Вызов новой архитектуры Transformer Анализ Mamba и воспроизведение Pytorch
Сегодня мы подробнее рассмотрим статью «Мамба: моделирование линейных временных рядов с выборочным пространством состояний».

Mamba произвела фурор в сообществе искусственного интеллекта и рекламировалась как потенциальный конкурент Transformer. Что именно выделяет Мамбу в многолюдном списке застройщиков?
Прежде чем представить, краткий обзор существующих моделей.
Трансформатор: известен своим механизмом внимания, при котором любая часть последовательности может динамически взаимодействовать с любой другой частью. Трансформер, в частности, имеет механизм причинного внимания, который хорошо обрабатывает отдельные элементы последовательности. Но они требуют значительных вычислительных затрат и затрат памяти, пропорциональных квадрату длины последовательности (L²).
Рекуррентная нейронная сеть (rnn): RNN учитывает только текущий ввод и последнее скрытое состояние и обновляет скрытые состояния по порядку. Этот подход позволяет им потенциально обрабатывать последовательности бесконечной длины и постоянные требования к памяти. Но простота RNN является недостатком, ограничивающим их способность запоминать долгосрочные зависимости. Кроме того, обратное распространение ошибки во времени (BPTT) в RNN требует большого объема памяти и может страдать от исчезновения или взрыва градиентов, хотя существуют инновационные частичные структуры, такие как LSTM, которые решают эту проблему.
Модели пространства состояний (S4): Эти модели показали хорошие свойства. Они обеспечивают баланс более эффективного захвата удаленных зависимостей, чем RNN, и более эффективного использования памяти, чем Transformers.
Mamba
Выборочное пространство состояний: Мамба основывается на концепции моделей пространства состояний, но вносит новый поворот. Он использует выборочное пространство состояний, обеспечивая более эффективный и действенный сбор соответствующей информации в длинных последовательностях.
Линейная временная сложность: в отличие от Transformer, Mamba работает за линейное время относительно длины последовательности. Это свойство делает его особенно подходящим для задач, включающих очень длинные последовательности, с которыми традиционные модели не справляются.
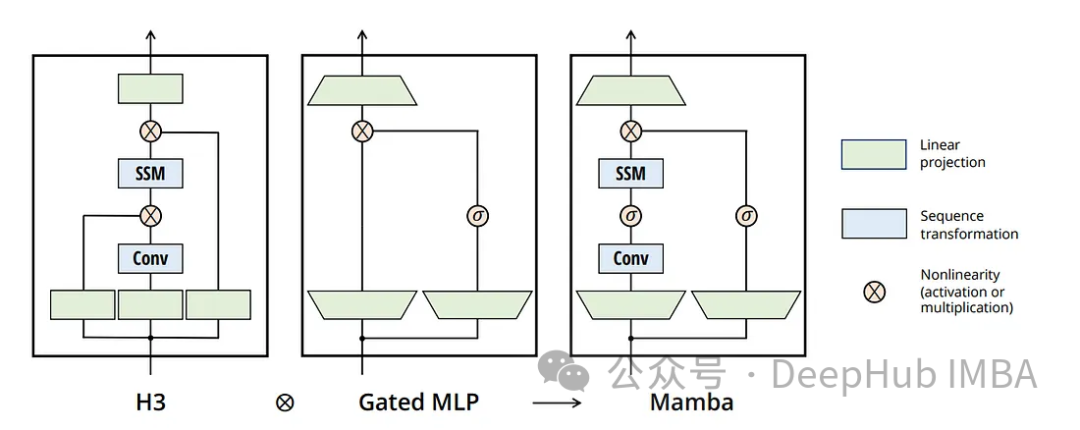
Mamba представляет интересное усовершенствование традиционной модели пространства состояний с концепцией выборочного пространства состояний. Этот подход немного ослабляет строгие переходы между состояниями стандартной модели пространства состояний, делая ее более адаптируемой и гибкой (что-то похожее на lstm). А Mamba сохраняет вычислительно эффективный характер модели пространства состояний, позволяя ей выполнять прямой проход всей последовательности за одно сканирование — функция, больше напоминающая Transformer.
