Все, что вы хотите знать об OLAP и OLTP
Все, что вы хотите знать об OLAP и OLTP
OLAP — это аббревиатура от английского Online Analytical Processing, которая на китайском языке называется онлайн-аналитической обработкой. Это технология анализа и обработки, основанная на многомерных моделях данных, используемая для интеллектуального анализа данных и анализа с разных точек зрения, чтобы помочь пользователям быстро обнаружить корреляции и тенденции между данными.
Технология OLAP обычно включает в себя технологии предварительных вычислений, кэширования и оптимизации запросов и может использоваться для создания систем онлайн-анализа (систем OLAP). Система организует и отображает большие объемы данных по нескольким измерениям, а также предоставляет гибкие функции запросов и агрегирования для поддержки таких сценариев приложений, как принятие решений, бизнес-анализ и создание отчетов.
По сравнению с традиционными системами управления реляционными базами данных (СУБД), системы OLAP имеют более высокую скорость запросов и более широкие функции анализа. Он может запрашивать десятки миллионов или даже сотни миллионов записей за считанные секунды и поддерживает такие функции, как многомерное агрегирование, детализация, нарезка и нарезка кубиками. Поэтому технология OLAP широко используется в области бизнес-аналитики (BI) и анализа больших данных.
Так что же такое OLTP?
OLTP — это аббревиатура от онлайн-обработки транзакций, которая представляет собой технологию баз данных, используемую для управления бизнес-транзакциями. Системы OLTP обычно поддерживают высокопараллельные операции вставки, обновления, удаления и запроса данных, чтобы обеспечить работу в режиме реального времени и точность бизнеса.
В отличие от OLAP, основная цель системы OLTP — быстрое добавление, удаление, изменение и проверка бизнес-данных. Поэтому OLTP-системы должны обладать высокими характеристиками доступности, транзакций и целостности данных, чтобы соответствовать требованиям бизнес-обработки. Кроме того, система OLTP также должна иметь хорошую производительность и масштабируемость, чтобы соответствовать требованиям высокого уровня одновременного доступа и крупномасштабного хранения данных.
OLTP-системы обычно реализуются с использованием систем управления реляционными базами данных (СУБД), таких как MySQL, Oracle, Microsoft SQL Server и т. д. Эти базы данных обеспечивают строгий контроль транзакций и функции ACID для обеспечения согласованности и надежности бизнес-данных. В то же время они также предоставляют богатые функции запросов и индексирования для поддержки различных сложных бизнес-запросов и создания отчетов.
Вот различные аспекты OLAPиOLTP:
характеристика | OLAP | OLTP |
|---|---|---|
Основные сценарии использования | Анализ данных, поддержка принятия решений | обработка бизнес-транзакций |
Объем задействованных данных | Крупномасштабные данные (терабайтный или петабайтный уровень) | Данные среднего размера (уровень ГБ или ТБ) |
Целостность транзакций и данных | Не требует транзакций и фокусируется на согласованности и точности данных. | Требуется строгий контроль транзакций и характеристика ACID.,Обеспечить согласованность и надежность данных. |
Функциональные требования к использованию | Многомерный запрос, агрегирование, нарезка, детализация и т. д. | Основные бизнес-операции, такие как вставка, обновление, удаление и запрос. |
Требования к параллелизму | Чтение и запись являются относительно средними, с относительно небольшим количеством одновременных запросов. | Высокопараллельные операции вставки, обновления, удаления и запроса данных. |
План технической реализации | Механизмы обработки на основе многомерных моделей данных (таких как Kylin, Palo и т. д.) | Реляционная система управления базами данных (СУБД) (например, MySQL, Oracle и т. д.) |
Требования к доступности | Акцент на разделении «горячих» и «холодных» данных, отказоустойчивости и т. д., но не на высокой доступности. | Акцент на высокой доступности, восстановлении после сбоев, резервном копировании и аварийном восстановлении и т. д. |
Модель данных/спецификация | Многомерная модель данных с поддержкой OLAP Cube и т. д. | Реляционная модель данных, поддержка SQL-запросов и т. д. |
Техническая модель | Стеки технологий больших данных, такие как Hadoop, Spark и Hive. | Традиционные стеки технологий баз данных, такие как MySQL, Oracle и Microsoft SQL Server. |
Рекомендации OLAP
- Многомерность: модели OLAP должны обеспечивать многомерные концептуальные представления, позволяющие пользователям разрезать, разбивать на кубики, детализировать и т. д. по множеству Измеренийдействовать.
- Рекомендации по прозрачности: система OLAP должна обеспечивать прозрачный доступ к данным. Пользователи могут легко получать доступ к данным и анализировать их, не зная базовой структуры хранилища данных.
- Критерии возможностей доступа: система OLAP требует наличия эффективных возможностей доступа к данным, включая запросы, обобщение и группировку большого количества операций с данными.
- Стабильные возможности создания отчетов: система OLAP должна иметь стабильные и эффективные возможности создания отчетов, поддерживать различные формы анализа и отображения данных.
- Архитектура клиент/сервер: OLAP необходимо принять архитектуру клиент/сервер для повышения надежности, производительности и производительности.
- Критерий эквивалентности измерений: система OLAP должна поддерживать эквивалентность измерений, то есть позволять пользователям выполнять сравнения и анализ различных измерений.
- Рекомендации по обработке динамической разреженной матрицы: система OLAP требует поддержки обработки динамической разреженной матрицы, чтобы легче обрабатывать нерегулярные данные.
- Критерии возможности многопользовательского подтверждения: OLAP-система должна иметь хорошие возможности многопользовательского подтверждения и может обрабатывать запросы запросов от нескольких пользователей одновременно.
- Неограниченное межпространственное действие: система OLAP требует поддержания неограниченного межпространственного действия, что позволяет пользователям свободно переключаться и анализировать данные в разных измерениях.
- Интуитивное управление данными: OLAP-система требует поддержки интуитивно понятного управления данными, например, операций путем перетаскивания, раскрывающихся меню и т. д.
- Генерация гибких отчетов: OLAPсистема требует создания гибких отчетов, что позволяет пользователям настраивать формат и стиль отчета в соответствии со своими потребностями.
- Неограниченные измерения и уровни агрегации: OLAP требует наличия неограниченных измерений и уровней агрегации, что позволяет пользователям выполнять анализ и сравнение данных на разных уровнях.
- Производительность: OLAP должен иметь хорошую производительность и может расширять емкость и производительность в соответствии с потребностями бизнеса, например, путем добавления узлов, разделов и т. д. для достижения горизонтального расширения.
- Простота Использование: OLAP-система должна быть максимально простой и удобной в использовании. Пользователи могут легко проводить анализ посредством запросов на естественном языке, предварительной обработки и снижения затрат на обучение.
- Безопасность: система OLAP должна иметь высокую степень безопасности. Она может защитить конфиденциальность и целостность данных посредством аутентификации личности, контроля доступа и т. д., а также предотвратить кражу или подделку данных неавторизованными пользователями.
Ключевые характеристики сценариев OLAP
Характеристики чтения и записи данных
- Большинство из них — запросы на чтение
- Сценарии приложений OLAP, такие как анализ веб-сайтов и инструменты бизнес-аналитики, обычно требуют быстрого ответа на запросы запросов, поэтому большинство операций считывает данные, а не записывает их.
- данныевсегда достаточно большими партиями(> 1000 строки) писать
- Система OLAP требует эффективной загрузки данных, и часто использование инструментов ETL позволяет пакетно импортировать данные в библиотеку данных.
- Не изменяйте добавленные данные
- Данные OLAPсистемы изменяются нечасто,В основном используется для долгосрочного анализа исторических данных.,Поэтому нет необходимости обновлять записи так часто, как OLTPсистема.
Возможности запроса
- Каждый запрос считывает большое количество строк из библиотеки данных, но в то же время требует лишь небольшого количества столбцов.
- OLAPсистемануждатьсяподдерживатьбольшому количествуданныеиз Сложный анализ запросов,Поэтому обычно считывается большое количество записей.,Но возвращает только несколько столбцов, которые нужны пользователю.
- Широкие таблицы, то есть каждая таблица содержит большое количество столбцов.
- Система OLAP требует поддержки многомерного анализа данных, обычно с использованием широких таблиц (Wide Таблица) структура хранилищеданная, каждая таблица содержит большое количество столбцов.
- Меньше запросов (обычно сотни запросов в секунду или меньше на сервер)
- OLAPсистема обычно обрабатывает лишь небольшое количество запросов, но каждый запрос требует чтения большого количества данных для анализа.
- для Простой запрос, позвольте Задержаться около 50 миллисекунд
- Для некоторых простых запросов пользователи могут согласиться на определенное время задержки, но для сложных запросов пользователям необходимо быстро получать результаты.
- Данные в столбцах относительно небольшие: числа и короткие строки (например, каждый URL 60 байт)
- Данные OLAP-системы хранения обычно более аккуратны.,тип данных в столбцах все одинаковый,И относительно небольшой.
- Каждый запрос небольшой, за исключением одной большой таблицы.
- Запросы в OLAPсистеме обычно включают несколько таблиц.,Но только одна таблица содержит большое количество данных,Остальные таблицы сравнительно небольшие.
- Результаты запроса значительно меньше исходных данных.,другими словами,данныефильтрованныйили Может храниться после полимеризации.существоватьодиночный серверизв памяти
- Цель OLAPсистемы — обеспечить быстрый ответ на запросы.,Поэтому результаты запроса обычно необходимо агрегировать и фильтровать.,Получите меньший набор данных,Чтобы уменьшить накладные расходы на передачу и обработку данных.
ТТХ
- Требует высокой пропускной способности при обработке одного запроса (до миллиардов строк в секунду на сервер).
- OLAPсистемануждатьсяподдерживатьвысокая производительностьизданныеиметь дело с,Способность обрабатывать большие объемы данных,Повысьте эффективность запросов и скорость ответа.
- Бизнес не обязателен
- В системе OLAP относительно мало модификаций данных, поэтому обработка транзакций не требуется.
- Низкие требования к согласованности данных
- Данные в OLAPсистеме обычно используются для долгосрочного анализа исторических данных, и несоответствие данных можно допускать до определенной степени. Поэтому требования к согласованности данных относительно низкие.
Отличительные характеристики OLAP и OLTP
- OLAPсистема делает упор на анализ данных, а не на эффективность памяти библиотеки данных.
- Целью системы OLAP является поддержка сложного анализа данных и принятия решений.,Поэтому сосредоточьтесь на возможностях запроса и анализа.,а не эффективность памяти.
- OLAPсистема уделяет особое внимание времени выполнения SQL и дисковому вводу-выводу.,Вместо команды скорости различных показателей памяти и привязки переменных
- Системе OLAP необходимо обрабатывать большое количество данных.,Поэтому мы уделяем особое внимание производительности выполнения SQL и эффективности дискового ввода-вывода.,Повысьте эффективность запросов и скорость ответа.
- Система OLAP делает упор на секционирование,Для повышения эффективности запросов и Расширяемый。
- OLAPсистема обычно разделяет данные по определенным правилам.,Для повышения эффективности запросов и Расширяемый,И поддержка более быстрой загрузки и резервного копирования данных.
