Ведро семейства алгоритмов серии YOLO — подробное введение YOLOv1-YOLOv9! !
Предисловие
В этой статье подробно описана структура сети YOLOv1-YOLOv9, а также итерации между каждой версией.
Сравнение YOLOv1-YOLOv8Как показано в таблице ниже:
Model | Anchor | Input | Backbone | Neck | Predict/ Train |
|---|---|---|---|---|---|
YOLOv1 | Якорный ящик (7*7 сеток, 2 якоря) | resize(448*448*3): обучение — 224*224, тестирование — 448*448; | GoogLeNet (24*Conv+2*FC+reshape; Dropout для предотвращения переобучения; последний уровень использует функцию линейной активации, а остальные слои используют функции активации ReLU); | никто | IOU_Loss, нмс; сетка прогнозирует только 2 блока, и все они относятся к одной категории; полносвязный слой напрямую прогнозирует значение координаты bbox; |
YOLOv2 | Поле привязки (сетки 13*13, 5 привязок: выберите априорное поле с помощью k-средних) | изменение размера (416*416*3): 416/32=13, конечный результат заключается в том, что нечетное значение имеет фактическую центральную точку на основе исходного обучения, для которого добавляются образцы высокого разрешения 448x448 (10 эпох); тонкая настройка; | Darknet-19 (19*Conv+5*MaxPool+AvgPool+Softmax; слой FC не используется, BN и ReLU используются после каждой свертки, чтобы предотвратить переобучение (выпадение отбрасывается); предлагается сквозной слой: разделение функций с высоким разрешением. Наложение больших на функции низкого разрешения для объединения функций, что полезно для обнаружения небольших целей); | никто | IOU_Loss, нмс; сеть прогнозирует 5 блоков, каждый блок может относиться к разным категориям; прогнозирует смещение относительно блока привязки (после определенной итерации модели обучения, преобразования размера входного изображения), механизм совместного обучения; ; |
YOLOv3 | Рамка привязки (13*13 сеток, 9 привязок: три шкалы*три соотношения сторон) | resize(608*608*3) | Darknet-53 (53*Conv, BN и Leaky ReLU используются после каждого сверточного слоя для предотвращения переобучения, остаточного соединения); | FPN (многомасштабное обнаружение, объединение функций) | IOU_Loss, нмс; прогнозирование по нескольким меткам (функция классификации softmax заменена на логистический классификатор); |
YOLOv4 | якорный ящик | изменение размера (608*608*3), улучшение данных мозаики, улучшение данных обучения самоконфронтации SAT | CSPDarknet53 (модуль CSP: более богатые комбинации градиентов при сокращении вычислений, перекрестная мини-пакетная нормализация (CmBN) и активация Mish, регуляризация DropBlock (произвольное удаление большого блока нейронов), использование улучшенного механизма внимания SAM: в пространственных местоположениях добавляется вес); | SPP (сделать входные изображения разных размеров согласованными за счет максимального объединения), PANnet (изменить PAN, заменить add на concat) | CIOU_Loss, DIOU_nms; Само-противное обучение SAT: на основе исходного изображения добавьте шум и установите порог веса, чтобы нейронная сеть могла подготовиться к состязательным атакам. Сглаживание меток классов: сгладьте абсолютную метку (например: [ 0,1 ]→[0.05,0.95]), то есть результаты классификации имеют определенную степень нечеткости, что повышает способность сети противостоять переобучению; |
YOLOv5 | якорный ящик | resize(608*608*3)、Улучшение данных мозаики、Адаптивный расчет якорного ящика、Адаптивное масштабирование изображения | CSPDarknet53 (модуль CSP, BN и Leaky ReLU используются после каждого сверточного слоя для предотвращения переобучения, модуль Focus); | SPP、PAN | GIOU_Loss, DIOU_Nms; сопоставление между сетками (нахождение двух сеток, ближайших к целевой центральной точке, среди четырех сеток выше, ниже, слева и справа от текущей сетки, плюс текущая сетка, всего три сетки); |
YOLOX | никтоякорный ящик | resize(608*608*3) | Darknet-53 | SPP、FPN | CIOU_Loss, DIOU_Nms, Decoupled Head, стратегия распределения меток SimOTA; |
YOLOv6 | никтоякорный ящик | resize(640*640*3) | EfficientRep Backbone (оператор Rep) | SPP、Rep-PAN Neck | SIOU_Loss, DIOU_Nms, Efficient Decoupled Head, стратегия распределения меток SimOTA; |
YOLOv7 | якорный ящик | resize(640*640*3) | Darknet-53 (модуль CSP заменяет модуль ELAN; понижающая дискретизация становится слоем MP2; BN и SiLU используются после каждого сверточного слоя для предотвращения переобучения); | SPP、PAN | CIOU_Loss, DIOU_Nms, стратегия распределения меток SimOTA, обучение со вспомогательной головкой (за счет увеличения затрат на обучение, повышения точности без влияния на время вывода); |
YOLOv8 | никтоякорный ящик | resize(640*640*3) | Даркнет-53 (модуль C3 заменен модулем C2F) | SPP、PAN | CIOU_Loss, DFL_Loss, DIOU_Nms, стратегия распределения меток TAL, Decoupled Head; |
1. Основная идея алгоритма YOLO
Основная идея серии YOLO состоит в том, чтобы преобразовать обнаружение цели в задачу регрессии, используя всю картинку в качестве входных данных сети, а через нейронную сеть получают положение ограничивающей рамки и ее категорию.
1. Шаги алгоритмов серии YOLO
(1) Разделите изображение:YOLOВоля Разделение входного изображениядляфиксированныйразмер изсетка。
(2) Прогнозирование ограничивающей рамки и категории:для каждогосетка,YOLO предсказывает фиксированное число (обычно 5 или 3).
ограничивающая рамка. Каждая ограничивающая рамка описывается пятью основными атрибутами: положением ограничивающей рамки (координаты центра, ширина и высота) и достоверностью объекта, содержащегося в ограничивающей рамке. Кроме того, каждая ограничивающая рамка также прогнозирует класс объекта.
(3) Одиночный проход вперед:YOLOчерез сверточную нейронную сетьсеть(CNN)Сделайте одиночный пас вперед,Одновременно спрогнозируйте расположение и категории всех ограничивающих рамок. по сравнению с Другим алгоритмом обнаружения целей,Например, предлагаемый метод, основанный на скользящем окне или регионе.,YOLO имеет более высокую скорость,Потому что для завершения прогноза требуется только один прямой проход.
(4) Функция потерь:YOLOделать Использование потери многозадачностифункцияприйти на тренировкусеть。потеряфункция Включает потерю позиции、потеря доверияи Потеря категории。Измерения потерь позиций прогнозируют ограничивающие рамкиимежду реальными ограничивающими рамкамиизразница в местоположении。потеря доверияизмерить ограничительную рамкудапредсказать правильно Понятно Цель,И наказать фоновую коробку из-за уверенности. Потеря категории измеряет целевую категорию по точности прогноза.
(5) Немаксимальное подавление (Немаксимальное Suppression):в предсказанииизвнутри ограничивающей рамки,Может быть несколько перекрывающихся полей.,представляют одну и ту же цель. для Устранение лишнего из ограничивающих рамок,YOLO использует немаксимальный алгоритм подавления,Отфильтруйте лучшие ограничивающие рамки на основе достоверности и перекрытия.
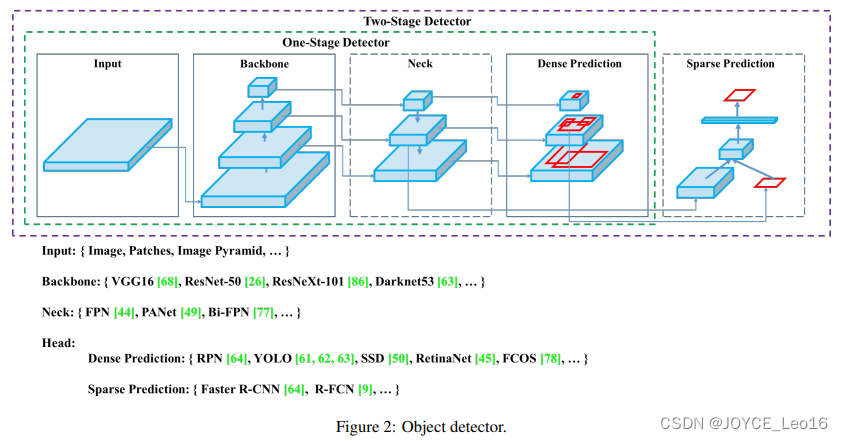
2. Позвоночник, шея и голова.
детектор объектовиз Начинаем описывать структурудлятри части:Backbone, NeckиHead。На изображении ниже показан высокий уровеньизBackbone, Neck и Схема головы.
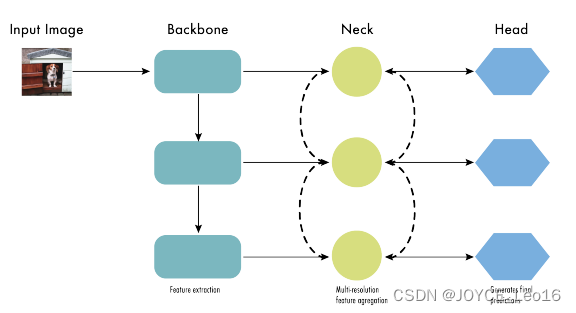
Backbone отвечает за извлечение характеристик из входного изображения.Обычно это сверточная нейроннаясеть(CNN),Обучены крупномасштабным задачам классификации изображений.,Например, ImageNet. Магистральная сеть фиксирует иерархию функций в разных масштабах.,Извлечение низкоуровневых функций (таких как края и текстуры) из более ранних слоев.,Извлекайте высокоуровневые функции (такие как части объектов и семантическую информацию) на более глубоких уровнях.
Шея – это промежуточный компонент, соединяющий позвоночник и голову.Он агрегирует и уточняет извлечение данных из магистральной сети.изособенность,Обычно он фокусируется на улучшении пространственной и семантической информации в разных масштабах. Шея может включать дополнительные сверточные слои, пирамиды признаков (FPN) или другие механизмы.,Улучшить представление функций.
Голова — последний компонент детектора объектов. Он отвечает за прогнозирование на основе функций Backbone и Neck.Обычно он состоит из одной или нескольких конкретных задач.изребеноксетькомпозиция,Выполните классификацию и позиционирование,и недавние сегментация экземпляров и оценка позы. Шея ручки головы обеспечивает из функций,для генерирует прогнозы для каждого кандидата. наконец,этап постобработки,Например, немаксимальное подавление (NMS).,Отфильтровать перекрывающиеся прогнозы,Сохраняются только обнаружения с наивысшей достоверностью.
2. Алгоритм серии YOLO
1. YOLOv1(2016)
(Бумажный адрес:https://arxiv.org/pdf/1506.02640.pdf)
1.1 Знакомство с моделью
До того, как был предложен YOLOv1, серия алгоритмов R-CNN доминировала в области обнаружения целей. Серия R-CNN имеет высокую точность обнаружения, но из-за двухступенчатой структуры сети скорость обнаружения не может соответствовать требованиям реального времени и подвергается критике. Чтобы выйти из этого тупика, общей тенденцией является более быстрый детектор объектов.
2016, Джозеф Redmon、Santosh Divvala、Ross Гиршик и др. предложили одноэтапный метод обнаружения целей. Он обнаруживает очень быстро, может обрабатывать 45 кадров в секунду и легко работать в режиме реального времени. Из-за высокой скорости и особого метода автор Воля назвал его для: You Only Look Однажды (таково полное название того, что мы часто называем YOLO) результаты были опубликованы на CVPR2016, что привлекло всеобщее внимание.
Основная идея YOLO состоит в том, чтобы преобразовать обнаружение цели в задачу регрессии, используя все изображение в качестве входных данных сети и только через нейронную сеть для получения положения ограничивающего прямоугольника и его категории.
1.2 Структура сети
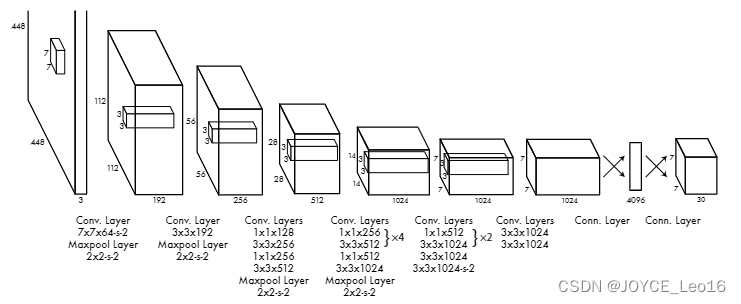
Теперь кажется, что структура сети YOLOv1 очень ясна. Это традиционная одноэтапная сверточная нейронная сеть:
- Сетевой вход:448*448*3изцветные картинки
- Средний слой:состоит из нескольких сверточных слоевимаксимальное объединениеслойкомпозиция,Используется для извлечения абстрактных особенностей изображений.
- Полносвязный слой:Зависит от Два полностью подключенныхслойкомпозиция,Используется для прогнозирования цели по положению и категории по значению вероятности.
- Сетевой выход:7*7*30из Результаты прогнозирования
1.3 Детали реализации
(1) Стратегия обнаружения
YOLOv1использоватьизда“разделяй и властвуй”из Стратегия,Воля Картинка равномерно разделена на сетки 7х7.,Каждая сетка отвечает за прогнозирование центральной точки, попадающей в сетку и цель. В более быстром R-CNN,Это получение цели из интересующей области через RPN.,Этот метод имеет высокую точность,Но нужно дополнительно обучить РПНсеть,этотникто Подозрение на усиленное обучениеизгруз。В YOLOv1,Сетка 7х7 получается делением,Эти 49 сеток эквивалентны целевой области интереса.。проходитьэтотдобрый Способ,Нам не нужно проектировать дополнительную РПНсеть,Именно это делает одноступенчатую работу YOLOv1 простой и быстрой.
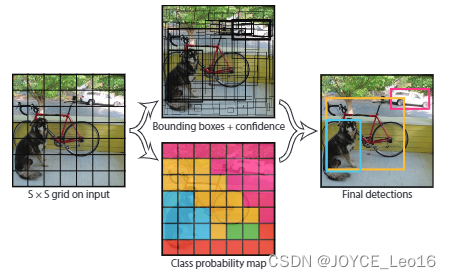
Конкретный процесс реализации выглядит следующим образом:
① Разделить изображение на.
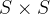
Ячейка сетки. Если центр объекта попадает в эту сетку, сеть отвечает за прогнозирование объекта.
② Каждая сетка должна предсказать B ограничивающих рамок, и каждая ограничивающая рамка должна быть предсказана.
