Выбор технологии структуры озера данных — Hudi, Delta Lake, Iceberg и Paimon.
Концепция озера данных
1. Что такое озеро данных?
озеро данныхэто централизованный репозиторий,Позволяет хранить все структурированные и неструктурированные данные из нескольких источников в любом масштабе.,Данные могут храниться как есть,Нет необходимости структурировать данные,и запускать различные типы анализа данных.,Например:большие данныеиметь дело с、анализ в реальном времени、машинное обучение,руководство для принятия более эффективных решений.
2. Почему большим данным необходимо озеро данных?
Текущее автономное хранилище данных, основанное на Hive, очень зрелое. Обновление данных на уровне записей в традиционных автономных хранилищах данных требует полного охвата всего раздела, которому принадлежат обновленные данные, или даже всей таблицы. При проектировании многоуровневой и послойной архитектуры автономного хранилища данных обновления данных также должны отражаться слой за слоем, начиная с исходного уровня, и отражаться в последующих производных таблицах.
вместе срасчет в реальном времениМеханизм продолжает развиваться, и потребности бизнеса в выводе отчетов в режиме реального времени продолжают расширяться.,В последние годы отрасль уделяет особое внимание созданию хранилищ данных реального времени и изучает возможности их создания. В соответствии с процессом эволюции архитектуры хранилища данных,Архитектура Lambda содержит два канала: автономную обработку и обработку в реальном времени.,Его архитектурная схема выглядит следующим образом:
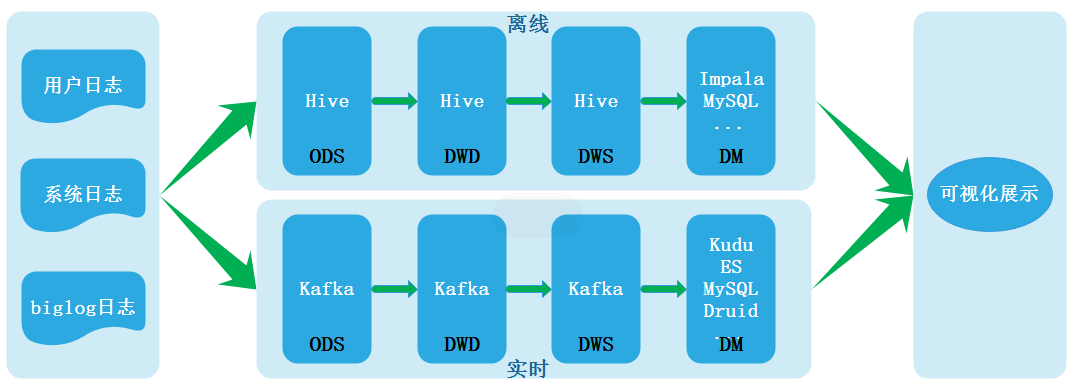
Именно из-за ряда проблем, таких как несогласованность данных, вызванная двумя ссылками, обрабатывающими данные, создается архитектура Каппа. Архитектура Каппа выглядит следующим образом:
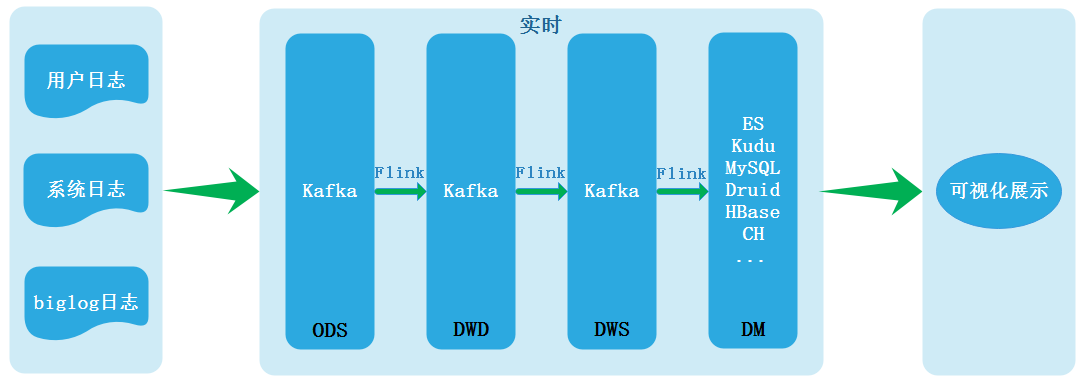
Архитектуру Kappa можно назвать настоящим хранилищем данных реального времени. В настоящее время наиболее часто используемой реализацией в отрасли является Flink + Kafka. Однако решение хранилища данных реального времени на основе Kafka + Flink также имеет несколько весьма очевидных недостатков. Поэтому многие компании в настоящее время создают хранилища данных реального времени, в Интернете часто используется гибридная архитектура, и все сервисы не реализуются с использованием обработки в реальном времени в архитектуре Kappa. Недостатки архитектуры Каппы заключаются в следующем:
- KafkaНевозможно поддерживать массовыехранение данных。Для бизнес-направлений с большими объемами данных,Kafka обычно может хранить данные только в течение очень короткого периода времени.,Например, за прошедшую неделю,Даже совсем недавно, в один прекрасный день.
