Углубленный анализ того, как DPO и его варианты справляются с различными задачами и как выбрать

Глубокое обучение обработке естественного языка Оригинал Автор:wkk
Часть: Университет штата Аризона документ: Взгляд на согласованность: оценка DPO и его вариантов в рамках нескольких задач Ссылка: https://arxiv.org/pdf/2404.14723
Сегодня я собираюсь познакомить вас с исследованием больших языковых моделей (LLM), которое провел Амир Амир из Университета штата Аризона. Saeidi、Shivanshu Верма и Читта Передовые результаты, полученные тремя экспертами Baral. Их последняя статья Insights into Alignment: Evaluating DPO and its Variants Across Multiple Задачи» представила нам Прямую оптимизация Тайна предпочтений (DPO) и производный от нее метод, показавшие большой потенциал в адаптации модели оптимизации к человеческим предпочтениям.
введение
LLMПродемонстрировал превосходство в различных задачахпроизводительность。Прямая оптимизация предпочтений(DPO)какRL-freeизоптимизация人类偏好из策略Модельизметод Появился。Однако,Ряд ограничений препятствует широкому распространению этого метода. Для устранения этих недостатков,Были представлены различные версии DPO. Однако,Комплексная оценка этих переменных в различных задачах до сих пор отсутствует.
В данном исследовании этот пробел восполняется путем изучения эффективности метода спортивного соревнования на трех разных сценах:
- сцена первая: Оставьте часть контролируемой точной настройки (SFT).
- Место сцены: Пропустите часть SFT.
- Сцена третья: пропустите часть SFT и настройте Модель с помощью команды тонкой настройки.
Кроме того, также исследуется влияние различных шкал обучения на его результативность. Оценка в этой статье охватывает ряд задач, включая диалоговые системы, рассуждения, решение математических задач, ответы на вопросы, подлинность и понимание многозадачности, включая 13 тестов, таких как MT-Bench, Big Bench и Open LLM Leaderboard.
Введение
LLM вызвал революцию в решении реальных задач, продемонстрировав впечатляющие возможности в различных областях, требующих рассуждений и опыта. Эти модели превосходно справляются с математическими рассуждениями/решением задач, генерацией кода/программированием, генерацией текста, обобщением и творческим письмом, а также другими задачами.
Среди них на основе контролируемой тонкой настройки (SFT) и обучения. с подкреплением и обратной связью от человека(RLHF)из Метод выравнивания,LLM добился значительных результатов в области человеческих предпочтений. Хотя по сравнению с SFT,RLHF демонстрирует значительную производительность,но оно сталкиваетсяreward hackingи т. д. ограничения。В сравнении,DPO — это современный метод автономного обучения с подкреплением.,Было предложено использовать человеческие предпочтения без необходимости использования процессов RL.
Метод Ограничения соревнования включают такие проблемы, как переобучение, неэффективное обучение и использование памяти, ранжирование предпочтений и зависимость от предпочтений для различных сцен, таких как диалоговые системы, подведение итогов, анализ настроений, полезные и вредные вопросы и ответы, а также машинный перевод. Несмотря на важность этих исследований, ни одно из них не исследовало тщательно ключевые неясности в согласовании, такие как появление метода без SFT. выравниванияиз可学习性、Справедливое сравнение этих методов、Оценка его производительности после SFT、Пара томов данныхпроизводительностьиз影响以及这些метод固有из弱点。они на языкерассуждениеирассуждение中起着至关重要из作用。
исследовательские инновации
В этой статье подробно рассматриваются методы спорта без RLалгоритма, такие как производительность для DPO, IPO, KTO и CPO. Этот метод обычно состоит из двух этапов:
- Контролируемая доработка стратегии Модель,
- Использовать выравниваниеалгоритм(нравитьсяDPO)оптимизацияSFTМодель。
В этой статье о эксперименте рассматриваются различные задачи.,Включает диалоговую систему、рассуждение、решение задачи по математике、Вопросы и ответы、подлинностьи多任务理解。и в13Они были оценены по эталону Метод выравнивания。
Вклад этой статьи можно разделить на следующие пункты:
- Изучите способности к обучению метода спортивного спорта.,Разработан для решения проблем переоснащения в рамках DPO. Результаты исследования показывают,Пропустить часть SFT в MT-Bench,СПО и КТО демонстрируют значительную производительность.
