Введение и руководство по использованию Stable Diffusion
Stable Diffusion — это модель скрытой диффузии текста в изображение, созданная исследователями и инженерами CompVis, Stability AI и LAION. Он обучается с использованием изображений размером 512x512 из подмножества базы данных LAION-5B. Используя эту модель, вы можете создать любое изображение, включая лица. Поскольку существуют предварительно обученные модели с открытым исходным кодом, мы также можем запустить их на нашей собственной машине, как показано на рисунке ниже.

Если вы достаточно умны и креативны, вы можете создать серию изображений, которые затем сформируют видео. Например, Ксандер Стенбрюгге использовал его и приглашения для ввода, изображенные выше, для создания потрясающего видео о путешествиях во времени, представленного ниже.
Ниже приведены источники вдохновения и тексты, которые он использовал для создания этого творческого произведения искусства:
В этой статье впервые рассказывается, что такое стабильная диффузия, и обсуждаются ее основные компоненты. Затем мы будем использовать модель для создания изображений тремя разными способами: от более простого к более сложному.
Stable Diffusion
Стабильная диффузия — это модель машинного обучения, которая обучена постепенному шумоподавлению случайного гауссовского шума для получения представляющих интерес образцов, таких как сгенерированные изображения.
Основным недостатком модели диффузии является то, что процесс шумоподавления очень дорог с точки зрения потребления времени и памяти. Это замедляет процесс и потребляет много памяти. Основная причина в том, что они работают в пиксельном пространстве, особенно при создании изображений с высоким разрешением.
Скрытая диффузия снижает затраты на память и вычисления, применяя процесс диффузии к скрытому пространству меньшей размерности, а не к использованию фактического пространства пикселей. Поэтому компания Stable Diffusion представила метод скрытой диффузии для решения этой дорогостоящей в вычислительном отношении проблемы.
1. Основные компоненты скрытой диффузии.
Скрытая диффузия состоит из трех основных компонентов:
Автоэнкодер (ВАЭ)
Автоэнкодер (ВАЭ) состоит из двух основных частей: кодера и декодера. Кодер преобразует изображение в низкоразмерное скрытое представление.,Это представление будет служить входными данными для следующего компонента U_Net. Декодер сделает обратное,Он преобразует базовое представление обратно в изображение.
Во время процесса обучения скрытой диффузии кодер используется для получения скрытого представления (скрытого) входного изображения во время процесса прямой диффузии. Во время вывода декодер VAE преобразует скрытый сигнал обратно в изображение.
U-Net
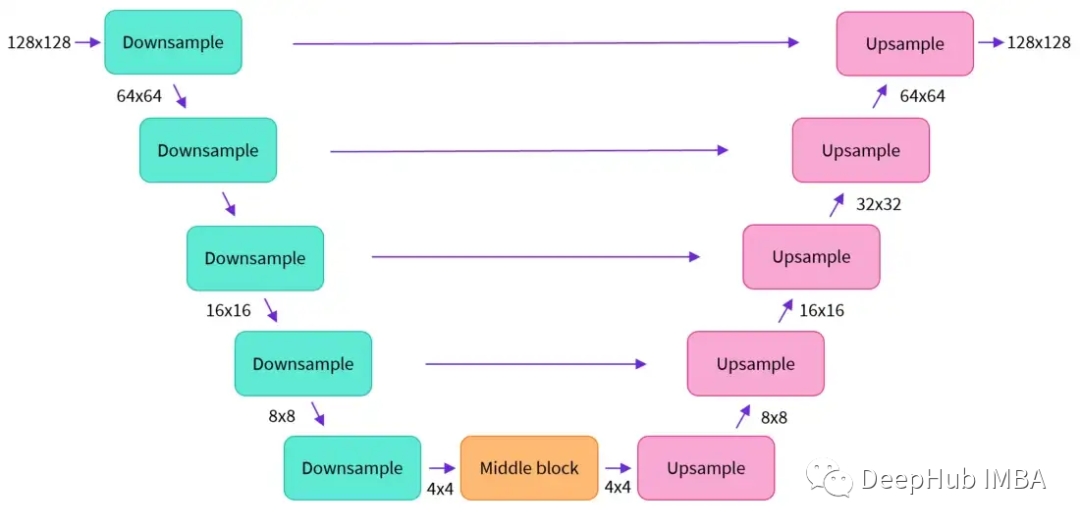
U-Net также включает в себя две части: кодер и декодер, обе из которых состоят из блоков ResNet. Кодер сжимает представление изображения в изображение с низким разрешением, а декодер декодирует изображение с низким разрешением обратно в изображение с высоким разрешением.
