Высокопроизводительная сеть — SmartNIC, эволюция DPU и принципы работы
2 Состав базового сетевого адаптера Ethernet
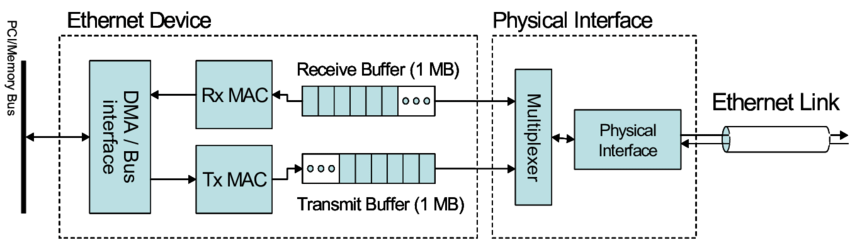
Физический интерфейс (разъем физического канала)
Физический интерфейс (разъем физического канал) отвечает за сетевой порт витой пары Воля (Электрический порт)или Оптический модуль(Оптический рот)илисоединятьприезжатьсетевая управление офисом одно. Physical Interface обычно имеют несколько Ethernet Ports。
- Электрический порт:в целомдля SFP、QSFP ждать,Например RJ45(Registered Джек, зарегистрирован из сокета) реализована сетевая карта и подключение сетевого кабеля.
- Оптический рот:в целомдляоптическое волокносоединятьустройство。
Распространенные скорости сетевых карт и типы интерфейсов в центрах обработки данных:
- Гигабитная сетевая карта 1GbE:Обычно на основе RJ45 Кабельный интерфейс, например Cat5e、Cat6 ждать。
- Сетевая карта 10GbE 10G:Обычно на основе SFP+ Интерфейс (10GbE) по оптическому кабелю.
- Сетевая карта 25GbE:Обычно на основе SFP28 Интерфейс (25GbE/10GbE) по оптическому кабелю.
- Сетевая карта 100GbE:Обычно на основе QSFP28 Интерфейс (100GbE/40GbE) по оптическому кабелю.
PHY (модем физического уровня)
PHY (модем физического уровня), реализация физического уровня TCP/IP, отвечает за преобразование цифровых сигналов, генерируемых компьютерами, в аналоговые сигналы, которые можно передавать на физическом носителе. Например: CSMA/CD, аналого-цифровое преобразование, кодек, последовательно-параллельное преобразование и т. д.
- Производительность на аппаратном уровне PHY Чип определяет электрические и оптические сигналы, состояние линии, опорную частоту, кодирование, скорость соединения и дуплексные возможности, необходимые для передачи и приема. И Кданный слой связи обеспечивает IEEE MII/GigaMII(Media Independed Interfade, независимый от носителя интерфейс) стандартный интерфейс для подключения MAC и PHY Поверхности управления транспортом иданные поверхности изданные. Кроме того, он имеет PCS(Physical Coding Подуровень, физическое кодирование), PMA (физическое Medium Вложение, подключение физического носителя), PMD (связанное с физическим носителем),MDIO (управление Data Input/Output)ждатьподслой。
- Выполнение на уровне программного обеспечения CSMA/CD(Carrier Sense Multiple Access/Collision протокол обнаружения, множественного доступа с контролем несущей/обнаружения коллизий). CSMA/CD Протокол имеет «Обнаружение конфликтов» и «Мониторинг перевозчика» Функция,Возможность определить, имеет ли место жительстваначальство данныесуществовать.,Если есть данныесуществовать, подождите.,После обнаружения приезжатьсеть простаивает,Подождите случайный период времени, а затем отправьте данные.
Существует также трансформатор между PHY и физическим интерфейсом, который имеет функции улучшения дальности передачи, восстановления формы сигнала, электрической изоляции, защиты от помех и молниезащиты. Трансформатор изолирует чипсет сетевой карты от внешней среды, повышает помехозащищенность, а также обеспечивает важную защиту.
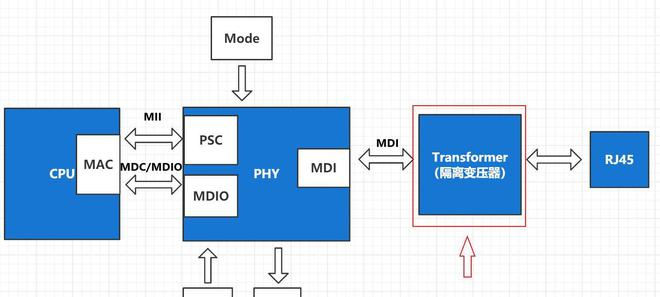
MAC (контроллер доступа к среде передачи данных)
MAC (Media Access Control, Media Access Controller), реализация уровня канала передачи данных TCP/IP, отвечает за управление физической средой, подключенной к физическому уровню.
- Производительность на аппаратном уровенькусок MAC чип, каждый Ethernet Ports Все они имеют глобальное уникальное MAC Адрес MAC Чип адреса. кроме того, MAC Существует также соответствующее из Rx/Tx Queues Для буферизации приема/отправки из Frames。
- Соответствие уровня программного обеспечения IEEE 802.3 Ethernet протокол, полный физический носитель Bit stream èОперационная система Ethernet Frames Преобразование между из, к и завершением Frames CRC проверять. Также будет контролировать PHY Конкретная реализация CSMA/CD протокол.
Усовершенствованные чипы MAC также будут обеспечивать функции фильтрации пакетов на уровне канала передачи данных. Например: фильтрация L2, фильтрация VLAN, фильтрация хостов и т. д.
Ethernet-контроллер
Ethernet-контроллердасетевая компонент cardizcore, соответствующий хосту компьютера (CPU + Память), обеспечивает основные функции плоскости управления и передает Водитель и Linux взаимодействовать с операционной системой. Имеет следующие функции:
- Инициализация устройства、запускать、останавливаться、Перезапустите рабочий интерфейс ожидания.
- DMA Control;
- Flow Control;
- Схема синхронизации и управления (программируемая логическая матрица);
- Обработка прерываний;
- ждать。
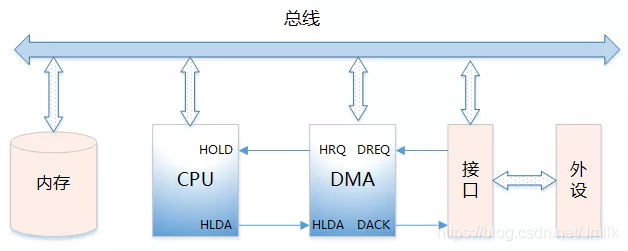
Шинный интерфейс
Шинный интерфейсдасетевая карты из разъема между материнскими платами компьютера, чтобы добиться CPU и NIC взаимодействие между. В основном включают DMA Interface и PCIe Interface Эти два типа.
DMA Interface
DMA Controller из Функция:
- Отправьте сигнал HOLD на ЦП и сделайте запрос на переключение шины.
- когда CPU После отправки сигнала разрешения на поглощение он отвечает за Bus изControl, введите DMA I/O модель.
- путем спаривания Main Memory Выполните адресацию и измените указатель адреса, чтобы реализовать Memory из Операций чтения и записи.
- К CPU проблема DMA Конечный сигнал, ЦП Возврат к нормальной работе модели.
Интерфейс DMA из Типа сигнала:
- DREQ (сигнал запроса периферийного устройства): ввод-вывод Периферийные устройства DMA Controller Сделайте запрос.
- DACK(DMA Ответный сигнал): DMA Controller К I/O периферийные устройстваизответный сигнал
- HRQ/HOLD(DMA Сигнал запроса): DMA Controller К CPU проблема,Требоватьперенимать Bus。
- HLDA (сигнал ответа ЦП): ответ ЦП позволяет контроллеру DMA взять на себя управление шиной.
PCIe Interface
PCI-E Стандарты периферийных интерфейсов прошли PCI,PCI-X и PCI-E Три этапа, разработанные почти 30 Годы времени. PCI-E Конечная цель – заменить и унифицировать Интерфейсы для PCI, дисков, сетевых карт, видеокарт и другой периферии решают проблему узкого места внутренней передачи данных компьютера.
