Учебное пособие по Hadoop: изучение важных компонентов эпохи больших данных — обзор Hadoop
Предисловие
В современную эпоху больших данных обработка огромных объемов данных стала критически важной задачей. Hadoop представляет собой инфраструктуру распределенных вычислений с открытым исходным кодом и представляет собой мощное решение для крупномасштабной обработки и хранения данных. В этой статье мы познакомимся с составом Hadoop и его важной ролью в обработке больших данных, а также позволим нам вместе отправиться в путь изучения Hadoop.
Обзор Hadoop
Что такое Хадуп
1) Hadoop — это инфраструктура распределенной системы, разработанная Apache Foundation. 2) В основном решают проблемы хранения больших объемов данных, а также анализа и расчета больших объемов данных. 3) В общих чертах, Hadoop обычно относится к более широкому понятию — экосистеме Hadoop.
Три основные версии Hadoop (понятно)
Существует три основных дистрибутива Hadoop: Apache, Cloudera и Hortonworks. Самая оригинальная (самая базовая) версия Apache, лучше всего подходит для вводного обучения. 2006 г. Cloudera внутренне интегрирует множество инфраструктур больших данных, что соответствует продукту CDH. 2008 год Hortonworks имеет лучшую документацию и соответствует продукту HDP. 2011 год Компания Hortonworks теперь приобретена Cloudera и запустила новый бренд CDP.
Apache Hadoop
Официальный адрес сайта Скачать адрес:https://hadoop.apache.org/releases.html
Cloudera Hadoop
Официальный адрес сайта:https://www.cloudera.com/downloads/cdh Скачать адрес (1)2008 Cloudera, основанная в 2006 году, была первой компанией, которая коммерциализировала Hadoop, предоставив партнерам Hadoop. Коммерческие решения в основном включают поддержку, консультационные услуги и обучение. (2)2009 Год Hadoop Основатель Дуг Cutting Также присоединяйтесь Cloudera компания. Клаудера Владелец продукта Для CDH, Cloudera Manager,Cloudera Support (3) CDH — это дистрибутив Hadoop от Cloudera, с полностью открытым исходным кодом и лучше, чем Apache. Hadoop в совместимости, безопасности Безопасность и стабильность были повышены. Прейскурантная цена Cloudera составляет 10 000 долларов США за узел. (4)Cloudera Manager Это платформа мониторинга распространения и управления кластерным программным обеспечением, которую можно развернуть в течение нескольких часов. Кластер Hadoop и выполняйте мониторинг узлов и сервисов кластера в режиме реального времени.
Hortonworks Hadoop
Официальный адрес сайта Скачать адрес:https://hortonworks.com/downloads/#data-platform
(1) Hortonworks, основанная в 2011 году, является совместным предприятием Yahoo! и венчурной компании Benchmark из Кремниевой долины. Совместное капиталовложение. (2) В начале своего создания компания привлекла около 25–30 инженеров Yahoo, специализировавшихся на Hadoop. Инженеры начали помогать Yahoo в разработке Hadoop в 2005 году и внесли 80% кода Hadoop. (3)Hortonworks Флагманский продукт — Hortonworks. Data Платформа (HDP) также открыта на 100%. Исходные продукты HDP помимо общих проектов также включают Ambari, систему установки и управления с открытым исходным кодом. (4)2018ГодHortonworks Его приобрела Cloudera.
Преимущества Hadoop (4 High)
1) Высокая надежность: Hadoop поддерживает несколько копий данных на нижнем уровне, поэтому даже если определенный вычислительный элемент Hadoop Даже если элемент или хранилище выйдет из строя, данные не будут потеряны.

2) Высокая масштабируемость: распределение данных задач между кластерами позволяет легко расширить тысячи узлов.
3) Эффективность. Согласно идее MapReduce, Hadoop работает параллельно, чтобы ускорить обработку задач. скорость обработки.
