Введение в интерфейс коллективной связи Nvidia-NCCL-GPU_примечания к исходному коду
термин
nccl: интерфейс коллективной связи библиотеки коллективных коммуникаций NVIDIA (NCCL).
Общие ссылки
Документация разработчика NCCL: https://developer.nvidia.com/nccl
Пользовательская документация: https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/index.html
Домашняя страница проекта: https://github.com/NVIDIA/nccl
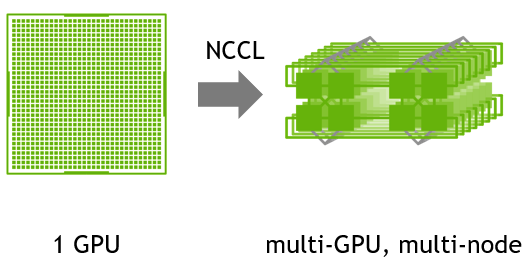
представлять
Оптимизированные примитивы для связи между графическими процессорами.
NCCL (произносится как «Никель») — это отдельная библиотека стандартных коммуникационных процедур графического процессора, которые реализуют все-сокращение, все-сбор, сокращение, широковещательную рассылку, уменьшение-рассеяние и любой режим связи на основе отправки/получения. Он оптимизирован для высокой пропускной способности на платформах, использующих PCIe, NVLink, NVswitch, а также в сетях, использующих InfiniBand Verbs или сокеты TCP/IP. NCCL поддерживает установку любого количества графических процессоров на одном узле или на нескольких узлах и может использоваться для однопроцессных или многопроцессных (например, MPI) приложений.
Примечания к чтению исходного кода
GIT-репозиторий: https://github.com/ssbandjl/nccl.git
Подвести итог:
Библиотека NCCL использует собственный интерфейс RDMA VERBS. Минималистский (по сравнению с UCX и Libfabric или другими коммуникационными библиотеками глаголов) реализует одностороннее чтение и запись, а также двустороннюю отправку/получение коммуникационной семантики, Чтобы обеспечить высокую производительность и высокую пропускную способность между графическими процессорами, Соответствует передаче данных при обучении крупных моделей ИИ.
Установление соединения стека вызовов RDMA-QP:
ncclResult_t ncclIbCreateQp
qpInitAttr.qp_type = IBV_QPT_RC
qpInitAttr.cap.max_send_wr = 2*MAX_REQUESTS -> 128
qpInitAttr.cap.max_recv_wr = MAX_REQUESTS -> 64
wrap_ibv_modify_qp
RDMA односторонний стек записи-вызова/с немедленным значением
ncclResult_t ncclIbIsend
NCCLCHECK(ncclIbMultiSend(comm, slot))
ncclResult_t ncclIbMultiSend
for (int r=0; r<nreqs; r++)
struct ibv_sge* sge = comm->sges+r
wr->opcode = IBV_WR_RDMA_WRITE
wr->wr.rdma.remote_addr = slots[r].addr
wr->next = wr+1
wr_id += (reqs[r] - comm->verbs.reqs) << (r*8)
immData |= (reqs[r]->send.size ? 1 : 0) << r -> Запишите размер данных в непосредственное число. При отправке нескольких сообщений просто напишите 0или1 в качестве размера, чтобы указать, есть ли данные для отправки или получения.
