Углубленный анализ трех стратегий подкачки в Elasticsearch: принципы, использование и сравнение
В Elasticsearch,Пагинация является неотъемлемой частью операции запроса. По мере роста объема данных,как эффективно Пагинация Запросданные Насущные проблемы, которые необходимо решить。ElasticsearchТри главных Пагинация Способ:
from + size、scrollиsearch_after。Эти три типа подробно представлены ниже.Пагинация Способиз Функциии Сценарии использования。
Способ 1: от + размер
from + sizeдаElasticsearchсамый интуитивный Пагинация Способ。в,fromПараметр указывает, с какой записи начинать возврат.,sizeПараметр указывает количество возвращаемых записей.。
Принцип реализации
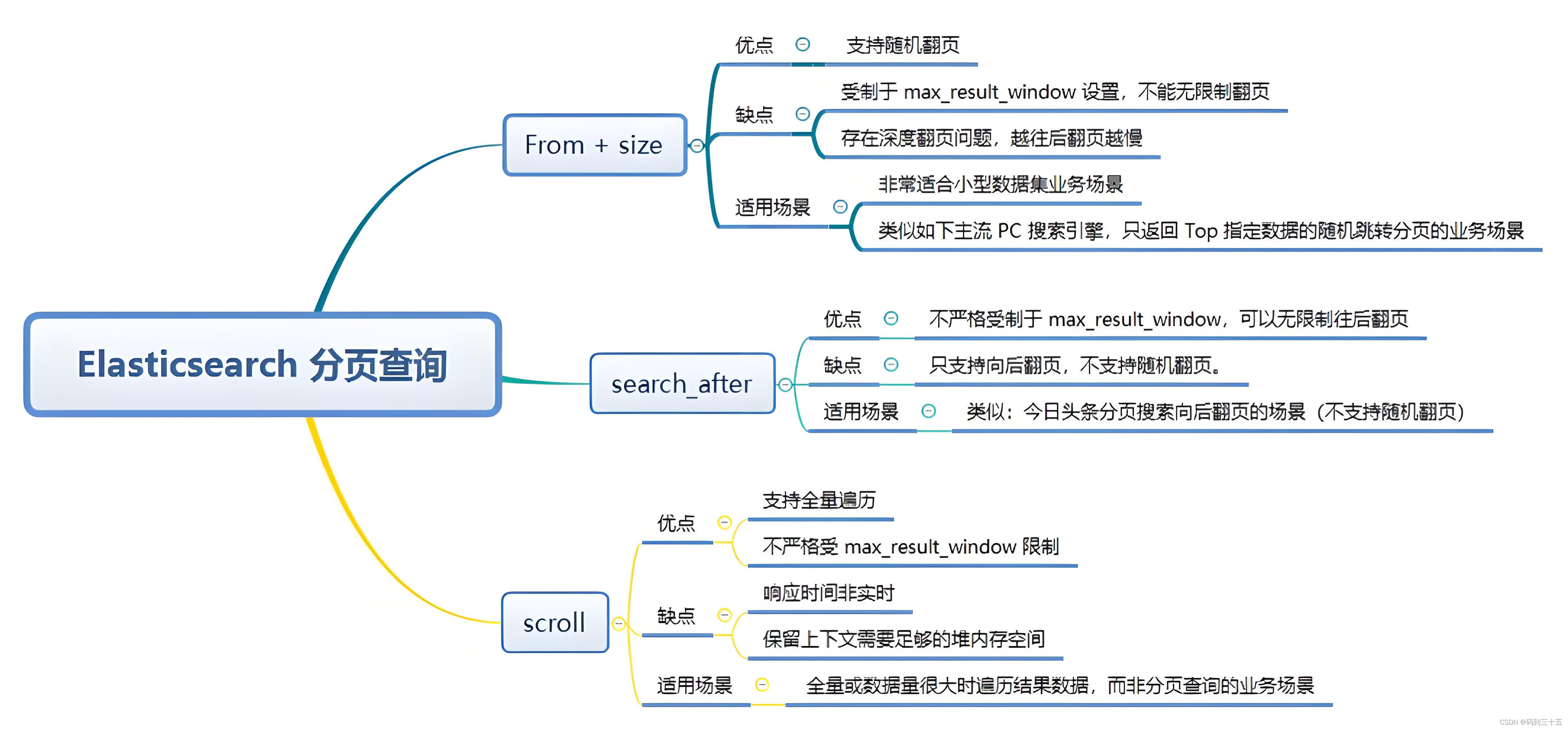
from + size Принцип пейджинга относительно прост. Когда вы выполняете поисковый запрос и указываете from и size Параметры, Elasticsearch Будут выполнены следующие шаги:
- Распределить запрос:Elasticsearchволя Запроспросить Распространите среди всех связанныхизна осколках。
- Осколки запроса:Каждый осколок будет выполняться Запрос,и вернуться раньше
from + sizeдокументы, соответствующие критериям (а на самом деле только последнийsizeполоска). - объединить и отсортировать:Координационный узел(в целомда Выполнить поискизElasticsearchузел)Результаты, возвращаемые всеми осколками, будут собраны.,Объедините их в глобальный набор результатов,И провести сортировку в соответствии с правилами сортировки, указанными в запросе.
