В этой статье вы разберетесь с Large Language Model (большая языковая модель).
Привет, ребята, меня зовут Луга. Сегодня мы поговорим о технологиях, связанных с экологической областью искусственного интеллекта (ИИ) — Большой языковой модели.
За последнее десятилетие область ИИ (искусственного интеллекта) добилась впечатляющих прорывов, и НЛП (обработка естественного языка) является одной из ее важных областей. НЛП фокусируется на разработке техник и методов обработки и понимания текстовых данных на человеческом языке.
Развитие НЛП позволяет машинам лучше понимать и обрабатывать человеческий язык, обеспечивая более интеллектуальное и естественное взаимодействие. Это включает в себя множество задач и областей применения, таких как классификация текста, анализ настроений, распознавание именованных объектов, машинный перевод, системы ответов на вопросы и т. д.
Суть технологии НЛП заключается в создании модели понимания и выражения языка. LLM (Large Scale Language Model) — одна из ключевых технологий. LLM основан на архитектуре глубоких нейронных сетей и может улавливать семантические и грамматические закономерности между словами, фразами и предложениями путем изучения текстовых данных в крупномасштабных корпусах. Это позволяет LLM автоматически генерировать связный и естественный текст, повышая производительность машины при обработке задач на естественном языке.
Поскольку технологии продолжают развиваться, сфера применения НЛП становится все более распространенной. Например, он широко используется в таких областях, как интеллектуальные помощники, интеллектуальное обслуживание клиентов, поиск информации, анализ общественного мнения и автоматическое обобщение. Однако НЛП по-прежнему сталкивается с некоторыми проблемами, такими как проблемы обработки двусмысленности, точности семантического понимания и обработки многоязычных и мультимодальных данных.
— 01 —
Что такое модель большого языка?
Языковая модель — это статистическая модель, используемая для прогнозирования вероятности появления ряда слов в текстовой последовательности. Языковая модель — важная технология искусственного интеллекта, основанная на искусственных нейронных сетях. Она обучается на крупномасштабных текстовых данных, чтобы понимать язык и предсказывать следующее слово в последовательности. LLM (Large Language Model), позже названная «LLM», представляет собой нейронную сеть с большим количеством настраиваемых параметров, позволяющих ей изучать сложные шаблоны и структуры языка.
Обучая крупномасштабные языковые модели, мы можем изучить контекстуальные отношения между словами, грамматическими правилами, а также общими фразами и структурами предложений, тем самым генерируя связный и естественный текст на основе заданного контекста.
LLM, также известная как предварительно обученная модель, представляет собой инструмент искусственного интеллекта, который использует огромные объемы данных для изучения особенностей языка. Благодаря обучению эти модели способны генерировать наборы данных на основе языка, которые можно использовать для различных задач понимания и генерации языка.
Одной из важных особенностей является способность LLM генерировать выходные данные, аналогичные человеческому тексту. Они создают связный, грамматический текст, который иногда даже демонстрирует чувство юмора. Кроме того, эти модели способны переводить текст с одного языка на другой и отвечать на вопросы в зависимости от заданного контекста.
Обучение LLM опирается на большой объем текстовых данных, включая веб-страницы, книги, новостные статьи и т. д. в Интернете. Обучаясь на этих данных, модель способна улавливать различные закономерности и закономерности языка, тем самым повышая точность предсказания следующего слова.
LLM имеет широкий спектр приложений, включая машинный перевод, генерацию текста, автоматическое обобщение, диалоговые системы и т. д. Например, в задачах машинного перевода модели могут генерировать результаты перевода на целевой язык в зависимости от контекста исходного языка. В диалоговой системе он может генерировать ответы на основе пользовательского ввода.

— 02 —
Ознакомьтесь с ландшафтом модели большого языка
На изображении ниже показан волновой эффект появления LLM (моделей большого языка), который может оказать влияние разными способами. В частности, появление LLM можно разделить на шесть групп или регионов, каждый из которых представляет разные потребности и возможности.