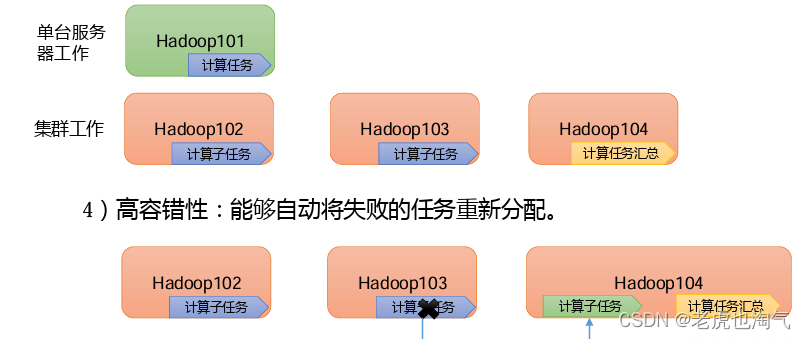
4) Высокая отказоустойчивость: возможность автоматического переназначения невыполненных задач.

Композиция Hadoop (тема интервью)
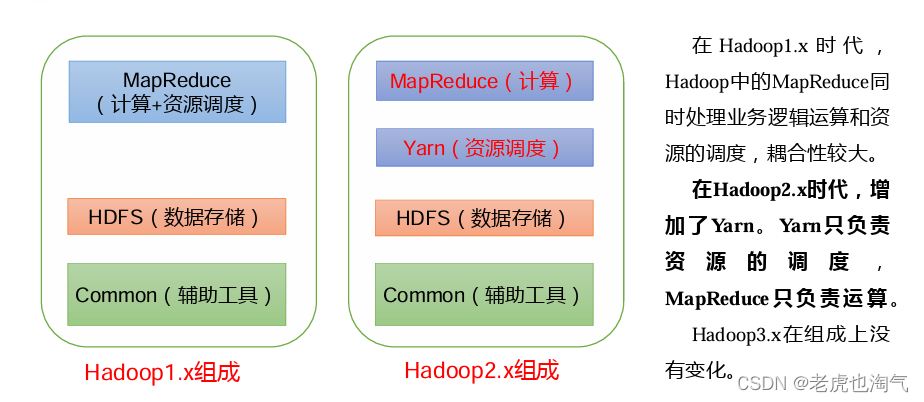
Обзор архитектуры HDFS
Распределенная файловая система Hadoop, сокращенно HDFS, представляет собой распределенную файловую систему.
- 1) NameNode (nn): элемент хранилища данных файла.,Например, имя файла,Структура каталогов файлов,Свойства файла(Время генерации、Количество дополнительных книг、 права доступа к файлам), а также список блоков каждого файла и DataNode, где расположены блоки, и т. д.
- 2) DataNode (dn): В локальной файловой системе хранится файл блока данных и контрольная сумма блока данных.
- 3)Secondary NameNode(2nn): время от времени создайте резервную копию элементов NameNode.
Обзор архитектуры YARN
Еще один переговорщик ресурсов, или сокращенно YARN, является еще одним координатором ресурсов и менеджером ресурсов Hadoop.
- 1) ResourceManager (RM): хозяин всех ресурсов кластера (памяти, процессора и т.д.)
- 2) NodeManager (NM): лидер среди серверных ресурсов с одним узлом.
- 3) ApplicationMaster (AM): руководитель выполнения одной задачи.
- 4) Контейнер. Контейнер — это вполне независимый сервер, который инкапсулирует ресурсы, необходимые для выполнения задач, такие как память, процессор, диск, сеть и т. д.
Примечание 1. Клиентов может быть несколько.
Примечание 2. В кластере можно запускать несколько ApplicationMasters.
Примечание 3. В каждом NodeManager может быть несколько контейнеров.
Обзор архитектуры MapReduce
MapReduce делит процесс вычислений на два этапа: Map и уменьшить. 1) Этап Map параллельно обрабатывает входные данные. 2) Этап сокращения обобщает результаты карты.