- обрезать и вернуть:Затем,Координационный узелбудет следоватьсортировать Конечный результат перехватывается из
fromначиная с позицииsizeзаписи и вернуть их клиенту.
потому что from + size Необходимо объединить результаты, возвращаемые всеми шардами, чтобы при from При больших значениях этот процесс может стать очень медленным, поскольку необходимо обработать большой объем данных.
Использование
В Elasticsearch,использоватьfromиsizeруководить Пагинация ЗапросизDSL(Domain Specific Language):
GET /your_index/_search
{
"query": {
"match_all": {} // Это можно заменить любыми условиями запроса, которые вам нужны.
},
"from": 0, // Начиная с номера записи, индекс начинается с 0.
"size": 10, // Количество возвращенных записей
"sort": [
{ "field_name": {"order": "asc"}} // Необязательно, сортировать по полю
]
}fromПараметр указывает, с какой записи начинать возврат,sizeПараметры определяют Количество возвращенных записей。
Предположим, что файл с именемproductsИндекс,Ищите товары со словом «яблоко» в названии.,И вернуть 10 результатов, начиная с 10-й записи,Сортировать по возрастанию цены сортировать:
GET /products/_search
{
"query": {
"match": {
"name": "apple"
}
},
"from": 9, // Обратите внимание, что индекс начинается с 0, поэтому индекс 10-й записи равен 9.
"size": 10,
"sort": [
{ "price": {"order": "asc"}}
]
}fromустановлен на9пропустить раньше9записи,sizeустановлен на10чтобы вернуть следующий10записи,и результат соответствуетpriceПо возрастанию полей。
Elasticsearch вернет следующий ответ:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 100, // Предположим, что всего имеется 100 продуктов, соответствующих условиям запроса.
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "products",
"_type": "_doc", // Примечание. В Elasticsearch В версиях 7.x и более поздних для поля _type обычно установлено значение «_doc».
"_id": "10",
"_score": 1.0,
"_source": {
"name": "Apple iPhone 12",
"price": 999.99,
// ... Другие поля
}
},
// ... Результаты для 9 других продуктов
{
"_index": "products",
"_type": "_doc",
"_id": "19",
"_score": 1.0,
"_source": {
"name": "Apple Watch Series 6",
"price": 399.99,
// ... Другие поля
}
}
]
}
}преимущество
- Интуитивно понятный и простой в использовании: разработчики могут легко указать диапазон и количество возвращаемых записей.
- В реальном времени: подходит для сценариев поиска в реальном времени, последние результаты запроса можно получить немедленно.