lastWr->wr_id = wr_id
lastWr->opcode = IBV_WR_RDMA_WRITE_WITH_IMM
lastWr->send_flags = IBV_SEND_SIGNALED
NCCLCHECK(wrap_ibv_post_send(comm->qps[comm->qpIndex], comm->wrs, &bad_wr))
qp->context->ops.post_send(qp, wr, bad_wr) -> ibv_post_send
main: основная функция
net_type: Тип сети
ncclNet_t* ncclNets[3] = { nullptr, &ncclNetIb, &ncclNetSocket };
src/transport/net_ib.cc
Интерфейс API, реализованный сетевой картой IB
ncclNet_t ncclNetIb = {
"IB",
ncclIbInit,
ncclIbDevices,
ncclIbGetProperties,
ncclIbListen,
ncclIbConnect,
ncclIbAccept,
ncclIbRegMr,
ncclIbRegMrDmaBuf,
ncclIbDeregMr,
ncclIbIsend,
ncclIbIrecv,
ncclIbIflush,
ncclIbTest,
ncclIbCloseSend,
ncclIbCloseRecv,
ncclIbCloseListen
};
Сетевые интерфейсы:
typedef struct {
// Name of the network (mainly for logs)
const char* name;
// Initialize the network.
ncclResult_t (*init)(ncclDebugLogger_t logFunction);
// Return the number of adapters.
ncclResult_t (*devices)(int* ndev);
// Get various device properties.
ncclResult_t (*getProperties)(int dev, ncclNetProperties_v6_t* props);
// Create a receiving object and provide a handle to connect to it. The
// handle can be up to NCCL_NET_HANDLE_MAXSIZE bytes and will be exchanged
// between ranks to create a connection.
ncclResult_t (*listen)(int dev, void* handle, void** listenComm);
// Connect to a handle and return a sending comm object for that peer.
// This call must not block for the connection to be established, and instead
// should return successfully with sendComm == NULL with the expectation that
// it will be called again until sendComm != NULL.
ncclResult_t (*connect)(int dev, void* handle, void** sendComm);
// Finalize connection establishment after remote peer has called connect.
// This call must not block for the connection to be established, and instead
// should return successfully with recvComm == NULL with the expectation that
// it will be called again until recvComm != NULL.
ncclResult_t (*accept)(void* listenComm, void** recvComm);
// Register/Deregister memory. Comm can be either a sendComm or a recvComm.
// Type is either NCCL_PTR_HOST or NCCL_PTR_CUDA.
ncclResult_t (*regMr)(void* comm, void* data, int size, int type, void** mhandle);
/* DMA-BUF support */
ncclResult_t (*regMrDmaBuf)(void* comm, void* data, size_t size, int type, uint64_t offset, int fd, void** mhandle);
ncclResult_t (*deregMr)(void* comm, void* mhandle);
// Asynchronous send to a peer.
// May return request == NULL if the call cannot be performed (or would block)
ncclResult_t (*isend)(void* sendComm, void* data, int size, int tag, void* mhandle, void** request);
// Asynchronous recv from a peer.
// May return request == NULL if the call cannot be performed (or would block)
ncclResult_t (*irecv)(void* recvComm, int n, void** data, int* sizes, int* tags, void** mhandles, void** request);
// Perform a flush/fence to make sure all data received with NCCL_PTR_CUDA is
// visible to the GPU
ncclResult_t (*iflush)(void* recvComm, int n, void** data, int* sizes, void** mhandles, void** request);
// Test whether a request is complete. If size is not NULL, it returns the
// number of bytes sent/received.
