Введение в серию «Последний выпуск» — Автоматическое тестирование Python+Playwright — 52-строчные операции — Следующая глава
1. Введение
Делая утверждения в ежедневной работе по автоматизированному тестированию, мы часто можем столкнуться со сценариями. Найдите набор чисел или определенные ключевые слова в строке вместо того, чтобы утверждать строку как результат. На данный момент нам нужно работать со строкой. Брат Хонг представляет здесь два метода: обычный метод и функцию разделения строки (split()).
2. Тестовый сценарий
Брат Хун расскажет здесь о своей бессмысленной тестовой сцене, это только для обучения и справки. Затем проведите автоматическое тестирование, как сказал брат Хун. Тестовый сценарий: Найдите «Брат Пекин Хун» в Ду Нян или других поисковых системах. После завершения поиска результаты поиска будут возвращены и сообщат вам, сколько «Брат Пекин» было найдено. . Хун Гэ использует Sogou и Bing для поиска соответственно, а затем сравнивает, кто из них нашел больше «Пекин Хун Гэ», а затем использует сравнение, чтобы показать, чьи поисковые способности сильны (больше результатов поиска указывает на сильные поисковые способности).
3. Строковые регулярные операции
Что касается извлечения ключевых слов из этой строки с помощью регулярных выражений, брат Хонг подробно расскажет здесь о концепции регулярности. Если вам интересно, вы можете проверить это самостоятельно. Но тестовый сценарий, упомянутый выше братом Хонгом, требует этой операции (re.sub).
3.1 Регулярные выражения
Что такое регулярное выражение?
Регулярное выражение — это логическая формула, которая работает со строками (включая обычные символы (например, буквы от a до z) и специальными символами (называемыми «метасимволами»)), в которой используются некоторые предопределенные конкретные символы и комбинация этих конкретных символов. символы образуют «строку правила». Эта «строка правила» используется для выражения логики фильтрации строк. Регулярное выражение — это текстовый шаблон, описывающий одну или несколько строк, которые необходимо сопоставить при поиске текста.
Что могут регулярные выражения?
- Быстро и эффективно находите и анализируйте строки
- Регулярно ищите и сравнивайте строки,также называется:сопоставление с образцом
- Возможность поиска, сравнения, сопоставления, замены, вставки, добавления, удаления и т. д.
Строки — наиболее часто используемая структура данных в программировании, и необходимость работы со строками возникает практически везде. Например, когда мы пишем сканер для сбора данных, мы сначала получаем исходный код веб-страницы, но как нам извлечь действительные данные?
3.2re модуль
Регулярное выражение — это специальная последовательность символов, которая поможет вам легко проверить, соответствует ли строка определенному шаблону. Начиная с версии 1.5 в Python добавлен модуль re, который предоставляет шаблоны регулярных выражений в стиле Perl. Модуль re обеспечивает полную функциональность регулярных выражений в языке Python.
потому что Строки PythonТакже используется сам по себе\побег,Так что будьте особенными
s = 'ABC\\-001' # Строки Python
# Соответствующее регулярное строка выражения становится:
# 'ABC\-001'Поэтому рекомендуетсяделатьиспользоватьPythonизrпрефикс,Нет нужды рассматривать вопрос о побеге:
s = r'ABC\-001' # Строки Python
# Соответствующее регулярное строка выражения без изменений:
# 'ABC\-001'Коллекция символов модуля 3.3re
Шаблон регулярного выражения
Строки шаблонов используют специальный синтаксис для представления регулярного выражения:
Буквы и цифры представляют собой сами себя. Шаблон регулярного выражения, в котором буквы и цифры соответствуют одной и той же строке.
Большинство букв и цифр имеют другое значение, если им предшествует обратная косая черта.
Знаки препинания совпадают только в том случае, если они экранированы, в противном случае они имеют особое значение.
Саму обратную косую черту необходимо экранировать обратной косой чертой.
Поскольку регулярные выражения обычно содержат обратную косую черту, для их представления лучше использовать необработанные строки. Элементы шаблона (например, r'\t', эквивалентные \t) соответствуют соответствующим специальным символам.
В следующей таблице перечислены специальные элементы грамматики шаблона регулярного выражения. Если вы используете модель, указав необязательный параметр флага, значение некоторых элементов модели изменится.
модель | описывать |
|---|---|
^ | Соответствует началу строки |
$ | Соответствует концу строки. |
. | Соответствует любому символу, кроме символов новой строки. Если указан флаг re.DOTALL, может быть сопоставлен любой символ, включая символы новой строки. |
... | Используется для обозначения группы символов, перечисленных отдельно: amk соответствует «a», «m» или «k». |
^... | Символы, не входящие в []: ^abc соответствует символам, кроме a, b, c. |
re* | Соответствует 0 или более выражениям. |
re+ | Соответствует одному или нескольким выражениям. |
re? | Соответствует 0 или 1 фрагменту, определенному предыдущим регулярным выражением, нежадным способом. |
re{ n} | Сопоставьте n предыдущих выражений. Например, "o{2}" не может соответствовать "o" в слове "Bob", но может соответствовать двум "o" в слове "food". |
re{ n,} | Точно соответствует n предыдущим выражениям. Например, «o{2,}» не может соответствовать «o» в «Bob», но может соответствовать всем «o» в «foooood». «o{1,}» эквивалентно «o+». «o{0,}» эквивалентно «o*». |
