Углубленный анализ буферного пула MySQL: принципы, состав и его основная роль в операциях с данными.
1. Принцип буферного пула
Буферный пул — это непрерывная область памяти в механизме хранения InnoDB, используемая для кэширования страниц данных и индексных страниц на диске. Поскольку доступ к памяти происходит намного быстрее, чем доступ к диску, загрузка часто используемых данных и индексов в пул буферов может значительно улучшить производительность чтения и записи базы данных. Принцип работы буферного пула в основном основан на принципах «временной локальности» и «пространственной локальности», то есть к данным, к которым недавно осуществлялся доступ, скорее всего, в будущем снова будет осуществлен доступ, и когда осуществляется доступ к элементу данных, его соседние элементы данных также могут быть доступны снова.
2. Состав буферного пула
Изображение ниже представляет собой оригинальное изображение с официального сайта MySQL, на котором показан состав буферного пула в архитектуре движка innodb.
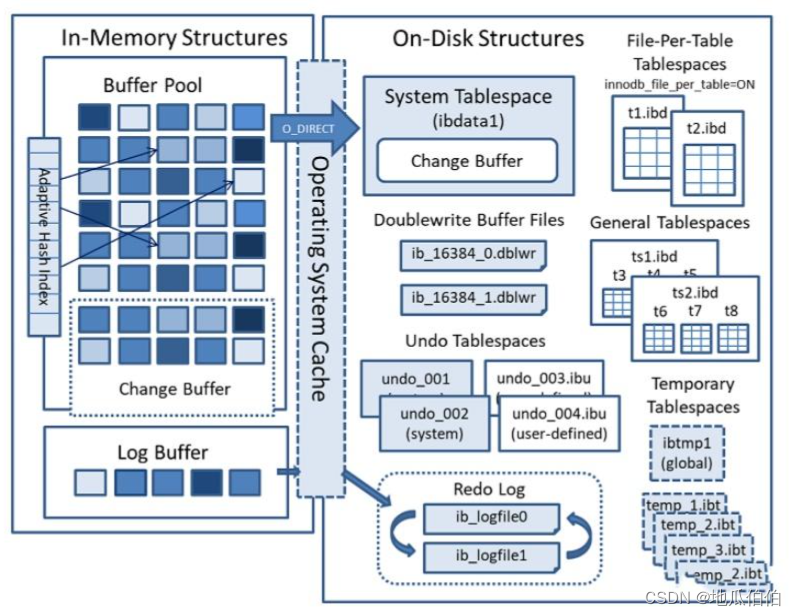
Подробное объяснение компонентов буферного пула
В механизме хранения MySQL InnoDB пул буферов (Buffer Pool) представляет собой ключевую структуру памяти, используемую для кэширования данных и индексов для сокращения операций ввода-вывода на физических дисках. Вот подробное объяснение некоторых важных компонентов буферного пула:
1. Индексные страницы
На индексной странице хранится индексная структура таблицы InnoDB, включая индекс первичного ключа (кластеризованный индекс) и вспомогательный индекс (некластеризованный индекс). Эти индексные страницы загружаются в пул буферов, чтобы ускорить поиск и доступ к данным в таблице. При выполнении операции запроса InnoDB сначала проверяет, находится ли требуемая индексная страница уже в буферном пуле. Если это так, она будет прочитана непосредственно из буферного пула. Это называется попаданием в буферный пул. для загрузки с диска. В пуле буферов это называется промахом пула буферов.
2. Страницы данных
На странице данных хранятся фактические строки данных таблицы InnoDB. В InnoDB данные хранятся на страницах, и каждая страница данных обычно содержит несколько строк данных. Когда данные в таблице необходимо прочитать или изменить, соответствующие страницы данных загружаются в пул буферов. Кэшируя страницы данных в памяти, InnoDB может быстро читать и изменять данные без необходимости каждый раз загружать их с диска.
