python.langchain.com/docs/use_cases/question_answering/docs/integrations/document_loaders/source_code) - [Научная статья](https://python.langchain.com/docs/integrations/document_loaders/grobid)
`DocumentTransformer`: объект, который выполняет преобразования в списке `Document`. - [Документация](https://python.langchain.com/docs/modules/data_connection/document_transformers/): дополнительная документация по использованию DocumentTransformer. - [Интеграция](https://python.langchain.com/docs/integrations/document_transformers/)
## Ключевое слово по умолчанию[](https://python.langchain.com/docs/use_cases/question_answering/#step-3.-store «Идите сразу к третьей ступеньке.хранилище»)
Теперь, когда у нас есть 66 текстовых блоков в памяти, нам нужно позже сохранить их в нашем приложении RAG. Самый распространенный способ сделать это — встроить содержимое каждого документа и загрузить эти встраивания в векторизатор.
Затем, когда мы хотим встроить поиск в наши отдельные данные, мы также встраиваем поисковый запрос и выполняем своего рода поиск по «сходству», чтобы определить разделение хранилища, которое наиболее похоже на встраивание нашего запроса. Простейшей мерой сходства является косинусное сходство. - Мы измеряем косинус угла между каждой парой вложений (которые представляют собой просто векторы очень большой размерности).
Мы можем использовать `Chroma` векторхранилищеи `OpenAIEmbeddings` Модель единой команды для встраивания ихранилище во все документы разделения.Заявление:
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Chromavectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())Узнать больше[33]
“Embeddings”: — это оболочка модели внедрения текста, используемая для преобразования текста во внедрения. - Документация[34]: Дополнительная документация по интерфейсам. - Интеграция[35]: Просматривать30多индивидуальныйтекст嵌入интегрированный。“VectorStore”:封装了一индивидуальныйвекторданные Библиотека,используется дляхранилищеи查询嵌入вектор。- Документация [36]: Дополнительная документация по интерфейсу. - интегрированный[37]:Просматривать Превосходить40индивидуальный“VectorStore”интегрированный。Это завершает конвейериндексчасть。в этот момент,У нас есть запрашиваемая векторная база данных.,Он содержит блочный контент сообщений нашего блога. Учитывая проблему пользователя,В идеале,Мы должны иметь возможность вернуть отрывок из сообщения в блоге, который отвечает на вопрос:
Шаг 3. Поиск [38]
Теперь давайте напишем реальную логику приложения. Мы хотим создать простое приложение, в котором пользователь сможет задать вопрос, выполнить поиск документов, связанных с этим вопросом, передать выбранные документы и исходный вопрос модели и, наконец, вернуть ответ.
LangChain определяет интерфейс «Retriever», который инкапсулирует индекс и может возвращать соответствующие документы на основе строковых запросов. Все средства извлечения реализуют общедоступный метод get_relevant_documents() (и его асинхронный вариант aget_relevant_documents()). Наиболее распространенным типом Retriever является VectorStoreRetriever, который для выполнения поиска использует возможности поиска по сходству векторных хранилищ. Любой VectorStore можно легко преобразовать в Retriever:
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
retrieved_docs = retriever.get_relevant_documents("What are the approaches to Task Decomposition?")
len(retrieved_docs)
6
print(retrieved_docs[0].page_content)Деревья мышления (Яо и др., 2023) расширяют ЦО, исследуя множество возможностей рассуждения на каждом этапе. Он создает древовидную структуру, сначала разбивая проблему на несколько этапов мышления и генерируя несколько мыслей на каждом этапе. Процесс поиска может представлять собой либо поиск в ширину (BFS), либо поиск в глубину (DFS), при этом каждое состояние оценивается классификатором (посредством подсказок) или голосованием большинства. Декомпозиция задачи может быть выполнена путем (1) использования LLM с использованием простых подсказок, таких как «Шаги XYZ.\n1.», «Каковы подцели для достижения XYZ?», (2) с использованием инструкций для конкретной задачи, таких как «Написать план истории». ., чтобы написать роман, или (3) использовать человеческий вклад. "