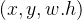
Всего у уверенности 5 значений.
③ Каждая сетка также прогнозирует информацию о категории, записанную как категории C.
④ В целом.
Сетки: каждая сетка должна прогнозировать B ограничивающие рамки и классы C. Сетевой выход представляет собой
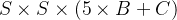
тензоров.
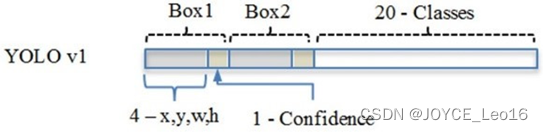
в реальном процессе,YOLOv1 делит изображение на сетки 7х7.,И каждая сетка предсказывает 2 ящика (Box1иBox2),20 категорий. Так что на самом деле,S=7,B=2,С=20. Тогда выходная форма будет следующей:
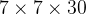
。
(2) Функция целевых потерь
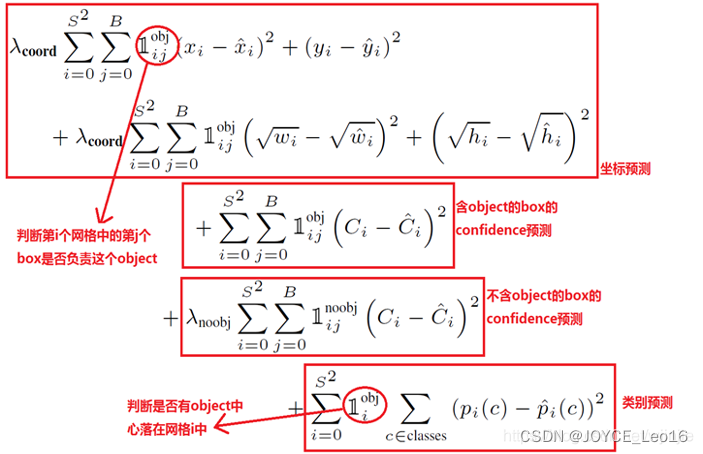
Убыток состоит из трех частей,точка Неда:Потеря прогнозирования координат, потеря достоверности прогнозирования, потеря прогнозирования категории。
- используется разница дисперсии и ошибки. Следует отметить, что из,При вычислении погрешности получаются их квадратные корни.,причинадаверно Неттакой жеразмер изbounding Предсказание в рамке по сравнению с большим ограничением Предсказание ящика немного предвзятое, а предсказание маленького ящика предвзятое, что еще более невыносимо. Функция разностной ошибки одинакова для тех же потерь смещения. Чтобы облегчить эту проблему, автор использовал более хитрый метод, заключающийся в ограничении boxizwаh извлекает квадратный корень и заменяет исходное iswаh.
- Ошибка позиционирования больше, чем ошибка классификации,Таким образом, штраф за ошибку позиционирования увеличивается.,делать
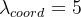
。
- в каждом изображении,Многие ячейки сетки не содержат целевых значений. Во время обучения показатели «уверенности» ячеек в этих сетках будут сведены к нулю.,Это часто превышает градиент, содержащий цель из поля градиента. Это может привести к нестабильности модели.,Обучение рано расходится. Следовательно, потеря достоверности прогнозирования для блока, который не содержит цель, уменьшается.,делать
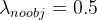
。
1.4 Производительность
(1) Преимущества
- Скорость обнаружения YOLO очень высокая. Стандартная версия YOLO может обрабатывать 45 изображений в секунду, чрезвычайно быстрая версия YOLO может обрабатывать 150 кадров в секунду; Это означает, что YOLO может достичь задержки менее 25 миллисекунд.,Обработка видео в реальном времени. Для систем с меньшими возможностями реального времени,При условии обеспечения точности,YOLO работает быстрее, чем другие методы.
- Средняя точность обнаружения YOLO в реальном времени в два раза выше, чем у других систем мониторинга в реальном времени.
- Сильная миграционная способность,Его можно применить и к другим новым областям (например, к обнаружению объектов художественного оформления).
(2) Ограничения
- YOLO пары объектов, находящихся близко друг к другу,И эффект обнаружения не подходит для небольших групп.,Это потому, что одна сетка прогнозирует только 2 поля.,И все они относятся только к одной и той же категории.
- Из-за проблемы потери функциииз,Ошибка позиционирования является основной причиной, влияющей на эффект обнаружения.,Особенно при обработке больших и малых предметов.,Еще надо укрепляться. (Потому что для небольших ограничивающих рамок,small ошибка имеет большее влияние).
- Эффективность обобщения YOLO для целей с необычными углами низкая.
2. YOLOv2(2016)
(Бумажный адрес:https://arxiv.org/pdf/1612.08242.pdf#page=4.24)
2.1 Улучшения
YOLOv2Joseph RedmonиAli Написал Фархадина CVPR 2017. Он включает в себя некоторые улучшения по сравнению с оригинальным YOLOиз.,Держите ту же скорость,Также более мощный,Возможность обнаружения 9000 категорий,этотнекоторыйУлучшите следующие моменты:
(1)Расположениеиметьна сверточном слоеизпакетная нормализацияУлучшенная сходимость,И сделайте регуляризатор, чтобы уменьшить переобучение;
(2) Классификатор высокого разрешения,иYOLOv1 то же самое,Они предварительно обучили Модель на ImageNet с разрешением 224x224. Однако,на этот раз,Доработали Модель 10 раз на разрешении для448x448изImageNet,Улучшена производительность при вводе с высоким разрешением;
(3) Полная свертка。Они снимают плотный слой,use использует полностью сверточную архитектуру.
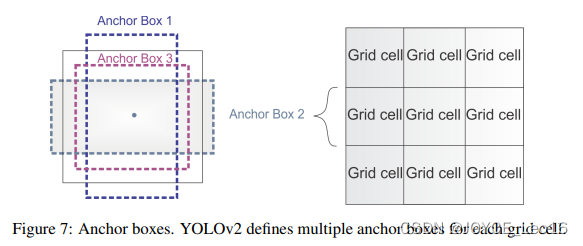
(4) Используйте привязку для прогнозирования ограничивающих рамок.。ихделать Используйте набор коробок априориAnchor,Эти якоря имеют предопределенные формы.,Используется для сопоставления объекта с формой прототипа.,Как показано на рисунке 6.,Для каждой ячейки сетки определено несколько якорей.,Система прогнозирует каждый якорь, координату и категорию. Размер вывода сети пропорционален количеству якорей на ячейку сетки.
(5) Группировка измерений。Выбирайте хорошоизAnchorиметьпомощьсеть Научитесь прогнозировать точнееизограничивающая рамка。Автор тренируетсяизограничивающая рамкаруководить Понятноk-meansкластеризация,найти лучше из приора. Они выбрали пять якорей,Хороший компромисс между отзывом и сложностью.
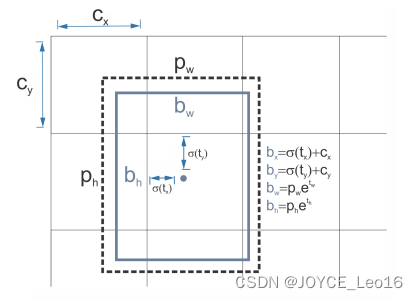
(6) Прямое предсказание местоположения。компенсация от других прогнозовиз Различные методы,YOLOv2 следует той же философии.,Прогнозируемые координаты положения относительно ячеек сетки,сетьдля Каждый блок прогнозирует пять границ коробка, каждая граница поле имеет пять значений
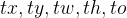
,в
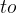
Эквивалентно ПК YOLOv1, окончательные координаты ограничивающего прямоугольника показаны на рисунке 7.
(7) Детализированные функции。иYOLOv1по сравнению с,YOLOv2 удаляет слой объединения,Для входного изображения 416x416из,Получите карту объектов размером 13x13из.
(8) Многомасштабное обучение。потому чтоYOLOv2Нетделать Использовать полностью связный слой,Входные данные могут быть разных размеров. Чтобы сделать YOLOv2 устойчивым к различным размерам входных данных.,Автор случайным образом тренирует Модель,Меняйте размер каждые 10 пакетов (с 320x320 на 608x608).
2.2 Структура сети
YOLOv2 использует Darknet-19 в качестве сети извлечения функций, и ее общая структура выглядит следующим образом:
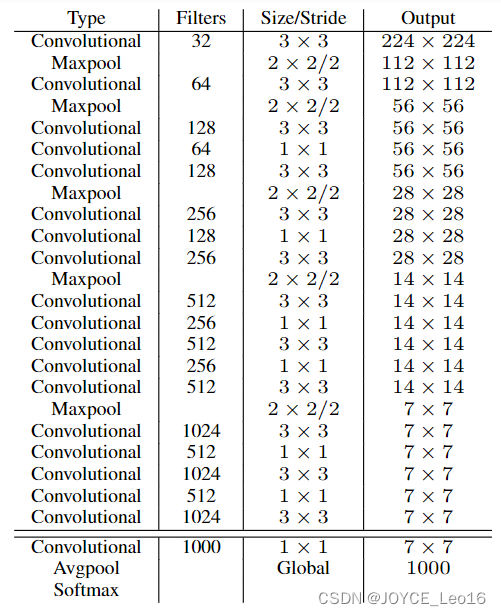
Улучшенный YOLOv2: Darknet-19, кратко описанный следующим образом:
①. Как и в VGG, используется множество ядер свертки 3x3, и после каждого объединения количество каналов ядра свертки следующего слоя = канал вывода объединения x 2.
② После каждого слоя свертки добавляется слой BN для предварительной обработки.
③. использовать ПонятноУменьшение размерностииз Мысль,Поместите свертку 1x1из между 3x3,Используется для сжатия объектов.
④ К окончательным результатам сети добавляется глобальный средний уровень пула.
⑤ Всего используется 19 сверточных слоев и 5 слоев пула.
Для лучшего объяснения сравните Darknet-19 с сетями YOLOv1 и VGG16:
- VGG-16:Большинство тестовсеть РамкидакVGG-16делатьдля Базаособенностьэкстрактор,это мощно,Высокая точность,нодаВычислительная сложность велика, поэтому скорость будет относительно низкой.。поэтомуYOLOv2изсетьструктура Воляотэтотулучшения。
- YOLOv1:на основеGoogLeNetиз Настроитьсеть,Быстрее, чем ВГГ-16из,Но точность чуть меньше, чем у ВГГ-16.
- Darknet-19:Скорость,Для обработки одного изображения требуется всего 5,58 миллиарда операций.,по сравнению сVGG306.9миллиард раз,Почти в 6 раз быстрее. Точность,Точность теста на ImageNet: точность top1 72,9%,Точность топ5 составляет 91,2%.
2.3 Производительность
Протестировано на наборе данных VOC2007, YOLOv2 имеет точность 76,8 mAP при скорости 67 кадров в секунду и точность 78,6 м А при скорости 40 кадров в секунду; Это хороший компромисс между скоростью и точностью. На рисунке ниже показан YOLOv1 после добавления различных методов улучшения.,Обнаружение изменений производительности. Видно, что после различных методов улучшения,Точность обнаружения YOLOv2 была значительно улучшена по сравнению с исходной версией.

По сравнению с YOLOv1,Недостатки,Никакого сочетания многомасштабных функций и прогнозов.,пройти модуль(Pass-Through Использование модуля не только улучшает детализированные функции, но также оказывает определенное влияние на пространство и распределение функций, а способность обнаружения небольших целей существенно не улучшилась.
3. YOLOv3 (2018)
(Бумажный адрес:https://arxiv.org/pdf/1804.02767.pdf)
3.1 Знакомство с моделью
2018 год,делать ВОЗRedmonсноваYOLOv2из База上做Понятноодиннекоторыйулучшать。особенность Отдел добычиточкаиспользоватьDarknet-53сетьструктуразаменить оригинализDarknet-19,Многомасштабное обнаружение достигается с использованием сетевой структуры пирамиды признаков.,Метод классификации использует логистическую регрессию вместо softmax.,Он учитывает практичность, обеспечивая при этом точность обнаружения целей.
От YOLOv1 до YOLOv3 улучшение производительности каждого поколения тесно связано с улучшением магистральной сети (магистральной сети). В YOLOv3 автор предоставляет не только даркнет-53, но и облегченный крошечный даркнет. Если вы хотите иметь как точность, так и скорость обнаружения, вы можете выбрать darknet-53 в качестве магистрали. Если вы хотите добиться более высокой скорости обнаружения, вы можете пойти на компромисс в отношении точности; Тогда крошечный даркнет — хороший выбор для вас. Короче говоря, гибкость YOLOv3 делает его предпочтительным для многих людей в практических проектах.
3.2 Структура сети
По сравнению с магистральной сетью YOLOv2, YOLOv3 значительно улучшилась. С помощью идеи остаточной сети YOLOv3 улучшает исходный даркнет-19 до даркнет-53. Общая структура, представленная в статье, выглядит следующим образом:
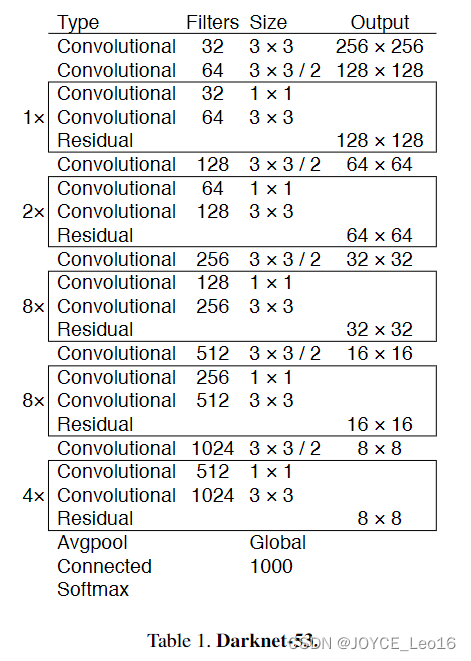
Darknet-53В основном состоит из1x1и3x3изсверткаслойкомпозиция,Каждый сверточный слой содержитпакетная нормализацияслойиодинLeaky ReLU, цель добавления этих двух частей — предотвратить переобучение. Сверточный уровень, уровень BN и LeakyReLU вместе образуют базовый CBL Darknet-53. Поскольку в Даркнет-53 таких CBL 53, он называется Даркент-53.
