[Учитель Чжао Юцян] Архитектура платформы, основанная на компонентах больших данных

Поняв компоненты и функциональные характеристики, включенные в каждую экосистему больших данных, вы можете использовать эти компоненты для создания платформы больших данных для хранения и расчета данных. На рисунке ниже показана общая архитектура платформы больших данных.
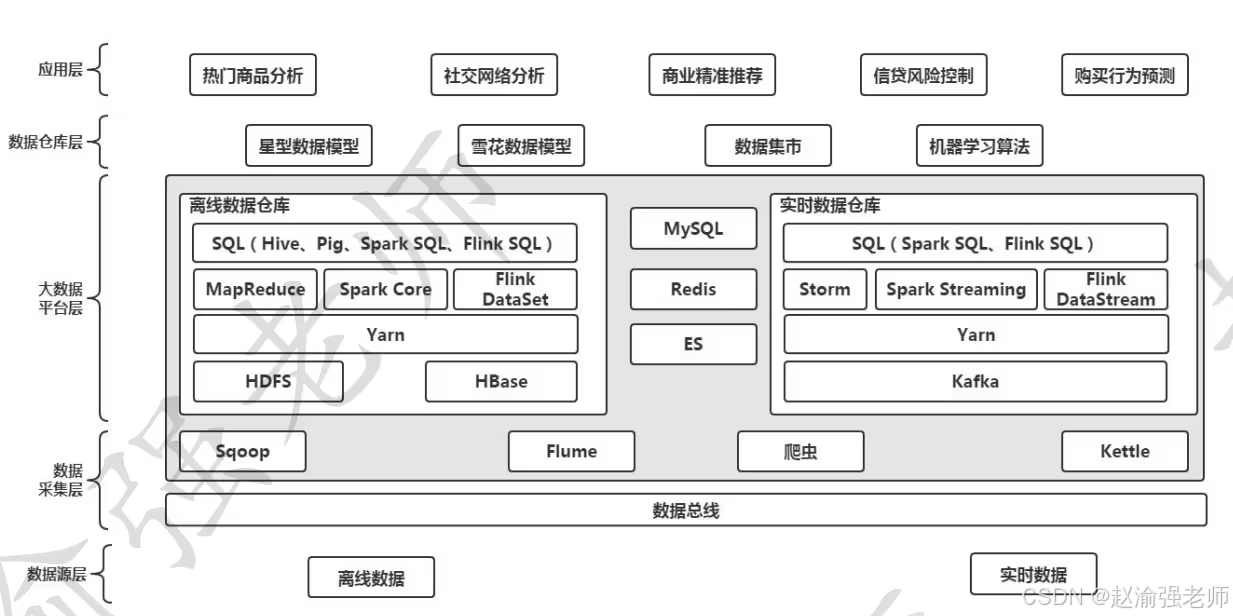
Видео объяснение следующее:
Общую архитектуру платформы больших данных можно разделить на пять уровней: уровень источника данных, уровень сбора данных, уровень платформы больших данных, уровень хранилища данных и уровень приложений.
1. Уровень источника данных
Основная функция уровня источника данных — предоставление различных необходимых бизнес-данных, таких как данные пользовательских заказов, данные транзакций, данные системного журнала и т. д. Короче говоря, все данные, которые могут быть предоставлены, можно назвать источниками данных. Хотя существуют различные типы источников данных, их можно разделить на две основные категории в системе платформы больших данных, а именно: автономные источники данных и источники данных в реальном времени. Как следует из названия, автономные источники данных используются в автономных вычислениях больших данных, а источники данных в реальном времени используются в вычислениях больших данных в реальном времени.
2. Уровень сбора данных
Имея данные из базового источника данных, вам необходимо использовать инструменты ETL для завершения сбора, преобразования и загрузки данных. Такие компоненты предусмотрены в системе Hadoop. Например, вы можете использовать Sqoop для завершения обмена данными между платформой больших данных и реляционной базой данных, используя Flume для завершения сбора данных журнала; Помимо компонентов, предоставляемых самой системой платформы больших данных, типичным методом сбора данных также являются сканеры. Конечно, вы также можете использовать сторонние инструменты сбора данных, такие как DataX и CDC, для завершения работы по сбору данных.
Чтобы решить проблему связи между уровнем источника данных и уровнем сбора данных, между этими двумя уровнями можно добавить шину данных. Шина данных не обязательна. Она введена только для уменьшения связи между уровнями при проектировании архитектуры системы.
3. Уровень платформы больших данных
Это базовый уровень всей системы больших данных, который используется для хранения больших данных и вычислений с большими данными. Поскольку платформу больших данных можно рассматривать как метод реализации хранилища данных, ее можно разделить на автономное хранилище данных и хранилище данных в реальном времени. Они представлены отдельно ниже.
- Реализация автономного хранилища данных на основе технологии больших данных
После того как базовый уровень сбора данных получит данные, их обычно можно сохранить в HDFS или HBase. Затем автономные вычислительные механизмы, такие как MapReduce, Spark Core и Flink DataSet, завершают анализ и обработку автономных данных. Чтобы иметь возможность единообразно управлять и планировать различные вычислительные механизмы на платформе, эти вычислительные механизмы можно запускать на Yarn, а затем использовать программы Java или Scala для выполнения анализа и обработки данных; Чтобы упростить разработку приложений, система платформы больших данных также поддерживает использование операторов SQL для обработки данных, то есть предоставляются различные механизмы анализа данных, такие как Hive в системе Hadoop, а его поведение по умолчанию — Hive на MapReduce. Таким образом, стандартный SQL можно написать в Hive, а движок Hive преобразует его в MapReduce, а затем запускает в Yarn для обработки больших данных. Помимо Hive, распространенные механизмы анализа больших данных включают Spark SQL и Flink SQL.
- Реализация хранилища данных в режиме реального времени на основе технологии больших данных
После того, как базовый уровень сбора данных получает данные в реальном времени, чтобы сохранить данные и обеспечить их надежность, собранные данные могут быть сохранены в системе обмена сообщениями Kafka, а затем использованы различными вычислительными механизмами реального времени, такими как; как Storm, Spark Stream и Flink DataStream для обработки. Как и автономные хранилища данных, эти вычислительные механизмы могут работать на Yarn и поддерживать операторы SQL для обработки данных в реальном времени.
В процессе реализации автономного хранилища данных и хранилища данных в реальном времени могут использоваться некоторые общие компоненты, такие как использование MySQL для хранения метаинформации, использование Redis для кэширования, включая использование ElasticSearch (сокращенно ES) для завершения поиска данных. и т. д.
4. Уровень хранилища данных
При поддержке уровня платформы больших данных можно дополнительно построить уровень хранилища данных. При построении модели хранилища данных ее можно построить на основе модели звезды или модели снежинки. Витрины данных и алгоритмы машинного обучения, упомянутые ранее, также можно отнести к этому уровню.
5. Прикладной уровень
Благодаря различным моделям данных и данным на уровне хранилища данных на основе этих моделей и данных можно реализовать различные сценарии приложений. Например: анализ популярных продуктов в электронной коммерции, анализ социальных сетей в графовых вычислениях, внедрение рекомендательных систем, контроль рисков, прогнозирование поведения и т. д.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