Чтобы предотвратить потерю U-Net важной информации при понижающей дискретизации, между ResNet понижающей дискретизации кодера и ResNet декодера повышающей дискретизации обычно добавляются короткие соединения.
В U-Net Stable Diffusion добавлен слой перекрестного внимания для настройки вывода встраивания текста. Между блоками ResNet кодера и декодера U-Net добавляется уровень перекрестного внимания.
Text-Encoder
Кодировщик текста преобразует входную текстовую подсказку в пространство внедрения, понятное U-Net. Это простой кодировщик на основе преобразователя, который сопоставляет последовательности токенов со скрытыми последовательностями внедрения текста. Отсюда вы можете увидеть, как использовать хорошие текстовые подсказки для получения более ожидаемого результата.
Почему латентная диффузия быстрая и эффективная
Причина, по которой «Скрытая диффузия» является быстрой и эффективной, заключается в том, что ее U-Net работает в низкомерном пространстве. Это уменьшает объем памяти и вычислительную сложность по сравнению с диффузией пространства пикселей. Например, образ (3512512) превратится в (4,64,64) в скрытом пространстве, а память уменьшится в 64 раза.
Процесс рассуждения о стабильной диффузии
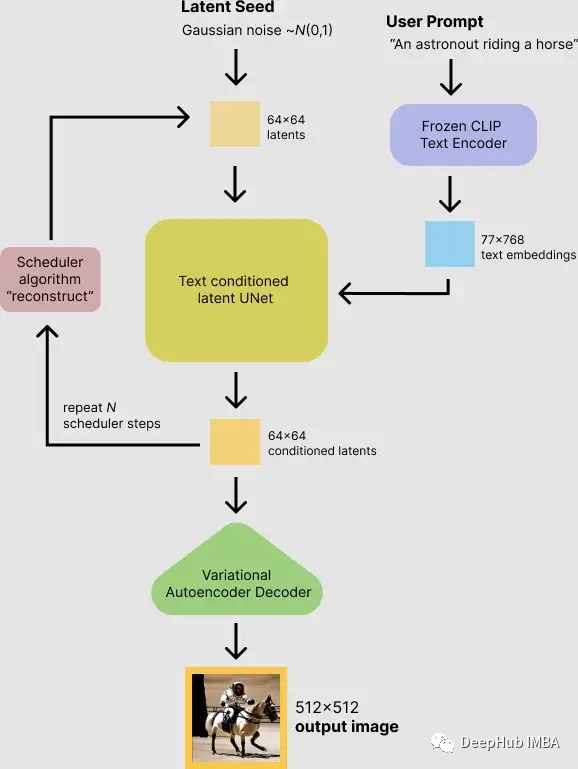
Во-первых, модель принимает на вход как случайное начальное число скрытого пространства, так и текстовую подсказку. Затем начальное значение скрытого пространства используется для генерации случайного представления скрытого изображения размером 64×64, а входная текстовая подсказка преобразуется во встраивание текста размером 77×768 с помощью текстового кодировщика CLIP.