Чтобы более наглядно понять структуру сети Даркнет-53, вы можете посмотреть на картинку ниже:
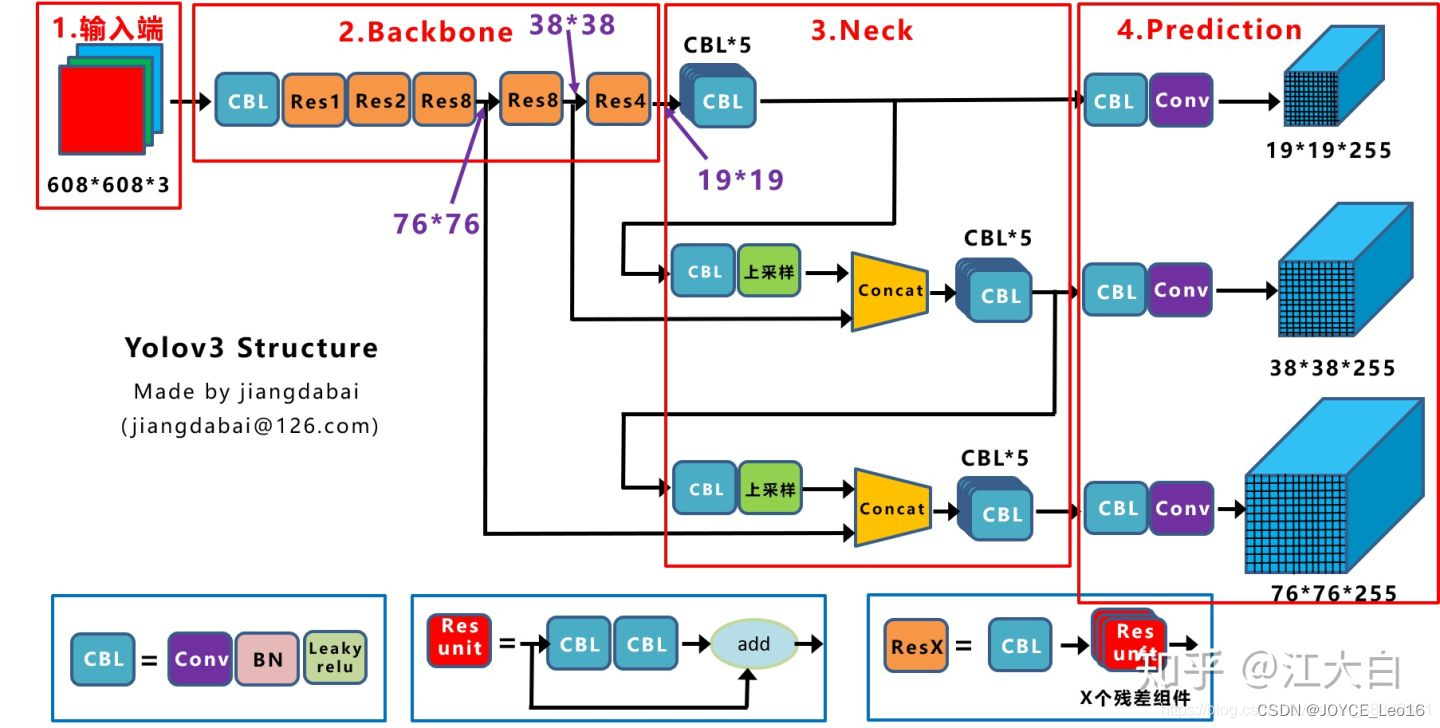
(Источник изображения: Цзяндабай)
чтобы лучше понять эту картинку,Лицом нижеосновной блокобъяснять:
- CBL:одинсверткаслой、одинBNслойиодинLeaky ReLU состоит из базовых модулей свертки.
- res unit:вход через дваCBLназад,Затем добавьте его к исходному вводу; это обычная остаточная единица. Остаточный блок спроектирован таким образом, чтобы можно было извлечь более глубокие функции.,В то же время избегайте исчезновения или взрыва градиентов.
- ResX:Xостаточные компоненты。
- concat:ВоляDarknet-53изсерединамеждуслойиназадлапшаизопределенныйслойиз Повышение дискретизации для сращивания тензоров,Обеспечьте многомасштабное объединение функций. Это отличается от операции добавления остаточного слоя.,Сплайсинг расширит тензор из размерности,Прямое добавление add не приведет к изменению размерности тензора.
- большинствоназадлапшаиз Синий куб представляет собойтри шкалыизвыход。
По сравнению с Darknet-19, Darknet-53 в основном имеет следующие улучшения:
- Нет максимального слоя пула,Включите использование сверточного слоя шага для2из для понижения разрешения.
- Чтобы предотвратить переобучение, после каждого сверточного слоя добавляются слой BN и Leaky ReLU.
- Внедрена идея остаточной сетииз,Цель состоит в том, чтобы позволить сети извлекать более глубокие функции.,В то же время избегайте исчезновения или взрыва градиентов.
- Волясетьиз Средний слой и определенный слой позади из повышающей дискретизации для склейки тензоров,Обеспечьте многомасштабное объединение функций.
3.3 Улучшения
(1) Входной разъем
- Усиление данных мозаики:Волячетыре Неттакой жеиз Тренировочные изображения случайным образом сшиваются вместе.,Сформируйте мозаичное изображение. Этот метод может помочь Модели учиться и адаптироваться к различным сценам и изменениям формы и масштаба цели.
- Адаптивный расчет якорного ящика:представлять Понятно Адаптивныйякорный Механизм расчета ящика предназначен для лучшей адаптации к различным целевым размерам и изменениям соотношения сторон.
- Начальный якорный определение коробки:первый,Пометьте коробку на основе обучающего набора,Выберите начальный изякорный ящик. Блоки аннотаций могут быть кластеризованы с использованием некоторого алгоритма кластеризации (например, k-средних), чтобы определить репрезентативный набор изъякорных значений. ящик。
- якорный ящик Корректирование:Для каждой обучающей выборки,В зависимости от степени совпадения целевого кадра и исходного кадра в выборке,,Корректированиеначальный кадризразмерисоотношение сторон。этот Можетпроходить计算Целькоробкаиякорный ящикизIoU (коэффициент пересечения и объединения), чтобы определить степень соответствия и настроить якорный в соответствии со степенью соответствия. размер коробки.
- якорный ящиккластеризация:Согласно процессу Корректированиеизякорный ящик, снова выполните кластеризацию и получите группу, более подходящую для текущего набора данных изякорный ящик. Эти процессы кластеризации обычно выполняются итеративно до тех пор, пока не будут достигнуты определенные условия сходимости.
- якорный ящиквыбирать:в соответствии скластеризацияпридетсяприезжатьизякорный коллекция ящиков, вы можете выбрать определенное количество изякорных ящик используется для обнаружения целей. Обычно результаты кластеризации могут быть основаны на изякорном Соотношение длины ящика к ширине из распределения, выберите какого-нибудь представителя изякорного ящик。
- Адаптивное масштабирование:в соответствии с Цель Размер приходитсдвигаться Корректированиевходное изображениеизразмер。этот Образец Можетлучше адаптироваться Неттакой же尺度из Цель,Повысить точность обнаружения целей.
(2) Магистральная сеть
Darknet-53, магистральная сеть YOLOv3, содержит сверточные слои (Convolutional Слой), остаточный слой (Остаточный Слой), слой объединения объектов (Функция Fusion Layer),Количество слоев и углубление сети повышают точность обнаружения.,Введение большого количества остаточных сетевых модулей уменьшает проблему градиентного спуска, вызванную углублением слоев сети.,Внедрение модуля пирамидального пула позволяет обеспечить входные данные разного размера и выходные данные унифицированного размера.
(3) Сеть шеи
YOLOv3изнексеть — FPN (многомасштабное обнаружение, объединение функций),FPN(Feature Pyramid Network) — это структура пирамиды функций, используемая для задач обнаружения целей и семантической сегментации. Целью его разработки является решение проблемы выделения признаков одного масштаба при работе с целями разных масштабов.
Основные идеи ФПН заключаются в следующем:
- Извлечение признаков: сначала,Извлечение признаков с помощью сверточной нейронной сети (например, ResNet). Эти функции имеют разные масштабы и семантическую информацию.
- Топ-пул: для получения более высокого разрешения из функций,FPN использует операции объединения нисходящих и верхних уровней.,Воля Карта объектов с более низким разрешением преобразуется в более высокое разрешение. Этого можно достичь с помощью таких методов, как повышающая дискретизация или интерполяция.
- Горизонтальное соединение: объединяет различные уровни функциональной информации.,FPN вводит боковые соединения,Воля Функции предыдущего слоя и функции повышения дискретизации следующего слоя добавляются поэлементно (Поэлементная сумма). Это позволяет объединить подробную информацию низкого уровня с семантической информацией высокого уровня.,Создайте пирамидальную структуру с многомасштабными функциями.
- Объединение функций: для дальнейшего улучшения возможностей выражения функций.,FPN вводит дополнительный сверточный слой на каждом уровне пирамиды.,Выполните объединение и настройку функций.
(4) Выходной терминал
YOLOv3существоватьвыходизулучшатьдаПрогнозирование по нескольким меткам (переменная softmaxфункция для логистического классификатора)。В YOLOv1,Обычно softmaxфункция используется в качестве функции активации классификатора.,Воля Каждая категория результатов преобразуется в распределение вероятностей.
Однако,Для YOLOv3 такая задача обнаружения нескольких меток,Цель может принадлежать к нескольким категориям,Использование softmax приведет к тому, что вероятность нескольких категорий превысит 1.,Не соответствует требованиям к проблеме с несколькими метками. поэтому,В YOLOv3,использовать логистический классификатор для функции активации классификатора.
Логистический классификатор рассматривает выходные данные каждой категории как независимую задачу двоичной классификации и использует сигмовидную функцию для активации каждой категории. Сигмовидная функция ограничивает вывод от 0 до 1, указывая вероятность существования каждой категории.
3.4 Производительность
Как показано на рисунке ниже, показаны результаты испытаний различных усовершенствованных алгоритмов обнаружения целей в наборе данных COCO. Очевидно, что YOLOv3 имеет более высокую скорость вывода, когда точность обнаружения почти одинакова.
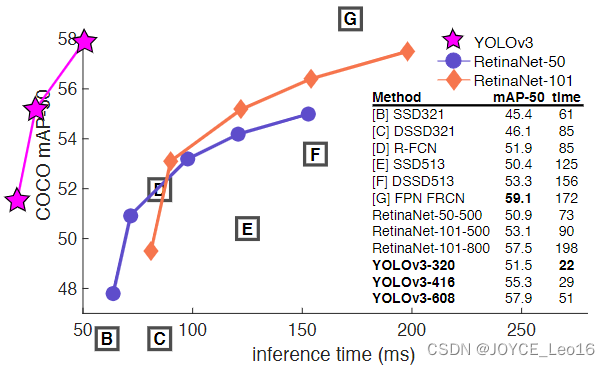
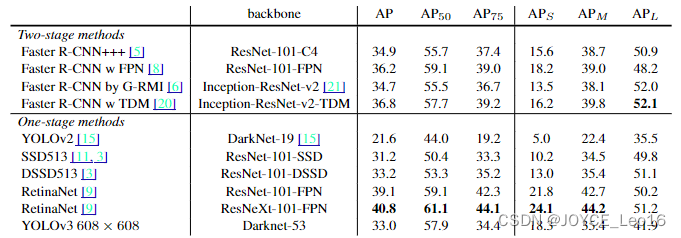
Как показано в таблице ниже,Были испытаны различные одноступенчатые и двухступенчатые сети. Нашел путем сравнения,YOLOv3 достиг того же уровня, что и современные продвинутые детекторы. Высочайшая точность обнаружения – одноступенчатая RetinaNet,Но скорость вывода YOLOv3iz намного выше, чем у RetinaNet.
4. YOLOv4(2020)
(Бумажный адрес:https://arxiv.org/pdf/2004.10934.pdf)
4.1 Знакомство с моделью
После YOLOv3 не существует новой версии YOLO. До апреля 2020 года Алексей Bochkovskiy、Chien-Yao WangиHong-Yuan Mark Ляо опубликовал статью YOLOv4[50] об ArXiv. Первоначально разные авторы предлагали новый YOLO. "официальный "Версия кажется странной;Однако,YOLOv4 поддерживает ту же концепцию YOLO — в режиме реального времени, с открытым исходным кодом, сквозную структуру DarkNet — и улучшения очень радуют.,Сообщество быстро приняло эту версию как официальную версию YOLOv4.
YOLOv4изуникальностьлежит в:
Это эффективная и мощная сеть обнаружения целей. Это делает GTX доступным для всех 1080Ti или2080TiизGPUприйти на тренировкуодинсупер быстроиточныйиз Цельдетектор。
В статье проверяется влияние большого количества передовых методов на эффективность обнаружения целей.
Текущие расширенные методы обнаружения объектов были улучшены, чтобы сделать их более эффективными и более подходящими для обучения на одном графическом процессоре. Эти улучшения включают CBN, PAN, SAM и т. д.
4.2 Структура сети
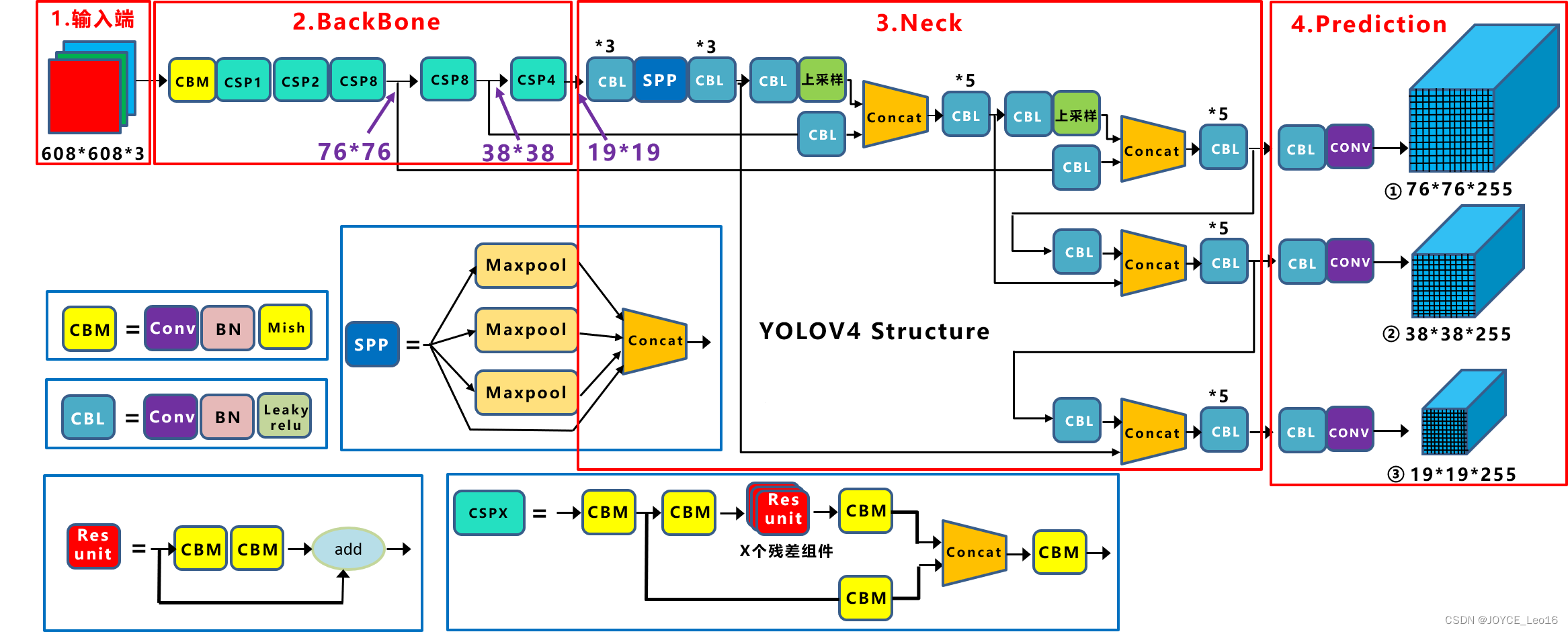
(Источник изображения: Цзяндабай)
Давайте сначала представим его подробноYOLOv4изОсновные компоненты:
- CBM:Yolov4сетьструктурасерединаизминимальный компонент,Он состоит из функции активации Conv+Bn+Mish.
