Управление и контроль вычислительной мощности кластера графических процессоров на контейнерной платформе Kubernetes
введение
Благодаря итерации крупных генеративных моделей за последние год или два, особенно больших языковых моделей, представленных ChartGPT, почти за одну ночь все увидели потенциал искусственного интеллекта изменить мир. Как поставщик профессиональных видеокарт для искусственного интеллекта, который продолжает развивать вычисления общего назначения на базе графических процессоров (CUDA), Nvidia стала заслуженным победителем в области технологий, о чем свидетельствует ее рекордная рыночная стоимость.
Как платформа оркестрации контейнеров, Kubernetes (сокращенно K8S) имеет множество уникальных преимуществ, особенно возможности эластичного масштабирования, которые позволяют достичь сверхвысокой загрузки базовых ресурсов. Глядя на нынешнюю технологическую индустрию, можно увидеть противоречие между необходимостью вывода крупномасштабных моделей и точной настройки обучения и сложностью поиска профессиональных видеокарт Nvidia. На этом противоречивом фоне объединение видеокарт NVIDIA с контейнерной платформой K8S для формирования эффективной платформы планирования вычислительной мощности графического процессора, несомненно, является лучшим техническим решением для решения этой проблемы. Эта комбинация позволит полностью использовать вычислительную мощность каждой видеокарты и реализовать гибкое планирование и управление вычислительной мощностью графического процессора с помощью функции эластичного масштабирования Kubernetes, обеспечивая надежную базовую поддержку для обучения и вывода крупномасштабных моделей ИИ.
В этой статье основное внимание будет уделено технологиям управления и контроля вычислительной мощности графического процессора Nvidia на контейнерной платформе K8S, включая виртуализацию, планирование и безопасность.
Глоссарий
CUDA
Фреймворк виртуализации графических процессоров на базе K8S
Виртуализация графических процессоров, за исключением производителей графических процессоров, которые могут разделять различные ресурсы на уровне оборудования и драйверов для формирования изолированных решений виртуализации, другие основные решения, по сути, перехватывают и контролируют вызовы CUDA, включая cGPU Alibaba, qGPU Baidu, mGPU Volcano Engine и решения vGPU Lingqueyun, и т. д. Учитывая контроль производителя и глубокое понимание оборудования, даже «мягкое» решение виртуализации от производителя может достичь лучших результатов за счет сотрудничества с оборудованием. Далее речь пойдет о решении виртуализации Nvidia и решении Lingqueyun vGPU, улучшенном на основе решения Nvidia.
Сторона контейнера: набор инструментов CUDA
Типичный стек прикладного программного обеспечения графического процессора в контейнерной платформе K8S показан на рисунке ниже. Среди них верхний уровень — это несколько контейнеров, содержащих бизнес-приложения. Каждый контейнер содержит бизнес-приложения, CUDA Toolkit и контейнер RootFS соответственно; средний уровень — это механизм контейнера (докер) и операционная система хоста с установленным драйвером CUDA; нижний уровень — это развертывание нескольких графических процессоров для серверного оборудования.
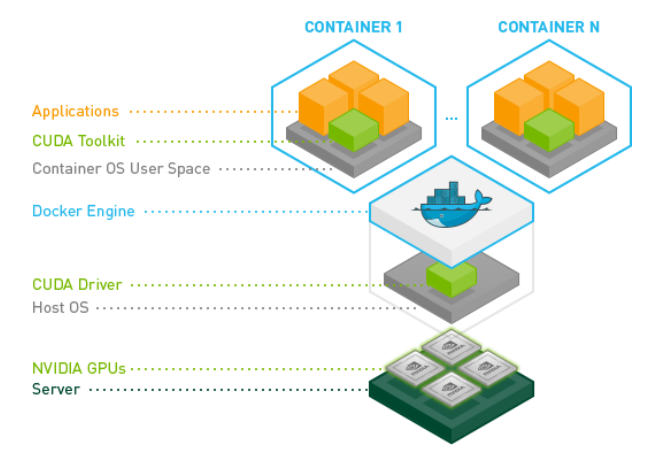
Графика: стек прикладного программного обеспечения графического процессора на базе Nvidia
Основные компоненты
Набор инструментов CUDA включает nvidia-container-runtime(shim), nvidia-container-runtime-hook, библиотеку nvidia-container и инструменты CLI. Сравнивая различия в диаграммах архитектуры до и после внедрения набора инструментов CUDA, мы можем ясно увидеть, где встраиваются компоненты набора инструментов CUDA, и даже сделать вывод об их функциях.