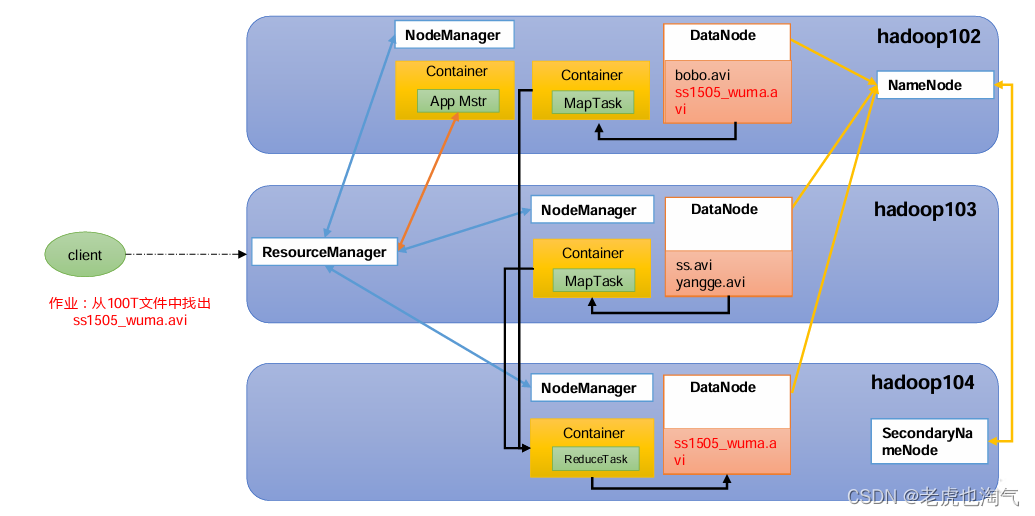
Взаимосвязь между HDFS, YARN и MapReduce
Экосистема технологий больших данных
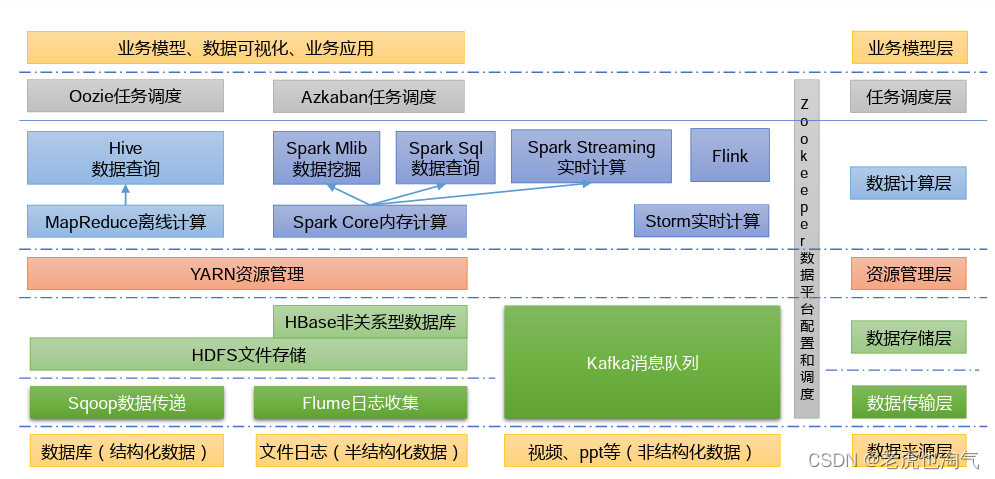
Технические термины, представленные на рисунке, поясняются следующим образом: Видео, ppt и т. д. (неструктурированные данные) Уровень источника данных 1) Sqoop: Sqoop — это инструмент с открытым исходным кодом, в основном используемый для Hadoop, Hive и традиционных баз данных (MySQL). Для переноса данных можно импортировать данные из реляционной базы данных (например: MySQL, Oracle и т.д.) В HDFS Hadoop данные HDFS также можно импортировать в реляционную базу данных. 2) Flume: Flume — это высокодоступная, высоконадежная распределенная система для сбора, агрегирования и передачи массивных журналов. Flume поддерживает настройку различных отправителей данных в системе журналов для сбора данных; 3) Kafka: Kafka — это высокопроизводительная распределенная система обмена сообщениями типа «публикация-подписка»; 4) Spark: в настоящее время Spark является самой популярной платформой для вычислений в памяти больших данных с открытым исходным кодом. Может быть основан на больших числах, хранящихся в Hadoop. рассчитывается на основе данных. 5) Flink: Flink в настоящее время является самой популярной платформой для вычислений в памяти больших данных с открытым исходным кодом. Существует множество сценариев вычислений в реальном времени. 6) Oozie: Oozie — это система управления планированием рабочих процессов для управления заданиями Hadoop. 