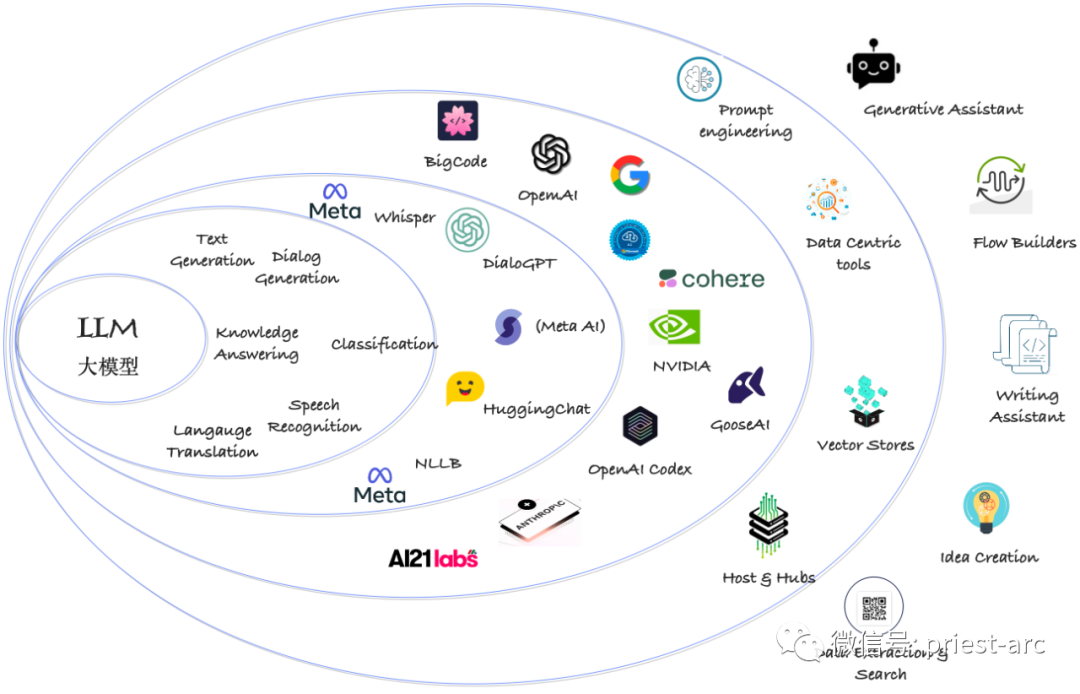
LLM (Large Language Model) панорамный вид с высоты птичьего полета
1. Область 1. Доступные большие языковые модели.
Учтите, что LLM (большая языковая модель) — это, по сути, модель для задач языковой обработки. Однако с точки зрения обработки мультимодальных данных, таких как изображения и аудио, вводятся мультимодальные модели или мультимодальные методы. Этот сдвиг привел к необходимости использования более общего термина для описания этих моделей — базовой модели.
Базовые модели — это модели, которые могут обрабатывать несколько типов данных (например, текст, изображения, аудио и т. д.). Они интегрируют различные компоненты и технологии для объединения и обработки информации в мультимодальных средах. Эти базовые модели могут одновременно обрабатывать входные данные из разных модальностей и генерировать соответствующие выходные результаты.
В дополнение к внедрению мультимодальной модели крупные коммерческие поставщики также предлагают еще несколько моделей, ориентированных на конкретные задачи. Эти модели предназначены для конкретных сценариев. примененияи Задачи оптимизированыитренироваться,Чтобы обеспечить более высокую производительность и более точные результаты. Например,Для таких задач, как классификация изображений, распознавание речи и понимание естественного языка.,Коммерческие поставщики предлагают специализированную модель,для удовлетворения клиентов с различными потребностями.
Кроме того, существует ряд моделей с открытым исходным кодом. Модели с открытым исходным кодом — это модели, совместно используемые исследователями и разработчиками, которые прошли обучение и продемонстрировали хорошую производительность при выполнении конкретных задач. Эти модели с открытым исходным кодом могут служить отправной точкой или основой, предоставляя разработчикам платформу для быстрого старта, а также способствуя исследованию моделей и обмену знаниями.
2. Область 2 — Общие сценарии применения
Модели обучаются конкретным задачам, чтобы обеспечить более целенаправленные и эффективные решения. Недавние разработки в области LLM используют подход, который сочетает в себе эти функции, позволяя модели использовать различные методы подсказки для достижения впечатляющей производительности.