ncclResult_t (*test)(void* request, int* done, int* sizes);
// Close and free send/recv comm objects
ncclResult_t (*closeSend)(void* sendComm);
ncclResult_t (*closeRecv)(void* recvComm);
ncclResult_t (*closeListen)(void* listenComm);
} ncclNet_v6_t;
ncclIbRegMr -> регистрация в памяти
ncclResult_t ncclIbRegMrDmaBuf
flags = IBV_ACCESS_LOCAL_WRITE|IBV_ACCESS_REMOTE_WRITE|IBV_ACCESS_REMOTE_READ
NCCLCHECKGOTO(wrap_ibv_reg_mr_iova2(&mr, verbs->pd, (void*)addr, pages*pageSize, addr, flags), res, returning)
NCCLCHECKGOTO(wrap_ibv_reg_mr(&mr, verbs->pd, (void*)addr, pages*pageSize, flags), res, returning)
Подпечать:
ncclResult_t ncclIbIflush(void* recvComm, int n, void** data, int* sizes, void** mhandles, void** request) {
NCCLCHECK(wrap_ibv_poll_cq(r->verbs->cq, 4, wcs, &wrDone))
ncclNet_v4_as_v6_init
collNetRegMr
Внешний интерфейс: src/include/coll_net.h
// Translation to external API
static const char* collNetName(struct ncclComm* comm) { return comm->ncclCollNet->name; }
static ncclResult_t collNetDevices(struct ncclComm* comm, int* ndev) { NCCLCHECK(comm->ncclCollNet->devices(ndev)); return ncclSuccess; }
static ncclResult_t collNetGetProperties(struct ncclComm* comm, int dev, ncclNetProperties_t* props) { NCCLCHECK(comm->ncclCollNet->getProperties(dev, props)); return ncclSuccess; }
static ncclResult_t collNetListen(struct ncclComm* comm, int dev, void* handle, void** listenComm) { NCCLCHECK(comm->ncclCollNet->listen(dev, handle, listenComm)); return ncclSuccess; }
static ncclResult_t collNetConnect(struct ncclComm* comm, void* handles[], int nranks, int rank, void* listenComm, void** collComm) { NCCLCHECK(comm->ncclCollNet->connect(handles, nranks, rank, listenComm, collComm)); return ncclSuccess; }
static ncclResult_t collNetReduceSupport(struct ncclComm* comm, ncclDataType_t dataType, ncclRedOp_t redOp, int* supported) { NCCLCHECK(comm->ncclCollNet->reduceSupport(dataType, redOp, supported)); return ncclSuccess; }
static ncclResult_t collNetRegMr(struct ncclComm* comm, void* collComm, void* data, int size, int type, void** mhandle) { NCCLCHECK(comm->ncclCollNet->regMr(collComm, data, size, type, mhandle)); return ncclSuccess; }
/* DMA-BUF support */
static ncclResult_t collNetRegMrDmaBuf(struct ncclComm* comm, void* collComm, void* data, int size, int type, uint64_t offset, int fd, void** mhandle) { NCCLCHECK(comm->ncclCollNet->regMrDmaBuf(collComm, data, size, type, offset, fd, mhandle)); return ncclSuccess; }
static ncclResult_t collNetDeregMr(struct ncclComm* comm, void* collComm, void* mhandle) { NCCLCHECK(comm->ncclCollNet->deregMr(collComm, mhandle)); return ncclSuccess; }
static ncclResult_t collNetIallreduce(struct ncclComm* comm, void* collComm, void* sendData, void* recvData, int count, ncclDataType_t dataType, ncclRedOp_t redOp, void* sendMhandle, void* recvMhandle, void** request) {
NCCLCHECK(comm->ncclCollNet->iallreduce(collComm, sendData, recvData, count, dataType, redOp, sendMhandle, recvMhandle, request)); return ncclSuccess; }
static ncclResult_t collNetIflush(struct ncclComm* comm, void* collComm, void* data, int size, void* mhandle, void** request) { NCCLCHECK(comm->ncclCollNet->iflush(collComm, data, size, mhandle, request)); return ncclSuccess; }