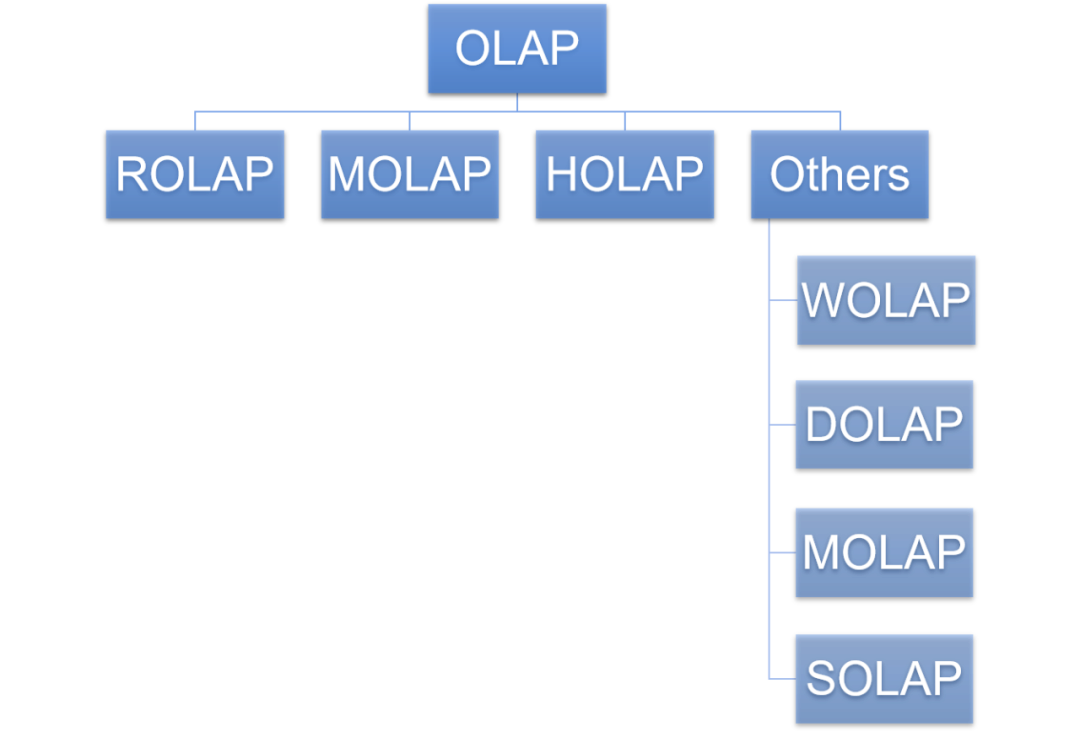
OLAP-классификация
тип | описывать | преимущество | недостаток |
|---|---|---|---|
ROLAP (реляционный OLAP) | Технология реализации OLAP на основе реляционной базы данных. | Имеет высокую производительность и может обрабатывать большое количество запросов с различными запросами, прост в управлении и обслуживании, пригоден для анализа; | Производительность слабее, чем у MOLAP; сложно поддерживать сложные многомерные отношения; для обеспечения высокой производительности требуются специализированные устройства хранения и программные среды. |
MOLAP (Многомерный OLAP) | Технология реализации OLAP на основе многомерной модели хранения. | Он обладает высокой производительностью и может быстро обрабатывать сложные многомерные запросы и операции анализа; он предоставляет богатые функции визуализации данных, облегчающие пользователям наблюдение и понимание данных; он поддерживает автономный анализ и интеллектуальный анализ данных; | Когда объем данных велик, он занимает много места; существуют определенные ограничения на операции изменения данных, он не подходит для одновременного доступа и запросов в реальном времени; |
HOLAP (гибридный OLAP) | Объединение функций ROLAP и MOLAP и использование двух технологий для создания системы OLAP. | обаROLAPиMOLAPизпреимущество,Производительность гибкий высока; поддерживает сложные многомерные запросы и анализы.,Он также может справиться с Запросом в первое время. | Требуется высокий уровень технических знаний для внедрения и обслуживания. Производительность может снизиться при обработке больших объемов данных. |
Другие (другие OLAP) | Включая другие технологии OLAP, отличные от HOLAP, такие как WOLAP, SOLAP и т. д. | Он обладает хорошей масштабируемостью и может адаптироваться к различным потребностям хранения и запроса данных. Он предоставляет определенные функции и инструменты для поддержки различных операций анализа данных. | Для обеспечения высокой и высокой производительности могут потребоваться дополнительные аппаратные и программные среды. производительность может снизиться при обработке больших объемов данных. Требуется специальное обучение и изучение различных технологий OLAP. |
OLAP-системы обычно можно разделить на три категории:
- на на основе OLAP для многомерных массивов (MOLAP): Эта система OLAPиспользует многомерные массивы для хранения данных, с быстрым откликом, высокой производительностью. производительностьждать Функции。но,MOLAPсистема сталкивается с такими проблемами, как ограничение пространства хранилища и эффективность кэша.,Особенно при работе с крупномасштабными данными,Могут возникнуть узкие места в производительности.
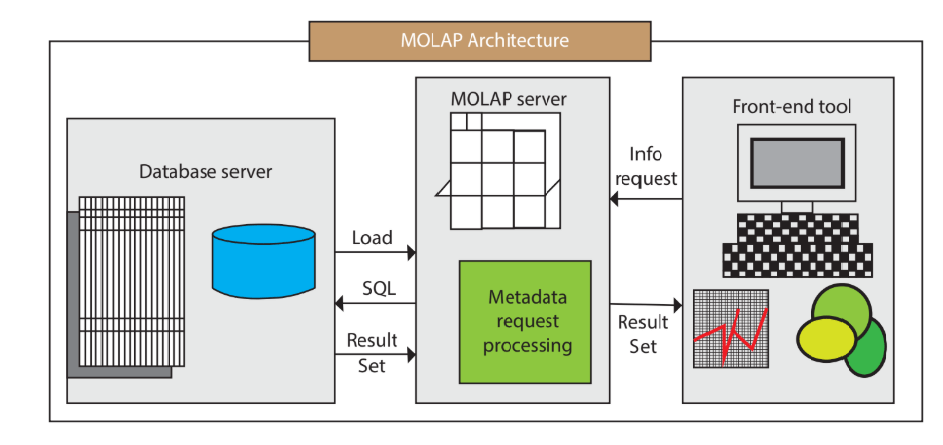
Многомерный OLAP (MOLAP) — это система OLAP, основанная на многомерных массивах или многомерных кубах. Она представляет и хранит данные в нескольких измерениях и обеспечивает быстрый анализ многомерных данных и функции запросов.
В многомерной OLAPсистеме,Данные обычно организованы в виде таблицы фактов и размеров и хранилищ. Таблица фактов содержит различные бизнес-данные и связанные с ними меры (меры).,Например, продажи, запасы и т. д., а таблица размеров содержит различную атрибутивную информацию об операции;,Такие как время, географическое положение, категория продукта и т. д. Путем соединения таблиц фактов и таблиц размеров,Это формирует многомерный куб данных.,Можно легко выполнить различные анализы данных и запросы.
Преимущество многомерного OLAP заключается в том, что он имеет быстрый отклик, высокую производительность、Простота в использованииждать Функции,Умение проводить различный сложный многомерный анализ и запросы,Например: нарезка и детализация данных разных размеров, одновременный анализ нескольких измерений, анализ в соответствии с временными тенденциями и т. д. также,Многомерная OLAP-система также обладает свойством гибкий и расширяемый.,Поддержка динамически добавляет новые Размерыимера и многое другое.
Поскольку я суммирую все популярные платформы OLAP, рассматриваемые в этой статье, я четко отделю платформы, которые будут классифицированы ниже, от краткого описания в начале.
- MOLAP — это технология, реализующая OLAP на основе многомерной модели хранилища.,Типичными представителями являются Друид и Кайлин.
- В МОЛАП,Предварительно агрегированные данные будут генерироваться на основе определяемых пользователем размеров данных, измеряемых при записи данных.,Чтобы ускорить поиск, подействуйте,Подходит для относительно фиксированных сценариев запросов.,И сценарии, требующие очень высокой производительности запросов.
- Преимущество MOLAP заключается в том, что он позволяет избежать большого количества вычислений в реальном времени во время процесса запроса посредством предварительной обработки, тем самым повышая производительность запроса. Он также обеспечивает расширенный анализ, такой как многомерный анализ и интеллектуальный анализ;
- Недостаток MOLAP заключается в том, что размеры необходимо определить заранее.,Ограничивает гибкость последующих запросов; добавление новых индикаторов требует повторного добавления процесса предварительной обработки;,стоимость хранилища также выше;,Применяется только к агрегированным запросам.
- MOLAP поддерживает некоторые агрегатные функции,Например, сумма, среднее значение, количество и т. д.,Выполните расчеты на этапе предварительной обработки,И позвонил при запросе. Эти функции можно использовать только для запроса предварительно агрегированных данных.,Невозможно запросить исходные данные.
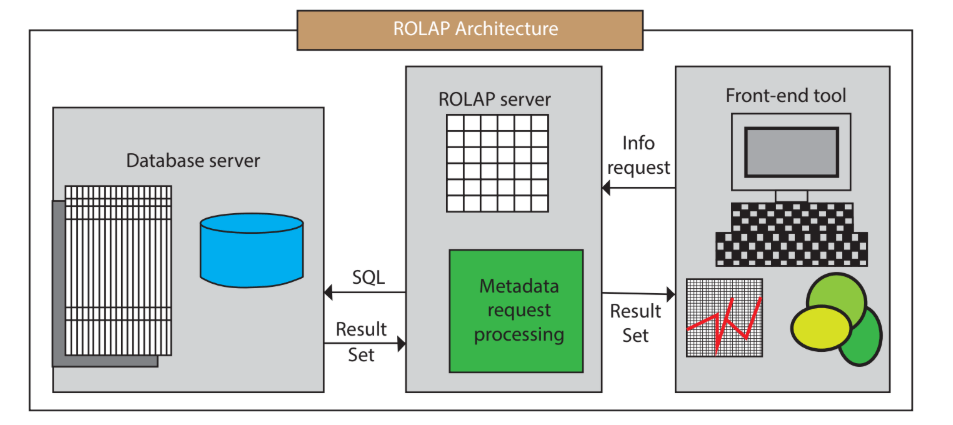
- на на основе Библиотека реляционных данных для OLAP (ROLAP): Эта система OLAPиспользовать реляционные данные Для запроса данных используется библиотечная технология, которая является более гибкой и расширенной, чем система MOLAP. Однако ROLAPсистема занимается Сложным При использовании запроса могут возникнуть проблемы с производительностью.
- ROLAP (реляционный Типичные представители OLAP) включают Presto, Impala, GreenPlum, Clickhouse, Elasticsearch, Hive, Spark. SQL、Flink SQL。
- ROLAP не использует технологию предварительной полимеризации.,Рассчитывается на лету при поступлении запроса на запрос,Предварительно агрегированные данные для оптимизации скорости запросов отсутствуют.
- ROLAP не требует предварительной обработки данных.,Итак, запросите гибкий,Расширяемыйхороший секс。этоиспользоватьMPPАрхитектура,Может эффективно обрабатывать большие объемы данных.
- Недостатком ROLAP является то, что при большом объеме и более сложном запросе,Производительность запросов не может быть такой стабильной, как у MOLAP, все вычисления запускаются мгновенно;,Это потребует больше вычислительных ресурсов,Приводит к потенциальному двойному счету.
- ROLAP подходит для сценариев, в которых режим запроса не фиксирован и производительность запросов высока.,Например, продукты для анализа данных, обычно используемые аналитиками данных.
- Гибридный OLAP (HOLAP): эта система OLAP сочетает в себе две технологии MOLAP и ROLAP.,Оба поддерживают быстрый многомерный анализ данных и запросы.,Вы также можете использовать мощные функции запросов и вычислений библиотеки реляционных данных. но,HOLAPсистеме необходимо обрабатывать множество различных наборов данных разного типа.,Могут возникнуть проблемы с производительностью или согласованностью.
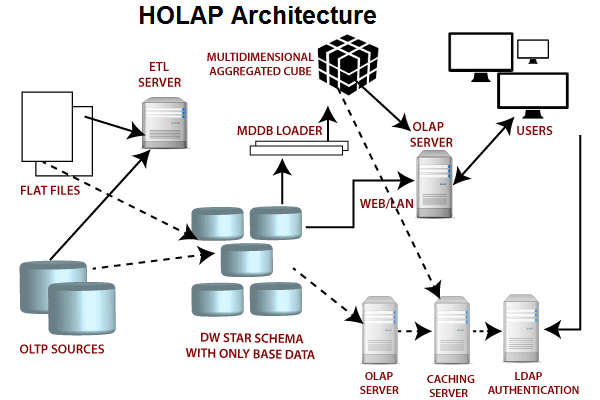
- Гибридный OLAP сочетает в себе преимущества MOLAP и ROLAP, обеспечивая быстрый доступ ко всем уровням агрегации.