Затем U-Net используется для итеративного шумоподавления случайного представления скрытого изображения при одновременной обработке встраивания текста. Выходными данными U-Net является остаток шума, который используется для расчета представления скрытого изображения с шумоподавлением с помощью алгоритма планировщика. Алгоритм планировщика вычисляет прогнозируемое представление изображения с шумоподавлением на основе предыдущего представления шума и прогнозируемого остаточного шума.
Для этого расчета можно использовать множество различных алгоритмов планировщика, каждый из которых имеет свои преимущества и недостатки. Для стабильной диффузии рекомендуется использовать одно из следующих действий:
- Планировщик PNDM (по умолчанию)
- DDIM scheduler
- K-LMS scheduler
Процесс шумоподавления повторяется примерно 50 раз, что позволяет постепенно получать более качественные представления скрытого изображения. После завершения представление скрытого изображения декодируется декодерной частью вариационного автокодировщика.
Использование API Hugging Face
Hugging Face предоставляет очень простой API для создания изображений с использованием нашей модели. На рисунке ниже вы можете видеть, что я использовал «астронавт верхом на лошади» в качестве входных данных для получения выходного изображения:

Предоставленная им модель также содержит некоторые дополнительные параметры для изменения качества создаваемых изображений, как показано ниже:
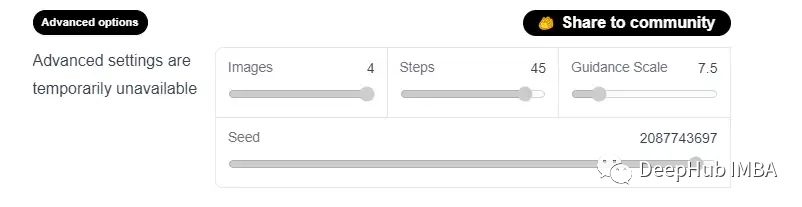
Ниже описаны четыре варианта:
изображения: этот параметр контролирует максимальное количество создаваемых изображений до 4.
Шаги: этот параметр выбирает желаемое количество шагов процесса распространения. Чем больше шагов, тем лучше качество получаемого изображения. Если вы хотите высокого качества, вы можете выбрать максимальное количество доступных шагов — 50. Если вы хотите получить более быстрые результаты, рассмотрите возможность уменьшения количества шагов.
Шкала управления. Шкала управления — это компромисс между тем, насколько точно сгенерированное изображение соответствует входным сигналам, и разнообразием входных данных. Его типичное значение составляет около 7,5. Чем больше вы увеличиваете соотношение, тем выше будет качество изображения, но тем меньше выходных данных вы получите.
Начальное число: случайных начальных чисел достаточно, чтобы контролировать разнообразие сгенерированных образцов.
Использование пакета Диффузор
Второй метод — использовать библиотеку Diffusers Hugging Face, которая содержит большинство доступных на данный момент стабильных моделей диффузии, и мы можем запустить ее непосредственно в Google Colab.