static ncclResult_t collNetTest(struct ncclComm* comm, void* request, int* done, int* size) { NCCLCHECK(comm->ncclCollNet->test(request, done, size)); return ncclSuccess; }
static ncclResult_t collNetCloseColl(struct ncclComm* comm, void* collComm) { NCCLCHECK(comm->ncclCollNet->closeColl(collComm)); return ncclSuccess; }
static ncclResult_t collNetCloseListen(struct ncclComm* comm, void* listenComm) { NCCLCHECK(comm->ncclCollNet->closeListen(listenComm)); return ncclSuccess; }
static int collNetSupport(struct ncclComm* comm) { return comm->ncclCollNet != nullptr ? 1 : 0; }
struct ncclTransport collNetTransport = {
"COL",
canConnect,
{ sendSetup, sendConnect, sendFree, NULL, sendProxySetup, sendProxyConnect, sendProxyFree, sendProxyProgress },
{ recvSetup, recvConnect, recvFree, NULL, recvProxySetup, recvProxyConnect, recvProxyFree, recvProxyProgress }
};
Библиотеки выравнивания и общие математические функции:
#define DIVUP(x, y) \
(((x)+(y)-1)/(y))
#define ROUNDUP(x, y) \
(DIVUP((x), (y))*(y))
#define ALIGN_POWER(x, y) \
((x) > (y) ? ROUNDUP(x, y) : ((y)/((y)/(x))))
#define ALIGN_SIZE(size, align) \
size = ((size + (align) - 1) / (align)) * (align);
#if !__CUDA_ARCH__
#ifndef __host__
#define __host__
#endif
#ifndef __device__
#define __device__
#endif
#endif
template<typename X, typename Y, typename Z = decltype(X()+Y())>
__host__ __device__ constexpr Z divUp(X x, Y y) {
return (x+y-1)/y;
}
template<typename X, typename Y, typename Z = decltype(X()+Y())>
__host__ __device__ constexpr Z roundUp(X x, Y y) {
return (x+y-1) - (x+y-1)%y;
}
// assumes second argument is a power of 2
template<typename X, typename Z = decltype(X()+int())>
__host__ __device__ constexpr Z alignUp(X x, int a) {
return (x+a-1) & Z(-a);
}
Публичный статус:
enum ncclIbCommState {
ncclIbCommStateStart = 0,
ncclIbCommStateConnect = 1,
ncclIbCommStateAccept = 3,
ncclIbCommStateSend = 4,
ncclIbCommStateRecv = 5,
ncclIbCommStateConnecting = 6,
ncclIbCommStateConnected = 7,
ncclIbCommStatePendingReady = 8,
};
ncclResult_t ncclIbConnect(int dev, void* opaqueHandle, void** sendComm)
if (stage->state == ncclIbCommStateSend) goto ib_send;
NCCLCHECK(ncclIbInitVerbs(dev, ctx, &comm->verbs))
инициализация
init()
Загружается во время компиляции:
ncclResult_t wrap_ibv_symbols(void) {
pthread_once(&initOnceControl,
[](){ initResult = buildIbvSymbols(&ibvSymbols); });
return initResult;
}
ncclResult_t buildIbvSymbols(struct ncclIbvSymbols* ibvSymbols)
ibvhandle=dlopen("libibverbs.so", RTLD_NOW)
интерфейс ИБВ, verbs, Упаковка, таблица символов
LOAD_SYM(ibvhandle, "ibv_get_device_list", ibvSymbols->ibv_internal_get_device_list);
LOAD_SYM(ibvhandle, "ibv_free_device_list", ibvSymbols->ibv_internal_free_device_list);
LOAD_SYM(ibvhandle, "ibv_get_device_name", ibvSymbols->ibv_internal_get_device_name);
LOAD_SYM(ibvhandle, "ibv_open_device", ibvSymbols->ibv_internal_open_device);
LOAD_SYM(ibvhandle, "ibv_close_device", ibvSymbols->ibv_internal_close_device);
LOAD_SYM(ibvhandle, "ibv_get_async_event", ibvSymbols->ibv_internal_get_async_event);
LOAD_SYM(ibvhandle, "ibv_ack_async_event", ibvSymbols->ibv_internal_ack_async_event);
