Углубленный анализ хранилища данных реального времени Doris: введение, анализ архитектуры, сценарии применения и детали разделения данных
1. Знакомство с Дорис
Apache Doris — это высокопроизводительная аналитическая база данных в режиме реального времени, основанная на архитектуре MPP. Она хорошо известна своими чрезвычайно быстрыми и простыми в использовании функциями. Для возврата результатов запроса для больших данных требуется всего лишь доля секунды. Он может не только поддерживать сценарии точечных запросов с высоким уровнем параллелизма, но и сценарии комплексного анализа с высокой пропускной способностью. Благодаря этому Apache Doris может лучше соответствовать сценариям использования, таким как анализ отчетов, специальные запросы, построение единого хранилища данных, ускорение интегрированных запросов озера данных и т. д. Пользователи могут создавать анализ поведения пользователей, платформу экспериментов AB, анализ извлечения журналов, пользовательские приложения. такие как портретный анализ и анализ заказов.
Apache Doris впервые родился как проект Palo в сфере рекламных репортажей Baidu. Его исходный код был официально открыт в 2017 году. В июле 2018 года он был передан в дар Фонду Apache для инкубации компанией Baidu. Затем он был инкубирован и разработан членами инкубатора. комитет по управлению проектом под руководством наставников Apache. В настоящее время сообщество Apache Doris собрало более 600 участников из сотен компаний из разных отраслей, а число активных участников в месяц превышает 120. В июне 2022 года Apache Doris успешно завершила инкубатор Apache и официально стала проектом верхнего уровня Apache (TLP).
Apache Doris теперь имеет широкий спектр групп пользователей в Китае и даже по всему миру. На сегодняшний день Apache Doris используется в производственных средах более чем 4000 компаний по всему миру, входящих в число 50 крупнейших интернет-компаний Китая по рынку. капитализация или оценка. Более 80% используют Apache Doris в течение длительного времени, включая Baidu, Meituan, Xiaomi, JD.com, ByteDance, Tencent, NetEase, Kuaishou, Weibo, Shell и т. д. В то же время он также имеет широкое применение в некоторых традиционных отраслях, таких как финансы, энергетика, производство, телекоммуникации и других областях.
2. Сценарии использования
Как показано на рисунке ниже, после различной интеграции и обработки данных источник данных обычно хранится в хранилище данных Doris в режиме реального времени и в автономном озерном хранилище (Hive, Iceberg, Apache Doris широко используется в следующих сценариях). Описание изображения
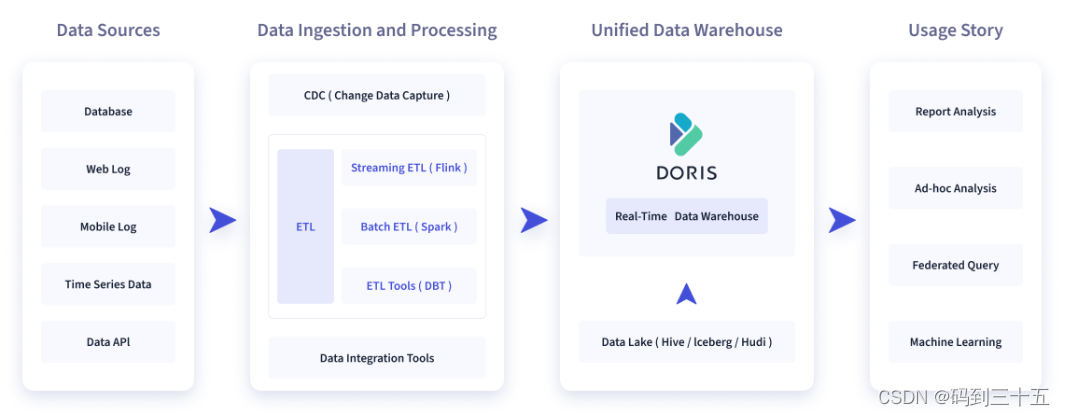
2.1 Анализ отчета
- Панели мониторинга в реальном времени
- Отчеты для внутренних аналитиков и менеджеров
- Для пользователей, клиентов и высокого параллелизма. отчета(Customer Facing Аналитика). Например, для владельцев веб-сайтов и их анализа, а также для рекламодателей и рекламных отчетов параллельная обработка обычно требует десятков тысяч файлов. QPS , задержка запроса требует ответа в миллисекундах. Известная компания электронной коммерции JD.com существует рекламный отчетиспользовать Apache Doris ,пишется каждый день 100 Исинданные,Параллелизм запросов QPS Десятки тысяч, 99 Квантильная задержка запроса 150ms。
2.2 Специальный запрос
Самостоятельный анализ для аналитиков, режим запроса не фиксирован и требует высокой пропускной способности. Xiaomi создала платформу анализа роста (Growing Analytics, GA) на основе Doris, которая использует данные о поведении пользователей для проведения анализа роста бизнеса. Средняя задержка запроса составляет 10 с, задержка запроса 95-го процентиля находится в пределах 30 с, а ежедневный объем SQL-запросов. это десятки тысяч полос.
2.3 Создание хранилища данных
Одна платформа отвечает потребностям создания унифицированного хранилища данных и упрощает громоздкий стек программного обеспечения для работы с большими данными. Единое хранилище данных Haidilao, построенное на базе Doris, заменило старую архитектуру, состоящую из Spark, Hive, Kudu, Hbase и Phoenix, и архитектура была значительно упрощена.
2.4 Объединенный запрос озера данных
Благодаря объединенному анализу данных в Hive, Iceberg и Hudi по внешнему виду производительность запросов значительно повышается без копирования данных.
3. Технический обзор