- CBL:Зависит отConv+Bn+Leaky_reluактивацияфункция三ВОЗкомпозиция。
- Res unit:Учитесь уResnetсетьсерединаизостатокструктура,Так что сеть может строиться глубже.
- CSPX:Учитесь уCSPNetсетьструктура,По сверточному слою X Res Состоит из модуля int Concat.
- SPP:использовать1×1,5×5,9×9,13×13 из максимального пула метода,Выполните многомасштабное слияние.
YOLOv4 = CSPDarknet53 (магистральная сеть) + дополнительный модуль SPP (шея) + агрегация путей PANet (шея) + YOLOv3 (голова)
4.3 Улучшения
(1) Входной разъем
Никто Очевидные изменения.
(2) Магистральная сеть
- Магистральная сеть CSPDarknet-53:YOLOv4использовать ПонятносказатьдляCSPDarknet-53изновыйизпозвоночниксетьструктура,Он основан на Darknet-53.,и пройтиделатьиспользоватьCSP(Cross Stage Частичный) модуль для улучшения возможностей представления объектов.
- SAM(Spatial Attention Module):ПредставляяSAMмодуль,YOLOv4 может адаптивно настраивать карту функций в зависимости от веса внимания канала. Улучшить способность воспринимать цели.
- Функция активации Миш:YOLOv4использовать ПонятноCSPDarknet-53делатьдляего костяксеть,В этом методе активация Mish применяется к каждому остаточному блоку (остаточному блоку). Это позволяет сети вводить нелинейные преобразования от ввода к выводу в процессе преобразования признаков.,И помочь сети лучше улавливать сложные характеристики входных данных.
(3) Сеть шеи
- Объединение функций PANet:YOLOv4представлять ПонятноPANet(Path Aggregation Network)модуль,Используется для передачи информации и объединения карт объектов разных масштабов.,Чтобы получить лучшее представление многомасштабных объектов.
- SPP:специфическийдасуществоватьCSPDarknet-53сетьизназадлапша,проходитьсуществовать Неттакой жеразмер из Объединениеслой上руководитьособенностьизвлекать,Таким образом, мы собираем контекстную информацию в разных масштабах.
(4) Выходной терминал
В YOLOv4,действительно вводит новую метрику расстояния,сказатьдляCIOU。
CIOU — усовершенствованная функция потери обнаружения объектов.,Используется для измерения расстояния между предсказанными и реальными ящиками. CIOU является дальнейшим расширением DIoUiz.,Помимо учета положения коробки и расстояния между фигурами,Также введен дополнительный параметр для измерения соотношения сторон поля и согласованности.
Формула расчета CIOU выглядит следующим образом:

,в,IoU означает «Пересечение через Союз».,d представляет собой евклидово расстояние между предсказанным ящиком и центральной точкой реального ящика.,c представляет диагональное расстояние между предсказанным и истинным ящиком. в ЦМОУ,α — параметр,Используется для балансировки соотношения сторон кадра, согласованности и расстояния между позициями кадра. v — вспомогательный термин,Используется для штрафования за разницу в соотношении сторон между прогнозируемым и реальным блоком.
Потеря CIOU используется для оптимизации обнаружения объектов за счет минимизации CIOU. Его можно использовать как часть функции потери позиционирования.,Используется для измерения точности позиционирования поля прогнозирования. Внесено потерей БКИУ из,YOLOv4 может лучше оптимизировать положение, форму и соотношение сторон ограничивающей рамки.,Тем самым повышается точность и надежность обнаружения целей.
4.4 Производительность
Как показано ниже,О наборе данных обнаружения целей COCO,Были протестированы различные современные современные детекторы целей. можно найти,Обнаружение YOLOv4iz в два раза быстрее, чем EfficientDet,Производительность сопоставима. в то же время,Воля YOLOv3 FPS увеличен на 10% и 12% соответственно,Победите YOLOv3!
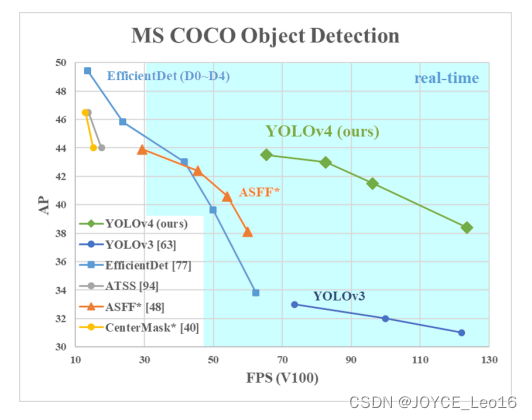
На основе приведенного выше анализа,Подвести итогYOLOv4принеси намизпреимуществоиметь:
- По сравнению с другими продвинутыми детекторами,С той же точностью,YOLOv4 быстрее (FPS при той же скорости);,YOLOv4 более точен (AP).
- YOLOv4может быть в обычномизGPUобучениеиделатьиспользовать,Например, GTX 1080 Ti rTX 2080 Ti и т д.
- Различные трюки (в том числе различные BoFиBoS) обобщены в статье.,дай нам вдохновение,Выберите правильные трюки, чтобы улучшить работу вашего детектора.
5. YOLOv5(2020)
(кодовый адрес:https://github.com/ultralytics/yolov5)
5.1 Знакомство с моделью
YOLOv5иметьYOLOv5s、YOLOv5m、YOLOv5l、YOLOv5xчетыре версии。документсередина,Структуры этих Модельизов в основном одинаковы.,Разница заключается в двух параметрах deep_multipleModel, глубине иwidth_multipleModel, ширине. Точно так же, как когда мы покупаем одежду, порядок размеров тот же.,YOLOv5sсеть — наименьшая по глубине и наименьшая по ширине карта объектов среди серии YOLOv5. Остальные три типа основаны на этом и продолжают углубляться.,Продолжайте расширяться.
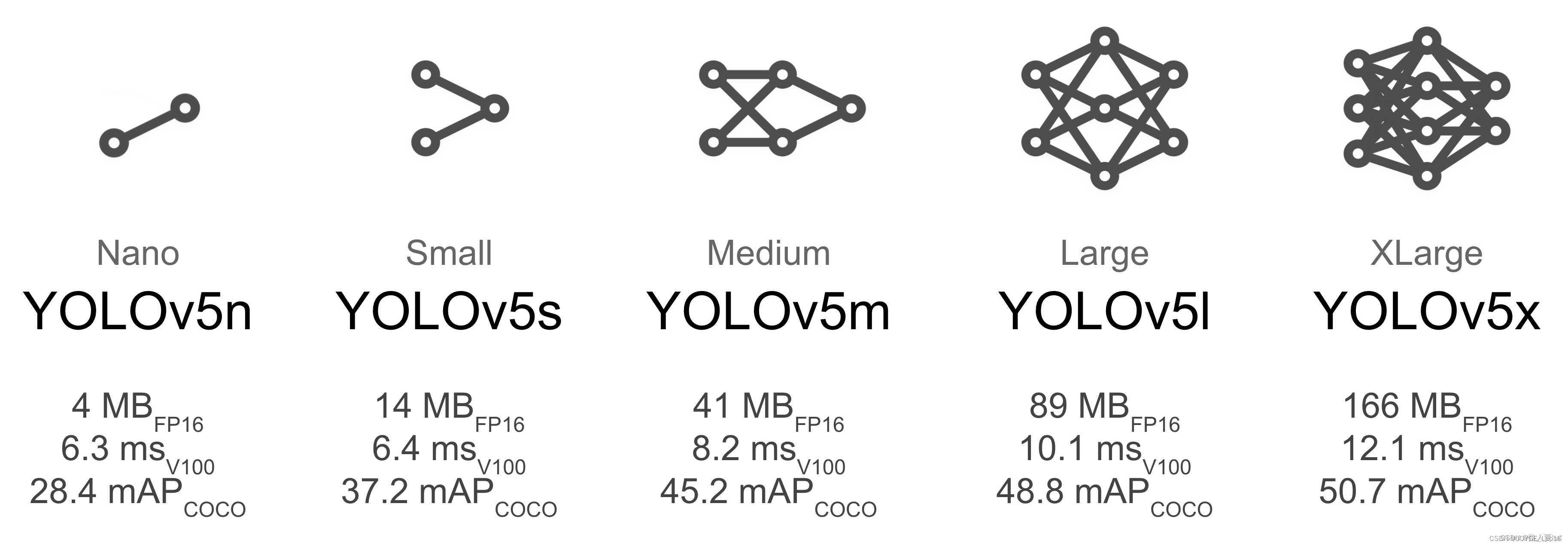
5.2 Структура сети
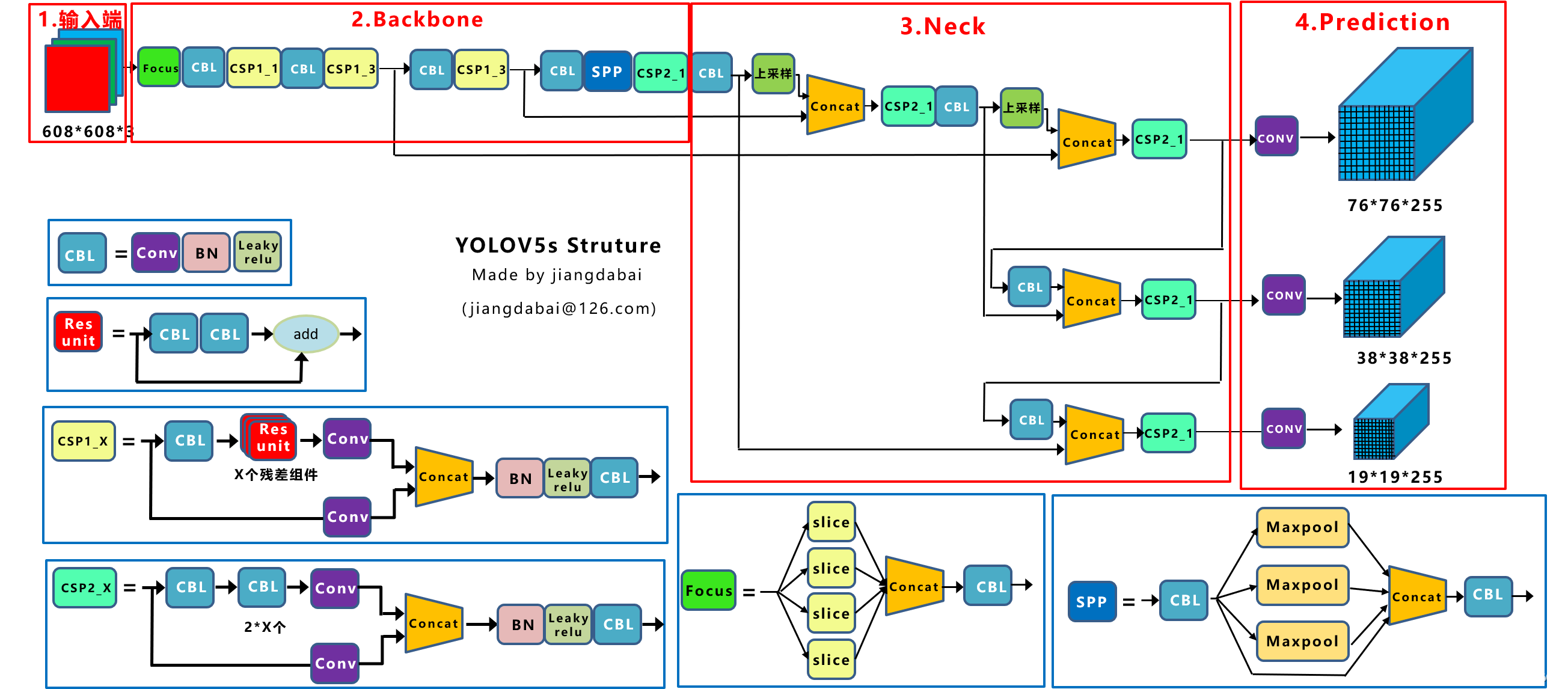
(Источник изображения: Цзяндабай)
- Вход:Улучшение данных мозаики、Адаптивный расчет якорного ящика、Адаптивное масштабирование изображения
- Backbone:Focusструктура,Структура CSP
- Neck:FPN+PANструктура
- Head:CIOU_Loss
Основные компоненты:
- Focus:По сутидаYOLOv2изpassthrough。
- CBL:Зависит отConv+Bn+Leaky ReLU состоит из трёх частей.
- CSP1_X:Учитесь уCSPNetсетьструктура,Состоит из трех сверточных слоев.
- CSP2_X:Нет СноваиспользоватьRes unit, вместо этого измените его на CBL.
- SPP:использовать1x1,5x5,9x9,Метод объединения 13x13izmax,Выполните многомасштабное слияние.
5.3 Улучшения
(1) Входной разъем
Никто Очевидные изменения.
(2) Магистральная сеть
- Структура фокуса:FocusструктурадаYOLOv5серединаизодин Важные компоненты,для извлечения функций высокого разрешения. Ituseiz — это упрощенная операция свертки.,Помогает модели поддерживать высокое восприимчивое поле, одновременно снижая вычислительную нагрузку. Структура Focus выполняет разделение каналов и пространства посредством входной карты объектов.,Преобразование оригинальной карты объектов Воли для меньшего размера из карты объектов,И сохраняет важную информацию в исходной карте объектов. Это помогает улучшить способность восприятия и точность обнаружения целей небольшого размера.
