[Учитель Чжао Юцян] Процесс загрузки и выгрузки данных HDFS

В HDFS Hadoop запрос операции клиента, будь то загрузка данных или выгрузка данных, принимается и обрабатывается NameNode. Наконец, данные сохраняются в узле данных DataNode в виде блоков данных. На рисунке ниже показан процесс загрузки данных HDFS.
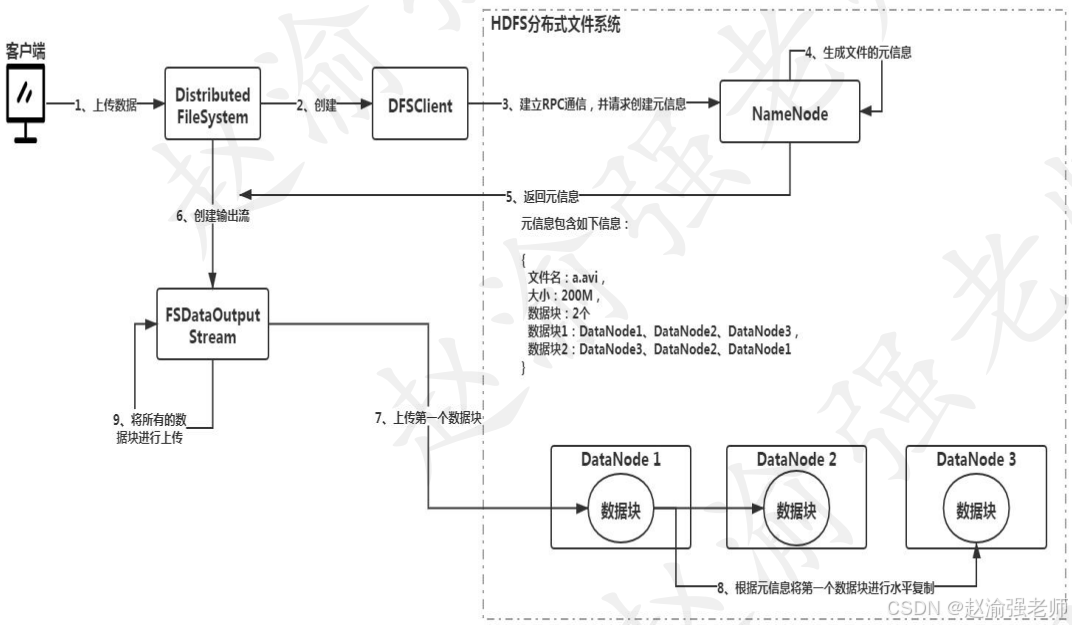
Видеообъяснение следующее:
Предположим, вам нужно загрузить файл размером 200 МБ. В соответствии с размером блока данных 128 МБ файл будет разделен на два блока данных. После того, как клиент выдает команду загрузки, объект DFSClient создается объектом DistributedFileSystem. Этот объект отвечает за установление связи RPC с NameNode и запрос к NameNode для создания метаинформации для файла. Когда NameNode получит запрос, он сгенерирует соответствующую метаинформацию, как показано в шаге 4 на рисунке. Метаинформация включает в себя следующее содержимое: количество блоков данных, мест хранения и избыточных мест. Например: блок данных 1 будет сохранен в DataNode1, и в то же время соответствующие две резервные копии будут храниться в DataNode2 и DataNode3. NameNode вернет сгенерированную метаинформацию в объект DistributedFileSystem и создаст объект выходного потока FSDataOutputStream. Затем фрагменты данных загружаются на основе сгенерированной метаинформации. Например, как показано на рисунке в шаге 7, клиент загрузит блок данных 1 в DataNode1 и скопирует его на другие резервные узлы посредством горизонтальной репликации, в конечном итоге обеспечив требования к избыточности блоков данных. Так до тех пор, пока все блоки данных не будут успешно загружены.
Узнав о процессе загрузки данных HDFS, следующий рисунок иллюстрирует процесс загрузки данных HDFS.
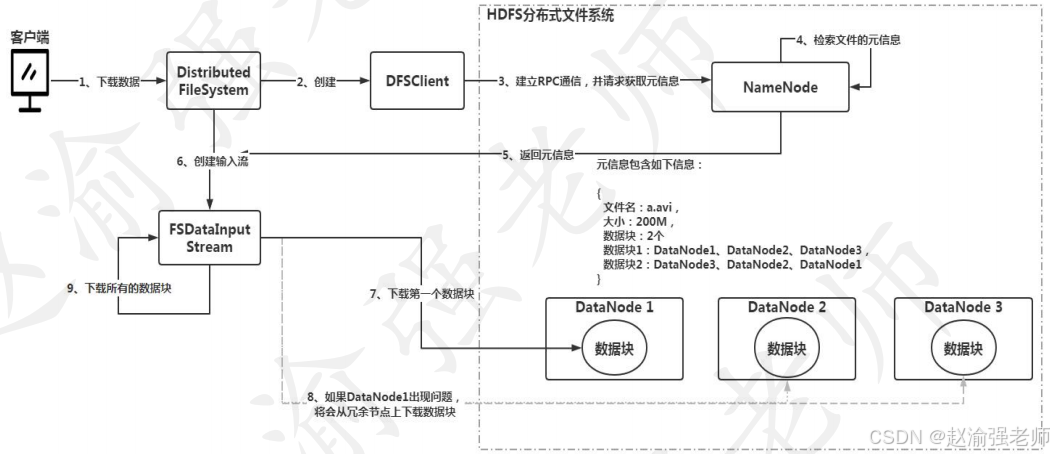
Видеообъяснение следующее:



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