LLM хорошо справляется с задачами по созданию текста, включая суммирование, переписывание, извлечение ключевых слов и многое другое. Эти модели способны генерировать точный и связный текст для удовлетворения различных потребностей.
В настоящее время анализ текста становится все более важным, и встраивание текста в модели имеет решающее значение для решения этих задач. Технология внедрения преобразует текст в векторные представления, обеспечивая лучшее семантическое понимание и понимание контекста.
Кроме того, распознавание речи (ASR) также является одним из направлений LLM, то есть процессом преобразования аудио речи в текст. Точность является важным показателем для оценки любого процесса ASR и часто измеряется с помощью коэффициента ошибок в словах (WER). Технология ASR предоставляет большой объем записанных языковых данных для обучения и использования LLM, делая преобразование и анализ текста более удобным и эффективным.
3. Область 3 — Реализация конкретной инфраструктуры
В этой области перечислены некоторые модели для конкретных целей. Реализации были разделены на мощные LLM общего назначения и цифровые/персональные помощники на основе LLM, такие как ChatGPT, HuggingChat и Cohere Coral. Эти специально созданные модели предоставляют индивидуальные решения для различных отраслей, делая языковую обработку и юридические приложения более эффективными и точными. Независимо от того, являются ли они общими моделями или моделями, специфичными для правовой сферы, все они играют важную роль в различных областях, обеспечивая пользователям лучшее понимание языка и возможности решения проблем.
4. Область 4 — Классификация моделей
В этом разделе перечислены самые известные крупные поставщики языковых моделей. Большинство LLM обладают встроенными знаниями и возможностями, включая перевод на человеческий язык, способность интерпретировать и писать код, диалог и управление контекстом посредством быстрого проектирования. LLM, предоставляемый поставщиком, может удовлетворить потребности различных пользователей: от межъязыкового общения до написания кода, от диалоговой системы до управления контекстом, предоставляя пользователям мощную языковую обработку и интеллектуальные услуги. Разработке этих крупномасштабных языковых моделей способствовали достижения в области глубокого обучения и обработки естественного языка, предоставляя людям более инновационные и удобные инструменты.
5. Область 5 — Основные инструменты/платформы
Концепции, представленные в этой области, представляют собой инструменты, ориентированные на данные, которые направлены на то, чтобы сделать использование LLM (больших языковых моделей) повторяемым и высокоэффективным. Это означает, что основное внимание уделяется тому, как эффективно использовать данные для повышения производительности и ценности применения LLM.
6. Область 6 — Конечный пользователь
В этой области появляется множество приложений, которые фокусируются на построении процессов, генерации идей, создании контента и помощи в написании. Эти продукты призваны обеспечить качественный пользовательский опыт и повысить ценность LLM (больших языковых моделей) и пользователей. С помощью этих приложений пользователи могут лучше использовать потенциал LLM для достижения более выдающихся и эффективных результатов в работе и творчестве.
— 03 —
Large Language Model Как это работает?
LLM работает с использованием метода, называемого обучением без учителя. При обучении без учителя модель обучается на больших объемах данных без конкретных меток или целей. Цель состоит в том, чтобы изучить базовую структуру данных и создать новые данные со структурой, аналогичной исходным данным.
Для LLM обучающие данные обычно представляют собой крупномасштабные текстовые корпуса. Модель изучает шаблоны в текстовых данных и использует эти шаблоны для создания нового текста. Процесс обучения включает в себя оптимизацию параметров модели, чтобы минимизировать разницу между сгенерированным текстом и фактическим текстом в корпусе.
После обучения модели ее можно использовать для создания нового текста. Для этого модели предоставляется начальная последовательность слов, и она генерирует следующее слово в последовательности на основе вероятностей слов в обучающем корпусе. Повторяйте этот процесс до тех пор, пока не будет сгенерирован текст нужной длины.