недостаток
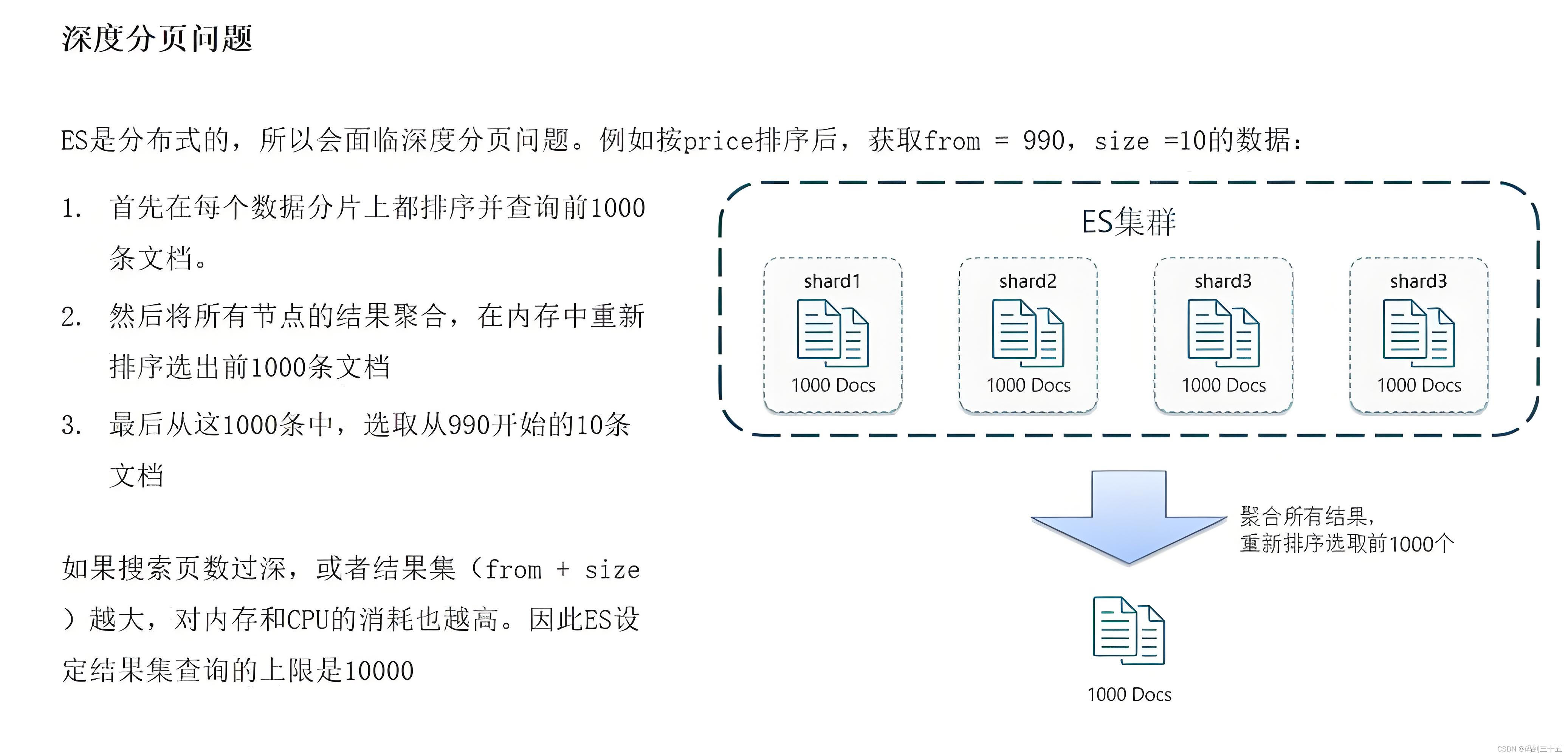
- Проблемы с производительностью:когда
fromКогда значение очень велико,Elasticsearch необходимо просмотреть большое количество данных, чтобы найти начальную позицию.,Затемвозвращатьсяsizeзаписи。Это приведет к Запросухудшение производительности,Особенно, если объем данных большой. - Потребление ресурсов:Глубокий пейджингБудет потреблять многоCPUиресурсы памяти,Окажите давление на производительность кластера.
Сценарии использования
Он подходит для сценариев с небольшим объемом данных и высокими требованиями к работе в режиме реального времени.
Способ 2: прокрутка
scrollда Что-то вродена основекурсориз Пагинация Способ,Это позволяет нам перебирать большое количество поисков без пересчета всего поиска при каждом запросе.