Новейший стандарт PCI-E — это новое поколение интерфейса периферийной шины, предложенное Intel, которое использует последовательное соединение «точка-точка», популярное в настоящее время в отрасли. По сравнению с общей параллельной архитектурой PCI и более ранними компьютерными шинами, каждое устройство PCI-E имеет собственное выделенное соединение, не требует запроса полосы пропускания всей шины и может увеличить скорость передачи данных до очень высокой частоты, достигая высокой частоты. пропускная способность, которую PCI не может обеспечить.
- Устройство PCI-E (Peripheral Component Interconnect Express, PCI Express, PCI-E, Peripheral Component Interconnect Express)

- Устройство PCI-E по типу интерфейса

- Тип размера устройства PCI-E
- LP (половина высоты)
- FH (общая высота)
- HL (половина длины)
- Флорида (полнометражный)
- SW (одинарная ширина)
- DW (двойная ширина)
- Слот PCI/PCI-E:PCI-E Поддержка PCI / PCI-X Программное обеспечение совместимо, но слот интерфейса материнской платы несовместим, поскольку для PCI-E Это последовательный интерфейс, количество контактов будет меньше, слот будет короче, PCI-E Длина слотиз связана с количеством каналов из.

Состав устройства SmartNIC
Базовая сетевая карта — это устройство PCIe, которое реализует только подключение к Ethernet, то есть реализует логику уровня L1-L2, отвечает за инкапсуляцию/декапсуляцию кадра данных уровня L2 и соответствующую обработку кадра данных уровня L1. электрические сигналы уровня; и главный процессор отвечает за обработку логики более высокого уровня в стеке сетевых протоколов. То есть: ЦП отвечает за инкапсуляцию/декапсуляцию пакетов данных согласно логике уровня L3-L7;
При изменении скорости сети от 1Gbps、10Gbps、25Gbps、100Gbps из Развитие, потребности в скорости сети CPU Разрыв в вычислительных возможностях продолжает увеличиваться, стимулируя спрос на выделенные вычисления на стороне сети. также в сопровождении NIC С развитием вычислительных возможностей на кристалле промышленность последовательно предлагала различные Hardware Offload программа, различные CPU из workload Выгрузите данные на карту расширения периферийных устройств для обработки.
Первый способ – увеличить NIC из workload вычислительная мощность, например, современная NIC Частично реализовано L3-L4 логика уровня разгрузка, например: расчет проверки, реорганизация фрагментации транспортного уровня, чтобы уменьшить Host CPU из Обработка нагрузки. Есть даже особенные Сетевая карта, например: RDMA сетевая карта, а также преобразует весь L4 Слой обработки offload Перейдем к аппаратному обеспечению.
- TSO(TCP Segmentation Offload)
- GSO(Generic Segmentation Offload)
- LRO(Large Receive Offload)
- GRO (Generic Receive Offload)
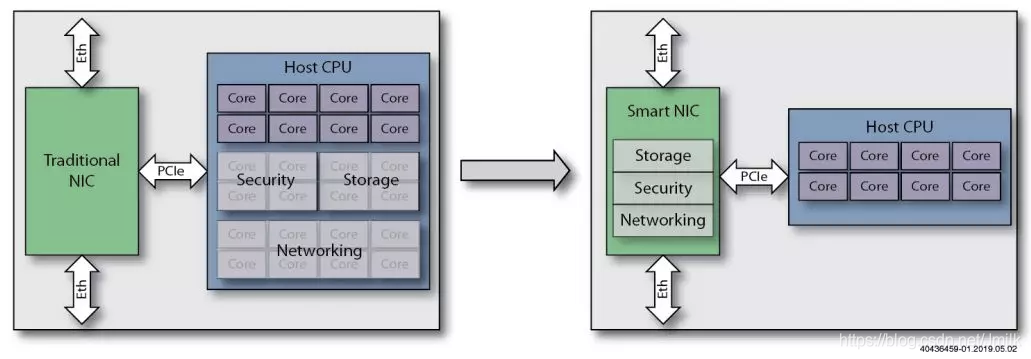
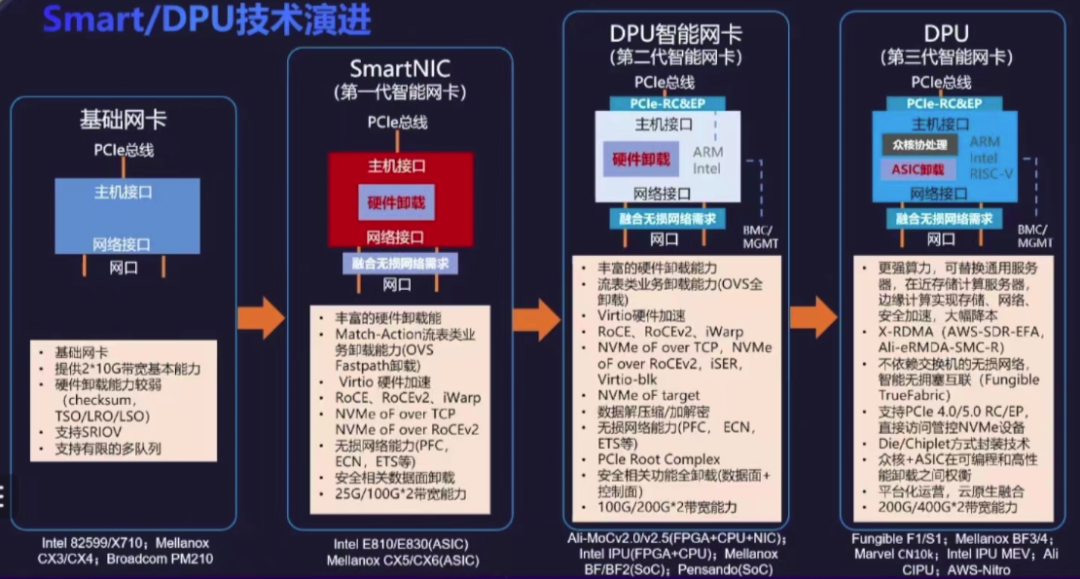
Поскольку сетевая карта обладает определенными вычислительными возможностями, ее также называют интеллектом, поэтому этот тип сетевой карты классифицируется как SmartNIC.
SmartNIC в NIC, представленный на чипе ASIC, FPGA или SoC для ускорения (обработки) определенного конкретного трафика.,оти Увеличить сетьиз Надежность,Уменьшите задержку,Улучшите производительность сети.
Короче говоря, SmartNIC Просто через Host CPU начальство Разгрузите рабочую нагрузку на оборудование сетевой карты для улучшения Host CPU из Управление производительностью. Среди них "рабочая нагрузка" не просто Сеть, это также может быть Storage、Security и т. д.
к FPGA осознать Smart NIC Примеры, чтобы понять, что именно workload Да Offload приезжать Smart NIC начальство для обработки из. И используйте FPGA Может кв соответствии снужно расслабитьсядобавить в,или Удалите эти функции.