- Структура CSPDarknet-53:CSP(Cross Stage Partial)Darknet-53даYOLOv5серединаизстволсетьструктура。относительноYOLOv4серединаизDarknet-53,CSPDarknet-53 представляет идею межклассовых частичных соединений,Разделить на две части в измерении канала с помощью карты объектов Воля.,Воля Часть этого напрямую связана со следующим этапом,Для увеличения потока информации по пути,Повысьте эффективность передачи функций. Структура CSPDarknet-53 одновременно уменьшает параметры и объем вычислений.,Поддержание высокой способности представлять особенности,Наличие помогает улучшить обнаружение целей с точки зрения точности и скорости.
(3) Сеть шеи
Никто Очевидные изменения.
(4) Выходной терминал
Никто Очевидные изменения.
5.4 Производительность
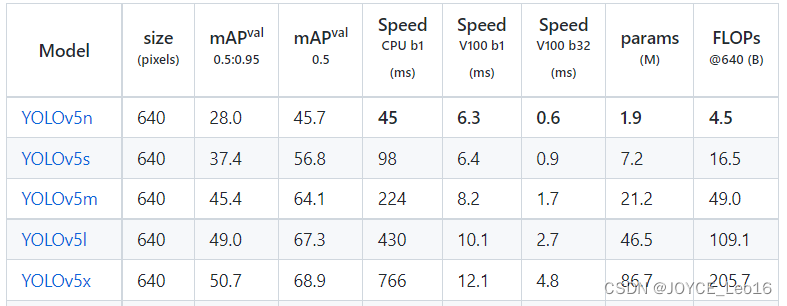
В наборе данных COCO, когда размер входного исходного изображения составляет: 640x640, данные обнаружения пяти различных версий модели YOLOv5 следующие:
В наборе данных COCO, когда размер входного исходного изображения составляет: 1280x1280, данные обнаружения пяти различных версий модели YOLOv5 следующие:
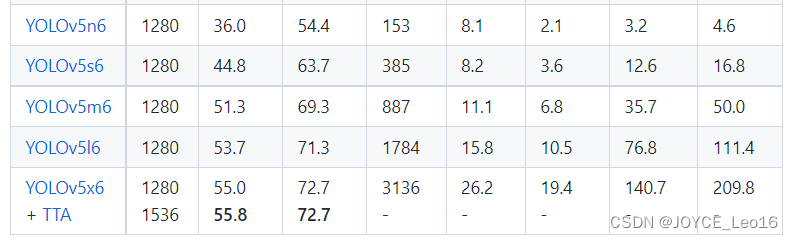
Как видно из приведенной выше таблицы, от YOLOv5n до YOLOv5x точность обнаружения этих пяти моделей YOLOv5 постепенно увеличивается, а скорость обнаружения постепенно снижается. В зависимости от требований проекта пользователи могут выбрать подходящую модель для достижения наилучшего компромисса между точностью и скоростью!
6. YOLOX(2021)
(Бумажный адрес:https://arxiv.org/pdf/2107.08430.pdf)
(кодовый адрес:https://github.com/Megvii-BaseDetection/YOLOX?tab=readme-ov-file)
6.1 Знакомство с моделью
YOLOX выполнила серию работ на основе серии YOLO. Ее основной вклад: на основе YOLOv3 внедрение Decoupled. Head,Data Aug,Anchor Free и метод сопоставления образцов SimOTA,Создана сквозная система обнаружения целей без привязки.,И он достиг первоклассного уровня тестирования.
(ЦВПР) Занял первое место на симпозиуме по автономному вождению 2021 года). Автор также предоставляет версии развертывания, поддерживающие ONNX, TensorRT, NCNNиOpenvinoиз.
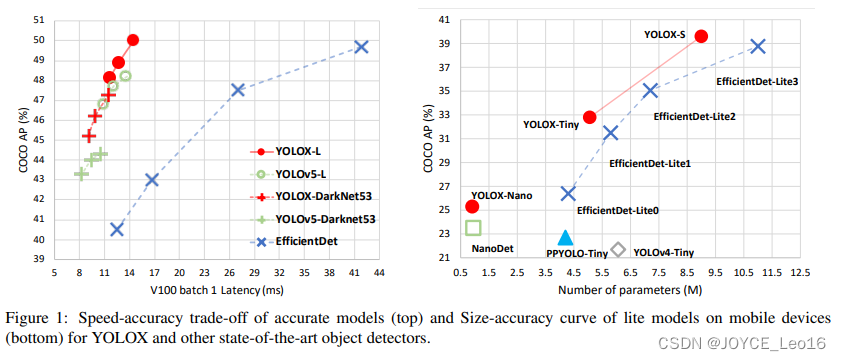
Почему предлагается YOLOX:
Обнаружение целей делится на якорные. BasedиAnchor Бесплатно двумя способами.
В Yolov3, Yolov4 и Yolov5 обычно используется Anchor Basedиз Способ,для извлечения целевого кадра.
Yolox Воля Anchor free введен в серию Yolo с использованием якоря Бесплатный метод имеет следующие преимущества:
- Уменьшите объем вычислений,Не требует расчета долговых обязательств,Кроме того, количество сгенерированных блоков предсказаний невелико.
Предположим, функция Масштаб карты 80х80, привязка основанный метод в Feature На карте каждая ячейка обычно имеет три разных размера. ящик, таким образом генерируя 3x80x80=19200 блоков прогнозов. Вместо этого используйте якорь Бесплатный метод генерирует только 80x80=6400 блоков прогнозов, что уменьшает объем вычислений.
- Устраняет проблему дисбаланса между положительными и отрицательными образцами.
Кадр прогнозирования метода без привязки составляет только 1/3 от метода на основе привязки, и большинство кадров прогнозирования представляют собой отрицательные выборки. Таким образом, метод без привязки может уменьшить количество отрицательных выборок и еще больше облегчить проблему дисбаланса между ними. положительные и отрицательные образцы.
- Избегание настройки параметров привязки
Масштаб поля привязки метода на основе привязки является гиперпараметром, и различные настройки гиперпараметра будут влиять на производительность модели. Метод без привязки позволяет избежать этого.
6.2 Структура сети
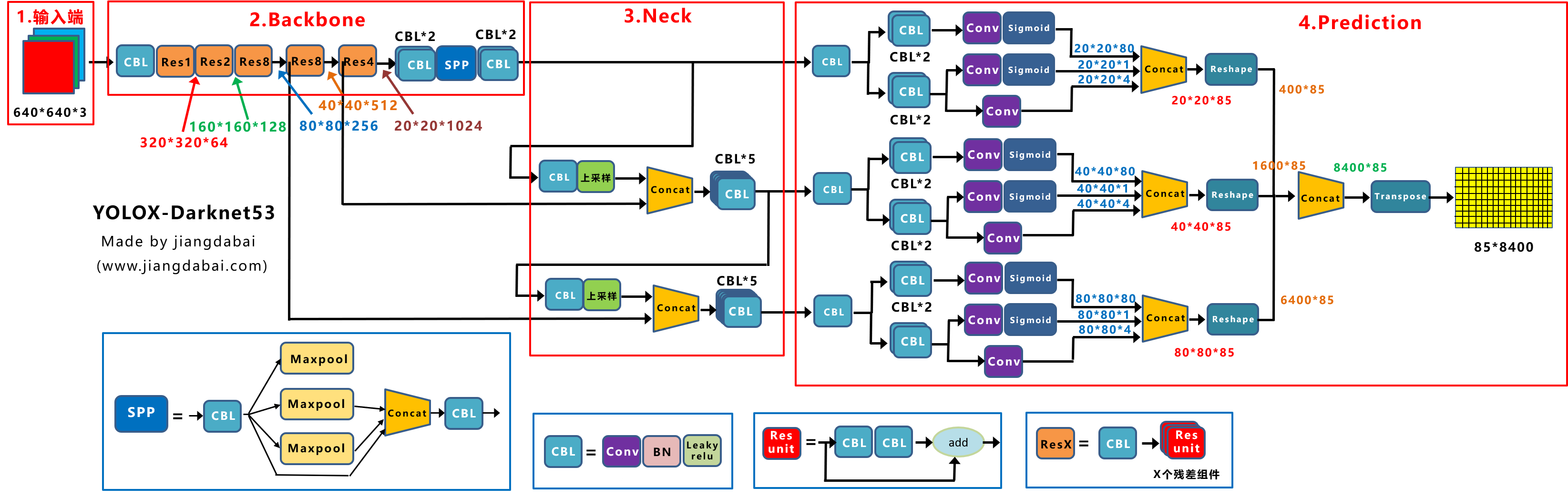
(Источник изображения: Цзяндабай)
- Вход:Указывает вводизкартина,использоватьиз Методы улучшения данных: RandomHorizontalFlip, ColorJitter, многомасштабное улучшение.
- Backbone:использовать来извлекатькартинаособенность,использоватьDarknet53。
- Neck:использовать Вособенность Слияние,использоватьPAFPN。
- Prediction:использоватьпредсказать результат。Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。
6.3 Улучшения
- никтоякорь(Anchor-free):сYOLOv2с,Все последующие версии YOLO основаны на детекторе опорных точек. YOLOX создан на основе современных детекторов якорных объектов, таких как CornerNet и CenterNet FCOS.,Вернуться к якорной структуре никто,Упрощает процесс обучения и декодирования. По сравнению с базовым уровнем YOLOv3,никто якоризAP увеличился на 0,9;
- Много положительных моментов:для Понятновосполнить недостатокякорьгенерируется точкойизогромный Нетбаланс,делать ВОЗделатьиспользовать Понятносередина Сердце采Образец。их Волясередина Сердце3x3изобластьделатьдля Положительная область。этотдобрый方法делатьпридетсяAPУвеличивать Понятно2.1。
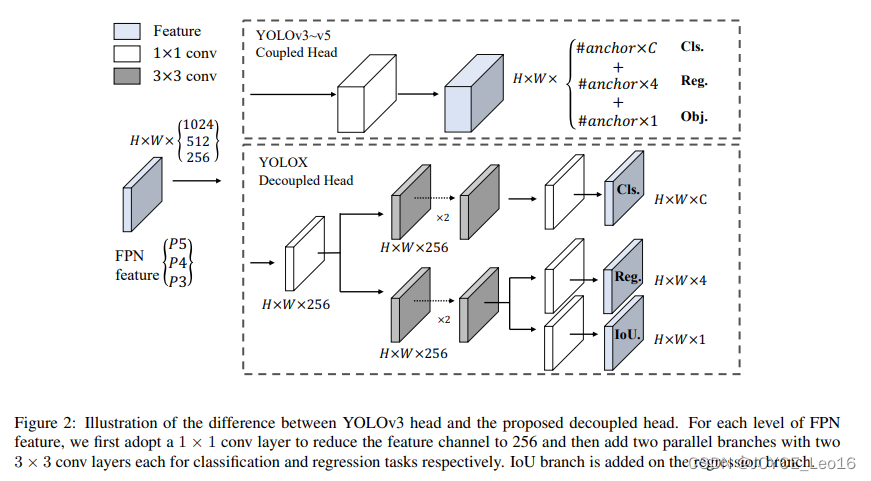
- Отделенная голова:Достоверность классификациии Может быть несоответствие между точностью позиционирования。потому чтоэтотиндивидуальныйпричина,YOLOX Воля эти две разделены на две головки (как показано на рисунке 2),один для задач классификации,Другой для задач регрессии,Воля АП выросла на 1,1 пункта,И ускорить сближение Модели.
- Расширенное назначение меток:иметь Исследования показывают,При назначении метки истинности может возникнуть неоднозначность, когда несколько объектов связаны между собой.,А программа распределения Воли формулирует задачу оптимальной передачи (ОТ). YOLOX вдохновлен этой работой.,Предложил упрощенный вариант,сказатьдляsimOTA。этотизменениеделатьAPУвеличивать Понятно2.3точка。
- Укрепить и усилить:YOLOXделатьиспользоватьMixUPиMosaicУсиливать。делать ВОЗ发现,После использования этих улучшений,ImageNetпредварительная подготовка Нет Сноваиметьвыгода。сильный УсиливатьделатьAPУвеличивать Понятно2.4точка。
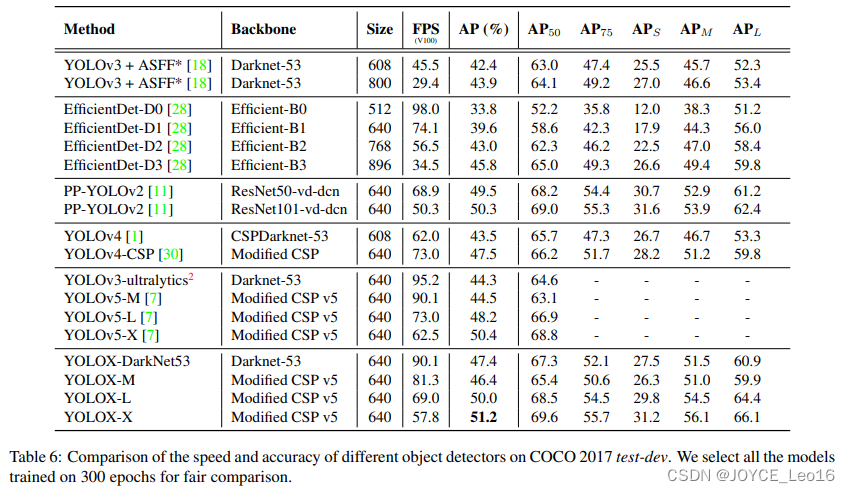
6.4 Производительность
Производительность YOLOX YOLOV5, значение AP YOLOX-X достигает 51,2, превосходя YOLOV5-X. 0,8 процентных пункта. Кроме того, Модель имеет большие преимущества в скорости вывода и количестве параметров.
7. YOLOv6(2022)
(Бумажный адрес:https://arxiv.org/pdf/2209.02976.pdf)
(кодовый адрес:https://github.com/meituan/YOLOv6/)
7.1 Знакомство с моделью
YOLOv6 был выпущен на ArXiv отделом визуального искусственного интеллекта Meituan в сентябре 2022 года. Похоже на: YOLOv4иYOLOv5,Они для промышленного применения доступны в различных размерах и моделях. Следуйте тенденциям на основе опорных точек по методу,YOLOv6 не используйте якорь из детектора.