3. Отменить страницы
На странице «Отменить» хранятся старые версии данных и используется для поддержки изоляции, устойчивости (Isolation) и долговечности (Durability) свойств ACID транзакций. При выполнении транзакции изменение данных не вступит в силу немедленно, но сначала будет записано на странице «Отменить». Если другим транзакциям необходимо прочитать измененные данные, они могут получить версию до изменения данных через страницу «Отменить», тем самым реализуя управление многоверсионным параллелизмом (MVCC). Кроме того, если транзакция завершается неудачно или происходит ее откат, данные на странице «Отменить» можно использовать для восстановления данных до состояния, существовавшего до начала транзакции.
4. Вставьте буфер
Кэширование вставки — это механизм, используемый в InnoDB для оптимизации операций вставки некластеризованного индекса. При вставке данных в таблицу, содержащую некластеризованный индекс, если соответствующая страница индекса не находится в пуле буферов, InnoDB не будет немедленно вставлять ключ индекса в страницу индекса, а сохранит его в кеше вставки. Когда связанные страницы индекса загружаются в пул буферов, ключи индекса, вставленные в кэш, объединяются и вставляются в страницу индекса. Это сокращает операции дискового ввода-вывода и повышает производительность операций вставки.
Следует отметить, что кэш вставки применяется только к операциям вставки в неуникальные индексы, а в некоторых случаях, например, когда пул буферов достаточно велик или таблица мала, кэш вставки может не использоваться.
5. Адаптивный хеш-индекс
Адаптивные хеш-индексы — это функция механизма хранения InnoDB, которая автоматически создает хэш-индексы на основе шаблонов доступа. Когда к определенным значениям индекса обращаются часто, InnoDB сохраняет эти значения индекса в адаптивных хеш-индексах, чтобы ускорить поиск этих значений. Адаптивные хэш-индексы полностью автоматические и не требуют ручного создания или обслуживания пользователем. Когда хеш-индексы больше не используются часто, InnoDB автоматически удаляет их, чтобы освободить память.
6. Информация о блокировке InnoDB (Информация о блокировке)
Механизм хранения InnoDB использует блокировки для обеспечения согласованности и целостности данных во время одновременного доступа. В пуле буферов InnoDB хранит информацию о блокировке, чтобы отслеживать, какие страницы или строки данных заблокированы, а также тип блокировки (например, общие или монопольные блокировки). Эта информация о блокировке имеет решающее значение для обеспечения изоляции транзакций и управления параллелизмом. Когда транзакция пытается получить доступ к данным, заблокированным другой транзакцией, она решает, ждать ли снятия блокировки или немедленно вернуть ошибку, в зависимости от типа блокировки и уровня изоляции транзакции.
Вместе эти компоненты буферного пула работают вместе, обеспечивая эффективный доступ к данным и возможности обработки транзакций. Путем правильной настройки и управления размером пула буферов и использованием компонентов можно дополнительно оптимизировать производительность и скорость ответа MySQL.
3. Процесс инициализации буферного пула
Когда сервер базы данных MySQL запускается, механизм хранения InnoDB выполнит ряд операций инициализации, включая инициализацию пула буферов. Основной поток процесса инициализации выглядит следующим образом:
- 1. Распределение пространства памяти: InnoDB сначала установит буфер в соответствии с параметрами конфигурации. Пул применяется для непрерывного пространства памяти. Размер этого пространства памяти настраивается и будет регулироваться в соответствии с рабочей нагрузкой и аппаратными ресурсами библиотеки данных.
- 2. Разделение страниц кэша: Запрошенное пространство памяти будет разделено на несколько страниц фиксированного размера. Эти страницы хранятся в буфере. Пул называется страницей кэша (или страницей буфера). В MySQL,Размер страницы по умолчанию — 16 КБ.,Но это значение также можно указать и в других размерах (например, 4 КБ, 8 КБ, 32 КБ и т. д.) при создании библиотеки данных.
- 3. Создание структуры управления: Для каждой кэшированной страницы,InnoDB создает структуру управления (также называемую блоком управления или дескриптором). Эта структура управления хранит метаданные кэшированной страницы.,Используется для управления статусом и жизненным циклом кэшированных страниц.