Пример 1 приезжать 13 Объяснил, что кдобавить вприезжать Basic NIC Из элементов процесса создать функцию более мощной. Smart NIC。
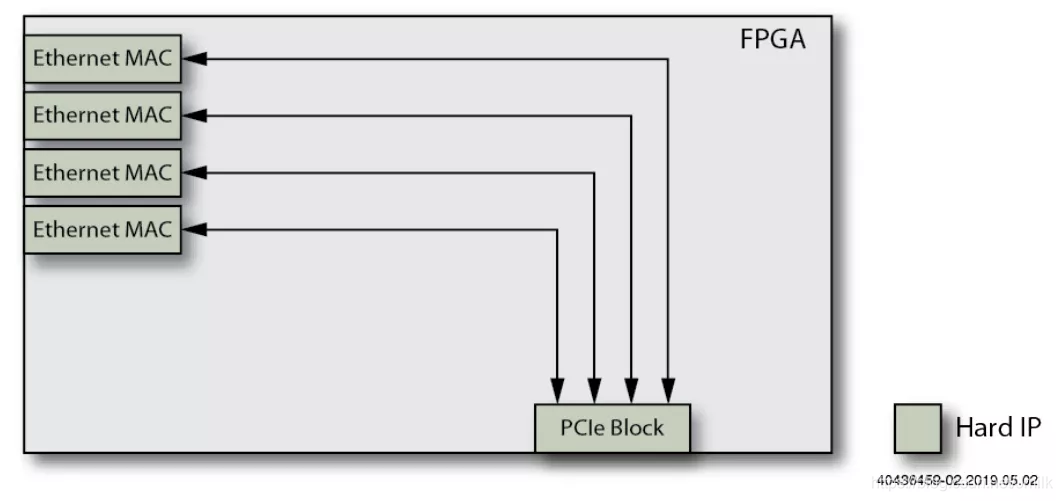
1. Basic NIC
Используйте несколько Ethernet MAC чип и один для использования с Host CPU Подключиться из PCIe Interface。Host CPU Со всем этим надо бороться превентивно Ethernet Packets。
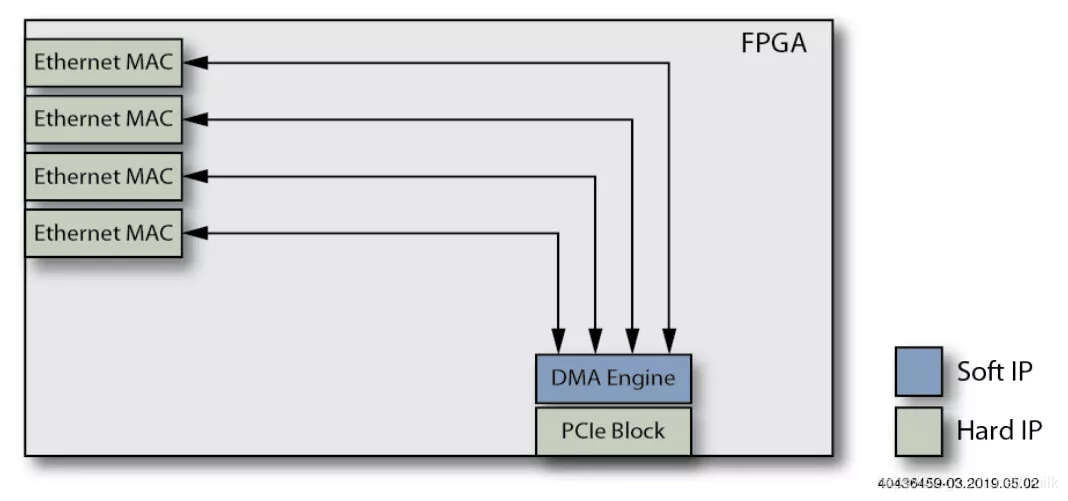
2. Добавьте функцию DMA Engine.
добавить в DMA Controller и DMA Интерфейс, будет NIC Memory Прямое картографирование Main Memory ZONE_DMA。Host CPU Доступно напрямую Main Memory читать Пакеты вместо необходимости скачивать с NIC Memory в ходе выполнения Копировать, тем самым уменьшая Host CPU израбочая нагрузка.
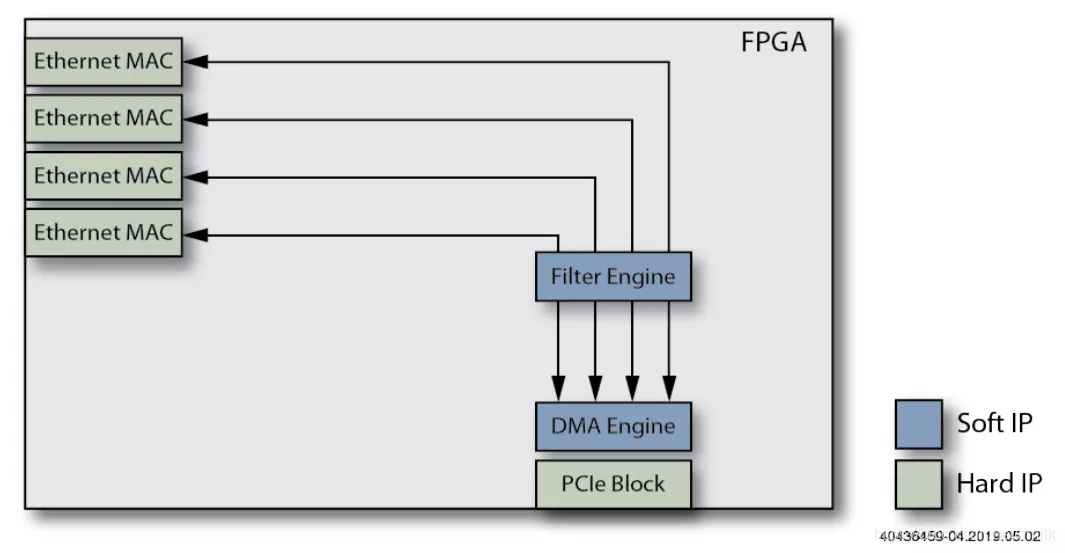
3. Добавить функцию фильтра.
Packets Filter модуль обеспечивает L2 Filtering、VLAN Filtering、Host Filtering функция ожидания, можно дополнительно уменьшить Host CPU израбочая нагрузка.
4. Добавьте внешнюю DRAM в механизм фильтрации.
для Packets Filter добавить виспользуется дляхранилище Filter Rules из DRMA память, дополнительно улучшенная Packets Filter из Функцияигибкость。
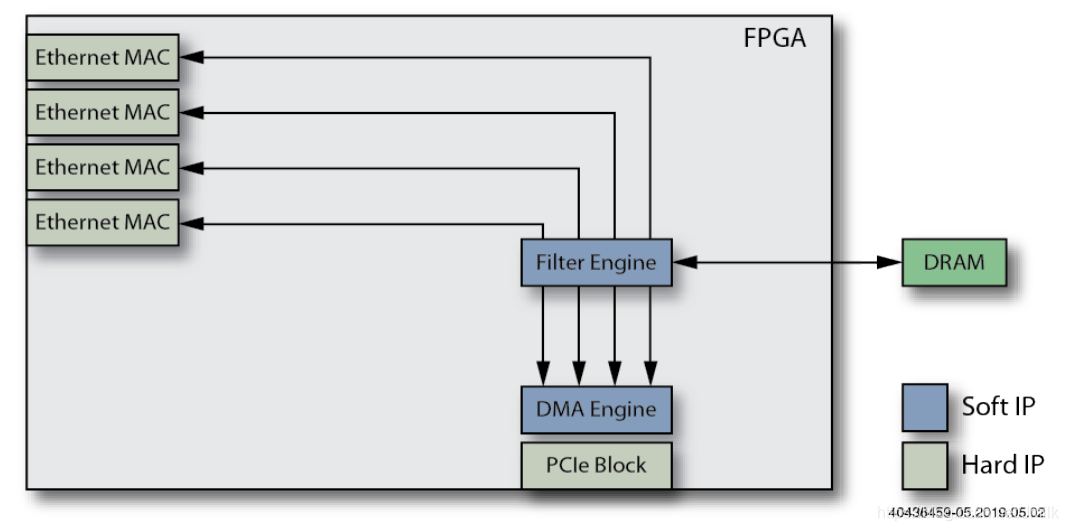
5. Добавьте функцию механизма разгрузки L2/L3.
добавить в L2 Switching и L3 Routing функция разгрузки функции пересылки плоскости данных для дальнейшего сокращения Host CPU израбочая нагрузка.
