Введение в модель BGE M3-Embedding
BGE M3-Embedding разработан BAAI и Китайским университетом науки и технологий. Это модель BAAI с открытым исходным кодом. Соответствующий документ находится по адресу https://arxiv.org/abs/2402.03216. В документе предлагается новая модель внедрения под названием M3-Embedding, которая является многоязычной (многоязычность) и многофункциональной (отличная многофункциональность). производительность в мультигранулярности. M3-Embedding поддерживает более 100 рабочих языков, поддерживает входной текст длиной 8192, а также поддерживает плотный поиск (Dense Retrival), многовекторный поиск (Multi-Vector Retrival) и разреженный поиск (Sparse Retrival), обеспечивая поиск информации в реальном времени. world. (IR) обеспечивает унифицированную модельную основу, и за счет комбинации этих методов поиска достигаются хорошие смешанные эффекты отзыва.
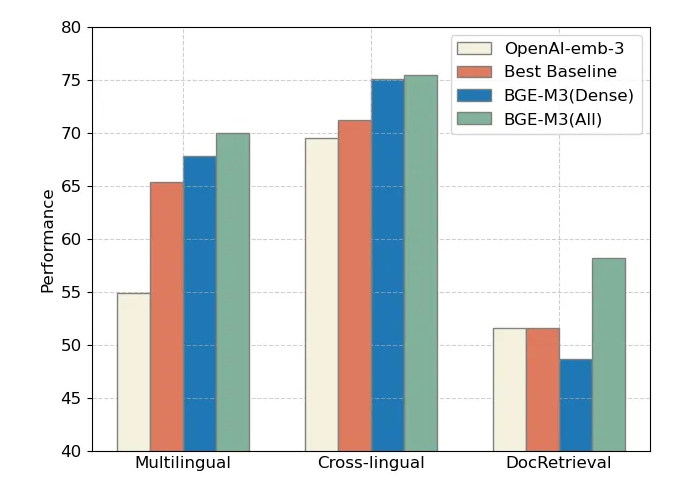
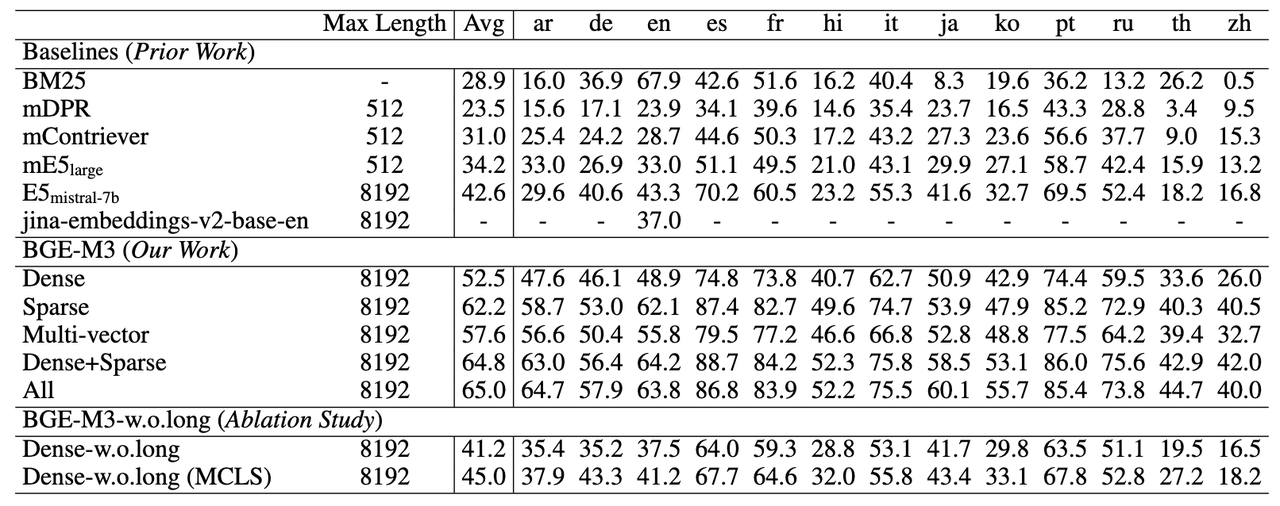
Мы можем проверить сравнение официальной модели и модели openai. В целом, BGE-M3 (ALL), который использует три метода совместного поиска, лидирует в трех оценках, в то время как плотный поиск BGE-M3 (плотный) работает лучше в многоязычных и межъязыковый поиск имеет очевидные преимущества.
