Улучшения YOLOv8: операция свертки внимания восприимчивого поля (RFAConv), эффект мгновенный, уничтожает CBAM, CA и т. д. Серия Plug and Play |
Улучшения в этой статье:Операция свертки рецептивного поля внимания(RFAConv),Решение модуля сверточного блока внимания (CBAM) и модуля координированного внимания (CA) фокусируется только на пространственных объектах.,Проблема совместного использования параметров ядра свертки не может быть полностью решена.
RFAConv | Персональный тест может обеспечить существенное увеличение количества баллов в нескольких наборах данных, а некоторые наборы данных достигают более 3 баллов.
1. Введение в RFAConv

бумага:https://arxiv.org/pdf/2304.03198.pdf
Аннотация: Пространственное внимание широко используется для повышения производительности сверточных нейронных сетей. Однако он имеет определенные ограничения. В этой статье мы предлагаем новый взгляд на эффективность пространственного внимания, то есть механизм пространственного внимания по существу решает проблему совместного использования параметров ядра свертки. Однако информации, содержащейся в карте внимания, сгенерированной пространственным вниманием, недостаточно для ядер свертки большого размера. Поэтому мы предлагаем новый механизм внимания, называемый вниманием рецептивного поля (RFA). Существующие методы пространственного внимания, такие как модуль внимания сверточных блоков (CBAM) и скоординированное внимание (CA), фокусируются только на пространственных объектах и не решают полностью проблему совместного использования параметров ядра свертки. Напротив, RFA не только фокусируется на пространственных характеристиках рецептивного поля, но также обеспечивает эффективные веса внимания для ядер свертки большого размера. Операция свертки восприимчивого поля внимания (RFAConv), разработанная RFA, представляет собой новую альтернативу стандартным операциям свертки. Это обеспечивает практически незначительные вычислительные затраты и приращение параметров, одновременно значительно улучшая производительность сети. Мы проводим серию экспериментов с наборами данных ImageNet-1k, COCO и VOC, чтобы продемонстрировать превосходство нашего метода. Что особенно важно, мы считаем, что пришло время сместить фокус нынешних механизмов пространственного внимания с пространственных особенностей на пространственные особенности рецептивного поля. Таким образом, мы можем еще больше улучшить производительность сети и добиться лучших результатов.
О пространственных характеристиках рецептивных полей,мы предлагаемРецептивное поле внимания (RFA)。 Этот подход не только подчеркивает важность различных особенностей в ползунке рецептивного поля, но также отдает приоритет пространственным особенностям рецептивного поля. Благодаря этому методу полностью решается проблема совместного использования параметров ядра свертки. Характеристики пространства восприимчивых полей генерируются динамически в зависимости от размера ядра свертки. Таким образом, RFA представляет собой фиксированную комбинацию сверток и не может быть отделена от операций свертки. В то же время мы полагаемся на RFA для повышения производительности. так что мы Предложена свертка внимания рецептивного поля (RFAConv). Общая структура RFAConv с ядром свертки размером 3×3 показана на рисунке 2.