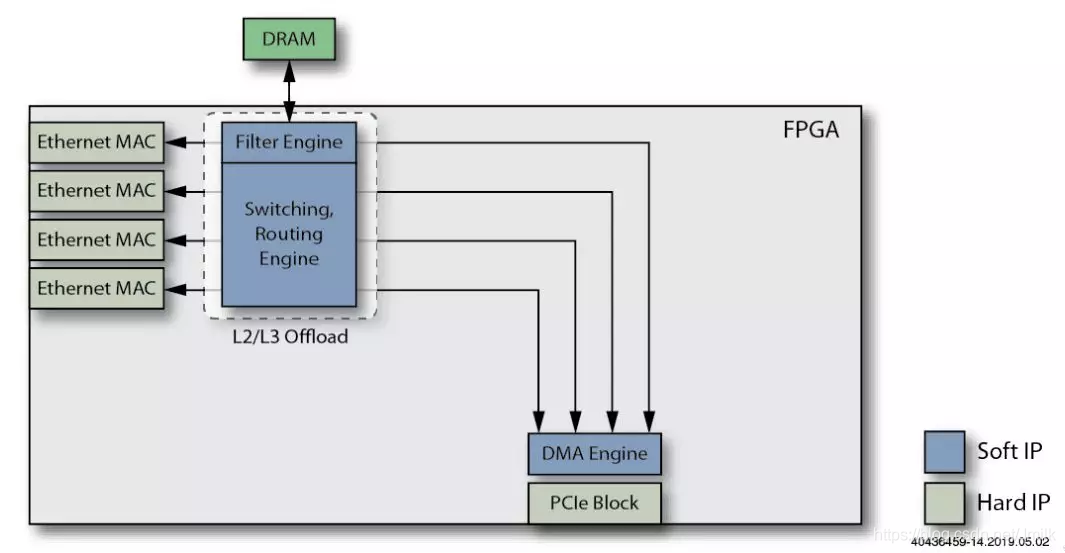
6. Добавьте функцию Tunnel Offload Engine.
Воля VxLAN、GRE、MPLSoUDP/GRE ждать Host Tunnel данныелапша Функцияудалитьприезжать SmartNIC, дальнейшее смягчение Host CPU Выполнение туннельной инкапсуляции/декапсуляции израбочая нагрузка.
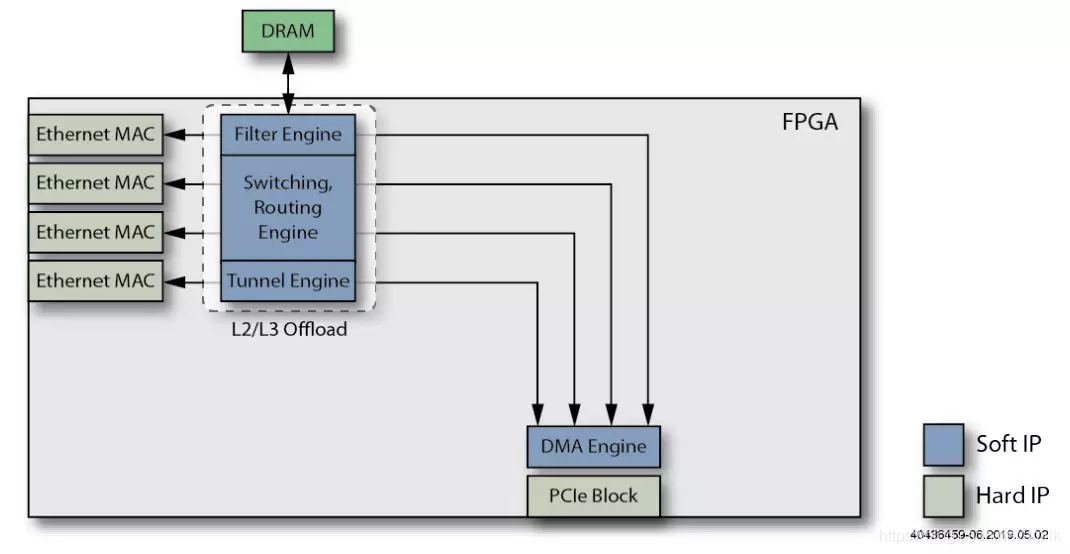
7. Добавьте внешнее хранилище с глубокой буферизацией.
добавить в Deep Выделенная память буфера (буфера глубины), используемая для построения опор. L2/L3/Tunnel Offloading из Дифференциация Buffer Rings。
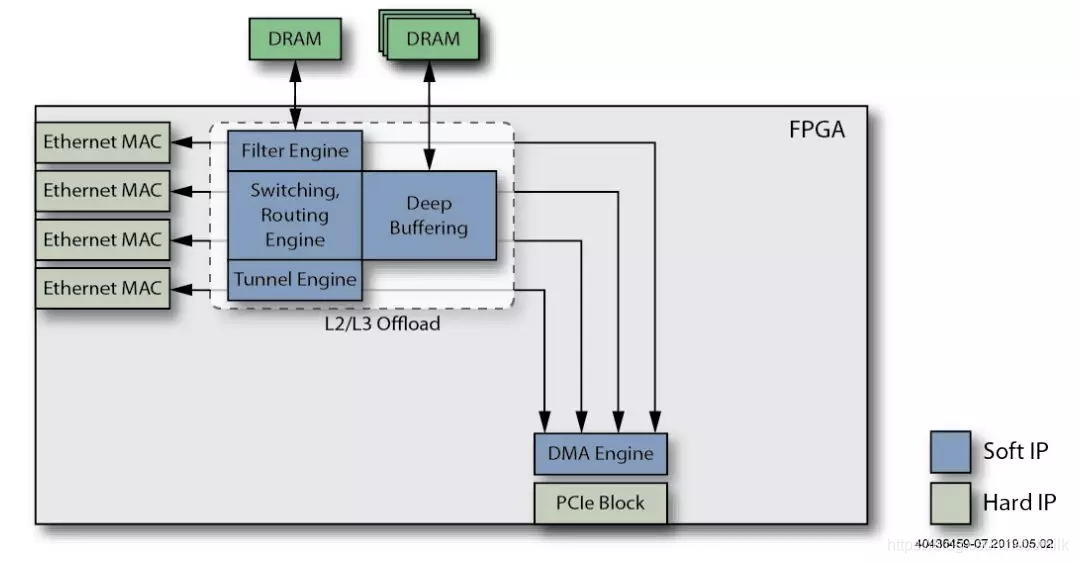
8. Добавьте функцию Flows Engine.
против vSwitch / vRouter Элемент виртуальной сети Fast Path поставлять Traffic Flows модуль, настройте другой DRAM процессор хранилища, способный обрабатывать миллионы Flow Table Entries。
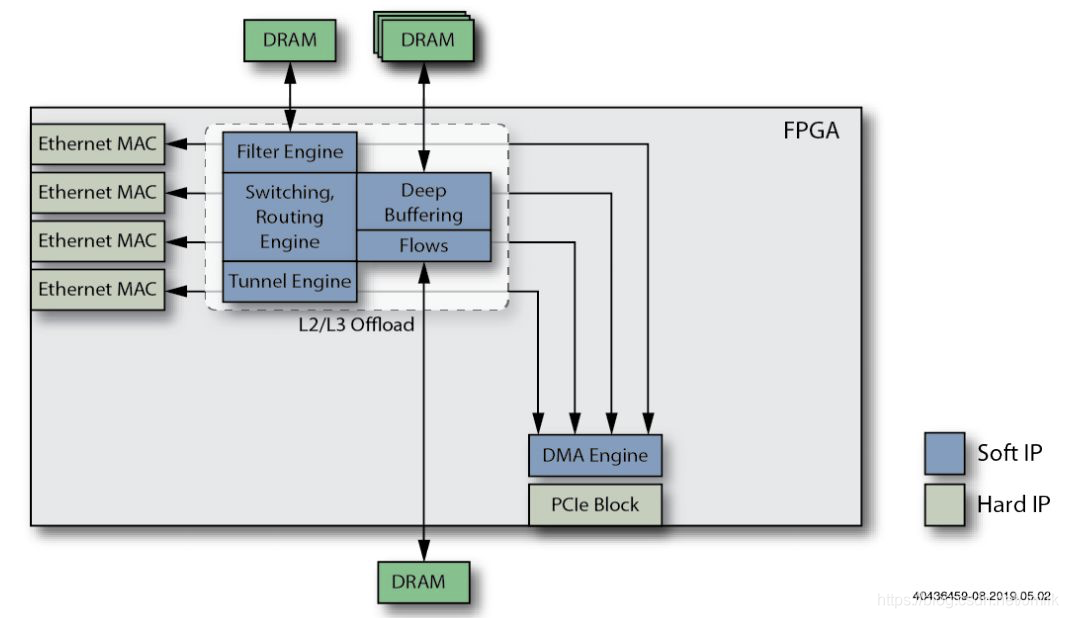
9. Добавьте функцию механизма разгрузки TCP.
