Вышел технический отчет FineWeb! Раскрытие самого большого и высококачественного набора предтренировочных данных HuggingFace.
Монтажер: Минди
【Шин Джиген Введение】из большого масштабасеть Ползти、Тонкая фильтрация для технологии дедупликации,Узнайте, как создавать высококачественные коллекции данных, с помощью технического отчета FineWeb,Лучшее качество и производительность для предварительной подготовки к большой языковой модели (LLM).
Производительность больших языковых моделей (LLM) сильно зависит от качества и размера набора данных для предварительного обучения.
Однако наборы данных для предварительного обучения для современных LLM, таких как Llama 3 и Mixtral, недоступны публично; о том, как они создаются, мало что известно;
Недавно команда Hugging Face выпустила набор данных FineWeb, новый крупномасштабный (15 триллионов токенов, 44 ТБ дискового пространства) набор данных для предварительного обучения LLM.
В то же время они также подробно представили процесс принятия решений по обработке этого набора данных в техническом отчете: FineWeb создан на основе 96 снимков CommonCrawl и показывает, как он обеспечивает более высокую производительность, чем другие открытые наборы данных для предварительного обучения, благодаря тщательной дедупликации. и стратегии фильтрации LLM.
Подготовка к созданию набора данных
Первым шагом для создания набора данных является получение крупномасштабных данных.
Common Crawl — это некоммерческая организация, которая сканирует веб-данные с 2007 года и каждые 1–2 месяца выпускает новую версию сканирования, содержащую от 200 до 400 Ти Б текстового контента.
Таким образом, Common Crawl послужил отправной точкой для набора данных FineWeb.
Во-вторых, из-за огромного объема задействованных данных необходима модульная и масштабируемая база кода для быстрого принятия решений по обработке и надлежащего распараллеливания рабочих нагрузок, обеспечивая при этом четкое понимание данных.
С этой целью команда разработала datatrove — библиотеку обработки данных с открытым исходным кодом, способную плавно масштабировать настройки фильтрации и дедупликации на тысячи ядер ЦП.
При создании набора данных главный вопрос, который следует учитывать, заключается в том, что представляют собой данные «высокого качества».
Распространенный подход заключается в обучении небольших моделей на репрезентативном подмножестве набора данных и их оценке с помощью набора оценочных задач.
Исследователи обучили две модели с одинаковой структурой на двух версиях набора данных: одной с дополнительными этапами обработки, а другой — без них, чтобы сравнить влияние этапов обработки данных на производительность модели.
Для оценки модели они выбрали тесты производительности, такие как Commonsense QA, HellaSwag и OpenBook QA, и ограничили размер выборки более длительных тестов производительности, чтобы избежать переобучения и обеспечить надежность и способность к обобщению результатов оценки модели.
Как дедуплицируется и фильтруется набор данных
На следующем рисунке показаны основные этапы создания набора данных FineWeb:
Фильтрация URL-адресов → Извлечение текста → Языковая фильтрация → Фильтрация Gopher → Дедупликация MinHash → Фильтр C4 → Пользовательский фильтр → Удаление PII (личной информации)
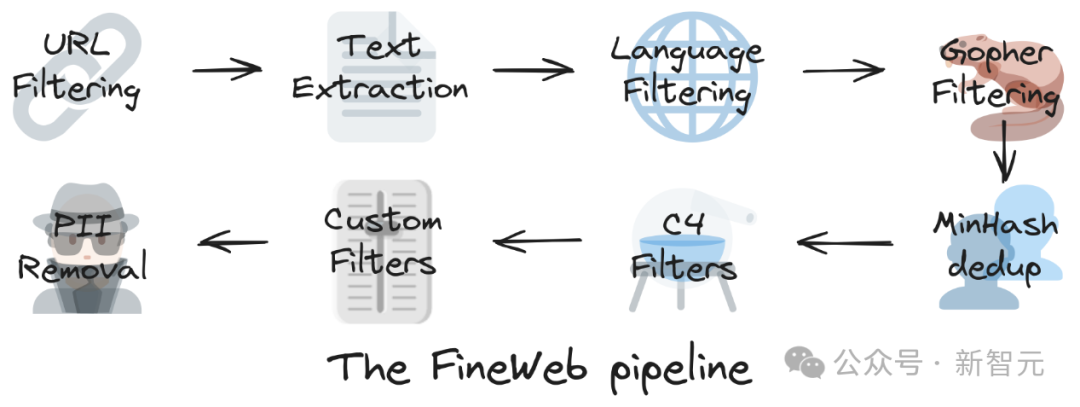
В этой статье в основном представлены части дедупликации и фильтрации, поскольку эти два шага имеют решающее значение для повышения производительности модели, а также увеличения разнообразия и чистоты данных для создания высококачественных наборов данных.
Дедупликация данных
В Интернете существует множество агрегаторов, зеркальных сайтов или шаблонных страниц, что может привести к дублированию контента на разных доменных именах и веб-страницах.