- 4. Инициализация связанного списка: InnoDB использует множество связанных списков для управления буферами. Кэшируйте страницы в пуле, например Связанный. список LRU (для управления порядком доступа и стратегией удаления кэшированных страниц) и бесплатный связанный список (для управления свободными страницами кэша). На этапе инициализации эти связанные списки также создаются и подготавливаются.
- 5. Настройка статуса страницы кэша: После завершения инициализации все кэшированные страницы находятся в состоянии ожидания, т. е. не содержат действительных данных. Эти бесплатные страницы кэша будут добавлены в бесплатный связанный список, ожидая последующей операции загрузки данных.
- 6. Загрузка данных: Когда библиотека данных начинает выполнять операцию CRUD, InnoDB при необходимости загружает страницу данных на диск в буфер. Бесплатные страницы кэша в Пуле. При загрузке страницы данных InnoDB проверит, находится ли запрошенная страница данных уже в буфере. Poolсередина(немедленная смертьсередина),если не,Страница данных считывается с диска и помещается на страницу свободного кэша.
- 7. Динамическое управление: При работающей библиотеке данных Buffer Кэшированные страницы в пуле изменяются динамически в зависимости от шаблонов доступа и условий загрузки. Часто используемые страницы данных будут храниться в буфере. Пул и страницы данных, к которым не было доступа в течение длительного времени, могут быть удалены, чтобы освободить место для новых страниц данных.
Благодаря такому процессу инициализации и управления InnoDB Buffer Pool может эффективно кэшировать «горячие» данные в базе данных, сокращать операции дискового ввода-вывода и тем самым улучшать общую производительность базы данных. В реальных приложениях администраторы баз данных могут регулировать размер пула буферов и другие связанные параметры в соответствии с требованиями к рабочей нагрузке и производительности для достижения оптимальной производительности.
4. Блок управления буферным пулом.
Блок управления буферным пулом — важная структура в механизме хранения InnoDB для управления страницами кэша. Чтобы лучше управлять страницами кэша, InnoDB создает отдельную область для каждой страницы кэшированных данных — блок управления. Этот блок управления используется для записи информации метаданных страницы данных, в основном включая следующие аспекты:
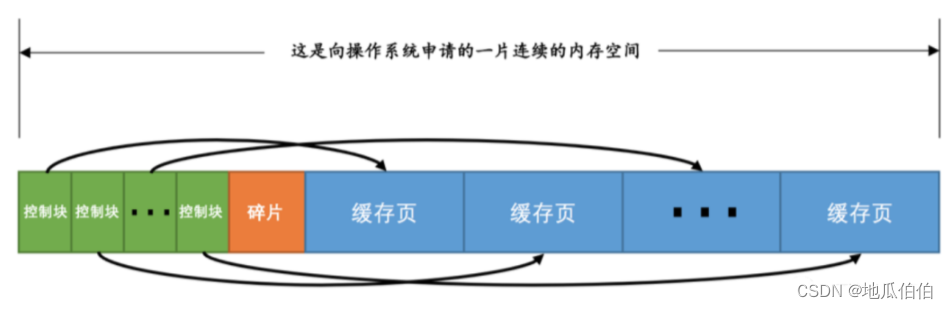
- 1. Номер табличного пространства, которому принадлежит страница данных.: Блок управления записывает номер табличного пространства, которому принадлежит страница данных. Это важная информация для поиска страницы данных в библиотеке данных.
- 2. Номер страницы данных: каждыйданные Каждая страница имеет уникальный номер,Номер страницы данных записывается в блок управления.,Чтобы вы могли найти его именно тогда, когда вам это нужно.
- 3. Адрес страницы кэша в буферном пуле.: Кэшировать записывается в блок управления страницу в буфере Адрес в пуле, который позволяет InnoDB быстро найти местоположение страницы кэша.
- 4. Информация об узле связанного списка: Из-за буфера В пуле имеется несколько связанных списков, используемых для управления страницами кэша (например, Связанный список LRU、бесплатный связанный список、очистить связанный список),Блок управления содержит информацию об узлах страницы кэша в этих связанных списках.,для операций со связанным списком.
- 5. Заблокировать информацию: Если страница кэша заблокирована, соответствующий запрос на блокировку будет записан в блоке управления. информацию,Включая тип замка, держатель и т. д.,Чтобы обеспечить согласованность данных во время одновременного доступа.