Во время обучения Мамба ведет себя как Трансформер, обрабатывая всю последовательность одновременно. И lstm должен шаг за шагом рассчитывать проход вперед, даже если все входные данные известны. Таким образом, поведение Mamba больше соответствует традиционной модели цикла, обеспечивая эффективную обработку последовательностей.
Ключевым ограничением априорных моделей пространства состояний (SSM) является их жесткая, инвариантная к входным данным структура. Эти модели используют фиксированный набор параметров для всей последовательности (назовем их a и B). Эта структура еще более ограничительна, чем такие модели, как lstm, где преобразование сигнала может зависеть от предыдущих скрытых состояний и входных данных.
Мамба — это смена парадигмы, то есть как просчитать переход в следующее скрытое состояние? В архитектуре Mamba преобразования зависят от текущих входных данных. Этот подход обеспечивает баланс между фиксированными вычислениями традиционного SSM и зависимой от входных данных динамикой рекуррентных нейронных сетей.
Основные компоненты следующие:
Фиксированная основа: переход от одного скрытого состояния к следующему остается фиксированным вычислением (определенным матрицей), что позволяет выполнять предварительные вычисления между последовательностями.
Преобразование, зависящее от ввода: то, как ввод влияет на следующее скрытое состояние (определенное матрицей B), зависит от текущего ввода, а не от предыдущего скрытого состояния. Эта входная зависимость обеспечивает большую гибкость, чем традиционный SSM.

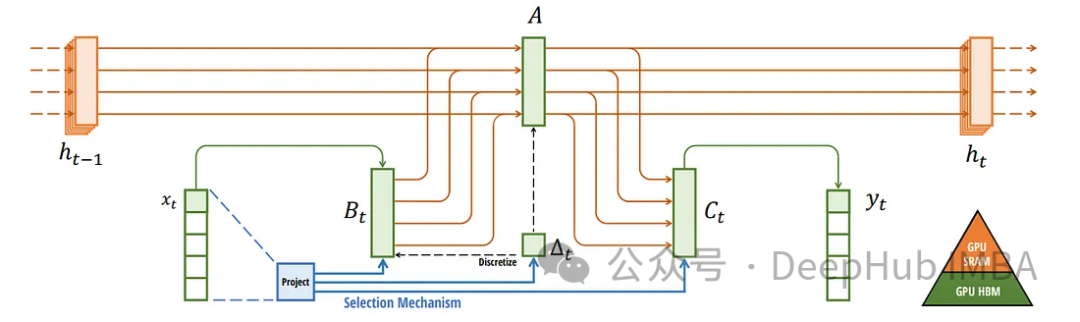
Чтобы удовлетворить вычислительные требования этого подхода, Mamba использует аппаратно-ориентированный алгоритм. Этот алгоритм использует операции сканирования вместо сверток для выполнения вычислений в цикле, что очень эффективно для графического процессора. Эта эффективность имеет решающее значение для поддержания высокой производительности, несмотря на алгоритмическую сложность, связанную с преобразованиями, зависящими от входных данных.
Мамба и модели выборочного пространства состояний не являются синонимами. Mamba — это реализация, использующая концепцию выборочных пространств состояний. Это различие имеет решающее значение, поскольку оно подчеркивает уникальный вклад Mamba: сделать структуру SSM более гибкой и отзывчивой на входные данные, сохраняя при этом вычислительную эффективность.
СРАМ и HBM
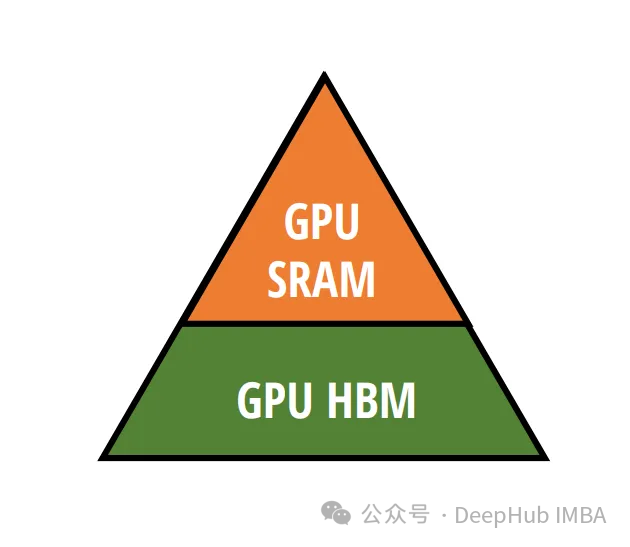
Графические процессоры содержат два основных типа памяти: HBM (память с высокой пропускной способностью) и SRAM (статическая память с произвольным доступом). Хотя HBM имеет высокую пропускную способность, время доступа к нему относительно медленное по сравнению с более быстрым, но меньшим по размеру SRAM. Mamba использует SRAM для быстрого доступа во время умножения матриц, что является ключом к ее расчетам.