Было показано, что удаление этих дубликатов (дедупликация) повышает производительность модели и уменьшает необходимость запоминать данные предварительного обучения, что помогает модели лучше обобщать.
Исследователи использовали MinHash, технологию дедупликации на основе нечеткого хеширования, поскольку ее можно эффективно масштабировать на множество узлов ЦП и регулировать порог сходства (путем контроля количества и размера сегментов) и длину рассматриваемых подпоследовательностей (путем управления n- размер грамма).
Исследователи разделили каждый документ на 5 граммов и использовали 112 хэш-функций для расчета минхэшей.
112 хеш-функций разделены на 14 сегментов, каждый блок имеет 8 хешей, с целью найти документы, которые похожи как минимум на 75%.
Документы с одинаковыми 8 минхешами в любом сегменте считаются дубликатами друг друга.
Следует отметить, что исследователи обнаружили странный феномен: хотя после дедупликации объем данных значительно меньше (например, самый старый пакет данных после дедупликации имеет только 10% исходного содержимого), но после дедупликации при использовании данных для обучения модели производительность модели не улучшилась и даже хуже, чем у предыдущей модели, обученной на данных без дедупликации.
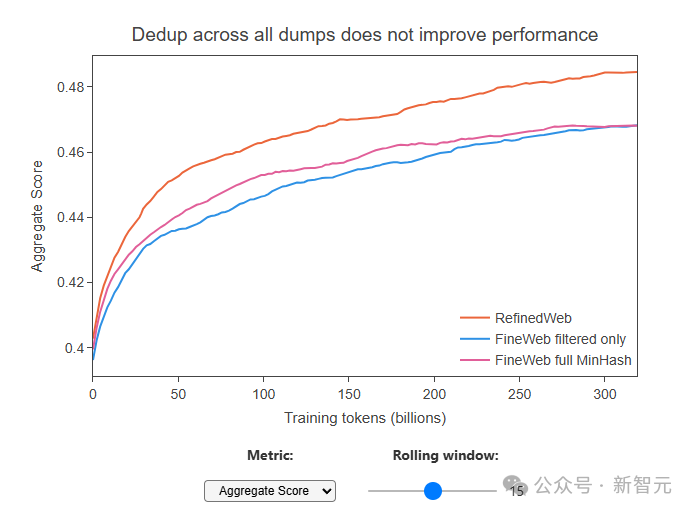
Дедупликация всех пакетов не улучшила производительность.
Это показывает, что иногда дедупликация бывает слишком жесткой, и часть полезного контента может быть удалена, а оставшийся контент может быть не высокого качества.
Это также напоминает нам о том, что нам необходимо найти точку баланса, которая заключается в удалении повторяющихся и некачественных данных, сохраняя при этом достаточную и ценную информацию.
Чтобы улучшить метод дедупликации, исследователи попробовали новую стратегию: использовать технологию MinHash для каждого отдельного пакета данных для выполнения независимой дедупликации вместо объединения всех пакетов данных вместе для дедупликации.
Таким образом, разница в распределении между каждым кластером с большим количеством повторений и кластером с меньшим количеством повторений сбалансирована, что делает дедупликацию более «щадящей».
Фильтрация данных
Во-первых, давайте представим набор данных C4, который часто используется для обучения модели большого языка (LLM). Он очень хорошо работает в тесте Hellaswag.
Исследователи FineWeb сначала обратились к стратегии фильтрации C4, сначала догоняя ее производительность, а затем превосходя ее.
Применив все правила фильтрации (удалив строки, не заканчивающиеся знаками препинания, упоминания JavaScript и уведомления о файлах cookie, а также удалив документы, длина которых не превышает порогового значения, содержащие «lorem ipsum» или фигурные скобки {}), они смогли сравнить производительность Hellaswag с C4. .
Затем, посредством многочисленных исследований абляции, исследователи определили три специальных фильтра, которые показали наиболее значительные улучшения в общих показателях:
- Удалить документы с соотношением строк, оканчивающихся знаками препинания ≤ 0,12 (удалено 10,14% токенов)
- Удалить документы с соотношением символов в повторяющихся строках ≥ 0,1 (удалено 12,47% токенов)
- Удалить документы с соотношением строк короче 30 символов ≥ 0,67 (удалено 3,73% токенов)
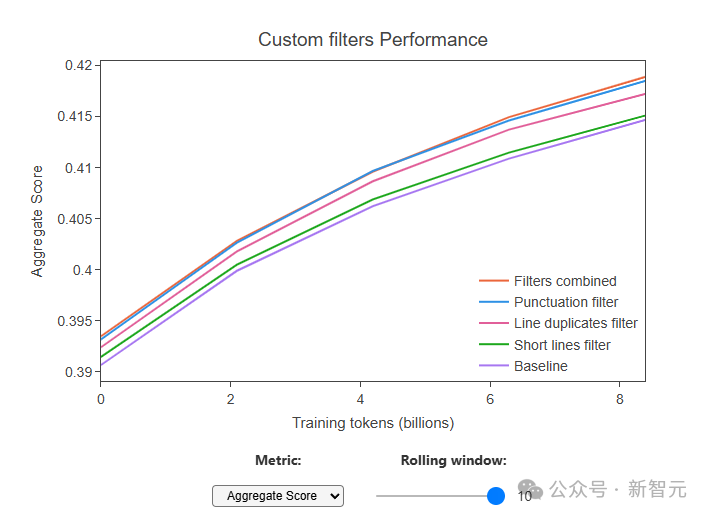
Когда эти три фильтра применялись вместе, было удалено примерно 22% маркеров.
