Углубленный анализ видеомодели Соры Вэньшэна: эксклюзивное руководство для всей сети, понимание 98% ключевой информации, чисто практическая информация
Углубленный анализ видеомодели Соры Вэньшэна: эксклюзивное руководство для всей сети, понимание 98% ключевой информации, чисто практическая информация
Sora — это модель с множеством возможностей, в основе которой лежит генерация видео, со следующими возможностями:
- Генерация текста/изображения видео
- видео создать видео
- Создано 1 минутное сверхдлинное видео высокого качества
- видео Генерация многовидового деления
- Квазииндустриальные цифровые игры-близнецы/научно-фантастические фильмы и другие спецэффекты, возможности физического движка
1. Сравнение различий в способностях Соры, Runway Gen2, Пики и т. д.
Предметы способностей | OpenAl Sora | Другие модели |
|---|---|---|
Продолжительность видео | 60 секунд | Десять секунд максимум |
Соотношение сторон видео | Любой размер от 1920x1080 до 1080x1920. | Фиксированный размер, например 16:9,9:16,1:1 и т. д. |
Четкость видео | 1080P | масштабирование до 4К |
Видео о генерации текста | поддерживать | поддерживать |
Изображение в видео | поддерживать | поддерживать |
видео создать видео | поддерживать | поддерживать |
Несколько ссылок на видео | поддерживать | Нетподдерживать |
Видео по редактированию текста | поддерживать | поддерживать |
Расширенное видео | Развернуть вперед/назад | толькоподдерживать Развернуть назад |
видео соединение | поддерживать | Нетподдерживать |
симуляция реального мира | поддерживать | поддерживать |
Имитация экшн-камеры | мощный | слабый |
Моделирование зависимостей | мощный | слабый |
Влияние на состояние мира (мировое взаимодействие) | мощный | слабый |
Моделирование искусственных процессов (цифрового мира) | поддерживать | Нетподдерживать |
- Четкость видео,OpenAI Sora Значение по умолчанию: 1080P, и большинство разрешений по умолчанию на других платформах также 1080P Следующее просто проходит мимо upscale После операции ожидания можно достичь более четкого и четкого уровня.
- Sora Из коробки генерирует 60-е из продолжительности видео, где видео соединение、цифровой мирмоделирование、Влиять на состояние мира(мировое взаимодействие)、Имитация экшн-камерыждать недоступны на предыдущих видеоплатформах и инструментах.
- OpenAI Sora Модель также может генерировать изображения напрямую, это видео генерирует ядро из многофункциональной модели.
2. Точка прорыва в технологии Sora
Сора — это модель с тремя ключевыми моментами: латентным, трансформирующим и диффузным.
- Официальный сайт-витрина
- Подсказка: «Два пиратских корабля сражаются друг с другом, плывя внутри чашки кофе из реалистичного видео крупным планом».

- Моделирование экземпляров двух изысканных из 3D Активы: Пиратские корабли с разными декорациями. Sora должен неявно разрешить текст в его скрытом пространстве, чтобы 3D из проблемы.
- 3D-объект остается анимированным, пока плывет и избегает пути друг друга.
- Кофе из гидродинамики,Вокруг корабля даже образуется пузырь. Гибкая графика — это целая область компьютерной графики.,Традиционно требовались очень сложные алгоритмы и уравнения.
- Фотореализм, почти как рендеринг с трассировкой лучей.
- В моделировании учитываются небольшие размеры чаши и океана, а также используется фотография «Приход» с наклоном и сдвигом, чтобы создать «маленький» воздух.
- Сценария из семантики не существует в реальном мире,Но движок по-прежнему реализует правильные физические правила, которые мы ожидаем.