- KafkaНевозможно поддерживать эффективнуюOLAPЗапрос,Большинство компаний надеются поддерживать специальные запросы на уровне DWD\DWS.,Но Кафка не может очень дружелюбно поддержать такие потребности.
- Невозможно повторно использовать и без того очень зрелую систему управления происхождением данных и качеством данных, основанную на автономных хранилищах данных. Необходимо заново внедрить систему управления происхождением данных и качеством данных.
- Kafka не поддерживает обновление/обновление. В настоящее время Kafka поддерживает только добавление.
Для решения проблем архитектуры Kappa наиболее распространенным методом в отрасли является использование подхода «пакетно-потоковой интеграции». Здесь пакетно-потоковую интеграцию можно понимать как одну и ту же обработку пакетно-потоковой обработки с использованием SQL. или это также можно понимать как унификацию инфраструктур обработки, таких как Spark, Flink. Но что здесь более важно, так это унификация уровня хранения. Пока уровень хранения является «интегрированным пакетным потоком», различные. проблемы, с которыми сталкивается Каппа, могут быть решены. Технология озера данных вполне может обеспечить «интеграцию пакетных потоков» на уровне хранения, поэтому озера данных необходимы в больших данных.
3. Разница между озером данных и хранилищем данных
Основные различия между хранилищем данных и озером данных заключаются в следующих двух моментах:
- Тип данных хранилища
Хранилище данных хранит данные и выполняет моделирование, а также хранит структурированные данные; озеро данных сохраняет большой объем исходных данных в исходном формате, включая структурированные, полуструктурированные и неструктурированные данные, в основном состоящие из исходных, состоящих из беспорядочных, неструктурированных данных. . Структуры данных и требования не определяются до тех пор, пока данные не потребуются.
- Режим обработки данных
Прежде чем мы сможем загрузить данные в хранилище данных, нам сначала необходимо определить их, что называется схемой при записи. Используя озеро данных, вы просто загружаете необработанные данные, а затем, когда будете готовы использовать данные, вы даете им определение, которое называется Schema-On-Read. Это два совершенно разных подхода к обработке данных. Поскольку озеро данных переопределяет структуру модели при использовании данных, оно повышает гибкость определения модели данных и может удовлетворить требования к высокоэффективному анализу большего количества различных предприятий верхнего уровня.