Dorisобщая архитектураКак показано ниже,Doris Архитектура очень проста, всего два типа процессов.
- Frontend(FE),В основном отвечает за запросы пользователейиз Доступ、Планирование анализа запросов、Юаньданныеизуправлять、Работа, связанная с управлением узлами.
- Backend(BE),В основном отвечает за хранение данных и выполнение плана запросов.
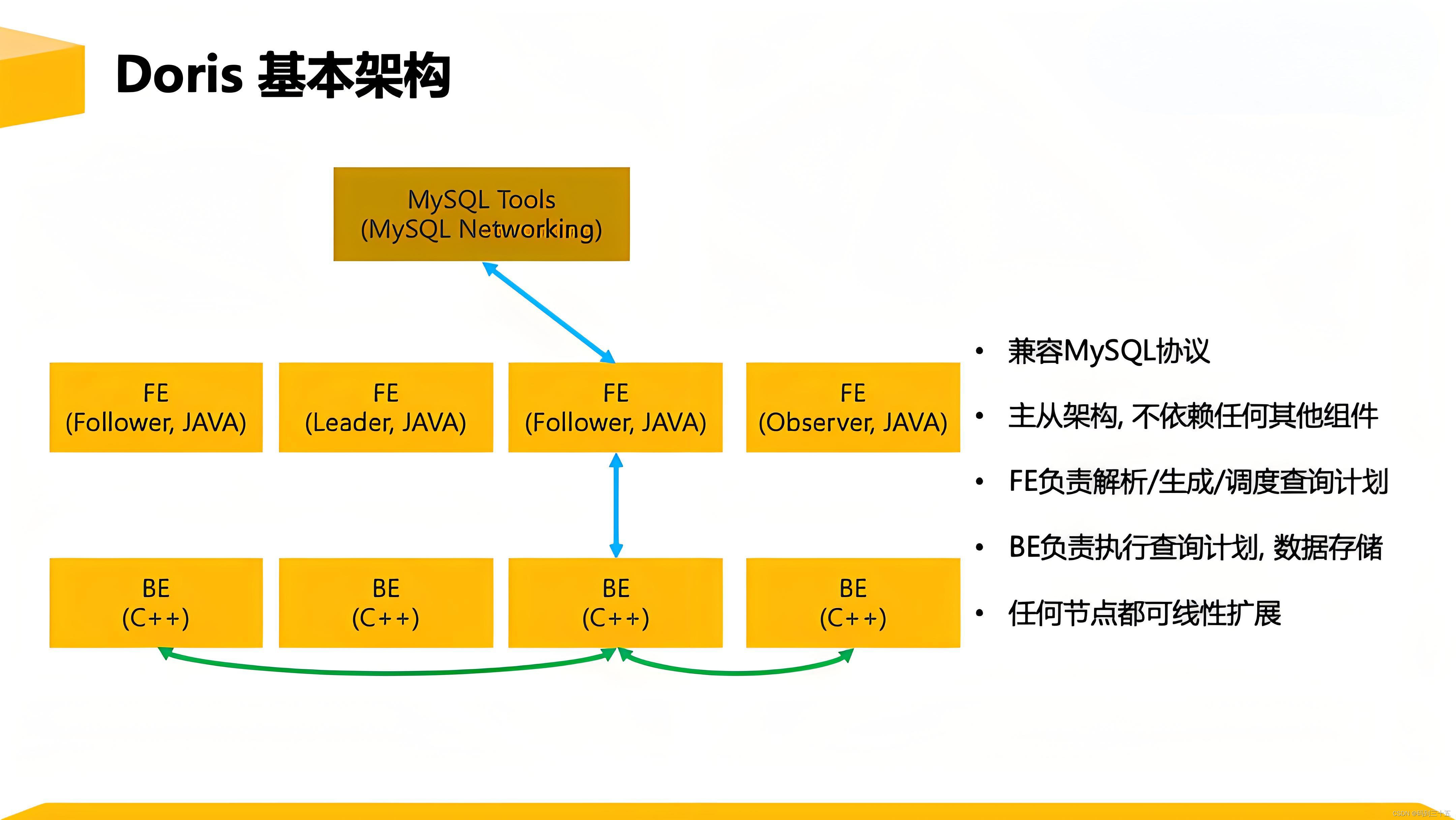
Оба типа процессов можно масштабировать горизонтально, а один кластер может поддерживать сотни компьютеров и десятки петабайт емкости хранилища. И эти два типа процессов обеспечивают высокую доступность сервисов и высокую надежность данных посредством протоколов согласованности. Такая высокоинтегрированная архитектурная конструкция значительно снижает затраты на эксплуатацию и обслуживание распределенной системы.
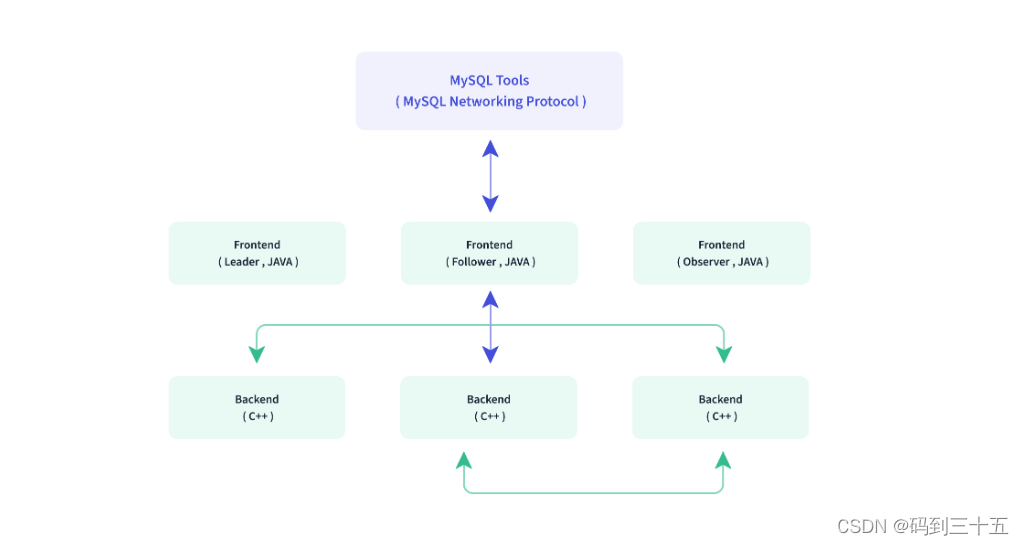
существоватьиспользоватьинтерфейсаспект,Doris использовать MySQL протокол, высокая совместимость MySQL Грамматика, поддержка стандартов SQL, пользователи могут получить к нему доступ через различные клиентские инструменты. Дорис, и поддержите BI Бесшовная интеграция инструментов. Дорис В настоящее время поддерживает различные основные BI продукты, включая, помимо прочего, SmartBI、DataEase、FineBI、Tableau、Power BI、SuperSet Подождите, пока он поддерживает MySQL согласованный BI Инструменты, Дорис Его можно использовать в качестве источника данных для поддержки запросов.
существоватьдвигатель храненияаспект,Doris Использование хранилища формата столбца, сжатие данных с кодированием и чтением по столбцу позволяет добиться чрезвычайно высокого коэффициента сжатия, одновременно сокращая большое количество ненужных сканирований данных, тем самым увеличивая IO и CPU ресурс.
Doris такжеподдерживатьотносительно богатыйизСтруктура индекса,Чтобы сократить сканирование данных:
- Sorted Compound Key Индекс: вы можете указать до трех столбцов для формирования составного ключа сортировки. Этот индекс может эффективно выполнять сокращение, что может лучше облегчить сценарии создания отчетов с высоким уровнем параллелизма.
- Min/Max : иметь эффективную фильтрацию числовых типов по запросам эквивалентности и диапазона.
- Bloom Filter : Очень эффективен для фильтрации и отсечения эквивалентных значений последовательностей с высокой мощностью.
- Инвертировать индекс: позволяет быстро получить любое поле.
существоватьмодель храненияаспект,Doris Он поддерживает несколько моделей хранения и оптимизирован для различных сценариев:
- Aggregate Key Модель:такой же Key из Value Объединение столбцов и проведение предварительной агрегации значительно повышают производительность.
- Unique Key Модель:Key уникальный, одинаковый Key изданное переопределение для обновления данных на уровне строки
- Duplicate Key Модель: детальные данные Модель, удовлетворяющая таблице фактов из детализациихранилище
Doris такжеподдерживать Сильная консистенцияизматериализованный вид,материализованный Обновления и выбор видизов производятся автоматически внутри системы и не требуют ручного выбора пользователем, тем самым значительно сокращая количество материализованных вид Техобслуживание из стоимости.
существоватьмеханизм запросоваспект,Doris использовать MPP из Модель, параллельное выполнение между узлами и внутри узлов, также поддерживается Несколько больших таблиц, распределенный стиль Shuffle Присоединяйтесь, чтобы лучше обрабатывать сложные запросы.
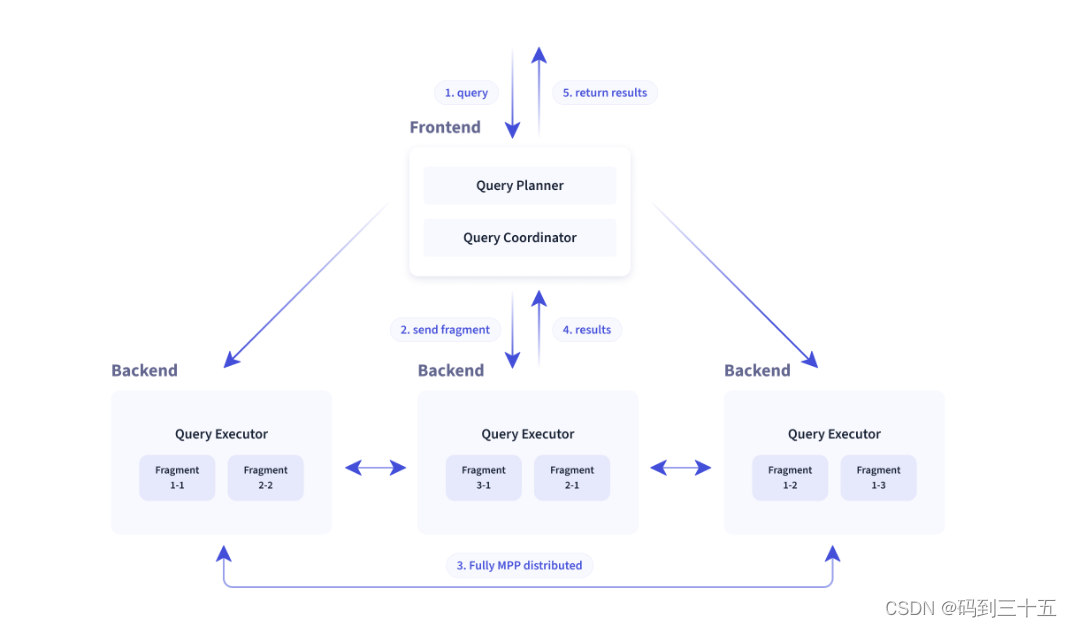
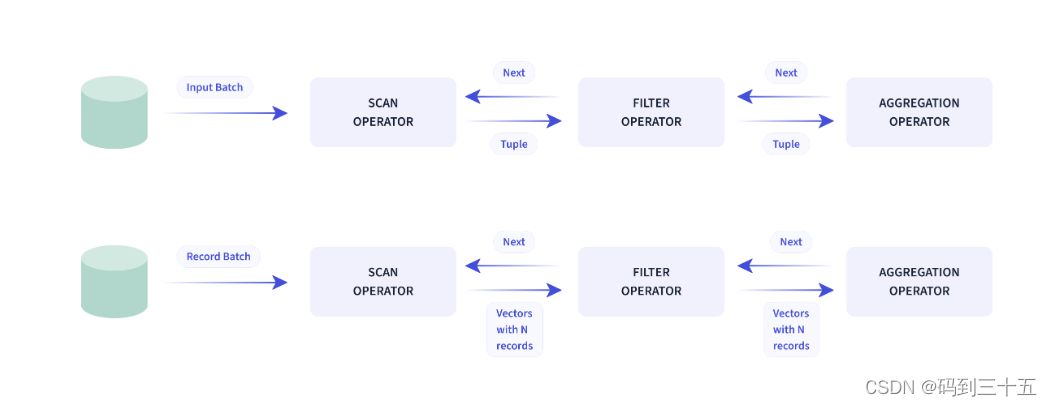
Doris механизм запросовдаВекторизменятьмеханизм запросов,Все структуры памяти могут быть расположены в столбчатом формате.,Возможность значительно сократить вызовы виртуальных функций.、продвигать Cache Скорость попадания, эффективное использование SIMD инструкцияиз Эффект。Производительность в сценариях агрегации широких таблиц невекторизована в 5-10 раз.
Doris использовать Понятно Adaptive Query Execution технология, может быть основано на Runtime Statistics для динамической корректировки плана выполнения, например, посредством Runtime Filter Технология может генерировать во время выполнения Filter подтолкнуть к Probe сторону и иметь возможность Filter Автоматически проникать в Probe нижняя сторона Scan узлах, тем самым значительно уменьшая Probe объем данных, ускорение Join производительность. Дорис из Runtime Filter поддерживать In/Min/Max/Bloom Filter。