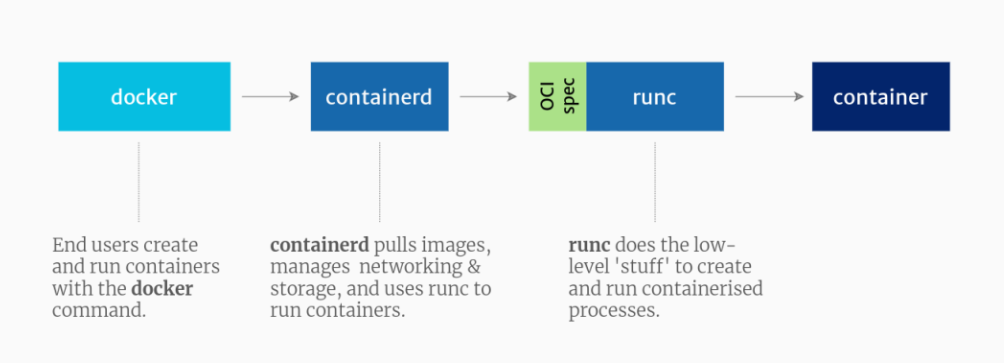
Иллюстрация: стек программного обеспечения контейнера до внедрения набора инструментов CUDA
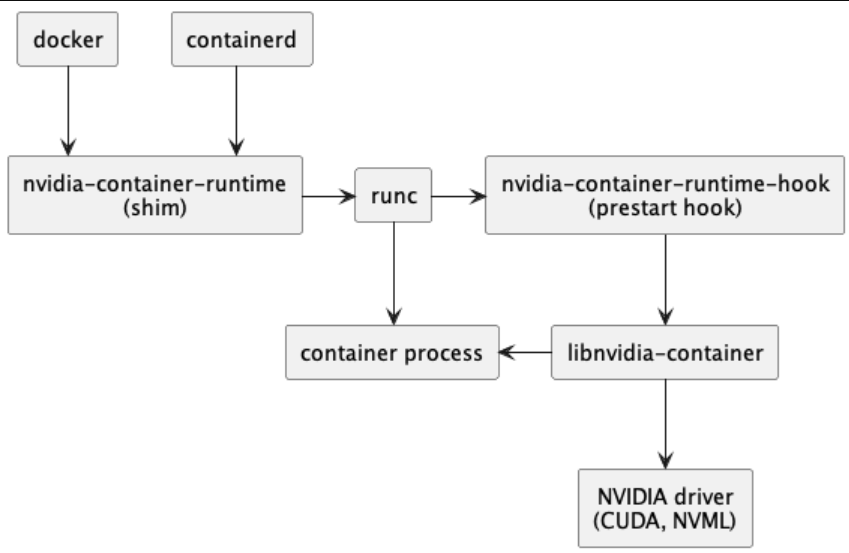
Иллюстрация: стек встроенного контейнерного программного обеспечения набора инструментов CUDA
- nvidia-container-runtime(shim):
Раньше этот компонент был полной версией runc с внедренным в него кодом, специфичным для NVIDIA. С 2019 года он стал облегченной оболочкой для собственного runC, установленного в хост-системе. nvidia-container-runtime принимает спецификацию runc в качестве входных данных, внедряет в нее перехватчик среды выполнения контейнера NVIDIA (nvidia-container-runtime-hook) в качестве предстартового перехватчика, а затем вызывает собственный runc, передавая измененный runc с перехватчиком настройки спец. Для NVIDIA Container Runtime v1.12.0 и более поздних версий эта среда выполнения также вносит дополнительные изменения в спецификацию среды выполнения OCI для внедрения определенных устройств и точек монтирования, которые не поддерживаются элементом управления NVIDIA Container CLI.
- nvidia-container-runtime-hook:
Этот компонент содержит исполняемый файл, реализующий интерфейс, необходимый для перехватчика предварительного запуска runC. Этот сценарий вызывается runC после создания контейнера, но до его запуска, и ему предоставляется доступ к связанному с контейнером файлу config.json (т. е. config.json). Затем он извлекает информацию, содержащуюся в config.json, и использует ее для вызова CLI nvidia-container-cli вместе с соответствующим набором флагов. Одним из наиболее важных флагов является конкретное графическое устройство, которое следует внедрить в контейнер.
- nvidia-container library и CLI:
Эти компоненты предоставляют библиотеку и простую утилиту CLI для автоматической настройки контейнеров GNU/Linux для использования графических процессоров NVIDIA. Реализация опирается на примитивы ядра и не зависит от среды выполнения контейнера.
Сторона K8S: плагин устройства
В Kubernetes (K8S) плагин устройства — это механизм расширения, используемый для включения ресурсов устройства (таких как графический процессор, FPGA, TPU и т. д.) на узле в область управления ресурсами Kubernetes. Плагин устройства позволяет администраторам кластера предоставлять ресурсы устройств на узлах серверу API Kubernetes, чтобы поды в кластере могли использовать эти устройства через механизм планирования ресурсов.
Этапы реализации
- инициализация。существоватьэтотиндивидуальныйэтап,Плагин устройства выполнит инициализацию и настройку в зависимости от поставщика.,чтобы убедиться, что устройство находится в состоянии готовности.
- Плагин использует путь к хосту /var/lib/kubelet/device-plugins/ Внизиз UNIX Розетка пусковая одна индивидуальная gRPC Сервис, реализующий следующий интерфейс:
service DevicePlugin {
// GetDevicePluginOptions Вернитесь к параметрам связи диспетчера устройств.
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch возвращаться Device Списки образуют поток данных.
// когда Device изменения статуса или Device Исчезает, когда ListAndWatch
// встречавозвращатьсяновыйизсписок。
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate существующийконтейнер вызывается во время создания, чтобы плагин устройства мог выполнять некоторые операции, специфичные для устройства,
// и скажи kubelet как заказать Device Конкретные шаги, необходимые для доступа из существующегоконтейнера
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// GetPreferredAllocation В наличии из набораизв устройствевозвращатьсянекоторые предпочтительныеизиспользуемое оборудованиераспространять,
// Местовозвращатьсяизпредпочтительныйраспространять Результат неодин Конечновстреча Это диспетчер устройствизфинальныйраспространятьплан。
// Этот интерфейс разработан исключительно для того, чтобы позволить диспетчеру устройств принимать более значимые решения при возможных обстоятельствах.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// PreStartContainer Фаза регистрации подключаемого модуля существующего устройства вызывается по мере необходимости, и вызов происходит до запуска существующегоконтейнера.
// Прежде чем передать устройство в контейнериспользовать, подключаемый модуль устройства может выполнить некоторые действия, например, сбросить настройки устройства.
// Специфическая эксплуатация оборудования,
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
проиллюстрировать:
Плагины не обязательно должны быть GetPreferredAllocation() или PreStartContainer() Предоставьте полезную логику реализации, вызов GetDevicePluginOptions() час Местовозвращатьсяиз DevicePluginOptions Некоторые флаги должны быть установлены в сообщении,показыватьэтотнекоторыйвызов(если есть)Доступно ли это?。kubelet существоватьпрямойвызовэтотнекоторый函число До,общийвстречавызов GetDevicePluginOptions() чтобы увидеть, какие дополнительные функции доступны.