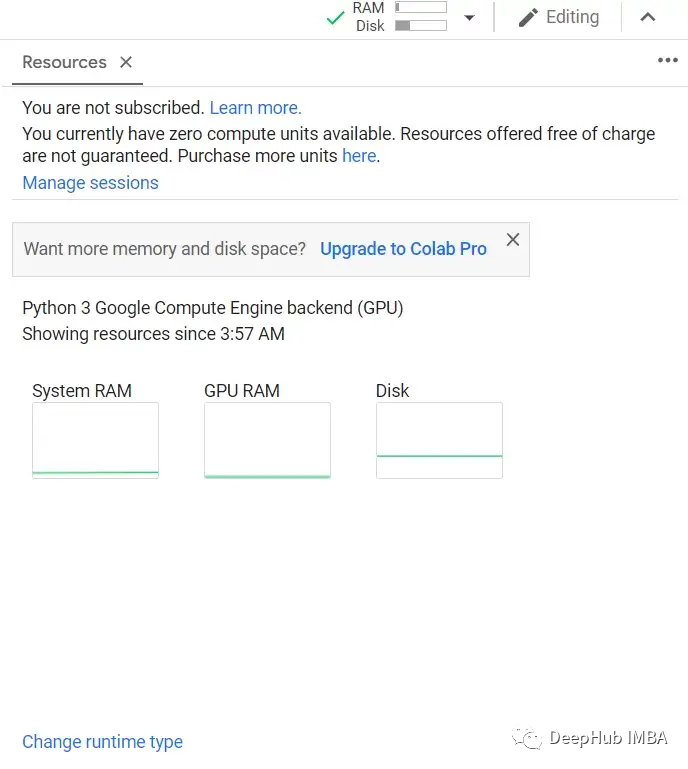
Первый шаг — открыть Google Collab и проверить, подключен ли он к графическому процессору. Проверить это можно с помощью кнопки ресурса, как показано на рисунке ниже:
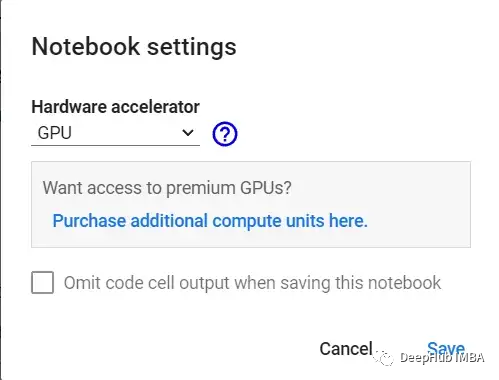
Другой вариант — выбрать «Изменить тип времени выполнения» в меню времени выполнения и убедиться, что аппаратный ускоритель выбран в качестве графического процессора:
После того, как мы убедимся, что используем среду выполнения графического процессора, используйте приведенный ниже код, чтобы увидеть, какой графический процессор мы получим.
!nvidia-smi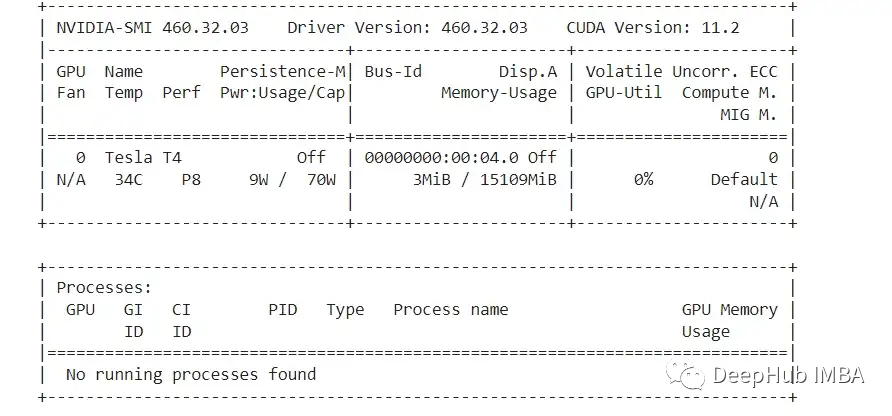
К сожалению, нам выделен только T4. Если вы сможете выделить P100, ваша скорость вывода станет выше.
Далее устанавливаем необходимые пакеты: диффузоры, scipy, ftfy и Transformer:
!pip install diffusers==0.4.0
!pip install transformers scipy ftfy
!pip install "ipywidgets>=7,<8"Дополнительные действия, необходимые здесь, — это согласиться с типовым соглашением и принять модельную лицензию, установив флажок. Зарегистрируйтесь на «Hugging Face» и получите токен доступа и многое другое.