re{ n, m} | Сопоставьте n и m раз фрагмент, определенный предыдущим регулярным выражением, жадный режим |
a|b | совпадение a или b |
(re) | Соответствует выражению в круглых скобках, также представляющему группу. |
(?imx) | Регулярные выражения содержат три необязательных флага: i, m или x. Влияет только на область в скобках. |
(?-imx) | Регулярное выражение отключает необязательные флаги i, m или x. Влияет только на область в скобках. |
(?: re) | Похож на (...), но не представляет группу |
(?imx: re) | Используйте дополнительные флаги i, m или x в скобках. |
(?-imx: re) | Не используйте дополнительные флаги i, m или x в скобках. |
(?#...) | Комментарий. |
(?= re) | Прямой положительный разделитель. Успешно, если содержащееся регулярное выражение, обозначаемое ... , успешно соответствует текущей позиции, в противном случае оно завершается неудачно. Но как только содержащееся выражение будет опробовано, механизм сопоставления вообще не улучшится; оставшейся части шаблона все равно придется проверять правую сторону разделителя. |
(?! re) | Разделитель прямого отрицания. Противоположно положительному разделителю; выполняется успешно, если содержащееся выражение не может быть сопоставлено в текущей позиции в строке. |
(?> re) | Сопоставление независимых шаблонов, исключающее возврат. |
\w | Сопоставление цифр, букв и подчеркиваний |
\W | Соответствует нецифровым буквам и подчеркиваниям. |
\s | Соответствует любому символу пробела, эквивалентному \t\n\r\f. |
\S | Соответствует любому непустому символу |
\d | Соответствует любому числу, эквивалентному 0–9. |
\D | Соответствует любому нечисловому значению |
\A | начало строки совпадения |
\Z | Соответствует концу строки. При наличии новой строки сопоставляется только конец строки перед новой строкой. |
\z | Конец строки соответствия |
\G | Сопоставьте позицию, в которой было завершено последнее совпадение. |
\b | Соответствует границе слова, которая представляет собой положение между словом и пробелом. Например, «er\b» соответствует «er» в слове «никогда», но не в слове «глагол». |
\B | Сопоставьте несловные границы. 'er\B' соответствует 'er' в слове "глагол", но не в слове "никогда". |
\n, \t и т. д. | Соответствует символу новой строки. Соответствует символу табуляции и т. д. |
\1...\9 | Сопоставьте содержимое n-й группы. |
\10 | Соответствует содержимому n-й группы, если оно соответствует. В противном случае это относится к выражению восьмеричного кода символа. |
Примечание: re в таблице относится к выражению, а не к буквальным двум буквам re.
Модификатор регулярного выражения – необязательные флаги
Регулярные выражения могут содержать некоторые необязательные модификаторы флагов для управления сопоставляемыми шаблонами. Модификатор указывается как необязательный флаг. Несколько флагов можно указать с помощью побитового ИЛИ(|). Например, re.I | re.M установлены флаги I и M:
модификатор | описывать |
|---|---|
re.I | Сделать совпадение нечувствительным к регистру |
re.L | Выполнять сопоставление с учетом локали |
re.M | Многострочное сопоставление влияет на ^ и $ |
re.S | Сделать . соответствовать всем символам, включая символы новой строки. |
re.U | Анализ символов в соответствии с набором символов Юникода. Этот флаг влияет на \w, \W, \b, \B. |
re.X | Этот флаг упрощает понимание регулярных выражений, предоставляя вам более гибкий формат. |
объект регулярного выражения
re.RegexObject
re.compile() возвращает объект RegexObject.
re.MatchObject
group() возвращает строку, соответствующую RE.
- start() возвращатьсясоответствоватьначинатьрасположение
- end() возвращатьсясоответствовать Заканчиватьрасположение
- span() Возвращает кортеж, содержащий совпадения (начало, конец) расположение
3.4 Распространенные методы ремоделирования
3.4.1re.match()
re.match пытается сопоставить шаблон с начала строки. Если совпадение в начале не удалось, match() возвращает none.
синтаксис функции:
re.match(pattern, string, flags=0)Описание параметра функции:
параметр | описывать |
|---|---|
pattern | Соответствие регулярному выражению |
string | Строка для сопоставления. |
flags | Бит флага, используемый для управления методом сопоставления регулярных выражений, например: учитывать ли регистр, многострочное сопоставление и т. д. См. таблицу дополнительных флагов выше. |
Метод re.match возвращает соответствующий объект, если сопоставление прошло успешно, в противном случае он возвращает None.
Пример и вывод:
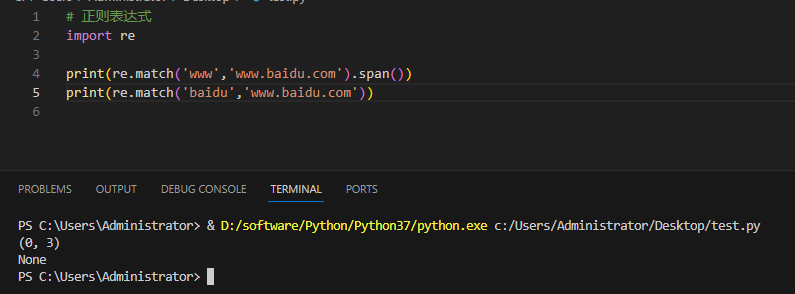
Первый матч успешен, второй провален
3.4.2re.search()
re.search сканирует всю строку и возвращает первое успешное совпадение.
Синтаксис функции:
re.search(pattern, string, flags=0)Описание параметра функции:
параметр | описывать |
|---|---|
pattern | Соответствие регулярному выражению |
string | Строка для сопоставления. |
flags |
Метод re.search возвращает соответствующий объект, если сопоставление прошло успешно, в противном случае он возвращает None.
Пример и вывод:
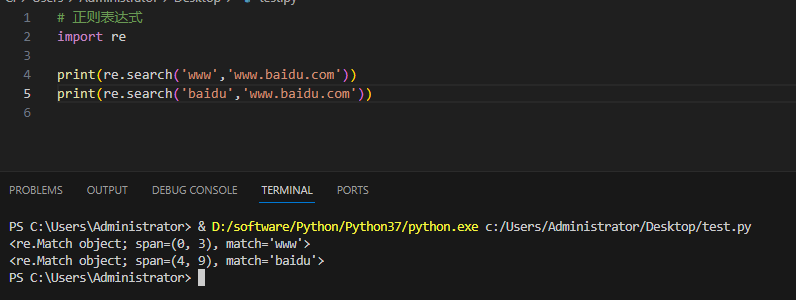
3.4.3 функция компиляции
Функция компиляции используется для компиляции регулярных выражений и создания объекта регулярного выражения (шаблона), который используется функцией re.
Предварительная компиляция может сократить время выполнения нескольких регулярных матчей.