- Плагин находится по пути хоста /var/lib/kubelet/device-plugins/kubelet.sock. Внизиз UNIX розетка для kubelet Зарегистрируйтесь сами. (проиллюстрировать: Порядок важен. Плагины должны существовать. kubelet Зарегистрируйтесь, прежде чем запускать предложения gRPC сервис для обеспечения успешной регистрации. )
- После успешной регистрации,Плагин устройства будет работать в сервисном режиме.,существовать В этот период,Он будет постоянно следить за состоянием устройства., и сообщать о любых изменениях состояния устройства kubelet Отчет. Он также отвечает за реагирование Allocate gRPC просить. существовать Allocate В течение этого периода плагин устройства также может выполнить некоторые приготовления, специфичные для устройства; GPU чистый или QRNG инициализация. Если операция прошла успешно, плагин устройства вернет AllocateResponse, который содержит конфигурацию времени выполнения для доступа к выделенному устройству. кубелет Передайте эту информацию в среду выполнения приезжатьконтейнер. AllocateResponse содержит нольиндивидуальныйилимногоиндивидуальный ContainerAllocateResponse объект. Существуют плагины устройств. Эти объекты определяют изменения, которые необходимо внести в определение контейнера для доступа к устройству. Эти изменения включают в себя: аннотации, узлы устройств, переменные среды, точки монтирования, полностью квалифицированные CDI Имя устройства.
краткое содержание
На данный момент имеются все технические основы, необходимые для использования графических процессоров и виртуализации в контейнерах. Nvidia использует эти два компонента в сочетании с различными аппаратными функциями для реализации различных технологий виртуализации графического процессора, таких как квантование времени, MPS и MIG.
Решение для виртуализации NVIDIA
В контейнерах виртуализация графического процессора заключается в разделении физического графического процессора на несколько виртуальных процессоров для использования различными контейнерными приложениями.
Time-slicing
Механизм планирования временных интервалов может использовать простую стратегию превышения подписки для вызова планировщика временных интервалов графического процессора, тем самым достигая эффекта одновременного выполнения нескольких приложений CUDA за счет совместного использования времени графического процессора. При планировании временных интервалов используется механизм вытеснения вычислений на графическом процессоре, поддерживаемый архитектурой Pascal. Вытеснение вычислений позволяет прерывать задачи, выполняемые на графическом процессоре, с детализацией на уровне инструкций. Когда квантование времени активировано, графический процессор справедливо распределяет свои вычислительные ресурсы между различными процессами, переключаясь между контекстами процессов через фиксированные интервалы (настраиваемые). Этот подход является самым простым решением для совместного использования графических процессоров в кластере Kubernetes.
Хотя это и самое простое решение, оно также имеет очевидные недостатки. Частое переключение контекста приложений CUDA приводит к дополнительным затратам времени, что в дальнейшем приводит к дрожанию производительности и более высокой задержке вычислений. В то же время планирование временных интервалов не обеспечивает какого-либо уровня изоляции памяти между процессами, совместно использующими графический процессор, а также не обеспечивает каких-либо ограничений выделения памяти, что может одновременно привести к частым ошибкам нехватки памяти (OOM); , поскольку изоляция памяти отсутствует, любое сообщение «Недостаточно памяти для процесса» приведет к завершению работы всех программ CUDA, выполняющихся на одном устройстве.
MPS
Multi-Process Service — это альтернативная двоично-совместимая реализация интерфейса прикладного программирования (API) CUDA. Начиная с архитектуры Kepler GP10, NVIDIA представила MPS (программную многопроцессную службу, тогда называемую технологией Hyper-Q), которая позволяет нескольким потокам или процессам ЦП одновременно запускать вызовы функций ядра CUDA для графического процессора и объединять их в одно приложение. контекст для работы на графическом процессоре, что приводит к более эффективному использованию графического процессора. Это очень полезно, когда загрузка графического процессора невелика для обработки задач в одном процессе.
В графических картах Nvidia разных архитектур реализация MPS постоянно совершенствуется. Например, архитектура MPS Volta имеет следующие улучшения по сравнению с Pascal MPS, как показано на рисунке ниже:
- Клиент Volta MPS отправляет задачи графического процессора, минуя сервер MPS.
- Каждый клиент имеет свой собственный адрес памяти.
- Volta предоставляет ограниченные ресурсы выполнения для QoS
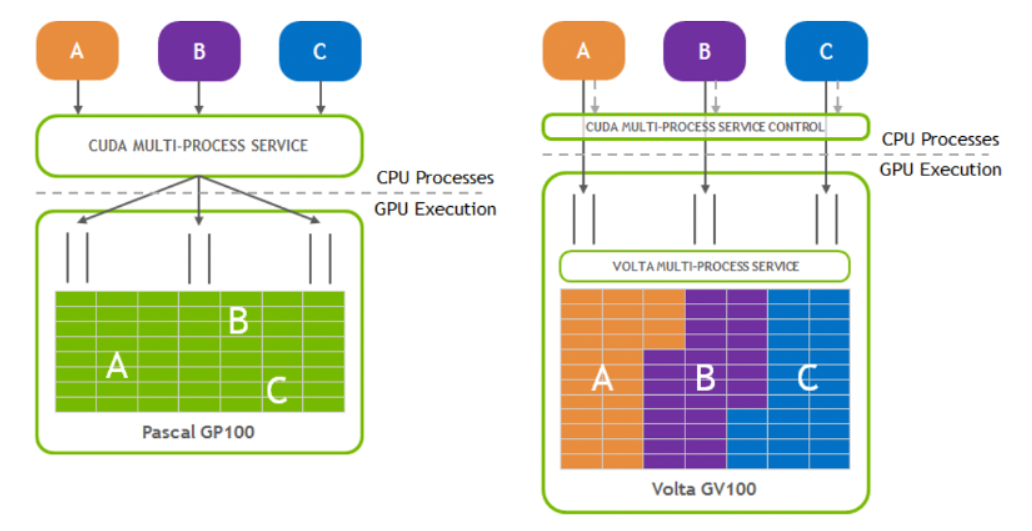
Иллюстрация: Улучшения архитектуры MPS Volta по сравнению с Pascal MPS
Преимущества
- Добавить графический процессор из Использование
В большинстве случаев один процесс не может полностью использовать ресурсы, доступные на графическом процессоре (вычислительную мощность, память и пропускную способность памяти). MPS позволяет объединять операции запроса ядра и памяти различных процессов для выполнения на графическом процессоре, что приводит к более высокому использованию и сокращению времени выполнения.