Основным узким местом в вычислениях обычно являются не сами вычисления, а перемещение данных между типами памяти. Мамба решает эту проблему, значительно снижая необходимость передачи больших объемов данных. Это достигается путем выполнения критических частей алгоритма, таких как дискретизация и рекурсивные вычисления, непосредственно в SRAM, тем самым уменьшая задержку.
Также представлен слой сканирования выбора слияния, что делает его требования к памяти сопоставимыми с оптимизированной реализацией Transformer, использующей флэш-внимание. Этот уровень имеет решающее значение для поддержания эффективности, особенно при работе с элементами модели, зависящими от входных данных.
результат
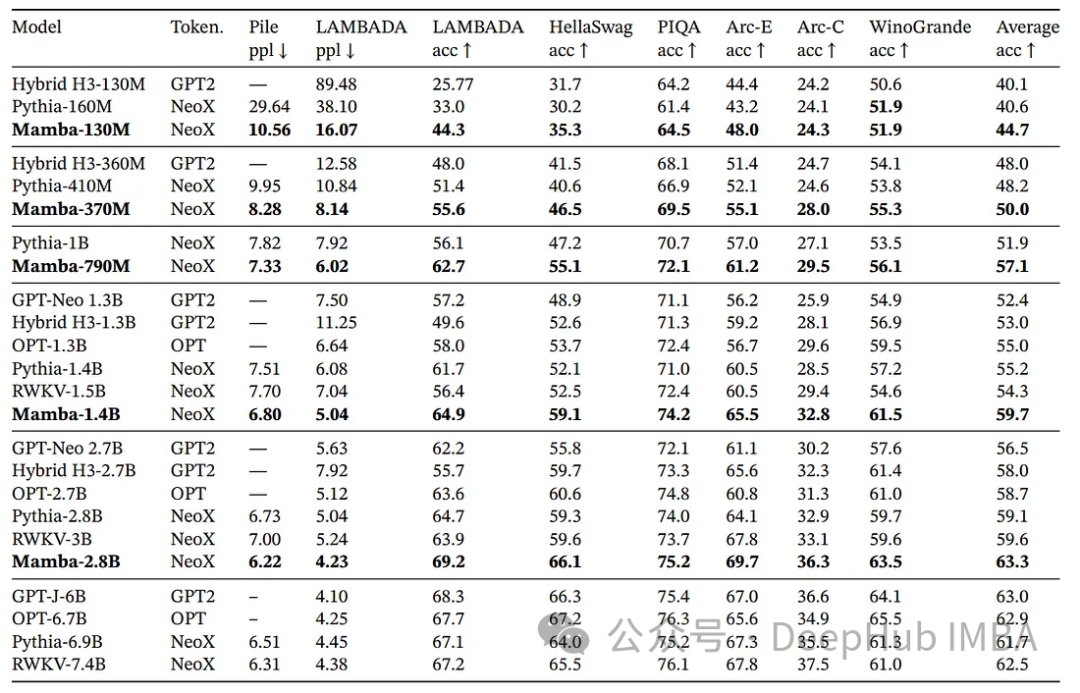
Mamba представляет собой крупный прогресс в моделировании последовательностей, особенно в эффективном использовании памяти графического процессора и вычислительных стратегиях. Его способность эффективно обрабатывать длинные последовательности делает его многообещающей моделью для различных приложений. Давайте воспроизведем ее, используя код Pytorch ниже.