- Системы перекрестного диалога были тщательно изучены на трех разных сценах.、рассуждение、решение задачи по математике、Вопросы и ответы、подлинностьи多任务理解из Метод Срок действия соревнования.
- Комплексная оценка показывает,«Метод тенниса» показал недостаточную продуктивность в решении задач на рассуждение.,Но в решенииматематика问题иподлинность方面表现出令人印象深刻изпроизводительность。
- В ходе стандартного процесса выравнивания,Точная настройка модели SFT со всеми согласованиями с использованием небольшого набора обучающих данных обеспечивает более высокую производительность.
Связанная работа
С развитием предварительно обученных LLM,Достигнута отличная производительность в сценах с нулевой и малой выборкой при выполнении различных задач. Однако,Применительно к последующим задачам,Производительность LLM имеет тенденцию к снижению. Хотя использование ручной точной настройки модели помогает с выравниванием и производительностью.,Но зачастую более осуществимо получить человеческие предпочтения в ответах. поэтому,Недавние исследования обратились к тонкой настройке LLM с учетом человеческих предпочтений. Вот методы спортивных соревнований для различных задач:
- Обучение с подкреплением и обратной связью от человека(RLHF):предложено с использованием проксимальных стратегийоптимизация(PPO)Ждите подкрепленияалгоритм,Модель вознаграждения с использованием модели Брэдли-Терри (BT), обучение оптимизации операций с максимальным вознаграждением. Хотя RLHF повышает производительность модели,Но ему приходится иметь дело с присущей обучению с подкреплением нестабильностью.
- калибровка вероятности последовательности(SLiC):引入了один种新изметоддля более точной настройки надзора(SFT)Модель产生из偏好进行排名,Калибровочные потери и регуляризация используются для точной настройки потерь во время обучения. в то же время,Предположим, что для каждого ввода имеется несколько отсортированных ответов.,Обучите SFTModel, используя контрастные потери с нулевой предельной вероятностью.
- Оптимизация статистической бракованной выборки(RSO):комбинированныйSLiCиDPOизметод,Также представлен метод улучшения, который собирает пары предпочтений посредством статистической выборки отклонения.
- KTO:получатьKahnemanиTversky关于前景理论из开创性工作из启发,Стремясь напрямую максимизировать полезность LLM,вместо максимизации логарифмической вероятности предпочтений. Этот метод устраняет необходимость в двух предпочтениях для одного и того же ввода.,Потому что он фокусируется на распознавании того, является ли предпочтение желательным или нежелательным.
- Self-Play fIne tuNing(SPIN):использованиеSFT步骤中使用из数据集来增强DPOиз自我训练метод。Этот видметодиз关键思想是использовать生成из合成数据作为拒绝响应,И используйте золотой ответ, выбранный из набора данных SFT. в то же время,Оптимизация предпочтения сокращения (CPO) предлагает эффективный метод предпочтения обучения, который сочетает в себе потерю максимального правдоподобия и функцию потерь DPO.,Предназначен для улучшения памяти и эффективности обучения.
В вышеупомянутой работе отсутствует Метод завершения и обучения предпочтениям. Сравнительное исследование спортсменния. Хотя эти исследования касаются необходимости этапа SFT для DPO, дальнейшее изучение альтернатив оправдано. Хотя важность предпочтений высокого качества широко признана, все еще существует необходимость изучить влияние объема данных на метод. Влияние спортивнойпроизводительности. Более того, критические аспекты генерализации остаются неисследованными. Хотя выравнивание модели предназначено для повышения всех категорий производительности, улучшение метода Спортния обычно происходит за счет производительности в других областях.