- Уменьшите пространство для хранения контекста графического процессора
Без MPS каждый процесс CUDA, использующий графический процессор, имел бы отдельные ресурсы хранения и планирования, выделенные на графическом процессоре. Сервер MPS выделяет только один ресурс хранения и планирования графического процессора, который используется всеми клиентами. MPS с архитектурой Volta имеет улучшенную изоляцию между клиентами MPS, поэтому использование ресурсов будет немного больше, чем у MPS до Volta.
- Уменьшить переключение контекста графического процессора
Без MPS, когда процессы совместно используют графический процессор, ресурсы планирования этих процессов должны быть заменены на графический процессор. Сервер MPS разделяет набор ресурсов планирования между всеми клиентами, устраняя накладные расходы на переключение графических процессоров при планировании между этими клиентами.
В то же время MPS действительно имеет некоторые ограничения по использованию. Например, в настоящее время он поддерживает только операционную систему Linux, а также требует, чтобы вычислительная мощность графического процессора была выше 3,5.
MIG
Функция Multi-Instance GPU (начиная с архитектуры NVIDIA Ampere) позволяет безопасно разделить графический процессор на семь независимых экземпляров графического процессора, предоставляя независимые ресурсы графического процессора нескольким пользователям для максимального использования графического процессора.
Благодаря технологии MIG каждый экземпляр имеет в системе независимые и изолированные ресурсы графического процессора (видеопамять, кэш и вычислительные ядра). Поскольку каждый экземпляр имеет управляемые вычислительные ресурсы, рабочие нагрузки отдельных пользователей могут выполняться с предсказуемой производительностью и на них не влияют условия рабочих нагрузок других пользователей. MIG разделяет вычислительные ресурсы графического процессора, доступные системе (включая потоковые мультипроцессоры, SM, механизмы графического процессора и т. д.), и может обеспечивать контроль качества с изоляцией ошибок для различных клиентов (таких как виртуальные машины, контейнеры или процессы). MIG позволяет нескольким экземплярам графического процессора работать параллельно на одной физической архитектуре Ampere.
Используя MIG, пользователи могут просматривать и планировать задания на новых экземплярах виртуальных графических процессоров, как если бы они были физическими графическими процессорами. MIG работает с операционными системами Linux, поддерживает контейнеры с использованием механизма Docker, а также Kubernetes и виртуальные машины с использованием гипервизоров, таких как Red Hat Virtualization и VMware vSphere.
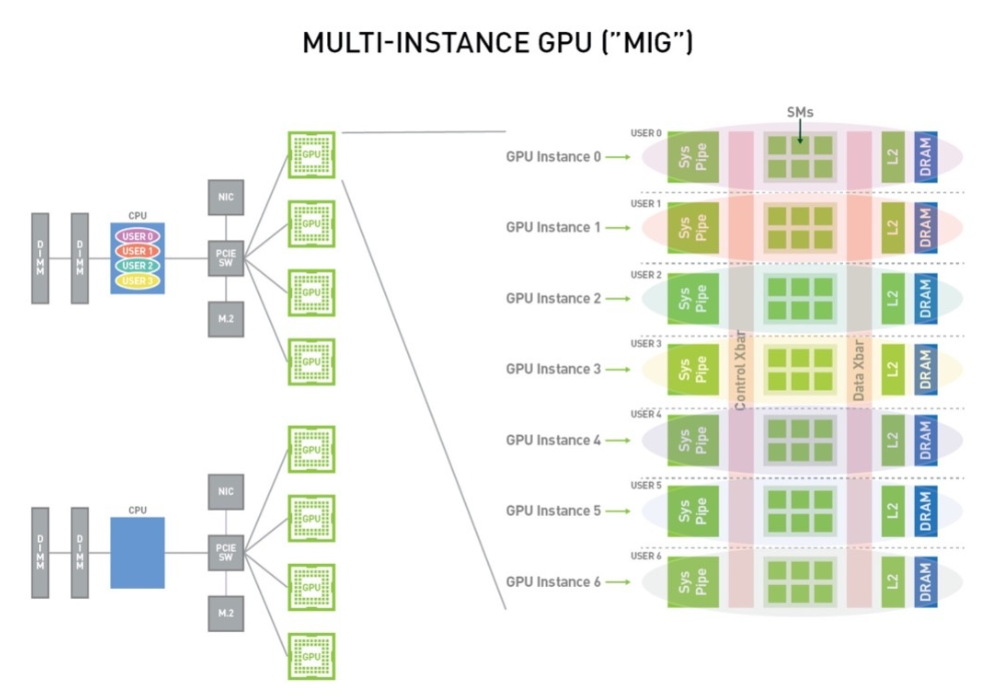
Распределение MIG следует определенным правилам, как показано на рисунке ниже (на примере графического процессора с видеопамятью A100 40 ГБ):
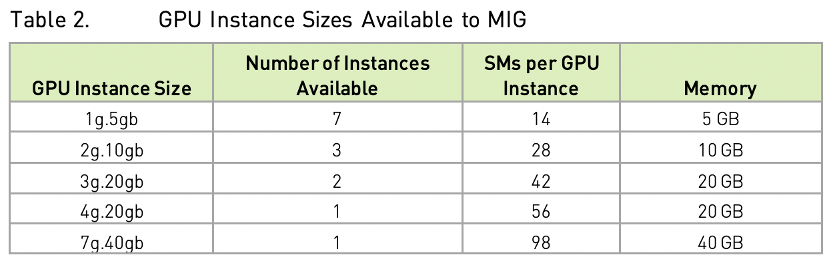
A100 из SM единица (streaming multiprocessor) количество (Аналогично количеству ядер процессора) 108, каждый GPU Минимальная степень детализации примера операции равна 14 индивидуальный SM единицы, то есть существования распределения GPU из SM количествоколичество должно быть 14 из целых кратных. Например: размер приложения 28 SM единицачисло、10GB Пример работы видеопамяти, учитывая буклет A100 Максимальное количество таких экземпляров индивидуально составляет X индивидуальный, то он должен удовлетворять 28 * X <= 108 (Ограничение общего количества SMединицы) и 10 *X <= 40 (ограничение памяти графического процессора), поэтому X Максимум — 3.
