Углубленный анализ основных компонентов экосистемы Hadoop: HDFS, MapReduce и YARN.
Статья, объясняющая три основных компонента экосистемы Hadoop.
Выход на этап больших данных означает переход на этап NoSQL, который больше ориентирован на сценарии OLAP, то есть хранилища данных, BI-приложения и т. д. Развитие технологий больших данных не случайно. Централизованные базы данных или распределенные базы данных, основанные на архитектуре MPP, часто используют стабильные, но дорогие миникомпьютеры, компьютеры «все в одном» или P Серверы C и т. д. имеют относительно плохую масштабируемость, в то время как среда вычислений больших данных может быть построена на основе недорогих обычных аппаратных серверов и теоретически поддерживает неограниченное расширение для поддержки сервисов приложений.
Наиболее известной в области больших данных является экосистема Hadoop. В целом она в основном состоит из трех частей: базовой системы хранения файлов HDFS (Hadoop Distributed File System, Распределенная файловая система Hadoop) и платформы планирования ресурсов и вычислений Yarn. (Еще один переговорщик ресурсов, еще один координатор ресурсов) и компоненты приложений верхнего уровня на основе HDFS и Yarn, такие как HBase, Hive и т. д. Типичное приложение на базе Hadoop показано на рисунке ниже.
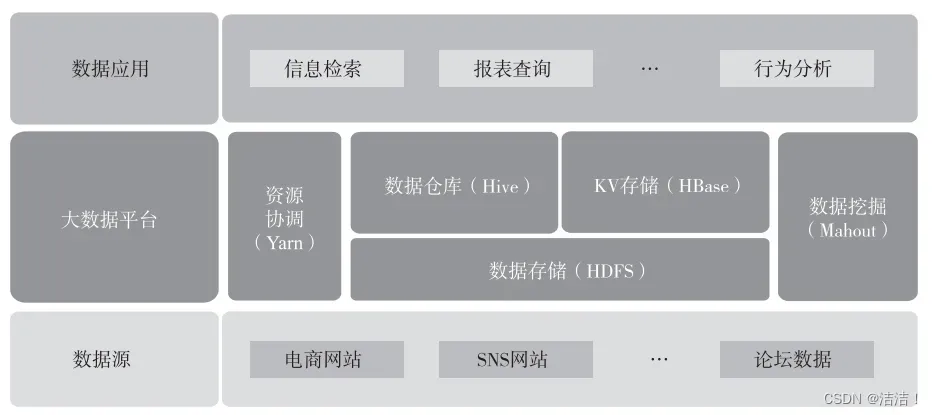
Типичное приложение Hadoop
01HDFS
HDFS спроектирована как распределенная файловая система, подходящая для работы на обычном оборудовании. Она имеет много общего с существующими распределенными файловыми системами, например, с типичной архитектурой Master-Slave (которая здесь не будет представлена). Она также имеет отличия. HDFS является высокоотказоустойчивой системой и подходит для развертывания на дешевых машинах. Что касается HDFS, я хочу отметить два основных момента: настройку количества реплик по умолчанию и Rack Awareness.
Число копий HDFS по умолчанию — 3. Это связано с тем, что Hadoop обладает высокой отказоустойчивостью. С точки зрения избыточности и распределения данных данные необходимо хранить в разных шкафах в одном компьютерном зале и в разных центрах обработки данных, чтобы обеспечить максимальный объем данных. доступность. Следовательно, для достижения вышеуказанной цели блоки данных необходимо хранить как минимум на разных стойках в одном компьютерном зале (2 копии) и в стойке по всему дата-центру (1 копия), всего 3 копии. данных.
Целью осведомленности о стойках является попытка обеспечить возможность связи между различными вычислительными узлами внутри одной стойки, а не между стойками, тем самым уменьшая передачу данных между различными сетями в распределенных вычислениях и уменьшая потребление ресурсов пропускной способности сети. Например, когда чтение данных происходит в кластере, клиент определяет, какой узел данных отправляет данные клиенту в порядке приоритета от ближнего к дальнему, поскольку в распределенной среде сетевой ввод-вывод стал основным узким местом производительности.
Только глубоко поняв эти два момента, мы сможем понять, почему Hadoop обладает высокой отказоустойчивостью. Высокая отказоустойчивость является основой для работы Hadoop на оборудовании общего назначения.
02Yarn
Yarn — еще один подпроект Hadoop после Common, HDFS и MapReduce. Он был предложен в MapReduceV2.
В Hadoop1.0 JobTracker состоит из двух частей: диспетчера ресурсов (реализуемого модулем TaskScheduler) и управления заданиями (реализуемого несколькими модулями в JobTracker).
В Hadoop 1.0 JobTracker не отделял функции, связанные с управлением ресурсами, от функций, связанных с приложениями, и постепенно стал узким местом кластера, что, в свою очередь, привело к плохой масштабируемости, снижению использования ресурсов и недостаточной поддержке нескольких платформ в кластере. проблема.
В MapReduceV2 Yarn отвечает за управление ресурсами (памятью, процессором и т. д.) в MapReduce и их упаковку в контейнеры. Это позволяет MapReduce сосредоточиться на задачах обработки данных, с которыми он хорошо справляется, не беспокоясь о планировании ресурсов. Эта слабосвязанная архитектура обеспечивает гибкость всей платформы Hadoop.
03Hive
Hive — это инфраструктура хранилища данных, основанная на Hadoop. Она использует простые операторы SQL (сокращенно HQL) для запроса и анализа данных, хранящихся в HDFS, а также преобразует операторы SQL в программы MapReduce для обработки данных. Основные различия между Hive и традиционными реляционными базами данных отражены в следующих моментах.