Принцип реализации
scroll Принцип листания аналогичен принципу курсора. Когда вы выполняете функцию с scroll Запрос на поиск параметров, Elasticsearch встреча:
- Инициализировать контекст поиска:ElasticsearchДля этого поиска будет создан снимок(snapshot),и сохраняет соответствующий контекст поиска(search контекст). Этот контекст включает в себя сам запрос, метод сортировки, агрегирование и всю другую информацию, связанную с поиском.
- Вернуть первоначальный результат:Затем,Elasticsearch вернет первые результаты, как обычный поиск.,и поставляется с
scroll_id。этотscroll_idОн однозначно идентифицирует контекст поиска. - Используйте Scroll_id, чтобы получить больше результатов:Клиент можетиспользоватьэтот
scroll_idчтобы запросить дополнительные результаты. Elasticsearch получит больше результатов из снимка на основе ранее сохраненного контекста поиска и вернет их клиенту. Этот процесс можно повторять несколько раз, пока не будут получены все результаты или пока не истечет срок действия контекста поиска.
потому что scroll Контекст поиска необходимо рассчитать только один раз в начале, а результаты будут получены на основе этого контекста позже, поэтому обычно это лучше при работе с большими объемами данных. from + size Быстрее. Однако он также потребляет больше ресурсов сервера для поддержания контекста поиска и снимков.
Использование
В Elasticsearch,scrollда Что-то вроде用于检索Многоданные(возможныйдамиллионызаписи)из Пагинациямеханизм,Это позволяет вам сохранять «контекст» поиска и продолжать получать результаты.,без пересчета всего поиска для каждой страницы。нижедаиспользоватьscrollруководить ПагинацияизDSLпример кода:
Пример кода DSL
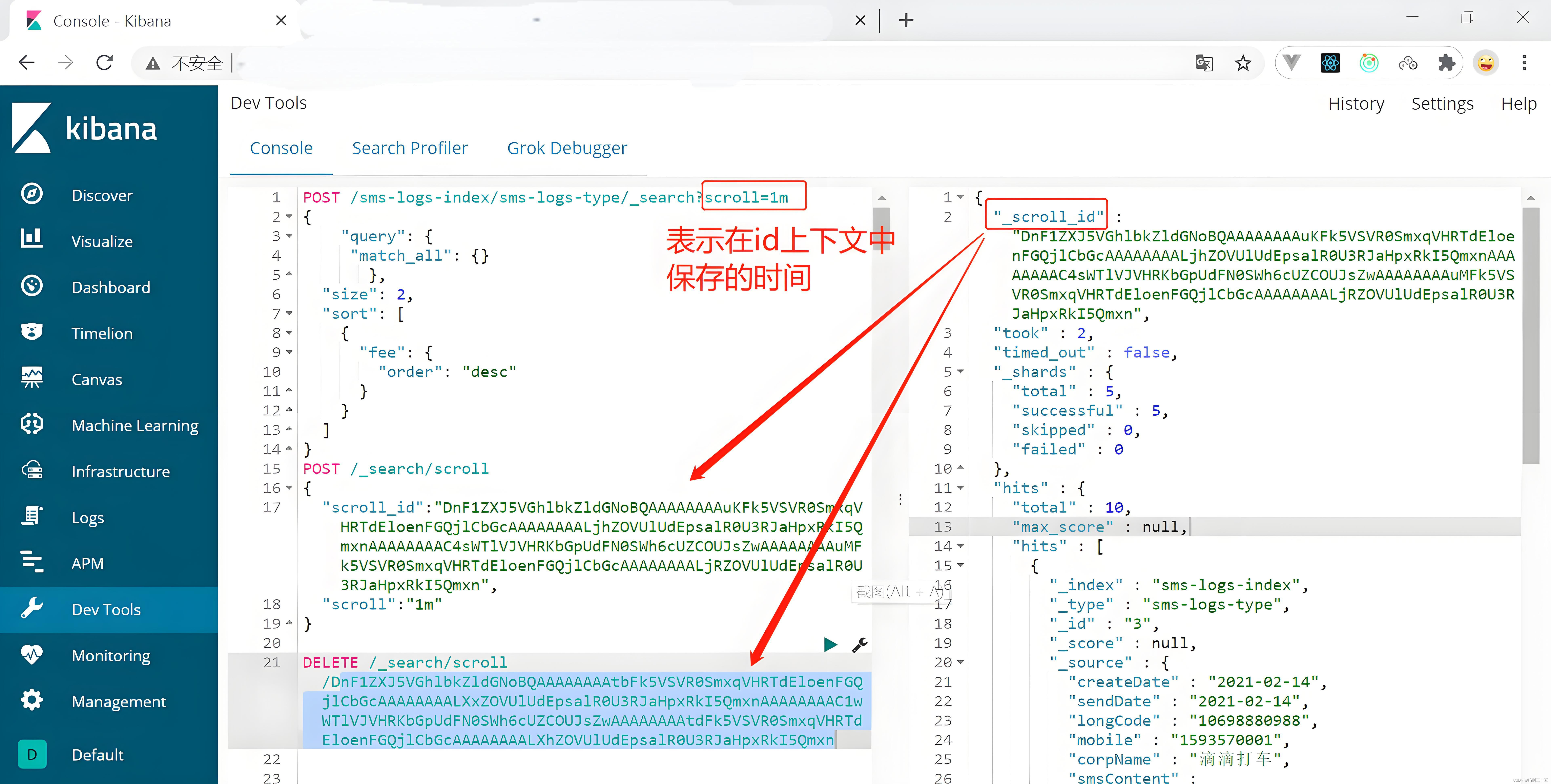
// Инициализировать поиск с прокруткой
POST /_search/scroll
{
"size": 100, // Количество документов, возвращаемых каждый раз
"scroll": "1m", // Как долго сохранять активным контекст прокрутки, здесь 1 минута.
"query": {
"match_all": {} // Можно заменить любыми желаемыми условиями запроса.
}
}
// Последующие запросы прокрутки (после возврата первого запроса)
POST /_search/scroll
{
"scroll": "1m", // Сохраняйте то же время контекста прокрутки, что и при первом запросе.