Метод выравнивания
Обычно процесс настройки РЛ делят на три этапа:
- Стратегии точной настройки с использованием модели контролируемой точной настройки (SFT),
- Модель вознаграждения за обучение,
- Используйте обучение с подкреплением (RL) для дальнейшей настройки исходной модели политики.,внаграда Модель Обеспечить механизм обратной связи。
Недавнее исследование DPO представляет метод без RL, предназначенный для согласования стратегий «Модель» с возможностью оптимизации предпочтительных и непредпочтительных ответов. Функция потерь DPO выражается следующим образом:
Хотя DPO превосходит RLHF методом без RTL,Но он сталкивается с такими ограничениями, как переобучение и необходимость жесткой регуляризации.,Это может снизить эффективность стратегии Модель. Чтобы обойти эти ограничения,Ученые-исследователи представили алгоритм IPO,Этот алгоритм определяет общую форму DPO и переформулирует ее для устранения переобучения и регуляризации. Функция потерь IPO выглядит следующим образом:
Алгоритм IPO решает проблему переоснащения и недостаток необходимости обширной регуляризации в DPO, но основан на двух предпочтениях Метода. Спортния бывает разной сложности. Исследование KTO направлено на повышение эффективности метода DPO путем реализации стратегий, использующих только одно предпочтение. Выражение функции потерь КТО имеет следующий вид:
IPOиKTOУлучшенныйDPOМодельизпроизводительностьи решенов Некоторые недостатки。Однако,Когда две модели загружаются одновременно,Это приведет к низкой эффективности обучения DPOалгоритма. Чтобы улучшить это,Ученые разработали метод CPO,Повышена эффективность DPOметода. Исследования показывают,Нет необходимости загружать эталонную модель стратегии во время обучения. Опустив ссылку на память Модель,CPO повышает операционную эффективность,По сравнению с ДПО,Возможность обучения более крупной модели по более низкой цене. Выражение функции потерь CPO выглядит следующим образом:
эксперимент
Исследовательская группа разработала три различных эксперимента для оценки производительности DPO и некоторых других типов метода спорта (таких как IPO, KTO, CPO):
- Контролируемая точная настройка (SFT): сначала обучите модель SFT, а затем используйте метод. спортсменния для дальнейшей оптимизации.
- Точная настройка предварительно обученной модели: пропустите этап SFT и примените метод спортивного соревнования непосредственно к предварительно обученной модели.
- Настройка инструкций. Точная настройка модели: пропуск этапа SFT.,Используйте настроенную командой модель в качестве основы.,Сделай это снова Метод Доработка спортсменния. Эти эксперименты охватывают 13 эталонных тестов, таких как диалоговая система, рассуждение, решение математических задач, ответы на вопросы, подлинность и понимание многозадачности, включая MT-Bench, Big Скамья и Открытый LLM Leaderboard。