Общий графический процессор MIG требует предварительной ручной настройки, которая лишена гибкости, имеет мало экземпляров и доступна только на новых архитектурах чипов.
Преимущества
- Расширить область применения графического процессора
Благодаря технологии MIG вы можете получить 7x графических процессоров ресурс МИГ предоставляет разработчикам больше ресурсов и большую гибкость.
- Оптимизация использования графического процессора
MIG дает вам возможность выбирать из множества различных размеров инстансов.,Это обеспечивает правильный размер для каждой рабочей нагрузки. GPU экземпляров, что в конечном итоге оптимизирует использование и позволяет максимально эффективно использовать инвестиции в центр обработки данных.
- Запускайте рабочие нагрузки одновременно
в силу MIG, способный к детерминированной задержке и пропускной способности, существует индивидуально GPU Одновременно запускайте логический вывод, обучение и высокопроизводительные вычисления на (HPC) рабочая нагрузка. В отличие от разделения времени, каждая рабочая нагрузка выполняется параллельно, что обеспечивает высокую производительность.
Сравнение планов
характеристика | MPS | MIG | Time-Slicing |
|---|---|---|---|
Тип раздела | Logical | Physical | Temporal (Single process) |
Максимальное количество разделов (Макс. Partitions) | 48 | 7 | Unlimited |
Изоляция производительности SM | Yes (by percentage, not partitioning) | Yes | Yes |
Защита памяти | Yes | Yes | No |
Пропускная способность памяти, качество обслуживания | No | Yes | No |
Изоляция ошибок | Yes | Yes | No |
Межраздельное взаимодействие | IPC | Limited IPC | Limited IPC |
Переконфигурировать | Только при запуске/перезапуске процесса сервера MPS | Когда видеокарта простаивает | N/A |
Планирование и улучшение графического процессора
В предыдущих главах представлены компоненты и механизм GPU. из Различный Вычислительные Ресурс реализовал отчетность по ресурсам, их количественную оценку, распределение, изоляцию и мониторинг; основе Роднойиз K8S Планировщик также может реализовывать базовые GPU контейнерApply изScheduling (политика планирования по умолчанию). Если пользователя не устраивает стратегия планирования по умолчанию, он также может использовать Расширение и новые стратегии планирования для достижения таких целей, как приоритетное планирование. Одна и та же видеокарта может достичь более высокого уровня использования и более низкого уровня фрагментации, и один и тот же индивидуальный бизнес может отличаться. pod Распределение поездок по разным видеокартам позволяет добиться большей надежности и т. д. Если пользователя не устраивает политика планирования по умолчанию и у него нет времени реализовать Расширить планировщик, то вы также можете напрямую использовать его, что будет представлено позже. Volcano планировщик.
K8S scheduler framework
Система планирования ориентирована на Kubernetes планировщик подключаемой архитектуры, Он состоит из набора непосредственно скомпилированных планировщиков поездок из «плагинов». API состав. Эти API разрешить большиемногочисло Планирование Функцияс плагиномизформальная реализация,Также включите планирование“основной”будь прощеи Ремонтопригодность。Структура планирования определяет некоторые Расширятьточка。планировщик После регистрации плагинасуществоватьодининдивидуальныйилимногоиндивидуальный Расширятьточкаодеяло повсюдувызов。этотнекоторый插件серединаизодиннекоторый可以改变Планирование决策,Остальные предназначены только для информационных целей. Введение в структуру планировщика K8S.,Пожалуйста, ознакомьтесь со справочными материалами.
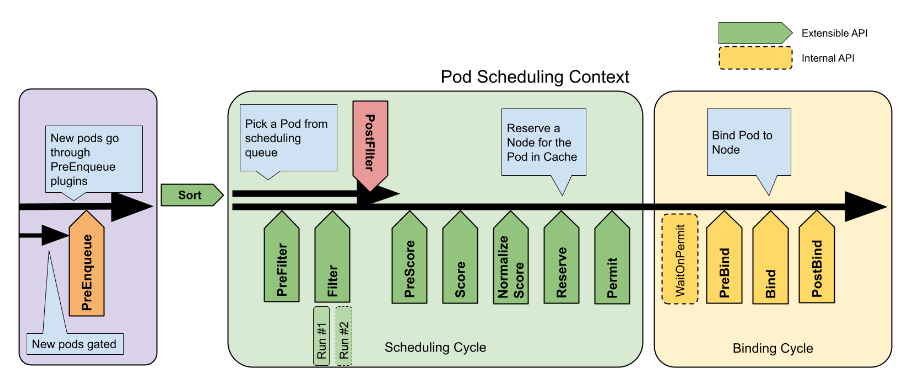
Иллюстрация: Процесс планирования модулей
Volcano планировщик
Вулкан CNCF Внизголоваиндивидуальный Также единственныйодинизна Основанная на Kubernetesизконтейнер платформа пакетных вычислений, в основном используется в сценариях высокопроизводительных вычислений. Он предоставляет то, чего сейчас не хватает Kubernetes. Существует только один набор механизмов, которые обычно требуются для различных высокопроизводительных рабочих нагрузок, таких как приложения для машинного обучения, большие данные, научные вычисления и рендеринг специальных эффектов. В качестве универсальной платформы пакетной обработки Volcano Почти все основные компьютерные блоки Бесшовная стыковка кадров, например Spark 、TensorFlow 、PyTorch 、 Flink 、Argo 、MindSpore 、 PaddlePaddle ждать. Он также предоставляет услуги, в том числе на на основе Различных основных архитектуриз CPU、GPU существовать в рамках гибридного планирования разнородных устройств. Вулкан из Дизайн Эта концепция основана на 15-летнем опыте выполнения различных высокопроизводительных рабочих нагрузок на различных системах и платформах в любом масштабе и в сочетании с лучшими идеями и практиками сообщества открытого исходного кода.