Здесь мы кратко понимаем принцип работы LLM. Для получения подробной информации обратитесь к следующей принципиальной схеме:
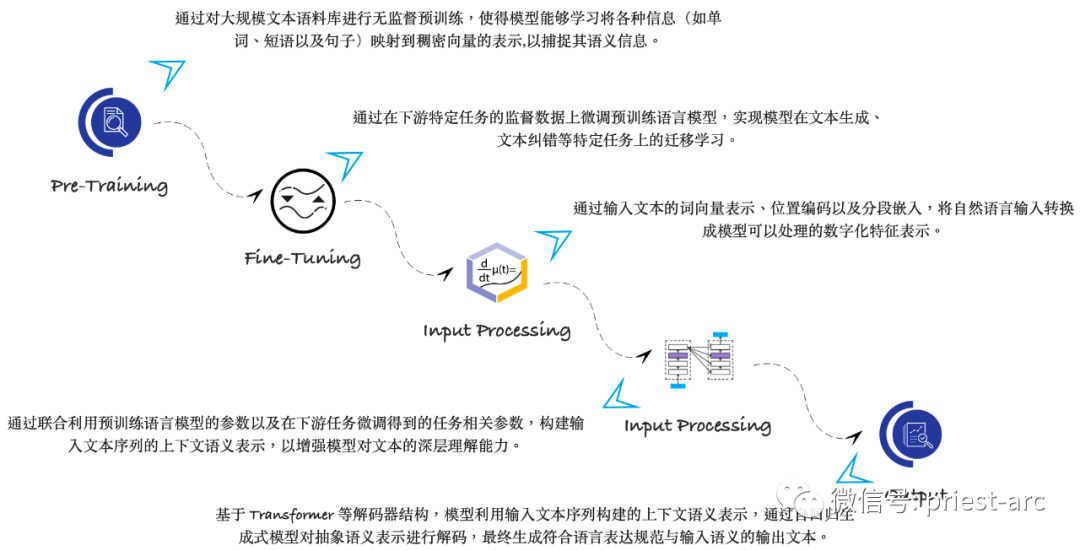
Важно понимать, как работают LLM, и понимать различные типы доступных языковых моделей. Наиболее распространенные типы языковых моделей включают рекуррентные нейронные сети (RNN), сверточные нейронные сети (CNN) и сети долгосрочной краткосрочной памяти (LSTM). Эти модели обычно обучаются на больших наборах данных, таких как Penn Treebank, и могут использоваться для создания наборов данных на основе языка.
Далее, давайте подробнее рассмотрим некоторые из ведущих LLLM (больших языковых моделей), их создателей и количество параметров, по которым они обучаются. Эти модели представляют собой самые передовые технологические разработки в области искусственного интеллекта. Для получения более подробной информации, пожалуйста, обратитесь к следующей диаграмме:
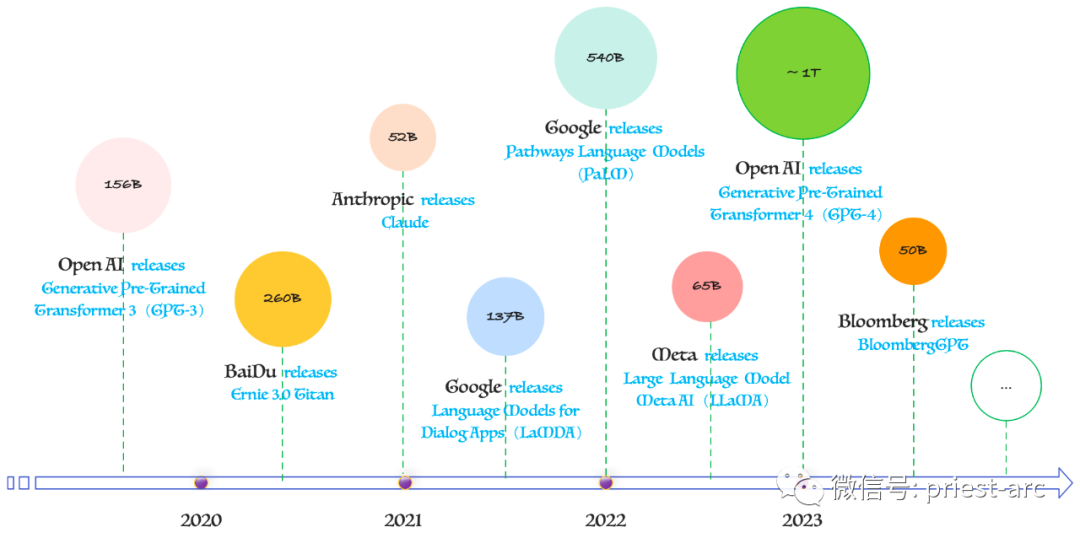
Источник: Roundhill Investments.
