Улучшения YOLOv8: Gold-YOLO далеко впереди, превосходя всех YOLO | Huawei Noah NeurIPS23
💡💡💡Эксклюзивные улучшения этой статьи:предложил новыйАгрегация и распространение информации (Механизм сбора и распределения) Механизм GD, Gold-YOLO,заменятьyolov8 головная часть Достичь резкого подъема
Gold-YOLO | Персональный тест может добиться существенной выгоды в нескольких наборах данных
💡💡💡Yolov8 Magician, эксклюзивное первое нововведение (оригинальное), подходящее для различных серий Yolo, таких как Yolov5, Yolov7, Yolov8 и т. д. В статье в рубрике представлены все этапы и исходный код, которые помогут вам легко приступить к преобразованию волшебной сети.
💡💡💡Ключевой момент: прочитав эту колонку, вы также сможете самостоятельно модифицировать сеть в будущем и выполнять волшебные модификации в разных местах сети (магистраль, голова, обнаружение, потеря и т. д.) для достижения инноваций! ! !
Введение в столбец:
https://blog.csdn.net/m0_63774211/category_12289773.html
✨✨✨Оригинальная волшебная сеть, воспроизведение новейших документов, оптимизация сочетания и инновации.
🚀🚀🚀Улучшение работы с небольшими целями, препятствиями и сложными образцами.
🍉🍉🍉Постоянное обновление, регулярное обновление точек увеличения различных наборов данных.
1.Gold-YOLO

Связь:https://arxiv.org/pdf/2309.11331.pdf
код:https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO
Часть: Лаборатория Ноева ковчега Huawei
Теоретическая часть может быть отнесена к:За пределами серии YOLO! Huawei предлагает Gold-YOLO: эффективный детектор целей в реальном времени - Чжиху
Проблемы с традиционным YOLO
В модели обнаружения ряд функций на разных уровнях обычно сначала извлекается через магистраль. FPN использует эту особенность магистрали для построения соответствующей объединенной структуры: неуровневые функции содержат информацию о местоположении объектов разных размеров. Содержащаяся информация различна, но после интеграции друг с другом эти функции могут восполнить недостающую информацию друг друга, повысить насыщенность информации на каждом уровне и улучшить производительность сети.
