Улучшение точки подъема YOLOv10: оператор повышения дискретизации | облегченный оператор повышения дискретизации CARAFE
💡💡💡Эксклюзивные улучшения этой статьи: Операция повышения дискретизации CARAFE обладает преимуществами большого воспринимающего поля, осведомленности о контенте, легкости, быстрой скорости вычислений и т. д. и представляет второе нововведение yolov10;
1) Используется вместо Upsample;
Усовершенствованная структурная схема выглядит следующим образом:
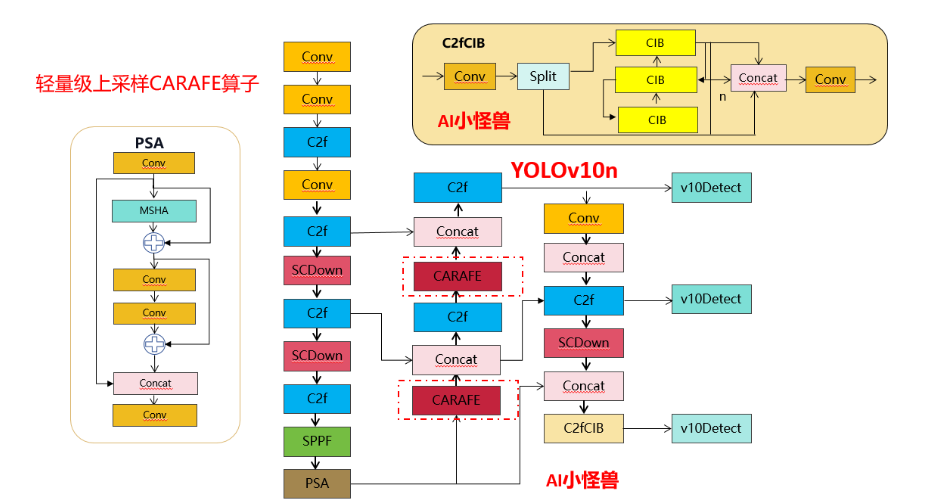
1.Введение YOLov10

Добавить описание
бумага: https://arxiv.org/pdf/2405.14458
Код: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
краткое содержание:в последние несколько лет,Благодаря эффективному балансу между вычислительными затратами и производительностью обнаружения.,YOLOS стал ведущей парадигмой в области обнаружения объектов в реальном времени. Исследователи изучили архитектурный дизайн YOLOS, цели оптимизации, стратегии увеличения данных и т. д.,и добились значительного прогресса. Однако,Использование немаксимального подавления (NMS) для постобработки препятствует сквозному развертыванию YOLOS и влияет на задержку вывода.также,В конструкции каждого компонента YOLOS отсутствует всесторонняя и тщательная проверка.,что приводит к значительной вычислительной избыточности,ограничивает производительность модели. Это приводит к неоптимальной эффективности.,и значительный потенциал для улучшения производительности. в этой работе,Наша цель — еще больше расширить границы производительности и эффективности YOLOS как с точки зрения постобработки, так и с точки зрения архитектуры модели. с этой целью,Мы впервые предложилиНепрерывное двойное назначение для обучения YOLO без NMS,Такой подход приводит к конкурентной производительности и низкой задержке вывода. также,Мы также представляем общую стратегию проектирования моделей YOLOS, ориентированную на эффективность и точность. Мы полностью оптимизировали каждый компонент YOLOS с точки зрения эффективности и точности.,Значительно снижает вычислительные затраты,Улучшения производительности. Результатом наших усилий стала серия YOLO следующего поколения для сквозного обнаружения объектов в режиме реального времени.,Позвонил YOLOV10. Обширные эксперименты показывают,YOLOV10 обеспечивает высочайшую производительность и эффективность в различных масштабах моделей. Например,Под аналогичным AP на COCO,Наш YOLOV10-S в 1,8 раза быстрее, чем RT-DETR-R18.,Также имеет в 2,8 раза меньше параметров и FLOPS. По сравнению с YOLOV9-C,YOLOV10-B имеет такую же производительность.,Задержка уменьшена на 46 %,Параметры были уменьшены на 25%.
1.1 Знакомство с C2fUIB
Чтобы решить эту проблему, мы предлагаем схему блочного проектирования на основе рангов, целью которой является снижение сложности этапов, которые оказываются избыточными за счет компактного архитектурного проектирования. Сначала мы предлагаем архитектуру компактного инвертированного блока (CIB), в которой используются дешевые отделимые по глубине свертки для пространственного микширования и экономичные двухточечные свертки для микширования каналов.