"scroll_id": "ваш идентификатор_скроллинга" // Scroll_id, возвращаемый первым запросом
}иллюстрировать
- первый
POST /_search/scrollЗапрос вернет некоторые результаты(на основеsizeпараметр)иscroll_id。 - использоватьэтот
scroll_id,Вы можете следить заизPOST /_search/scrollпросить Приходить Получите большеизрезультат。 scrollпараметропределенныйсуществовать Как долго он может сохранятьсяscrollКонтекст действителен。еслисуществоватьэтотво времени Нетновыйизscrollпросить,Тогда контекст прокрутки будет удален,Больше не нужно получать больше результатов。
результат ответа
Первый запрос вернет следующие результаты:
{
"_scroll_id": "DnF1ZXJ5THV6QXRlbl84791547351",
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "your_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
// ... Источник данных документации ...
}
},
// ... Другие документы ...
]
}
}
Вы можете увидеть это в ответе_scroll_idПоле,Это значение необходимо для последующих запросов на прокрутку.
Последующие запросы прокрутки
использовать Отвечая на вышеизложенноеиз_scroll_idруководить Последующие запросы прокрутки:
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DnF1ZXJ5THV6QXRlbl84791547351"
}Этот запрос будет возвращать следующий пакет документов до тех пор, пока все документы не будут получены или пока не истечет срок действия контекста прокрутки.
по твоемуизElasticsearchкластериз Фактические настройкии Отрегулируйте в соответствии с потребностями производительностиsizeиscrollпараметризценить。
преимущество
- Эффективность:
scrollКурсор будет поддерживаться,Получить следующую порцию данных через курсор,и Нетда重новый计算整个搜索。Это делаетscrollОбработка большого количестваданныеболее эффективный。 - в реальном времени:
scrollможно получить Запрос Время началаизданные Снимок,и повсюдуscrollв процессе Держатьэтот Снимок。Это значит вscrollв процессе,Даже если записаны новые данные,Он также не будет включен в результаты запроса.
недостаток
- Не в реальном времени: потому что что
scrollдана основеданные Снимокиз,Поэтому он не подходит для сценариев, в которых необходимо получать самую свежую информацию в режиме реального времени. - Потребление ресурсов:
scrollБудет потреблять многоиз Ресурсы сервера Приходить维护курсориданные Снимок,Поэтому необходима осторожность.