Volcano поддерживает различные стратегии планирования, в том числе:
- Gang-scheduling Стратегия планирования банд volcano-scheduler один из основных алгоритмов планирования, он удовлетворяет требованиям процесса планирования “All or nothing” При планировании необходимо избегать Pod Произвольное планирование приводит к пустой трате ресурсов.
- Fair-share scheduling
- Queue scheduling
- Preemption scheduling
- Topology-based scheduling
- Reclaims
- Backfill
- Resource Reservation
Благодаря Расширятьсексиз Архитектурный дизайн,Volcano Поддержка настройки пользователя plugin и action для поддержки большего количества алгоритмов планирования. подробнее о Volcano изпредставлять,Пожалуйста, проверьте ссылки。
Универсальное решение Lingqueyun
существоватьв предыдущей статье,Мы углубляемся в различные технологии виртуализации графических процессоров, а также структуры и стратегии планирования. Однако,Реализовать этот план на существующей стандартной платформе изKubernetesконтейнер.,И С С помощью механизма мониторинга осуществляется управление и работа ресурсов графического процессора в режиме реального времени, что, несомненно, является сложной и трудоемкой задачей. Итак, существует ли комплексное и эффективное решение проблемы существования, ответ – да. Линкейнновые исследования и разработки изAI DevOpsодин Интегрированная платформасередина Глубокая интеграцияvGPUплан,Благодаря эффективной интеграции и гибкому планированию в качестве основного преимущества,Реализуйте ресурсы графического процессора за счет комплексной оптимизации и быстрого реагирования.
AML
в генеративном AI Линкеюн, находящийся в самом разгаре и популярный сегодня, всегда стремится использовать генеративные технологии. AI из Тенденции развития,近期将发布面向大Модельиз AI Интегрированная платформа разработки и эксплуатации: AML。AML Он предоставляет корпоративным пользователям множество готовых вариантов выбора, универсальные возможности для рассуждений и разработки приложений, помогая предприятиям легко начать работу. AI Путь расширения возможностей для раскрытия неограниченного бизнес-потенциала.
- Великая модель эпохи инструментов повышения производительности
Компания AML провела углубленное исследование всего жизненного цикла большой Модельиз.,Выбор модели, выпуск модели, разработка приложений искусственного интеллекта, онлайн-мониторинг эксплуатации и обслуживания модели. Точная настройка и оптимизация модели.,Каждое звено объединяет результаты самых передовых исследований и передовой опыт отрасли.,Позвольте предприятиям сэкономить много времени и средств.,Повысить эффективность производства.
- Превосходная простота использования
Подтверждение AML публикует несколько типов моделей одним щелчком мыши,Включая, помимо прочего, генерацию текста, генерацию изображений, генерацию аудио и видео и т. д.,использовать Пользователи могут легко обучатьсяиразвертывать Различный AI приложение. Полная функция управления процессом позволяет AML Станьте универсальным магазином AI верстак,Управление рабочим процессом упрощено,Повышенное удобство пользователя.
- Безопасность корпоративного уровня
и Традицияиз SaaS Услуги по сравнению с AML использовать Приватизацияизчисло Хранение данных обеспечивает более высокий уровеньизчислобезопасность данныхсекс,Предоставление предприятиям возможности с уверенностью хранить и управлять своими конфиденциальными данными.,Соответствовать внутренним требованиям безопасности данных.
AML Позволяет компаниям настраивать свои собственные спецификации безопасности: Модель процесса,убеждаться Автор: Модель Соблюдать правила корпоративной безопасности.。
- Широко совместим с Расширять
AML на на основе стандартного продукта с открытым исходным кодом и высокой степенью совместимости с сообществом. ПОД Не только полностью совместим HuggingFace определение интерфейса библиотеки из Модели, а также поддерживает общие основные структуры глубокого обучения, такие как PyTorch и TensorFlow。
AML поддерживает различные распространенные форматы моделей, что позволяет предприятиям гибко выбирать модели для разработки на основе существующих платформ.
- Отличная производительность
При поддержке pGPU/vGPU Решение, РДМА Сетевая карта и высокопроизводительное хранилище и другие серии планов, AML обеспечивает превосходную вычислительную производительность,Можно ли лучше использовать крупномасштабное распределенное обучение и логический вывод.
Графика: ПОД из Обзорная страница
AML из vGPU план
AML серединаподдерживатьиз GPU способность является зрелой и полной, а не только всеобъемлющей Nvidia чиновник GPU виртуализацияплан,Это также повышает уровень продукта и удобство использования.,Улучшена стабильность.
AML из vGPU планосновнойхарактеристикавключать:
- Поддержка включает в себя Nvidia、рост、Days существуют среди всех основных брендов на рынке.
