Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Маленькие цели имеют очевидные преимущества | ICASSP2023
1.EMA

бумага:https://arxiv.org/abs/2305.13563v1
Приемка: ICASSP2023
Моделирование межканальных отношений посредством уменьшения размерности канала может иметь побочные эффекты при извлечении глубоких визуальных представлений. В этой статье предлагается новый эффективный модуль многомасштабного внимания (EMA). С целью сохранения информации о каждом канале и снижения вычислительных затрат некоторые каналы преобразуются в пакетные измерения, а измерения канала группируются в несколько подфункций, чтобы пространственные семантические признаки были равномерно распределены в каждой группе признаков.
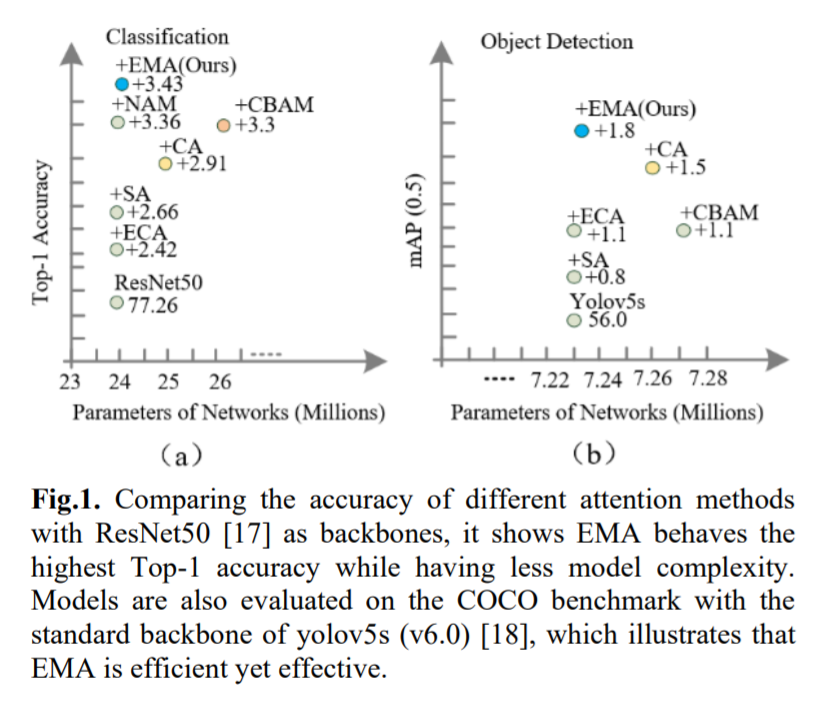
Предлагается новое эффективное многомасштабное внимание (EMA) без снижения размерности. Обратите внимание, что здесь только два ядра свертки будут размещены в параллельных подсетях соответственно. Одна из параллельных подсетей представляет собой ядро свертки 1x1, обрабатываемое так же, как CA, а другая — ядро свертки 3x3. Чтобы продемонстрировать общность предлагаемой EMA, в разделе 4 приведены подробные эксперименты, включая результаты тестов CIFAR-100, ImageNet-1k, COCO и VisDrone2019. На рисунке 1 показаны экспериментальные результаты задач классификации изображений и обнаружения целей. Наш основной вклад заключается в следующем:
В этой статье предлагается новый метод межпространственного обучения и разрабатывается многомасштабная параллельная подсеть для установления коротких и длинных зависимостей. 1) Мы рассматриваем общий подход к преобразованию части размеров канала в размеры партии, чтобы избежать некоторой формы уменьшения размерности посредством общей свертки. 2) Помимо построения локальных межканальных взаимодействий в каждой параллельной подсети без уменьшения размерности канала, мы также объединяем выходные карты признаков двух параллельных подсетей с помощью метода межпространственного обучения. 3) По сравнению с CBAM, NAM [16], SA, ECA и CA, EMA не только дает лучшие результаты, но и более эффективен по требуемым параметрам.
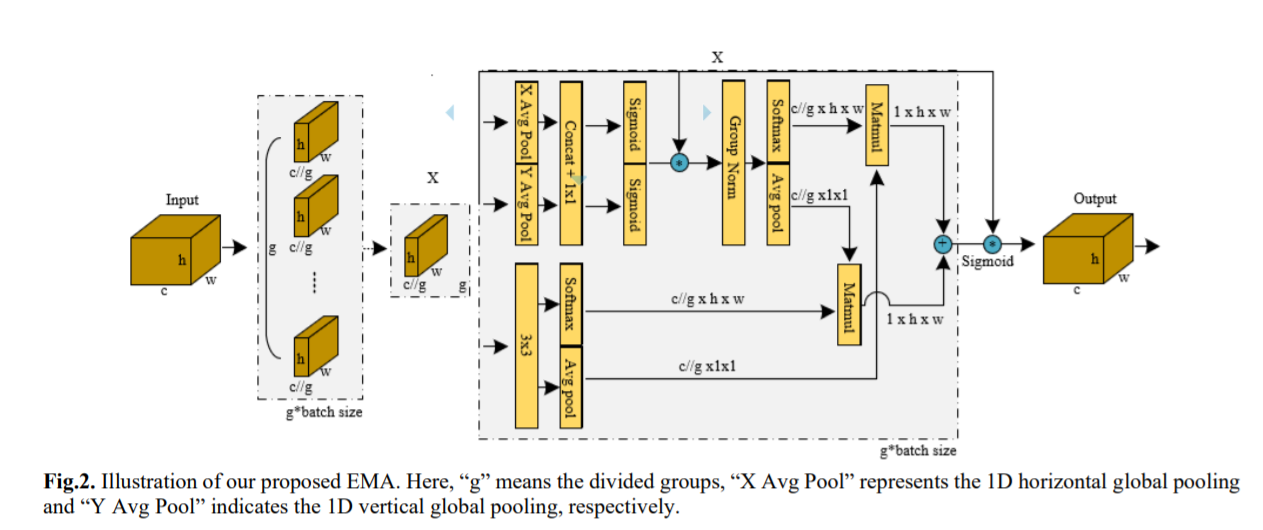
Блок CA можно сначала рассматривать как подход, аналогичный модулю внимания SE, где операция глобального среднего пула используется для моделирования межканальной информации. Как правило, статистика канала может быть сгенерирована с использованием глобального среднего пула, при котором глобальная информация о пространственном местоположении сжимается в дескриптор канала. Немного отличаясь от SE, CA встраивает информацию о пространственном местоположении в карты внимания каналов для улучшения агрегирования функций.
Параллельная подструктура помогает сети избежать более последовательной обработки и большой глубины. Учитывая описанную выше стратегию параллельной обработки, мы применяем ее в модуле EMA. Общая структура EMA показана на рисунке 3(b). В этом разделе мы обсудим, как EMA изучает эффективные описания каналов без уменьшения размерности канала в операциях свертки и обеспечивает лучшее внимание на уровне пикселей для карт объектов высокого уровня. В частности, мы выбираем только общие компоненты свертки 1x1 из модуля CA и называем их ветвью 1x1 в нашей EMA. Чтобы агрегировать информацию о многомасштабной пространственной структуре, ядро 3x3 размещается параллельно с ветвью 1x1 для достижения быстрого ответа, которую мы называем ветвью 3x3. Учитывая группировку функций и многомасштабную структуру, эффективное установление краткосрочных и долгосрочных зависимостей полезно для повышения производительности.