Формат синтаксиса:
re.compile(pattern[, flags])параметр:
- шаблон: регулярное выражение в виде строки.
- флаги необязательны, указывающие на соответствие шаблону
3.4.4re.findall()
Найти все подстроки, соответствующие регулярному выражению в строке, и вернуть список. Если совпадений не найдено, возвращается пустой список.
Уведомление: match и search это совпадение findall Соответствует всем.
Использование 1
прямойделатьиспользоватьиз Формат синтаксиса:
re.findall(pattern, string, flags)параметр:
- регулярное выражение шаблона
- строка строка, подлежащая сопоставлению
- Некоторые флаги являются необязательными.
Пример и вывод:
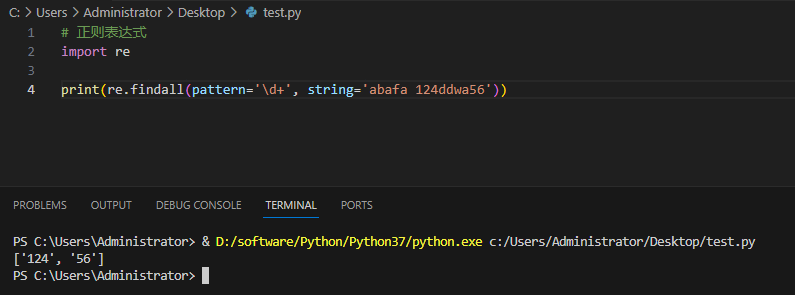
Использование 2
compileназадделатьиспользоватьfindallиз Формат синтаксиса:
re.findall(string, pos, endpos)параметр:
- строка строка, подлежащая сопоставлению。
- pos Необязательный параметр, указывает начальную позицию строки, значение по умолчанию: 0。
- endpos — необязательный параметр,Указывает конечную позицию строки,По умолчанию равна длине строки.
Пример и вывод:
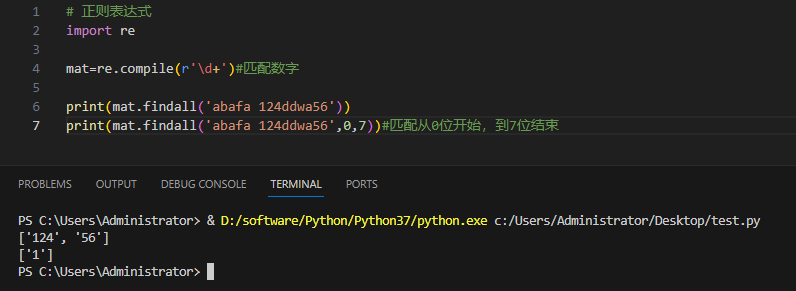
3.4.5re.finditer
и findall Аналогичным образом найдите в строке все подстроки, соответствующие регулярному выражению, и верните их в виде итератора.
re.finditer(pattern, string, flags=0)Пример и вывод:
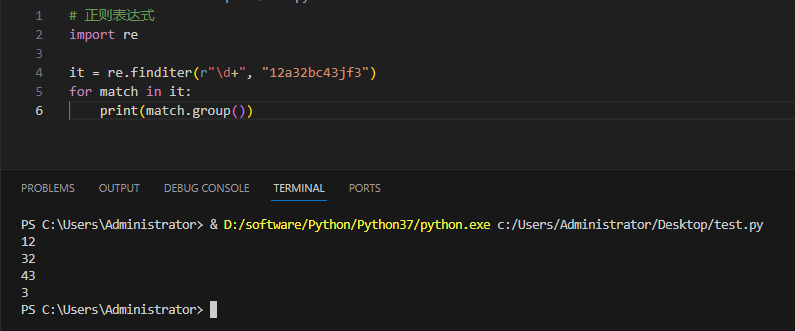
3.4.6re.split
Метод разделения разбивает строку в соответствии с совпадающими подстроками и возвращает список. Форма его использования следующая:
re.split(pattern, string[, maxsplit=0, flags=0])параметр:
параметр | описывать |
|---|---|
pattern | Соответствие регулярному выражению |
string | Строка для сопоставления. |
maxsplit | Количество разделений, maxsplit=1 отделяется один раз, значение по умолчанию — 0, количество раз не ограничено. |
flags |
Пример:
Использование регулярных выражений для разделения строк более гибкое, чем использование фиксированных символов. См. обычный код разделения:
>>> 'a b c'.split(' ')
['a', 'b', '', '', 'c']Обнаружив, что непрерывные пробелы не распознаются, попробуйте использовать регулярные выражения:
>>> re.split(r'\s+', 'a b c')
['a', 'b', 'c']Его можно разделить обычным способом, независимо от того, сколько в нем мест. присоединиться,Пытаться:
>>> re.split(r'[\s\,]+', 'a,b, c d')
['a', 'b', 'c', 'd']Присоединяйтесь снова;Пытаться:
>>> re.split(r'[\s\,\;]+', 'a,b;; c d')
['a', 'b', 'c', 'd']3.4.7groups()
Мы можем использовать функцию объекта сопоставления group(num) или groups(), чтобы получить соответствующее выражение.
Методы объекта соответствия | описывать |
|---|---|
group(num=0) | Соответствует строке всего выражения. group() может ввести несколько номеров групп одновременно, и в этом случае он вернет кортеж, содержащий значения, соответствующие этим группам. |
groups() | Возвращает кортеж, содержащий все строки группы, от 1 до номера группы, содержащегося в . |
Пример и вывод:
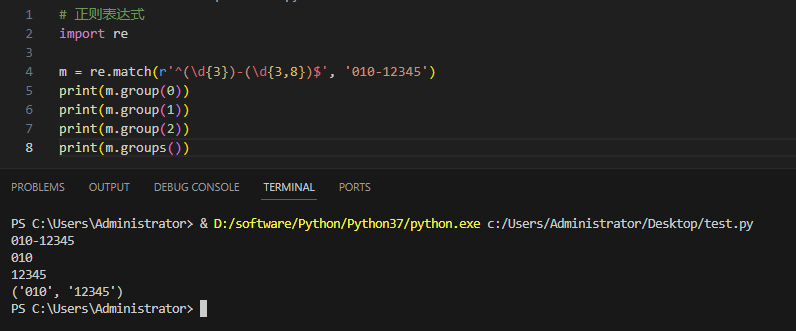
3.4.8re.sub
Модуль re Python предоставляет re.sub для замены совпадений в строке.