C2fUIB просто заменяет структуру «узкого места» C2f в YOLOv8 на структуру CIB.
Код реализации ultralytics/nn/modules/block.py
class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))1.2 Введение в PSA
В частности, мы делим объекты на две части равномерно после свертки 1×1. Мы только часть его передаем в блок NPSA, состоящий из многоголовочного модуля самообслуживания (MHSA) и сети прямой связи (FFN). Затем две части соединяются и сливаются с помощью свертки 1×1. Кроме того, следуйте инструкциям, чтобы назначить размеры запросов и ключей половине значений, и замените LayerNorm на BatchNorm для быстрого вывода.
Код реализации ultralytics/nn/modules/block.py
class Attention(nn.Module):
def __init__(self, dim, num_heads=8,
attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (
(q.transpose(-2, -1) @ k) * self.scale
)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W))
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))1.3 SCDown
OLO обычно используют обычные стандартные свертки 3×3 с шагом 2, реализуя при этом пространственную понижающую дискретизацию (от H×W до H/2×W/2) и преобразование каналов (от C до 2C). Это приводит к значительным вычислительным затратам O(9HWC^2) и количеству параметров O(18C^2). Вместо этого мы предлагаем разделить операции уменьшения пространства и увеличения каналов, чтобы добиться более эффективной понижающей дискретизации. В частности, мы сначала используем двухточечную свертку для настройки размеров канала, а затем используем отделимую по глубине свертку для пространственной понижающей дискретизации. Это снижает вычислительные затраты до O(2HWC^2 + 9HWC), а количество параметров — до O(2C^2 + 18C). В то же время это максимизирует сохранение информации во время субдискретизации, тем самым уменьшая задержку, сохраняя при этом конкурентоспособную производительность.
Код реализации ultralytics/nn/modules/block.py
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x):
return self.cv2(self.cv1(x))2. Знакомство с ГРАФИНОМ

бумага:https://arxiv.org/abs/1905.02188
Код:GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark
В этой статье делается попытка предложить новую операцию повышения дискретизации CARAFE, которая должна иметь следующие характеристики:
- Почувствуйте себя диким. В отличие от предыдущей работы, в которой используются только субпиксельные окрестности (например, билинейная интерполяция), CARAFE может агрегировать контекстную информацию в большом восприимчивом поле.
- Содержимое в курсе. Вместо использования фиксированного ядра для всех выборок (например, деконволюции), CARAFE поддерживает обработку с учетом содержимого для конкретного экземпляра, которая динамически генерирует адаптивные ядра.
- Легкий и быстрый в расчете. CARAFE требует небольших вычислительных затрат и может быть легко интегрирован в существующие сетевые архитектуры.
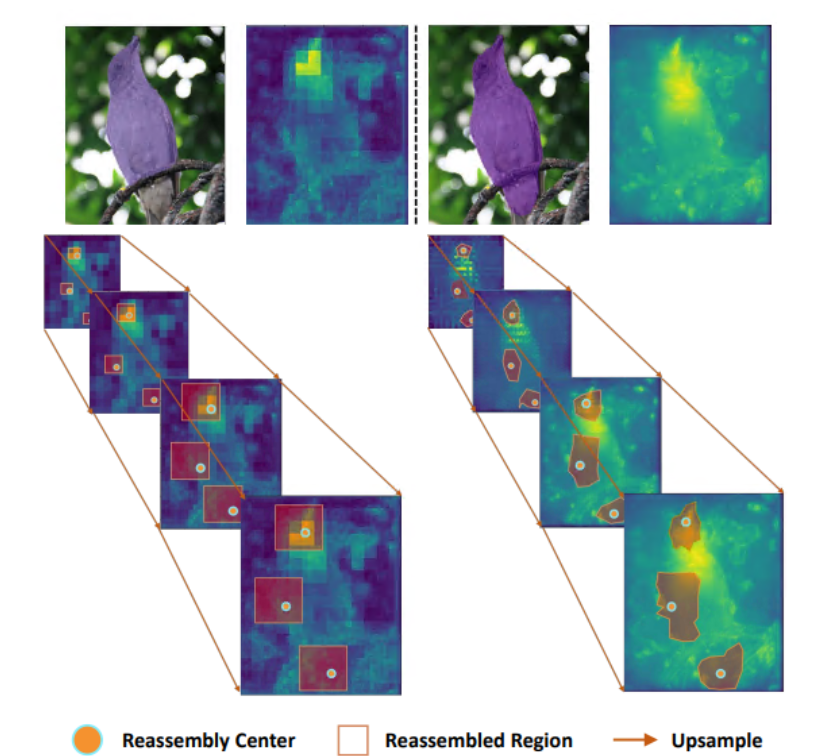
В этой работе мы предлагаем рекомбинацию объектов с учетом содержимого (CARAFE) для повышения дискретизации карты объектов. В каждом месте CARAFE может использовать базовую информацию о содержимом для прогнозирования ядра рекомбинации и рекомбинации функций в заранее определенной близлежащей области. Благодаря информации о содержимом CARAFE может использовать адаптивные и оптимизированные ядра рекомбинации в разных местах, достигая более высокой производительности, чем обычные операции повышения дискретизации, такие как интерполяция или деконволюция.