Предлагаемая EMA изучается на наборе данных CIFAR-100 с использованием стандартных показателей точности CIFAR Top-1 и Top-5 для оценки производительности сети.

Используйте YOLOv5x в качестве базовой CNN для обнаружения целей в наборе данных VisDrone, в котором внимание CA, CBAM и EMA интегрировано в детектор соответственно. Из результатов в Таблице 2 видно, что CA, CBAM и EMA могут улучшить базовые характеристики обнаружения целей. Видно, что предлагаемый модуль EMA всегда превосходит базовые сети CA и CBAM по показателям mAP(0,5) и mAP(0,5:0,95). Стоит отметить, что CBAM повышает производительность YOLOv5x на 0,11%, что выше, чем у CA, но ценой большего количества параметров и вычислений. Для CA он получает почти ту же производительность, что и базовый уровень, и превосходит YOLOv5x на 0,01% по mAP (0,5), в то время как CA получает более высокие параметры и вычислительные затраты, чем EMA (91,28M против 91,18M и 315,2M против 0,315,0). М). В частности, EMA добавляет 0,22 млн параметров по сравнению с базовым методом. Когда параметры немного выше, он улучшает mAP (0,5) на 0,31% и mAP (0,5:0,95) на 0,4% по сравнению с YOLOv5x. Эти результаты показывают, что EMA является эффективным модулем обнаружения объектов, что еще раз доказывает эффективность метода EMA.
2.EMA присоединяется к yolov8
2.1 Присоединяйтесь modules.pyсередина
основной код
class EMA_attention(nn.Module):
def __init__(self, channels, c2=None, factor=32):
super(EMA_attention, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)Подробности см.: https://cv2023.blog.csdn.net/article/details/131370577.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