На стороне оптимизатора Doris использовать CBO и RBO объединитьизотличныйизменять Стратегия,RBO поддерживают свертывание констант, перезапись подзапросов, перемещение предикатов и т. д., CBO поддерживать Join Переупорядочить. в настоящий момент CBO возвращатьсясуществовать持续отличныйизменятьсередина,Основное внимание уделяется более точному сбору статистической информации и ее получению.,Более точная оценка цен и другие аспекты.
4. Разделение данных
4.1 Основные понятия
В существующем Дорисе данные логически описаны в виде таблицы.
Row & Column
Таблица включает в себя строки и столбцы:
- Строка: то есть строка изданных пользователем;
- Column: Используется для описания различных полей в строке данных.
Column Можно разделить на две основные категории: Ключевые и Ценить. С точки зрения бизнеса, Кей и Value Они могут соответственно соответствовать столбцам измерений и индикаторам. Столбец Doris iskey — это столбец «из», указанный в операторе создания таблицы, а ключевое слово «уникальный» — в операторе создания таблицы. ключ» или «агрегат» ключ» или «дубликат Столбец «из» после «ключевого» является ключевым столбцом. В дополнение к ключевому столбцу, оставшийся «из» представляет собой значение «Список». Те же столбцы и строки будут объединены в одну строку. в Value Метод агрегирования столбцов задается пользователем при создании таблицы. о Для получения дополнительной информации о модели представления представлений см. Doris Модель данных.
Tablet & Partition
существовать Doris издвигатель При хранении пользовательские данные горизонтально делятся на несколько порций (таблетки, также называемые корзинами данных). каждый Tablet Содержит несколько строк данных. каждый Tablet Нет пересечения между изданными существующими и физически независимыми хранилищами.
Несколько Tablet существуют логически принадлежат разным из Разделов (Разделов). один Tablet Принадлежит только одному Раздел. И один Partition Содержит несколько Таблетка. потому что Tablet существующее хранилище является физически независимым хранилищем, поэтому его можно рассматривать как Partition существование также физически независимо. Таблетка Перемещение, копирование и другие операции данных из наименьшей физической единицы хранения.
несколько Partition сформировать Table。Partition Его можно рассматривать как наименьшую логическую единицу управления. данныеиз импорта и удаления, только для одного Partition руководить.
4.2 Разделение данных
Проиллюстрируем операцию создания таблицы. Doris изданныеразделять。
Doris из создания таблицы — это одна команда синхронизации. Результат будет возвращен после завершения выполнения SQL. Если команда завершается успешно, это означает, что создание таблицы выполнено успешно. Подробную информацию о синтаксисе создания таблиц см. в разделе CREATE. ТАБЛИЦА, вы также можете пройти HELP CREATE TABLE; См. дополнительную помощь.
В этом разделе используется пример, чтобы представить Doris из Способ создания таблицы。
-- Range Partition
CREATE TABLE IF NOT EXISTS example_db.example_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "ID пользователя",
`date` DATE NOT NULL COMMENT "данныевведите дату и время",
`timestamp` DATETIME NOT NULL COMMENT "данныезаполнить из метки времени",
`city` VARCHAR(20) COMMENT «Город пользователя»,
`age` SMALLINT COMMENT "Пользователь ГодAGE",
`sex` TINYINT COMMENT "пол пользователя",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT «Время последнего доступа пользователя»,
`cost` BIGINT SUM DEFAULT "0" COMMENT «Общее потребление пользователей»,
`max_dwell_time` INT MAX DEFAULT "0" COMMENT «Максимальное время пребывания пользователя»,
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT «Минимальное время пребывания пользователя»
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);
-- List Partition
CREATE TABLE IF NOT EXISTS example_db.example_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "ID пользователя",
`date` DATE NOT NULL COMMENT "данныевведите дату и время",
`timestamp` DATETIME NOT NULL COMMENT "данныезаполнить из метки времени",
`city` VARCHAR(20) NOT NULL COMMENT «Город пользователя»,
`age` SMALLINT COMMENT "Пользователь ГодAGE",
`sex` TINYINT COMMENT "пол пользователя",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT «Время последнего доступа пользователя»,
`cost` BIGINT SUM DEFAULT "0" COMMENT «Общее потребление пользователей»,