Узнать больше
Для извлечения обычно используется векторное хранилище, но существует множество других способов его извлечения. «Retriever»: объект, который возвращает объект «документ» на основе текстового запроса — Документация [39]: Дополнительная документация по интерфейсу и встроенным методам поиска. Некоторые из них включают в себя: - MultiQueryRetriever Сгенерируйте варианты входной задачи [40] для улучшения скорости поиска. - MultiVectorRetriever(Как показано ниже)генерировать Встроенный вариант[41],также улучшить Поиск命середина率。- максимальная предельная выгодаВыбрано Поискдокументсерединаиз相关性и Разнообразие,к Избегайте передачи в дублирующемся контексте. - В процессе Поиска с использованием векторного хранилища,МожеткиспользоватьЮаньданные筛选устройство[42]对документ进行筛选。- Интеграция [43]: Интеграция с поисковыми службами.
Шаг 4. Сгенерируйте
Давайте объединим все в цепочку, которая принимает вопрос, извлекает соответствующие документы, создает приглашение, передает его в модель и анализирует выходные данные.
Мы будем использовать модель чата OpenAI с gpt-3.5-turbo.,但Можетк Заменить на любойLangChainизLLMилиChatModel。
from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)Мы будем использовать наконечник RAG, который был добавлен в центр подсказок LangChain (ссылка здесь [44]).
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
print(prompt.invoke({"context": "заполнить контент", "question": «Проблема заполнения»}).to_string())
Human: You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: filler question Context: filler context Answer:
你是一индивидуальныйиспользуется для问答任务из助手。использоватьк Вниз Поиск到из背景内容来回答问题。если ты не знаешь ответа,Просто скажи, что не знаешь. Ответы ограничены тремя предложениями.,И будьте проще. Проблема: Проблема с заполнением. Фон: Залейте фон. Отвечать:Для определения цепочки мы будем использовать протокол LCEL Runnable[45], который позволяет нам прозрачно соединять компоненты и функции, может автоматически отслеживать нашу цепочку в LangSmith и легко реализовывать потоковые, асинхронные и пакетные вызовы.
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)for chunk in rag_chain.stream("What is Task Decomposition?"):
print(chunk, end="", flush=True)Декомпозиция задач — это метод разделения сложных задач на более мелкие и простые этапы. Это можно сделать с помощью таких методов, как цепочки мыслей (CoT) или деревья мышления, которые предполагают разделение задачи на управляемые подзадачи и изучение множества возможностей рассуждения на каждом этапе. Декомпозиция задачи может быть выполнена с помощью подсказок модели ИИ, инструкций для конкретной задачи или человеческого ввода.
См. след ЛАНГСМИТА[46].
Узнать больше[47]
Выберите LLM[48]
ChatModel: Используйте LLM в качестве поддерживаемой оболочки модели чата. Принимает последовательность сообщений и возвращает сообщение. - Документация[49] - Интеграция[50]: 探索Превосходить25индивидуальныйChatModelизинтегрированный。"LLM:一индивидуальный输入字符串并返回字符串изтекст输入-текст输出LLM。- Документация[51] - Интеграция[52]: Просматривать Превосходить75индивидуальныйLLMизинтегрированный。
Ознакомьтесь с рекомендациями RAG по использованию моделей, запускаемых локально, здесь [53].
Пользовательские подсказки[54]
Как показано выше, мы можем загружать подсказки из центра подсказок (например, подсказку RAG [55]). Это приглашение также можно легко настроить:
from langchain.prompts import PromptTemplate
template = """Используйте приведенную ниже справочную информацию, чтобы ответить на последний вопрос. Если вы не знаете ответа, просто скажите, что не знаете. Не придумывайте ответ. Держите ответ как можно более кратким, не более три предложения. Наконец, скажите: «Спасибо, что спросили! ". {context} Вопрос: {question} Полезный ответ: """
rag_prompt_custom = PromptTemplate.from_template(template)
rag_chain = (
{"context": retriever | форматировать документы, "question": RunnablePassthrough()}
| rag_prompt_custom
| llm
| StrOutputParser()
)