грамматика:
re.sub(pattern, repl, string, count=0, flags=0)параметр:
- шаблон: строка шаблона в регулярном выражении.
- repl: строка, которую необходимо заменить, или это может быть функция.
- строка: исходная строка для поиска и замены.
- count : сопоставление с Максимальное количество замен после образца, по умолчанию 0 Заменяет все совпадения.
- флаги: шаблон соответствия, используемый во время компиляции, в числовой форме.
Первые три параметра являются обязательными, а последние два — необязательными.
Пример и вывод:
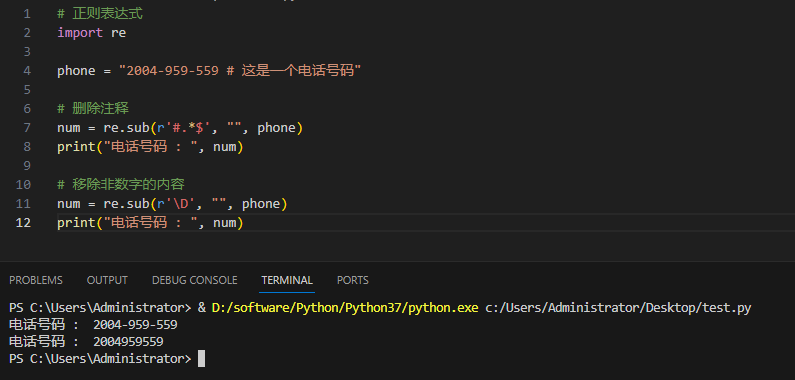
параметр repl может быть функцией
В следующем примере совпадающие числа в строке умножаются на 2:
Пример и вывод:
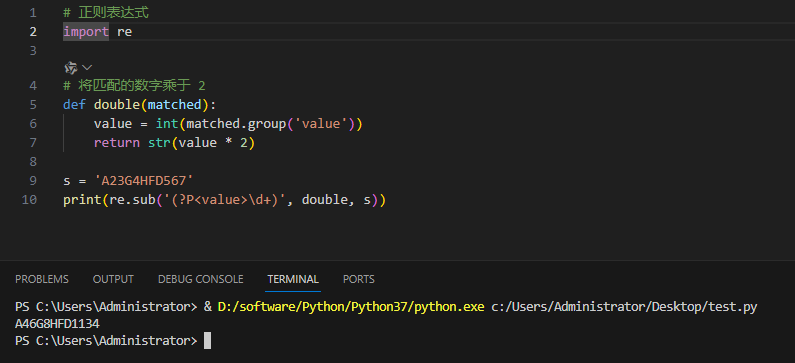
3.5 Жадное сопоставление
Следует отметить, что,обычныйсоответствовать По умолчанию жадныйсоответствовать,Это соответствует как можно большему количеству символов. Примеры следующие:,соответствовать Выясните цифрыназадлапшаиз0:
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')потому что\d+Выбиратьиспользоватьжадныйсоответствовать,прямой Пучокназадлапшаиз0всесоответствовать Понятно,результат0*может толькосоответствоватьпустая строка Понятно。
должен позволить\d+Выбиратьиспользовать非жадныйсоответствовать(То есть как можно меньшесоответствовать),才能Пучокназадлапшаиз0соответствоватьпублично заявить,Добавить один?Просто позволь\d+Выбиратьиспользовать非жадныйсоответствовать:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')3.6 Примеры регулярных выражений
3.6.1 Сопоставление символов
Пример | описывать |
|---|---|
python | Соответствует «питону». |
3.6.2 Класс символов
Пример | описывать |
|---|---|
Ppython | Соответствует «Python» или «python». |
rubye | Соответствует «рубину» или «рубе». |
aeiou | Сопоставьте любую букву в квадратных скобках |
0-9 | Соответствует любому числу. Похоже на: 0123456789 |
a-z | Соответствует любой строчной букве |
A-Z | Соответствует любой заглавной букве |
a-zA-Z0-9 | Сопоставьте любые буквы и цифры |
^aeiou | Все символы, кроме букв aeiou |
^0-9 | Соответствует символам, кроме цифр. |
3.6.3 Классы специальных символов
Пример | описывать |
|---|---|
. | Соответствует любому одиночному символу, кроме "\n". Чтобы сопоставить любой символ, включая «\n», используйте шаблон, например «.\n». |
\d | Соответствует цифровому символу. Эквивалент 0-9. |
\D | Соответствует нечисловому символу. Эквивалент ^0-9. |
\s | Соответствует любому пробельному символу, включая пробелы, табуляцию, каналы форм и т. д. Эквивалентно \f\n\r\t\v. |
\S | Соответствует любому символу без пробелов. Эквивалентно ^ \f\n\r\t\v. |
\w | Соответствует любому символу слова, включая подчеркивание. Эквивалентно «A-Za-z0-9_». |
\W | Соответствует любому символу, не являющемуся словом. Эквивалентно '^A-Za-z0-9_'. |
4. Проект реального боя
4.1 Тестовые примеры
Сначала брат Хун разработал тестовые примеры в соответствии со сценарием тестирования следующим образом:
1. Найдите «Пекин Хонге» в полях поиска Sogou и Bing соответственно.
2. Нажмите «Запрос» соответственно и просмотрите результаты запроса.
3. Получите результаты запроса отдельно
4. Извлеките числа из результата и сохраните их в переменных.