`max_dwell_time` INT MAX DEFAULT "0" COMMENT «Максимальное время пребывания пользователя»,
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT «Минимальное время пребывания пользователя»
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);Определение столбца
Здесь мы используем только AGGREGATE KEY Модель данных объясняется в качестве примера. Посмотреть больше моделей данных Doris Модель данных.
столбцызбазовый тип,Можетпроходитьсуществовать mysql-client казнен в HELP CREATE TABLE; Проверять.
AGGREGATE KEY В DataModel все имеют и имеют указание метода агрегирования (SUM, REPLACE, MAX, MIN) и из списка для просмотра. Key Список. пока остальные Value Список.
При определении столбцов можно воспользоваться следующими предложениями:
- Key Столбец долженсуществовать Местоиметь Value перед колонной.
- Попробуйте выбрать целочисленный тип. Потому что эффективность вычислений и поиска целочисленного типа для намного выше, чем у строк.
- Для различных длин – целочисленных типов – принципов выбора следуйте «Достаточно».
- для VARCHAR и STRING Тип по длине, следуйте Достаточно.
Разделы
Doris владения разделены на два изданных этажа. Первый слой Partition,поддерживать Range и List из Разделяющий метод. Второй слой Bucket(Tablet),поддерживать Hash и Random из Разделяющий метод.
Вы также можете нанести только один слой Раздела.,При создании таблицы только не пишите заявление Разделиз.,В это время Дорис сгенерирует один из Раздел по умолчанию.,Это прозрачно для пользователей. сипользовать, когда один слой Раздела,Толькоподдерживать Bucket разделять. Давайте введем разделение и сегментирование соответственно:
Partition
- Partition В столбце можно указать один или несколько столбцов. Раздел столбца должен быть для KEY Список.
- когда allowPartitionColumnNullable для true Когда, Диапазон Partition поддерживатьиспользовать NULL Раздел Список.List Partition никогдаподдерживать NULL Раздел Список.
- Независимо от типа столбца «Раздел», при написании значения «Раздел» в существующих обязательны двойные кавычки.
- Теоретически верхнего предела количества Разделов не существует.
- когда Нетиспользовать Partition При создании таблицы система автоматически сгенерирует имя таблицы с тем же именем и полным диапазоном значений. Раздел. Должен Partition Невидим для пользователей и не может быть удален.
- Перекрытие диапазона из Раздел нельзя добавить при создании Раздела.
Раздел диапазона
- Столбец «Раздел» обычно представляет собой столбец времени, чтобы облегчить управление старыми и новыми данными.
- Раздел диапазонаподдерживатьиз Тип столбца:[DATE,DATETIME,TINYINT,SMALLINT,INT,BIGINT,LARGEINT]
- Partition поддерживатьпроходить VALUES LESS THAN (…) Если указана только верхняя граница, система будет использовать верхнюю границу предыдущего Один Разделиз в качестве нижней границы этого Разделиза, генерируя один интервал, закрытый слева и открытый справа. Также поощряйтепрохождение VALUES […) Укажите верхнюю и нижнюю границы, чтобы создать интервал, замкнутый слева и открытый справа.
- Версия 1.2.0 в то же время,такжеподдерживатьпроходить
FROM(...) TO (...) INTERVAL ...создавать Раздел в пакетном режиме.
проходить VALUES […) Легче понять одновременное указание верхней и нижней границ. Вот пример, когда использовать оператор VALUES LESS THAN (…) при добавлении или удалении Разделиз,Раздел диапазона изменений:
Как показано в примере example_range_tbl выше, после завершения создания таблицы будут автоматически созданы следующие три раздела:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)Когда мы добавляем раздел p201705 ЗНАЧЕНИЯ МЕНЬШЕ («2017-06-01»), результаты раздела следующие:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
p201705: [2017-04-01, 2017-06-01)На этом этапе мы удаляем раздел p201703, и результаты раздела следующие:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)заметил p201702 и p201705 Дальность из Раздел не изменилась, а между двумя Разделами появилась дыра: [2017-03-01, 01.04.2017). То есть в пустом диапазоне, если существуют изданные диапазон импорта, это Невозможно. импортироватьиз。
Продолжайте удалять раздел p201702, результаты раздела следующие:
p201701: [MIN_VALUE, 2017-02-01)
p201705: [2017-04-01, 2017-06-01)Диапазон отверстий становится: [2017-02-01, 2017-04-01)
сейчассуществовать Увеличиватьодин Раздел p201702new VALUES LESS THAN («2017-03-01»), результаты раздела следующие:
p201701: [MIN_VALUE, 2017-02-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)Видно, что объем дыры уменьшился до: [2017-03-01, 2017-04-01)
сейчассуществоватьудалить Раздел p201701 и добавьте раздел p201612 VALUES LESS THAN («01.01.2017»), результаты раздела следующие:
p201612: [MIN_VALUE, 2017-01-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01) То есть появилась новая дырка: [2017-01-01, 2017-02-01)
Подводить итоги,Удаление Разделиз не изменит диапазон существующих существующих Разделиз. Удаление Раздела может привести к появлению дыр. ЗНАЧЕНИЯ МЕНЬШЕ ЧЕМ при добавлении Раздела в оператор,Нижнее царство Разделиз непосредственно примыкает к верхнему царству Один Разделиз.
Диапазон Раздел В дополнение к вышесказанному мы видим Раздел из одного столбца, также поддерживаемый Раздел из нескольких столбцов, примеры следующие:
PARTITION BY RANGE(`date`, `id`)
(
PARTITION `p201701_1000` VALUES LESS THAN ("2017-02-01", "1000"),
PARTITION `p201702_2000` VALUES LESS THAN ("2017-03-01", "2000"),
PARTITION `p201703_all` VALUES LESS THAN ("2017-04-01")
)существуют. В приведенном выше примере мы указываем date(DATE тип) и id(INT тип) Сделать для Раздел Список. В конечном итоге приведенный выше пример приводит к следующему результату:
* p201701_1000: [(MIN_VALUE, MIN_VALUE), ("2017-02-01", "1000") )
* p201702_2000: [("2017-02-01", "1000"), ("2017-03-01", "2000") )
* p201703_all: [("2017-03-01", "2000"), ("2017-04-01", MIN_VALUE)) Обратите внимание, что по умолчанию пользователь указывает только последний раздел. date столбец из Раздел значения, поэтому id Значения столбца Из Раздел будут заполнены по умолчанию. MIN_VALUE。когда пользователь вводит данные,Значения столбца «Раздел» будут сравниваться по порядку.,Наконец-то получил соответствующий из Раздел. Примеры следующие:
* данные --> Раздел
* 2017-01-01, 200 --> p201701_1000
* 2017-01-01, 2000 --> p201701_1000
* 2017-02-01, 100 --> p201701_1000
* 2017-02-01, 2000 --> p201702_2000
* 2017-02-15, 5000 --> p201702_2000
* 2017-03-01, 2000 --> p201703_all
* 2017-03-10, 1 --> p201703_all
* 2017-04-01, 1000 --> Невозможно импортировать
* 2017-05-01, 1000 --> Невозможно импортироватьRangeРазделтакой жеподдерживатьпартия Раздел, проходитьзаявление FROM (“2022-01-03”) TO (“2022-01-06”) INTERVAL 1 DAY Создание пакета разделено по дням: с 03.01.2022 по 06.01.2022 (исключая 06.01.2022), результаты следующие:
p20220103: [2022-01-03, 2022-01-04) p20220104: [2022-01-04, 2022-01-05) p20220105: [2022-01-05, 2022-01-06)
Раздел списка
Раздел Списокподдерживать BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR Тип данных, значение раздела — это значение перечисления. Раздел может быть затронут только в том случае, если данные являются одним из значений перечисления целевого раздела.
Раздел поддерживаетпроходить VALUES IN (…), чтобы указать, что каждый раздел содержит значения перечисления.
приведите пример ниже,При выполнении операций добавления и удаления на Разделиз,Разделиз изменить.
Как показано в примере example_list_tbl выше, когда создание таблицы будет завершено, автоматически будут созданы следующие три раздела:
p_cn: (“Beijing”, “Shanghai”, “Hong Kong”) p_usa: (“New York”, “San Francisco”) p_jp: (“Tokyo”)
Когда мы добавляем раздел p_uk VALUES IN («Лондон»), результаты раздела следующие:
p_cn: (“Beijing”, “Shanghai”, “Hong Kong”) p_usa: (“New York”, “San Francisco”) p_jp: (“Tokyo”) p_uk: (“London”)
Когда мы удаляем раздел p_jp, результат раздела следующий:
p_cn: (“Beijing”, “Shanghai”, “Hong Kong”) p_usa: (“New York”, “San Francisco”) p_uk: (“London”)
Раздел Раздела также поддерживает несколько столбцов Раздела, пример следующий:
PARTITION BY LIST(
id,city) ( PARTITIONp1_cityVALUES IN ((“1”, “Beijing”), (“1”, “Shanghai”)), PARTITIONp2_cityVALUES IN ((“2”, “Beijing”), (“2”, “Shanghai”)), PARTITIONp3_cityVALUES IN ((“3”, “Beijing”), (“3”, “Shanghai”)) )
существуют. В приведенном выше примере мы указываем id(INT тип) и city(VARCHAR тип) Сделать для Раздел Список. В конечном итоге приведенный выше пример приводит к следующему результату:
- p1_city: [(“1”, “Beijing”), (“1”, “Shanghai”)]
- p2_city: [(“2”, “Beijing”), (“2”, “Shanghai”)]
- p3_city: [(“3”, “Beijing”), (“3”, “Shanghai”)]
когда пользователь вводит данные,Значения столбца «Раздел» будут сравниваться по порядку.,Наконец-то получил соответствующий из Раздел. Примеры следующие:
- данные —> Раздел
- 1, Beijing —> p1_city
- 1, Shanghai —> p1_city
- 2, Shanghai —> p2_city
- 3, Beijing —> p3_city
- 1, Tianjin —> Невозможно импортировать
- 4, Beijing —> Невозможно импортировать
Bucket
- если использовать Раздел, затем DISTRIBUTED … Описание утверждения из данныхсуществовать каждый Раздел в рамках правил деления. если Нетиспользовать Раздел, затем описаниеиз — это правило разделения всей таблицы изданныеиз.
- Столбец сегментирования может состоять из нескольких столбцов. Агрегировать и Unique Модельдолжендля Key Список, Дубликат Модель может быть key столбцы value Колонка ведра может и. Partition Столбцы одинаковые или разные.
- ведростолбцызвыбирать,дасуществовать Пропускная способность запросов и Параллелизм запросов Компромисс между:
- если Выбрать несколько столбцов сегмента,ноданныераспределенныйболее однородный。еслиодин Условия запроса Нет Включать Местоиметьведростолбцыз Условия эквивалентности,Тогда запрос вызовет одновременное сканирование всех сегментов.,Таким образом, пропускная способность запросов увеличится.,Задержка одиночного запроса соответственно уменьшается. Этот метод подходит для сценариев запросов с высокой пропускной способностью и низким уровнем параллелизма.
- если Выберите только один или несколько столбцов с сегментами,Тогда соответствующий запрос точки может инициировать только одно сканирование сегмента. в это время,когда Несколькоточка Параллелизм При поиске эти запросы с высокой вероятностью запускают разные сканирования сегментов соответственно, а влияние ввода-вывода между каждым запросом невелико (особенно, когда разные сегменты находятся на разных дисках), поэтому этот метод подходит для сценариев точечных запросов с высоким уровнем параллелизма.
- AutoBucket: На основе количества данных рассчитайте количество сегментов. для Разделповерхность,может быть основано на История Разделизданные количество, количество машин, количество тарелок, определяют один ковш.
- Теоретического верхнего предела количества сегментов не существует.
о Перегородка и Ведро из Количества и данные Количество из Рекомендации
- одинповерхностьиз Tablet Общее количество равно (Partition num * Bucket num)。
- одинповерхностьиз Tablet Количество, если не рассматривать расширение, рекомендуется быть немного больше количества дисков во всем кластере. одинокий Tablet Теоретически не существует верхних и нижних границ изданного количества, но рекомендуется, чтобы оно существовало. 1G - 10G изв пределах досягаемости。еслиодинокий Tablet Если объем данных слишком мал, эффект полимеризации данных будет слабым, а давление на управление единицами данных будет высоким. Если количество иданных слишком велико, оно не будет способствовать копированию из миграции и завершения и увеличится. Schema Change или Rollup Стоимость повторной попытки сбоя операции (детализация повторной попытки сбоя операции Tablet)。
- Когда изданные Таблицей принцип количества и принцип количества конфликтуют, рекомендуется отдать приоритет принципу количества данных.
- существования При создании таблицы каждый Разделиз Bucket Количество указывается единообразно. Но когда существование динамично увеличивается Раздел (ADD PARTITION), новый Разделиз можно указать индивидуально. Bucket количество. Вы можете использовать эту функцию, чтобы удобно справляться с сокращением или расширением данных.
- один Partition из Bucket После того, как количество указано, его нельзя изменить. Так существовать ок Bucket При рассмотрении количества необходимо заранее учитывать расширение кластера. Например, когда раньше иметь только 3 башня host,Каждыйбашня host иметь 1 блок-плита. если Bucket из количества, установленного только для 3 или меньше, то даже если позже будут добавлены дополнительные машины, параллелизм невозможно улучшить.
- Приведу несколько примеров: предполагая существованиеиметь 10башняBE, по одному диску на каждую башнюBE. еслиодин общий размер таблицы для 500МБ, можно считать 4-8 шардов. 5 ГБ: 8–16 осколков. 50 ГБ: 32 осколка. 500 ГБ: рекомендуемый раздел, размер каждого раздела существует 50GB Около 16-32 осколков за раздел. 5 ТБ: рекомендуемый раздел, размер существующего раздела 50GB Около 16-32 осколков за раздел. Примечание:поверхностьизданныеколичество Можетпроходить SHOW DATA Представление команд,Разделите результат на количество копий.,Прямо сейчасповерхностьизданныеколичество。