- Подсказка: стильная женщина идет по улице Токио, наполненной теплыми светящимися неоновыми огнями и анимированными вывесками города. На ней была черная кожаная куртка, красная юбка, черные ботинки и при себе была черная сумочка. Она носила солнцезащитные очки и красную помаду. Она ходит уверенно и непринужденно. Улицы мокрые и отражающие свет, создавая красочный эффект освещения и зеркал. Много пешеходов ходят вокруг

Сора Винсент Видео, исследуя новую эру создания видео с помощью искусственного интеллекта
ссылка на видео: https://live.csdn.net/v/364231
* Создавайте несколько перспектив независимо друг от друга

>мир Модельа физический движок - это виртуальная реальность(VR)и компьютерная графикаиз Две ключевые концепции。мир Модельэто описание виртуальной средыизрамка,Включает сцену, объект, элементы освещения и ожидания.,Используется для представления внешнего вида виртуального мира. Физический движок используется для расчета физического движения и взаимодействия между объектами.,нравиться Гравитация, столкновение, трение, ожидание. суммируя,Модель мира — виртуальная среда со статическим описанием.,Физический движок отвечает за динамическое поведение объектов в виртуальной среде. Они работают вместе в технологии виртуальной реальности.,Обеспечьте пользователям захватывающийизопыт。
>мир Модель Более требовательный,Сюда входит умение обрабатывать сложные сцены и физические эффекты. способность к обобщению в новых условиях.、и лучшее использование предшествующих знаний для рассуждений в реальном времени.、Ожидание прогнозирования и принятия решений. Хотя Sora Он смог генерировать более точный контент, но когда сцена включает в себя взаимодействие нескольких объектов или сложные физические движения, Сора Могут возникнуть ошибки или отклонения. Во-вторых Sora В настоящее время он в основном полагается на большое количество тренировок для изучения правил генерации, но этот метод может ограничивать его способность к обобщению и способность принимать решения в реальном времени в новых средах. Это также в настоящее время Sora Не мир Модельиз причиныИз технического отчета модели Сора мы видим, что реализация модели Сора основана на серии солидных исторических технических работ OpenAI, включая, помимо прочего, визуальное понимание (Клип), модель Трансформеров и появление крупных модели ( ChatGPT), субтитры к видео (DALL·E 3)
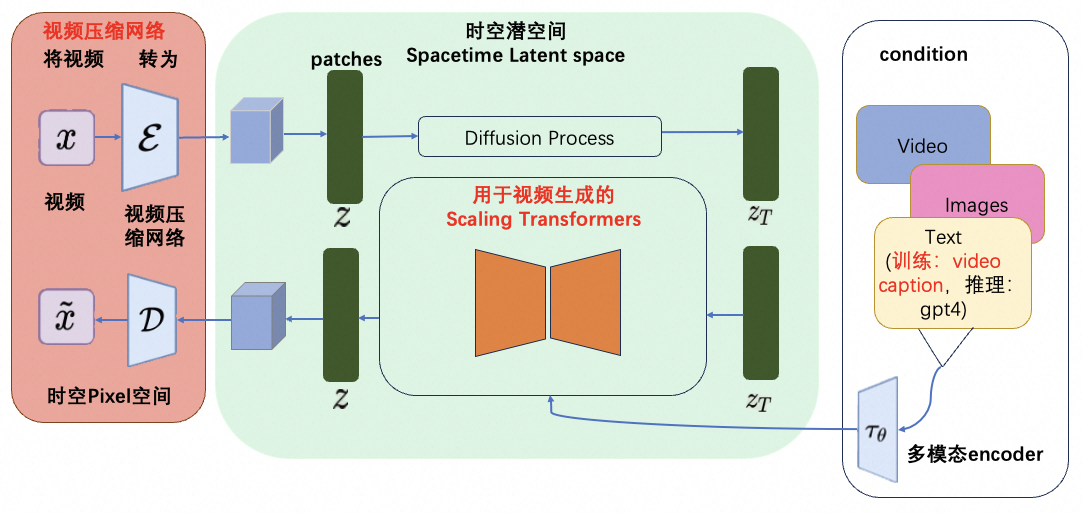
2.1 Основной пункт 1: Сеть сжатия видео
Патчи созданы на основе больших языковых моделей — парадигмы, которая частично обязана своим успехом использованию токенов, элегантно объединяющих различные текстовые модальности (код, математику и различные естественные языки). В больших языковых моделях есть текстовые токены, а в Sora — визуальные патчи. В своей предыдущей работе, такой как Clip, OpenAI полностью использовала технический подход, согласно которому разбиение на фрагменты является эффективным представлением моделей визуальных данных (справочный документ: Изображение стоит 16x16 слов: Трансформаторы для распознавания изображений в масштабе). Задача сети сжатия видео заключается в преобразовании видеоданных высокой размерности в фрагменты. Сначала она сжимает видео в скрытое пространство низкой размерности, а затем разлагает его на фрагменты пространства-времени.