Также для Google Collab отключены внешние виджеты, поэтому их необходимо включить. Запустите следующий код, чтобы иметь возможность использовать «notebook_login»
from google.colab import output
output.enable_custom_widget_manager()Теперь вы можете войти в Hugging Face, используя токен доступа, полученный от вашей учетной записи:
from huggingface_hub import notebook_login
notebook_login()Загрузите StableDiffusionPipeline из библиотеки диффузоров. StableDiffusionPipeline — это сквозной конвейер вывода, который можно использовать для создания изображений из текста.
Мы загрузим предварительно обученные веса модели. Идентификатор модели будет CompVis/stable-diffusion-v1-4, и мы также будем использовать функцию torch_dtype для конкретной версии. Установите номер ревизии = "fp16", чтобы загрузить веса из ветви половинной точности, и установите torch_dtype = "torch.torch_dtype = "torch.float16", чтобы указать модели использовать веса из fp16.
Такая настройка уменьшает объем памяти и работает быстрее.
import torch
from diffusers import StableDiffusionPipeline
# make sure you're logged in with `huggingface-cli login`
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16) Настройте графический процессор ниже
pipe = pipe.to("cuda")Теперь вы можете сгенерировать изображение. Мы напишем текст подсказки, передадим его в канал и распечатаем результат. Входное приглашение здесь — «космонавт верхом на лошади», давайте посмотрим на выходные данные:
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0] # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
# Now to display an image you can do either save it such as:
image.save(f"astronaut_rides_horse.png")
Каждый раз, когда вы запускаете приведенный выше код, вы получаете другое изображение. Чтобы каждый раз получать одни и те же результаты, вы можете передать ему случайное начальное число, как показано в следующем коде:
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, generator=generator).images[0]
imageВы также можете изменить количество шагов с помощью параметра num_inference_steps. Вообще говоря, чем больше шагов вывода, тем более качественные изображения получаются, но для получения результатов требуется больше времени. Если вам нужны более быстрые результаты, вы можете использовать меньше шагов.
В ячейке ниже используется то же начальное значение, что и в предыдущей, но с меньшим количеством шагов. Обратите внимание, что некоторые детали, такие как голова или шлем лошади, обозначены более расплывчато, чем на предыдущем изображении:
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, num_inference_steps=15, generator=generator).images[0]
image
Еще один параметр — масштаб навигации. Это способ улучшить соответствие условному сигналу, которым в случае диффузионных моделей является текст и общее качество выборки.
Проще говоря, загрузка без категориальной информации заставляет генерацию лучше соответствовать текстовым подсказкам. Такие числа, как 7 или 8,5, могут дать хорошие результаты. Если вы используете очень большие числа, изображение может выглядеть хорошо, но это уменьшит разнообразие.
Если вы хотите создать несколько изображений для одной и той же текстовой подсказки, просто введите один и тот же текст несколько раз. Мы можем отправить в модель список текста, давайте напишем вспомогательную функцию для отображения нескольких изображений.
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return gridТеперь мы можем генерировать несколько изображений и отображать их вместе.
num_images = 3
prompt = ["a photograph of an astronaut riding a horse"] * num_images
images = pipe(prompt).images
grid = image_grid(images, rows=1, cols=3)
grid
Вы также можете генерировать n*m изображений:
num_cols = 3
num_rows = 4
prompt = ["a photograph of an astronaut riding a horse"] * num_cols
all_images = []
for i in range(num_rows):
images = pipe(prompt).images
all_images.extend(images)
grid = image_grid(all_images, rows=num_rows, cols=num_cols)
grid
Размер сгенерированного изображения по умолчанию составляет 512*512 пикселей. Высоту и ширину сгенерированного изображения можно изменить с помощью параметров высоты и ширины. Вот несколько советов по выбору изображений хорошего размера:
Выберите параметры высоты и ширины, кратные 8. Высота и ширина установлены меньше 512.,Может привести к ухудшению качества, если оба параметра установлены на512Вышеупомянутое может привести к глобальной согласованности(Global Coherence),Поэтому, если вам нужно большое изображение, попробуйте выбрать фиксированное значение 512.,А другой больше 512. Например, следующие размеры:
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt, height=512, width=768).images[0]
image
Создайте свой собственный конвейер обработки
Мы также можем настроить диффузионные трубы и диффузоры с помощью Diffusers. Здесь мы покажем, как использовать другой планировщик, а именно планировщик K-LMS Кэтрин Кроусон.