Особенности модели BGE-M3
1. Многоязычность,Обучающий набор содержит более 100+ языков. 2. Многофункциональность,Поддержка плотного поиска (Dense Извлечение), также поддерживает разреженный поиск (Sparse Поиск) и многовекторный поиск (Multi-vector Retrieval) 3. Многоуровневая детализация BGE-M3 в настоящее время может обрабатывать максимальную длину 8192. входной текст, поддерживающий входной текст различной детализации, такой как «предложение», «абзац», «глава», «документ» и т. д.
Данные обучения BGE-M3
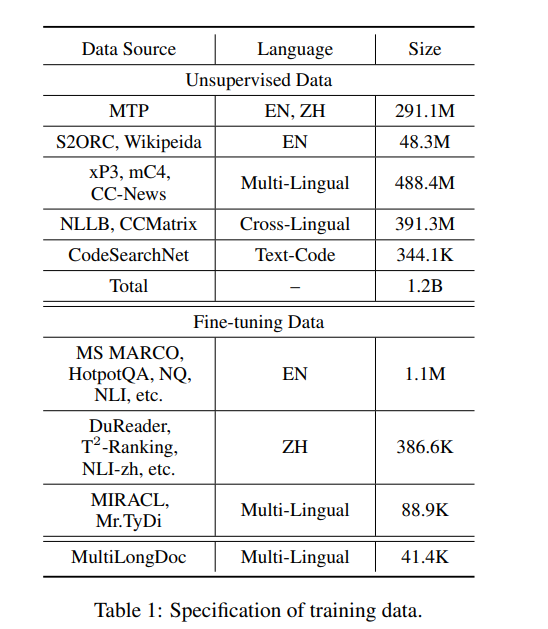
Состав обучающих данных модели M3-Embedding является ключевым инновационным моментом, который делает модель лучше, поскольку она предназначена для поддержки многоязычности, многофункциональности и многогранности. Данные обучения разделены на три части:
- Неконтролируемые данные:
- Извлечение неразмеченного текста из больших многоязычных корпусов данных.,К таким корпусам относятся Wikipedia, S2ORC, xP3, mC4иCC-News и др.
- Эти данные работают путем извлечения богатых семантических структур (например, заголовок-тело、Название-Аннотация、Инструкции - вывод и т. д.), чтобы обогатить семантическое понимание Модели.
- Масштаб неконтролируемых данных достигает 120 миллионов текстовых пар,Охватывает 194 языка и 2655 межъязыковых соответствий.
- Данные точной настройки:
- Высококачественные данные из размеченного корпуса,Включает сбор данных на английском, китайском и других языках.
- Например,Сбор данных на английском языке включает HotpotQA, TriviaQA, NQ, MS MARCO и другие.,В китайскую коллекцию данных входят DuReader, T2-Ranking, NLI-zh и др.
- Эти наборы данных используются для дальнейшей точной настройки модели.,улучшить его производительность при выполнении конкретных задач и языков.
- Синтетические данные:
- Чтобы решить проблему нехватки данных в задачах длительного поиска документов,Исследователи создали дополнительную многоязычную настройку данных (называемую MultiLongDoc).
- Случайным образом выбирая длинные статьи из Википедии и набора MC4данные,и случайным образом выбирать абзацы из,Затем используйте GPT-3.5, чтобы сгенерировать вопросы на основе этих отрывков.,Сгенерированный вопрос и выбранная статья образуют новую текстовую пару.,Увеличение разнообразия и охвата обучающих данных.
Что инновационного в этих обучающих данных:
- Многоязычное покрытие:M3-EmbeddingЧерез крупномасштабное многоязычное неконтролируемоеданные,Изучение общего семантического пространства между разными языками,Это поддерживает многоязычный поиск и поиск на разных языках.
- Разнообразие данных:путем объединения неконтролируемыхданные、тонкая настройкаданныеисинтезданные,M3-Embedding может захватывать семантическую информацию текстовых данных разных типов и длин.,Это улучшает способность Модели обрабатывать входные данные различной степени детализации.
- Высококачественная интеграция данных:путем тщательного отбораи Интегрируйте разные источникиданные,M3-Embedding обеспечивает высокое качество обучающих данных,Это очень важно для Модели, чтобы научиться эффективному встраиванию текста.
