Введение в искусственный интеллект | Узнайте о популярной в настоящее время модели диффузии за десять минут
Алгоритмы машинного обучения и искусственного интеллекта продолжают развиваться, чтобы решать сложные проблемы и углублять наше понимание данных. Одним из примечательных классов моделей являются диффузионные модели, которые ценятся за свою способность фиксировать и моделировать сложные процессы, такие как генерация данных и синтез изображений.
В этой статье мы рассмотрим:
- Что такое диффузия?
- Что такое диффузионная модель?
- Как работает диффузионная модель?
- Применение модели диффузии(Нет дисплея,Следующие несколько твитов будут посвящены этому)

Рисунок 1. Изображение, созданное DALL-E 3.
введение:
Диффузионные модели, как передовая генеративная модель, стали ключевым достижением в области машинного обучения за последние несколько лет. Начиная с 2020-х годов, серия знаковых исследовательских работ доказала миру силу диффузионных моделей, особенно в области синтеза изображений за пределами традиционных генеративно-состязательных сетей (GAN). Одним из наиболее ярких примеров является DALL-E 3, выпущенная OpenAI, усовершенствованная модель генерации изображений, которая еще раз демонстрирует огромный потенциал моделей диффузии в практических приложениях.

Рисунок 2. Модели диффузии можно использовать для создания изображений из шума.
Что такое диффузия?
Диффузионное моделирование — это метод генерации данных, который моделирует распространенные в природе процессы диффузии для синтеза новых данных. Точно так же, как капля чернил, падающая в воду, медленно растекается, модель диффузии начинается с простого шумового сигнала и постепенно добавляет детали и узоры, в конечном итоге генерируя новые сложные данные.
Исследователи обнаружили, что, запустив этот процесс в обратном порядке, начиная со сложных данных, постепенно удаляя детали и, наконец, оставляя простой случайный шум, а затем снова запуская его в обратном порядке, можно восстановить новые данные. Эта технология используется в таких областях, как компьютерное зрение и обработка естественного языка.
Модели диффузии неоднократно добавляют и удаляют шум для имитации различных случайных процессов, тем самым учатся извлекать сложные закономерности из случайности. Это одна из важных технологий и направлений исследований генеративных моделей.
Что такое диффузионная модель в машинном обучении?
В области машинного обучения диффузионная модель является уникальной генеративной моделью. Их особенностью является способность создавать совершенно новые выборки данных на основе обучающих данных. Например, если у вас есть серия изображений лиц и вы используете их для обучения модели диффузии, модель может генерировать новые, очень реалистичные лица с множеством различных черт и выражений, даже если лица не существуют в оригинальный тренировочный набор.
Диффузионное моделирование фокусируется на моделировании постепенной эволюции распределений данных от простой отправной точки (например, стандартного распределения Гаусса) к более сложным распределениям. Этот процесс осуществляется посредством ряда обратимых этапов. Короче говоря, как только модель освоит этот процесс преобразования, она может начать с простого распределения и постепенно «рассеивать» или трансформировать эту точку в более сложное распределение данных, создавая тем самым новые образцы данных.
1. Вероятностная модель диффузии с шумоподавлением (DDPM).
DDPM — это диффузная модель для вероятностной генерации данных, специально разработанная для генерации высококачественных данных. Как упоминалось ранее, модели диффузии генерируют данные, применяя серию преобразований к случайному шуму. В частности, DDPM моделируют процесс распространения, который преобразует зашумленные данные в чистые выборки данных. Представьте себе, что есть изображение, искаженное шумами и не выглядящее четким. ДДПМ подобен художнику, способному постепенно превратить эту шумную картинку в ясное, чистое изображение.
Как работает этот процесс? Во-первых, DDPM начинается с данных, содержащих случайный шум (например, размытые изображения). Затем он постепенно применяет ряд сложных преобразований, которым DDPM научился во время обучения. Этот процесс обучения включает понимание взаимосвязи между шумом и чистыми данными на разных этапах.

Рисунок 3. Принципиальная схема DDPM (Янг и др., 2023 г.).