удалить все или часть TCP Функции протокола, смягчение TCP Сервер из Host CPU рабочая нагрузка.
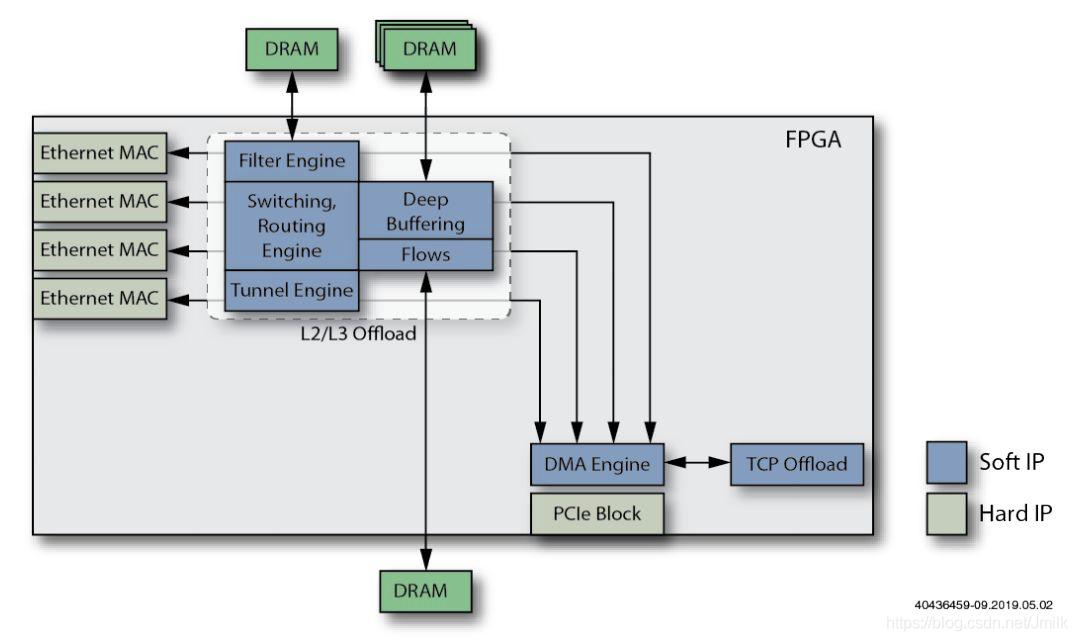
10. Добавьте функцию механизма разгрузки безопасности.
удалить TLS Такая функция шифрования/дешифрования, противоречащая Traffic Flow Можно выбрать включение/выключение TLS ускориться.
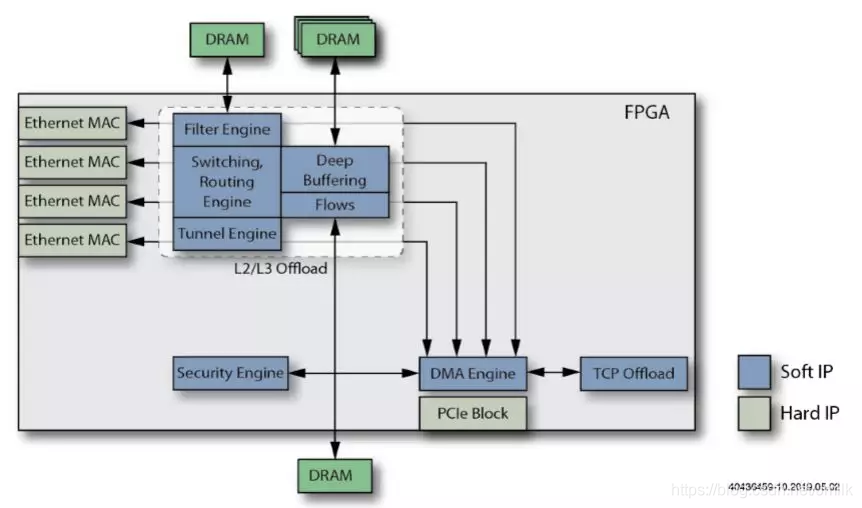
11. Добавьте функцию QoS Engine.
добавить в QoS Engine Функция,удалить TC может быть реализован модуль управления потоком ожидания Multi-Queues и QoS Функция планирования.
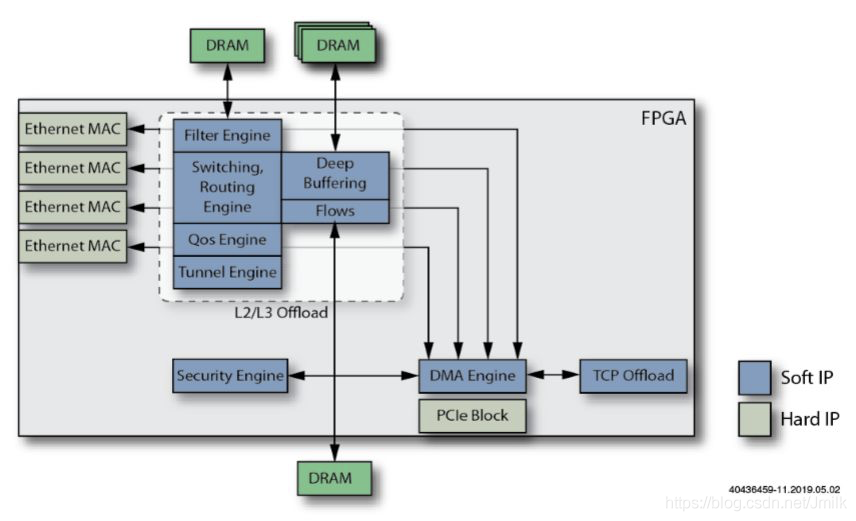
12. Добавьте функцию программируемого двигателя.
добавить в P4 RMT(Reconfigurable Match Столы реконфигурируемые Match-Action таблица) этого типа Programmable Двигатель, по его словам, должен быть программируемым. Pipeline способность.
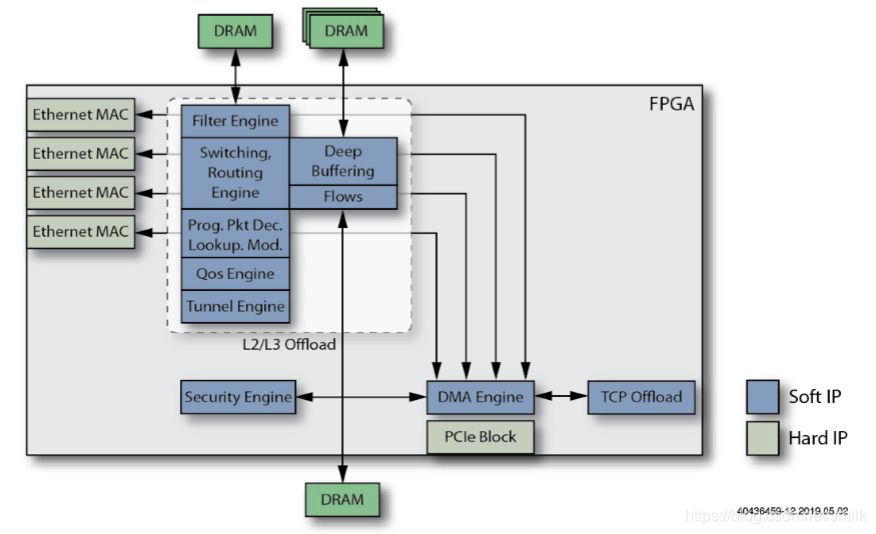
13. Добавьте один или несколько встроенных процессоров ASIC.
добавить в используется для плоскости управления и плоскости управления. CPU Процессор обеспечивает полную программируемость программного обеспечения.
