Углубленный анализ принципов хранения данных MongoDB.
MongoDB, как популярная база данных NoSQL, получила широкое внимание благодаря своей модели документа, горизонтальной масштабируемости и превосходной производительности. В этом подробном техническом блоге мы углубимся в принципы хранения данных MongoDB, включая такие ключевые аспекты, как модель данных, формат хранения, механизм хранения, механизм сегментирования, стратегия индексации и высокая доступность.
1. Модель данных и формат BSON.
Модель данных MongoDB основана на документах.,Это структура данных, состоящая из пар ключ-значение.,Похоже на:JSON。Каждый документ имеет уникальный_idПоле как первичный ключ,Используется для уникальной идентификации документа в коллекции. Документы могут быть вложенными.,Эта гибкая структура данных делает MongoDB идеальным хранилищем полуструктурированных данных.
На уровне хранилища MongoDB использует формат BSON (двоичный JSON) для сериализации документов. BSON — это двоичное представление, которое расширяет функциональность JSON, поддерживает больше типов данных и является более эффективным. Формат BSON позволяет передавать документы непосредственно в двоичной форме по сети, сокращая накладные расходы на сериализацию и десериализацию и тем самым повышая эффективность передачи данных.
2. Механизм хранения данных
Принцип хранения MongoDB тесно связан с используемым механизмом хранения. Начиная с версии MongoDB 3.2, WiredTiger стал механизмом хранения по умолчанию. WiredTiger — это высокопроизводительный механизм хранения с поддержкой транзакций, который сочетает в себе преимущества индексов B-дерева и деревьев LSM (дерево слияния с лог-структурой), обеспечивая MongoDB превосходную производительность чтения и записи.
В частности, WiredTiger обеспечивает быстрый поиск данных через структуру индекса B-дерева. В то же время он использует принцип проектирования дерева LSM, чтобы сначала записать данные в структуру данных (MemTable) в памяти, а затем в соответствующее время объединить данные в постоянное хранилище на диске. Такая конструкция позволяет WiredTiger эффективно обрабатывать большое количество операций записи и особенно подходит для сценариев приложений, требующих высокой производительности записи.
3. Шардинг данных и кластерная архитектура
Для поддержки хранения и запроса больших объемов данных MongoDB использует технологию сегментирования. Шардинг — это процесс горизонтального разделения данных на несколько серверных узлов, при этом каждый узел хранит подмножество набора данных. Эта архитектура позволяет MongoDB масштабироваться горизонтально и преодолевать ограничения хранилища на одной машине.
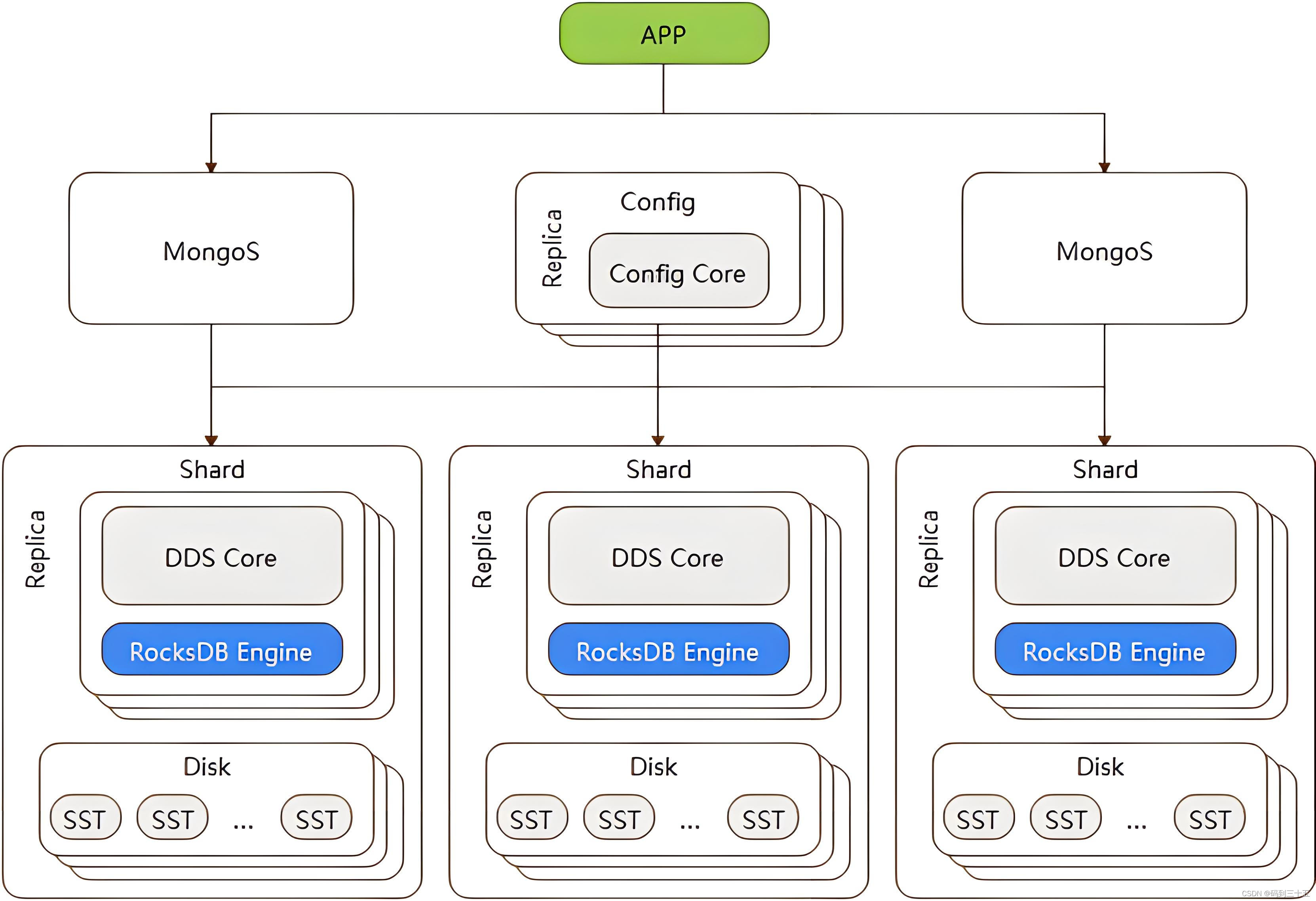