Состоит из этих инновационных обучающих данных,M3-EmbeddingСпособен эффективно учиться и поддерживать более чем100Встраивание текста в языки,Одновременная обработка документов, начиная от коротких предложений и заканчивая длинными документами длиной до 8192 токенов.,Он добился прорыва в многоязычности, многофункциональности и многогранности.
С точки зрения отрасли,M3-Embedding、E5-mistral-7b,LLM, такие как GPT, используются для синтеза большого количества многоязычных языков.,Это должно стать основным решением в будущем.
Гибридный поиск BGE-M3
M3-Embedding объединяет три общие функции поиска моделей внедрения, а именно: плотный поиск, лексический поиск и многовекторный поиск. Ниже приведены шаблонные описания этих методов:
- Плотный поиск: входной запрос q преобразуется в скрытое состояние Hq на основе кодировщика текста.,Используйте специальные теги“[CLS]”Нормализованное скрытое состояние для представления запроса:e_q = \text{norm}(H_q[0])。Сходным образом,Мы можем получить абзацpВстраивание e_p = \text{norm}(H_p[0])。Запроси Оценка релевантности между абзацами с помощью двух векторов внедрения e_p и e_qизмерить внутренний продукт:s_{\text{dense}} \leftarrow \langle e_p, e_q \rangle。
def dense_embedding(self, hidden_state, mask):
if self.sentence_pooling_method == 'cls':
return hidden_state[:, 0]
elif self.sentence_pooling_method == 'mean':
s = torch.sum(hidden_state * mask.unsqueeze(-1).float(), dim=1)
d = mask.sum(axis=1, keepdim=True).float()
return s / d- Лексический Поиск): выходное внедрение также используется для оценки важности каждого термина для облегчения лексического поиска. Для каждого терма t в запросе (в нашей работе терм соответствует токену) вес терма рассчитывается как w_{qt} \leftarrow \text{Relu}(W_{\text{lex}} H_q[i]),в W_{\text{lex}} \in \mathbb{R}^{d \times 1} это матрица, которая отображает скрытое состояние в действительное число。если срокtсуществовать Запроспоявляться несколько раз в,Мы сохраняем только его максимальный вес. Аналогично рассчитываем вес каждого термина в абзаце. На основе расчетных весов терминов,Запросиабзац Оценка корреляции между Запроси Общие термины в абзацах(Выражено какq ∩ p)рассчитать общую значимость:s_{\text{lex}} \leftarrow \sum_{t \in q \cap p}(w_{qt} \cdot w_{pt})。
def sparse_embedding(self, hidden_state, input_ids, return_embedding: bool = True):
# sparse_linear линейный слой = torch.nn.Linear(in_features=self.model.config.hidden_size, out_features=1)
# Рассчитать токен через relu weight
token_weights = torch.relu(self.sparse_linear(hidden_state))
if not return_embedding: return token_weights
# Форма (input_ids.size(0), input_ids.size(1), нулевой тензор self.vocab_size)
sparse_embedding = torch.zeros(input_ids.size(0), input_ids.size(1), self.vocab_size,
dtype=token_weights.dtype,
device=token_weights.device)
# Раскидываем значения в token_weights по соответствующим позициям sparse_embedding, а позиции индекса предоставляются согласно input_ids
sparse_embedding = torch.scatter(sparse_embedding, dim=-1, index=input_ids.unsqueeze(-1), src=token_weights)
# CLS,PAD Подождите бесполезный токен
unused_tokens = [self.tokenizer.cls_token_id, self.tokenizer.eos_token_id, self.tokenizer.pad_token_id,
self.tokenizer.unk_token_id]
sparse_embedding = torch.max(sparse_embedding, dim=1).values
# Бесполезный токен вес установлен на 0
sparse_embedding[:, unused_tokens] *= 0.