5. Сравните размер двух чисел
4.2 Разработка кода
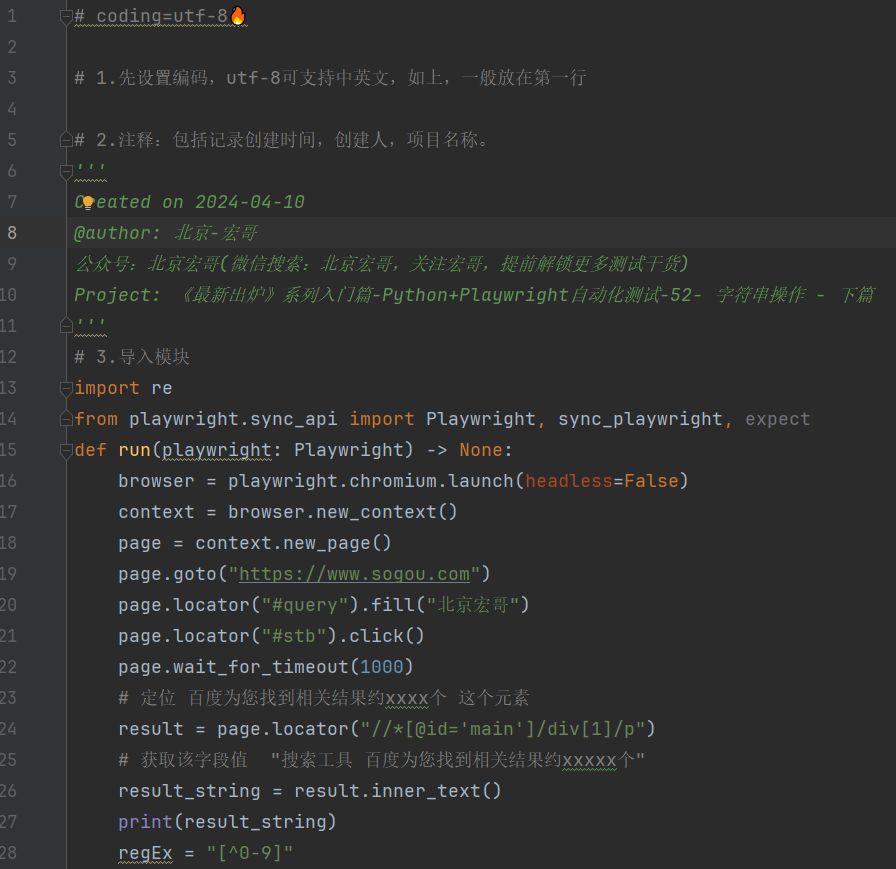
4.3 Справочный код
# coding=utf-8🔥
# 1. Сначала установите кодировку UTF-8, которая поддерживает китайский и английский языки, как указано выше, обычно они располагаются в первой строке.
# 2. Примечания: включая время создания записи, автора и название проекта.
'''
Created on 2024-04-10
@author: Пекин-Хонге
Публичный аккаунт: Beijing Hongge (поиск WeChat: Beijing Hongge, фокус на Брат Хун, разблокируй больше тестовых вещей заранее)
Project: Введение в серию «Последний выпуск» — Автоматическое тестирование Python+Playwright — 52-строчные операции — Следующая глава
'''
# 3. Импортировать модули
import re