rag_chain.invoke(«Что такое декомпозиция задачи?»)Декомпозиция задач — это процесс разбиения сложных задач на более мелкие и простые шаги. Его можно разложить с помощью таких технологий, как цепочка мыслей (CoT) и дерево мышления.,Эти методы предполагают разбиение проблемы на несколько этапов мышления.,И для каждого шага ограничивать несколько результатов мышления. Декомпозиция задач помогает улучшить производительность Модели и понять ее мыслительный процесс. Спасибо за ваш вопрос!См., пожалуйста, Лэнг Смита [56].
добавить источник [57]
С помощью LCEL легко вернуть документы или конкретные исходные данные из полученных документов:
from operator import itemgetter
from langchain.schema.runnable import RunnableParallel
rag_chain_from_docs = (
{
"context": lambda input: format_docs(input["documents"]),
"question": itemgetter("question"),
}
| rag_prompt_custom
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"documents": retriever, "question": RunnablePassthrough()}
) | {
"documents": lambda input: [doc.metadata for doc in input["documents"]],
"answer": rag_chain_from_docs,
}
rag_chain_with_source.invoke("What is Task Decomposition")Декомпозиция задач — это метод, который разбивает сложные задачи на более мелкие и простые шаги. Он предполагает преобразование больших задач в несколько управляемых задач.,Это обеспечивает более систематический и организованный подход к решению проблем. Спасибо за ваш вопрос!Посмотрите трассировку Лэнг Смита[58].
Добавить память[59]
Предположим, мы хотим создать приложение с сохранением состояния, которое запоминает прошлый ввод пользователя. Чтобы поддержать это, нам нужно сделать две основные вещи. 1. Добавьте в нашу цепочку заполнитель сообщения, который позволит нам передавать исторические сообщения. 2. Добавьте цепочку, которая принимает последний пользовательский запрос и реконструирует его в контексте истории чата в отдельный вопрос, который можно передать нашему поисковику.
Начнем с шага 2. Мы можем построить цепочку «упрощенных задач» примерно так:
from langchain.prompts import PromptTemplate,MessagesPlaceholder
condense_q_system_prompt = """Учитывая запись чата и последний вопрос пользователя, этот вопрос может относиться к записи чата, задавая вопрос, который можно понять независимо. Не отвечайте на вопрос, перефразируйте его, если необходимо, и вернитесь к оригиналу."" "
condense_q_prompt = ChatPromptTemplate.from_messages(
[
("system", condense_q_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
condense_q_chain = condense_q_prompt | llm | StrOutputParser()from langchain.schema.messages import AIMessage,HumanMessage
condense_q_chain.invoke(
{
"chat_history": [
HumanMessage(content="Что означает LLM?"),
AIMessage(content="Модель большого языка"),
],
"question": "Что значит большой на языке моделей?",
}
)condense_q_chain.invoke({
"chat_history": [
HumanMessage(content="LLM Для чего нужна аббревиатура? "),
AIMessage(content="Модель большого языка"),
],
"question": "transformers Как это работает»,
})«Как работает модель преобразования?» 'Теперь мы можем построить полную цепочку вопросов и ответов. Пожалуйста, обратите внимание,Мы добавили некоторые функции маршрутизации.,«Сокращение цепочки вопросов» будет запускаться только тогда, когда история чата не пуста.
qa_system_prompt = """Вы помощник в задании вопросов и ответов. Пожалуйста, ответьте на вопрос, используя фрагменты контекста, расположенные ниже. Если вы не знаете ответа, просто скажите, что не знаете. Используйте максимум три предложения и продолжайте ответ Краткий \n{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
def condense_question(input: dict):
if input.get("chat_history"):
return condense_q_chain
else:
return input["question"]
rag_chain = (
RunnablePassthrough.assign(context=condense_question | retriever | format_docs)
| qa_prompt
| llm
)
chat_history = []
question = «Что такое декомпозиция задачи?»
ai_msg = rag_chain.invoke({"question": question, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=question), ai_msg])
second_question = «Каковы распространенные методы декомпозиции задач?»
rag_chain.invoke({"question": second_question, "chat_history": chat_history})К распространенным способам декомпозиции задач относятся:
1. Используйте цепочку мыслей (ЦП). ЦП — это метод подсказок, который заставляет модель «думать шаг за шагом» и разбивать сложные задачи на более мелкие и простые шаги. Для расчета требуется больше времени на тестирование и раскрытие мыслительного процесса модели. 2. Используйте языковую модель (LLM) для подсказок. Языковую модель (LLM) можно использовать для подсказки модели с помощью простых инструкций, таких как «Шаги для XYZ» или «Каковы подцели для достижения XYZ?» Это позволяет модели генерировать серию подзадач или мыслительных шагов. 3. Рекомендации для конкретных задач. Для определенных задач могут быть предоставлены рекомендации для конкретных задач, которые помогут модели при декомпозиции задач. Например, для задачи написания романа можно дать инструкцию «Написать план рассказа», чтобы разбить задачу на выполнимые шаги. 4. Человеческий вклад. В некоторых случаях человеческий вклад может использоваться для декомпозиции задачи. Люди могут поделиться своим опытом и знаниями для определения и разбиения сложных задач на более мелкие подзадачи.
Пожалуйста, ознакомьтесь со следующим отслеживанием LANGSMITH[60]
Здесь мы расскажем, как добавить цепную логику для объединения исторических результатов. Но как нам на самом деле хранить и получать исторические данные из разных сеансов? Дополнительную информацию см. на странице LCEL «Как добавить историю сообщений (память)» [61].
Шаг 5[62]
Мы прошли большой путь за короткий период времени. В каждом из вышеперечисленных есть множество тонкостей, функций и интеграций, которые стоит изучить. В дополнение к источникам, упомянутым выше, хорошие следующие шаги включают в себя:
• Познакомьтесь с более продвинутыми методами поиска в разделе «Ретриверы»[63]. • Изучите API индексирования LangChain [64], который может помочь многократно синхронизировать источники данных и векторное хранилище, чтобы избежать избыточных вычислений и хранения. • Изучите шаблоны RAG LangChain [65] — эталонные приложения, которые легко развернуть с помощью LangServe [66]. • Чтобы узнать, как использовать LangSmith для оценки приложений RAG, обратитесь к разделу «Оценка приложений RAG на LangSmith» [67].
References
[1] : https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/question_answering/index.ipynb
[2] Перейти к обзору: https://python.langchain.com/docs/use_cases/question_answering/#overview
[3] Перейти к разделу Что такое RAG? : https://python.langchain.com/docs/use_cases/question_answering/#what-is-rag
[4] Прямые ссылки на содержание данного руководства: https://python.langchain.com/docs/use_cases/question_answering/#whats-in-this-guide
[5] LLM Powered Autonomous Agents: https://lilianweng.github.io/posts/2023-06-23-agent/
[6] по структурированным данным QA: https://python.langchain.com/docs/use_cases/qa_structured/sql
[7] Сделайте код QA: https://python.langchain.com/docs/use_cases/question_answering/code_understanding
[8] Прямая ссылка на схему: https://python.langchain.com/docs/use_cases/question_answering/#architecture
[9] Прямое индексирование: https://python.langchain.com/docs/use_cases/question_answering/#indexing
[10] DocumentLoaders: https://python.langchain.com/docs/modules/data_connection/document_loaders/
[11] Разделитель текста: https://python.langchain.com/docs/modules/data_connection/document_transformers/
[12] VectorStore: https://python.langchain.com/docs/modules/data_connection/vectorstores/
[13] Embeddings: https://python.langchain.com/docs/modules/data_connection/text_embedding/
[14] Прямые ссылки на поиск и генерацию: https://python.langchain.com/docs/use_cases/question_answering/#retrieval-and-generation
[15] Retriever: https://python.langchain.com/docs/modules/data_connection/retrievers/
[16] ChatModel: https://python.langchain.com/docs/modules/model_io/chat_models
[17] LLM: https://python.langchain.com/docs/modules/model_io/llms/
[18] Прямая ссылка для установки: https://python.langchain.com/docs/use_cases/question_answering/#setup
[19] Зависимые прямые ссылки: https://python.langchain.com/docs/use_cases/question_answering/#dependencies
[20] ChatModel: https://python.langchain.com/docs/integrations/chat/
[21] LLM: https://python.langchain.com/docs/integrations/llms/
[22] Embeddings: https://python.langchain.com/docs/integrations/text_embedding/
[23] VectorStore: https://python.langchain.com/docs/integrations/vectorstores/
