Углубленное понимание архитектуры HBase: от теории к практике
HBase — это распределенная база данных NoSQL с колоночным хранилищем, разработанная на основе Google Bigtable и используемая для обработки огромных объемов структурированных данных. Уникальность архитектуры HBase делает ее широко используемой в сфере больших данных. В этой статье будет подробно представлен архитектурный проект HBase, от теоретических концепций до практического развертывания, и проанализирован его на конкретных примерах.
HBase изначально был разработан разработчиками Apache Hadoop для решения проблем хранения и извлечения больших объемов данных в распределенной файловой системе Hadoop (HDFS). Традиционные реляционные базы данных неэффективны при обработке крупномасштабных данных и их трудно расширять. Будучи базой данных NoSQL, HBase обеспечивает эффективные операции чтения и записи больших объемов данных и обладает высокой масштабируемостью.
Требование проекта состоит в том, чтобы построить крупномасштабную систему хранения данных, способную обрабатывать миллиарды записей. Система должна иметь возможность выполнять высококонкурентные запросы на чтение и запись, и в то же время производительность системы не будет значительно снижаться при выходе из строя. объем данных резко возрастает. HBase разработан специально для такого рода потребностей.
Обзор архитектуры HBase
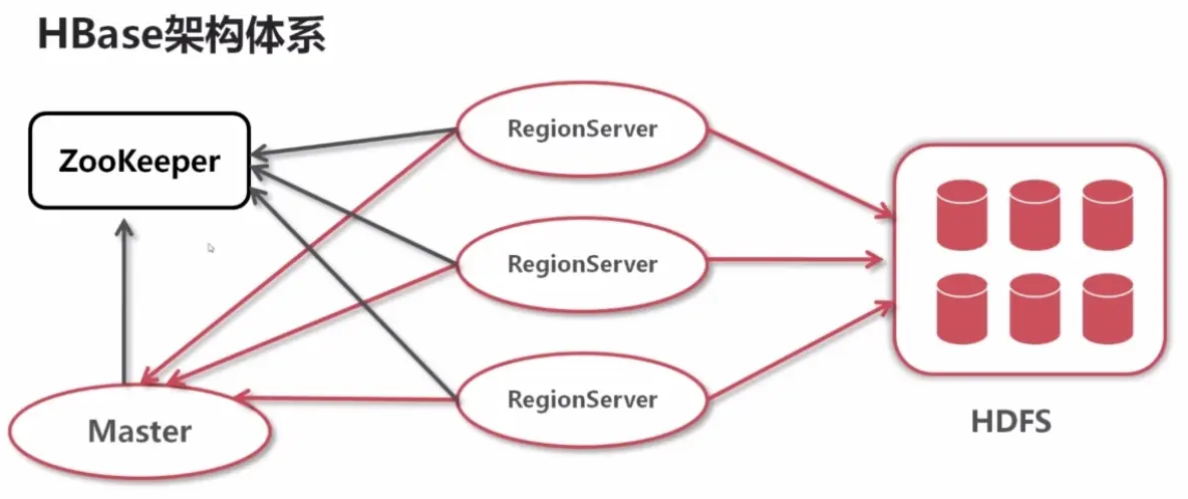
Архитектура HBase разделена на несколько ключевых компонентов:
компоненты | описывать |
|---|---|
HMaster | HMaster является главным узлом кластера HBase и отвечает за координацию операций кластера, таких как создание, удаление таблиц, управление разделами и т. д. HMaster также отвечает за выделение и мониторинг серверов RegionServers для обеспечения стабильной работы кластера. |
RegionServer | RegionServer — это узел, отвечающий за хранение и управление данными. Каждый региональный сервер может управлять несколькими регионами, и каждый регион представляет собой подмножество данных. RegionServer обрабатывает клиентские запросы на чтение и запись, обеспечивая согласованность и надежность данных. |
Zookeeper | Zookeeper — это служба координации кластера HBase. Она отвечает за управление информацией о конфигурации и метаданными кластера, а также за мониторинг состояния HMaster и RegionServer. Zookeeper обеспечивает высокую доступность кластера и автоматически восстанавливает вышедшие из строя узлы с помощью механизма выборов. |
HFile и MemStore | HFile — это физический файл хранения данных HBase, который хранится в модулях семейства столбцов. MemStore — это структура данных HBase в памяти, используемая для кэширования операций записи. Когда MemStore достигнет определенного размера, данные будут сброшены в HFile. |
Write-Ahead Log (WAL) | WAL — это журнал упреждающей записи HBase, который используется для записи операций записи данных, чтобы гарантировать, что данные не будут потеряны в случае сбоя системы. Существование WAL повышает надежность данных HBase. |
Модель данных и операции HBase
модель данных
HBase измодель данные отличаются от традиционной реляционной базы данных, усыновленной разреженной моделью многомерного отображения. Он относится к базовой единице хранения: таблица (Table). Таблица состоит из строки (Row) и семейства столбцов (Column). Семейный) состав. Каждое семейство столбцов может содержать несколько столбцов (Column), а версия данных столбца определяется по метке времени (Timestamp).
Таблицы в HBase ориентированы на строки, и каждая строка имеет уникальный ключ строки. Ключ строки — это уникальный идентификатор данных в таблице, а доступ к столбцам в семействе столбцов осуществляется через ключ столбца (ключ столбца). Значение данных каждой ячейки может иметь несколько версий, управляемых с помощью меток времени.