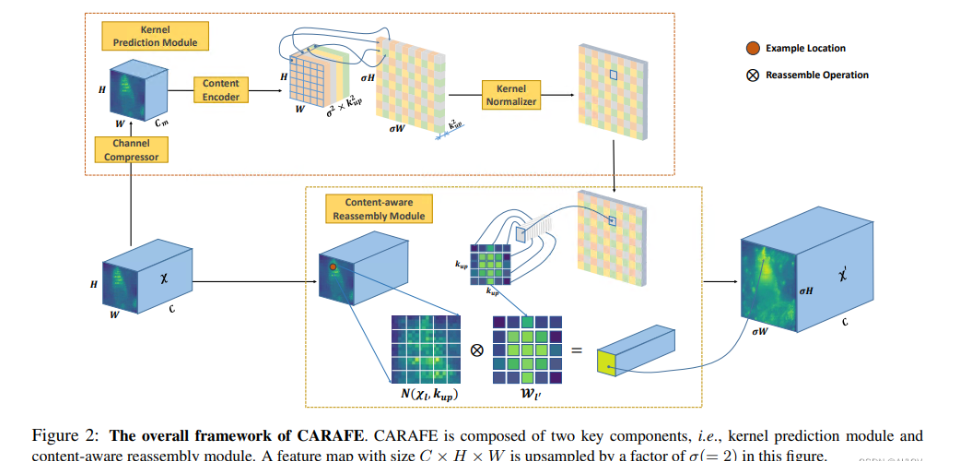
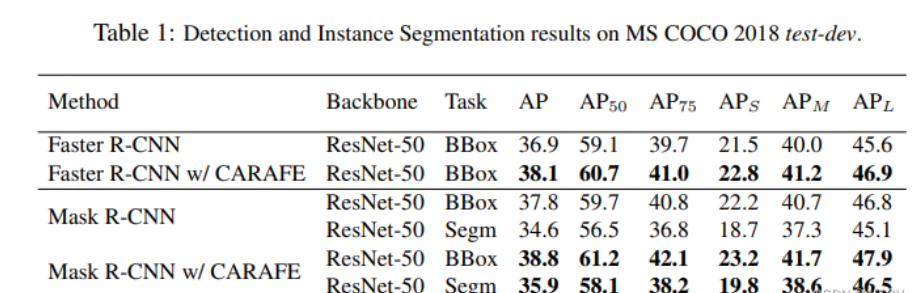
Чтобы проверить эффективность CARAFE, включая обнаружение целей, сегментацию экземпляров, семантическую сегментацию, восстановление изображений и т. д., на MS COCO test-dev 2018 CARAFE может повысить производительность обнаружения Faster RCNN на 1,2 % и улучшить сегментацию экземпляров. производительность Маска RCNN 1,3%. Когда 256-канальная карта признаков H × W подвергается повышающей дискретизации в 2 раза, вычислительные издержки, вносимые CARAFE, составляют всего H * W * 199 тыс. Флопс, тогда как вычислительные издержки деконволюции составляют H * W * 1180 тыс. флопов. Таким образом, CARAFE является эффективным и действенным оператором повышения дискретизации функций.