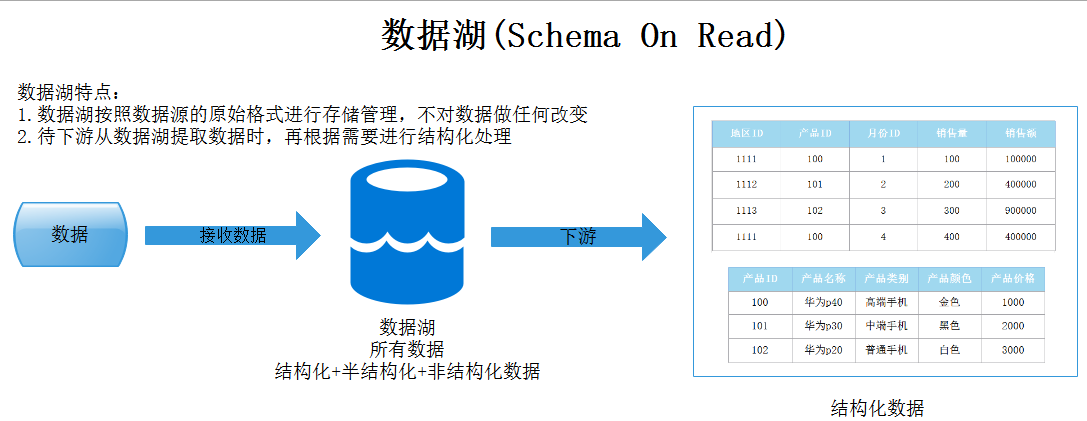

Все вышеперечисленные концепции взяты из: https://cloud.tencent.com/developer/article/2010793
Hudi
Официальное представление сайта Hello from Apache Hudi | Apache Hudi
What is Apache Hudi Apache Hudi (pronounced “hoodie”) is the next generation streaming data lake platform. Apache Hudi brings core warehouse and database functionality directly to a data lake. Hudi provides tables, transactions, efficient upserts/deletes, advanced indexes, streaming ingestion services, data clustering/compaction optimizations, and concurrency all while keeping your data in open source file formats
Delta Lake
Официальное представление сайта: Home | Delta Lake
Delta Lake is an open-source storage framework that enables building a Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, and Hive and APIs for Scala, Java, Rust, and Python.
Iceberg
Официальное представление сайта: Apache Iceberg - Apache Iceberg
What is Iceberg? Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
Apache Paimon
Официальное представление сайта: Apache Paimon™
A lake format that enables building a Realtime Lakehouse Architecture with Flink and Spark for both streaming and batch operations. Innovatively combines lake format and LSM structure, bringing realtime streaming updates into the lake architecture
от Официальное представление сайт Глядя на это, я растеряюсь, озеро данные — это формат хранения данных, такой же, как Delta. Знакомство с озером Платформа хранения данных с открытым исходным кодом. Является ли озеро данных действительно просто средой хранения? Используется для хранения структурированных и неструктурированных данных, что и HDFS Какая разница?
Hudi, Delta Lake, Iceberg и Paimon — это не просто промежуточные уровни хранения данных. Это инструменты управления и обработки данных, построенные на существующем озере данных и предоставляющие ряд функций и возможностей, включая управление версиями данных, запись транзакций, управление метаданными, данными. гарантия целостности и т. д. Их можно интегрировать с различными системами хранения (такими как HDFS, S3 и т. д.) для управления данными в озерах данных.
Эти инструменты обычно используют один или несколько форматов файлов для хранения данных, но они более оптимизированы для управления данными и их обработки в озерах данных, обеспечивая лучшее управление данными, производительность запросов, гарантию согласованности и другие функции. Таким образом, их можно рассматривать как усовершенствование озер данных, а не просто формат файла или средний уровень хранилища.
Вот краткое введение в эти инструменты:
Apache Hudi: Hudi — это инструмент озера данных с открытым исходным кодом для поэтапной обработки данных. Он поддерживает такие операции, как обновление, вставка и удаление данных, а также предоставляет такие функции, как путешествие во времени (запрос временной шкалы).
Delta Lake: Delta Lake — это уровень хранения с открытым исходным кодом, разработанный Databricks. Он построен на Apache Spark и используется для управления данными в крупномасштабных озерах данных. Он обеспечивает транзакции ACID, управление версиями данных, гарантию согласованности данных и другие функции.
Apache Iceberg: Iceberg — это формат таблиц данных с открытым исходным кодом и инструмент управления, разработанный Netflix. Он предназначен для обеспечения контроля версий данных, согласованности данных, записи транзакций и других функций и совместим с различными системами хранения (такими как HDFS, С3).
Paimon:PaimonЭто с открытым исходным кодомозеро данных管理平台,Предназначен для решения задач управления озером данных.,В том числе по качеству данных, Управление метаданными、управление даннымиТакие проблемы, как。
Цель этих инструментов — предоставить более полную информацию.озеро данных Решение,Путем расширения возможностей управления и обработки данных,улучшатьозеро Доступность, надежность и эффективность данных.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