Сложность: сеть сжатия видео аналогична VAE в модели скрытой диффузии, но какова степень сжатия и как обеспечить лучшее сохранение функций видео, требует дальнейших исследований.

2.2 Основной пункт 2: преобразователь масштабирования для длинных видео
Учитывая входной шумовой патч + текстовую подсказку, он обучается прогнозировать исходный «чистый» патч. Важно отметить, что Сора является масштабирующим преобразователем. Трансформеры демонстрируют значительную масштабируемость на больших языковых моделях.
Сложность: Можно scaling up из transformer нравиться Как тренироваться Приходить, для первого шага из patches Проводить эффективное обучение, которое может включать сложные области long контекст (до 1 Минуты извидео)изпод хранения, точка error accumulation нравиться, гарантия относительно низкая, видео средний объект высокого качества и последовательности, видео condition,image condition,text condition измультимодальныйподдерживатьждать。
2.3 Основной пункт 3: Видеозапись
Видео-резюме / Генерация видеописьма — это подзадача мультимодального обучения. Общая цель — дать одно или несколько текстовых описаний на основе содержания видео. созданный caption Его можно использовать для последующего восстановления ожидания, а также напрямую помочь интеллектуальным агентам или людям с нарушениями зрения понять реальную ситуацию. Благодаря такому качественному обучению гарантируется высокая степень связи текста (подсказки) и видеоданных. align。Sora также используйте DALL·E 3 из метод повторного захвата, то есть создание высокоописательных данных для визуального обучения. подпись, которая делает Sora Чтобы иметь возможность более точно следовать инструкциям пользователя из текста при создании видео и поддерживать длинный текст, это должно быть OpenAI Уникальные преимущества. На этапе генерации Сора будет основано на OpenAI из GPT Модельдля пользователейиз prompt Перепишите, чтобы получить высокое качество, очень наглядное и высокое качество. запрос, а затем отправьте его в модель создания видео для завершения работы по созданию. подпись Данных по обучению недостаточно:
- с одной стороны,Обычное описание изтекста изображения часто бывает слишком упрощенным (чем нравиться набор данных COCO),Большинство из них только описывают объект на изображении и игнорируют множество другой информации на изображении.,Сравниватьнравитьсяфон,Местоположение и количество объекта,из текста ждать на картинке.