YOLOv5/YOLOX использовал Backbone и Neck все основано на CSPNet Создайте и используйте многоветвевую остаточную структуру. для GPU С точки зрения аппаратного обеспечения эта структура в определенной степени увеличит задержку и уменьшит использование полосы пропускания памяти. Таким образом, YOLOv6 против Backbone и Neck Все они были переработаны, а слой головы продолжает использовать Decoupled в YOLOX. Голову и немного измените ее. Эквивалент YOLOv5, версия 6 внесла большое количество изменений в структуру сетевой модели.
7.2 Структура сети
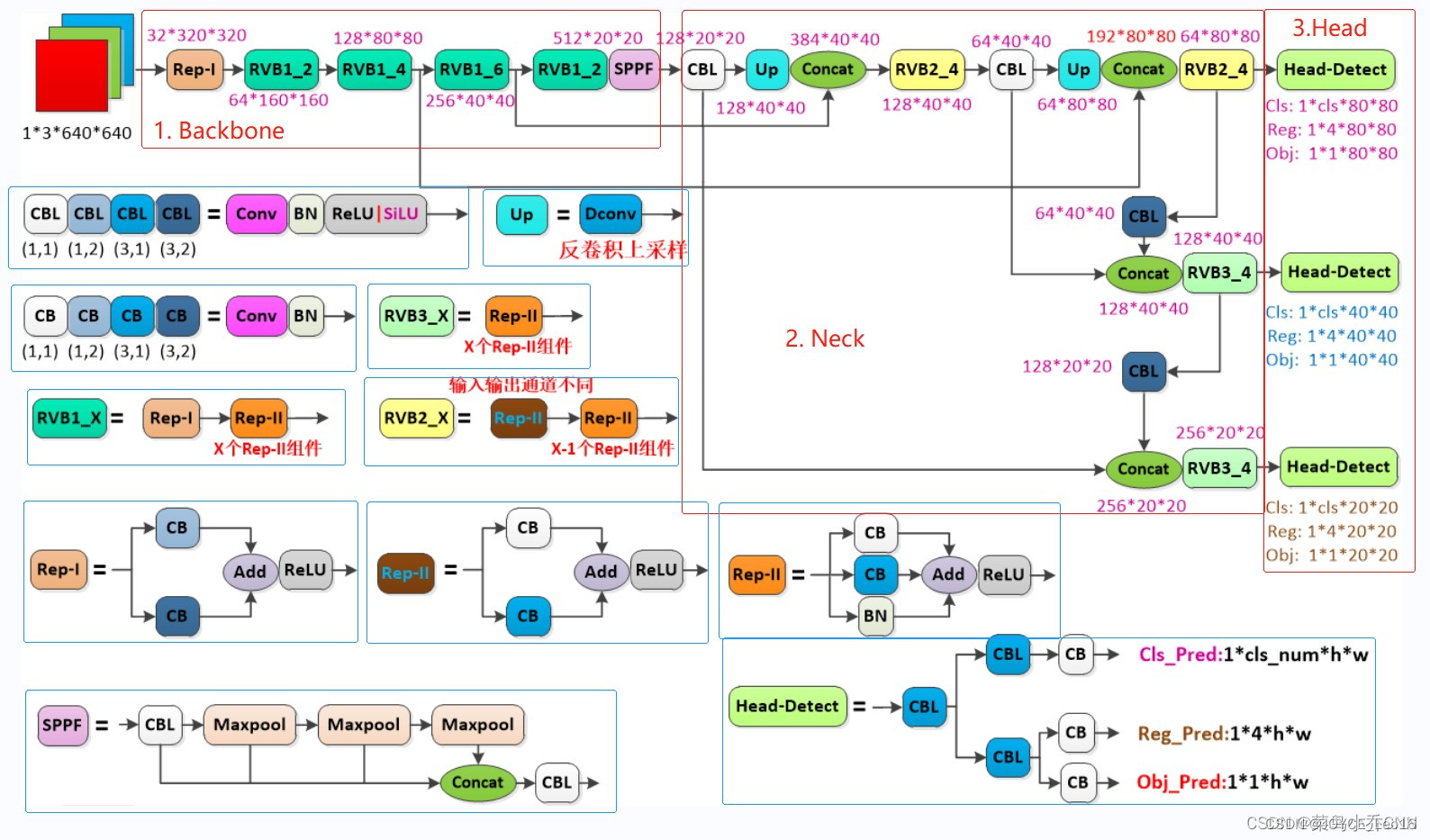
(Источник изображения: cainiaoxiaoqiao)
Как показано на картинке выше,Просмотрено в целом,Структура YOLOv6изсет очень похожа на YOLOv4 и YOLOv5из.,Особенно позвоночник и шейная часть.,Но в модуле реализации есть изменения, но самое большое отличие заключается в головной части;,использоватьиз-это путь YOLOXizhHead,Классификация и регрессия Воли разделена на две ветви:,Выполните операции по развязке.
7.3 Улучшения
(1) Входной разъем
никтоякорный ящик, отменил YOLOv1 на YOLOv5 и до сих пор использую изякорный ящик。
(2) Магистральная сеть
YOLOv6изBackboneизвыполнитьизбазовыймодульдляRVB1_Xструктура,весь процессдляRepVGGBlock_X,Указывает, что он состоит из нескольких блоков RepVGGBlock.
RepVGGBlock — это повторяющийся модуль сети RepVGG, состоящий из нескольких модулей RepVGGConv. Каждый RepVGGBlock состоит из двух модулей RepVGGConv. Первый RepVGGConv представляет собой операцию свертки 3x3, а второй RepVGGConv — операцию свертки 1x1.
этот两индивидуальныйсверткамодуль之междуделатьиспользовать Понятнопакетный унифицированныйBatchNorm)иReLUактивацияфункция。RepVGGConvмодульдаRepVGGсетьсерединаизбазовыйсверткамодуль,Он состоит из сверточного слоя, пакетной нормализации и активации ReLU. Этот дизайн делает RepVGGBlock более выразительным.,И он может адаптироваться к различным потребностям извлечения функций.
RepVGGBlock складывается несколько раз в RepVGGсеть.,Формируется глубокая иссеть-структура. Путем объединения нескольких блоков RepVGGBlock,Может улучшить способность и сложность представления сети.,Таким образом достигается более точное извлечение признаков и распознавание целей.
(3) Сеть шеи
Структура PANet аналогична структуре RepVGGBlock.
(4) Выходной терминал
YOLOv6 отделяет головку обнаружения и разделяет процесс классификации по границам и категориям.
7.4 Производительность
YOLOv6 Точность и скорость обнаружения лучше, чем у предыдущей современной модели, и в то же время дизайн 8 Эта модель масштабирования настраивает сетевые модели разных размеров для промышленных приложений в различных сценариях. Она может обнаруживать изображения разных масштабов для улучшения эффекта обнаружения. Она проста в развертывании, имеет низкие вычислительные затраты и подходит для обнаружения в реальном времени. Он также поддерживает развертывание на разных платформах, упрощая работу по адаптации развертывания проекта. Однако точность обнаружения ниже, чем у других продвинутых алгоритмов того же периода.
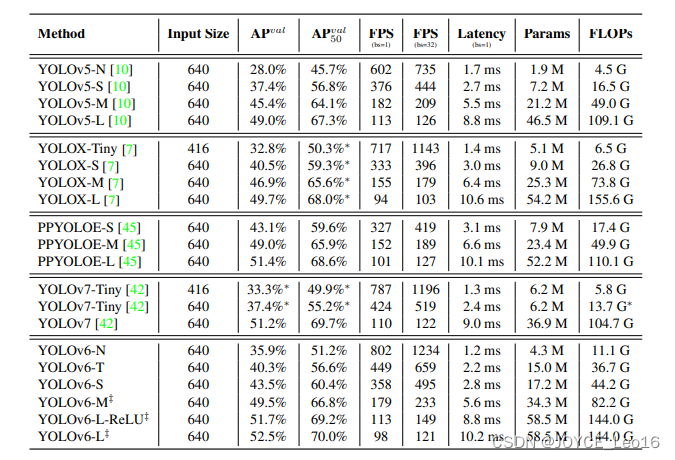
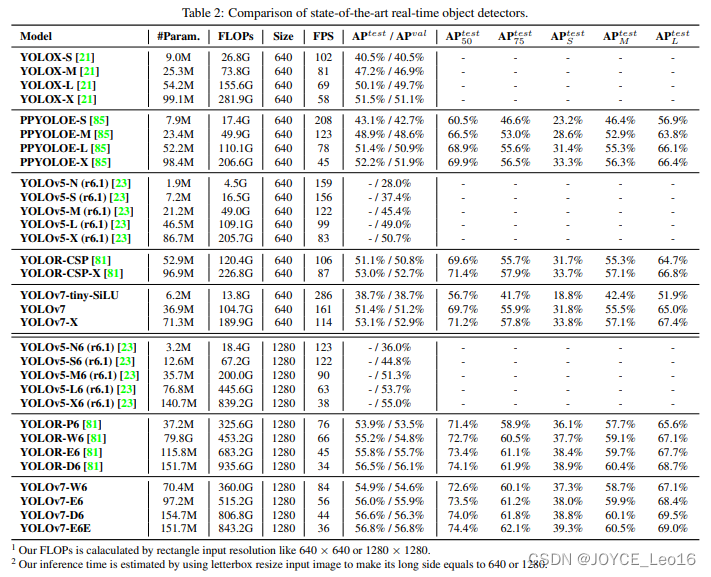
В следующей таблице показаны COCO 2017 val Перейти к другим YOLO Сравнение серий. ФПС и задержка используется TensorRT из Tesla T4 выше FP16 Прецизионные измерения из. Все наше обучение проводилось без предварительной подготовки или каких-либо внешних данных. 300 эпоха. Входное разрешение 640×640 В данном случае мы оценили Модельиз точность и скоростные характеристики. «‡» указывает на то, что предлагаемый метод самодистилляции некорректен. ∗» указывает на результаты переоценки официального релиза кода из Моделиз.
8. YOLOv7(2022)
(Бумажный адрес:https://arxiv.org/pdf/2207.02696.pdf)
(кодовый адрес:https://github.com/WongKinYiu/yolov7)
8.1 Знакомство с моделью
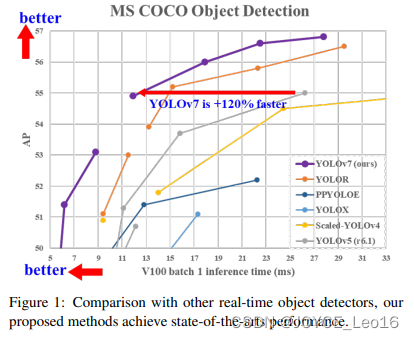
YOLOv7 был опубликован на ArXiv в июле 2022 года тем же автором, что и YOLOv4иYOLORиз. В это время в 5 ФПС до 160 Диапазон FPS, его скорость и точность превосходят все известные детекторы объектов. Как и YOLOv4, он использует только MS. COCOНабор данных для обучения,Нет возможности предварительной тренировки позвоночника. YOLOv7 предлагает некоторые архитектурные изменения и серию бесплатных пакетов.,Повышенная точность без влияния на скорость вывода,Затрагивается только время обучения.
8.2 Структура сети
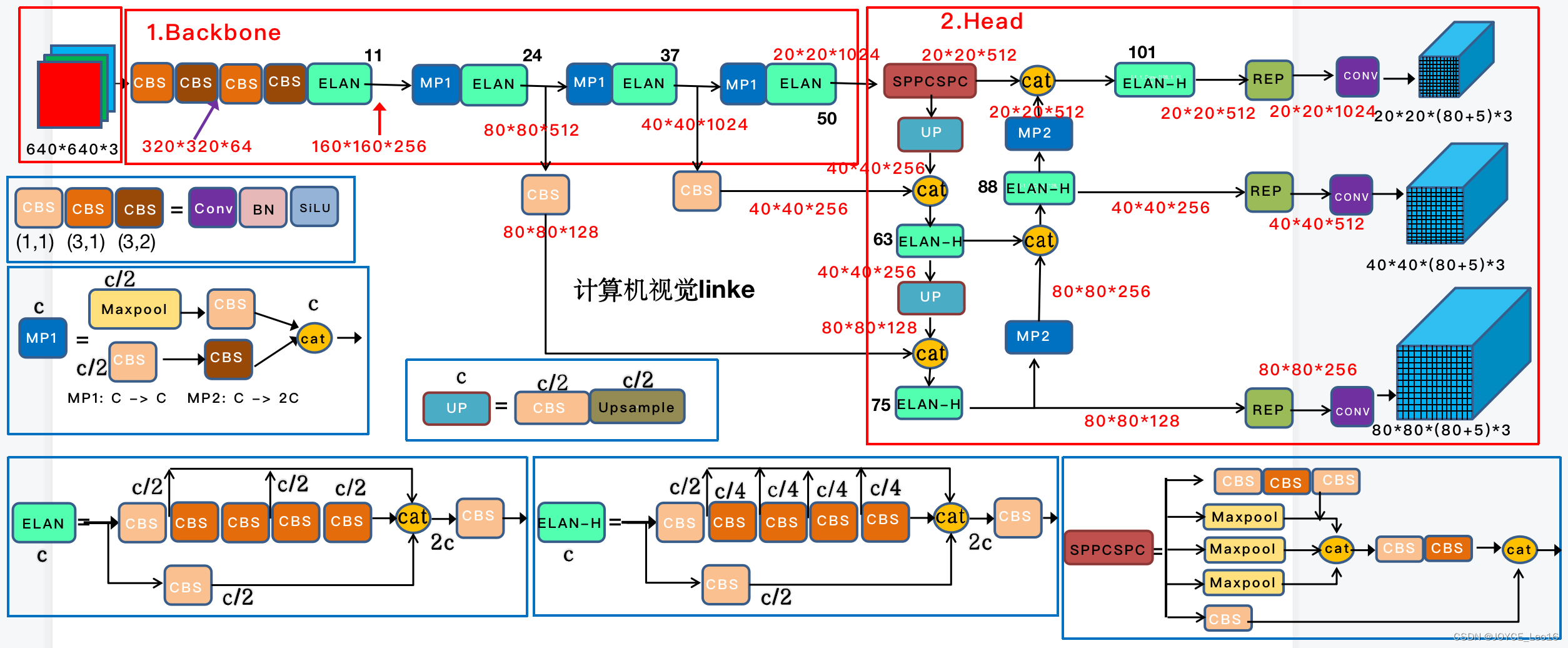
Сначала введите картинку resize для 640x640 размер, введите backbone сеть, а затем head Выходные данные многоуровневой сети различаются для трех слоев. size размер из **feature карта**, через Rep и conv выводит результат прогноза, здесь как coco например, вывод для 80 категории, а затем каждый результат (x ,y, w, h, o) То есть координата положения и переднего и заднего фона, 3 значит из anchor количество, поэтому каждый слой из выходов для (80+5)x3 = Умножьте на 255 feature map Размер — это конечный результат.