7) Hbase: HBase — это распределенная, ориентированная на столбцы база данных с открытым исходным кодом. HBase отличается от обычных реляционных баз данных. Это база данных, подходящая для хранения неструктурированных данных. 8) Hive: Hive — это инструмент хранилища данных на основе Hadoop, который может отображать файлы структурированных данных в Таблица базы данных и предоставляет простую функцию запроса SQL, которая может преобразовывать операторы SQL в задачи MapReduce для работы. ХОРОШО. Его преимущество состоит в том, что стоимость обучения невелика, а простую статистику MapReduce можно быстро реализовать с помощью SQL-подобных операторов без необходимости открывать Разработайте специализированные приложения MapReduce, которые очень подходят для статистического анализа хранилищ данных. 9) ZooKeeper: это надежная система координации для больших распределенных систем. Предоставляемые функции включают: обслуживание конфигурации. Служба имен, распределенная синхронизация, групповая служба и т. д.
Схема структуры системы рекомендаций
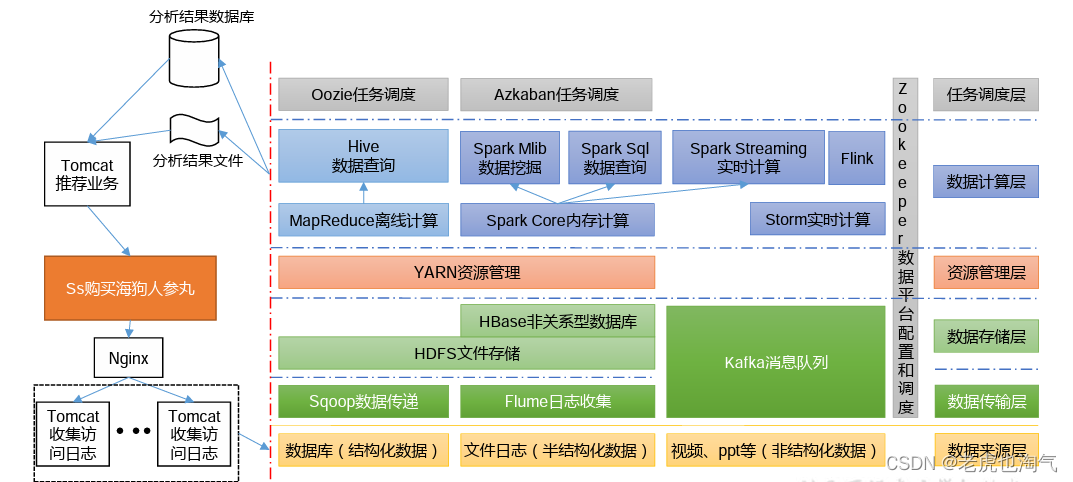
Подведите итог:
Hadoop — важная часть эпохи больших данных. Его распределенная файловая система HDFS и инфраструктура распределенных вычислений MapReduce составляют ядро Hadoop. Появление Hadoop привело к появлению новых решений для крупномасштабной обработки и хранения данных, а его высокая масштабируемость, отказоустойчивость и экономичность стали важными характеристиками, привлекающими пользователей.
Сегодня мы сосредоточимся на понимании и понимании Hadoop, полностью ознакомимся с его составом и деталями и поможем нам лучше его изучить.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
