Введение в распределенную базу данных HBase
Один、Простойпредставлять
HBase — это высоконадежная, высокопроизводительная, столбцово-ориентированная, масштабируемая, распределенная база данных NOSQL для чтения и записи в реальном времени.
Используйте Apache HBase, когда вам нужен произвольный доступ для чтения и записи к большим данным в режиме реального времени.
эффект:В основном используется для хранения неструктурированных、Полуструктурированные и структурированные из свободных данных (столбцовое хранилище из данных базы NoSQL)
Объяснение имени:
- NameSpace Пространство имен, эквивалентное реляционной базе данных В базе данных есть несколько таблиц в каждом пространстве имен. Hbase Пространство имен по умолчанию hbase и default;hbase хранится в HBase Встроенная таблица, по умолчанию Пространство имен, используемое пользователями по умолчанию.
- Region Таблицы аналогичны реляционным базам данных, за исключением того, что HBase Определение означает, что необходимо объявить только семейство столбцов и не нужно объявлять какие-либо конкретные столбцы. Столбцы можно указывать динамически по мере необходимости HBase; Больше подходит для сценариев, в которых поля часто меняются. Для начала создания таблицы одной таблице соответствует одна регион, когда таблица увеличится до определенного значения, она будет разделена на две части region。
- Row HBase Каждая строка данных в таблице называется ряд, состоит из RowKey Несколько Column Состав, данные основаны на RowKey хранятся в словарном порядке, а запросы могут основываться только на RowKey выполнить поиск, так что RowKey Дизайн имеет решающее значение.
- Column Столбцы состоят из семейств столбцов (Колонка Family) и квалификатор столбца (Column Классификатор), например: база: имя, база: пол. Это означает, что необходимо определить только семейство столбцов, а квалификатор столбца не нужно определять заранее.
- Cell Столбец в строке называется Ячейка (ячейка), состоящая из {rowkey, столбец Family:columnqualifier,timestamp} определяет единицу измерения. Клетка В нем нет определенного типа, все хранится в виде байт-кода (массива байтов).
- TimeStamp Используется для идентификации различных версий данных. При записи каждого фрагмента данных, если метка времени не указана, система автоматически добавит к нему это поле с записанным значением. HBase время.
2. Модель данных HBase
Логически модель данных HBase очень похожа на реляционную базу данных. Данные хранятся в таблице со строками и столбцами. Но с точки зрения базовой физической структуры хранения (ключ-значение) HBase больше похож на карту.
Логическая структура HBase следующая:
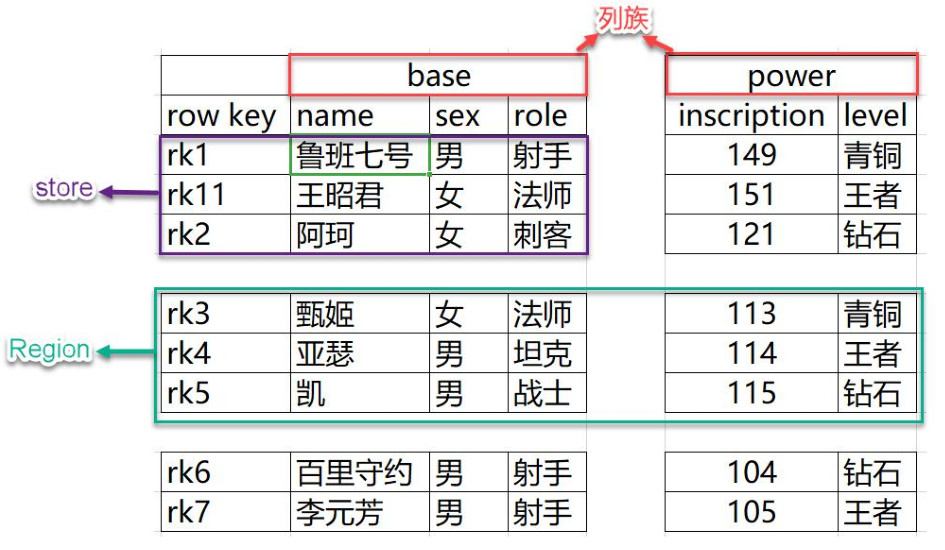
Физическая структура хранения HBase
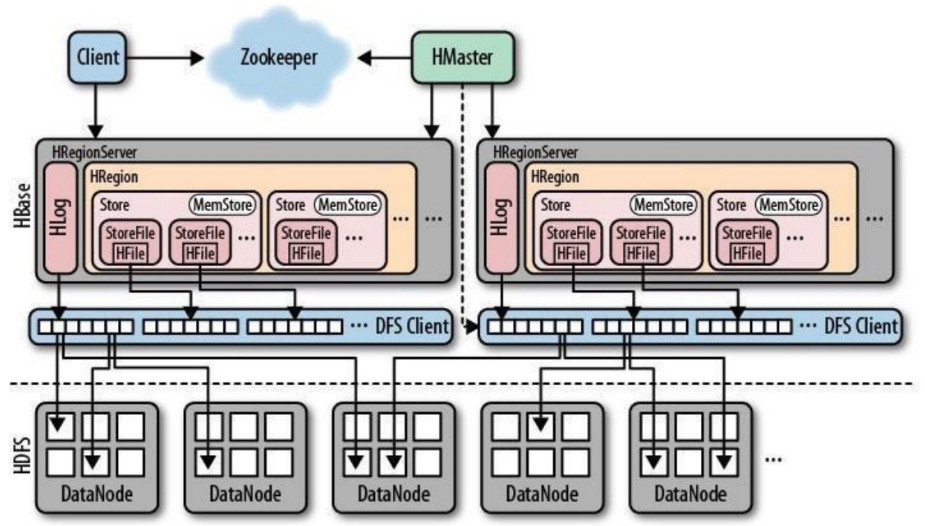
3. Архитектура HBase
- client
1) Содержит интерфейс для доступа к HBase для доступа к HBase 2) Клиент получает информацию о кластере HBase, запрашивая информацию в Zookeeper.