- кроме тогос одной стороны,График текущих тренировок Винсентаизизображениетекстверноданныенабор(Сравниватьнравиться LAION набор данных) сканируются на веб-странице, описание исходного текста изображения фактически является alt-text,Но многие из этих описаний не очень актуальны.,Сравниватьнравитьсярекламировать。
технологический прорыв:тренировать image captioner Приходитькомпозитное изображениеиз подпись, синтез caption с оригиналом caption соотношение смешивания до 95%: 5%, но не использовать; 95% синтетическая длина caption Придя на обучение, также получите из Модель «Переоснащение» слишком долго caption начальство,нравитьсяфруктыиспользоватьобщепринятыйизкороткий caption При генерации изображений эффект может ухудшиться. Чтобы решить эту проблему, OpenAI использовать GPT-4 Приходить “upsample” Пользователь из подпись, ниже показано, как использовать GPT-4 Приход выполняет эту оптимизацию независимо от того, что вводит пользователь. подпись, после GPT-4 После оптимизации мы получаем длинный caption:
Сложность: Эта технология не нова. Трудность заключается в накоплении. Даже ее синтез требует большого количества профессиональных аннотаций и оценок. "большой" модель, "высокая" Вычислительная мощность, «огромная» данные
Для получения дополнительной информации см.: Исследование новой эры создания видео с помощью искусственного интеллекта: Винсент Видео Сора. VS RunwayML、PikaиStableVideo——Кто будет руководить будущим Приходить:https://blog.csdn.net/sinat_39620217/article/details/136171409
3.У Соры есть недостатки



Логическая ошибка физического взаимодействия:Sora Иногда это порождает физически необоснованные действия; Sora Модельсуществоватьмоделирование Основные физические взаимодействия,нравитьсяразбитое стеклождатьаспект,Недостаточно точно. Это может быть связано с тем, что Модели не хватает примеров таких физических событий в обучающих данных.,Или Модель не может полностью изучить и понять эти сложные физические процессы, основанные на основных принципах.изменение статуса объектанекорректно:существоватьмоделированиенравиться Едаиобъектзначительное изменение статусаизво время взаимодействия,Sora Изменения не всегда могут быть отражены правильно. Это говорит о том, что Модель может иметь ограничения в понимании и прогнозировании изменений состояния объекта и динамических процессов.Точность теряется в сложных сценах:моделирование Несколькообъекти Несколькомежду персонажамииз Сложные взаимодействия могут привести к сюрреалистическим последствиямфрукты; Длинный образец видео из-за бессвязности: при создании длинных образцов видео Сора Может создавать бессвязные сюжеты или детали, возможно, из-за трудностей с поддержанием согласованности контекста на протяжении длительного периода времени. ; Внезапно появляется объектиз: объектиз может появляться без всякой причины в видео, что показывает, что понимание Моделью непрерывности пространства и времени необходимо улучшить.
4. Оптимизация видеоподсказок Винсента
видео | Официальное слово-подсказка | оптимизация |
|---|---|---|
Реалистичное видео крупным планом,Показано, как два пирата сражаются друг с другом во время плавания за чашкой кофе. | Контекст: Миниатюрный мир внутри чашки кофе. Персона: Два пиратских корабля. Цель: Показана реалистичная сцена боя между пиратскими кораблями в кафе. Ограничения: видео должно выделять пиратский корабль детализацией и динамикой, а также текстуру кофе в качестве фона. Шаги: Установите сцену в виде чашки, наполненной кофе, а поверхность кофе — в океане. Описание пиратских кораблей: Два детальных пиратских корабля в кофе. "океан" Перемещайтесь и сражайтесь. Голова крупным планом: используйте перспективу крупным планом, чтобы запечатлеть динамику пиратского корабля и текстуру кофе. Показаны подробности боя: перестрелка пиратского корабля, действия пиратов на борту. Примеры: Ссылка на аналогичный эффект. Шаблон: cssCopy. Код[описание сцены] В полной чашке поверхность кофе колеблется, словно миниатюрный океан. [Описание персонажа] Два хорошо оснащенных пиратских корабля плыли в этой чашке кофе и яростно сражались друг с другом. [Цель] Реалистичный снимок крупным планом показывает захватывающую сцену борьбы пиратских кораблей друг с другом внутри кофейной чашки. [Ограничения] Обратите внимание на детали и динамику пиратов, а также текстуру и колебания кофе в качестве фона. | |