Ключевым шагом является «подавление шума». На этом этапе DDPM постепенно устраняет шум и постепенно восстанавливает исходное состояние данных. Думайте об этом как о процессе постепенной ясности: сначала вы видите только размытое изображение, но со временем изображение становится все яснее и яснее.
DDPM особенно эффективен при шумоподавлении изображений. Они не только удаляют шум с поврежденных изображений, но и создают изображения, которые выглядят очень естественно и четко. Кроме того, DDPM также можно использовать для других сложных задач, таких как завершение изображения и улучшение разрешения изображения.
В целом, DDPM особенно эффективен для задач шумоподавления изображений. Они эффективно удаляют шум из поврежденных изображений и создают визуально ошеломляющие версии без шума. Кроме того, DDPM также можно использовать в таких приложениях, как рисование изображений и суперразрешение.
2. Генеративные модели на основе баллов (SGM).
Генеративные модели на основе оценок (сокращенно SGM) — это инновационный инструмент машинного обучения, предназначенный для создания новых выборок данных. Представьте, что у вас есть набор данных, например серия изображений или звуков, и вы хотите создать на их основе несколько новых, но естественно выглядящих сэмплов. Вот в чем хороши SGM!
Основная технология SGM — это интеллектуальный метод расчета, называемый «функцией оценки». Эта функция действует как компас, указывая модели, как ориентироваться в сложном мире данных. Он может сообщить модели, насколько вероятно появление данных в любой момент, и помочь модели понять глубокую структуру данных.
Процесс использования SGM немного похож на работу скульптора, создающего статую. Модель начинается с простой формы, а затем постепенно преобразует ее в более сложную и реалистичную форму в соответствии с указаниями функции оценки. Этот процесс завершается постоянным обновлением выборок данных, благодаря чему сгенерированные выборки могут все ближе и ближе приближаться к распределению реальных данных.
По сравнению с другими типами генеративных моделей, такими как генеративно-состязательные сети (GAN) или вариационные автоэнкодеры (VAE), SGM имеют свои уникальные преимущества. Они обеспечивают более прямой способ понять и воспроизвести распределение данных и, как правило, лучше справляются с созданием сложных выборок данных. Более того, SGM, как правило, более стабильны во время обучения и с меньшей вероятностью страдают от проблем с обучением, таких как GAN.
SGM продемонстрировали свою полезность во многих областях, таких как обработка изображений, синтез речи и распознавание сложных образов. Хотя они сталкиваются с некоторыми проблемами с точки зрения вычислительной сложности и стабильности обучения, будущие исследования могут быть сосредоточены на повышении эффективности SGM, совершенствовании процесса обучения и расширении сферы их применения.
Таким образом, генеративные модели на основе оценок являются крупным достижением в области машинного обучения и демонстрируют большой потенциал в понимании и моделировании сложных распределений данных. Поскольку технологии продолжают развиваться, мы ожидаем, что SGM будут играть важную роль в большем количестве областей в будущем.
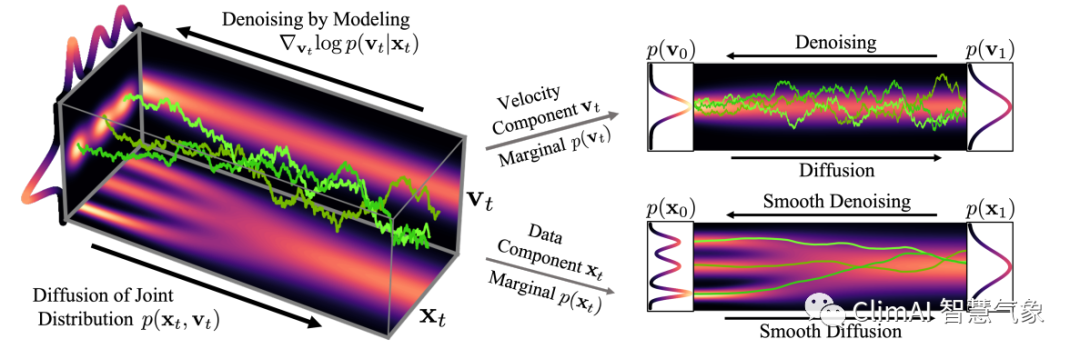
Рисунок 4. Принципиальная схема SGM (Тим и др., 2022).