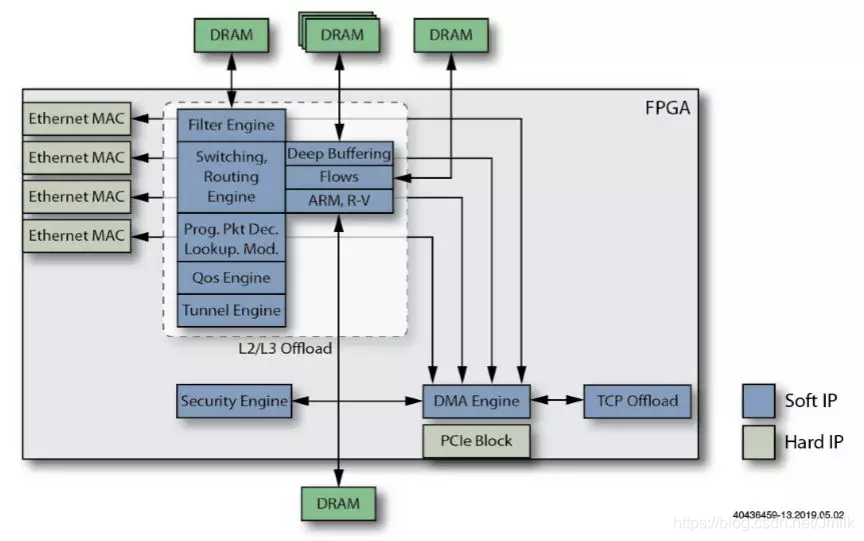
Состав устройства DPU
Закон Мура не работает
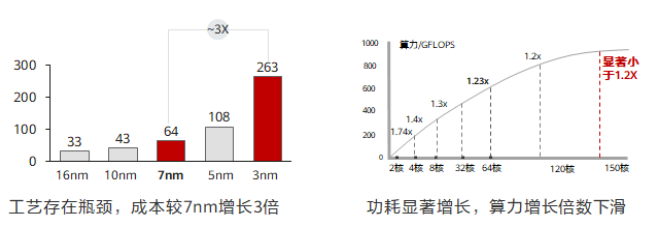
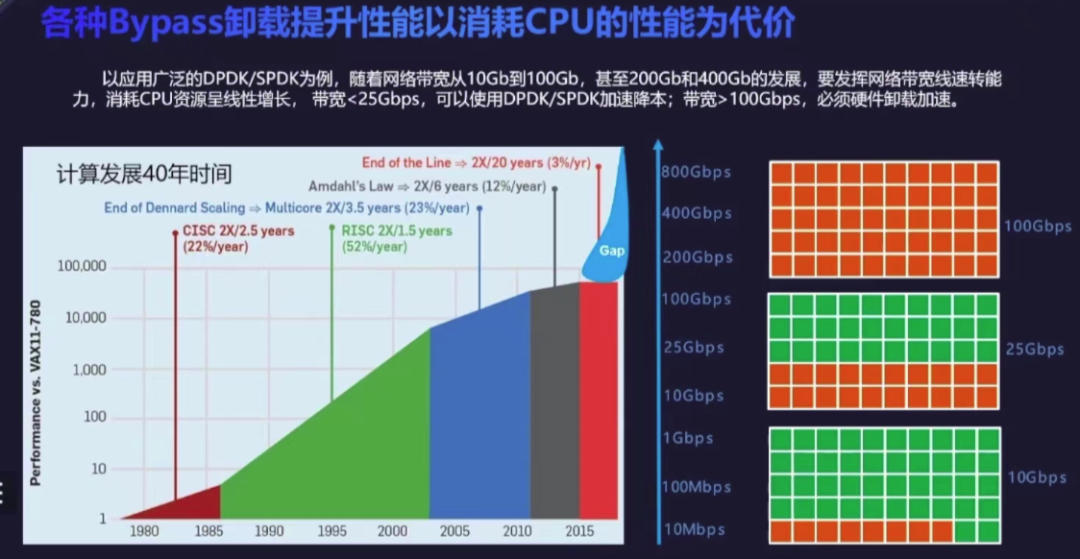
В настоящее время полупроводниковые технологии быстро развиваются, и производительность процессорных чипов улучшается быстрыми темпами. 18 Одну цифру можно удвоить, вычислительная мощность увеличивается, а спрос на программное обеспечение находится в состоянии баланса спроса и предложения. Однако в последние годы развитие полупроводниковой технологии приблизилось к физическому пределу, интегральные схемы становятся все более сложными, а совершенствование технологии одноядерных чипов в настоящее время остановилось на уровне 3nm。
Реальный способ — увеличить вычислительную мощность за счет многоядерного стекирования, но вместе По мере увеличения количества ядер коэффициент энергопотребления на единицу вычислительной мощности также будет значительно увеличиваться, а стекирование не может обеспечить линейного роста вычислительной мощности. Например: Воля 128 основной стек для 256 ядро, но общий уровень вычислительной мощности улучшить невозможно. 1.2 раз. Процесс эволюции вычислительных блоков приблизился к базовому уровню, и каждый 18 Их число удвоилось, и срок действия закона Мура истек. 2016 год Год 3 луна 24 Сегодня Intel объявила, что сдастся “Tick-Tock” В будущем модель НИОКР изменится с двух циклов НИОКР на три цикла НИОКР.
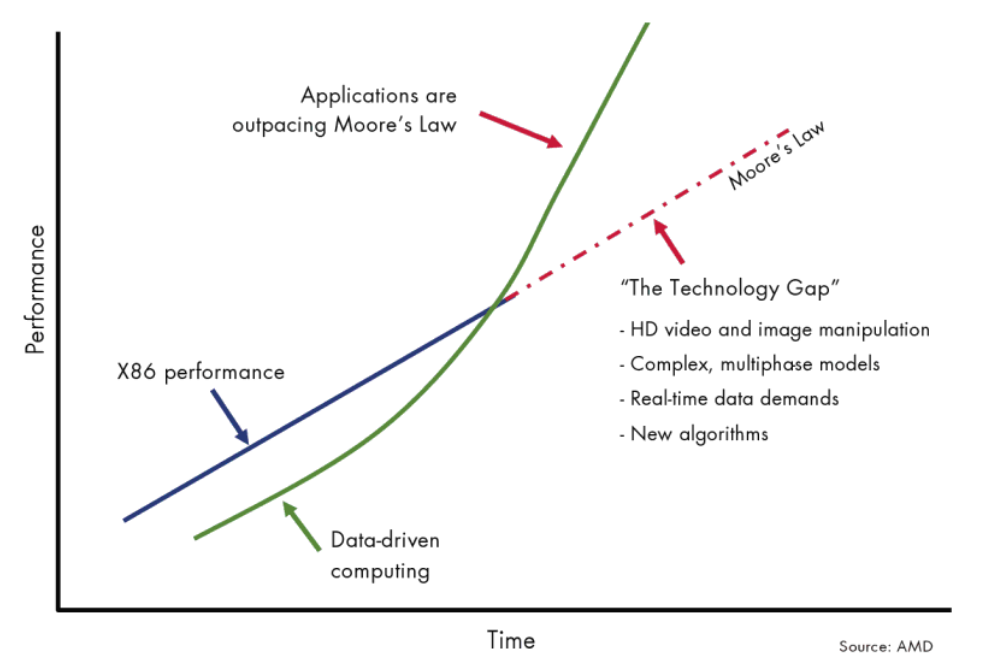
С одной стороны — Закон Мура не работает, но то, что происходит на другой стороне, существует «Закон данных Мура» —— IDC Данные показывают, что объем глобальных данных увеличился в прошлом. 10 Средний совокупный темп роста Годиз Года близок к 50%, а также прогнозирует, что спрос на вычислительную мощность будет удваиваться каждые четыре месяца.
Видно, что соотношение между спросом и предложением вычислительных мощностей уже разбалансировано.