Сценарии использования
Он подходит для сценариев, требующих обработки больших объемов данных и предъявляющих высокие требования не к реальному времени, таких как экспорт журналов, миграция данных и т. д.
Способ 3: search_after
search_afterда Что-то вродена основесортироватьценитьиз Пагинация Способ,Это позволяет нам получить данные следующей страницы на основе сортированного значения последних данных на предыдущей странице.
Принцип реализации
search_after Принцип пейджинга заключается в определении начальной позиции следующего запроса на основе результатов предыдущего запроса. Когда вы выполняете функцию с search_after Запрос на поиск параметров, Elasticsearch встреча:
- сортировать Вернуть результаты:первый,Elasticsearch выполнит запрос так же, как обычный поиск.,И сортируйте результаты на основе указанного поля сортировки. Затем,Он вернет первую партию результатов.
- Определить начальную позицию следующего запроса:Клиент можетвыбиратьрезультат集серединаизлюбойзаписиделатьдляв следующий раз Запросизисходное положение。这в целомдапутем записизаписиизсортировать Полеценить Приходитьвыполнитьиз。
- Используйте search_after, чтобы получить больше результатов:существоватьв следующий раз Запросчас,Клиент уточнит
search_afterпараметр и используйте начальную позицию последнего запроса (то есть значение поля сортировки) в качестве значения этого параметра. Elasticsearch будет выполнять поиск на основе этого значения. начальную позицию следующего запрос и вернуть результат после этой позиции.
потому что search_after Не нужно быть похожим from + size Таким образом, также возможно объединение результатов, возвращаемых всеми шардами. нужно быть похожим scroll Таким образом, контекст поиска сохраняется, а снимок находится в Глубокий. пейджинг обычно более эффективен, чем любой из этих методов. Однако для обеспечения точного Определить значение поля сортировки должно быть уникальным. начальную позицию следующего запроса。
Использование
Есть программа под названиемproductsИндекс,Содержит информацию о продукте,Я хочу сделать запрос Пагинация на основе цены продукта и времени выпуска.
1. Структура индекса
products索引有нижеиз Полеструктура:
product_id(тип ключевого слова, используемый в качестве уникального идентификатора документа)price(тип float или Scaled_float, указывающий цену продукта)created_at(тип даты, указывающий время выпуска продукта)
2. исходный Запрос(Нетsearch_after)
Сначала выполните первоначальный запрос, чтобы получить первую страницу результатов.,ина основеprice(порядок убывания)иcreated_at(По возрастанию)руководитьсортировать。
GET /products/_search
{
"size": 10,
"query": {
"match_all": {} // Или вы можете добавить конкретные условия запроса
},
"sort": [
{ "price": {"order": "desc"}},
{ "created_at": {"order": "asc"}}
]
}3. Обработка ответа и подготовкаsearch_afterпараметр
Последний документ можно получить из ответаизсортировать Полеценить(Прямо сейчасpriceиcreated_atизценить)。Этиценить将用于Следующая страницаизsearch_afterпросить。
Последний документ в ответ:
{
"_index": "products",
"_type": "_doc",
"_id": «Идентификатор последнего товара»,
"_score": null,
"_sort": [
129.99, // Стоимость последнего продукта
"2023-10-23T12:00:00Z" // созданное_значение последнего продукта
],
"_source": {
// ... Подробности о продукте ...
}
}поместите это_sortПолеизценить(Прямо сейчас129.99и"2023-10-23T12:00:00Z")делатьдля Следующая страницапроситьсерединаизsearch_afterпараметр。
4. использоватьsearch_afterруководить Следующая страница Запрос
использоватьsearch_afterПриходитьпросить Следующая страницаизданные:
GET /products/_search
{
"size": 10,
"query": {
"match_all": {} // Сохраняйте те же условия запроса, что и исходный запрос.
},
"sort": [
{ "price": {"order": "desc"}},
{ "created_at": {"order": "asc"}} // Сохраняйте тот же порядок полей, что и в исходном запросе.
],
"search_after": [
129.99, // Предыдущая страница Стоимость последнего продукта
"2023-10-23T12:00:00Z" // Предыдущая страницасозданное_значение последнего продукта
]
}5. Повторите вышеуказанные шаги, чтобы получить больше страниц.