- В гибридном OLAP,Агрегированное хранилище информации на OLAP-сервере,А подробные записи хранятся в базе данных соответствующих данных. поэтому,Дубликаты подробных записей не сохраняются.,Сбалансированные требования к дисковому пространству.
- Недостаток гибридного OLAP заключается в том, что ему необходимо поддерживать как MOLAP, так и ROLAP, поэтому сама архитектура также очень сложна.
- Другие (другие OLAP),Не из основной категории,Давайте использовать его в качестве справочного материала для расширения ваших знаний.
- Другие (другие OLAP) включают в себя различные технологии OLAP, кроме HOLAP.,нравитьсяWOLAP、DOLAP、MOLAPи СОЛАП и т. д.
- Веб-приложение хранилища данных OLAP (WOLAP) на основеWeb, позволяющее пользователям получать доступ к аналитическим данным в браузере.
- Desktop OLAP (DOLAP) — это OLAP, который работает на персональном компьютере или рабочей станции и обычно обрабатывает небольшие наборы данных.
- Mobile OLAP (MOLAP) — это OLAPсистема, разработанная специально для мобильных устройств.
- Пространственный OLAP (SOLAP) — это OLAP, который работает с пространственными данными.,поддержка карт и приложений ГИС и многое другое.
OLAP-архитектура
Концептуальная записка
- Serde:сериализациядесериализация,serialize/deSerialize
- MPP:крупный масштаби ХОРОШОиметь дело стехнология (Massively Parallel Processor)
Подробности
- OLAP-архитектуру в зависимости от типа запроса можно разделить на специальный запрос и сплошной запрос. Специальные запросы, написанные от руки SQL Выполните некоторые временные требования к анализу данных, такие как SQL Форма изменяема, логика сложная, жестких требований к времени запроса нет. Закрепленный запрос относится к некоторым определенным требованиям к извлечению и чтению данных, которые предоставляются пользователям в форме продуктов данных, тем самым повышая эффективность анализа и операций с данными. Этот тип SQL Режим фиксированный и имеет более высокие требования к времени отклика.
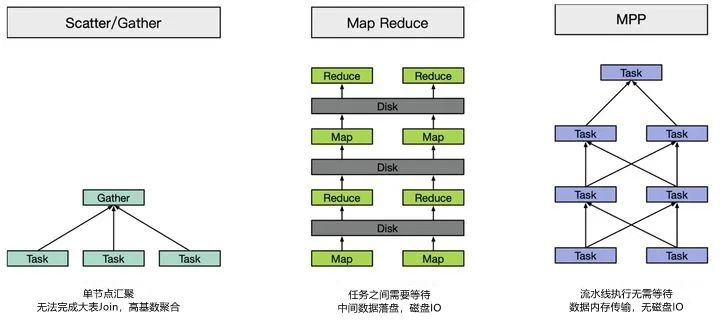
- мейнстрим OLAP двигатель можно разделить на MPP Архитектурасистема(нравитьсяPresto、Impala、SparkSQL、Drillждать)、поискдвигатель Архитектураизсистема(нравитьсяElasticsearch、Solrждать)и Предварительные вычислительная система (нравиться Друид、Килинждат).MPP Архитектурасистема В основном используетсяраспределенный Запросдвигатель,вместоиспользовать Hive+MapReduce Архитектура, тем самым повышая эффективность запросов; система поиска двигателя Архитектура преобразует данные в инвертированный индекс при входе в базу данных, используя Scatter-Gather Вычислительная модель может обеспечить ответ на поисковые запросы за доли секунды. Однако для запросов, которые в основном сканируют и агрегируют, по мере увеличения объема обработки время ответа также снижается до минутного уровня; вычислительная система предварительно агрегирует данные при вводе в базу данных, еще больше жертвуя гибкой производительностью ради достижения реакции второго уровня на чрезвычайно большие наборы данных.
- В выборе OLAP При построении структуры следует учитывать три аспекта: затраты на строительство хранилищ данных, затраты на установку и разработку. Конкретное содержание, связанное с этими тремя аспектами, включает интеграцию данных, разработку модели данных, ETL. Выбор инструментов, размера сервера, лицензионных сборов и т. д. Кроме того, вам также необходимо учитывать масштабируемость, стабильность и безопасность системы Простота. использованияждатьфактор。
- OLAP Преимущества Основанные хранилища данных представляют собой предметно-ориентированные, интегрированные, исторические и неизменяемые хранилища данных, а также многомерную модель, многоперспективную и многоуровневую организационную форму данных. Если эти две точки разделены, OLAP перестанет существовать, и преимущества не будет вообще. Этот метод хранилища может быстро реагировать на запросы пользователей и повышать эффективность анализа данных и операций. Кроме того, ОЛАП Двигатель также обеспечивает многомерный анализ, нарезку и нарезку кубиками, кэширование и сжатие и т. д., тем самым улучшая производительность и пропускную способность запросов.
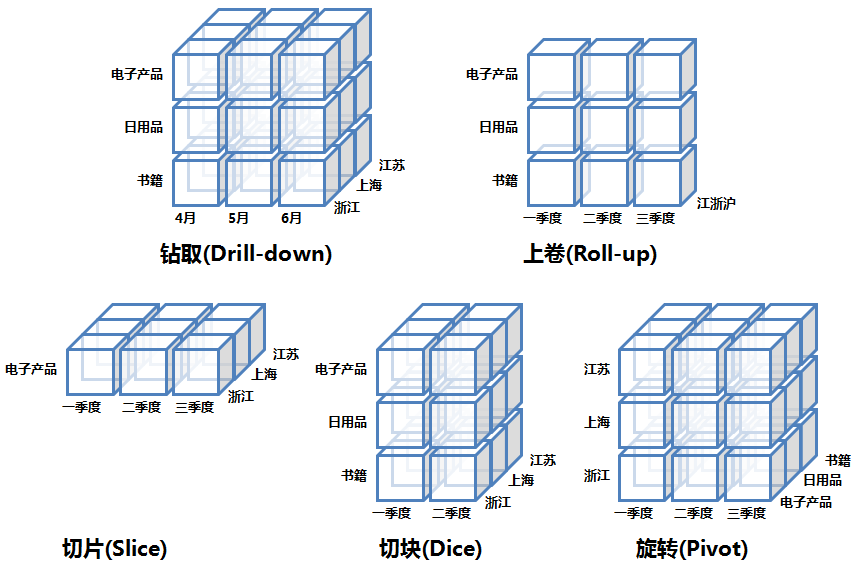
Общие операции механизма OLAP
Содержание общих операций в механизмах OLAP:
действовать | описывать |
|---|---|
Свернуть/Свернуть | Выберите определенные измерения, по которым агрегируются факты. Например: SELECT dim_a, aggs_func(fact_b) FROM fact_table GROUP BY dim_a |
Детализация/Детализация | Выберите определенные измерения, разберите их на более мелкие измерения (например, годы на месяцы, провинции на города), а затем агрегируйте факты. |
Нарезка, нарезка кубиками | Выберите определенные измерения и отфильтруйте значения этих измерений по конкретным значениям, чтобы разрезать исходный большой куб на маленькие кубики. Например: dim_a IN («CN», «США») |
Поворот/Поворот/Поворот | Смена позиции размера |
Сравнение движка OLAP с открытым исходным кодом
Сводка контрастности шести двигателей OLAP с открытым исходным кодом: Impala, Presto, ClickHouse, Doris, Druid и TiDB:
двигатель | Ситуация с открытым исходным кодом | преимущество | недостаток | Простота использования | самостоятельное хранение |
|---|---|---|---|---|---|
Impala | проект Апач | Поддерживает метаданные Hive, совместим с Hive SQL, использует архитектуру MPP и имеет высокую скорость отклика. | Не поддерживается Array тип часть Hadoop Отсутствие интеграции внутри экосистемы | Легче начать, но сложнее настроить | Зависит от хранилища HDFS или Kudu. |
Presto | Фейсбук с открытым исходным кодом | Поддерживает несколько источников и форматов данных с высокой масштабируемостью. | Производительность значительно падает при обработке больших объемов данных | Язык запросов поддерживает ANSI SQL. | Положитесь на внешнее хранилище (например, HDFS, S3 и т. д.) |
ClickHouse | Яндекс с открытым исходным кодом | Разработан для хранения столбцов с высокой скоростью запросов, высокой степенью сжатия и хорошей масштабируемостью. | Поддерживает только SQL92 Стандартная грамматика, Не поддерживается Неструктурированные данные, такие как JSON и XML. | Простой в использовании, богатый учебный материал | Колонная система хранения |
Doris | проект Апач | Он использует структуру хранения на основе столбцов для обработки сотен миллиардов строк данных с высокой скоростью запросов и легкостью расширения. Он поддерживает множественную запись и легко расширяется. Он предоставляет RESTFUL API и имеет хорошую техническую поддержку. | Не подходит для запросов со сложной структурой и отсутствием документации по разработке. | Поддержка протокола MySQL, легко начать работу | На основе хранилища HDFS |
Druid | проект Апач | Поддерживает сверхбыстрый совокупный запрос и прием данных в реальном времени, надежную масштабируемость, простоту установки, настройки и использования, а также высокоактивное сообщество. | Отличная производительность для данных временных рядов, но недостаточная поддержка данных, не относящихся к временным рядам. | Нет внешнегохранилище,самостоятельное хранение Сильная способность | самостоятельное хранение |
TiDB | PingCAP с открытым исходным кодом | Отличные возможности обработки распределенных транзакций, поддержка моделей данных SQL и NoSQL. | Производительность запросов к большим наборам данных немного ниже, а производительность автономной версии не идеальна. | Поддержка протокола MySQL, легко начать работу | Распределенная база данных NewSQL |
Я надеюсь, что это резюме будет вам полезно. Следует отметить, что,Приведенная выше информация может измениться по мере обновления версии двигателя.,Пожалуйста, обратитесь к официальным документам и последней информации.
Начнем с некоторых закусок. Давайте кратко резюмируем структуру OLAP, которая будет далее подробно проанализирована, и сначала оставим какое-то впечатление в нашем сознании.
Введение
- Impala:
Impala разработана Cloudera с открытым исходным кодом и представляет собой SQL-платформу. on Решение Hadoop. Похоже на: Улей,Но отказался от MapReduce,Использование технологии библиотекиMPP повышает скорость выполнения запросов. Impala может напрямую запрашивать хранилище данных HDFSиHBase.,И поддержка плавно соединяется с существующей хранилищем. Требует отдельной установки,PAAS является основной рекомендацией в компании. Предоставление интерфейса JDBC и механизма выполнения SQL.,Легко интегрируется с существующей системой.