Модная женщина ходитсуществовать充满温暖霓虹灯и动画城市标牌из Улицы Токионачальство。Она носит черную кожаную курткукрасная длинная юбка и черный саб,Носите с собой черный кошелек. Она носила солнцезащитные очки и красные румяна. Она ходит уверенно и непринужденно. Улицы мокрые и отражающие свет,Образует зеркальный эффект при освещении теневым светом. Многие пешеходы ходят по Приходить. | Context: Оживленная улица Токио ярко освещена ночью неоновыми огнями и анимированными рекламными щитами, переплетающимися в полосы разноцветного света. После дождя улицы становятся влажными и блестящими, создавая очаровательный зеркальный эффект под освещением разноцветных фонарей. Многие пешеходы спешили в эту ночь с мигалками. Персона: Стильная женщина носит черную кожаную куртку, ярко-красную юбку и черные ботинки, а также носит черную сумочку. В темных очках и красной помаде она шла уверенно и беззаботно. Цель: Демонстрация уверенности и стиля этой модной женщины в неоновом свете Токио. Ограничения: Визуал должен подчеркивать эффект неонового света в ночное время, отражать отражающий эффект мокрых улиц и модную одежду персонажей, подчеркивая уверенные шаги персонажей и непринужденный стиль ходьбы. -Шаги:: 1. Установите сцену на ночную улицу Токио, освещенную неоновыми огнями. 2. Опишите персонажа: Модная женщина в черной кожаной куртке, длинной красной юбке и черных ботинках, с черной сумочкой в руках, в темных очках и с красной помадой. 3. Внешний вид подчеркивает уверенный темп персонажа и непринужденную манеру ходьбы. 4. Опишите окружающую среду: сырая улица отражается в свете, вокруг ходят пешеходы. Пример: Предоставьте описание или изображение, показывающее эффект подобной сцены. Шаблон:cssCopy Code: [описание сцены] На оживленной улице неоновые огни и разноцветные огни колеблются, как миниатюрный ночной океан. [Описание персонажа] По этой улице уверенно шагает модная женщина. Ее черный жакет и красная юбка выглядят особенно эффектно в свете фонарей. [Цель] Через яркие описания сцен он показывает уверенный стиль модниц под неоновым светом. [Ограничения] Уделяем внимание передаче деталей и динамики костюмов персонажей, а также мокрых улиц в качестве фона, текстур и отражений. |

5. Какое влияние окажет появление Sora и AI на программистов?
- Положительное влияние:
- Повышение эффективности программирования: инструменты искусственного интеллекта могут автоматизировать некоторые утомительные задачи программирования.,нравиться Инспекция кода, рефакторинг кодаждать,от И уменьшить нагрузку на программистов,Повышена эффективность программирования. в то же время,Sora также предоставляет более эффективные и интеллектуальные инструменты разработки для программистов.,Может ускорить разработку.
- Улучшение качества кода: инструменты искусственного интеллекта могут помочь программистам обнаруживать дефекты и потенциальные проблемы в коде, повышая качество и надежность кода. Это имеет решающее значение для обеспечения качества программного обеспечения и удобства пользователей.
- Содействие образованию в области программирования: инструменты искусственного интеллекта и Sora могут предоставить начинающим программистам более дружественные среды и инструменты программирования.,Сделать обучение программированию более доступным и интересным,от И привлечь больше людей в сферу программирования.
- Предоставляйте больше возможностей для инноваций: инструменты искусственного интеллекта могут дать программистам больше вдохновения и творчества.,Помогите им создавать лучшие программы. в то же время,Сора Винсент также предоставляет больше сценариев применения и потребностей рынка для программистов.,и вдохновить их энтузиазм к инновациям.
- Негативные эффекты:
- Усиление давления профессиональной конкуренции: с развитием технологий искусственного интеллекта,Некоторые простые задачи программирования можно заменить автоматизированными инструментами.,Это требует от программиста постоянного обучения и освоения новых навыков.,Адаптироваться к потребностям технологических изменений. Это может привести к усилению конкурентного давления в профессии.,Некоторые люди с недостаточными навыками могут столкнуться с риском безработицы.
- Моральные и этические проблемы. Разработка и применение инструментов ИИ также порождают некоторые моральные и этические проблемы.,нравитьсяданные Конфиденциальность, алгоритмическая честностьждать. программисту нужно сосредоточиться на этих вопросах,И соблюдайте соответствующие законы, правила и этику в процессе разработки.