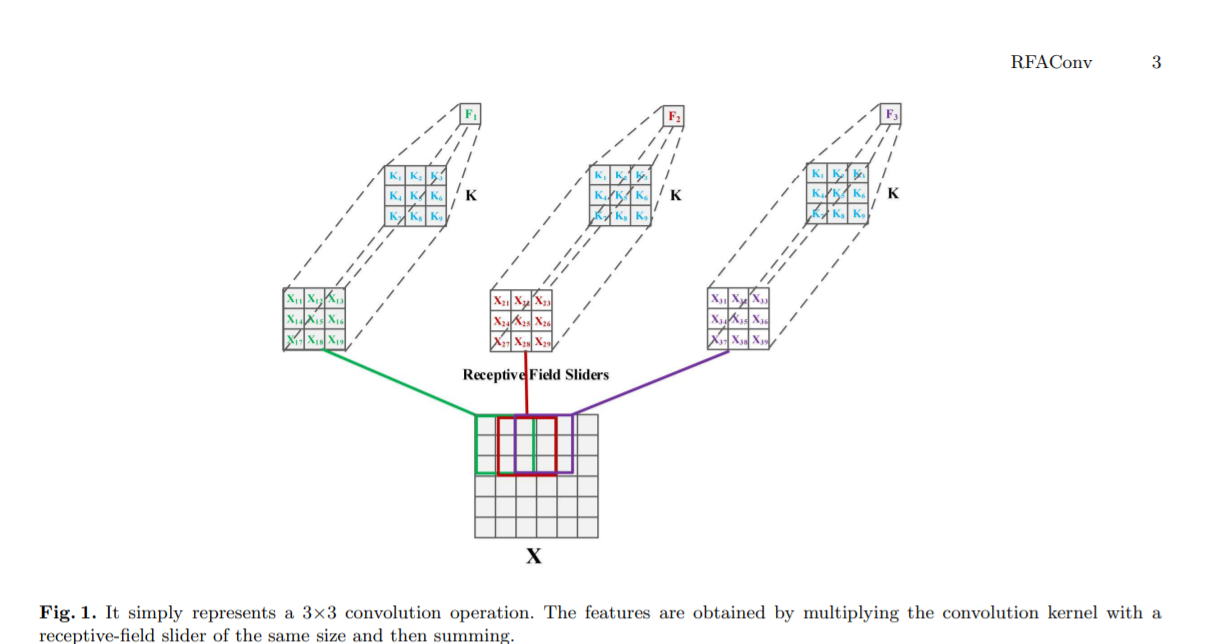
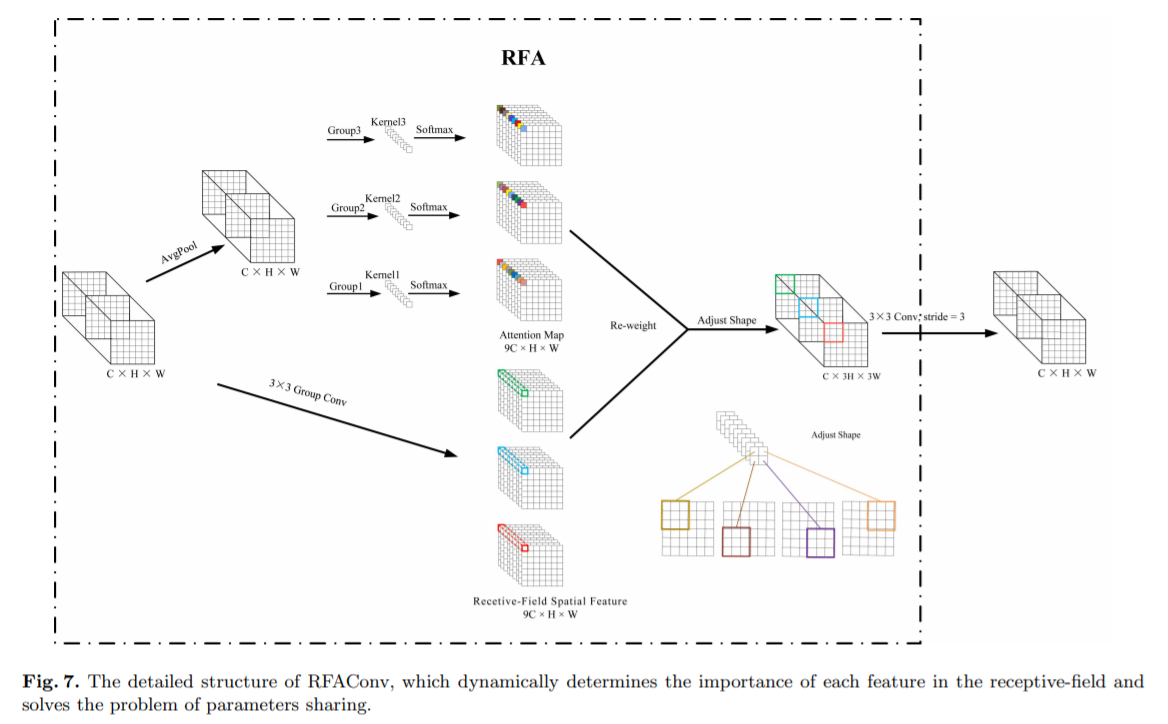
Авторы разработали новые CBAM и CA, названные RFACBAM и RFACA, которые фокусируются на пространственных характеристиках рецептивного поля. Подобно RFA, последняя операция свертки k×k с шагом k используется для извлечения информации о признаках. Конкретная структура показана на рисунках 4 и 5. Эти два новых метода свертки называются RFCBAMConv и RFCAConv. По сравнению с исходным CBAM, внимание SE используется для замены CAM в RFCBAM. Потому что это может уменьшить вычислительные затраты.