LOAD_SYM(ibvhandle, "ibv_query_device", ibvSymbols->ibv_internal_query_device);
LOAD_SYM(ibvhandle, "ibv_query_port", ibvSymbols->ibv_internal_query_port);
LOAD_SYM(ibvhandle, "ibv_query_gid", ibvSymbols->ibv_internal_query_gid);
LOAD_SYM(ibvhandle, "ibv_query_qp", ibvSymbols->ibv_internal_query_qp);
LOAD_SYM(ibvhandle, "ibv_alloc_pd", ibvSymbols->ibv_internal_alloc_pd);
LOAD_SYM(ibvhandle, "ibv_dealloc_pd", ibvSymbols->ibv_internal_dealloc_pd);
LOAD_SYM(ibvhandle, "ibv_reg_mr", ibvSymbols->ibv_internal_reg_mr);
// Cherry-pick the ibv_reg_mr_iova2 API from IBVERBS 1.8
LOAD_SYM_VERSION(ibvhandle, "ibv_reg_mr_iova2", ibvSymbols->ibv_internal_reg_mr_iova2, "IBVERBS_1.8");
// Cherry-pick the ibv_reg_dmabuf_mr API from IBVERBS 1.12
LOAD_SYM_VERSION(ibvhandle, "ibv_reg_dmabuf_mr", ibvSymbols->ibv_internal_reg_dmabuf_mr, "IBVERBS_1.12");
LOAD_SYM(ibvhandle, "ibv_dereg_mr", ibvSymbols->ibv_internal_dereg_mr);
LOAD_SYM(ibvhandle, "ibv_create_cq", ibvSymbols->ibv_internal_create_cq);
LOAD_SYM(ibvhandle, "ibv_destroy_cq", ibvSymbols->ibv_internal_destroy_cq);
LOAD_SYM(ibvhandle, "ibv_create_qp", ibvSymbols->ibv_internal_create_qp);
LOAD_SYM(ibvhandle, "ibv_modify_qp", ibvSymbols->ibv_internal_modify_qp);
LOAD_SYM(ibvhandle, "ibv_destroy_qp", ibvSymbols->ibv_internal_destroy_qp);
LOAD_SYM(ibvhandle, "ibv_fork_init", ibvSymbols->ibv_internal_fork_init); <- wrap_ibv_fork_init
LOAD_SYM(ibvhandle, "ibv_event_type_str", ibvSymbols->ibv_internal_event_type_str);
Пропускная способность сетевой карты RDMA:
static int ibvSpeeds[] = {
2500, /* SDR */
5000, /* DDR */
10000, /* QDR */
10000, /* QDR */
14000, /* FDR */
25000, /* EDR */
50000, /* HDR */
100000 /* NDR */ };
Формула расчета пропускной способности:
ncclIbDevs[ncclNIbDevs].speed = ncclIbSpeed(portAttr.active_speed) * ncclIbWidth(portAttr.active_width);
Асинхронный основной поток IB:
static void* ncclIbAsyncThreadMain(void* args)
wrap_ibv_event_type_str(&str, event.event_type)) -> Событие в строку
wrap_ibv_ack_async_event(&event)Подвести итог
Библиотека NCCL использует собственный интерфейс RDMA VERBS для реализации семантики одностороннего чтения и записи, а также двусторонней отправки и получения семантики связи минималистским способом (по сравнению с UCX, Libfabric или другими библиотеками связи глаголов) для удовлетворения высокой производительности и высоких требований между графическими процессорами. Пропускная способность связи для обеспечения передачи данных при обучении больших моделей ИИ
Сяобин (ssbandjl)
блог: https://cloud.tencent.com/developer/user/5060293/articles | https://logread.cn | https://blog.csdn.net/ssbandjl
Краткое описание ДАОС: https://cloud.tencent.com/developer/article/2344030
Технические доклады Сяобина (серия: DAOS/RDMA/UCX/Mercury/Libfabric/распределенное хранилище и т.д.)
видео: https://cloud.tencent.com/developer/user/5060293/video
блог: https://cloud.tencent.com/developer/column/99669
Друзья, интересующиеся высокопроизводительными технологиями, такими как DAOS, SPDK, RDMA, сопрограммы и т. д., могут присоединиться к обмену технологиями DAOS (группе)



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