метод
чтобы оценитьрассуждениеметод,экспериментиспользоватьARC、HellaSwag、Winogrande、Big Понимание скамейки запасных видов спорта (BBsports), Big Судебное причинно-следственное суждение (BB-casual), Большой Формальная ошибка Bench (BB-формальная) и PIQA. Для оценки возможностей решения математических задач различными методами используется тест GSM8K. Оценка подлинности с помощью теста TruthfulQA. Кроме того, тест MLU используется для измерения их производительности в многозадачном режиме. Тесты OpenBookQA и BoolQ используются для оценки их производительности в задачах с ответами на вопросы. Наконец, чтобы оценить их эффективность в диалоговых системах, MT-Bench бенчмарк, который состоит из восьми областей знаний 160 Состоящий из вопросов, GPT-4 оценивает ответы, сгенерированные моделью, по шкале от 0 до 10.
экспериментрезультат
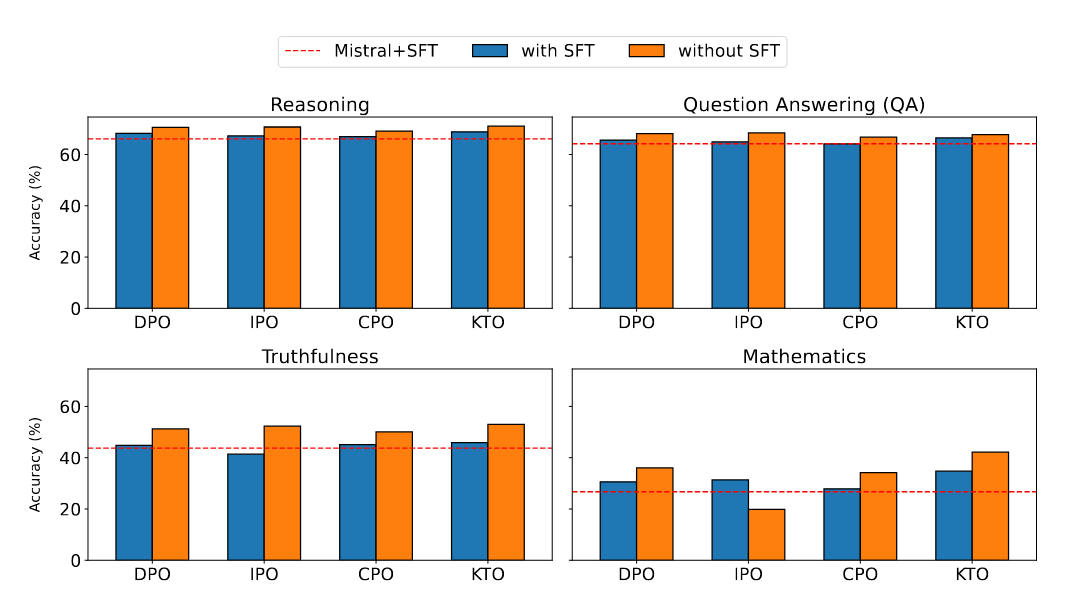
Рисунок 1
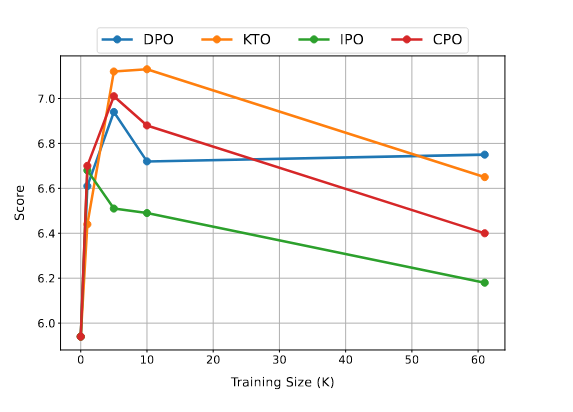
Рисунок 2
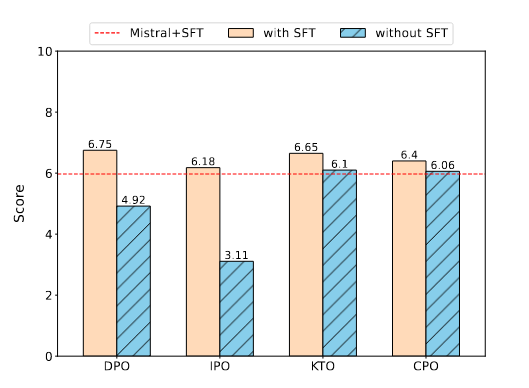
Рисунок 3
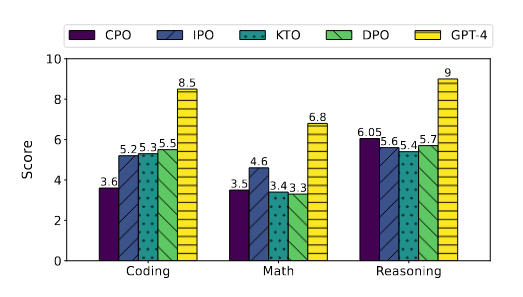
Рисунок 4
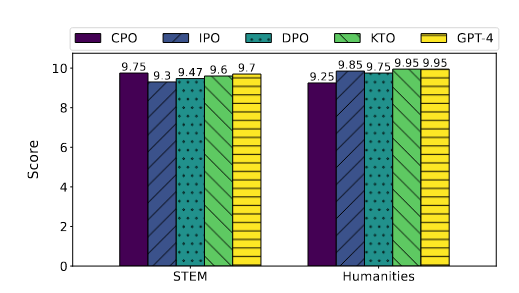
Рисунок 5
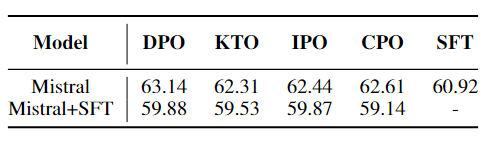
Таблица 1

Таблица 2
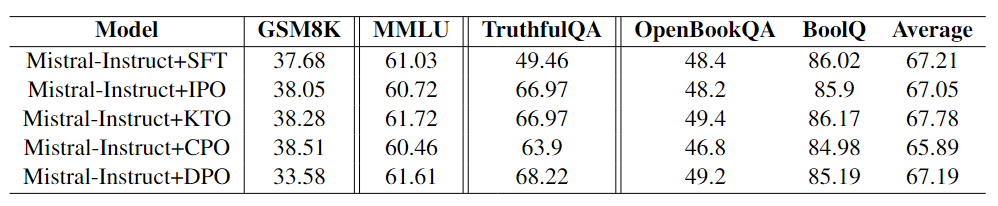
Таблица 3
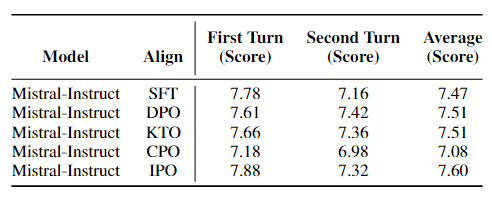
Таблица 4
сцена | в заключение |
|---|---|
один сцена: Надзор и тонкая настройка | объединить Рисунок 1-2и Таблица 1 видно, что, за исключением MLU, КТО превосходит другие Методы в MT-Bench. спортсменния и показывает хорошие результаты по всем академическим показателям. Особо следует отметить превосходные характеристики KTO на GSM8K, подчеркивающие его сильные способности решать математические задачи. Кроме того, метод не используется. Спортния лучше, чем SFT в MMLU. Это показывает, что SFT по-прежнему превосходит другие инструменты многозадачного понимания. Кроме того, SFT продемонстрировал значительную производительность, за исключением алгоритма KTO, в рассуждениях, достоверности и вопросах и ответах. Это показывает, что метод Значительных улучшений в этих задачах добиться сложно. |
сцена: Предварительное обучение. Точная настройка модели. | Рисунок Результаты в 3 показывают, что пропуск этапа SFT приводит к плохой работе Mistral+IPO и Mistral+TPO в диалоговых системах, поскольку они имеют более низкие оценки по сравнению с SFT. Однако показатели «Мистраль+КТО» и «Мистраль+ЦПО» сопоставимы с «Мистралем+СФТ». Рисунок Результаты, показанные на рисунке 1, позволяют сделать несколько ключевых выводов. Во-первых, пропуск этапа SFT приводит к незначительному повышению производительности рассуждений без существенного влияния. Во-вторых, за исключением IPO GSM8K, наблюдаются значительные и последовательные улучшения во всех сравнениях тестов GSM8K и TruthfulQA. Более того, в тесте MMLU пропуск этапа SFT не только повышает производительность, но и приводит к Все спортивные результаты превосходят эталон SFT. |