Исходная структура FPN позволяет полностью объединять информацию соседних слоев благодаря режиму послойного прогрессивного объединения информации, но это также приводит к проблемам при межуровневом объединении информации: когда межуровневая информация объединяется в интерактивном режиме, из-за из-за отсутствия прямого соединения. Интерактивные каналы могут полагаться только на средний уровень, который будет выступать в качестве «посредника» для интеграции, что приводит к определенному количеству потерь информации. Во многих предыдущих работах этой проблеме уделялось внимание, и решение обычно состоит в добавлении большего количества путей путем добавления ярлыков для улучшения потока информации.
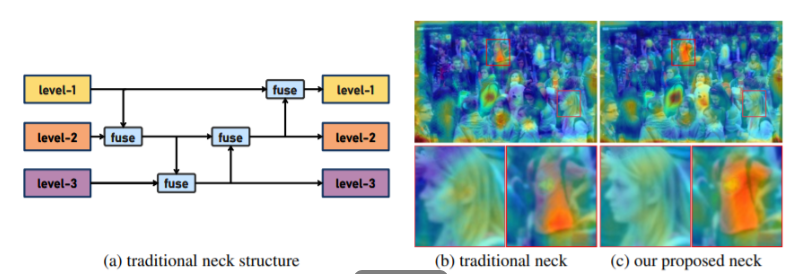
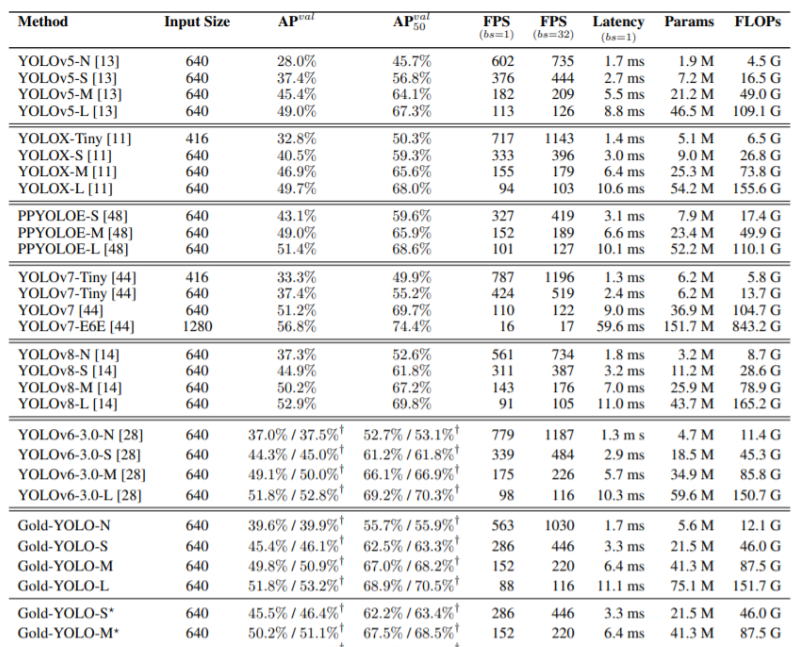
Аннотация: Текущие модели серии YOLO обычно используют FPN-подобные методы для объединения информации, но эта структура имеет проблему потери информации при объединении межуровневой информации.В ответ на эту проблему,我们предложил новый Агрегация и распространение информации (Gather-and-Distribute Механизм) Механизм GD, посредством унифицированной агрегации и объединения функций на разных уровнях с глобальной точки зрения, а также распределения и внедрения на разные уровни, создается более достаточный и эффективный механизм информационного взаимодействия и объединения, а Gold-YOLO построен на основе Механизм ГД. В наборе данных COCO наш Gold-YOLO превосходит существующую серию YOLO и достигает SOTA по кривой точности-скорости.
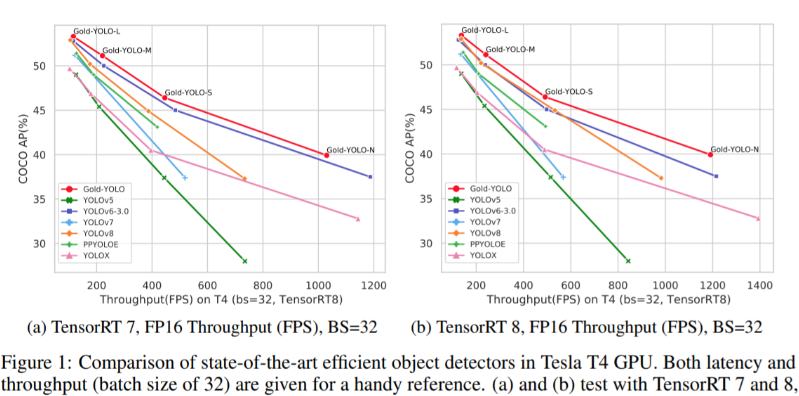
Предложен новый механизм информационного взаимодействия и слияния.:Механизм агрегирования и распределения информации (Gather-and-Distribute Mechanism)。Этот механизм получает глобальную информацию путем глобального объединения функций на разных уровнях.,и вводить глобальную информацию в функции на разных уровнях,Достигается эффективное информационное взаимодействие и интеграция. Механизм GD значительно расширяет возможности объединения информации в шейной части без значительного увеличения задержки.,Улучшена способность модели обнаруживать объекты разных размеров.