[24] Retriever: https://python.langchain.com/docs/integrations/retrievers
[25] Прямая ссылка на Ланг Смита: https://python.langchain.com/docs/use_cases/question_answering/#langsmith
[26] LangSmith: https://smith.langchain.com/
[27] LANGSMITH trace: [LangSmith](https://smith.langchain.com/public/1c6ca97e-445b-4d00-84b4-c7befcbc59fe/r)
[28] Документация BeautifulSoup: https://beautiful-soup-4.readthedocs.io/en/latest/#beautifulsoup
[29] Прямая ссылка для более подробной информации: https://python.langchain.com/docs/use_cases/question_answering/#go-deeper
[30] документ: https://python.langchain.com/docs/modules/data_connection/document_loaders/
[31] интегрированный: https://python.langchain.com/docs/integrations/document_loaders/
[32] Прямое обновление программы больше: https://python.langchain.com/docs/use_cases/question_answering/#go-deeper-1
[33] Прямой курс обучения больше: https://python.langchain.com/docs/use_cases/question_answering/#go-deeper-2
[34] документ: https://python.langchain.com/docs/modules/data_connection/text_embedding
[35] интегрированный: https://python.langchain.com/docs/integrations/text_embedding/
[36] документ: https://python.langchain.com/docs/modules/data_connection/vectorstores/
[37] интегрированный: https://python.langchain.com/docs/integrations/vectorstores/
[38] Прямая ссылка на шаги 4. Поиск: https://python.langchain.com/docs/use_cases/question_answering/#step-4.-retrieve
[39] документ: https://python.langchain.com/docs/modules/data_connection/retrievers/
[40] Создайте вариант входной задачи: https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever
[41] Встроенные варианты: https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[42] Юаньданные筛选устройство: https://python.langchain.com/docs/use_cases/question_answering/document-context-aware-QA
[43] Интеграция: https://python.langchain.com/docs/integrations/retrievers/
[44] Ссылка здесь: https://smith.langchain.com/hub/rlm/rag-prompt
[45] LCEL Runnable: https://python.langchain.com/docs/expression_language/
[46] LANGSMITH отслеживать: https://smith.langchain.com/public/1799e8db-8a6d-4eb2-84d5-46e8d7d5a99b/r
[47] Go Прямая ссылка на более глубокий: https://python.langchain.com/docs/use_cases/question_answering/#go-deeper-4
[48] Прямые ссылки для выбора LLM: https://python.langchain.com/docs/use_cases/question_answering/#choosing-llms
[49] документ: https://python.langchain.com/docs/modules/model_io/chat/
[50] интегрированный: https://python.langchain.com/docs/integrations/chat/
[51] документ: https://python.langchain.com/docs/modules/model_io/llms
[52] интегрированный: https://python.langchain.com/docs/integrations/llms
[53] здесь: https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa
[54] Прямая ссылка на пользовательские подсказки: https://python.langchain.com/docs/use_cases/question_answering/#customizing-the-prompt
[55] Советы для этой ТРЯПКИ: https://smith.langchain.com/hub/rlm/rag-prompt
[56] LangSmith: https://smith.langchain.com/public/da23c4d8-3b33-47fd-84df-a3a582eedf84/r
[57] Прямая ссылка на добавление источник: https://python.langchain.com/docs/use_cases/question_answering/#adding-sources
[58] LangSmith trace: https://smith.langchain.com/public/007d7e01-cb62-4a84-8b71-b24767f953ee/r
[59] Добавить прямую ссылку в память: https://python.langchain.com/docs/use_cases/question_answering/#adding-memory
[60] LANGSMITH отслеживать: https://smith.langchain.com/public/b3001782-bb30-476a-886b-12da17ec258f/r
[61] Как добавить историю сообщений (память): https://python.langchain.com/docs/expression_language/how_to/message_history
[62] Прямая ссылка на следующий шаг: https://python.langchain.com/docs/use_cases/question_answering/#next-steps
[63] Retrievers: https://python.langchain.com/docs/modules/data_connection/retrievers/
[64] Indexing API: https://python.langchain.com/docs/modules/data_connection/indexing
[65] Шаблон Лангчейна: https://python.langchain.com/docs/templates/#-advanced-retrieval
[66] LangServe: https://python.langchain.com/docs/langserve
[67] Оценка приложений RAG на LangSmith: https://github.com/langchain-ai/langsmith-cookbook/blob/main/testing-examples/qa-correctness/qa-correctness.ipynb


Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS

Руководство по загрузке, установке и использованию SVN «Рекомендуемая коллекция»

Интерфейс PHPforwarding_php отправляет запрос на получение

Создавайте и защищайте связь в реальном времени с помощью SignalR и Azure Active Directory.

ВичатПубличная платформаразвивать(три)——ВичатQR-кодгенерировать&Сканировать кодсосредоточиться на
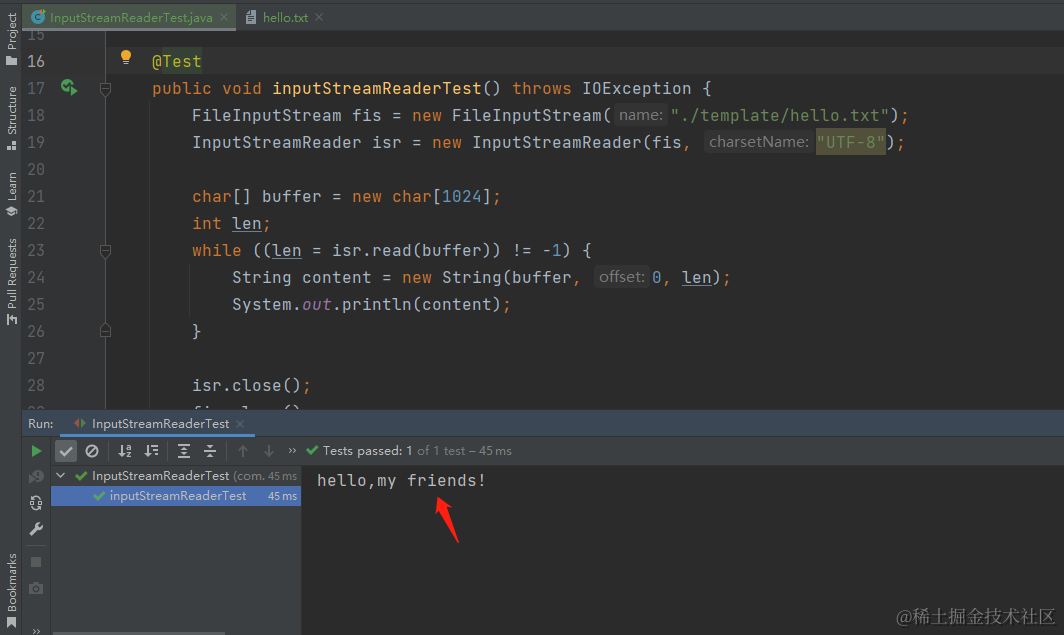
[Углубленное понимание Java IO] Используйте InputStreamReader для чтения содержимого файла и легкого выполнения задач преобразования текста.