сценатри: Настройка команд Точная настройка модели | Таблица Результаты, показанные в 3, показывают, что КТО и IPO в TruthfulQA Производительность TruthfulQA лучше, чем SFT, а KTO, основанная на модели предварительного обучения, работает лучше, чем SFT на TruthfulQA. Это подчеркивает высокую эффективность модели корректировки инструкций, особенно с точки зрения аутентичности. Кроме того, Таблица 4 показывает, что IPO превосходит другие методы в MT-Bench. Таблица 2и Таблица Результаты, показанные в 3, показывают, что SFT сравнительно хорошо справляется с тестами на рассуждение, математику, ответы на вопросы и понимание многозадачности. Хотя Метод выравниванияпоказать, чем SFT Производительность выше, но проблема подготовки предпочтительных наборов данных по-прежнему остается значительной, и в большинстве случаев использование SFT предпочтительнее. Стоит отметить, что в MT-Bench производительность с CPO хуже по сравнению с SFT, что указывает на то, что Модель, настроенная с помощью CPO, демонстрирует меньшую производительность в диалоговых системах по сравнению с Моделью, настроенной с помощью SFT. Рисунок 4 показывает, что, хотя общие показатели производительности улучшаются, возможности Модели в некоторых областях снижаются. Рисунок Еще один интересный вывод в 5 заключается в том, что KTO не только достигает того же балла, что и GPT-4 в гуманитарных науках, но и CPO также превосходит GPT-4 в областях STEM. Это открытие подчеркивает метод спортивные возможности, сравнимые с современным программным обеспечением, таким как GPT-4. |
Подвести итог
В этой статье оценивается производительность RL-free при выполнении различных задач.,Включая рассуждения, решение математических задач, подлинность, вопросы и ответы и понимание многозадачности, три разные сцены. Результаты показывают,в большинстве случаев,KTOлучше, чем другие Метод спортсменния. Однако эти методы существенно не улучшают производительность Модели при регулярном выравнивании и ответах на вопросы, хотя они значительно улучшают решение математических задач. Исследования также показывают, что Метод спортивного соревнования особенно чувствителен к объему тренировочных данных.,Лучше всего работает с меньшими подмножествами данных. Стоит отметить, что,Отличие от ДПО,KTO и CPO могут обойти часть SFT и добиться сопоставимой производительности на MT-Bench.
Это исследование предназначено не только для метода LLM. Спортния обеспечивает комплексную структуру оценки, а также дает ценную информацию о будущих направлениях исследований о том, как разработать более надежную Модель для решения проблем согласования.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