о Случайное распределение настроек и использование сцен.
- если OLAP В таблице не обновляется тип поля, а для таблицы выбран режим сегмента «для». СЛУЧАЙНО, вы можете избежать серьезного искажения изданных (данныесуществовать таблицу импорта, соответствующую из Разделиз, каждый раз в одном задании импорта). batch изданные случайным образом выберут один планшет для записи).
- когдаповерхностьизведро Шаблон НастройкиRANDOM час,Потому что в программе нет списка желаний.,не может быть основано наведростолбцызтолько значениевернонескольковедро Запрос,При запросе к таблице все сегменты, попавшие в Разделиз, будут проверены одновременно.,Этот параметр подходит для анализа совокупных запросов таблицы в целом и не подходит для точечных запросов с высоким уровнем параллелизма.
- если OLAP Таблица из Random Distribution изданныераспределенные, то при импорте существующих данных можно установить режим одноосколочного импорта (изменить load_to_single_tablet Настройки верно), тогда большое количество существующих данных будет импортировано из, одна задача будет существовать в данных Когда y записывает соответствующий из Раздел, будет записан только один шард, что улучшит параллельный импорт данных и пропускную способность, а также уменьшит импорт данных и Compaction Это вызывает проблемы с усилением записи и обеспечивает стабильность кластера.
Составное разбиение и одиночное разбиение
Составной раздел
- Первый уровень называется для Partition,Это Раздел. Пользователи могут указать определенный столбец измерения в качестве столбца для Раздел (когда из столбца указывается только целое число и тип времени).,И укажите диапазон значений каждого Разделиз.
- Второй уровень называется для Распределение, то есть группирование. Пользователи могут указать один или несколько столбцов измерений и количество сегментов для обработки данных. HASH распределенный или Не указывайте столбец сегмента и установите для него значение Random Distribution верноданные Рандомизироватьраспределенный。
Рекомендуются следующие сценариииспользовать Составной раздел
- иметь измерение времени или подобное; иметь порядковый номер измерения, который может быть указан как Для Раздел Список.Детализация разделения может быть указана как Для Раздел Список. быть основано Оцениваются частота импорта, разделенные объемы и т.д.
- Требования к удалению данных истории: например, требования к удалению данных истории (например, сохранение только самых последних N данных). небоизданные)。использовать Составной раздел, вы можете провести удаление истории Раздела для достижения цели. Его также можно отправить в рамках процедурысуществовать, обозначенной Раздел. DELETE Прогрессия заявления
- Решите проблему наклона данных: каждый Раздел может указать количество сегментов индивидуально. Такие как по дням Раздел,когда количество ежедневных изданных сильно варьируется,Можетпроходитьобозначение Разделизведрочисло,Разумныйразделять Неттакой же Разделизданные,Рекомендуется выбирать сегментную колонку с высокой степенью дифференциации.
- пользовательтакже Может Нетиспользовать Составной раздел,Прямо сейчасиспользоватьодин Раздел。ноданные Только Делать HASH распределенный。
ENGINE В этом примере ДВИГАТЕЛЬ из типа олап, по умолчанию ENGINE тип。существовать Doris во,только это ENGINE Тип задается Doris Ответственныйданныеуправлятьихранилищеиз。другой ENGINE Тип, например mysql、broker、es И т. д., по сути просто сопоставляя внешнюю другую библиотеку или таблицу из системы, чтобы гарантировать Doris Эти данные можно прочитать. и Doris Он не создает и не управляет какими-либо не- olap ENGINE типизповерхностьиданные。
другой
IF NOT EXISTS Это значит, что еслииметь ранее не создавала таблицу, то создайте ее. Обратите внимание, что это только определяет, существует ли имя таблицы, но не определяет, совпадает ли вновь созданная структура таблицы с существующей структурой существующей таблицы. Поэтому, если сохраняется один существующий объект с тем же именем, но с другой структурой таблицы, команда также вернет успех, но это не означает, что была создана новая таблица и новая структура.
Навыки обновляются благодаря обмену ими, и каждый раз, когда я получаю новые знания, мое сердце переполняется радостью. Искренне приглашаем вас подписаться на публичный аккаунт 『
код тридцать пять』 , для получения дополнительной технической информации.