- 6. Информация о номере LSN: LSN(Log Sequence Number) — важная информация, используемая InnoDB для идентификации порядкового номера журнала. LSN страницы кэша будет записан в блоке управления, чтобы можно было найти правильное местоположение журнала во время восстановления после сбоя.
Между блоком управления и страницей кэша существует взаимно однозначное соответствие, и они оба хранятся в пуле буферов. Размер каждого управляющего блока обычно составляет около 5% страницы кэша, что составляет около 800 байт (при размере страницы кэша по умолчанию 16 КБ). При запуске сервера MySQL процесс инициализации пула буферов будет завершен, а используемое пространство памяти будет разделено на несколько управляющих блоков и страниц кэша. В это время блок управления записывает соответствующий адрес страницы кэша, и страница кэша находится в состоянии пустых данных.
С помощью блоков управления InnoDB может эффективно управлять страницами кэша в буферном пуле, обеспечивая быстрый доступ к данным и обработку транзакций.
5. Подробное объяснение трех связанных списков в буферном пуле.
В механизме хранения MySQL InnoDB буферный пул — это область памяти, используемая для кэширования данных и индексов для сокращения операций ввода-вывода на диске. Чтобы лучше управлять страницами кэша в этой области памяти, InnoDB использует три важных связанных списка: связанный список LRU, свободный связанный список и очищенный связанный список. Ниже приводится подробное объяснение этих трех связанных списков:
1. Связанный список LRU (наименее использованный в последнее время)
Связанный список LRU является наиболее важным связанным списком в пуле буферов и используется для управления последовательностью доступа и стратегией удаления страниц кэша. Ее название «Наименее недавно использованная» означает, что страница, использовавшаяся реже всего, будет удалена. Но на самом деле алгоритм LRU InnoDB — это улучшенная версия, которая разделена на две части: молодое поколение (молодой подсписок) и старое поколение (старый подсписок).
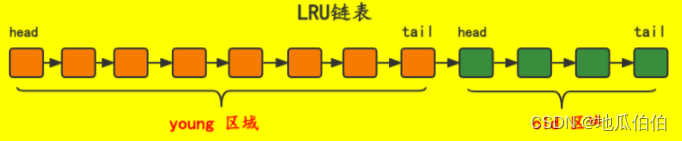
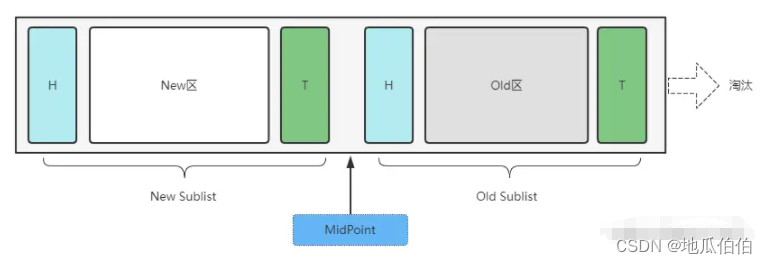
молодое поколение:Недавно загружено вBuffer Страницы пула в первую очередь будут ориентированы на молодое поколение. Если к странице обращаются несколько раз за короткий период времени среди молодого поколения, она считается «горячей» страницей и передается старшему поколению.
старость:старостьсерединахранится, считается“горячий”страница кэша,эти страницысуществовать Часто посещали в последнее время。когдаBuffer Когда пулу требуется место для загрузки новых страниц, он удаляет страницы старого поколения.
Эта стратегия генерации может гарантировать, что «горячие» страницы останутся в буферном пуле в течение более длительного периода времени, тем самым улучшая скорость попадания в кеш.