На основе приведенной выше диаграммы параметров модели мы видим, что существует множество популярных LLM (больших языковых моделей), а именно:
OpenAI — компания, занимающая важную позицию в сфере LLLM. Их модель ChatGPT прошла обширные исследования и обучение и представляет собой мощную языковую модель, основанную на модели генеративного предварительно обученного трансформатора (GPT). Хотя конкретное количество параметров не разглашается, исходя из предыдущих версий, разумно предположить, что ChatGPT может иметь от десятков до сотен миллиардов параметров.
Google также инвестирует значительные ресурсы в исследования и разработку крупномасштабных языковых моделей. Каждая из их моделей LaMDA и PaLM имеет десятки миллиардов параметров, и эти модели демонстрируют превосходное понимание языка и возможности генерации благодаря обучению на крупномасштабных наборах данных. В то же время Google также инвестировала в Anthropic, компанию, которая выпустила модель Клода с десятками миллиардов параметров.
Модель Ernie 3.0 Titan от Baidu, которая используется в чат-боте ErnieBot, имеет сотни миллиардов параметров. и китайская компания SenseTime, занимающаяся искусственным интеллектом, разработали модель SenseNova для своего чат-бота SenseChat и других сервисов, которые также имеют сотни миллиардов параметров.
Кроме того, Bloomberg создал модель BloombergGPT, специфичную для финансовой сферы, которая имеет десятки миллиардов параметров и обеспечивает мощные возможности языковой обработки для задач, связанных с финансами.
Хотя Microsoft явно не отмечена выше, на самом деле Microsoft также внесла не менее важный вклад в область LLLM. Они запустили модель GPT, используемую в поиске Bing AI. По количеству параметров эта модель, пожалуй, сравнима с другими топ-моделями.
Эти ведущие крупномасштабные языковые модели благодаря огромному количеству параметров позволяют им лучше понимать и генерировать естественный язык. Они представляют собой последние достижения в области искусственного интеллекта и демонстрируют большой потенциал и перспективы применения в различных областях.
— 04 —
Large Language Model Сценарии применения
В последние годы использование больших языковых моделей значительно возросло благодаря доступности больших наборов данных и достижениям в области технологий искусственного интеллекта. Поскольку технология искусственного интеллекта продолжает совершенствоваться, точность и возможности больших языковых моделей будут продолжать улучшаться, что делает их более полезными в различных задачах обработки естественного языка.
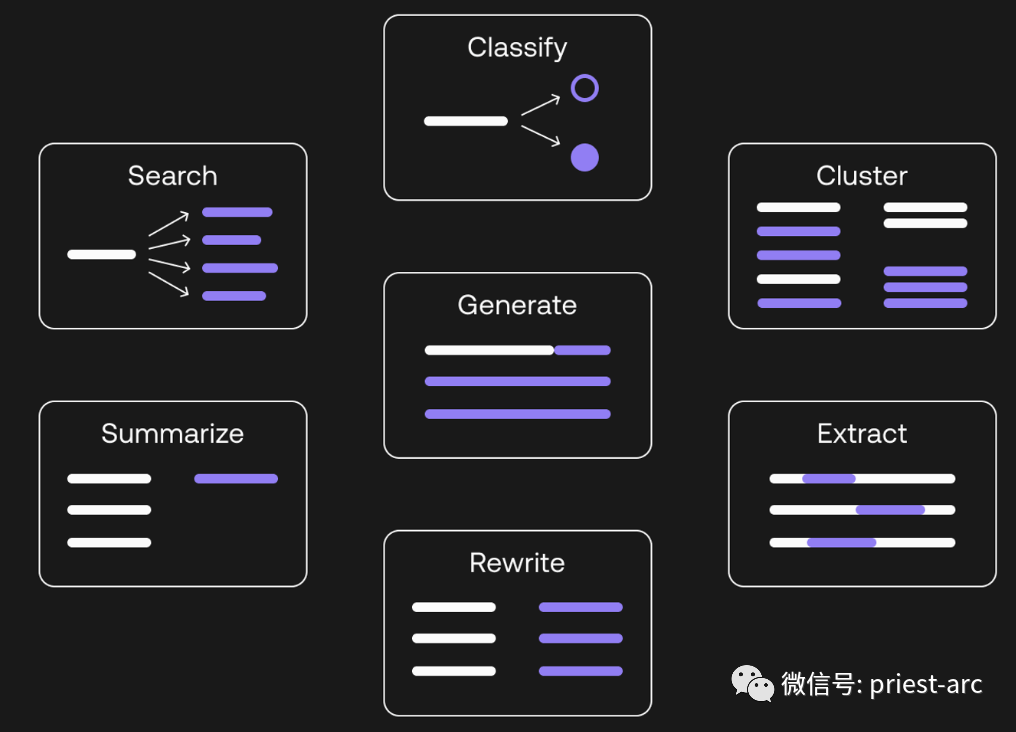
Обычно большие языковые модели имеют широкий спектр приложений в различных областях. Их можно применять в таких областях, как обработка естественного языка, искусственный интеллект и наука о данных, обеспечивая мощную поддержку и функциональность для многих приложений. Вот некоторые типичные области применения и примеры:
1. Языковой перевод