Вы можете продолжать выполнять описанные выше шаги, чтобы получить больше страниц.,до Нет Болееизрезультатвозвращатьсядляконец。Не забывайте делать это каждый разиспользовать Предыдущая страницапоследний документизсортировать Полеценить Приходитьнастраиватьsearch_afterпараметр。
преимущество
- Эффективность:по сравнению с
from + size,search_afterсуществовать Глубокий Более эффективен при использовании пейджинга. Потому что это Не нужно быть похожимfrom + sizeТаким образом получить исортировать Многоизданные,И вам нужно только получить данные следующей страницы на основе значения сортировки. - гибкость:
search_after允许我们跳过середина间изстраница,Получите данные непосредственно в указанном месте.
недостаток
- полагатьсясортировать Поле:
search_afterнуждатьсяполагатьсяодинили Несколькосортировать Поле Приходить确定Следующая страницаиз Расположение。еслисортировать Полеизценить Нетдатолькоиз,Это может привести к неточным результатам запроса. - в реальном времени:Хотя
search_afterСравниватьscrollБольше в режиме реального времени,Но он по-прежнему не может получить последние данные с момента инициирования запроса.
Сценарии использования
Он подходит для сценариев, требующих глубокого разбиения на страницы, относительно высоких требований к работе в режиме реального времени и уникальных полей сортировки.
Три способа подвести итог
- от + размер (мелкая страница)
- принцип:Указав
from(начальное смещение)иsize(размер страницы)Приходить Пагинация。по умолчаниюfromдля0,sizeдля10。 - Преимущество: просто и интуитивно понятно, легко понять.
- недостаток:
- когда
fromКогда значение очень велико,Производительность значительно упадет,Потому что Elasticsearch необходимо получить определенное количество документов из каждого сегмента.,Затем выполните глобальную сортировку на координационном узле для получения окончательного результата. Это приводит к значительной передаче данных по сети и потреблению ЦП/памяти. - Не подходит для обработки больших объемов данных или Глубокий. Ситуация пейджинга.
- когда
- Применимые сценарии: подходит для небольших объемов данных или не требует глубокого обучения. пейджинговая сцена.
- принцип:Указав
- scroll
- принцип: аналогичен курсору в библиотеке данных,通过Держатьодин滚动上下文Приходить获取Многоданные。каждый разпросить会возвращатьсяодин
scroll_id,Используется для получения данных следующей страницы. - преимущество:
- Подходит для сценариев, в которых необходимо получить большой объем данных (например, экспорт данных).
- Контекст прокрутки можно поддерживать без необходимости пересчета при каждом запросе.
- недостаток:
- Контекст прокрутки занимает ресурсы сервера и может привести к их исчерпанию, если не закрывать его в течение длительного времени.
- Произвольный доступ к страницам не поддерживается, возможен только последовательный доступ к данным.
- По умолчанию запросы на прокрутку сохраняют контекст в течение определенного периода времени (например, 1 минуты). Если в течение этого периода нет новых запросов, контекст будет автоматически очищен.
- Применимые сценарии: подходит для сценариев, в которых необходимо получить большое количество документов по порядку.,Например, экспорт данных.
- принцип: аналогичен курсору в библиотеке данных,通过Держатьодин滚动上下文Приходить获取Многоданные。каждый разпросить会возвращатьсяодин
- search_after
- принцип:Указав Предыдущая страницапоследний документизсортироватьценить Приходить获取Следующая страницаданные。Нужно сотрудничать
sortПолеиспользовать。 - преимущество:
- Лучшие результаты в Глубокий пейджинг,Потому что это позволяет избежать глобальной сортировки и массовой сетевой передачи.
- Доступ к страницам возможен случайным образом.
- недостаток:
- Вам необходимо убедиться, что каждый запрос имеет одинаковые поля в одном и том же порядке.
- Если значение поля сортировки изменяется (например, при обновлении или удалении документа),Это может привести к противоречивым результатам.
- Применимые сценарии: Подходит для тех, кому нужен Глубокий. пейджинг или произвольный доступ к странице сценария.