1) Место хранения. Данные Hive хранятся в HDFS или HBase, причем последние данные обычно хранятся на необработанных устройствах или в локальных файловых системах. Поскольку Hive построен на HDFS, он опирается на отказоустойчивую функцию таблиц данных HDFS. естественно избыточно.
2) Обновление базы данных. Hive не поддерживает обновления. Обычно он записывается один раз, а читается и записывается несколько раз (эта часть начинает поддерживать транзакционные операции после Hive 0.14, но существует множество ограничений, поскольку Hive основан на HDFS). в качестве базового хранилища. Чтение и запись HDFS не поддерживает функции транзакций, поэтому поддержка транзакций Hive должна разделять файлы данных и файлы журналов для поддержки функций транзакций.
3) Задержка выполнения SQL. Задержка Hive относительно высока, поскольку каждое выполнение требует анализа оператора SQL в программе MapReduce.
4) По масштабу данных Hive обычно находится на уровне TB, тогда как последний относительно невелик.
5) Что касается масштабируемости, Hive поддерживает UDF, UDAF и UDTF, причем последний имеет относительно плохую масштабируемость.
04HBase
HBase (база данных Hadoop) — это высоконадежная, высокопроизводительная, столбцово-ориентированная, масштабируемая распределенная система хранения. Его базовая файловая система использует HDFS, а ZooKeeper используется для управления связью между HMaster кластера и каждым сервером региона, мониторинга состояния каждого сервера региона и хранения адреса входа каждого региона.
1. Функции
HBase — это база данных в форме «ключ-значение» (аналог Map в Java). Поскольку это база данных, в ней должны быть таблицы. Таблицы в HBase, вероятно, имеют следующие характеристики.
1) Большой: таблица может иметь сотни миллионов строк и миллионы столбцов (при наличии большого количества столбцов вставка замедляется).
2) Ориентация на столбцы: управление хранением и разрешениями на основе столбцов (семейств), независимый поиск по столбцам (семействам).
3) Разреженность: пустые (нулевые) столбцы не занимают места для хранения, поэтому таблицу можно сделать очень разреженной.
4) Данные в каждой ячейке могут иметь несколько версий. По умолчанию номер версии назначается автоматически и является меткой времени при вставке ячейки.
5) Все данные в HBase представляют собой байты, и не существует конкретного объекта данных, определенного по типу (поскольку системе необходимо адаптироваться к различным типам форматов данных и источникам данных, схема не может быть строго определена заранее).
Здесь следует отметить, что HBase также основан на HDFS, поэтому он также имеет характеристики трех копий по умолчанию и избыточности данных. Кроме того, HBase также использует характеристики WAL для обеспечения согласованности чтения и записи данных.
2. хранилище
HBase использует столбчатое хранилище для хранения данных. Традиционные реляционные базы данных в основном используют хранилище строк для хранения данных. Характеристика чтения данных заключается в чтении записей данных с диска в соответствии с степенью детализации строк, а затем их обработке в соответствии с фактически необходимыми данными полей. число большое, но требуется обрабатывать меньше полей (особенно в сценариях агрегации). Из-за основного принципа хранения строк данные по-прежнему необходимо запрашивать в строках (все поля). В этом процессе дисковый ввод-вывод, требования к памяти и сетевой ввод-вывод, генерируемые приложением, вызовут определенное количество отходов; метод чтения данных из хранилища столбцов в основном считывает данные в соответствии с детализацией столбца. Подход к чтению по требованию снижает дисковый ввод-вывод, требования к памяти и сетевой ввод-вывод, выполняемый приложениями при запросе данных.
Кроме того, поскольку данные одного и того же типа хранятся единообразно, выбор и эффективность алгоритмов сжатия будут дополнительно улучшены в процессе сжатия данных, что еще больше снижает требования к ресурсам в распределенных вычислениях.
Метод столбчатого хранения больше подходит для сценариев приложений OLAP, поскольку этот тип сценария имеет характеристики большого объема данных и небольшого количества полей запроса (часто агрегатных функций). Например, недавно популярный ClickHouse также использует столбчатое хранилище для хранения данных.
05Sparkи Потоковое вещание Spark
Spark был разработан и открыт Twitter для решения проблемы анализа массивных потоков данных. Spark сначала импортирует данные в кластер Spark, затем быстро сканирует данные с помощью управления на основе памяти и использует итерационные алгоритмы для минимизации глобальных операций ввода-вывода для повышения общей производительности обработки. Это похоже на идею реализации Hadoop по поиску «данных» из «вычислений» и обычно подходит для сценариев, в которых несколько запросов и анализов записываются один раз.
Spark Streaming — это платформа потоковых вычислений, основанная на Spark. Она обрабатывает и контролирует данные в реальном времени, а также может записывать результаты вычислений в HDFS. Он похож на популярную платформу вычислений в реальном времени Flink, но они существенно отличаются, поскольку Spark Streaming обрабатывает данные на основе микропакетов, а не построчно.
Об авторе:
Ли Ян, старший архитектор данных, имеет более 10 лет опыта работы в областях, связанных с данными. Руководитель группы разработчиков торговой системы технологической платформы ведущей компании по управлению страховыми активами, отвечающий за создание, оптимизацию и миграцию множества приложений и платформ данных. Когда-то он работал техническим партнером в компании, занимающейся данными, и отвечал за работу, связанную с хранилищем данных или платформой данных, для нескольких финансовых учреждений. Автор книги «Архитектура корпоративных данных: основные элементы, модель архитектуры, управление данными и построение платформы».
Причины рекомендации:
В этой книге систематически объясняется архитектура данных уровня предприятия с точки зрения архитектуры предприятия. В ней систематически разбираются и объясняются базовые знания об архитектуре предприятия, а также теоретические знания о компонентах архитектуры данных, архитектурных моделях, управлении данными и активах данных. управление.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