6.Sora Полный анализ технических принципов&краткое содержание
OpenAI из Научная работа «Видео generation models as world Симуляторы» исследует крупномасштабный метод обучения для создания Модельиз на видеоданных. В этом исследовании особое внимание уделяется В текстовой модели условной диффузии эти модели обучаются одновременно на видео и изображениях, обрабатывая различную продолжительность, разрешение и соотношение сторон изображения. Модель изMAX, упомянутая в исследовании Sora Способен генерировать высокую точность в течение одной минуты. Ниже приведены некоторые ключевые моменты статьи:
-
Унифицированное визуальное представление данных:Исследователи классифицировали все видыиз Зрениеданныепреобразовать в единицуизвыражать,для проведения масштабныхизгенерировать Модельтренироваться。Sora В качестве своего представления он использует визуальные патчи, аналогичные разметке изтекста в модели большого языка (LLM). -
сеть сжатия видео:исследователитренироватьсясеть,Сжимайте исходное видео в низкоразмерное скрытое пространство.,и сделай этовыражатьразложен на пространственно-временные участки。Sora Тренируйтесь в этом сжатом скрытом пространстве и создавайте видео. -
Диффузионная модель:Sora это модель диффузии, которая генерирует видео, предсказывая исходный «чистый» патч на основе входного сигнала «Приход» из шумового патча. Diffusion продемонстрировал значительную масштабируемость в области языкового моделирования, компьютерного зрения и генерации изображений. -
видео Генерацияиз Расширяемость:Sora Возможность создания различных разрешений, длительности и соотношений сторон, включая Full HD. Эта гибкость позволяет Sora Возможность создавать контент напрямую для разных устройств или быстро создавать прототипы контента перед созданием полного разрешения. -
понимание языка:длятренироватьсятекстприезжатьвидеогенерироватьсистема,Нужно многоизвидеои соответствующиеизтекстзаголовок。исследователи应用了существовать DALL·E 3 Метод переописания представлен в , который сначала обучает высокоописательный генератор заголовков, а затем генерирует текстовые заголовки для всех видео в обучающем наборе. -
Редактирование изображений и видео:Sora Вы можете не только создавать видео на основе текстовых подсказок, но также создавать подсказки на основе существующих изображений или видео. Это делает Sora Способный выполнять широкий спектр задач по работе с изображениями и редактированию, нравиться создает идеальные циклы из видео, анимированные неподвижные изображения вперед или назад Расширенное видеождать。 -
моделированиеспособность:когдавидео Модельсуществоватькрупный масштабтренироватьсячас,Они демонстрируют некоторые интересные и новые возможности.,делать Sora Способность моделировать определенные аспекты физического мира, нравиться динамическое движение камеры, долговременную последовательность и постоянство объекта в ожидании.
хотя Sora Продемонстрировал потенциал игрока, но у него все еще есть много ограничений, таких как недостаточная точность при взаимодействии с базовой физикой (разбивание стекла). Исследователи полагают, что продолжение Расширенного видео Модель – это перспективный путь к развитию физического и цифрового миров. В этом документе представлено введение в Sora Модельиз предоставляет углубленный анализ, показывающий его потенциал и проблемы в области создания видео. Таким образом, OpenAI Ищем способы использования AI Приходя лучше понимать и моделировать окружающий мир из.
Для получения более качественного контента, пожалуйста, обратите внимание на публичном аккаунте: Тин, искусственный интеллект предоставит некоторые соответствующие ресурсы и высококачественные статьи для бесплатного чтения;
- Справочные ссылки:
Исследуйте новую эру поколения ИИ-видео: Винсент видео Сора VS RunwayML, Pika и StableVideo — кто возглавит будущее https://blog.csdn.net/sinat_39620217/article/details/136171409?
stable-diffusion-videos:https://github.com/nateraw/stable-diffusion-videos
StableVideo:https://github.com/rese1f/StableVideo
Официальный сайт соры: https://openai.com/sora
отчет сора по ссылке: https://openai.com/research/video-generation-models-as-world-simulators



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