Языковой перевод является одним из важных применений LLM. LLM может быстро переводить слова с одного языка на другой. Он делает это, сравнивая два языка и пытаясь перевести их предложение за предложением с помощью так называемого параллельного корпуса. LLM использует два основных метода перевода: прямой перевод и перевод кодер-декодер.
Обе технологии используют методы глубокого обучения для достижения высококачественного перевода. Все эти технологии перевода основаны на методах глубокого обучения. Благодаря крупномасштабным обучающим данным и способности нейронных сетей к обучению LLM может обеспечить точный и плавный языковой перевод. Благодаря постоянному развитию технологий применение LLM в области языкового перевода еще больше улучшит качество и эффективность перевода, а также будет способствовать удобству межъязыкового общения и культурного обмена.
2. Генерация контента
Генерация контента — еще одна важная область применения LLM. Результаты, генерируемые LLM, могут использоваться для создания текстового контента продуктов. Он может генерировать различные типы текста, такие как статьи, описания продуктов, брошюры и другой письменный контент. В этом отношении ChatGPT — очень мощный инструмент, способный генерировать высококачественный текстовый контент, практически неотличимый от контента, созданного человеком. Поэтому, если вам нужно писать контент для своих пользователей, идеальным выбором будет LLM и ChatGPT.
Важно отметить, что, хотя LLM и ChatGPT обладают большим потенциалом для создания контента, они по-прежнему требуют ручного просмотра и редактирования. Из-за автоматизированного характера модели она может генерировать неточную или вводящую в заблуждение информацию. Таким образом, перед использованием контента, созданного LLM, по-прежнему требуется проверка и изменение вручную, чтобы обеспечить точность и уместность контента.
3. Чат-бот и поддержка клиентов
Чат-боты являются основной областью применения LLM. LLM широко используется для создания чат-ботов, среди которых широко используемым инструментом является ChatGPT. Многие компании внедрили ChatGPT как часть своих чат-ботов поддержки клиентов, чтобы предоставить клиентам лучший опыт обслуживания, предоставляя точные ответы. По мере развития технологий многие технологические лидеры рассматривают возможность разработки собственных языковых моделей для удовлетворения уникальных потребностей бизнеса путем предоставления соответствующих внутренних данных.
Используя внутренние данные и обучение с учетом специфики бизнеса, компании могут создавать индивидуальные чат-боты, которые лучше соответствуют их бизнес-сценариям и потребностям клиентов.
4. Анализ эмоций и мониторинг общественного мнения
Анализ настроений — еще одно важное применение LLM. Эти модели можно использовать для анализа тональности текста, помогая определить, имеет ли текст положительную или отрицательную направленность. Анализ настроений имеет широкое применение во многих областях, включая мониторинг социальных сетей, управление репутацией бренда, исследования рынка и т. д.