- Presto:
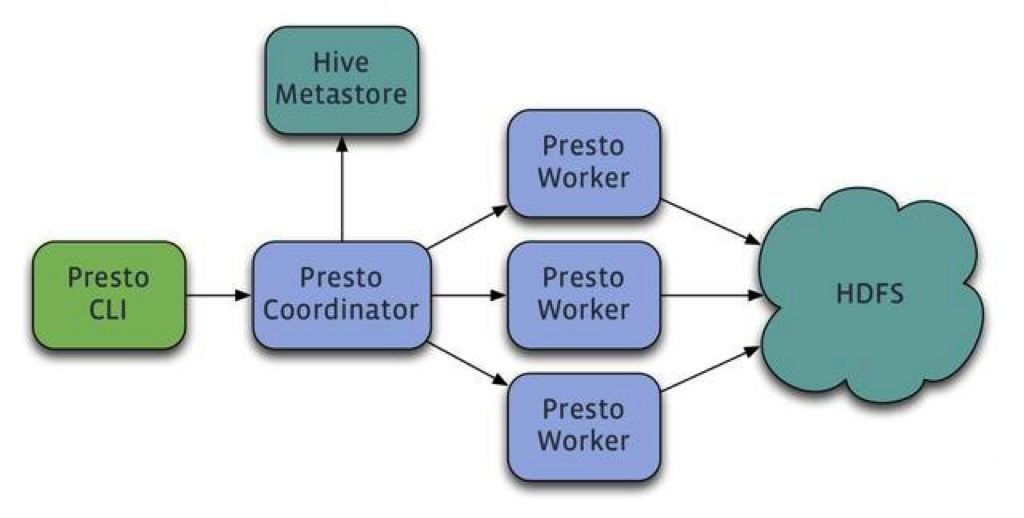
Prestoда Фейсбук с открытым исходным кодомизбольшойданные Запросдвигатель,Предназначен для решения проблемы низкой скорости запросов Hive. использовать Написано на Java,Все операции обрабатываются в памяти. Нативная интеграция с Hive, HBase и реляционными библиотеками. Предоставление интерфейса JDBC и механизма выполнения SQL.,Легко интегрируется с существующей системой.
- Druid:
Druidиспользовать Предварительные вычисление способа решения на основе данных временных рядов, задача агрегирования запроса. Данные могут быть получены в режиме реального времени и немедленно доступны для просмотра, при этом данные практически неизменяемы. Обычно События фактов на основе временных рядов поступают в Druid, и внешняя система может запросить этот факт. Нужны предварительные Вычисляя, поместите хранилища данных в файл Segment Druid, занимающие определенные ресурсы хранилища. в поддержку SQL недружелюбен и должен быть написан на собственном диалекте Druid. Никакая внешняя память не требуется, самостоятельно давая сильные способности.
- Kylin:
Kylin — OLAPданный двигатель.,проходить Предварительные расчет кэширует многомерныйданный куб, заданный пользователем, для достижения цели быстрого запроса. Сценарий приложения предназначен для сложного SQL. Кэш данных после присоединения. Его необходимо предварительно вычислить, чтобы собрать данные в кубы и сохранить их в HBase. Предоставляет интерфейс JDBC и службы REST для простой интеграции с существующими системами.
- Redis:
Redis может синхронизировать анализируемые данные с Redis и быстро запрашивать их в нем. Данные за этот месяц можно синхронизировать с Redis перед анализом.
контраст
Возможности параллелизма
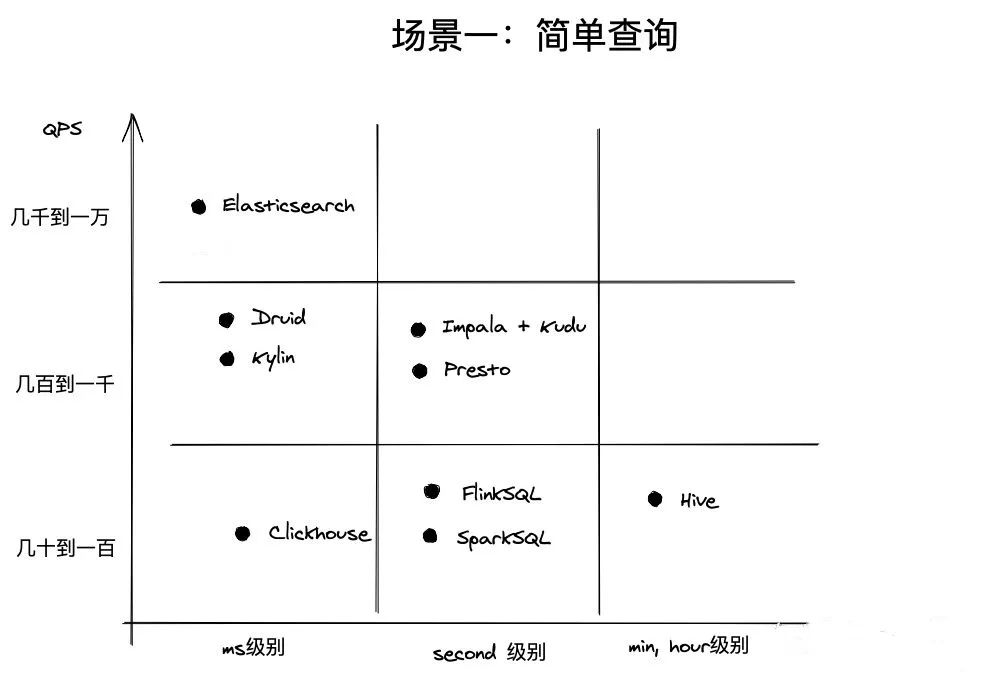
- Простой запрос:
- Импала: отличная производительность,Отлично справляется с параллельными запросами,Может поддерживать тысячи клиентов одновременно.
- Presto: имеет лучшую производительность и может поддерживать до сотен клиентов.
- Друид: поддерживает высокий уровень параллелизма,Параллельный запрос,Возможности параллелизма кластера можно расширить за счет добавления узлов.,Подходит для обработки нескольких потоков данных.
- Kylin:Благодаря механизму Предварительных вычислений с использованием слоя Cubing.,Кубы в кеше можно быстро получить при запросе,Таким образом, он также имеет сильное одновременное одобрение.
- Redis: имеет чрезвычайно высокие возможности параллелизма и может легко обрабатывать уровни QPS до 100 000.
Простой запрос
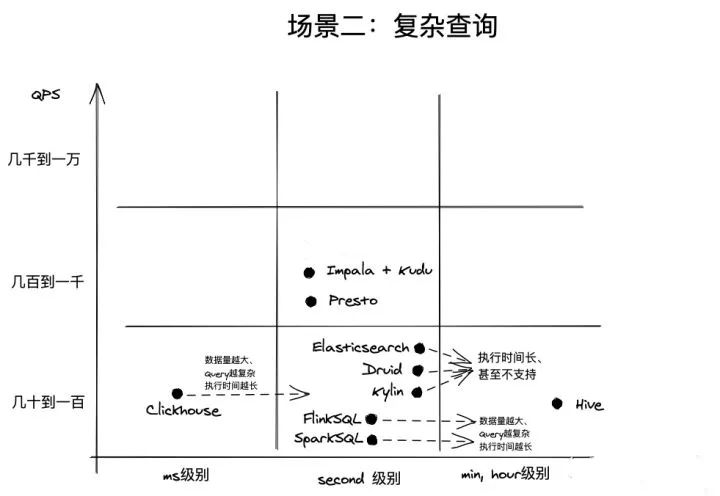
- Сложный запрос:
- Импала: на нее может повлиять более крупная Задержка в сценариях Сложных запросов.,Но по-прежнему возможно обрабатывать значительное количество одновременных запросов.
- Presto: в простоте и Сложный все сцены запроса выполнены хорошо, но Сложный Корпус запроса За поддержку немного выше, чем у Импалы.
- Druid: запрос агрегирования данных временных рядов,Задержка очень низкая. Но если вам нужно иметь дело с непоследовательными данными,Тогда Задержка станет существенно выше.
- Кайлин: по-прежнему имеет сильную поддержку параллелизма,Благодаря механизму Предварительных вычислений с использованием слоя Cubing.,существовать Сложный Его по-прежнему можно эффективно обрабатывать в сценариях запроса.
- Redis: не очень хорошо справляется со Сложным запрос, подходящий для обработки простых сценариев запросов.
Сложный запрос
Возможности параллелизма
- Impala: отличная производительность в параллельных запросах.,Может поддерживать тысячи клиентов одновременно.
- Престо: Не так хорошо, как Impala, для большого количества одновременных запросов, но все же может поддерживать до сотен клиентов.
- Друид: поддерживает высокий уровень параллелизма,Параллельный запрос,Возможности параллелизма кластера можно расширить за счет добавления узлов.,Подходит для обработки нескольких потоков данных.
- Kylin:Благодаря механизму Предварительных вычислений с использованием слоя Cubing.,Кубы в кеше можно быстро получить при запросе,Таким образом, он также имеет сильное одновременное одобрение.
- Redis: имеет чрезвычайно высокие возможности параллелизма и может легко обрабатывать уровни QPS до 100 000.
Запрос Задерживатьконтраст:
- Impala:существовать Простой В сцене запроса Задержка выступила отлично. Но в Сложном В сценарии запроса на Импалу может повлиять более крупная Задержка.
- Presto: в простоте и Сложный Оба хорошо работают в сценарии запроса, но запрос За поддержку обычно немного выше, чем у Impala.
- Druid: запрос агрегирования данных временных рядов,Задержка очень низкая. Но если вам нужно иметь дело с непоследовательными данными,Тогда Задержка станет существенно выше.
- Kylin:Благодаря механизму Предварительных вычислений с использованием слоя Cubing.,Кубы в кеше можно быстро получить при запросе,Поэтому имеет очень низкую Задержку.
- Redis: потому что все данные обрабатываются в памяти.,Таким образом, запрос Redis на поддержку очень низкий.
Контрастность модели исполнения:
- Impala:использоватьMPPАрхитектура,поддерживать Параллельный запрос,Подходит для обработки большого количества мелкомасштабных данных.
- Presto:поддерживатьраспределенный Запросииволосы Запрос,Может обрабатывать более сложные запросы. Но поскольку использование виртуальной машины Java на одном узле выполняет запрос,,Таким образом, производительность может пострадать.
- Друид: принимает столбчатую структуру хранилища.,поддерживают эффективный запрос агрегации. Но из-за отсутствия сложных SQL-запросов,Поэтому он не подходит для обработки других запросов.
- Kylin:использоватьCubeруководить Предварительные вычисленияикэш,Кубы в кеше можно быстро получить во время запроса.,Отлично справляется со сложными запросами OLAP.
- Redis: поскольку все данные обрабатываются в памяти.,поддерживать Эффективныйизключевое значениедействовать,Подходит для обработки простых сценариев запросов.
Hive
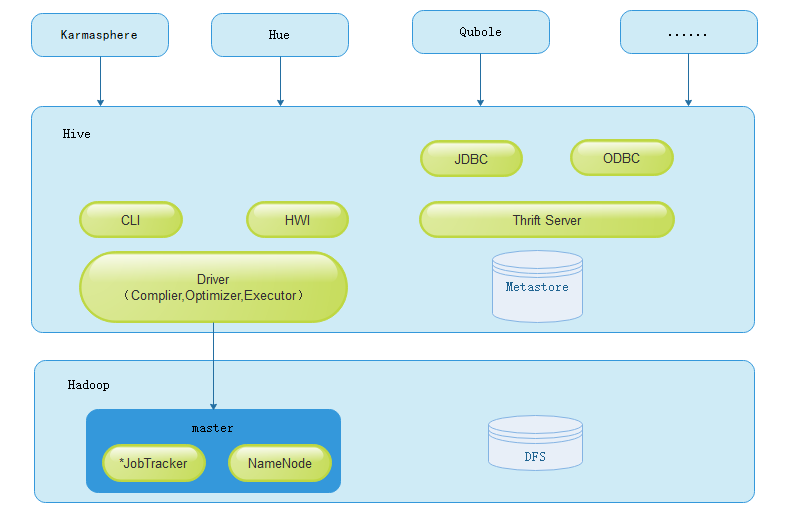
Hive — это распределенное решение SQL на Hadoop, которое может выполнять распределенные вычисления на основе базовой модели вычислений MapReduce. Он хорошо справляется с длительной пакетной обработкой в автономном режиме, и чем больше объем данных, тем более очевидны его преимущества. Поэтому Hive очень популярен среди крупных интернет-компаний с большими объемами данных и сильными потребностями, ориентированными на данные.
Однако в последние два года, по мере роста популярности Clickhouse, многие компании перешли на решения Clickhouse для нужд интернет-хранилищ данных с общим объемом данных не более ста петабайт. По сравнению с Hadoop/Hive Clickhouse имеет следующие преимущества:
- Отдельные запросы выполняются быстрее.