Новое появление Пайторча
Импортировать базовую библиотеку
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.nn import functional as F
from einops import rearrange
from tqdm import tqdm
import math
import os
import urllib.request
from zipfile import ZipFile
from transformers import AutoTokenizer
torch.autograd.set_detect_anomaly(True)Установите флаги и гиперпараметры
# Configuration flags and hyperparameters
USE_MAMBA = 1
DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM = 0
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')Определение гиперпараметров и инициализации
d_model = 8
state_size = 128 # Example state size
seq_len = 100 # Example sequence length
batch_size = 256 # Example batch size
last_batch_size = 81 # only for the very last batch of the dataset
current_batch_size = batch_size
different_batch_size = False
h_new = None
temp_buffer = NoneЗдесь присутствуют гиперпараметры, такие как размерность модели (d_model), размер состояния, длина последовательности и размер пакета.
Модуль S6 — это сложный компонент архитектуры Mamba, отвечающий за обработку входных последовательностей посредством серии линейных преобразований и процессов дискретизации. Он играет ключевую роль в фиксации временной динамики последовательностей, что является ключевым аспектом задач моделирования последовательностей, таких как моделирование языка. Сюда входят тензорные операции и специальные методы дискретизации для обработки сложных данных последовательностей.
class S6(nn.Module):
def __init__(self, seq_len, d_model, state_size, device):
super(S6, self).__init__()
self.fc1 = nn.Linear(d_model, d_model, device=device)
self.fc2 = nn.Linear(d_model, state_size, device=device)
self.fc3 = nn.Linear(d_model, state_size, device=device)
self.seq_len = seq_len
self.d_model = d_model
self.state_size = state_size
self.A = nn.Parameter(F.normalize(torch.ones(d_model, state_size, device=device), p=2, dim=-1))
nn.init.xavier_uniform_(self.A)
self.B = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.C = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.delta = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
self.dA = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.dB = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
# h [batch_size, seq_len, d_model, state_size]
self.h = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.y = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
def discretization(self):
self.dB = torch.einsum("bld,bln->bldn", self.delta, self.B)
self.dA = torch.exp(torch.einsum("bld,dn->bldn", self.delta, self.A))
return self.dA, self.dB
def forward(self, x):
# Algorithm 2 MAMBA paper
self.B = self.fc2(x)
self.C = self.fc3(x)
self.delta = F.softplus(self.fc1(x))
self.discretization()
if DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
global current_batch_size
current_batch_size = x.shape[0]
if self.h.shape[0] != current_batch_size:
different_batch_size = True
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h[:current_batch_size, ...]) + rearrange(x, "b l d -> b l d 1") * self.dB
else:
different_batch_size = False
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h) + rearrange(x, "b l d -> b l d 1") * self.dB
# y [batch_size, seq_len, d_model]
self.y = torch.einsum('bln,bldn->bld', self.C, h_new)
global temp_buffer
temp_buffer = h_new.detach().clone() if not self.h.requires_grad else h_new.clone()
return self.y
else:
# h [batch_size, seq_len, d_model, state_size]
h = torch.zeros(x.size(0), self.seq_len, self.d_model, self.state_size, device=x.device)
y = torch.zeros_like(x)
h = torch.einsum('bldn,bldn->bldn', self.dA, h) + rearrange(x, "b l d -> b l d 1") * self.dB
# y [batch_size, seq_len, d_model]
y = torch.einsum('bln,bldn->bld', self.C, h)
return yЭтот модуль S6 может обрабатывать процесс дискретизации и прямого распространения.
Класс MambaBlock — это специальный модуль нейронной сети, разработанный как ключевой строительный блок модели Mamba. Он инкапсулирует несколько слоев и операций для обработки входных данных.