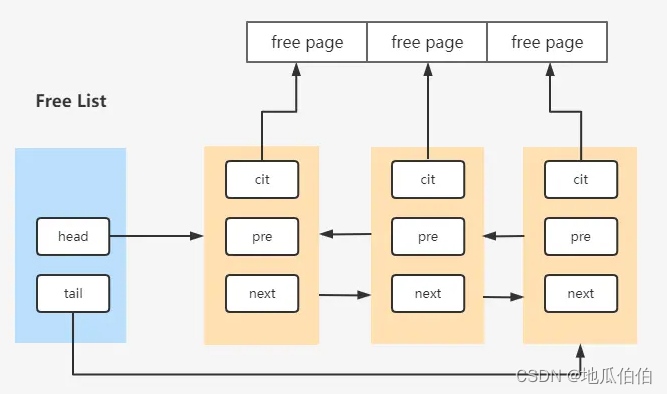
2. бесплатный связанный список
Свободный связанный список используется для управления свободными страницами, которые в данный момент не используются в пуле буферов. Когда страница удаляется из списка LRU или других связанных списков, она добавляется в свободный список. Когда новую страницу необходимо загрузить в пул буферов, InnoDB сначала получит бесплатную страницу из свободного связанного списка. Если список свободных пуст, InnoDB необходимо удалить страницы из списка LRU, чтобы освободить место.
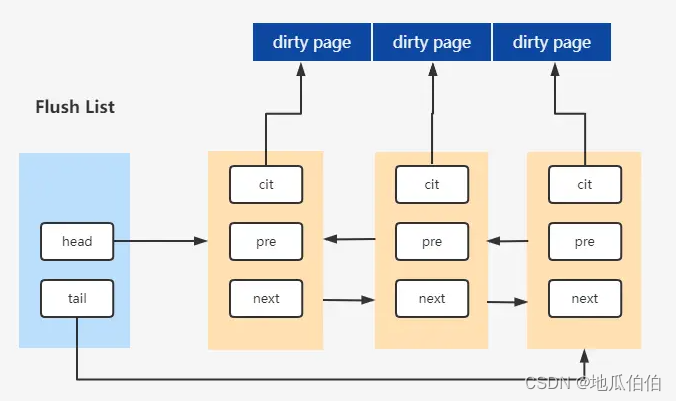
3. очистить связанный список
Связанный список очистки используется для управления страницами кэша, которые были изменены (т. е. «грязными страницами») и должны быть сброшены на диск. Когда транзакция зафиксирована или в буферном пуле недостаточно свободного места, InnoDB выберет несколько грязных страниц для добавления в список очистки и сбросит их на диск в подходящее время. Связанный список очистки гарантирует, что грязные страницы могут быть удалены в определенном порядке и приоритете, тем самым обеспечивая постоянство и согласованность данных.
Таким образом, эти три связанных списка играют разные роли в буферном пуле:
Связанный список LRU:Управляйте последовательностью доступа и стратегией удаления страниц кэша.,Убедитесь, что «горячие» страницы кэшируются в течение длительного периода времени.
бесплатный связанный список:Управление неиспользуемыми бесплатными страницами,Обеспечьте место для загрузки новых страниц.
очистить связанный список:Управляйте грязными страницами, которые необходимо сбросить на диск.,Гарантированная долговечность и согласованность данных.
Благодаря использованию и взаимодействию этих трех связанных списков InnoDB может эффективно управлять страницами кэша в буферном пуле и повышать производительность и скорость ответа базы данных.
6. Принцип буферного пула в операциях добавления, удаления, изменения и запроса базы данных.
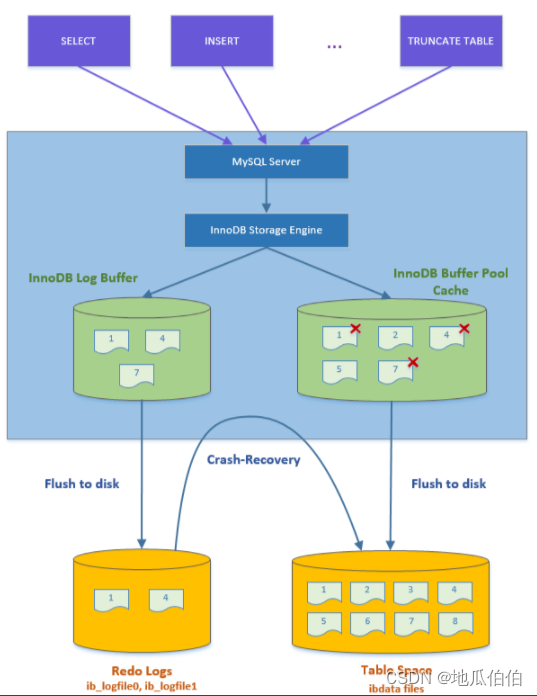
1. Загрузка и кэширование данных
При выполнении операции CRUD система базы данных сначала проверяет, находится ли требуемая страница данных уже в буферном пуле. Если страница данных отсутствует в буферном пуле (то есть промах в кэше), система считывает соответствующую страницу данных с диска и загружает ее в свободную страницу кэша в буферном пуле. Этот процесс включает в себя чтение данных с диска в память. Поскольку доступ к памяти происходит намного быстрее, чем к диску, скорость доступа к данным можно значительно повысить за счет кэширования.