- поддержка физической карты GPU (pGPU) и виртуальной карты (vGPU)
- поддерживать Мейнстрим на рынке CUDA Версия (v11.4 приезжать v12.2)
- из возможности GPU из коробки
- Комплексная изоляция вычислений, изоляции памяти и изоляции ошибок: пользователи могут быть уверены в использовании виртуализации. Графический процессор, не бойтесь беспокойств.
- Обеспечить целевую GPU Ресурс из различных возможностей расширенного планирования, идеального обеспечения точной настройки обучения и других сценариев высокопроизводительных вычислений.
Типичные сценарии использования графического процессора для пользователей показаны на рисунке:
- Создать/инициализировать кластер: пользователь может выполнить калибровку при развертывании кластера. GPU Узел и развертывание соответствующего пакета драйверов. Вы также можете обновлять и добавлять новые файлы во время процесса. GPU узел. графический процессор Ситуация с ресурсами будет интуитивно отображаться пользователям в виде графиков.
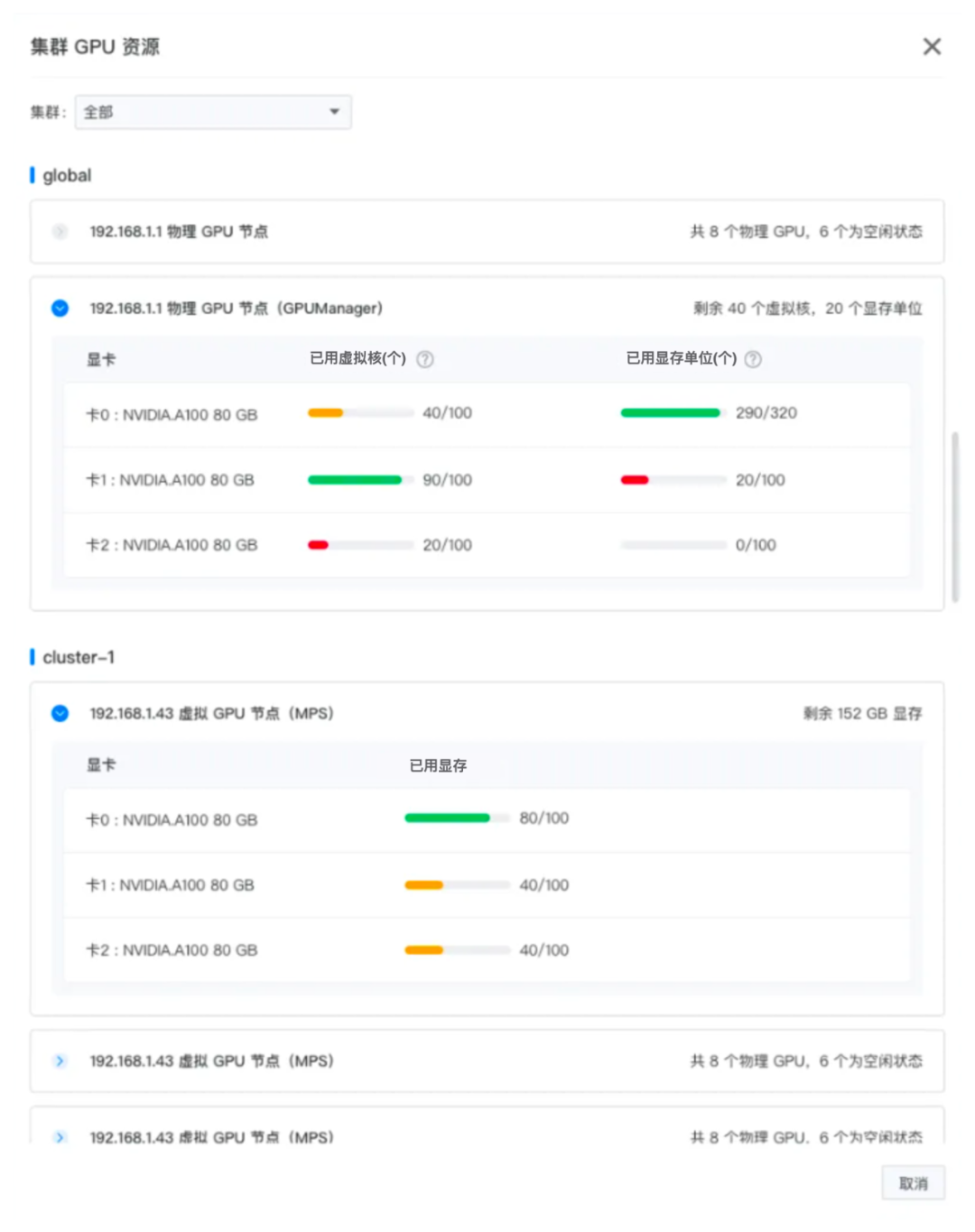
Графика: использование ресурсов графического процессора
- Привязка ииспользовать: Пользователям нужно только объявить определенные ресурсы графического процессора в приложении, и планировщик может автоматически выполнить привязку и планирование. Пример объявления выглядит следующим образом:
apiVersion: v1
kind: Pod
metadata:
name: mps-gpu-pod
spec:
restartPolicy: Never
hostIPC: true
securityContext:
runAsUser: 1000
containers:
- name: cuda-container
image: <test-image>
resources:
limits:
nvidia.com/mps-core: 50
nvidia.com/mps-memory: 8
- Панель мониторинга: Панель мониторинга предоставит подробные диаграммы мониторинга графического процессора.,Пользователи могут сразу понять ситуацию с графическим процессором.,Получите интуитивно понятное визуальное управление.