- Не полагается на Hadoop.
- Архитектура, эксплуатация и обслуживание проще.
Таким образом, Clickhouse может быть лучшим выбором для компаний, которым требуются небольшие хранилища больших данных с более высокой скоростью запросов и более простой структурой.
Spark SQL、Flink SQL
В большой части сцены,Скорость вычислений Hive слишком низкая. Даже для специальных запросов к внутренним продуктам, операциям и аналитикам данных.,Я часто жалуюсь, что выполнение Hive слишком медленное. Не говоря уже о потребности в высоком количестве запросов в секунду и низком уровне запросов на поддержку внешних онлайн-сервисов. Эти болевые точки способствовали рождению и развитию моделей итерации памяти MPP и вычислительных моделей DAG.,примернравитьсяSpark SQL、Flink Такие технологии, как SQL и Presto, в настоящее время очень популярны на предприятиях.
По сравнению с Hive, Spark SQL и Flink SQL имеют более высокую скорость выполнения, богатые API-интерфейсы программирования, поддерживают как потоковые вычисления, так и пакетную обработку, а также имеют тенденцию к унификации потоков и пакетов, что упрощает приложения с большими данными. Поэтому в сценариях, требующих высокой производительности и низкой задержки, Spark SQL и Flink SQL могут быть лучшим выбором.
Presto
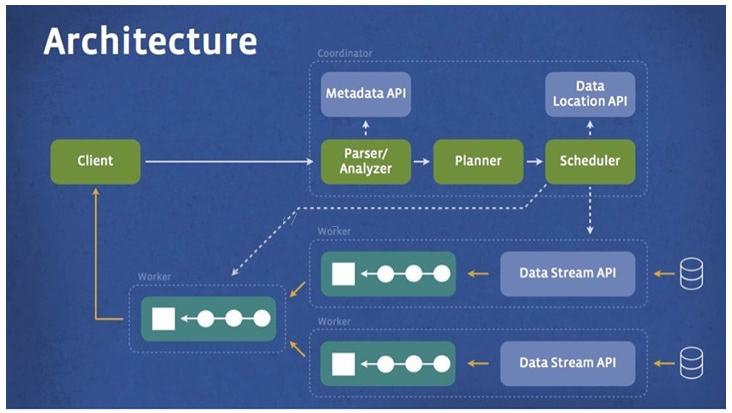
Для баз данных архитектуры MPP, таких как Presto и Apache. Дрель и Апач Impala и Greenplum и т. д., все они имеют следующие функции:
- распределенные вычисления:Этиданные Библиотекаиспользоватьраспределенные вычислительная технология, которая обрабатывает данные параллельно на нескольких узлах. Каждый узел отвечает только за свои частичные и предоставляет локальные результаты вычислений.
- Поддержка SQL:Этиданные БиблиотекаподдерживатьSQLЗапросязык,Можеткудобноруководить Запрос и анализ данные. В то же время они также используют методы оптимизации, такие как вычисления векторизации столбчатых хранилищ, для повышения производительности запросов.
- Масштабировать:Этиданные Библиотекаподдерживать Масштабировать,Вычислительные мощности хранилища можно расширить за счет добавления дополнительных узлов. Это позволяет им удовлетворять потребности крупномасштабных коллекций и высокого уровня одновременного доступа.
- Запрос в реальном времени:Этиданные Библиотекаподдерживать Запрос в реальном времяи Интерактивный анализ данных может возвращать результаты запроса в течение миллисекунд. Это делает их подходящими для обработки бизнес-сценариев в реальном времени, таких как анализ журналов в реальном времени и потоковая обработка.
Суммируя,Библиотека данных MPP Архитектура имеет распределенные вычисления, поддержку SQL, масштабирование Запрос в первую очередь. время и функции. Эти функции делают их очень подходящими для обработки больших объемов данных в сценариях приложений с высокой степенью одновременного доступа.,нравитьсяв реальном временибревноанализировать、Рекомендации по электронной коммерции、Поиск и искусственный интеллект и другие области.
Базы данных с архитектурой Elasticsearch, Druid, Kylin и MPP в настоящее время являются популярными решениями для обработки и анализа больших данных. Между ними существуют следующие различия:
- архитектурные узоры:ElasticsearchиMPPАрхитектураизданные Библиотекаиспользоватьраспределенные Режим вычисления хранилища распределяет хранилища данных по нескольким узлам и использует возможности кластерных вычислений для эффективной обработки и анализа данных. А Друид и Килин более сосредоточены В области OLAP для повышения производительности запросов используются такие технологии, как столбчатые хранилища и многомерные агрегированные запросы.
- Применимые сценарии:ElasticsearchВ основном используется для полнотекстового поиска.ив реальном временибревноанализироватьждатьполе,MPPАрхитектураизданные Библиотекабольше подходит для уровня предприятияданныесклад Библиотека、существоватьонлайн-торговляиметь дело сив реальном времениданныеанализироватьждатьсцена。DruidиKylinзатем применяется кна Сценарии применения базомногомерного анализа.
- Возможности обработки данных и производительность запросов:ElasticsearchиMPPАрхитектураизданные Библиотекаподдерживатьв реальном времениданныеиметь дело сиинтерактивный Запрос,Результаты запроса могут быть возвращены в течение миллисекунд. Druid и Kylin обладают более высокой производительностью и возможностями анализа многомерных агрегирующих запросов.
- Технический порог и сложность:ElasticsearchиMPPАрхитектураизданные Библиотекаизразвертыватьи Техническое обслуживание является относительно более сложным,нуждатьсядолженизтехнология知识иопыт。иDruidиKylinтогда имеет тенденцию Простота в использованииихороший。
Помимо таких факторов, как режим архитектуры, применимые сценарии, возможности обработки данных и технические пороговые значения, также необходимо учитывать такие показатели производительности, как рекламный документ и количество запросов в секунду.
- ad-doc:существоватьбольшойданныеиметь дело сианализироватьв поле,ad-doc(average document count per запрос) обычно представляет собой среднее количество документов, участвующих в каждом запросе. Более низкие значения ad-doc обычно означают более высокую скорость ответа на запросы и более высокие возможности одновременной обработки запросов. В этом плане библиотеки данных Elasticsearch и MPP Архитектура показали лучшую производительность, тогда как Druid и Kylin могут иметь некоторые ограничения.
- QPS:QPS(Query Per Second) представляет собой количество запросов, которые могут быть обработаны в секунду, а также является одним из важных показателей для измерения производительности системы. Более высокое значение QPS обычно означает более высокую скорость ответа на запрос и более высокую возможность одновременной обработки запросов. В этом плане библиотека данных MPP Архитектура в целом показывает более высокую производительность, чем другие решения, тогда как Elasticsearch и Druid и т. д. относительно слабы.
- QPS для одной машины:существовать单机развертыватьиз Состояние Вниз,Elasticsearch может обрабатывать тысячи запросов в секунду.,Библиотека данных MPP Архитектура может обрабатывать десятки тысяч запросов в секунду.,Друид и Кайлин могут обрабатывать от сотен до тысяч запросов в секунду.
- Развертывание кластера:существовать Развертывание В случае кластера возможности QPS этих решений будут различаться. Для библиотеки данных Elasticsearch и MPP Архитектура они поддерживают горизонтальное расширение и балансировку нагрузки, а другие технологии могут улучшить пропускную способность запросов и возможности одновременной обработки запросов всей системы за счет добавления дополнительных узлов. Такие решения, как Druid и Kylin, также легко развернуть, но их масштабируемость относительно слаба и требует больше ручной настройки и настройки.
- Возможность обработки запрошенного QPS:существоватьиметь дело с Запроспо запросу,Существуют также определенные различия в возможностях QPS разных решений. Например,При работе с простыми агрегатными запросами,Производительность запросов Druid и Kylin обычно выше, чем у библиотеки данных Elasticsearch и MPP Архитектура при работе с такими сценариями, как анализ журналов в реальном времени;,Библиотека данных Elasticsearch и MPP Архитектура может работать лучше.
Сводная информация о задержке и характеристиках источников данных баз данных с архитектурами Elasticsearch, Druid, Kylin и MPP.
1. Задержка
1.1 Elasticsearch
Elasticsearch — это инструмент поиска и анализа с открытым исходным кодом.,В основном используется в таких областях, как полнотекстовый поиск и анализ журналов в реальном времени. Он поддерживает обработку данных в реальном времени и интерактивные запросы.,Результаты запроса могут быть возвращены в течение миллисекунд. Время ответа на запрос Elasticsearch обычно составляет несколько сотен миллисекунд.,Для таких сценариев, как анализ журналов в реальном времени, может быть достигнута скорость ответа на запрос на уровне миллисекунд. Elasticsearch может выполнять поиск в больших объемах документов в режиме реального времени.,И он обладает хорошей горизонтальной масштабируемостью и возможностями балансировки нагрузки. в то же время,Elasticsearch также можно интегрировать с различными источниками данных.,Например, MySQL, Oracle, MongoDB и т. д.
Варианты использования:
- На веб-сайтах электронной коммерции после того, как пользователи вводят ключевые слова для поиска, Elasticsearch может быстро возвращать результаты поиска по ключевым словам из огромной библиотеки продуктов, улучшая качество поиска.
- В сценарии анализа журнала,Elasticsearch может помочь предприятиям быстро находить и анализировать большие объемы данных журналов.,Найдите проблемы и решите их.
1.2 Druid
Druid — это система хранения данных и запросов с открытым исходным кодом для анализа OLAP, использующая такие технологии, как столбчатое хранилище и многомерные агрегирующие запросы. При обработке простых запросов агрегации время ответа на запрос Druid обычно составляет от десятков до сотен миллисекунд. Druid в основном подходит для источников данных на основе событий и источников данных временных рядов и может выполнять онлайн-анализ и обработку данных в высокопроизводительных потоках данных в реальном времени. В то же время Druid также поддерживает пакетную загрузку статических данных, например чтение журналов из кластера Hadoop.
Варианты использования:
- В индустрии мобильных игр,Druid можно использовать для мониторинга поведения пользователей на мгновение.,Такие как регистрация, вход в систему, оплата и т. д.,и выполнить анализ в режиме реального времени,Для улучшения пользовательского опыта и качества продукта.
- В сфере умного дома,Druid можно использовать для управления данными о состоянии и поведении устройства.,И делайте прогнозы и рекомендации на основе истории действий пользователя и его жизненных привычек.
1.3 Kylin
Kylin — распределенный OLAP-движок с открытым исходным кодом.,Может сохранять крупномасштабные данные в Hadoop.,А также поддержкамногомерный совокупный запрос и быстрая фильтрация. При работе со сложными многомерными запросами агрегации,Время ответа на запрос Kylin обычно составляет от нескольких секунд до десятков секунд. Кайлину требуется больше времени на сборку,В то же время требования к источникам данных относительно строгие. Кайлин работает с источниками данных, ориентированными на строки.,Основная функция — реализация OLAP-анализа.
Варианты использования:
- в финансовой индустрии,Kylin может использоваться для обработки больших объемов транзакционных данных.,И проводим многомерный анализ и формирование отчетов,Помочь руководству принимать более эффективные бизнес-решения.
- в телекоммуникационной отрасли,Kylin может использоваться для обработки записей звонков пользователей, текстовых сообщений, трафика и т. д. данных.,к Контролируйте качество сетиколичествоибизнесоперации Состояние。
1.4 База данных архитектуры MPP
MPPАрхитектураизданные Библиотекада Что-то вродевысокая производительностьизраспределенныйданные Библиотекасистема,Он имеет хорошие возможности горизонтального расширения и балансировки нагрузки. Библиотека данных MPP Архитектура подходит для крупномасштабных хранилищ данных и приложений уровня предприятия. Он способен обрабатывать различные источники данных типа,Включая структурированные, полуструктурированные и неструктурированные данные. в то же время,MPPАрхитектураизданные Библиотекатакжеподдерживатьи Несколькоданныеисточникруководитьвзаимныйдействовать,Такие как Hadoop, NoSQL, RDBMS и т. д.