2. Модификация данных
Для операций добавления, удаления и изменения система базы данных будет напрямую изменять соответствующую страницу кэша в буферном пуле, а не немедленно записывать ее обратно на диск. Это связано с тем, что операции модификации в памяти выполняются очень быстро и могут значительно увеличить вычислительную мощность базы данных. Измененные страницы кэша помечаются как «грязные страницы», что означает, что их содержимое не синхронизировано с данными на диске.
3. Запись на диск
Грязные страницы не записываются обратно на диск немедленно, а сбрасываются на диск асинхронно фоновым процессом в соответствующее время. Эта стратегия отложенной обратной записи может сократить операции ввода-вывода на диске и повысить производительность системы. Однако, чтобы обеспечить надежность и согласованность данных, система базы данных принудительно запишет «грязные» страницы обратно на диск при определенных обстоятельствах (например, при фиксации транзакции).
4. Стратегия замены кэша
Поскольку размер буферного пула ограничен, необходима стратегия, позволяющая решить, какие данные следует заменить или удалить при использовании всех страниц кэша. Наиболее распространенной стратегией является алгоритм «наименее недавно использовавшийся» (LRU), который определяет, какие страницы следует удалить, в зависимости от того, как часто они используются. Однако системы баз данных часто вносят некоторые изменения в стандартный алгоритм LRU, чтобы адаптироваться к своим конкретным моделям доступа и требованиям к производительности.
5. Управление параллелизмом
Когда несколько пользователей одновременно обращаются к базе данных, буферный пул также должен предоставить соответствующие механизмы управления параллелизмом, чтобы гарантировать согласованность и целостность данных. Обычно это предполагает использование блокировок и других механизмов синхронизации для координации доступа между различными пользователями.
6. Восстановление и устранение неполадок
Чтобы предотвратить потерю данных, вызванную системными сбоями, системы баз данных обычно используют журналы (например, журналы повторного выполнения) для записи изменений данных. Таким образом, после сбоя системы данные можно восстановить до согласованного состояния путем повторного воспроизведения журнала. Грязные страницы в буферном пуле также будут перестроены в процессе восстановления.
Благодаря вышеуказанным принципам пул буферов играет ключевую роль в операциях добавления, удаления, изменения и запроса базы данных. Он значительно повышает производительность и масштабируемость базы данных с помощью таких стратегий, как кэширование и отложенная обратная запись.
Заключение
Буферный пул MySQL — это высокооптимизированная область памяти, которая сокращает операции дискового ввода-вывода за счет кэширования данных и индексов горячих точек, что значительно повышает производительность базы данных. Проектирование и реализация пула буферов включает в себя множество сложных алгоритмов и структур данных, таких как алгоритм LRU, механизм упреждающего чтения и т. д. Понимание принципа работы и компонентов пула буферов имеет важное значение для оптимизации производительности MySQL и решения проблем с производительностью. С помощью изображений и текста мы можем более интуитивно понять основную роль пула буферов в операциях с данными.
Навыки обновляются благодаря обмену ими, и каждый раз, когда я получаю новые знания, мое сердце переполняется радостью. Искренне приглашаем вас подписаться на публичный аккаунт 『
код тридцать пять』 , для получения дополнительной технической информации.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