LLM имеет широкие перспективы применения в области анализа настроений. Автоматизированный анализ настроений может помочь компаниям и организациям лучше понять эмоциональные отношения пользователей, чтобы принимать более целенаправленные решения и улучшения. Тем не менее, по-прежнему необходимо обращать внимание на ограничения модели и учитывать человеческий анализ и суждения, чтобы обеспечить точность и надежность результатов анализа настроений.
5. Персонализированные рекомендации и реклама
Персонализированные рекомендации и реклама — еще одна важная область применения LLM. Эти модели могут предоставлять персонализированные рекомендации и рекламный контент на основе интересов и моделей поведения пользователей. Глубоко понимая потребности и предпочтения пользователей, LLM может предоставить более точные и персонализированные рекомендации, тем самым повышая удовлетворенность пользователей и эффективность рекламы.
— 05 —
Large Language Model Текущие проблемы
LLM (большая языковая модель) добилась крупных прорывов в области обработки естественного языка, но также сталкивается с некоторыми проблемами. Вот некоторые общепризнанные проблемы, с которыми сталкиваются LLM:
1. Затраты на обучение и потребности в ресурсах
Вообще говоря, LLM требует огромных обучающих данных и вычислительных ресурсов для обучения. Такой процесс обучения требует много времени, ресурсов хранения и вычислительных мощностей, а также огромных объемов размеченных данных. Поэтому создание и обучение LLM требует огромных инвестиций.
2. Смещение данных и тенденция модели
LLM имитирует закономерности и предвзятости в своих обучающих данных. Если данные обучения предвзяты, например, по признаку пола или расовой принадлежности, модель может отражать эти предвзятости и проявляться в сгенерированном тексте. Это может привести к тому, что модель будет давать несправедливые или вредные результаты. Решение этой проблемы требует более сбалансированных и разнообразных обучающих данных, а также эффективного обнаружения и коррекции ошибок моделей.
3. Недостаточные знания и рассуждения.
Хотя студенты LLM добились значительного прогресса в создании и понимании языка, они по-прежнему страдают от недостатков реальных знаний и рассуждений. Из-за этого модель плохо работает при работе со сложными сценариями реального мира, логическими рассуждениями и рассуждениями, основанными на здравом смысле. Решение этой проблемы требует дальнейшей интеграции внешних знаний и возможностей рассуждения в модель для улучшения ее возможностей реального применения.
4. Объясняемость и управляемость
LLM Модель, которую часто считают черным ящиком, трудно объяснить, на чем основаны ее решения и генерируется текст. Это для некоторых Сценариев применение - это единственная проблема,Например, прозрачное и объяснимое принятие решений необходимо в таких областях, как право и медицина. поэтому,Улучшение интерпретируемости и управляемости Модели является важным направлением для компании One.
5. Ложная информация и злоупотребления
LLM может использоваться для создания дезинформации, злонамеренных атак и злоупотреблений. Их можно использовать для таких действий, как онлайн-мошенничество, фишинг и распространение фейковых новостей. Поэтому обеспечение безопасности моделей и устойчивости к злоупотреблениям является важной задачей.
Несмотря на то, что вышеперечисленное является лишь некоторыми из проблем, с которыми сталкивается LLM, поскольку технология продолжает развиваться, исследователи и разработчики усердно работают над решением этих проблем, чтобы улучшить производительность, надежность и удобство использования модели.
Reference :
[1] https://cobusgreyling.medium.com/
[2] https://em360tech.com/tech-article/large-language-model
Adiós !
··································
📣📣📣
Привет, ребята, я Луга, посол Traefik, посол Jakarta EE, технический ветеран более 10 лет. Я прошел путь от ИТ до кодирования и, наконец, до архитектора «соевого соуса». Если вам нравятся технологии, но не нравится стонать, то поздравляю, вы попали по адресу. Следуйте за мной и учитесь, прогрессируйте и превосходите вместе~

Я серьезно отношусь к каждому лайку, просмотру и репосту, который вы получаете, как лайк ~



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).
Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
