Углубленное понимание многоклассовых матриц путаницы: интерпретация, применение и примеры.
Каталог статей
- 🍋Введение
- 🍋Что такое матрица путаницы?
- 🍋Применение матрицы путаницы
- 🍋Практическая матрица путаницы с несколькими классификациями
- 🍋Резюме
🍋Введение
в машинном обучении инаука о данныхполе,матрица путаницы(Confusion Матрица) — важный инструмент для оценки эффективности моделей классификации. Хотя матрица путаницы широко используется в задачах бинарной классификации, она также подходит для задач мультиклассификации. В этой статье мы углубимся в концепцию, методы интерпретации, сценарии применения матриц путаницы мультиклассификации и предоставим практический пример, который поможет вам лучше понять и использовать ее.
🍋Что такое матрица путаницы?
Матрица путаницы — это таблица, используемая для визуализации производительности модели классификации и сравнения прогнозов модели с фактическими метками. Для задач мультиклассификации структура матрицы путаницы может немного отличаться, но основная идея та же.
типичныйМногоклассовая матрица путаницыКак показано ниже:
Class 1 Class 2 Class 3 ... Class N
Class 1 TP11 TP12 TP13 TP1N
Class 2 TP21 TP22 TP23 TP2N
Class 3 TP31 TP32 TP33 TP3N
... ... ... ... ...
Class N TPN1 TPN2 TPN3 TPNNКаждая строка представляет фактический класс, а каждый столбец представляет прогнозируемый класс модели. Элементы на диагонали матрицы (TPii) представляют количество выборок, правильно предсказанных моделью, а недиагональные элементы представляют количество выборок, неправильно предсказанных моделью.
Интерпретация матрицы путаницы
- Истинные положительные результаты (TP): количество образцов, правильно предсказанных моделью как i-й класс.
- Ложные срабатывания (FP): количество образцов, ошибочно спрогнозированных моделью как принадлежащих к классу i.
- Ложноотрицательные результаты (FN): количество образцов, которые модель ошибочно спрогнозировала как не принадлежащие к i-му классу.
- Истинные отрицательные числа (TN): количество образцов, которые модель правильно предсказывает как не i-й класс.
🍋Применение матрицы путаницы
Матрица путаницы предоставляет обширную информацию для оценки моделей классификации, помогает анализировать производительность модели и корректировать ее параметры. Вот некоторые распространенные применения матриц путаницы:
- Точность: Рассчитайте долю количества правильно классифицированных образцов по всем категориям к общему количеству образцов, то есть (TP1 + TP2 +… + ТПС)/(общее количество образцов).
- Точность: вычислите долю количества выборок, правильно предсказанных моделью как i-й класс, к количеству выборок, предсказанных как i-й класс, то есть TPi / (TPi + FPi).
- Напомним: вычислите долю количества выборок, правильно предсказанных моделью как i-го класса, к общему количеству выборок, которые на самом деле относятся к i-му классу, то есть TPi/(TPi + FNi).
- Оценка F1 (F1-Score): учитывает точность и полноту и используется для балансировки взаимосвязи между ними, особенно подходит для несбалансированных наборов данных.
🍋Практическая матрица путаницы с несколькими классификациями
Во-первых, нам нужно импортировать набор данных для распознавания рукописных цифр и подготовить данные. В этом разделе мы будем использовать его для практики.
from sklearn.datasets import load_digits
digits = load_digits()
X = digits.data
y = digits.targetКроме того, нам также необходимо импортировать некоторые библиотеки следующим образом:
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix,recall_score,precision_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionЗатем мы разрезаем набор данных, подгоняем обучающий набор и делаем прогнозы.
log_reg = LogisticRegression(max_iter=10000)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.8,random_state=666)
log_reg.fit(X_train,y_train)
log_reg.score(X_test,y_test)Вы можете оценить точность

Далее мы делаем прогнозы на основе хорошей модели логистической регрессии.
y_predict = log_reg.predict(X_test)И распечатайте матрицу путаницы
confusion_matrix(y_test,y_predict)Результаты бега следующие

Затем мы можем взглянуть на значения точности и полноты
precision_score(y_test,y_predict,average='micro')
recall_score(y_test,y_predict,average='macro')Результаты бега следующие