Включает функции линейной проекции, свертки, активации, специальные модули S6 и остаточные соединения. Этот блок является базовым компонентом модели Mamba и отвечает за обработку входной последовательности посредством серии преобразований для выявления соответствующих закономерностей и особенностей данных. Сочетание этих различных слоев и операций позволяет MambaBlock эффективно решать сложные задачи моделирования последовательностей.
class MambaBlock(nn.Module):
def __init__(self, seq_len, d_model, state_size, device):
super(MambaBlock, self).__init__()
self.inp_proj = nn.Linear(d_model, 2*d_model, device=device)
self.out_proj = nn.Linear(2*d_model, d_model, device=device)
# For residual skip connection
self.D = nn.Linear(d_model, 2*d_model, device=device)
# Set _no_weight_decay attribute on bias
self.out_proj.bias._no_weight_decay = True
# Initialize bias to a small constant value
nn.init.constant_(self.out_proj.bias, 1.0)
self.S6 = S6(seq_len, 2*d_model, state_size, device)
# Add 1D convolution with kernel size 3
self.conv = nn.Conv1d(seq_len, seq_len, kernel_size=3, padding=1, device=device)
# Add linear layer for conv output
self.conv_linear = nn.Linear(2*d_model, 2*d_model, device=device)
# rmsnorm
self.norm = RMSNorm(d_model, device=device)
def forward(self, x):
"""
x_proj.shape = torch.Size([batch_size, seq_len, 2*d_model])
x_conv.shape = torch.Size([batch_size, seq_len, 2*d_model])
x_conv_act.shape = torch.Size([batch_size, seq_len, 2*d_model])
"""
# Refer to Figure 3 in the MAMBA paper
x = self.norm(x)
x_proj = self.inp_proj(x)
# Add 1D convolution with kernel size 3
x_conv = self.conv(x_proj)
x_conv_act = F.silu(x_conv)
# Add linear layer for conv output
x_conv_out = self.conv_linear(x_conv_act)
x_ssm = self.S6(x_conv_out)
x_act = F.silu(x_ssm) # Swish activation can be implemented as x * sigmoid(x)
# residual skip connection with nonlinearity introduced by multiplication
x_residual = F.silu(self.D(x))
x_combined = x_act * x_residual
x_out = self.out_proj(x_combined)
return x_outMambaBlock — основная функция Mamba.
Модель Мамба
Включает серию модулей MambaBlock. Каждый блок последовательно обрабатывает входные данные, при этом выходные данные одного блока служат входными данными для следующего блока. Подобная последовательная обработка позволяет модели улавливать сложные закономерности и взаимосвязи во входных данных, что делает ее эффективной для задач, связанных с последовательным моделированием. Объединение нескольких блоков является распространенным решением в архитектурах глубокого обучения, поскольку оно позволяет модели изучать иерархическое представление данных.
class Mamba(nn.Module):
def __init__(self, seq_len, d_model, state_size, device):
super(Mamba, self).__init__()
self.mamba_block1 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block2 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block3 = MambaBlock(seq_len, d_model, state_size, device)
def forward(self, x):
x = self.mamba_block1(x)
x = self.mamba_block2(x)
x = self.mamba_block3(x)
return xRMSNorm — это пользовательский уровень нормализации, используемый для нормализации активации нейронных сетей, что может помочь стабилизировать и ускорить обучение.
class RMSNorm(nn.Module):
def __init__(self,
d_model: int,
eps: float = 1e-5,
device: str ='cuda'):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model, device=device))
def forward(self, x):
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) * self.weight
return outputИспользование этого слоя:
x = torch.rand(batch_size, seq_len, d_model, device=device)
# Create the Mamba model
mamba = Mamba(seq_len, d_model, state_size, device)
# rmsnorm
norm = RMSNorm(d_model)
x = norm(x)
# Forward pass
test_output = mamba(x)
print(f"test_output.shape = {test_output.shape}") # Should be [batch_size, seq_len, d_model]Выше приведен весь основной код модели, а подготовку и обучение данных можно выполнить ниже.
Мы настраиваем Enwiki8Dataset
class Enwiki8Dataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data['input_ids'])
def __getitem__(self, idx):
item = {key: val[idx].clone().detach() for key, val in self.data.items()}
return itemPad_sequences_3d используется для дополнения пакета последовательностей до одинаковой длины, гарантируя, что каждая последовательность в пакете имеет одинаковое количество элементов (или временных шагов). Это особенно важно во многих задачах машинного обучения, где входные данные должны иметь единообразную форму.