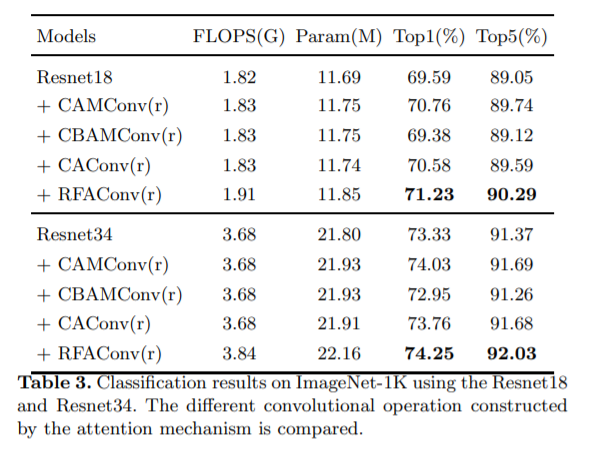
Результаты эксперимента
Классификация
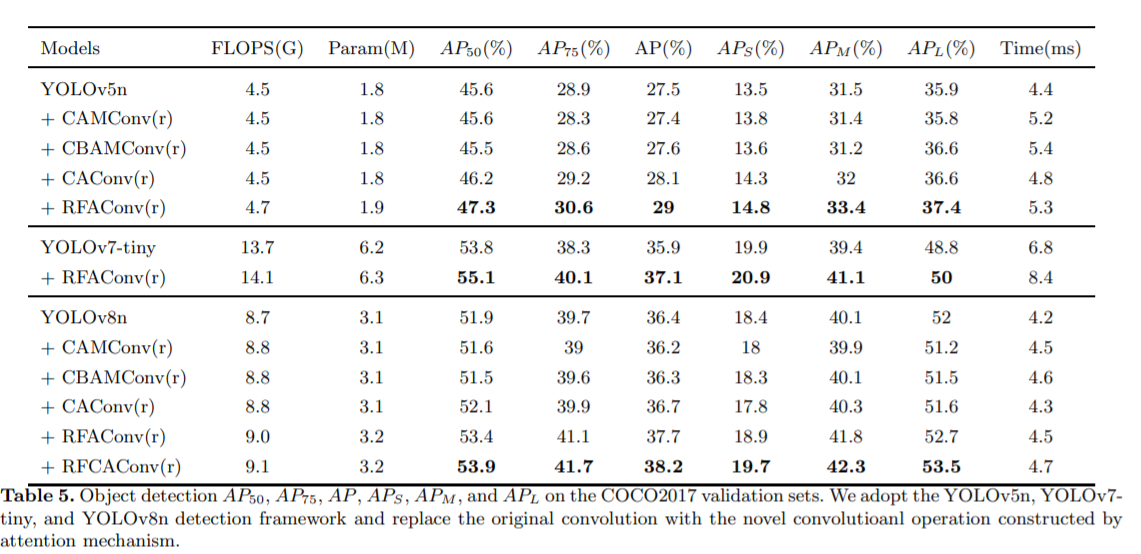
Обнаружение цели
2.RFA добавлен в yolov8
2.1 Создайте новый ultralytics/nn/Conv/RFA.py
Основной код:
class DyCAConv(nn.Module):
def __init__(self, inp, oup, kernel_size, stride, reduction=32):
super(DyCAConv, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv = nn.Sequential(nn.Conv2d(inp, oup, kernel_size, padding=kernel_size // 2, stride=stride),
nn.BatchNorm2d(oup),
nn.SiLU())
self.dynamic_weight_fc = nn.Sequential(
nn.Linear(inp, 2),
nn.Softmax(dim=1)
)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
# Compute dynamic weights
x_avg_pool = nn.AdaptiveAvgPool2d(1)(x)
x_avg_pool = x_avg_pool.view(x.size(0), -1)
dynamic_weights = self.dynamic_weight_fc(x_avg_pool)
out = identity * (dynamic_weights[:, 0].view(-1, 1, 1, 1) * a_w +
dynamic_weights[:, 1].view(-1, 1, 1, 1) * a_h)
return self.conv(out)Подробности см.:



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