return sparse_embedding- Многовекторный поиск (Многовекторный поиск) Поиск: как расширение интенсивного поиска.,Многовекторные методы используют все выходные вложения для представления Запросиабзац:E_q = \text{norm}(W_{\text{mul}} H_q), E_p = \text{norm}(W_{\text{mul}} H_p),в W_{\text{mul}} \in \mathbb{R}^{d \times d} представляет собой обучаемую матрицу проекции. Следите за ColBERT (Хаттаби Захария, 2020)метод,Используйте поздние взаимодействия для расчета более точных показателей релевантности.:s_{\text{mul}} \leftarrow \frac{1}{N} \sum_{i=1}^{N} \max_{j=1}^{M} E_q[i] \cdot E_p[j];NиMОни есть Запросиабзацдлина。
Благодаря универсальности встроенной модели,Процесс извлечения может выполняться во время процесса смешивания. первый,Результаты-кандидаты могут быть получены индивидуально каждым методом (из-за его высокой стоимости).,Этот этап многовекторного метода можно исключить)。Окончательные результаты поиска переоцениваются на основе интегрированного показателя релевантности.:s_{\text{rank}} \leftarrow s_{\text{dense}} + s_{\text{lex}} + s_{\text{mul}}。
Методы обучения и инновации БГЭ-М3
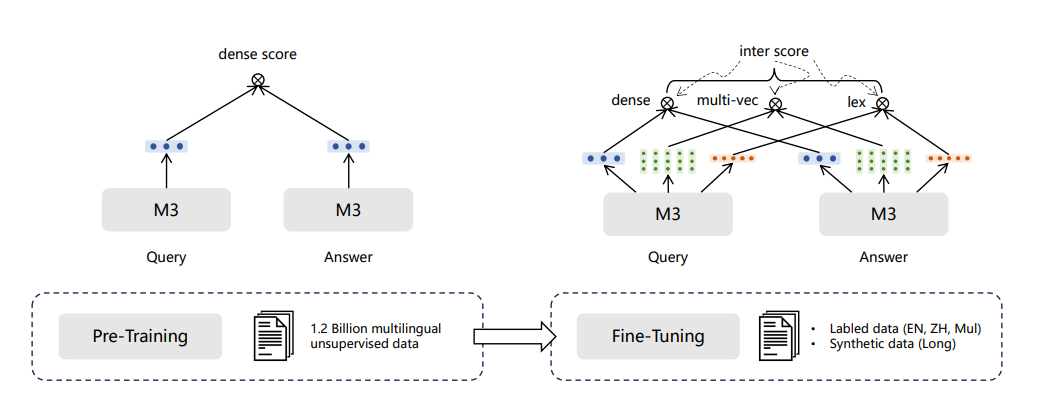
Обучение модели BGE-M3 разделено на три этапа:
- 1)Предварительная тренировка RetroMAE,На странице данныеи викиданные на 105 языках.,Предоставляет базовую модель, которая может поддерживать 8192 длины и задачи, ориентированные на представление;
- 2)Контрастное обучение без учителя,Масштабное сравнительное обучение на 194 отдельных языках и 1390 парах перевода, всего 1,1 млрд текстовых пар;
- 3)Единая оптимизация нескольких методов поиска,Универсальный поиск по качественным и разнообразным даннымоптимизация,Предоставьте модели несколько возможностей поиска.
- Среди них можно выделить следующие важные ключевые технологии:
1. Самообучающаяся дистилляция
Люди могут вычислять результаты и исправлять ошибки разными способами. Модель также может достичь лучших результатов, чем один режим поиска, путем объединения результатов нескольких методов поиска. Поэтому BGE-M3 использует метод самовозбуждающейся дистилляции для улучшения производительности поиска. В частности, выходные данные трех режимов поиска объединяются для получения нового показателя сходства текста, который используется в качестве стимулирующего сигнала, позволяющего каждому отдельному режиму изучить сигнал для улучшения эффекта одного режима поиска.
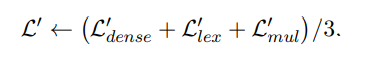
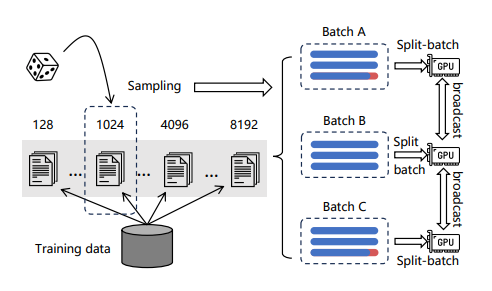
2. Оптимизация эффективности обучения
Группируя текстовые данные по длине, он гарантирует, что длина текста в пакете будет относительно одинаковой, тем самым уменьшая заполнение. Чтобы уменьшить потребление памяти при текстовом моделировании, пакет данных разделяется на несколько небольших пакетов. Для каждого мини-пакета модель используется для кодирования текста, выходные векторы собираются, отбрасывая все промежуточные состояния при прямом распространении, и, наконец, векторы агрегируются для расчета потерь, что может значительно увеличить размер обучающего пакета.