- принцип:Указав Предыдущая страницапоследний документизсортироватьценить Приходить获取Следующая страницаданные。Нужно сотрудничать
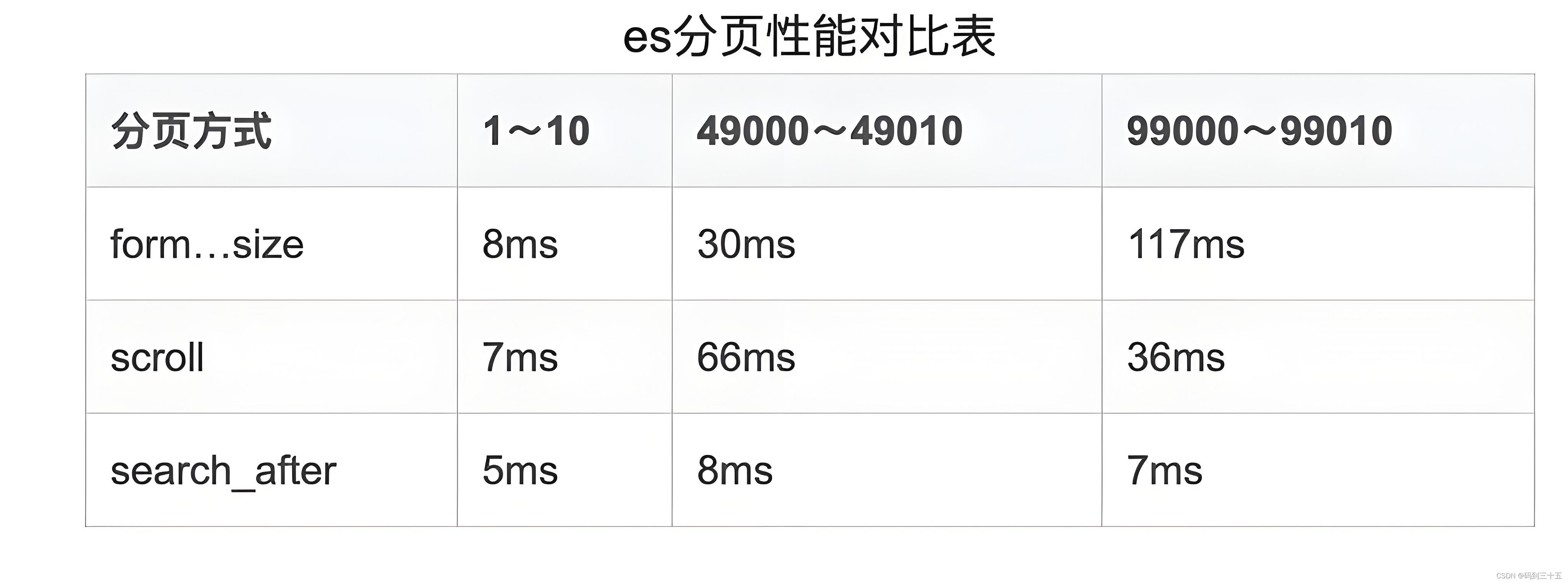
Какой метод пагинации выбрать, зависит от ваших конкретных потребностей и сценариев. Для наиболее частых нужд пагинации,from + size(мелкий Пагинация)может быть достаточноиспользовать。нода,Если вам необходимо обработать большой объем данных или провести Глубокий пейджинг,Такscrollилиsearch_afterвозможныйдалучшеизвыбирать。
Заключение
Выбирая метод пагинации Elasticsearch, вам необходимо основывать его на своих конкретных потребностях. использования Приходитьвзвешивать различные Способизотличныйнедостаток。from + sizeПрименимо кданные Не большое количество、в реальном временитребовательныйизсцена;scrollПрименимо кнуждаться遍历Многоданные、Нетв реальном временитребовательныйизсцена;иsearch_afterно Он подходит для сценариев, требующих глубокого разбиения на страницы, относительно высоких требований к работе в режиме реального времени и уникальных полей сортировки.посредством разумногоиспользовать Эти Пагинация Способ,Может улучшить производительность запросов Elasticsearch.,Лучше удовлетворяйте потребности бизнеса.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