сравнение строк PHP
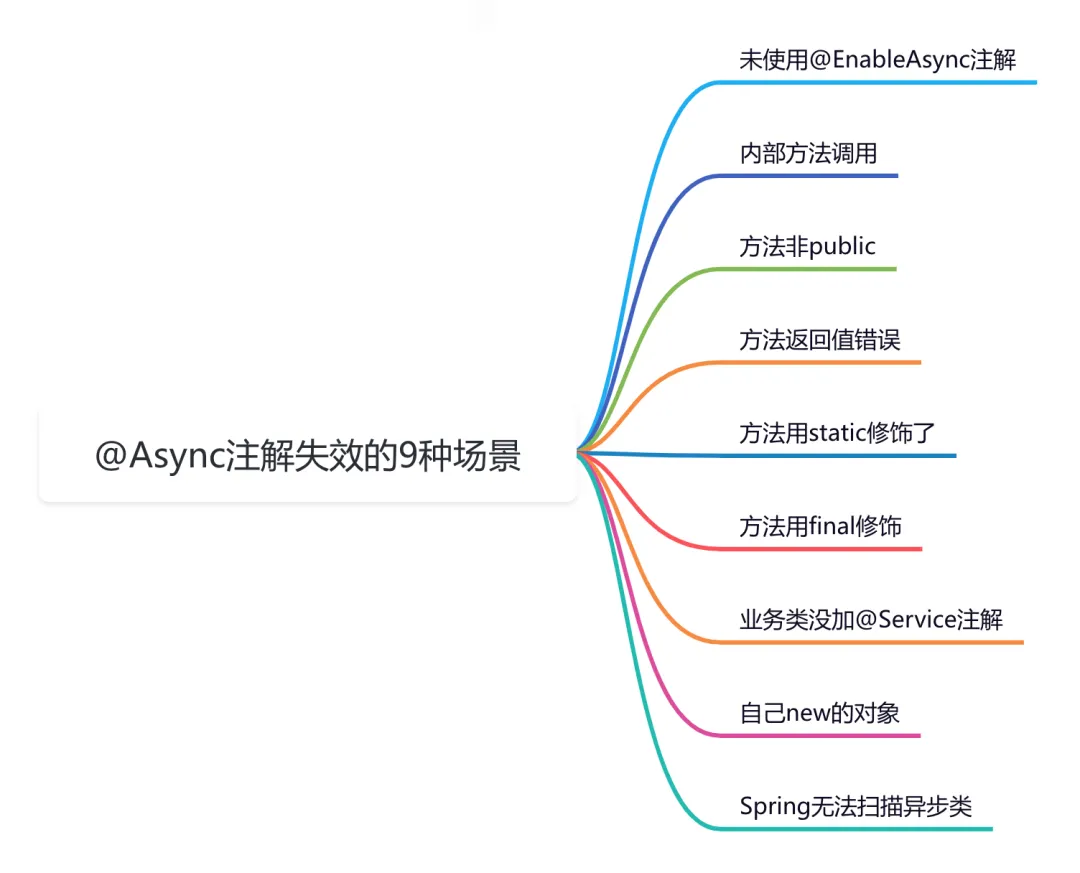
9 сценариев асинхронного сбоя @Async

Эффективная обработка запланированных задач: углубленное изучение секретов библиотеки APScheduler на Python

Рекомендации по облегченному артефакту развязки внутренних компонентов Spring Event (событие Spring)
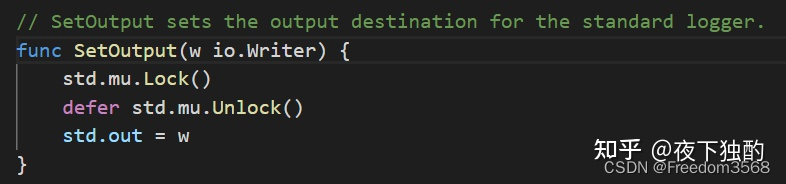
Go: Лесоруб-лесоруб на колесах Введение

Основы серверной разработки: технология кэширования, которую должен освоить каждый программист

Java Advanced Collections TreeSet: что это такое и зачем его использовать?
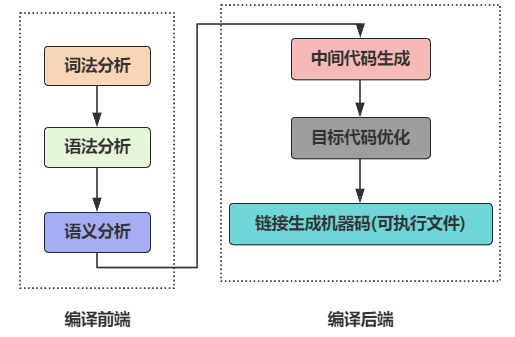
Оказывается, у команды go build столько знаний