Варианты использования:
- в финансовых учреждениях,Библиотеку данных MPP Архитектура можно использовать для обработки данных транзакций и информации о клиентах.,Для управления рисками и бизнес-анализа.
- в розничной торговле,Библиотеку данных MPP Архитектура можно использовать для обработки записей о покупках клиентов и информации о запасах.,Повысить эффективность цепочки поставок и удовлетворенность клиентов.
2. Характеристики источника данных
При выборе обработки данных и анализа решения также необходимо учитывать характеристики источника данных. Вот различные источники, к которым применимы эти четыре решения:
2.1 Elasticsearch
Elasticsearch работает с текстом, журналами, метриками и другими структурированными или полуструктурированными данными. Он поддерживает индексацию в реальном времени для быстрого хранения, поиска и анализа больших объемов данных документа. В то же время Elasticsearch также можно интегрировать с различными источниками данных, такими как MySQL, Oracle, MongoDB и т. д.
Варианты использования:
- в социальных сетях,Elasticsearch можно использовать для управления пользовательским контентом.,Например, фотографии, видео, посты и т. д.
- На сайте электронной коммерции,Elasticsearch можно использовать для управления информацией о продуктах и данными заказов.,Чтобы лучше понять потребности клиентов.
2.2 Druid
Druid работает с источниками данных на основе событий и источниками данных временных рядов. Он поддерживает многомерные агрегатные запросы и быструю фильтрацию, обеспечивая онлайн-анализ и обработку данных в высокопроизводительных потоках данных в реальном времени. В то же время Druid также поддерживает пакетную загрузку статических данных, например чтение журналов из кластера Hadoop.
Варианты использования:
- В игровой индустрии,Druid можно использовать для мониторинга активности игроков и доставки ее в хранилище данных в режиме реального времени.,Для анализа и отчетности.
- существовать Интернет вещейв поле,Druid можно использовать для мониторинга состояния устройства и проведения анализа в режиме реального времени.,И уведомите соответствующий персонал с помощью пороговых оповещений.
2.3 Kylin
Kylin подходит для источников данных, ориентированных на строки, и его основная роль — реализация OLAP-анализа. Для обработки больших объемов агрегированных данных требуются предварительные вычисления и кэширование, а также загрузка данных в Kylin из различных источников данных (таких как Hive, HBase, MySQL, PostgreSQL и т. д.) с помощью инструментов ETL.
Варианты использования:
- в телекоммуникационной отрасли,Kylin может использоваться для обработки записей звонков, текстовых сообщений, трафика и т. д. данных.,И проводим многомерный анализ и формирование отчетов,кпомощьоперации Поставщики могут лучше сформулироватьизбизнес Стратегия。
- в здравоохранении,Kylin можно использовать для обработки данных пациента и информации о лекарствах.,И провести многомерный анализ и отчитаться.
2.4 База данных архитектуры MPP
Библиотека данных MPP Архитектура подходит для крупномасштабных хранилищ данных и приложений уровня предприятия. Он способен обрабатывать различные источники данных типа,Включая структурированные, полуструктурированные и неструктурированные данные. в то же время,MPPАрхитектураизданные Библиотекатакжеподдерживатьи Несколькоданныеисточникруководитьвзаимныйдействовать,Такие как Hadoop, NoSQL, RDBMS и т. д.
Варианты использования:
- в финансовых учреждениях,Библиотеку данных MPP Архитектура можно использовать для обработки данных транзакций и информации о клиентах.,И проводить управление рисками и бизнес-анализ.
- в телекоммуникационной отрасли,Библиотеку данных MPP Архитектура можно использовать для записи вызовов и данных о трафике.,И выполнять мониторинг и обслуживание сети.
Clickhouse
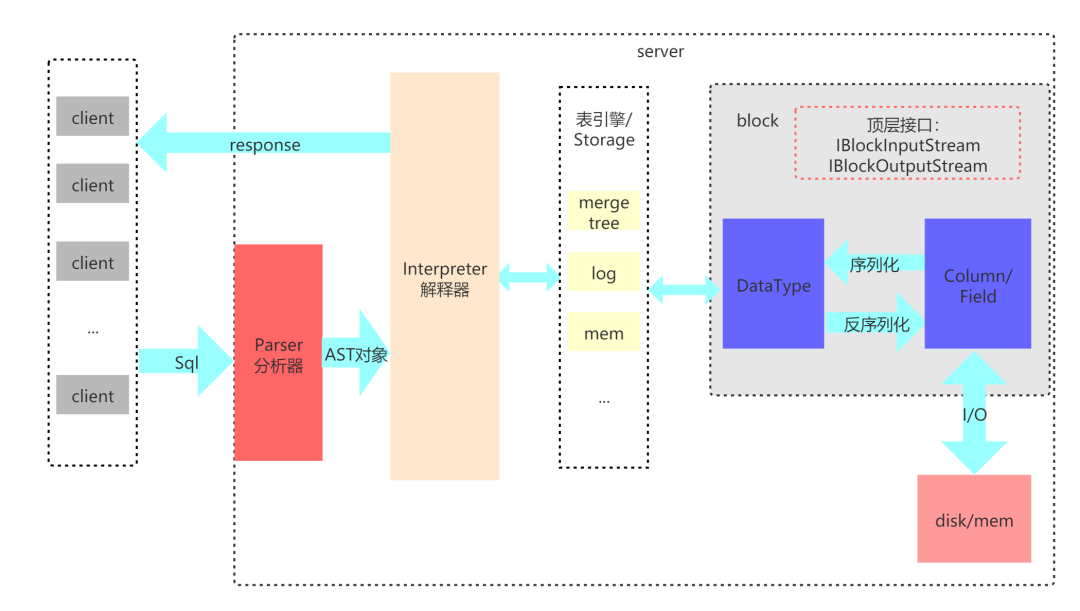
ClickHouse — это столбчатая база данных с открытым исходным кодом, которая в последние годы привлекла большое внимание и в основном используется в области анализа данных (OLAP). В настоящее время отечественное сообщество находится на подъеме, и крупные производители последовали его примеру и использовали его в больших масштабах.
ClickHouse исходит из потребностей сценариев OLAP,Настроен и разработан новый набор высокоэффективных формул колонного двигателя.,И добился упорядоченного хранения данных, индекса. первичного ключа、разреженный индекс、данныеSharding、данныеPartitioning、TTL、Основное и резервное копирование и другие богатые функции. Вышеупомянутые функции вместе закладывают основу для чрезвычайно быстрого выполнения анализа ClickHouse.
ClickHouse имеет простую архитектуру развертывания, прост в использовании и не зависит от системы Hadoop (HDFS+YARN). Что он хорош, так это выполнение агрегатных запросов к одной таблице с большим объемом данных. Clickhouse реализован на C++. Базовая реализация имеет возможности оптимизации, такие как векторизованное выполнение (Vectorized Execution) и сокращение ветвей, а также обеспечивает высокую производительность запросов. В настоящее время широко используемый в интернет-компаниях, он больше подходит для внутренних приложений типа отчетов BI и может обеспечить скорость ответа с малой задержкой (уровень мс), что означает, что одиночный запрос выполняется очень быстро.
Но у Clickhouse есть и свои ограничения.,При выборе технологии OLAP,Его следует избегать в качестве двигателя для запросов на объединение нескольких таблиц (JOIN).,Вам также следует избегать его использования в сценариях, где вы ожидаете поддержки высококонкурентных запросов.,В сценарии анализа OLAP,Обычно считается, что QPS достигает 1000+, что считается высоким параллелизмом.,Вместо таких бизнес-сценариев, как электронная коммерция и получение красных конвертов,,10 Вт или более считается высоким уровнем параллелизма.,Ведь сцена анализа данных,данные Массивный,Расчет сложный,Достичь 1000 QPS непросто. Например Кликхаус,Если сумма соответствует уровню ТБ,Агрегационные расчеты немного сложнее.,Как правило, для одного кластера очень сложно достичь показателя QPS 100.,Поэтому он больше подходит для внутренних приложений отчетов BI предприятия.,Он не подходит для отчетов о приложениях, связанных с сотнями тысяч рекламодателей или миллионами владельцев магазинов Taobao. Модель выполнения Clickhouse определяет, что она сделает все возможное для выполнения запроса.,Вместо одновременного выполнения множества запросов.
ElasticSearch
Я написал много статей об Elasticsearch в своем блоге.,Потому что он рожден из люцены,Lucene хорошо известна как поисковая система. Опираясь на инвертированную структуру индекса сортировки Lucene,Плюс поддержка сегментации текста,Поэтому поле поиска можно назвать лидером. И производительность тоже очень высокая,По сути, это кластер из трех узлов.,Он может легко поддерживать более 1000 qps. Вы думаете, что его мощь применима только к сценариям поиска? На самом деле нет,Он предоставляет мощные функции агрегирования.,Хотя это структура json,Но их можно конвертировать друг в друга с помощью традиционного sql.
Пример:
Заявление об агрегации Elasticsearch:
{
"aggs": {
"orders_per_month": {
"date_histogram": {
"field": "order_date",
"interval": "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "order_total"
}
},
"average_sales": {
"avg": {
"field": "order_total"
}
}
}
}
}
}Смысл приведенного выше оператора запроса агрегирования заключается в вычислении общего количества заказов (total_sales) и средних продаж (average_sales), сгруппированных по месяцам (интервал: месяц), и их отображении в каждом месяце.
Оператор SQL-запроса:
Используйте язык запросов SQL Impala, чтобы преобразовать приведенный выше оператор агрегирования в оператор запроса SQL, примерно следующим образом:
SELECT
DATE_TRUNC('month', order_date) AS month,
SUM(order_total) AS total_sales,
AVG(order_total) AS average_sales
FROM
my_table
GROUP BY
month;Смысл приведенного выше оператора SQL-запроса заключается в вычислении общего количества заказов (функция SUM) и средних продаж (функция AVG) путем группировки (предложение GROUP BY) по месяцам (функция DATE_TRUNC) и отображении результатов для каждого месяца.
Elasticsearch как механизм OLAP может дать следующие преимущества:
- Эффективный запрос и анализ данных:Elasticsearchиздокументхранилище Модельитехнология инвертированного индекса,Это делает его идеальным для запросов к хранилищам неструктурированных или полуструктурированных данных. в то же время,Elasticsearch предоставляет богатые функции агрегирования.,Анализ данных и статистика могут быть легко выполнены. Это позволяет Elasticsearch поддерживать эффективную производительность при обработке больших и сложных коллекций.
- Горизонтальное масштабирование и высокая доступность:Elasticsearchдаодинраспределенныйсистема,поддерживать горизонтальное расширение,Данные могут быть распределены по нескольким узлам хранилища обработки. в то же время,Elasticsearch также предоставляет механизм репликации.,Обеспечить высокую доступность данных. Это позволяет Elasticsearch легко справляться с требованиями массового доступа с высоким уровнем параллелизма.
- Гибкое моделирование и обработка данных:Elasticsearchдаодин面向документизданные Библиотека,Разрешить пользователям свободно определять структуру документа,И поддержка динамически добавляет и удаляет поля. Это позволяет Elasticsearch адаптироваться к различным потребностям моделирования и обработки данных.,примернравитьсяв реальном временибревноанализировать、Рекомендации по электронной коммерции、Поиск и другие сценарии.
Двигатель выполнения запроса Elasticsearch основеScatter-Gather Модель MapReduce, ниже приводится описание взаимосвязи между ними:
- Scatter:ElasticsearchиспользоватьShard(Шардинг)какданныеиметь дело сизнаименьшая единица。существоватьScatterэтап,Запросы будут распределяться по нескольким шардам для выполнения. Каждый Шард отвечает только за обработку своих частей.,и возвращает часть результата.