Эти фильтры позволяют им еще больше повысить производительность и значительно превзойти производительность набора данных C4, обеспечивая при этом больший набор данных.
Производительность набора данных FineWeb
Сравнение абляции с другими общедоступными наборами данных веб-масштаба, которые обычно считаются наиболее качественными, включая RefinedWeb (500 миллиардов токенов), C4 (172 миллиарда токенов), Dolma v1.6 (3 триллиона токенов)) и т. д., FineWeb ( 15 триллионов токенов) обеспечивает самую высокую производительность модели на данный момент, позволяя при этом обучать триллионам токенов.
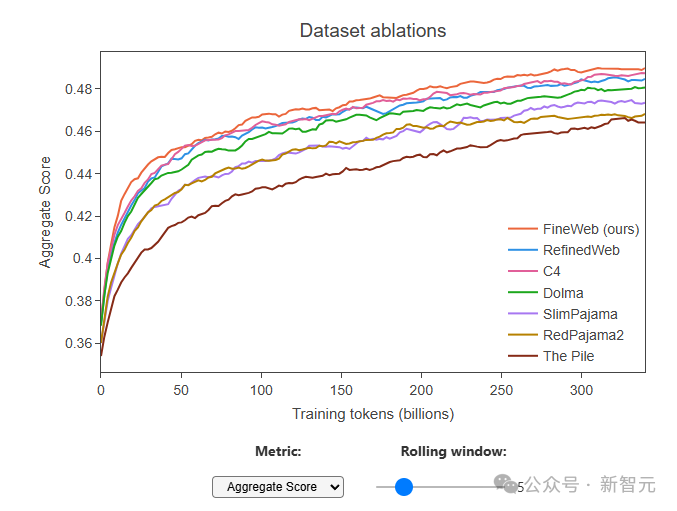
В дополнение к этому команда также выпустила FineWeb-Edu, который был разработан с использованием нового подхода, использующего синтетические данные для разработки классификаторов для идентификации образовательного контента.
Для сферы образования, добавив аннотации к рейтингам качества образования и добавив отдельную систему оценки, исследователи создали эффективный классификатор, который может идентифицировать и фильтровать контент, имеющий образовательную ценность, в крупномасштабных наборах данных.
FineWeb-Edu достигает значительных улучшений в образовательных тестах, таких как MMLU, ARC и OpenBookQA, превосходя FineWeb и все другие открытые наборы веб-данных.
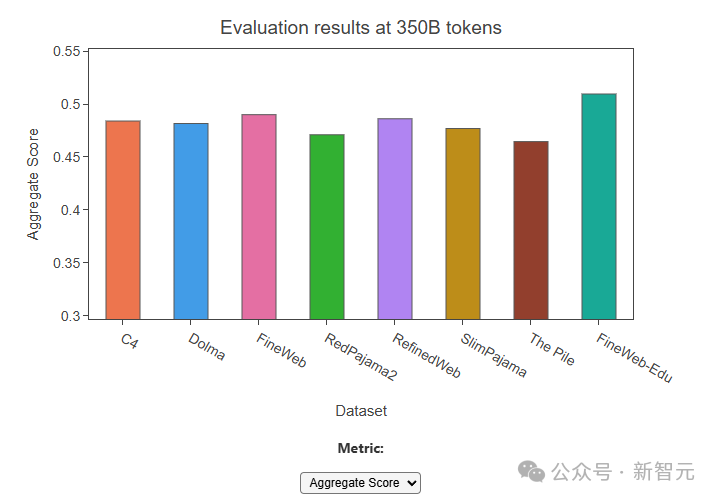
В то же время создание FineWeb-Edu также доказывает эффективность классификатора, обученного с использованием аннотаций LLM, в крупномасштабной Фильтрации данных.
В конце технического отчета исследователи выразили надежду и дальше раскрывать «черный ящик» высокопроизводительного обучения моделям большого языка и дать возможность каждому тренеру моделей создавать самые передовые LLM.
Они также надеются применить опыт FineWeb и изучить другие неанглийские языки, чтобы можно было легче получать высококачественные многоязычные сетевые данные.
Ссылки:
https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