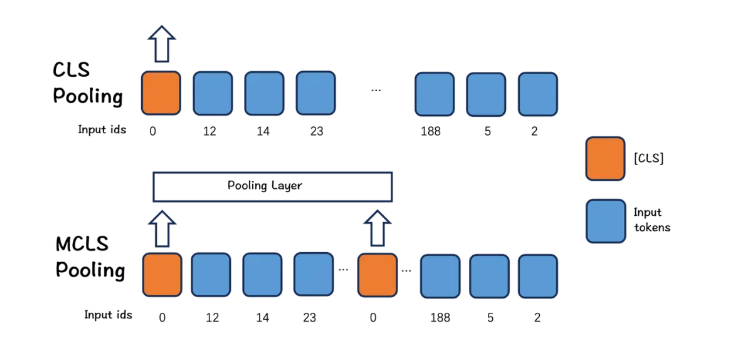
3. Оптимизация длинного текста
BGE-M3 предлагает простой и эффективный метод: MCLS (множественный CLS) для расширения возможностей модели без тонкой настройки длинных текстов.
Подход MCLS направлен на использование нескольких токенов CLS для совместного захвата семантики длинных текстов. Вставьте токен cls для каждого фиксированного количества токенов, каждый токен cls может получать семантическую информацию из соседних токенов и, наконец, получить окончательное встраивание текста путем усреднения последних скрытых состояний всех токенов cls.
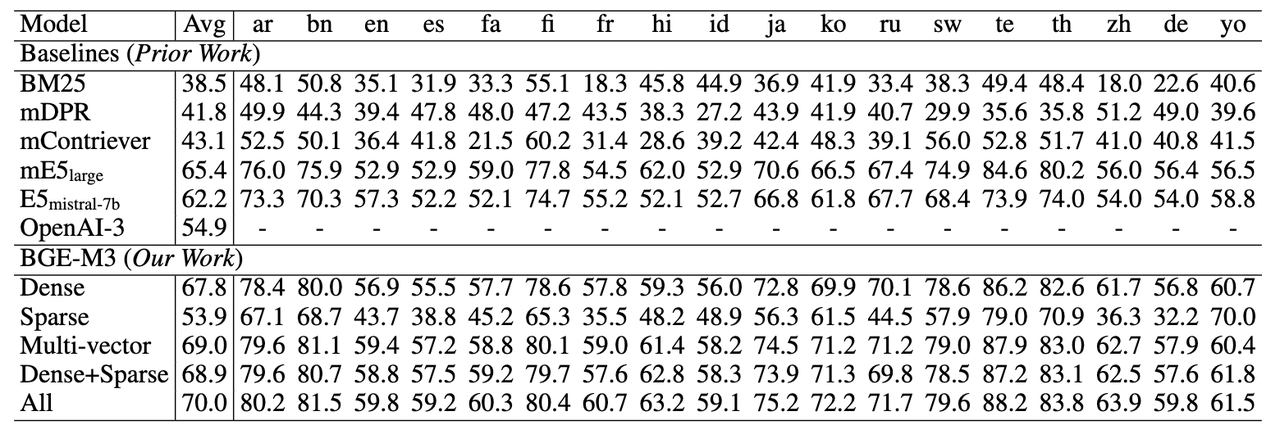
Результаты экспериментов БГЭ-М3
Для задач многоязычного поиска разреженный поиск (Sparse) значительно превосходит традиционный алгоритм разреженного сопоставления BM25. Многовекторный поиск (мультивекторный) достиг наилучшего эффекта среди трех методов поиска.