- Gather:существоватьGatherэтап,Результаты, возвращаемые одним и тем же шардом, будут объединены в набор результатов. Эти результаты могут быть перераспределены на большее количество осколков для дальнейшего расчета и проверки.
- MapReduce:существоватьMapReduceэтап,Выполните фильтрацию, агрегирование и расчет результирующего набора. в,Этап «Карта» преобразует и расширяет результаты.,Фаза сокращения объединяет и сводит результаты.
Elasticsearch можно понимать как простейший метод Scatter-Gather. Используя модель MapReduce, Elasticsearch может эффективно обрабатывать большое количество запросов данных. В частности, данная модель имеет следующие преимущества:
- Распределенная обработка: Scatter-Gather MapReduceМодельиспользоватьраспределенные вычислительная технология, распределяющая хранилища обработки данных по нескольким узлам. Это позволяет Elasticsearch легко справляться с крупномасштабными коллекциями и сценариями с высоким уровнем одновременного доступа.
- Высокоэффективный запрос. Модель Scatter-Gather MapReduce разбивает запросы запросов на несколько подзадач и выполняет их параллельно на нескольких узлах, тем самым повышая эффективность запросов.
- Компьютерная модель гибкий: Scatter-Gather Модель MapReduce использует вычислительную модель MapReduce, которая выполняет различные типы обработки, такие как агрегирование, фильтрация и сокращение.
Эта структура функций также определяет ее применимую сферу деятельности, поскольку обмен данными на узле является приоритетным. на основе памяти, вместо того, чтобы сначала записывать на диск при каждом перетасовке, как MapReduce. Структура данных Lucene с обратной сортировкой на самом деле представляет собой смешанный режим хранения строк и столбцов, и при выполнении запросов она может ускорять запросы данных через FPS и пропускать таблицы, поэтому, когда объем данных невелик, производительность по-прежнему очень высока. . Но если оно развернуто только на одной машине, то такого рода на основе Дизайн, улучшающий концепцию QPS, приведет к крайне медленному исполнению, на что следует обратить внимание при развертывании.
Elasticsearch имеет следующие недостатки как двигатель OLAP:
- Не подходит для высоких нагрузок записи.:Elasticsearchиз Основные цели дизайнадабыстрый Запросианализироватьданные,а не высокое одновременное письмо. Когда большое количество документов необходимо удалить с помощью частых обновлений,Производительность Elasticsearch может пострадать.
- Не хватает строгой поддержки транзакций.:ElasticsearchНе В традиционных СУБД операции являются строго транзакционными, поэтому при работе с транзакционными операциями могут возникнуть некоторые проблемы. Например, если одновременно выполняется несколько запросов на обновление, может возникнуть состояние гонки или конфликт.
- Высокая сложность и технический порог:ElasticsearchИмеет множество расширенных функций,Чтобы в полной мере воспользоваться этими функциями, от пользователя требуется определенный технический уровень. также,Развертывание и обслуживание Elasticsearch также требуют соответствующих технических знаний и опыта.
- Емкость хранилища для одной машины ограничена:Elasticsearchиз Емкость хранилища для одной машины Ограничена Из-за аппаратных ресурсов и количества узлов, когда кластер данных вырастает до определенного масштаба, может потребоваться расширение кластера для удовлетворения потребностей хранилища.
Например: используйте Elasticsearch для поиска продуктов по запросу «двигатель» на веб-сайте электронной коммерции для обработки онлайн-транзакций (онлайн-транзакций). Transaction Processing)。
В этом примере приложение Java может выполнять с Elasticsearch следующие действия:
- Запись и обновление данных:Когда пользователи просматривают товары,Приложения Java могут записывать информацию о продукте в индекс Elasticsearch. Когда пользователь покупает товар,Приложения Java могут обновлять такую информацию, как запасы продукции и продажи.
- Поиск и фильтрация в реальном времени:когда пользовательруководитьтоварпоискчас,Приложения Java могут использовать возможности полнотекстового поиска Elasticsearch.,Запрос в реальном времени и вернуть список подходящих продуктов. В то же время приложения Java также могут использовать функцию совокупных запросов Elasticsearch для добавления цены, бренда, спецификаций и других условий фильтрации к результатам поиска.
- Оптимизация производительности и расширение:Java应用程序МожеткиспользоватьElasticsearchизраспределенный Архитектура,Распространение крупномасштабных наборов данных в хранилищах вычислений,отинестивысокая производительность и Расширяемый. Например, поместить разные товары в разные индексы и разделить нагрузку с Shard.
В частности, приложения Java могут использовать Java API взаимодействует с кластером Elasticsearch через протокол HTTP для реализации описанных выше действий. Этот код Java продемонстрирует, как использовать Elasticsearch Java. API для добавления документов в индекс:
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
IndexRequest request = new IndexRequest("my_index");
request.id("1");
String jsonString = "{" +
"\"name\":\"John\"," +
"\"age\":30," +
"\"city\":\"New York\"" +
"}";
request.source(jsonString, XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());RestHighLevelClient подключается к кластеру Elasticsearch, создает индекс с именем «my_index» и добавляет в индекс документ, содержащий имя, возраст и информацию о городе.
Impala
Impala:
- базовая реализация:Impalaиспользоватьсвоего родана основанная на столбцах память, хранилище-двигатель, который отличается от платформы Hadoop MapReduce. В Impala данные хранятся в виде столбцов на диске и могут быть сжаты и закодированы перед запросом. Это позволяет Impala быстро сканировать большие объемы данных с очень высокой производительностью и низким уровнем затрат.
- Поддерживаемые языки:ImpalaподдерживатьстандартныйSQLграмматика,Включая ВЫБРАТЬ, ОТКУДА, ГРУППУ ПО ПРИКАЗУ BY и другие ключевые слова. Кроме того, Impala также поддерживает UDF (определяемые пользователем функции) и UDAF (определяемые пользователем агрегатные функции), которые могут быть написаны на таких языках, как C++ или Java.
- Широкая перспектива:ImpalaМожеткпрямой ЗапросHDFSиApache данные в HBase и могут быть легко интегрированы с другими компонентами экосистемы Hadoop, такими как Apache. Hive、Apache Искра и Апач Кафка и др. Impala поддерживает несколько форматов файлов, включая Parquet, Avro, SequenceFile и TextFile и т.д. В то же время Impala также предлагает различные запросы, такие как базовые запросы, запросы соединения, запросы групповой агрегации, запросы оконных функций и т. д.
Кроме того, с точки зрения совместимости данных Impala также имеет некоторые преимущества:
- HBase:HBaseдаодин开источникизраспределенныйNoSQLданные Библиотека,Он может работать в кластере Hadoop. Поддержка Impala напрямую запрашивает данные в HBase,и рассматривать ее как реляционную таблицу.
- Hive:Hiveдаодинна основано на хранилище данных Hadoop, которое предоставляет SQL-подобный язык запросов и простую функциональность сводки данных. Impala можно интегрировать с Hive для запроса таблиц Hive.
- JDBC/JAR:ImpalaпредоставилJDBCиODBCразъем,使得用户МожеткиспользоватьстандартныйизSQLклиентские инструменты(примернравитьсяApache Zeppelin, Tableau и т. д.) для подключения к Impala. Кроме того, Impala предоставляет набор Java API, позволяющий пользователям встраивать его в свои собственные Java-приложения.
- Parquet/Avro:ParquetиAvroВседаHadoopэкологиясистемараспространено виз Тип столбцахранилище Формат。Impalaподдерживать Эти Формат,и может оптимизировать запросы,для лучшей производительности при чтении и записи.
Короче говоря, Impala — это инструмент, который может напрямую запрашивать данные в HDFS и HBase и легко интегрируется с Hive для запроса двигателя в SQL. Он также предоставляет соединитель JDBC и ODBC, поддержку Parquet и Avro и другие форматы файлов. Благодаря этим функциям Impala предоставляет очень широкий спектр возможностей доступа, которые можно комбинировать с другими компонентами экосистемы Hadoop, такими как Apache. Zeppelin, Tableau ожидания) легко интегрируются. Тем временем Импалана основе Памятьиз Тип столбцахранилищедвигательиоптимизация Запросалгоритм,Позволяет быстро и эффективно обрабатывать крупномасштабные данные.,И имеет крайне низкую Задержку.
Варианты использования в C++ и Java
- C++:ImpalaпредоставилгруппаC++ API позволяет разработчикам легко подключаться, запрашивать и обрабатывать данные Impala в локальных приложениях. Например, следующий фрагмент кода демонстрирует, как использовать C++. API подключается к кластеру Impala и выполняет SQL-запросы:
#include <impala/client.h>
using namespace impala;
int main() {
// Создать клиентское соединение Impala
boost::shared_ptr<ImpalaClient> client(new ImpalaClient("localhost", 21050));
// Выполнить SQL-запрос
TExecResult result;
client->Exec("SELECT * FROM my_table", &result);
// Обработка результатов запроса
if (result.__isset.data) {
for (int i = 0; i < result.data.size(); ++i) {
// Обработка каждой строки записей
}
}
}- Java:ImpalaтакжепредоставилгруппаJava API, который позволяет разработчикам использовать Impala в приложениях Java. Например, следующий фрагмент кода демонстрирует, как использовать Java. API подключается к кластеру Impala и выполняет SQL-запросы:
import java.sql.*;
public class ImpalaDemo {
public static void main(String[] args) throws SQLException {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
// Подключить Импалу
Class.forName("org.apache.hive.jdbc.HiveDriver");
connection = DriverManager.getConnection("jdbc:hive2://localhost:21050/default", "", "");
statement = connection.createStatement();
// Выполнить SQL-запрос
String sql = "SELECT * FROM my_table";
resultSet = statement.executeQuery(sql);
// Обработка результатов запроса
while (resultSet.next()) {
// Обработка каждой строки записей
}
} finally {
// тесная связь
resultSet.close();
statement.close();
connection.close();
}
}
}Kylin
Говоря о Kylink, мы должны упомянуть концепцию — систему MOLAP.
MOLAP
MOLAP (Многомерная онлайн-аналитическая обработка) — это технология хранилища данных, основанная на многомерных хранилищах данных. Он организует данные в соответствии с различными измерениями и использует агрегатные вычисления для повышения производительности запросов. MOLAP обычно имеет следующие функции:
- Сложный запрос:MOLAPМожеткподдерживатьсложныйиз Запросдействовать,Например, многомерный анализ, перспектива и нарезка данных и т. д.
- высокая производительность:MOLAPиспользовать Предварительное вычисление совокупных значенийииндекс,Таким образом, производительность запросов очень высока,И он также очень подходит для крупномасштабных наборов данных.
- Визуализация:MOLAPМожеткпроходить Различные графикии Визуализацияинструменты для демонстрации Запросрезультат,Это позволяет пользователям более интуитивно понимать данные.
MOLAP Cube
MOLAP Куб — одно из наиболее важных понятий в MOLAP. Это физическое представление многомерных данных, состоящее из множества измерений и индикаторов. МОЛАП Cubeиметьк Вниз Функции:
- многомерный:MOLAP CubeМожетк包含Несколько Размеры,примернравитьсячас间、географическое положение、Линия продуктов и группа клиентов и т. д.
- Метрики:MOLAP Каждая ячейка куба содержит один или несколько элементов, таких как продажи, прибыль, запасы и т. д.
- Предварительные вычисления:MOLAP Cubeиспользовать Предварительные вычислительная технология для ускорения обработки запросов, которая может предварительно рассчитывать совокупные значения и показатели перед выполнением запроса.
MOLAP Cube обычно содержит следующие компоненты:
- Размеры:обратитесь кданныеиз Классификация,примернравитьсячас间Размеры、географическое положение Размерыждать。
- мера:обратитесь кнуждатьсяодеяломераизданные,Например, продажи, прибыль и т. д.