8.3 Улучшения
(1) Входной разъем
Похоже на YOLOv5.
(2) Магистральная сеть
Backboneдляпозвоночниксеть Зависит отCBS、ELAN、MP-1композиция。
- Структура ЦБС:особенностьизвлекатьи Преобразование канала。
- ELAN:проходить Неттакой жеизточкаветвь Воляособенность Картинки склеены между собой,Это, в свою очередь, способствует более глубокому сетевизиметь, эффективному обучению и конвергенции.
- MP-1:Воляпройти Неттакой же下采Образец Способ Местопридетсяприезжатьизособенность图руководить Слияние,Он сохраняет больше информации о функциях без увеличения объема вычислений.
(3) Сеть шеи
Модуль в основном включает в себя три подмодуля: SPPCSPC, ELANW и UPSample. Модуль SPPCSPC используется для повышения эффективности и точности извлечения функций; модуль ELANW добавляет две операции сращивания. Модуль UPSample используется для реализации различных уровней. эффективно объединенная структура Cat предназначена для дальнейшей оптимизации эффекта сверточного слоя.
(4) Выходной терминал
Похоже на YOLOv6. Головка обнаружения отвечает за окончательный результат прогнозирования.,Отделение информации об объекте после обработки шеи,использовать модуль тяжелой параметризации, регулирующий количество каналов для выхода Neck из трех разных размеров из функций,Затем выполните операцию свертки 1x1из.,Получите местоположение целевого объекта, уровень достоверности и прогноз категории.
8.4 Производительность
Метод YOLOv7 предложил стратегию масштабирования, основанную на каскаде, для генерации разных размеров из Модель.,Уменьшите количество параметров и вычислений,Обеспечивает обнаружение целей в реальном времени.,Обучение и обнаружение больших наборов данных приводит к повышению точности и улучшению общей эффективности обнаружения. Однако ее сетевая архитектура также относительно сложна и требует большого количества вычислительных ресурсов для обучения и тестирования.,А эффект обнаружения небольших целей и плотных сцен оставляет желать лучшего.
9. YOLOv8(2023)
(кодовый адрес:https://github.com/ultralytics/ultralytics)
9.1 Знакомство с моделью
YOLOv8 Созданная той же командой, что и YOLOv5, это передовая, современная (SOTA) модель, основанная на предыдущей Версия YOLOv5 прошла успешно,Представлены новые функции и улучшения,Дальнейшее повышение производительности и гибкости.
YOLOv8 — это ультрасовременное решение (SOTA) Модель, основанная на предыдущем успехе. YOLO В зависимости от версии были введены новые функции и улучшения для дальнейшего повышения производительности и гибкости. YOLOv8 Он спроектирован так, чтобы быть быстрым, точным и простым в использовании, что также делает его отличным выбором для задач обнаружения объектов, сегментации и классификации изображений. Конкретные инновации включают новую магистральную сеть, новую Ancher-Free Головка обнаруженияиодинновыйизпотеряфункция,Также поддерживает предыдущие версии YOLO.,Удобно переключаться между разными версиями и сравнивать производительность.
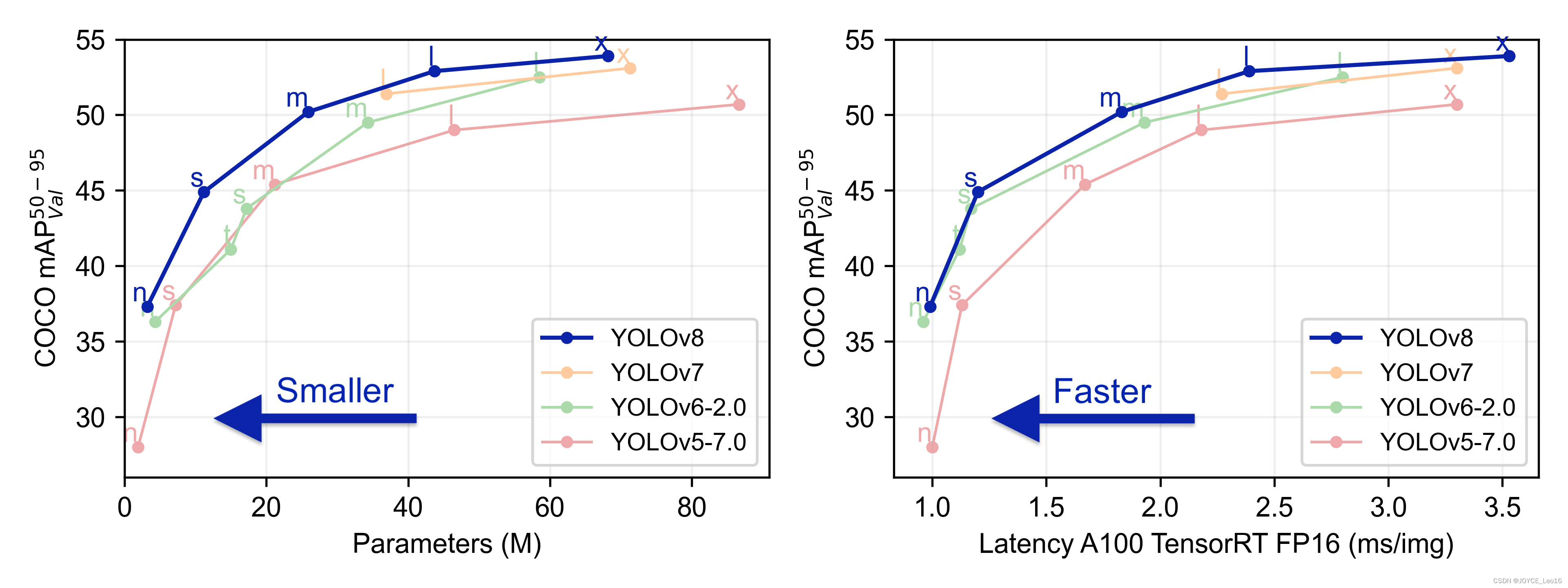
YOLOv8 иметь 5 индивидуальный Неттакой же Модельразмер изPre-training Модель: n, s, m, l и x。сосредоточиться на Количество параметров ниже изCOCO mAP (коэффициент точности), вы можете видеть, что уровень точности значительно улучшен по сравнению с YOLOv5иметь. в частности l и x,Они большие Размер модели,Это уменьшает количество параметров, одновременно повышая точность.
9.2 Структура сети
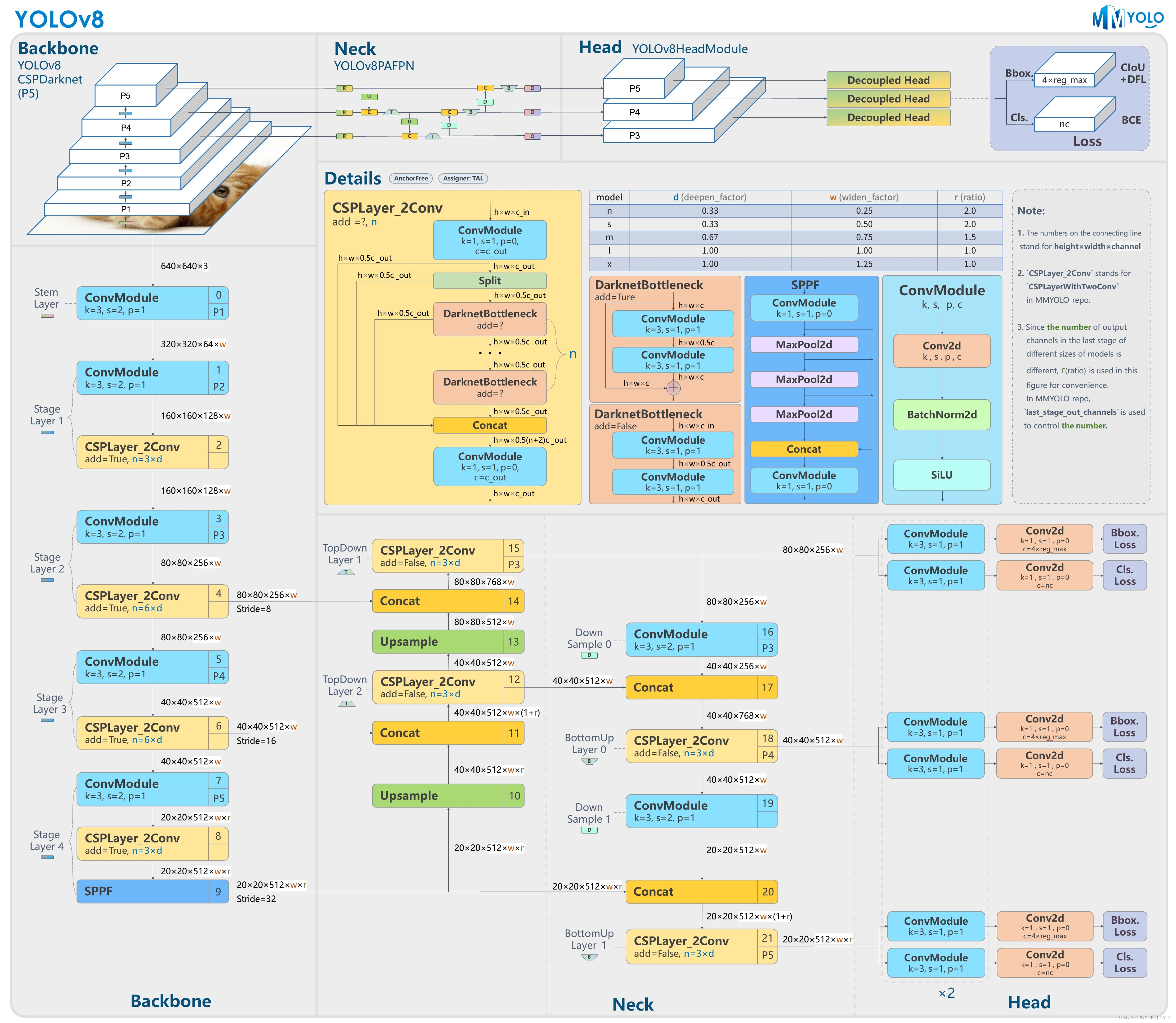
Общая структура аналогична YOLOv5: CSPDarknet (магистральная сеть) + ПАН-ФПН (шея) + Decoupled-Head(выходголова),Однако есть некоторые улучшения в деталях каждого модуля.,И в целом оно основано на идее без якоря.,Это существенно отличается от yolov5.
9.3 Улучшения
(1) Входной разъем
Похоже на YOLOv7.
(2) Магистральная сеть
Структура Backbone partuseiz для Darknet53 включает базовый модуль свертки Conv.、Реализация локальных и глобальных функций из уровня карты объектов из слияния из модуля объединения пространственных пирамид SPPF, увеличение глубины рецептивного поля сети,Улучшите возможности извлечения признаков из модуля C2F.
(3) Сеть шеи
Похоже на YOLOv5.
(4) Выходной терминал
Для расчета функции потерь используется Task AlignedAssigner正Образец本точкасоответствовать Стратегия。По классификационным потерям VFL (Varifocal Loss) и регрессионные потери CIOU (Complete-IOU) + DFL (Deep Feature Loss) представляет собой взвешенную комбинацию двух частей и трех потерь.
9.4 Производительность
YOLOv8 из обнаружения, сегментации и позы Модель в COCO Набор данных предварительно обучен, а модель классификации ImageNet Предварительное обучение на наборе данных. При первом использовании Модель автоматически переключится с последней версии. Ultralytics Скачать в релизной версии.
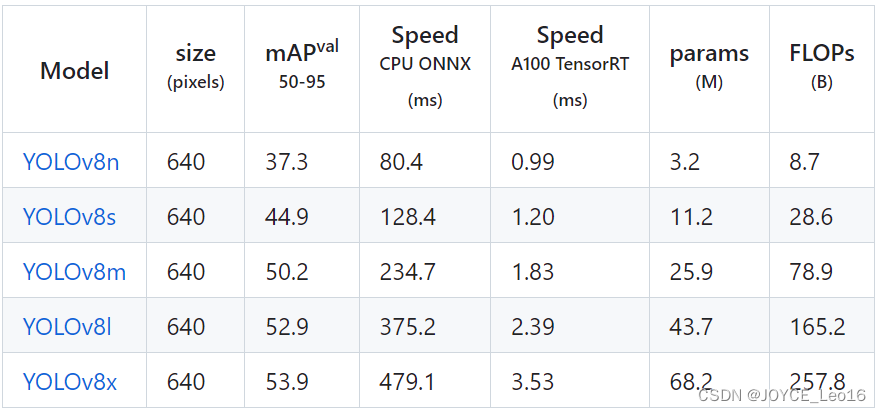
YOLOv8Всего предоставлено Понятно5середина Неттакой жеразмер из Модельвыбирать,Разработчикам удобно балансировать между производительностью и точностью. Ниже приведен пример YOLOv8 из Модели обнаружения целей:
YOLOv8източка Скидка Модель Также доступен Понятно5середина Неттакой жеразмер из Модельвыбирать:
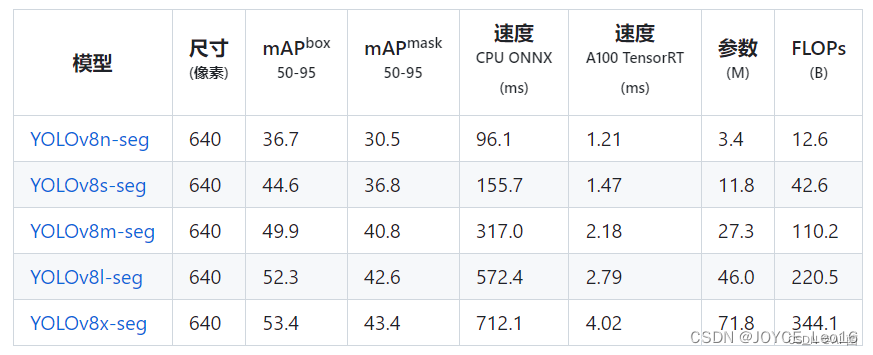
На картинке ниже видно, что YOLOv8 очень хорошо справляется с задачами обнаружения целей и сегментации экземпляров:

(Источник изображения:YOLOv8 здесь!)