3. Стохастические дифференциальные уравнения (Score SDE)
Стохастические дифференциальные уравнения (СДУ) — это особый тип математических уравнений, которые описывают, как система изменяется с течением времени под влиянием детерминированных и стохастических сил. В мире генеративных моделей существуют стохастические дифференциальные уравнения на основе оценок (сокращенно SDE), которые представляют собой уникальный подход к построению и настройке моделей на основе оценок.
Представьте себе, что Score SDE похожи на «систему GPS» для моделей машинного обучения. Они загружают модель с помощью функции оценки. Эта оценочная функция является решением стохастического дифференциального уравнения, которое помогает модели научиться адаптироваться и понимать распределение данных. Это все равно что рассказывать модели, как ориентироваться в океане данных, чтобы найти правильный путь.
Оценочные SDE используют случайные процессы для моделирования процесса изменения выборок данных и направляют модель для создания высококачественных выборок данных. Этот процесс немного похож на приключенческое путешествие по миру данных, где модель учится развиваться от простой отправной точки к сложной и разнообразной конечной точке.
Когда Score SDE и методы моделирования на основе оценок объединены, можно создать мощные генеративные модели. Эти модели не только могут обрабатывать сложные распределения данных, но также могут генерировать разнообразные и реалистичные выборки. Это все равно, что дать модели волшебную палочку, позволяющую ей создавать реалистичные и разнообразные произведения искусства или моделировать сложные системы в реальном мире.
Короче говоря, стохастические дифференциальные уравнения на основе оценок (Score SDE) открывают новый взгляд на генеративные модели, помогая им лучше понимать и моделировать сложность реального мира. Эта технология открывает новые возможности для создания высококачественных, разнообразных выборок данных, демонстрируя большой потенциал в таких областях, как создание произведений искусства и моделирование сложных систем.

Рисунок 5. Схематическая диаграмма SDE Score (Yang et al., 2021).
Подводя итог, DDPM, SGM и SDE Score вращаются вокруг моделей того, как генерировать четкие данные из зашумленных данных. DDPM фокусируется на постепенном добавлении шума и восстановлении из него данных, тогда как SGM фокусируется на использовании функции оценки для управления этим процессом. SDE Score предоставляют более широкую математическую основу, которая объединяет эти концепции и процессы, показывая, как эти модели связаны друг с другом и работают в рамках более широкой математики.
Как работает диффузионная модель?
Модель диффузии — это усовершенствованная модель генерации данных, которая моделирует процесс обратной диффузии. Этот процесс включает в себя следующие шаги:
- Предварительная обработка данных: данные сначала стандартизируются,для обеспечения равномерного масштаба и центра. Этот шаг предназначен для того, чтобы Модель могла лучше обрабатывать данные.,и подготовиться к следующим шагам.
- Прямая диффузия: модель начинается с простого распределения (например, распределения Гаусса).,Постепенно вводите шум,Усложнение данных. Этот процесс включает в себя ряд обратимых преобразований.,Постепенно увеличивайте сложность ваших данных.
- Модельное обучение: на данном этапе,Модель Узнайте, как выполнять обратимые преобразования. Обучение включает в себя оптимизацию функции потерь.,Эта функция измеряет, насколько хорошо Модель преобразует простые выборки данных в сложные распределения данных.
- Обратная диффузия: после завершения прямой диффузии.,Модель преобразует сложные выборки данных обратно в простое исходное состояние посредством обратной операции. Этот процесс позволяет модели начать с точки простого распределения.,Постепенно сгенерируйте новые выборки, аналогичные исходному распределению данных.
Благодаря этому процессу обратной диффузии модель диффузии способна генерировать новые выборки данных, начиная с точки простого распределения и постепенно распространяя ее до желаемого сложного распределения данных. Сгенерированные образцы поразительно похожи на исходное распределение данных, что делает диффузионные модели мощным инструментом для таких задач, как синтез изображений, пополнение данных и шумоподавление.
Справочные источники:
https://encord.com/blog/diffusion-models/
https://arxiv.org/pdf/2209.00796.pdf
https://arxiv.org/abs/2112.07068
https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