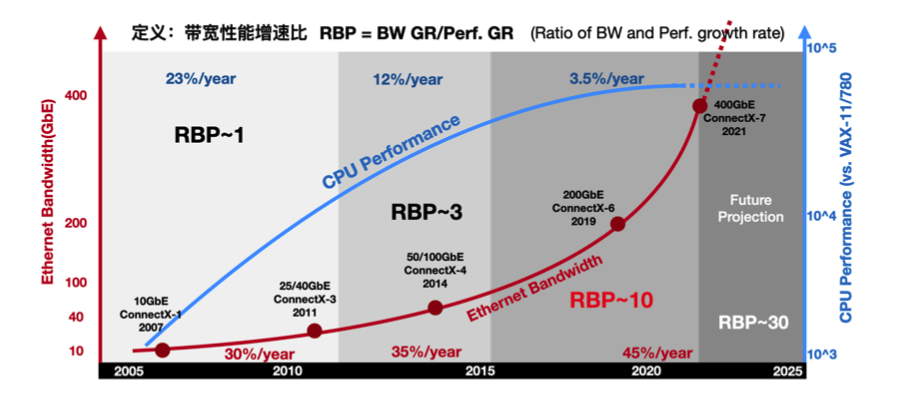
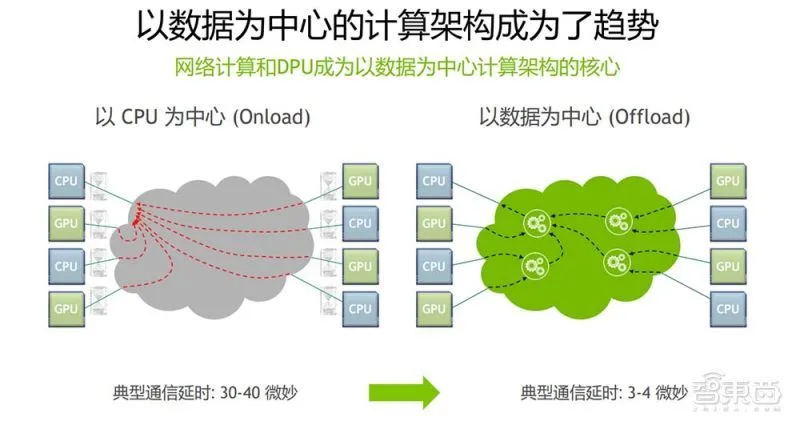
одинотсетьиз Начиная с перспективы,Можеткиспользовать RBP(Ratio of Bandwidth and Performance growth скорость, коэффициент роста производительности полосы пропускания) описывает эту взаимосвязь спроса и предложения. РБП=БВ GR/Perf. GR (темпы роста пропускной способности сети) / CPU рост производительности).
2010 До Года рост пропускной способности сетииз Годизации составлял ок. 30%,приезжать 2015 Годувеличиватьприезжать 35%,Затемсуществоватьзакрывать Годдостигатьприезжать 45%. Соответствует из, ЦП из Рост производительностиот 10 Годвпередиз 23%,отклонитьприезжать 12%,исуществоватьзакрывать Годнапрямую сократитьприезжать 3,5%. В течение этих трех периодов времени RBP Индикатор начинается с RBP~1 Рядом (ввод-вывод Давление пока не проявилось), начальство приезжать RBP~3, а существование почти превзошло Год RBP~10。CPU Темпы роста вычислительных мощностей практически не справляются с темпами роста пропускной способности.
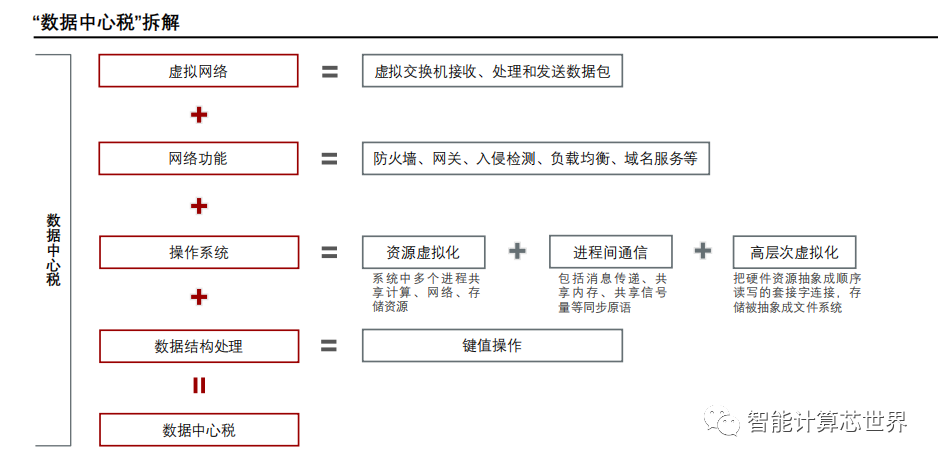
Высокий налог на центры обработки данных
существовать 10GbE и 25GbE сцена, традиционная NIC из Производительность приемлемая, DPDK ждатьвысокая производительностьданные технологии наземной транспортировки займут лишь часть CPU ресурс. Но существование постепенно становилось популярнымиз 40GbE и 100GbE В сценарии процессор Произойдет блокировка.
в соответствии с Fungible и AWS из статистики, существуют крупные дата-центры, учтен сетевой трафик, рассчитанный из 30% Слева и справа, то есть: ЦП 30% из workload Все они используются для обработки трафика. Эти накладные расходы ярко называются Datacenter Tax (Налог на центры обработки данных). налог). То есть перед запуском бизнес-программы, если ее сначала подключить, она займет вычислительные ресурсы.
Стена памяти фон Неймана
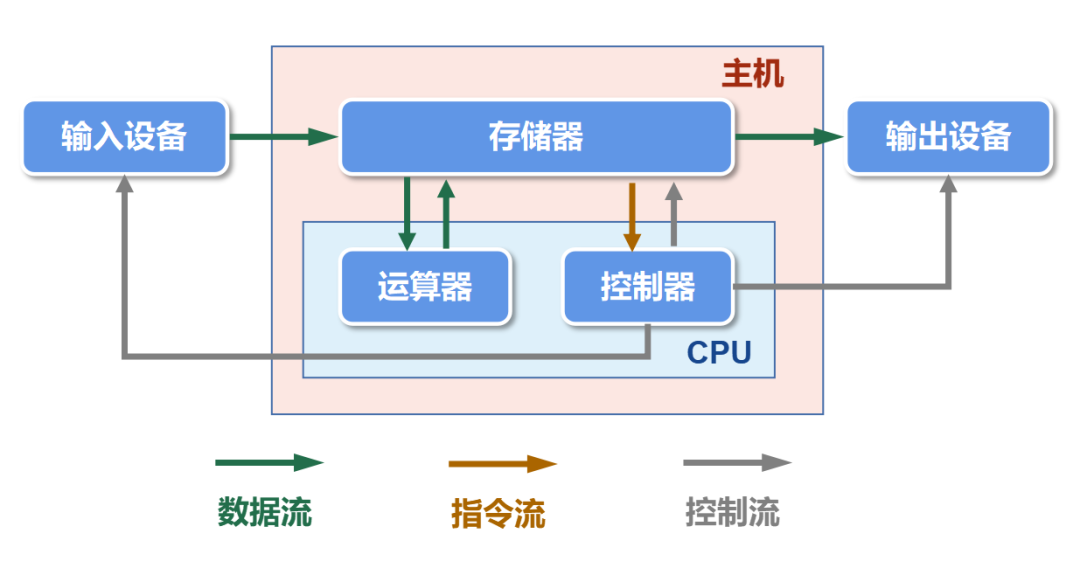
Архитектура фон Неймана как компьютер с хранилищем программ, ЦП от Main Memory В читаемых, после завершения расчета существования, обратно записывается Воляданный. Негласное правило сохранения существования гласит. CPU Скорость вычислений Main Memory Фаза скорости передачикогда。относительноиз,Однажды выйдя из равновесия,Тогда медленная сторона станет узким местом.
и «Стена памяти» из Реальность такова DDR(Main Memory иземкостьи Bus Пропускная способность передачи) стала недостатком. Это означает, что традиционная компьютерная архитектура больше не может удовлетворить потребности новых приложений, интенсивно использующих память. Например AI DL/ML Сцена обучения имеет характеристики высокого параллелизма и высокой связанности. Мало того, что во всем процессе работы алгоритма участвует большое количество людей, связь между этими людьми также очень сильна, поэтому это очень важно для нее. Main Memory Выдвинули очень высокие требования.