Node.js
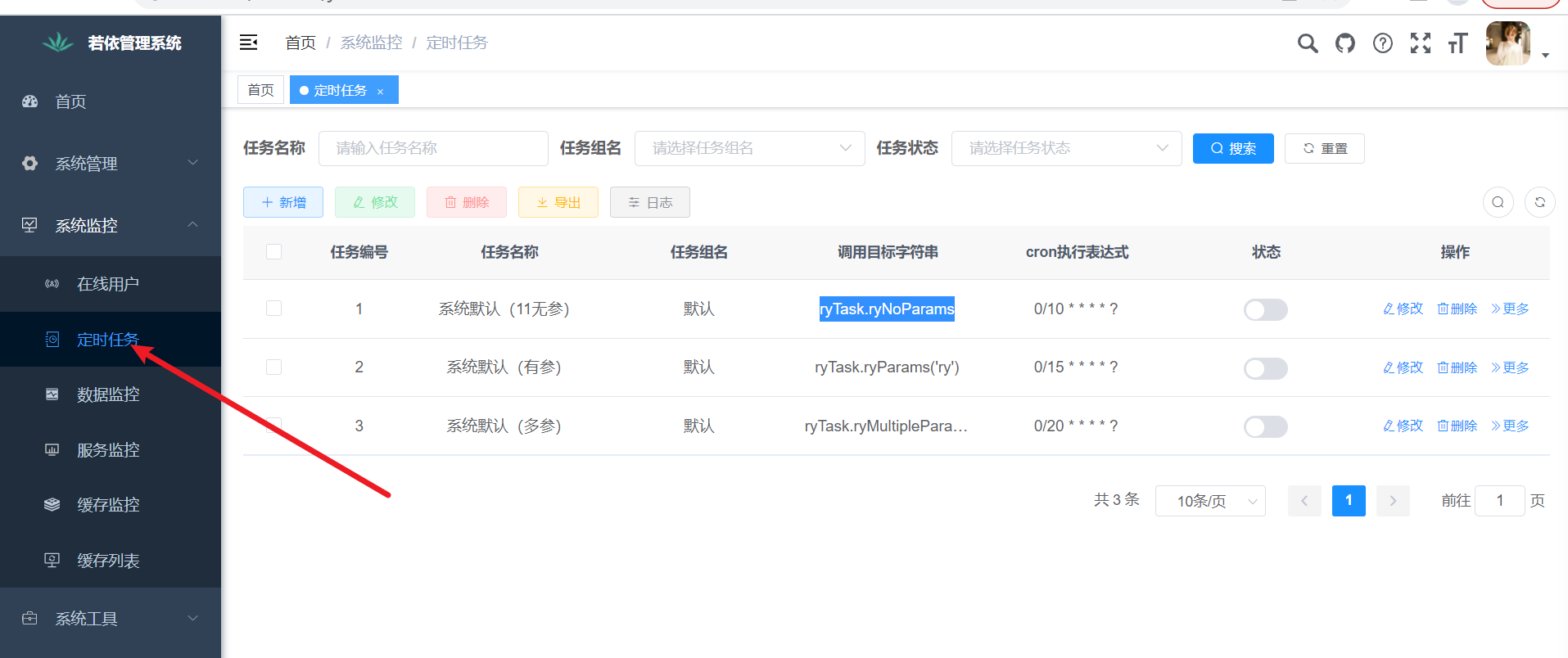
Анализ исходного кода, связанный с запланированными задачами версии ruoyi-vue (7), то есть анализ модуля ruoyi-quartz.

Вход в систему с помощью скан-кода WeChat (1) — объяснение процесса входа в систему со скан-кодом, получение авторизованного QR-кода для входа.

HikariPool-1 — обнаружено отсутствие потока или скачок тактовой частоты, а также конфигурация источника данных Hikari.
Сравнение высокопроизводительной библиотеки JSON Go

Простое руководство по извлечению аудио с помощью FFmpeg

Подсчитайте количество строк кода в проекте