Пример отображения:
Row Key | Column Family:Column | Value | Timestamp |
|---|---|---|---|
row1 | cf1:col1 | value1 | 1627871234000 |
row1 | cf1:col2 | value2 | 1627871235000 |
row2 | cf1:col1 | value3 | 1627871236000 |
Основные операции
HBase Обеспечивает богатый API Выполнять операции с данными, в том числе Put、Get、Delete и Scan。Put для записи данных,Get для чтения данных,Delete используется для Удалить данные,Scan Используется для пакетного чтения данных.
- Put:Записать данные в таблицусередина.
- Get:Чтение данных на основе ключа строки。
- Delete:Удалить указанную строку или столбецизданные。
- Scan:Пройти через столизданные。
Хранение и извлечение данных HBase
HBase Усыновленный LSM (Log-Structured Merge) древовидная структура, комбинация WAL и MemStore Повышена эффективность записи данных.
Процесс записи
Когда клиент отправляет запрос на запись в HBase, данные сначала записываются в WAL, а затем сохраняются в MemStore. WAL гарантирует, что данные не будут потеряны в случае сбоя RegionServer. MemStore сохранит данные в HFile на диске после достижения определенного порога.
Процесс чтения
Когда клиент инициирует запрос на чтение, RegionServer сначала будет внутри MemStore Искать данные в, если не нашли, то из HFile Найдите в . путем спаривания MemStore и HFile Используется совместно с HBase. Способен обеспечить высокую производительность чтения данных.
Масштабируемость HBase и высокая доступность
HBase из Архитектурный дизайн обеспечивает хорошую из Маштабируемостьи Высокая доступность。
характеристика | описывать |
|---|---|
Масштабируемость | HBase может обеспечить горизонтальное расширение путем добавления узлов RegionServer. Когда объем данных увеличивается, HMaster может разделить регион на более мелкие регионы и распределить их по новым серверам региона. |
Высокая доступность | Контролируя каждый узел кластера через Zookeeper, HBase реализует механизм автоматического восстановления после сбоев. В случае сбоя RegionServer HMaster перераспределит регионы, которыми он управляет, другим работоспособным RegionServer. |
Практический бой: установка и развертывание HBase
Экологическая подготовка
- Операционная система: Ubuntu 20.04
- Java: JDK 1.8+
- Hadoop: 3.2.2
- HBase: 2.4.8
- Zookeeper: 3.7.1
Этапы установки
(i) Установить Java
sudo apt update
sudo apt install openjdk-8-jdk
java -version(ii) Развертывание Hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
tar -xzvf hadoop-3.2.2.tar.gz
sudo mv hadoop-3.2.2 /usr/local/hadoopНастройте переменные среды Hadoop:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin(iii) Установите Zookeeper
wget https://downloads.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
tar -xzvf apache-zookeeper-3.7.1-bin.tar.gz
sudo mv apache-zookeeper-3.7.1-bin /usr/local/zookeeperНастройте Zookeeper:
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg(iv) Установите HBase
wget https://downloads.apache.org/hbase/2.4.8/hbase-2.4.8-bin.tar.gz
tar -xzvf hbase-2.4.8-bin.tar.gz
sudo mv hbase-2.4.8 /usr/local/hbaseНастройте переменные среды HBase:
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/binКонфигурация hbase-site.xml:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
</configuration>(v) Запустить HBase
start-hbase.shпутем доступа http://localhost:16010 подтверждать HBase Стартовал успешно.
Практический бой: операции с данными HBase
- Создать таблицу
Создайте простую таблицу в HBase.
hbase shellcreate 'test', 'cf'- Вставить данные
Вставьте некоторые данные в таблицу.
put 'my_table', 'row1', 'cf1:col1', 'value1'
put 'my_table', 'row2', 'cf1:col2', 'value2'- Данные запроса
Прочитайте вставленные данные.
get 'my_table', 'row1'- данные сканирования
Чтение данных в пакетном режиме.
scan 'my_table'- Удалить данные
Удалить указанную строку или столбец.
delete 'my_table', 'row1', 'cf1:col1'- Удалить таблицу
Удалить всю таблицу.
disable 'my_table'
drop 'my_table'Оптимизация и настройка HBase
Стратегия оптимизации | описывать |
|---|---|
Настройка памяти | HBase из Производительность сильно зависит от памяти из Конфигурация. Можно регулировать путем |
Оптимизация диска | HBase из I/O Производительность напрямую влияет на эффективность чтения и записи. Можно регулировать с помощью HDFS из Размер блока HBase Метод сжатия файлов для повышения эффективности использования диска. |
Оптимизация сети | существовать в распределенной среде,Задержка и пропускная способность сети оказывают большое влияние на производительность HBase. проводитьконфигурацию нескольких сетевых интерфейсов, оптимизацию стека сетевых протоколов и другие методы.,Может уменьшить узкие места в сети. |
HBase как Мощный из Распределенного NoSQL База данных с хорошей из Маштабируемостьюи Высокая доступность。проходить Глубокое понимание HBase Архитектура и принцип ее работы в сочетании с реальными потребностями в разумной оптимизации конфигурации могут дать полную свободу HBase существуют из Преимущества в обработке больших данных.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