Давайте сначала посмотрим на StableDiffusionPipeline:
import torch
torch_device = "cuda" if torch.cuda.is_available() else "cpu"Предварительно обученные модели включают все компоненты, необходимые для построения полноценного конвейера. Они хранятся в следующих папках:
text_encoder:Stable Diffusion использует CLIP, но другие модели диффузии могут использовать другие кодировщики, такие как BERT.
токенизатор: он должен соответствовать токенизатору, используемому моделью text_encoder.
планировщик: алгоритм планировщика для постепенного добавления шума к изображениям во время обучения.
U-Net: модель для создания скрытых представлений входных данных.
VAE, мы будем использовать его для декодирования скрытого представления в реальное изображение.
Компоненты можно загрузить с помощью параметра подпапки from_pretraining, указав папку, в которой сохранен компонент.
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
# 1. Load the autoencoder model which will be used to decode the latents into image space.
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. The UNet model for generating the latents.
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")Теперь вместо загрузки предустановленного планировщика мы загружаем K-LMS
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)Переместите модель в графический процессор.
vae = vae.to(torch_device)
text_encoder = text_encoder.to(torch_device)
unet = unet.to(torch_device)Определите параметры, используемые для создания изображения. Установите num_inference_steps = 100, чтобы получить более четкое изображение по сравнению с предыдущим примером.
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 100 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(32) # Seed generator to create the inital latent noise
batch_size = 1Получите text_embeddings текстовой подсказки. Затем эти внедрения используются для настройки модели U-Net.
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]Получите безусловные внедрения текста для начальной загрузки без классификатора, которые представляют собой просто внедрения, заполненные токенами (пустой текст). Они должны иметь ту же форму, что и text_embeddings (batch_size и seq_length).
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
with torch.no_grad():
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]Для неклассифицированной начальной загрузки требуются два прямых прохода. Первый — это условный ввод (text_embeddings), а второй — безусловное внедрение (uncond_embeddings). Объедините их в пакет, чтобы избежать двух проходов вперед:
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])Сгенерируйте начальный случайный шум:
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)Получающееся случайное скрытое пространство имеет форму 64*64. Модель преобразует это скрытое представление (чистый шум) в изображение размером 512*512.
Инициализирует планировщик с выбранным num_inference_steps. Это рассчитает сигму и точное значение шага, используемое в процессе шумоподавления:
scheduler.set_timesteps(num_inference_steps)K-LMS необходимо умножить значение сигмы на значение скрытого пространства:
latents = latents * scheduler.init_noise_sigmaНаконец, есть цикл шумоподавления:
from tqdm.auto import tqdm
from torch import autocast
for t in tqdm(scheduler.timesteps):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sampleЗатем используйте VAE для декодирования полученного скрытого пространства обратно в изображение:
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sampleНаконец, преобразуйте изображение в PIL, чтобы мы могли отобразить или сохранить его.
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]
Таким образом, процесс обработки полной модели устойчивой диффузии завершен. Я надеюсь, что после прочтения этой статьи вы уже знаете, как использовать Stable Diffusion и как он работает. Если у вас все еще есть вопросы о процессе его обработки, вы сможете получить более глубокое представление о его рабочем процессе с помощью пользовательских конвейеров обработки, я надеюсь, что эта статья. будет вам полезен, помог.
Если вас заинтересовала эта статья, код находится здесь: https://github.com/youssefHosni/Stable-Diffusion.
colab находится здесь: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb#scrollTo=AAVZStIokTVv
Автор: Юсеф Хосни



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