3.CARAFE присоединяется к YOLOv10
3.1 — Ultralytics/nn/attention/attention.py
import torch
import torch.nn as nn
from torch.nn import functional as F
###################### CARAFE #### start ###############################
class CARAFE(nn.Module):
# CARAFE: Content-Aware ReAssembly of FEatures https://arxiv.org/pdf/1905.02188.pdf
def __init__(self, c1, c2, kernel_size=3, up_factor=2):
super(CARAFE, self).__init__()
self.kernel_size = kernel_size
self.up_factor = up_factor
self.down = nn.Conv2d(c1, c1 // 4, 1)
self.encoder = nn.Conv2d(c1 // 4, self.up_factor ** 2 * self.kernel_size ** 2,
self.kernel_size, 1, self.kernel_size // 2)
self.out = nn.Conv2d(c1, c2, 1)
def forward(self, x):
N, C, H, W = x.size()
# N,C,H,W -> N,C,delta*H,delta*W
# kernel prediction module
kernel_tensor = self.down(x) # (N, Cm, H, W)
kernel_tensor = self.encoder(kernel_tensor) # (N, S^2 * Kup^2, H, W)
kernel_tensor = F.pixel_shuffle(kernel_tensor, self.up_factor) # (N, S^2 * Kup^2, H, W)->(N, Kup^2, S*H, S*W)
kernel_tensor = F.softmax(kernel_tensor, dim=1) # (N, Kup^2, S*H, S*W)
kernel_tensor = kernel_tensor.unfold(2, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W*S, S)
kernel_tensor = kernel_tensor.unfold(3, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W, S, S)
kernel_tensor = kernel_tensor.reshape(N, self.kernel_size ** 2, H, W,
self.up_factor ** 2) # (N, Kup^2, H, W, S^2)
kernel_tensor = kernel_tensor.permute(0, 2, 3, 1, 4) # (N, H, W, Kup^2, S^2)
# content-aware reassembly module
# tensor.unfold: dim, size, step
x = F.pad(x, pad=(self.kernel_size // 2, self.kernel_size // 2,
self.kernel_size // 2, self.kernel_size // 2),
mode='constant', value=0) # (N, C, H+Kup//2+Kup//2, W+Kup//2+Kup//2)
x = x.unfold(2, self.kernel_size, step=1) # (N, C, H, W+Kup//2+Kup//2, Kup)
x = x.unfold(3, self.kernel_size, step=1) # (N, C, H, W, Kup, Kup)
x = x.reshape(N, C, H, W, -1) # (N, C, H, W, Kup^2)
x = x.permute(0, 2, 3, 1, 4) # (N, H, W, C, Kup^2)
out_tensor = torch.matmul(x, kernel_tensor) # (N, H, W, C, S^2)
out_tensor = out_tensor.reshape(N, H, W, -1)
out_tensor = out_tensor.permute(0, 3, 1, 2)
out_tensor = F.pixel_shuffle(out_tensor, self.up_factor)
out_tensor = self.out(out_tensor)
# print("up shape:",out_tensor.shape)
return out_tensor
###################### CARAFE #### end ###############################
3.2 yolov10n-CARAFE.yaml
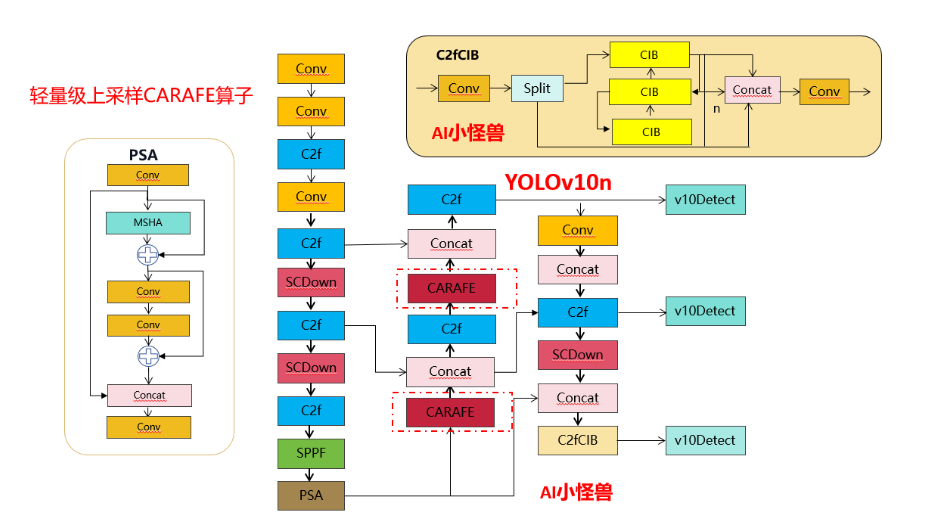
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PSA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, CARAFE, [512,3,2]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, CARAFE, [256,3,2]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
Оригинальный текст см.:
https://blog.csdn.net/m0_63774211/article/details/139408026



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