- zookeeper
1) Убедитесь, что в кластере всегда есть только один мастер. 2) Сохраните записи адресации всех регионов. 3) Отслеживайте онлайн- и оффлайн-информацию RegionServer в режиме реального времени и уведомляйте HMaster в режиме реального времени. 4) Сохраните схему HBase и метаданные таблицы.
- Master
1) Назначьте регион RegionServer 2) Отвечает за балансировку нагрузки RegionServer. 3) Обнаружьте неисправный RegionServer и перераспределите на нем регионы. 4) Управляйте операциями пользователей по добавлению, удалению и изменению таблиц.
- RegionServer
1) RegionServer поддерживает регионы и обрабатывает запросы ввода-вывода к этим регионам. 2) RegionServer отвечает за разделение Региона, который в процессе работы становится слишком большим.
- HLog(WAL Log)
1) Файл HLog — это обычный файл последовательности Hadoop. Ключ файла последовательности — это объект HLogKey. HLogKey записывает информацию о владельце записанных данных. Помимо имен таблиц и регионов, он также включает порядковый номер и. timestamp. Временная метка — «запись «Введите время», начальное значение порядкового номера — 0 или последний порядковый номер, сохраненный в файловой системе. 2) Значением HLog SequenceFile является объект KeyValue HBase, который соответствует KeyValue в HFile.
- Region
1) HBase автоматически делит таблицу на несколько регионов (регионов) по горизонтали. Каждый регион сохраняет в таблице определенный фрагмент непрерывных данных. Каждая таблица имеет только один регион в начале. Поскольку данные в таблицу непрерывно вставляются, это регион. продолжает расти, когда он достигнет порога, Регион будет разделен на два новых Региона (деление). 2) По мере увеличения строк в таблице Регионов будет все больше и больше. Такая полная таблица сохраняется на нескольких серверах региона.
- Memstore&StoreFile
1) Регион состоит из нескольких магазинов, и один магазин соответствует одному CF (семейству столбцов) 2) Store включает в себя memstore, расположенный в памяти, и storefile, расположенный на диске. Операция записи сначала записывается в Memstore. Когда данные в Memstore достигают определенного порога, HRegionserver запускает процесс flashcache для записи в файл хранилища. Каждая запись формирует отдельный файл хранилища. 3) StoreFile доступен только для чтения и не может быть изменен после создания. Таким образом, обновление Hbase на самом деле представляет собой непрерывную операцию добавления. Когда количество файлов Storefile в Магазине увеличивается до определенного порога, система объединяется (незначительное, крупное сжатие). В процессе слияния будет выполняться объединение и удаление версий (majar), а также будут вноситься изменения в один и тот же ключ. объединены вместе, образуя больший файл хранилища. 4) Когда сумма размеров всех файлов хранилища в регионе превышает определенный порог, текущий регион будет разделен на два и распределен hmaster на соответствующий сервер региона для достижения балансировки нагрузки. 5) Когда клиент получает данные, он сначала ищет их в хранилище памяти, а затем ищет файл хранилища, если не может его найти. 6) HRegion — наименьшая единица распределенного хранилища и балансировки нагрузки в HBase. Наименьшая единица означает, что разные HRegions могут быть распределены на разных серверах HRegionServer. 7) HRegion состоит из одного или нескольких магазинов, в каждом магазине хранится семейство столбцов. 8) Каждое хранилище состоит из memStore и от 0 до нескольких StoreFiles.