Далее сохраняем матрицу путаницы в формате CFM и рисуем изображение.
cfm = confusion_matrix(y_test,y_predict)
plt.matshow(cfm) Результаты бега следующие
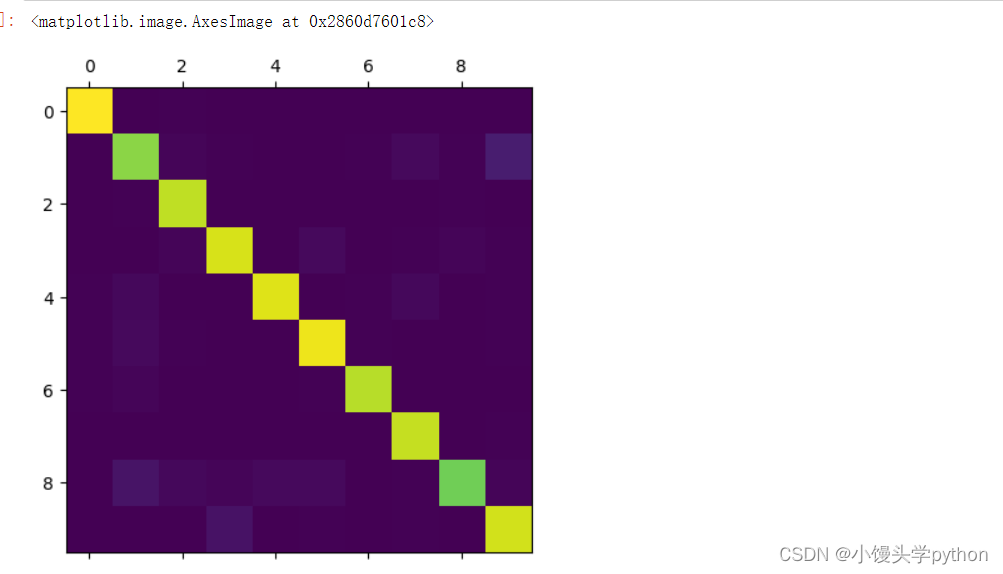
Примечание. Чем ярче область, тем больше ошибок.
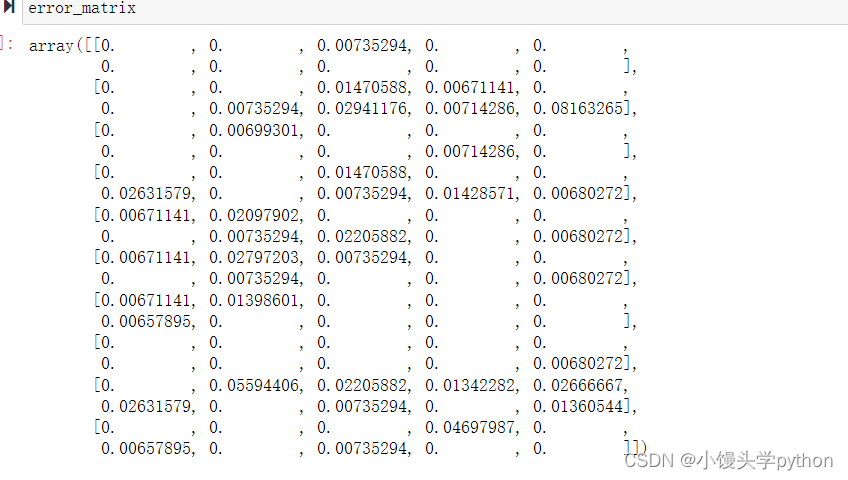
Мы можем установить диагональ равным 0
import numpy as np
row_sum = np.sum(cfm,axis=1)
error_matrix = cfm/row_sum
np.fill_diagonal(error_matrix,0) # Диагональ установлена на 0Результаты бега следующие
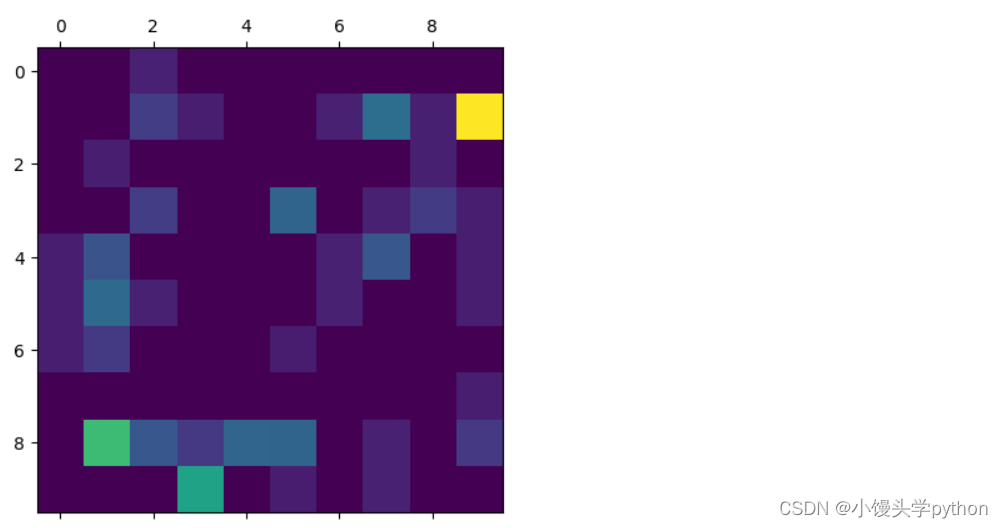
Затем нарисуйте вот такое изображение
plt.matshow(error_matrix)Вы сможете более интуитивно увидеть, где уровень ошибок высок, что облегчит последующую обработку.
🍋Резюме
Подводить итоги,Матрицы путаницы — мощный инструмент для оценки эффективности моделей мультиклассификации.,он предоставляет подробную информацию,Помогите нам понять, как модель работает в каждой категории. Сочетает в себе такие показатели, как точность, точность, отзыв и показатель F1.,Позволяет более полно оценить эффективность модели.,а затем улучшить модель или провести дальнейший анализ.。深入理解和应用матрица путаницы有助于提高Проект машинного обучениякачество и эффект。



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