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.sogou.com")
page.locator("#query").fill("Пекин Хонге")
page.locator("#stb").click()
page.wait_for_timeout(1000)
# позиция Согоу нашел около xxxx результатов, связанных с приездом для вас. этот элемент
result = page.locator("//*[@id='main']/div[1]/p")
# Получить значение поля «Инструмент поиска Согоу нашел около xxxx результатов, связанных с прибытием для вас"
result_string = result.inner_text()
print(result_string)
regEx = "[^0-9]"
search_number = re.sub(regEx,"", result_string)
print(search_number)
page.goto("https://cn.bing.com")
page.locator("#sb_form_q").fill("Пекин Хонге")
page.locator("#search_icon").click()
page.wait_for_timeout(1000)
# позиция Bing имеет результаты xxxx этот элемент
result1 = page.locator("//*[@id='b_tween_searchResults']/span")
# Получить значение поля "о xxx результаты"
result_string1 = result1.inner_text()
print(result_string1)
st2 = re.sub(regEx, "",result_string1)
print(st2)
# Сначала преобразуйте оба числа в int данные
a_N = int(search_number)
b_N = int(st2)
# Сравнение результатов поиска Sogou и Bing
if (a_N > b_N):
print("Сого потрясающий, Сого сильный!!!")
else:
print("Bing потрясающий, Bing могучий!!!");
page.wait_for_timeout(20000)
page.close()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)4.4 Запуск кода
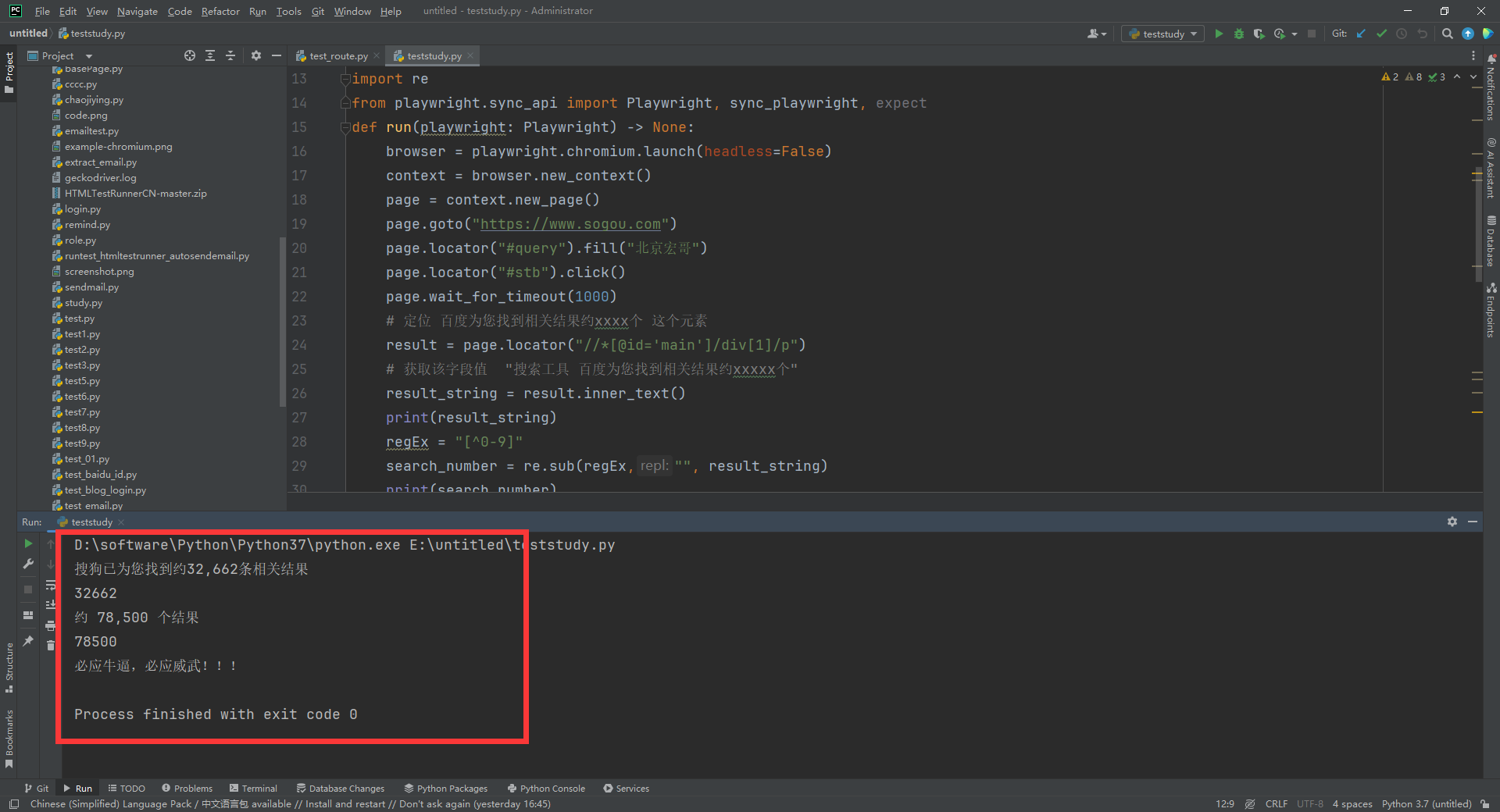
1. Запустите код, щелкните правой кнопкой мыши «Выполнить тест», и вы увидите вывод консоли, как показано ниже:
2. Действия браузера на компьютере после запуска кода. Как показано ниже:
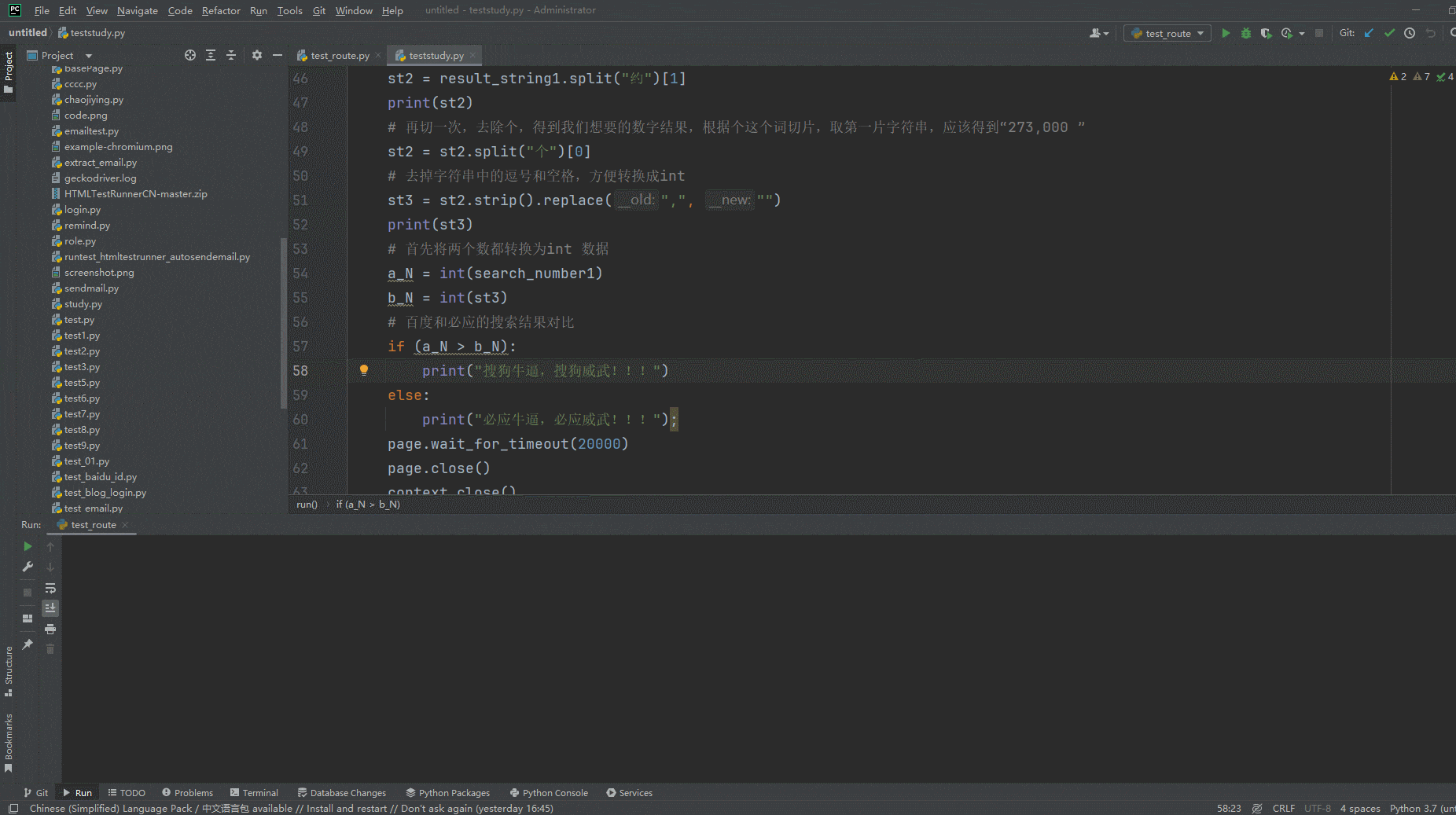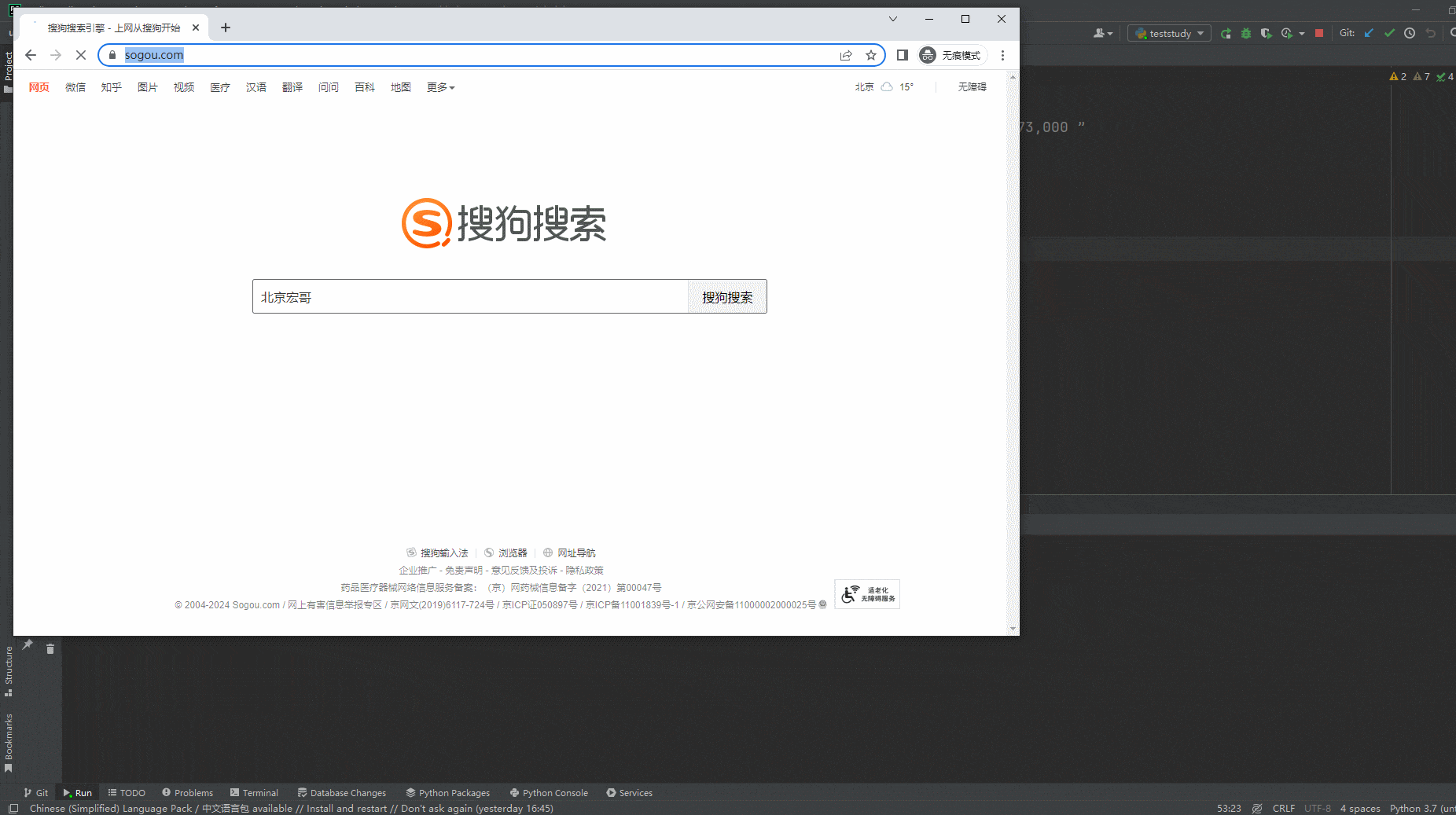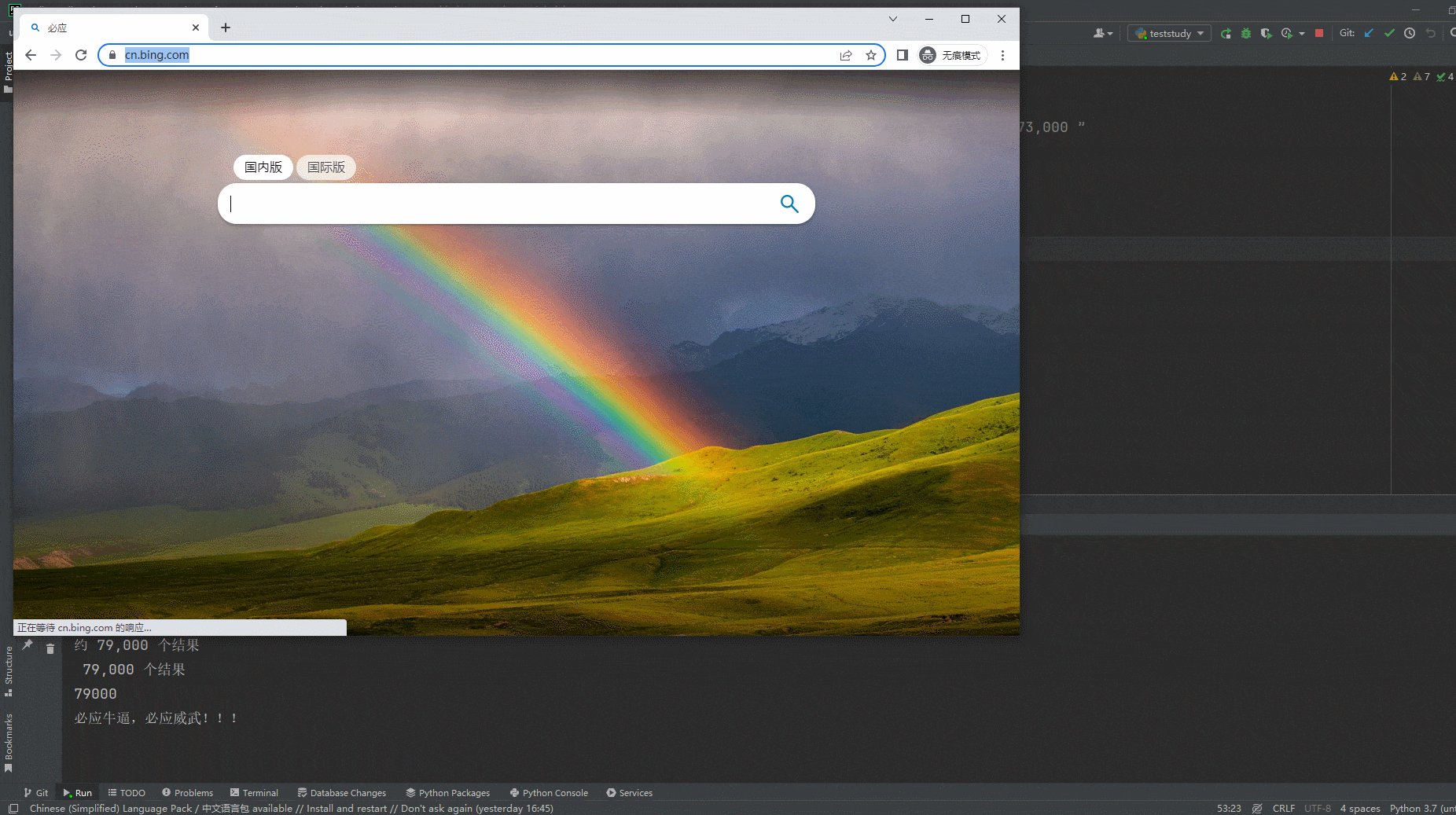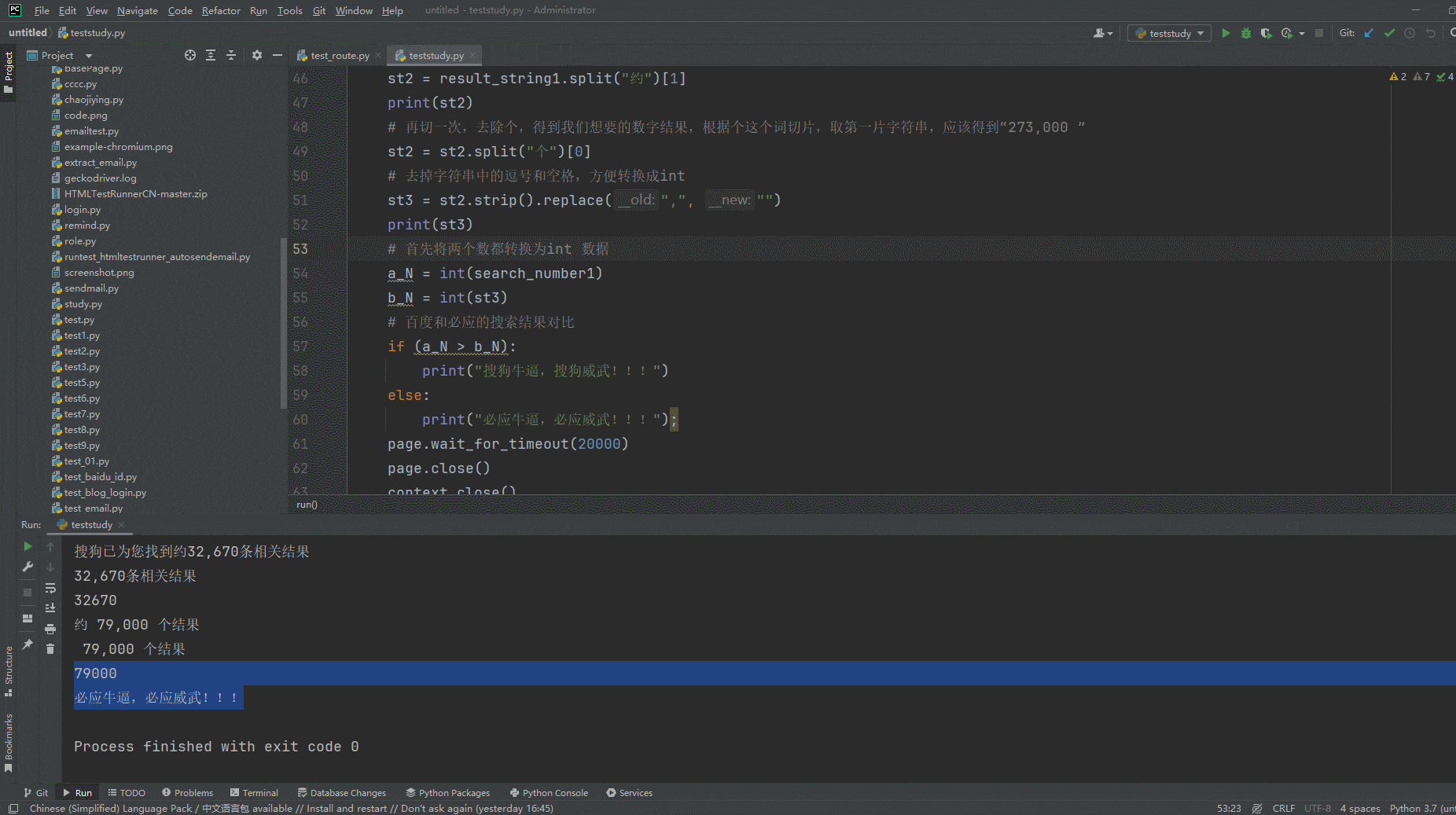
5. Резюме
Хорошо, брат Хун представил здесь работу со строками. На самом деле, у этих двух методов есть свои преимущества. Если один из них не подходит или сложен в использовании, вы можете попробовать другой метод, возможно, он окажется успешным. Не попадайте в неприятности и идите до конца. Еще есть синтаксис регулярных выражений. Проверьте сами и посмотрите. Освоить его можно почти за полчаса. Потом надо уделить внимание практике, иначе после еды забудешь.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