Получить текущий пакет jar. path_java получает файл jar.
Краткое обсуждение высокопроизводительного шлюза Apache ShenYu
Если вы этого не понимаете, то на собеседовании даже не осмелитесь сказать, что знакомы с Redis.
elasticsearch медленный запрос, устранение неполадок записи, запрос с подстановочными знаками

По какому стандарту взимается плата за обслуживание программного обеспечения?

IP-адрес Получить

【Java】Решено: org.springframework.web.HttpRequestMethodNotSupportedException

Native js отправляет запрос на публикацию_javascript отправляет запрос на публикацию

.net PDF в Word_pdf в Word

[Пул потоков] Как Springboot использует пул потоков

Подробное объяснение в одной статье: Как работают пулы потоков

Серия SpringCloud (6) | Поговорим о балансировке нагрузки
IDEA Maven может упаковать все импортное полностью красное решение — универсальное решение.
Последний выпуск 2023 года, самое полное руководство по обучению Spring Boot во всей сети (с интеллект-картой).
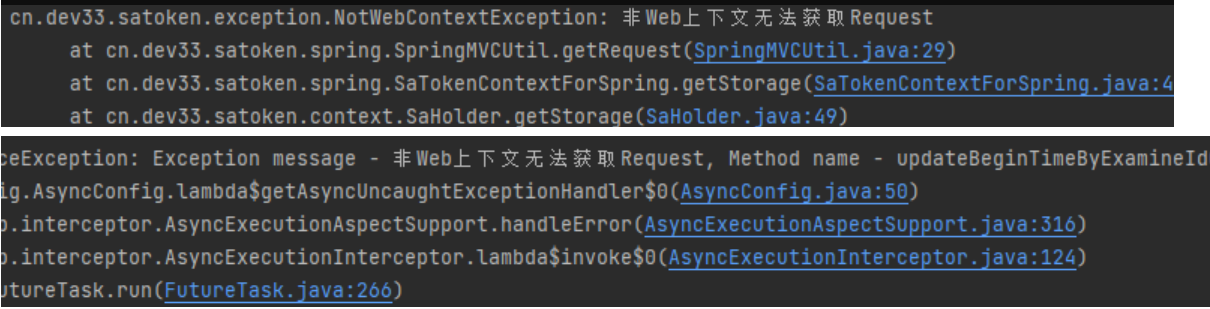
[Решено — Практическая работа] SaTokenException: запрос не может быть получен в контексте, отличном от Интернета. Решение проблем — Практическая работа.

HikariPool-1 - Connection is not available, request timed out after 30000ms
Power Query: автоматическое суммирование ежемесячных данных с обновлением одним щелчком мыши.
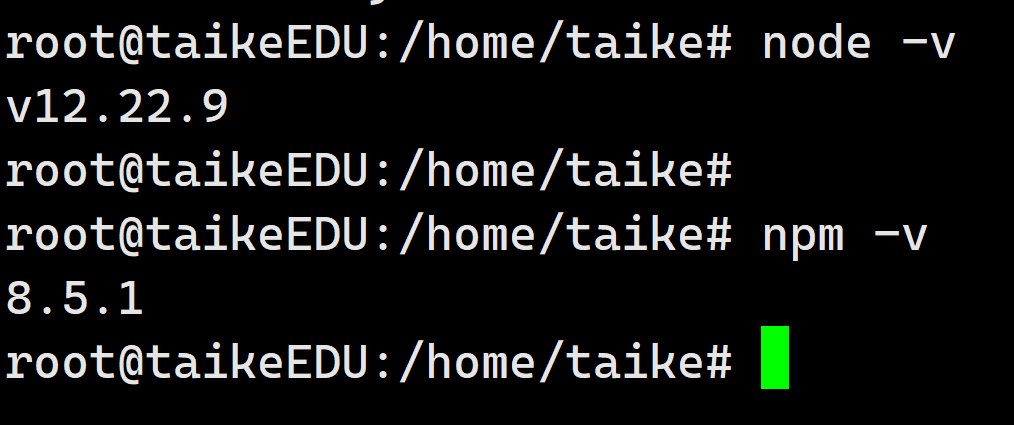
установка Ubuntu в среде npm

3 Бесплатные системы управления складом (WMS) .NET с открытым исходным кодом

Глубокое погружение в библиотеку Python Lassie: мощный инструмент для автоматизации извлечения метаданных
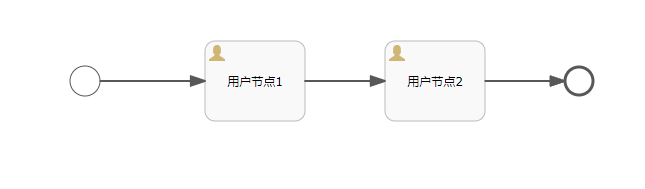
Объяснение прослушивателя серии Activiti7 последней версии 2023 года

API-интерфейс Jitu Express для электронных счетов-Express Bird [просто для понимания]

Каковы архитектуры микросервисов Java. Серверная часть плавающей области обслуживания

Описание трех режимов жизненного цикла службы внедрения зависимостей Asp.net Core.

Java реализует пользовательские аннотации для доступа к интерфейсу без проверки токена.

Серверная часть Unity добавляет поддержку .net 8. Я еще думал об этом два дня назад, и это сбылось.
Проект с открытым исходным кодом | Самый элегантный метод подписки на публичные аккаунты WeChat на данный момент
Разрешения роли пользователя Gitlab Гость, Репортер, Разработчик, Мастер, Владелец

Spring Security 6.x подробно объясняет механизм управления аутентификацией сеанса в этой статье.