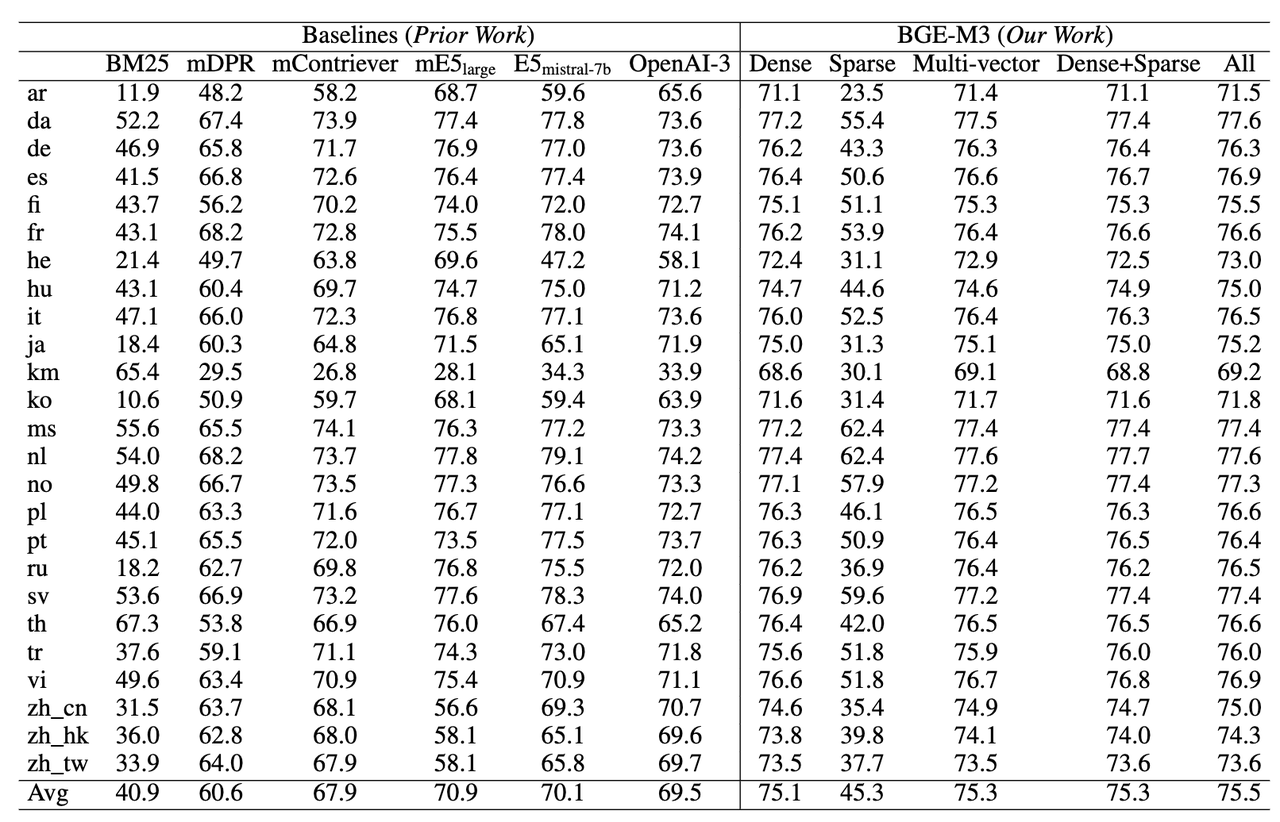
Возможность межъязыкового поиска (MKQA)
BGE-M3 по-прежнему имеет лучший эффект поиска при выполнении межъязыковых задач. Разреженный поиск не подходит для сценариев межъязыкового поиска, где перекрытие словарного запаса очень мало. Таким образом, преимущества разреженного поиска сами по себе и в сочетании с другими методами относительно невелики.
Возможность поиска длинных документов (MLRB: многоязычный тест длинного поиска)
BGE-M3 может поддерживать входные документы длиной до 8192 раз. Из экспериментальных результатов видно, что эффект разреженного поиска (Sparse) значительно выше, чем эффект плотного поиска (Dense), что показывает, что информация по ключевым словам чрезвычайно важна. для длительного поиска документов.
Доработка модели БГЭ-М3
Сначала нужно установить,
- with pip
pip install -U FlagEmbedding- from source
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .Формат набора данных для точной настройки модели — это файл формата строки json. Формат json следующий:
{"query": str, "pos": List[str], "neg":List[str]}query — это запрос, pos — список положительных текстов, а neg — список отрицательных текстов.
Модельное обучение:
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.BGE_M3.run \
--output_dir {path to save model} \
--model_name_or_path BAAI/bge-m3 \
--train_data ./toy_train_data \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size {large batch size; set 1 for toy data} \
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len 64 \
--passage_max_len 256 \
--train_group_size 2 \
--negatives_cross_device \
--logging_steps 10 \
--same_task_within_batch True \
--unified_finetuning True \
--use_self_distill TrueСсылки
- 1 BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