4. Процесс записи HBase
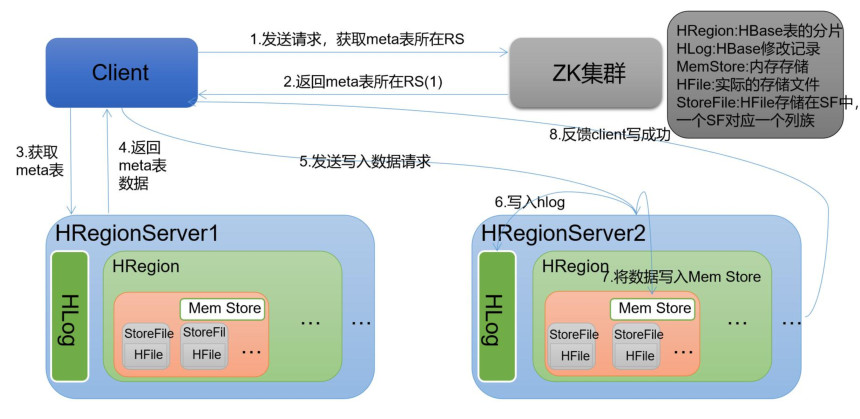
1. Клиент отправляет запрос на получение адреса HMaster и адреса RegionServer, где находится метатаблица, от Zookeeper, а также отправляет запрос на запись данных на HRegionServer.
2. Данные записываются в MemStore HRegion, а также в HLog.
3. Данные из MemStore сбрасываются в StoreFile.
4. Когда MemStore достигает порогового значения, данные сбрасываются в файл хранилища. Когда несколько файлов StoreFile достигают определенного размера, запускается операция компактного слияния. После сжатия постепенно формируется все больший и больший файл хранилища.
5. После того, как размер StoreFile превысит определенный порог, запускается операция разделения, которая разделяет текущий HRegion на 2 новых HRegion. Родительский HRegion будет отключен, а 2 дочерних HRegion из нового разделения будут выделены соответствующему HRegionServer. HMaster, чтобы исходное 1 Давление одного HRegion можно было распределить на два HRegion.
6. Если данные в MemStore утеряны, их можно восстановить из HLog.
5. Процесс чтения HBase
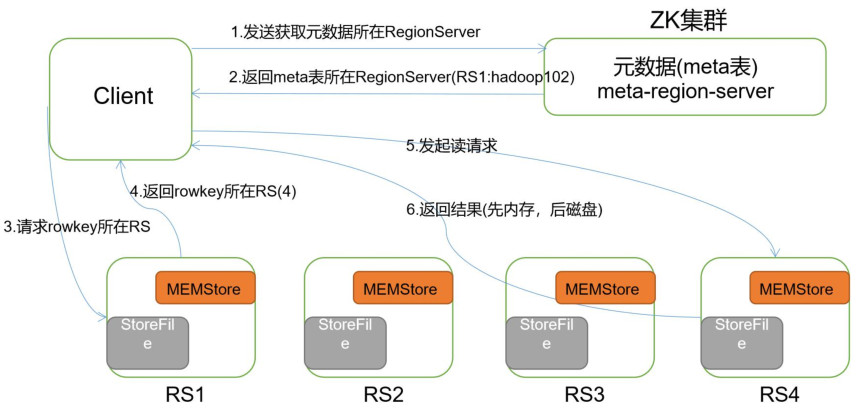
1. Клиент сначала находит местоположение региона метатаблицы у Zookeeper, а затем считывает данные в метатаблице. Мета хранит информацию о регионе пользовательской таблицы.
2. Найдите информацию о регионе, для которого записаны данные, согласно данным в метатаблице на основе пространства имен, имени таблицы и ключа строки.
3. Найдите соответствующий RegionServer, найдите соответствующий Region, сначала найдите данные из Memstore, а если нет, прочтите данные из StoreFile.
6. Мелкое и крупное слияние HBase
Когда клиент записывает данные в HBase, они сначала записываются в HLog и Memstore. В хранилище, когда память Memstore заполнена, данные будут записаны на диск для формирования нового файла хранения данных (StoreFile With the memstore). При перепрошивке будет создано множество файлов хранилища. Когда файлы хранилища в хранилище достигнут определенного порога, изменения одного и того же ключа будут объединены в один большой файл хранилища. Наконец, когда размер файла хранилища достигнет определенного порога. , файл хранилища будет разделен на два файла хранилища.
Поскольку обновления в таблицу постоянно добавляются, при слиянии вам необходимо получить доступ ко всем файлам хранилища и хранилищам памяти в хранилище и объединить их по ключам строк. Поскольку файлы хранилища и хранилища памяти сортируются, а файлы хранилища имеют индексы в памяти, процесс слияния. относительно быстро.