- Иерархия:обратитесь кданныеиз Иерархия,примернравитьсячас间Размерысерединаиз Год、четверть、лунаждать Иерархия。
- правила агрегирования:обратитесь кнравитьсячторуководитьсовокупный расчет,примернравиться Можетиспользоватьпроситьи、средний、Агрегация по максимальным/минимальным значениям и т.д.
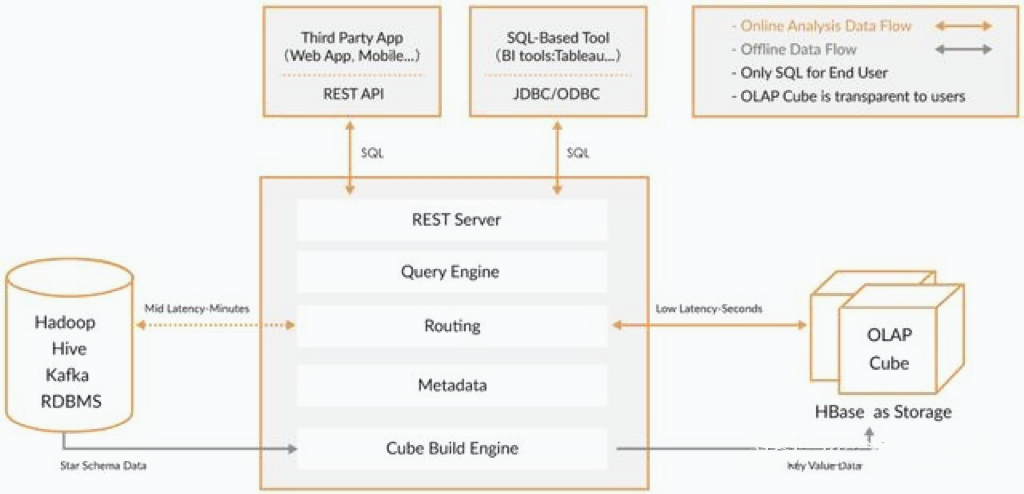
Сценарии, подходящие для Кайлина, включают:
- Объем данных: Данные пользователя существуют в Hadoop В HDFS Hive используется для реляционного доступа к файлам HDFS. Количество файлов огромно, более 500 ГБ, и каждый день постепенно импортируется несколько или даже десятки ГБ файлов.
- Размеры Связанный: Имеется менее 10 относительно фиксированных анализов.
Проще говоря, идея куба данных в Kylin заключается в обмене пространства на время. Задавая ряд широт, комбинация каждой широты предварительно рассчитывается и сохраняется. Имеется N широт и будет N комбинаций 2. Поэтому лучше всего контролировать количество широт, потому что емкость хранилища будет стремительно расти по мере увеличения широты, что приведет к катастрофическим последствиям.
Druid
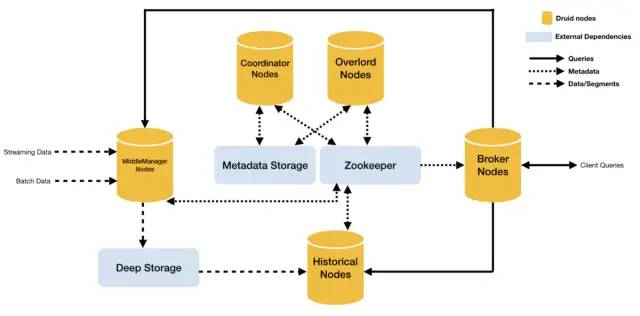
Druidда一款быстрый、гибкийиз开источникданныехранилище、Запросианализироватьдвигатель,поддерживать Обработка в режиме реального времени и пакетная обработка,и РасширяемыйприезжатьPBуровеньизданныеколичество。
Функции
- Обработка в режиме реального времени и пакетная обработка:Druidподдерживать Обработка в режиме реального времени и пакетная обработку, может транслировать события в реальном времени и хранить данные автономной истории в одной системе.
- высокая производительность:Druidдадлявысокая Благодаря высокой производительности десятки миллионов строк данных могут быть запрошены за считанные секунды.
- Особенно подходит для временных рядов:это Можетк Пучокданныепакетно по временному рядухранилище,Он очень подходит для сценариев, в которых статистический анализ выполняется с течением времени.
- Расширяемый:Druidда Расширяемыйиз,Легко масштабируется до томов петабайтного уровня.
- гибкий:Druidиз Дизайн оченьгибкий,Может быть настроен по мере необходимости,Его также можно интегрировать с другими инструментами.
- многомерныйанализировать:DruidДоступно длямногомерныйанализировать,Поддержка Быстрое переключение, группировка и фильтрация нескольких анализов.
- Простота в использовании:Druidпредоставил Простота в использованииизWeb UIиAPI позволяет пользователям удобно выполнять запросы и управление данными.
- Не подходит для непрерывного запроса с несколькими таблицами.:Определяется природными свойствами,DruidНе объединение нескольких таблиц
- Не подходит для стадии грубого просеивания.:Этот вид Состояние Вниз,一般Всеипохожий ВSparkЭтот типиз Вычислительная платформа в сочетаниииспользовать Druid — это распределенная библиотека столбцов для быстрых запросов в режиме реального времени и пакетных запросов, которую можно использовать для многомерного анализа и мониторинга. в реальном времяиданные исследования и др. Сцены. Spark — это универсальная кластерная вычислительная платформа для быстрых вычислений, которая может удовлетворить потребности крупномасштабной обработки, такие как машинное обучение и обработка графики. вычисленияждать。
- ЭТЛ данных:DruidМожетк用Вв реальном времениили Офлайнизданные Подготовитьи Чистый,А Spark можно использовать для преобразования данных и предварительной обработки данных. CanuseDruid загрузить исходные данные в Druid,Затем используйтеSpark выполняет преобразование данных и предварительную обработку данных.,Наконец, импортируйте данные в Druid для запроса и анализа.
- Запрос и анализ данных:Druidдаодин用Вмногомерныйанализироватьи Мониторинг в реальном Хранилище данных столбца времени может быстро запрашивать данные на уровне PB и предоставлять интуитивно понятный веб-интерфейс. UIиAPI. А Spark может выполнять сложные преобразования и операции анализа, такие как машинное обучение, обработка графов и т. д. Можно использовать Druid в качестве основного Запроса и анализ данныхдвигатель, а Spark можно использовать в качестве дополнения для выполнения более сложных операций обработки данных.
- Потоковые вычисления:DruidМожетк用ВМониторинг в реальном времении Потоковые вычисления, такие как потоковая передача событий в реальном времени и обработка журналов. В то же время Spark обладает мощными возможностями потоковой передачи и может быть интегрирован с такими потоками, как Kafka. Таким образом, Druid и Spark можно использовать вместе для создания крупномасштабных потоковых приложений.
- Не подходит для обработки сложных и изменяемых сценариев запросов перспективных размеров.:потому чтоDruidизданные Модельдастолбчатыйиз,иииспользоватьформула столбцахранилищедвигатель,Поэтому в сложных и изменяемых сценариях запросов могут существовать некоторые ограничения.,причинанравиться Вниз:
- Избыточность данных:Druidизданные Модельдастолбчатыйиз,Поэтому все данные необходимо разнести по разным столбцам.,Для облегчения выполнения запросов и агрегации. Для перспективных измерений сложные и изменяемые сценарии запросов,Эта избыточность может привести к тому, что набор данных окажется слишком большим.,Вызывает такие проблемы, как эффективность запросов хранилища.
- Управление индексами:Druidиспользоватьсвоего родана Метод индекса на основе Bitmap предназначен для ускорения запросов, но для сложных и изменяемых сценариев запросов может потребоваться создание большого количества индексов Bitmap, что увеличит нагрузку на систему и снизит производительность системы.
- Размеры Вывод:Druidизданные Модельнуждаться Определите все заранееиз Размеры,Для перспективных измерений сложные и изменяемые сценарии запросов,Эти размеры могут быть очень многочисленными.,и сложно определить заранее. Это требует вывода размеров во время запроса.,Повышенная сложность запросов и накладные расходы.
- Обновление данных:Druidиз Списокхранилищедвигатель Подходит для статикиданныеибыстрый Запросждатьсцена,Но для часто обновляемых и меняющихся наборов данных,Возможно, потребуется перезагрузить весь набор данных.,В результате производительность запроса снижается.
- Хорошо справляется с запросами типа сингл:некоторые общиеизsql(group мимо и т.д.) бегает на средней скорости в друиде
- Обновления вставляются медленно:Druidподдерживать低延часизданныевставлять、Новее, но лучше, чем hbase、Традиционная библиотека данных работает намного медленнее.
- Проблемы с производительностью после обращений:этотда Запросзакон,Конечно, друид не застрахован от пошлости.,У Druid могут возникнуть проблемы с производительностью, когда условия запроса затрагивают большое количество данных.,Более того, такие способности, как сортировка и агрегирование, как правило, не очень хороши.,гибкий и масштабируемости недостаточно,Например, отсутствие Join, подзапроса и т. д.
Использование
Друид широко используется в следующих сферах:
- Мониторинг в реальном времени:DruidМожетк用ВМониторинг в реальном Время и анализ системных показателей производительности приложений, журналов и потоков событий.
- рекламные технологии:DruidДоступно длярекламные технологии, включая доставку и анализ рекламы, автоматизацию маркетинга, назначение ставок в реальном времени и т. д.
- Интернет вещей:DruidМожетк用Виметь дело с Интернет Вещи Датчики оборудования, такие как температура, влажность, давление воздуха и т.д.
- игра:DruidДоступно для Мониторинг в реальном показатели производительности времениигры, поведение пользователей и платежные данные и т. д.
- электронная коммерция:DruidМожетк用Вэлектронная коммерческие поля, такие как рекомендации в реальном времени, анализ корзины покупок, отслеживание заказов и т. д.
Можно сказать, что мониторинг в реальном времени — это специальность Druid, поэтому при разработке Spring вы обнаружите, что многие компании напрямую интегрировали его в некоторые предприятия для мониторинга данных. Что делать, если вы хотите использовать Druid для мониторинга в Spring?
Пример кода для Java Spring Framework, интегрирующего Druid для мониторинга уровня доступа к данным (DAO):
- Добавьте зависимости druid-spring-boot-starter и mysql-connector-java в pom.xml.
<dependencies>
<!-- druid spring boot starter -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<!-- mysql connector java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>- Настройте источник данных Druid в файле application.properties.
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=root
# Druid configuration
spring.datasource.druid.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.druid.initial-size=5
spring.datasource.druid.min-idle=5
spring.datasource.druid.max-active=20
spring.datasource.druid.max-wait=60000
spring.datasource.druid.time-between-eviction-runs-millis=60000
spring.datasource.druid.min-evictable-idle-time-millis=300000
spring.datasource.druid.validation-query=SELECT 1 FROM DUAL
spring.datasource.druid.test-while-idle=true
spring.datasource.druid.test-on-borrow=false
spring.datasource.druid.test-on-return=false
spring.datasource.druid.filters=stat,wall
spring.datasource.druid.connection-properties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000- Создать класс сущности пользователя
public class User {
private Long id;
private String username;
private String password;
// getters and setters
}- Создайте интерфейс UserMapper и класс реализации.
@Mapper
public interface UserMapper {
@Select("SELECT id, username, password FROM user WHERE id=#{id}")
User selectById(Long id);
}
@Repository
public class UserMapperImpl implements UserMapper {
@Autowired
private JdbcTemplate jdbcTemplate;
public User selectById(Long id) {
return jdbcTemplate.queryForObject("SELECT id, username, password FROM user WHERE id=?", new Object[]{id}, new BeanPropertyRowMapper<>(User.class));
}
}- Вызовите метод selectById UserMapper в контроллере и верните результат.
@RestController
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/users/{id}")
public User getUserById(@PathVariable Long id) {
return userMapper.selectById(id);
}
}С помощью описанных выше шагов вы можете интегрировать Druid в Java Spring Framework для мониторинга уровня доступа к данным (DAO).



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