Для решения проблемы стены памяти в настоящее время в отрасли существуют следующие решения:
- Увеличение пропускной способности хранилища:Используйте высокую пропускную способностьизвнешнее хранилище,Например, HDM2, снижение доступа к DDR. Хотя этот метод кажется самым простым и прямым.,Но проблема в том, что эффективность кэширования и планирования глубокого обучения затруднена;
- кусокначальствохранилище:существоватьиметь дело сустройствоосновнойкусок Университет Лицзихранилище,Отказаться от ГДР, например, интеграция десятков мегабайт. СРАМ. Этот метод кажется относительно простым и понятным, однако высокая стоимость также является существенным недостатком.
- Вычисления в памяти:существоватьхранилищеустройствоначальствоинтегрированные вычисленияодин Юань,сейчассуществоватьтакжеэтоотносительно популярныйсосредоточиться наизнаправление К。
Длинные пути ввода-вывода данных
На основе данных кначальства,Область DSA/DSL (выделенный сопроцессор) и гетерогенных вычислений стала популярным методом исследования. против различных сценариев применения,Существует развертывание выделенных сопроцессоров (например, GPU, ASIC, FPGA, DSA) в системе фон Неймана для ускорения обработки.
Но есть и интуитивная проблема, процессор и Main Memory к И Device Memory между из Длинными пути ввода-вывода Данные также станут узким местом в производительности вычислений. к CPU+GPU Пример гетерогенных вычислений, графический процессор Он обладает мощной вычислительной мощностью и может одновременно работать с сотнями ядер, но “CPU+GPU "отдельный" Невозможно легко хранить большие объемы существующего в архитектурном хранилищеприезжать. GPU Device Memory , необходимо дождаться обновления видеопамяти. В то же время огромные объемы данныхсуществовать CPU и GPU Перемещение вперед и назад между ожидающими акселераторами также увеличивает расход дополнительной скорости.
Видно, к. CPU для Центра архитектуры существуют в гетерогенных вычислительных сценариях из-за памяти IO Слишком длинные пути также могут стать узким местом в производительности.
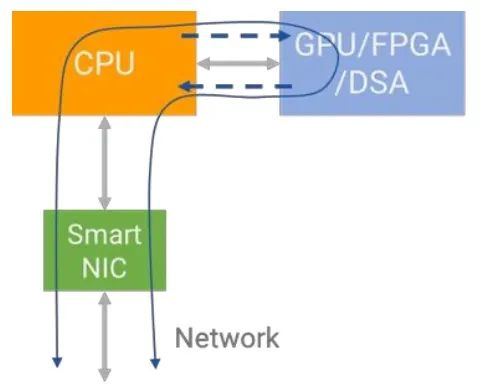
Новая архитектура, ориентированная на DPU
к DPU для Центра и зданные Центр — это новое слово в компьютерной архитектуре. существующие Центр, Воля Еще CPU и GPU из workload offload приезжать DPU(Data Processing Unit,блок обработки данных),Производит расчеты, хранилищеисеть становится более тесно связанной.
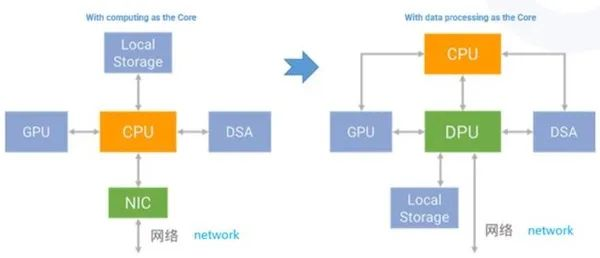
существоватьк Прошлое,Расчеты исеть независимы друг от друга.,Каждый заботится о своих делах. Как упоминалось в тексте начальствоприезжаиз,Вместе с узким местом производительности процессора истекает срок действия закона Мура,Необходимо ускорить расчеты различными способами.,Но эти методы очень усложняют проблему. Становится очень трудно решать проблемы, следуя старому образу мышления. Интеграция вычислений и исеть,Используйте метод сетииз для решения расчетных задач,Решите задачу сетииз вычислительным путем,Но это очень эффективная и новая идея.
Важной тенденцией будущего является непрерывная интеграция вычислений и вычислений. Суть DPU заключается в том, чтобы вычисления происходили близко к тому месту, где они происходят.
- ЦП отвечает за общие вычисления.
- Графический процессор отвечает за ускорение вычислений
- DPU Отвечает за внутреннюю и зданную передачу и обработку данных центра обработки данных.
Абстрактная архитектура ДПУ
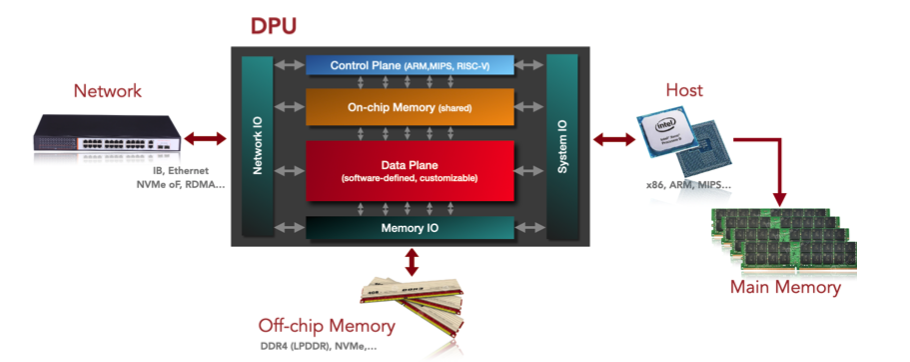
плоскость управления
Работает на процессорах общего назначения (x86 / ARM / MIPS) и реализация памяти чипа, могут работать NIC ОС (Linux), в основном отвечающая за следующую работу:
- Управление работой устройства DPU
- Управление безопасностью:корень доверия、Безопасностьзапускать、Безопасное обновление прошивки、На основе аутентификации и управления жизненным циклом контейнера и приложения.
- Мониторинг в реальном времени:верно DPU из Различных Подсистем отслеживаются, в том числе: плоскость данныхиметь дело содин Юаньждать。Оборудование для наблюдения в реальном времениданет Можетиспользовать、Трафик в устройстведанет正常,Периодически формируйте отчеты,Записывайте журналы доступа к устройствам и журналы изменений конфигурации.
- Вычислительная задача DPU и конфигурация ресурсов
- Сеть Функция управления вычислительными задачами.
- хранилище Функция задач расчета поверхности управления.
- ждать。
плоскость данных
Работает на выделенном процессоре (NP / ASIC / FPGA)и NIC Реальностьсейчас,В основном отвечает за следующую работу:
- Программируемая функция обработки сообщений.
- Функция ускорения протокола.
Подсистема ввода-вывода
System I/O:Зависит от PCIe осознать, взять на себя ответственность за DPU и Интеграция с другими системами из. поддерживать Endpoint и Root Complex Два типа реализации.
- Endpoint System I/O:Воля DPU делатьдля "от оборудования" Доступприезжать Host CPU Платформа обработки, Воляданныеначальство передается CPU для обработки.
- Root Complex System I/O:Воля DPU делатьдля «Основное устройство» Подключитесь к другим платформам ускоренной обработки (например, FPGA, GPU) или высокоскоростных периферийных устройств (например. SSD), воляданные выгружаются на платформу ускорения или периферийные устройства для обработки.
Network I/O:Зависит от Реализация NIC (процессора сетевого протокола) с IP/FC Fabric взаимосвязаны.
Main Memory I/O:Зависит от DDR и HBM Реализация интерфейса, связанного с внекристальной памятью, может использоваться как для Cache и Shared Memory。
- DDR Может ли кпо обеспечить относительно большую емкость хранилища (512 ГБ кначальство)。
- HBM Может ли кпо обеспечить относительно большую пропускную способность хранилища (500 ГБ/с)? кначальство)。



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