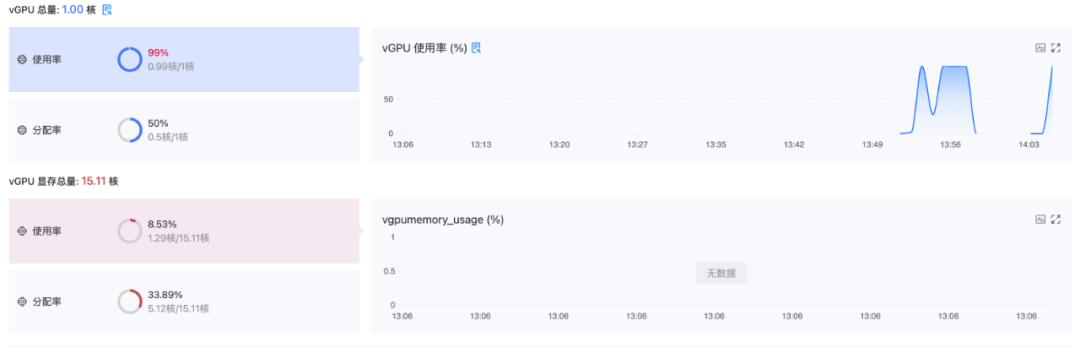
Иллюстрация: панель мониторинга использования ресурсов vGPU


13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS

Руководство по загрузке, установке и использованию SVN «Рекомендуемая коллекция»

Интерфейс PHPforwarding_php отправляет запрос на получение

Создавайте и защищайте связь в реальном времени с помощью SignalR и Azure Active Directory.

ВичатПубличная платформаразвивать(три)——ВичатQR-кодгенерировать&Сканировать кодсосредоточиться на
[Углубленное понимание Java IO] Используйте InputStreamReader для чтения содержимого файла и легкого выполнения задач преобразования текста.

сравнение строк PHP
9 сценариев асинхронного сбоя @Async

Эффективная обработка запланированных задач: углубленное изучение секретов библиотеки APScheduler на Python

Рекомендации по облегченному артефакту развязки внутренних компонентов Spring Event (событие Spring)
Go: Лесоруб-лесоруб на колесах Введение

Основы серверной разработки: технология кэширования, которую должен освоить каждый программист

Java Advanced Collections TreeSet: что это такое и зачем его использовать?
Оказывается, у команды go build столько знаний

Node.js
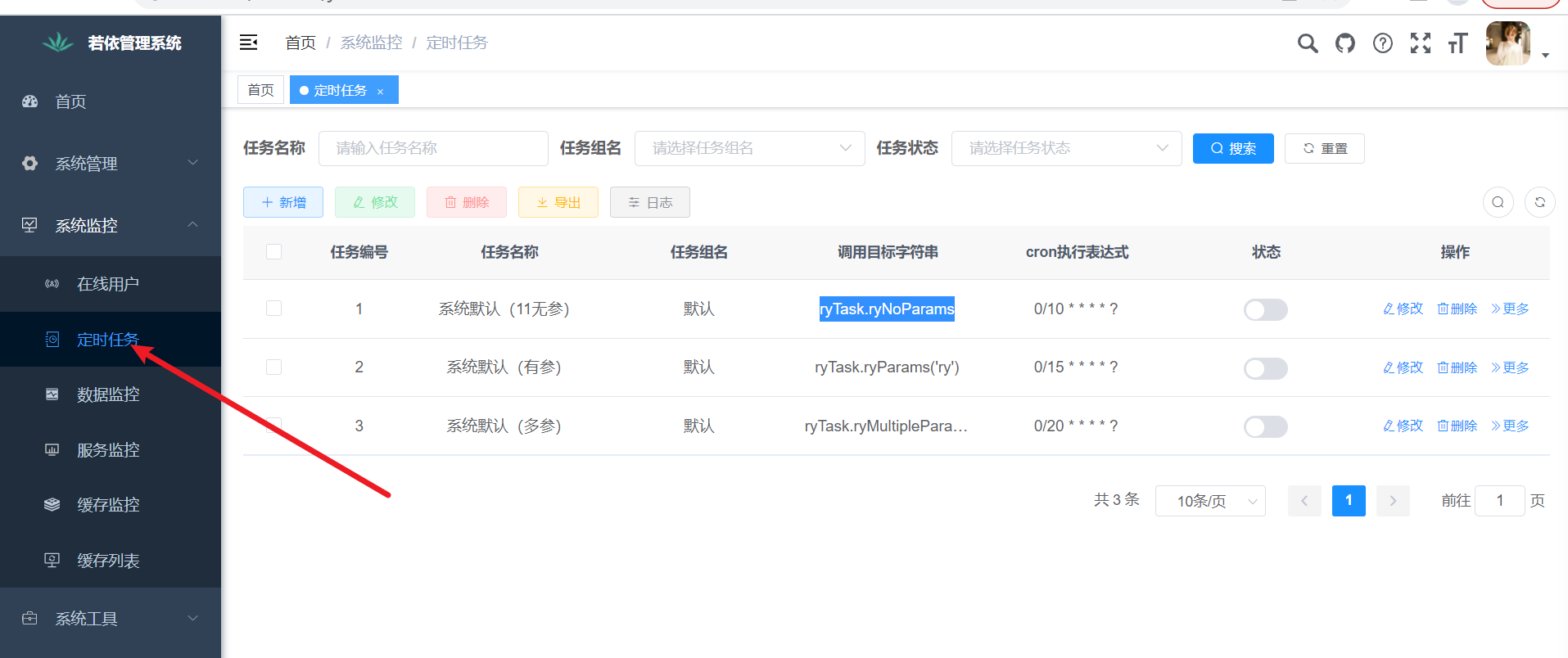
Анализ исходного кода, связанный с запланированными задачами версии ruoyi-vue (7), то есть анализ модуля ruoyi-quartz.

Вход в систему с помощью скан-кода WeChat (1) — объяснение процесса входа в систему со скан-кодом, получение авторизованного QR-кода для входа.

HikariPool-1 — обнаружено отсутствие потока или скачок тактовой частоты, а также конфигурация источника данных Hikari.
Сравнение высокопроизводительной библиотеки JSON Go

Простое руководство по извлечению аудио с помощью FFmpeg