В кластерной архитектуре MongoDB имеется несколько ключевых компонентов: шард-сервер, сервер конфигурации и маршрутизатор запросов (mongos). Сервер сегментов отвечает за хранение фактических сегментов данных, сервер конфигурации хранит метаданные кластера, а маршрутизатор запросов действует как посредник между клиентом и сервером сегментов, отвечающий за маршрутизацию запроса клиента на правильный сервер сегментов. .
4. Индексная стратегия и оптимизация
Индексы играют ключевую роль в повышении производительности запросов к базе данных. MongoDB поддерживает несколько типов индексов, включая индексы с одним ключом, составные индексы, полнотекстовые индексы и т. д., для удовлетворения различных потребностей запросов. Эти индексы создаются с использованием структур данных, таких как B-деревья, для обеспечения эффективной производительности запросов.
При создании индекса MongoDB выберет подходящий тип индекса в зависимости от распределения данных и режима запроса. Например, для полей, которые часто используются в условиях запроса, вы можете создать индексы с одним ключом, чтобы повысить скорость запроса. Для условий запроса, которые должны соответствовать нескольким полям одновременно, вы можете использовать составные индексы для оптимизации производительности.
Кроме того, MongoDB также предоставляет некоторые предложения по оптимизации индексов, например, избегать создания слишком большого количества индексов для уменьшения использования пространства хранения и накладных расходов на операции записи, а также регулярно переоценивать и корректировать индексы для адаптации к изменениям данных.
5. Высокая доступность и репликация данных
Чтобы обеспечить доступность и долговечность данных, MongoDB использует наборы реплик для достижения высокой доступности данных. Набор реплик состоит из набора экземпляров MongoDB с одним и тем же набором данных, включая основной узел и несколько вторичных узлов. Первичный узел отвечает за обработку запросов на запись и синхронизацию изменений данных со вторичным узлом. Вторичный узел используется для обработки запросов на чтение и обеспечения резервного копирования данных.
При выходе из строя основного узла MongoDB автоматически запускает механизм аварийного переключения и выбирает новый основной узел, который возьмет на себя его работу. Такая конструкция обеспечивает доступность и надежность данных, а также снижает риск возникновения единых точек отказа. В то же время MongoDB также поддерживает функции автоматического резервного копирования и восстановления данных для дальнейшего повышения надежности данных.
6. Заключение
Принципы хранения MongoDB включают в себя множество аспектов, в том числе гибкую модель данных, эффективный формат BSON, мощный механизм хранения, масштабируемый механизм сегментирования, оптимизированную стратегию индексации и дизайн с высокой доступностью. В совокупности эти функции обеспечивают MongoDB превосходную производительность и масштабируемость, что позволяет ей хорошо работать в различных сценариях приложений.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