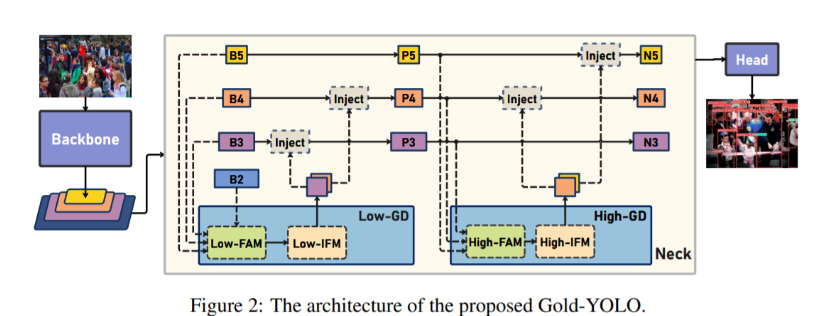
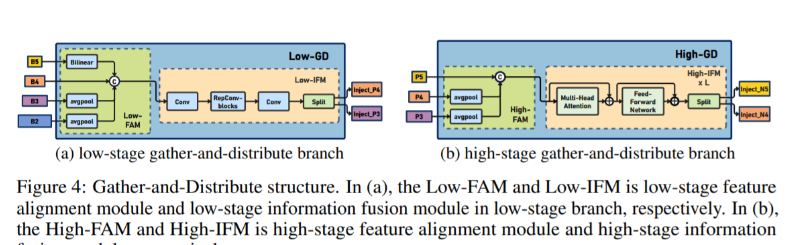
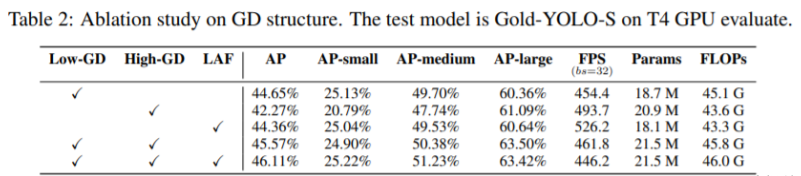
В Gold-YOLO, в ответ на необходимость того, чтобы модель обнаруживала объекты разных размеров, а также взвешивала точность и скорость, мы построили две ветви GD для объединения информации: ветвь агрегирования-распределения информации низкого уровня (Low-GD) и высокий уровень. Ветвь сбора-распределения информации (High-GD) извлекает и объединяет информацию о характеристиках на основе свертки и преобразования соответственно.
Результаты эксперимента:
2.золото-йоло представлено в yolov8
2.1 Создайте новый gold-yolo и добавьте ultralytics/nn/head/goldyolo.py
Основной код:
###################### gold-yolo #### STRAT by AI&CV ###############################
#gold-yolo Gather-and-Distribute Mechanism
class top_Block(nn.Module):
def __init__(self, dim, key_dim, num_heads, mlp_ratio=4., attn_ratio=2., drop=0.,
drop_path=0.):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
self.attn = Attention(dim, key_dim=key_dim, num_heads=num_heads, attn_ratio=attn_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x1):
x1 = x1 + self.drop_path(self.attn(x1))
x1 = x1 + self.drop_path(self.mlp(x1))
return x1
class TopBasicLayer(nn.Module):
def __init__(self, embedding_dim, ouc_list, block_num=2, key_dim=8, num_heads=4,
mlp_ratio=4., attn_ratio=2., drop=0., attn_drop=0., drop_path=0.):
super().__init__()
self.block_num = block_num
self.transformer_blocks = nn.ModuleList()
for i in range(self.block_num):
self.transformer_blocks.append(top_Block(
embedding_dim, key_dim=key_dim, num_heads=num_heads,
mlp_ratio=mlp_ratio, attn_ratio=attn_ratio,
drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path))
self.conv = nn.Conv2d(embedding_dim, sum(ouc_list), 1)
def forward(self, x):
# token * N
for i in range(self.block_num):
x = self.transformer_blocks[i](x)
return self.conv(x)
class AdvPoolFusion(nn.Module):
def forward(self, x):
x1, x2 = x
if torch.onnx.is_in_onnx_export():
self.pool = onnx_AdaptiveAvgPool2d
else:
self.pool = nn.functional.adaptive_avg_pool2d
N, C, H, W = x2.shape
output_size = np.array([H, W])
x1 = self.pool(x1, output_size)
return torch.cat([x1, x2], 1)
###################### gold-yolo #### END by AI&CV ###############################Подробности смотрите в исходном коде:https://cv2023.blog.csdn.net/article/details/133271100



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