# Define a function for padding
def pad_sequences_3d(sequences, max_len=None, pad_value=0):
# Assuming sequences is a tensor of shape (batch_size, seq_len, feature_size)
batch_size, seq_len, feature_size = sequences.shape
if max_len is None:
max_len = seq_len + 1
# Initialize padded_sequences with the pad_value
padded_sequences = torch.full((batch_size, max_len, feature_size), fill_value=pad_value, dtype=sequences.dtype, device=sequences.device)
# Pad each sequence to the max_len
padded_sequences[:, :seq_len, :] = sequences
return padded_sequencesПроцесс обучения по-прежнему остается традиционным процессом Pytorch:
def train(model, tokenizer, data_loader, optimizer, criterion, device, max_grad_norm=1.0, DEBUGGING_IS_ON=False):
model.train()
total_loss = 0
for batch in data_loader:
optimizer.zero_grad()
input_data = batch['input_ids'].clone().to(device)
attention_mask = batch['attention_mask'].clone().to(device)
target = input_data[:, 1:]
input_data = input_data[:, :-1]
# Pad all the sequences in the batch:
input_data = pad_sequences_3d(input_data, pad_value=tokenizer.pad_token_id)
target = pad_sequences_3d(target, max_len=input_data.size(1), pad_value=tokenizer.pad_token_id)
if USE_MAMBA:
output = model(input_data)
loss = criterion(output, target)
loss.backward(retain_graph=True)
for name, param in model.named_parameters():
if 'out_proj.bias' not in name:
# clip weights but not bias for out_proj
torch.nn.utils.clip_grad_norm_(param, max_norm=max_grad_norm)
if DEBUGGING_IS_ON:
for name, parameter in model.named_parameters():
if parameter.grad is not None:
print(f"{name} gradient: {parameter.grad.data.norm(2)}")
else:
print(f"{name} has no gradient")
if USE_MAMBA and DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
model.S6.h[:current_batch_size, ...].copy_(temp_buffer)
optimizer.step()
total_loss += loss.item()
return total_loss / len(data_loader)То же самое касается и функции оценки:
def evaluate(model, data_loader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for batch in data_loader:
input_data = batch['input_ids'].clone().detach().to(device)
attention_mask = batch['attention_mask'].clone().detach().to(device)
target = input_data[:, 1:]
input_data = input_data[:, :-1]
# Pad all the sequences in the batch:
input_data = pad_sequences_3d(input_data, pad_value=tokenizer.pad_token_id)
target = pad_sequences_3d(target, max_len=input_data.size(1), pad_value=tokenizer.pad_token_id)
if USE_MAMBA:
output = model(input_data)
loss = criterion(output, target)
total_loss += loss.item()
return total_loss / len(data_loader)Наконец, Calculate_perplexity используется для оценки производительности языковых моделей, таких как Mamba.
def calculate_perplexity(loss):
return math.exp(loss)Функция load_enwiki8_dataset используется для загрузки и извлечения набора данных enwiki8, который обычно используется для сравнительного анализа языковых моделей.
def load_enwiki8_dataset():
print(f"Download and extract enwiki8 data")
url = "http://mattmahoney.net/dc/enwik8.zip"
urllib.request.urlretrieve(url, "enwik8.zip")
with ZipFile("enwik8.zip") as f:
data = f.read("enwik8").decode("utf-8")
return dataФункция encode_dataset предназначена для маркировки и кодирования набора данных при подготовке к обработке набора данных с помощью модели нейронной сети (например, Mamba).