Поскольку файл хранилища не может быть изменен, HBase не может просто удалить данные, удалив определенный ключ/значение. Вместо этого он ставит метку удаления на удаленные данные, чтобы указать, что данные были удалены. Во время процесса извлечения метка удаления закрывается. данные, клиент не может прочитать данные.
По мере того как данные в memstore продолжают записываться на диск, будут создаваться все новые и новые файлы storeFile, HBase внутренне решает эту проблему с небольшими файлами, объединяя несколько файлов в один файл большего размера. следует:
незначительное слияние
Незначительное слияние отвечает за объединение нескольких файлов StoreFile в Магазине. Когда количество файлов StoreFile достигает значения hbase.hstore.compaction.min (значение по умолчанию — 3), они будут объединены в один большой файл StoreFile. При таком слиянии несколько небольших файлов в основном перезаписываются в меньшее количество больших файлов, чтобы уменьшить количество хранимых файлов. Поскольку каждый файл в StoreFile классифицируется, скорость слияния очень высокая и в основном зависит от производительности дискового ввода-вывода.
крупное слияние
Перезапишите несколько небольших объединенных больших файлов StoreFile кластера столбцов (соответствующего Store) в регионе в новый StoreFile. Более того, основное слияние может сканировать все пары ключ/значение и перезаписывать все данные последовательно. В процессе перезаписи данные, помеченные для удаления, будут пропущены.
7. Метатаблица целевой таблицы HBase
Таблица каталога hbase:meta существует как таблица HBase и отфильтровывается из команд списка оболочки hbase (аналогично показу таблиц), но на самом деле это таблица, подобная любой другой таблице.
Таблица hbase:meta (ранее .META.) содержит список всех регионов в системе. Информация о местоположении hbase:meta хранится в Zookeeper, hbase:meta представляет собой точку входа для всех запросов.
Структура таблицы следующая:
key:
регионизключ, структура следующая: [таблица],[регион start key,end key],[region id]
values:
info:regioninfo (сериализация текущего региона из экземпляра HRegionInfo)
info:server (содержит текущий регионизRegionServerизserver:port)
info:serverstartcode (содержит текущий регион, процесс RegionServer, время запуска)Во время разделения таблицы создаются два дополнительных столбца с именами info:splitA и info:splitB, которые представляют два дочерних региона, и значения этих столбцов также являются сериализованными экземплярами HRegionInfo. Эта строка будет удалена после разделения региона.
a,,endkey
a,startkey,endkey
a,startkey,Пустой ключ используется для обозначения начала и конца таблицы. Регион с нулевым начальным ключом является первым регионом в таблице. Если регион имеет как нулевой начальный, так и нулевой конечный ключ, это единственный регион в таблице.
8. Возможности HBase
- Строго согласованное чтение/запись HBase, а не «конечно согласованная» база данных (DataStore). Он идеально подходит для таких задач, как высокоскоростное агрегирование счетчиков.
- Автоматическое шардинг: HBase стол пройден region распределены по кластеру, и по мере роста данных регионы Будет автоматически разделен и перераспределен. Автоматический RegionServer Аварийное переключение.
- Интеграция Hadoop/HDFS: HBase поддерживает HDFS в качестве распределенной файловой системы.
- MapReduce:HBase поддержка через MapReduce Выполните массовую параллельную обработку для HBase Использовать в качестве источника данных и сохранять хранилище данных из базы данных.
- Java Client API: HBase поддерживает простой в использовании Java API для программного доступа.
- Thrift/REST API:HBase Также поддерживает не- Java внешний интерфейс Thrift и REST。
- Кэш блоков и фильтр Блума: HBase Поддержка блочного кэша и фильтров Блума для оптимизации запросов большого объема.
- Управление эксплуатацией и техническим обслуживанием: HBase Предоставляет встроенные веб-страницы для мониторинга эксплуатации и технического обслуживания. JMX индекс.
- HBase не поддерживает межстрочные транзакции.
9. Сценарии использования HBase
HBase подходит для сценариев, требующих обработки огромных объемов данных и требующих высокой надежности и производительности. Например:
- хранилище объектов:например, новости、веб-страница、Изображения и другие данные сохраняются.
- Портрет пользователя:особенно пользователиизизображение,Это относительно большая разреженная матрица.
- Хранение сообщений/заказов:в сфере телекоммуникаций、В банковской сфере многие запросы заказов требуют базового хранилища и связи.、Приложения синхронизации сообщений могут быть созданы на базе HBase.
В целом HBase — это высокопроизводительная, высоконадежная и масштабируемая распределенная база данных, которая подходит для обработки огромных объемов неструктурированных или структурированных данных и может отвечать требованиям управления чтением и записью практически в реальном времени.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