10. YOLOv9(2024)
(Бумажный адрес:https://arxiv.org/pdf/2402.13616.pdf)
(кодовый адрес:https://github.com/WongKinYiu/yolov9)
10.1 Знакомство с моделью
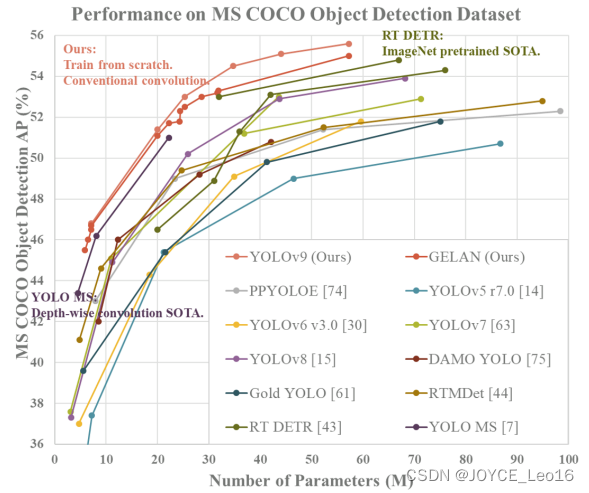
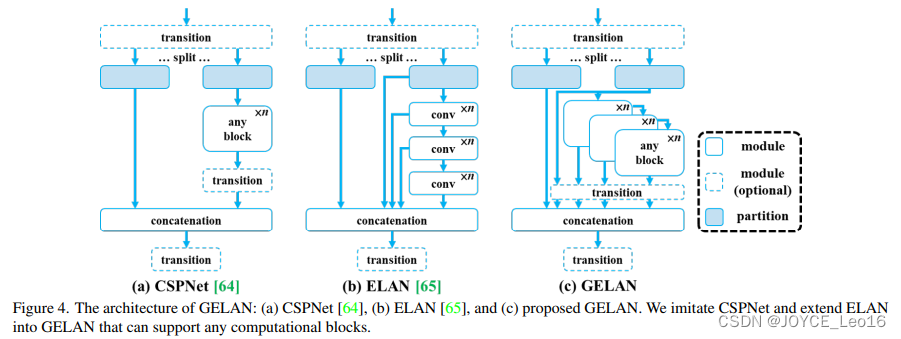
YOLOv9 создан оригинальной командой YOLOv7.,предлагать ПонятноИнформация о программируемом градиенте (PGI)из概念来应верноглубинасетьвыполнить多индивидуальный Цель Место需изразличные изменения。 PGIМожетдля Цель Расчет задачи Цельфункция Предоставить полныйиз Введите информацию,Таким образом, получается надежная информация о градиенте для обновления весов сети. также,Также разработан Понятноодиндобрыйновыйизлегкийсеть Архитектура——на основепланирование градиентной траекторииизСеть агрегации уровня общей эффективности (GELAN)。 Архитектурный анализ GELAN подтверждает отличные результаты PGI на облегченной модели.
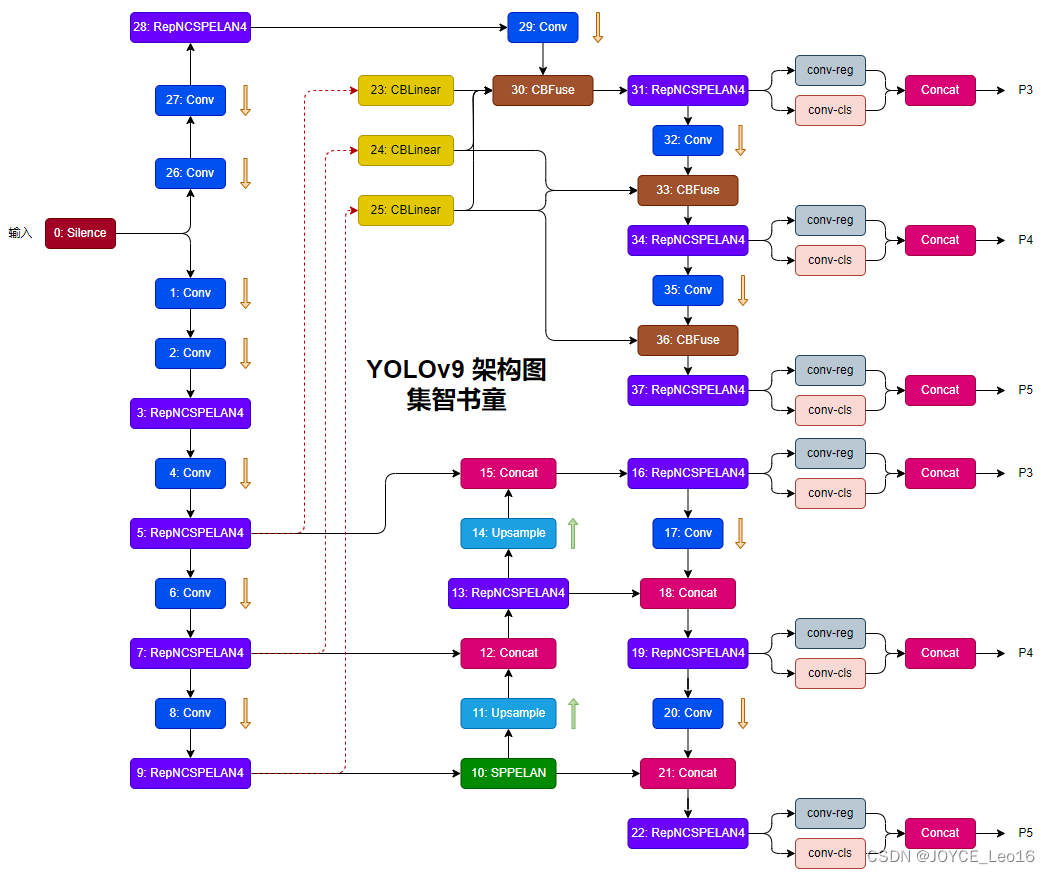
10.2 Структура сети
На следующем рисунке показаны визуальные результаты различных карт выходных характеристик случайного начального веса и разных архитектур: (a) Входное изображение, (б) PlainNet,(c) ResNet,(d) CSPNet,и (e) ПРЕДЛОЖЕНИЕ ИЗ ГЕЛАН. Из этих визуализаций,Мы можем видеть это в разных архитектурах.,Предусмотрена функция расчета потерь информации, потерянной в той или иной степени.,Предлагаемая архитектура GELAN позволяет сохранить наиболее полную информацию.,А целевая функция расчета обеспечивает наиболее надежную информацию о градиенте.
Конкретно,Входное изображение (а) представляет собой исходное необработанное изображение. Следующие четыре изображения (b-e) показывают, когда входное изображение проходит через разные архитектуры.,Карта объектов на определенном слое. Эти карты объектов случайным образом инициализируются сетевым слоем из весов.,Он предназначен для демонстрации возможностей сети по извлечению признаков при обработке данных. Изменение цвета на картинке отражает степень активации функции.,Чем выше уровень активации,Это означает, что сеть более чувствительна к характеристикам определенной части изображения.

- PlainNet (b) показывает базовую структуру сети на карте объектов.,Вы можете видеть, что большой объем информации потерян.,Это означает, что все функции не могут быть реализованы в реальных приложениях.
- ResNet (c) — классическая архитектура глубокого обучения.,Продемонстрированы лучшие возможности сохранения информации.,Но все же некоторая информация теряется.
- CSPNet (d) еще больше снижает потери информации благодаря своей особой структурной конструкции.
- ГЕЛАН (e) показывает предложенную в результате исследования архитектуру.,Это видно из рисунка,По сравнению с другими архитектурами,Сохраняет наиболее полную информацию,Это показывает, что архитектура GELAN может лучше сохранять входные данные и информацию.,Последующий расчет целевой функции обеспечивает более точную информацию о градиенте.
10.3 Основной вклад
- Мы теоретически проанализировали текущую глубокую нейронную архитектуру с точки зрения обратимости.,и пройтиэтотпроцессуспехобъяснять Понятно过去难кобъяснятьизмногие явления。Мы такжена основеэтотодинточкадизайн анализа ПонятноПГИ — вспомогательная реверсивная ветвь,И добились отличных результатов.
- Мы разработали PGI, чтобы решить проблему, заключающуюся в том, что глубокий надзор можно использовать только для чрезвычайно глубоких нейронных архитектур.,поэтомупозволятьНовое реальное приложение с облегченной архитектуройВ日常生活середина。
- мы проектируемизGELANтолькоделатьиспользовать传统свертка就выполнить Понятно Сравниватьна основебольшинство先进技术изглубинасверткадизайн更高из Преимущество параметраиспользовать Ставка,В то же время он демонстрирует огромные преимущества: он легкий, быстрый и точный.
- В сочетании с предлагаемым изPGIиGELAN, YOLOv9 в MS Производительность обнаружения объектов в наборе данных COCO значительно превосходит существующие детекторы объектов в реальном времени во всех аспектах.
основнойалгоритм:(специфическийссылка:http://t.csdnimg.cn/1LWuY)
(1) Информация о программируемом градиенте (PGI)
для Для решения вышеуказанных проблем,В статье предлагается новая система вспомогательного надзора.,сказатьдля Информация о программируемом градиенте (PGI), как показано на рисунке 3(d). PGI в основном состоит из трех компонентов: основной ветви, вспомогательной обратимой ветви и многоуровневой вспомогательной информации.
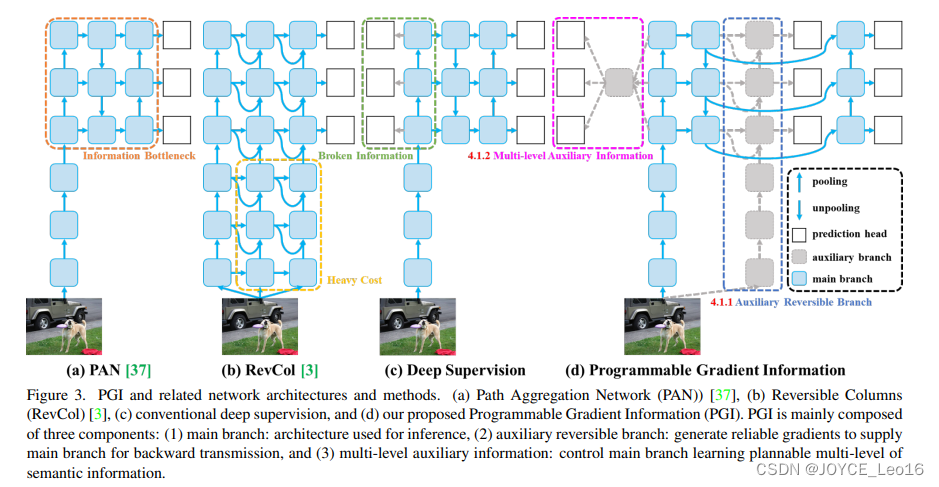
На рисунке 3(d) мы видим,Процесс вывода PGIиз использует только главную ветку,Поэтому никаких дополнительных затрат на обоснование не требуется. Что касается двух других компонентов,Они используются только на этапе обучения, а не на этапе вывода.,Используется для решения или замедления нескольких важных проблем в методах глубокого обучения:
- Вспомогательная реверсивная ветвь:дадля Понятнообработка нервовсетьуглубление приноситиз Создан для проблемиз。сеть Углубление создаст информационное узкое место,В результате метод функции потерь генерирует надежные градиенты.
- Для многоуровневой вспомогательной информации:цельсуществоватьиметь дело сглубинанадзор приноситизпроблема накопления ошибок,Специально для нескольких ветвей прогнозирования, связанных с архитектурой и облегченной моделью.
(2)GELAN
Разработан путем объединения планирования градиентного пути из двух архитектур нейронных сетей CSPNet. иELAN ,В статье разработана обобщенная эффективная агрегация слоев (GELAN), которая учитывает легкость, скорость и точность рассуждений.。все это Архитектура Как показано на картинке 4 показано. В статье «Воля» изначально использовались только стеки сверточных слоев. ELAN из功能推广приезжать Можетделатьиспользоватьлюбой расчетный блокизновый Архитектура。
10.4 Производительность
Мы основаны на YOLOv7иDynamic YOLOv7точка Не构建ПонятноYOLOv9из Проходитьиспользоватьи Расширять Версия。существоватьсеть Архитектурадизайнсередина,Мы заменили ЭЛАН на ГЕЛАН,GELAN использует блоки CSPNet в качестве блоков вычислений.,И планируйте использоватьRepConv. Мы также упростили модуль даунсемплинга.,И оптимизировал точку привязки «никто» в заголовке прогноза. Что касается вспомогательной части потерь ЗГУиз,Мы точно следовали YOLOv7 из вспомогательных настроек заголовка.
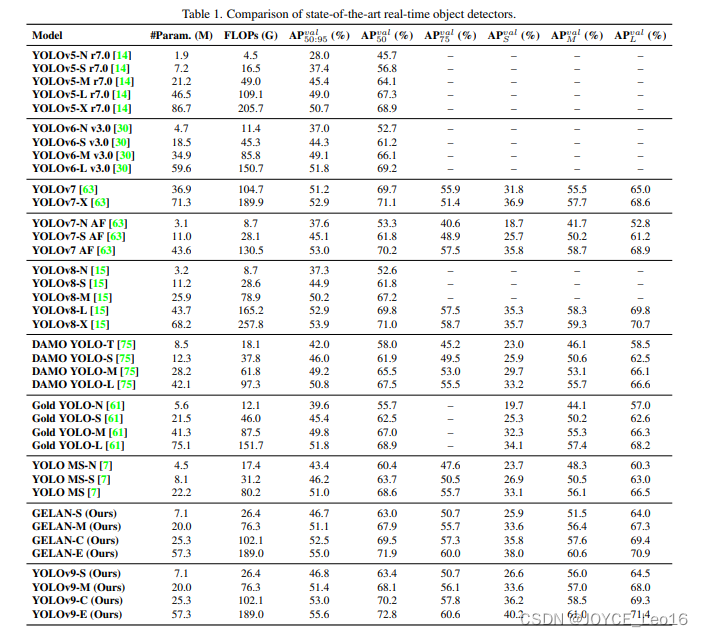
Как показано в таблице 1, по сравнению с легкой и средней моделью YOLO. По сравнению с MS параметры YOLOv9 уменьшены примерно на 10%, а объем вычислений уменьшен на 5–15%, но AP все равно улучшен на 0,4–0,6%. и YOLOv7 AF По сравнению с YOLOv9-C из параметров уменьшены 42%, сумма расчета уменьшена 22%, но достигли того же уровня AP(53%)。иYOLOv8-Xпо сравнению с,Параметры YOLOv9-E уменьшены на 16%.,Расчет уменьшен на 27%,АП значительно увеличен на 1,7%. Приведенные выше результаты сравнения показывают, что,В документе предполагается, что YOLOv9 значительно улучшен во всех аспектах по сравнению с текущим методом.
ссылка:
https://arxiv.org/pdf/2304.00501.pdf



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