# Tokenize and encode the dataset
def encode_dataset(tokenizer, text_data):
def batch_encode(tokenizer, text_data, batch_size=1000):
# Tokenize in batches
batched_input_ids = []
for i in range(0, len(text_data), batch_size):
batch = text_data[i:i+batch_size]
inputs = tokenizer(batch, add_special_tokens=True, truncation=True,
padding='max_length', max_length=seq_len,
return_tensors='pt')
batched_input_ids.append(inputs['input_ids'])
return torch.cat(batched_input_ids)
# Assuming enwiki8_data is a list of sentences
input_ids = batch_encode(tokenizer, enwiki8_data)
# vocab_size is the number of unique tokens in the tokenizer's vocabulary
global vocab_size
vocab_size = len(tokenizer.vocab) # Note that for some tokenizers, we might access the vocab directly
print(f"vocab_size = {vocab_size}")
# Create an embedding layer
# embedding_dim is the size of the embedding vectors (MAMBA model's D)
embedding_layer = nn.Embedding(num_embeddings=vocab_size, embedding_dim=d_model)
# Pass `input_ids` through the embedding layer
# This will change `input_ids` from shape [B, L] to [B, L, D]
def batch_embedding_calls(input_ids, embedding_layer, batch_size=256):
# Check if input_ids is already a tensor, if not convert it
if not isinstance(input_ids, torch.Tensor):
input_ids = torch.tensor(input_ids, dtype=torch.long)
# Calculate the number of batches needed
num_batches = math.ceil(input_ids.size(0) / batch_size)
# List to hold the output embeddings
output_embeddings = []
# Process each batch
for i in range(num_batches):
# Calculate start and end indices for the current batch
start_idx = i * batch_size
end_idx = start_idx + batch_size
# Get the batch
input_id_batch = input_ids[start_idx:end_idx]
# Call the embedding layer
with torch.no_grad(): # No need gradients for this operation
batch_embeddings = embedding_layer(input_id_batch)
# Append the result to the list
output_embeddings.append(batch_embeddings)
# Concatenate the embeddings from each batch into a single tensor
all_embeddings = torch.cat(output_embeddings, dim=0)
return all_embeddings
# `input_ids` is a list or tensor of the input IDs and `embedding_layer` is model's embedding layer
if USE_MAMBA:
# Set `batch_size` to a value that works for memory constraints
encoded_inputs = batch_embedding_calls(input_ids, embedding_layer, batch_size=1).float()
attention_mask = (input_ids != tokenizer.pad_token_id).type(input_ids.dtype)
return encoded_inputs, attention_maskТеперь вы можете тренироваться
# Load a pretrained tokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# Assuming encoded_inputs is a preprocessed tensor of shape [num_samples, seq_len, d_model]
encoded_inputs_file = 'encoded_inputs_mamba.pt'
if os.path.exists(encoded_inputs_file):
print("Loading pre-tokenized data...")
encoded_inputs = torch.load(encoded_inputs_file)
else:
print("Tokenizing raw data...")
enwiki8_data = load_enwiki8_dataset()
encoded_inputs, attention_mask = encode_dataset(tokenizer, enwiki8_data)
torch.save(encoded_inputs, encoded_inputs_file)
print(f"finished tokenizing data")
# Combine into a single dictionary
data = {
'input_ids': encoded_inputs,
'attention_mask': attention_mask
}
# Split the data into train and validation sets
total_size = len(data['input_ids'])
train_size = int(total_size * 0.8)
train_data = {key: val[:train_size] for key, val in data.items()}
val_data = {key: val[train_size:] for key, val in data.items()}
train_dataset = Enwiki8Dataset(train_data)
val_dataset = Enwiki8Dataset(val_data)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# Initialize the model
model = Mamba(seq_len, d_model, state_size, device).to(device)
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=5e-6)
# Training loop
num_epochs = 25 # Number of epochs to train for
for epoch in tqdm(range(num_epochs)): # loop over the dataset multiple times
train_loss = train(model, tokenizer, train_loader, optimizer, criterion, device, max_grad_norm=10.0, DEBUGGING_IS_ON=False)
val_loss = evaluate(model, val_loader, criterion, device)
val_perplexity = calculate_perplexity(val_loss)
print(f'Epoch: {epoch+1}, Training Loss: {train_loss:.4f}, Validation Loss: {val_loss:.4f}, Validation Perplexity: {val_perplexity:.4f}')Выше приведен полный код для обучения.
Подвести итог
Мы знакомим с концепциями и архитектурой Mamba и создаем репликацию Mamba с нуля, чтобы мы могли воплотить теорию в практику. Благодаря этому практическому подходу можно увидеть методы и эффективность моделирования последовательностей Mamba. Если вы хотите использовать его напрямую, вы можете посмотреть код, приведенный в статье.
Бумажный адрес:
https://arxiv.org/abs/2312.00752
Исходный код, предоставленный в статье:
https://github.com/state-spaces/mamba
Если вам это нравится, пожалуйста, подпишитесь на него:
Нажмите заглянуть Ты самый красивый!


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
