Цифровой интеллект в управлении эксплуатацией и техническим обслуживанием: практика использования данных и интеллектуальные сценарии эксплуатации и технического обслуживания
Эта статья предоставлена пользователем сообщества Tencent Blue Whale Zhiyun: CanWay.
краткое содержание:Автор опирается на собственное техническое и отраслевое понимание.,Поделитесь данными Jiawei Blue Whale и практикой интеллектуальных сценариев эксплуатации и технического обслуживания.
Использование ключевых слов:Комплексная эксплуатация и техническое обслуживание、Эксплуатация и обслуживание платформы、Цифровое интеллектуальное управление и обслуживание、AIOps、Эксплуатация и обслуживание PaaS、Система инструментов для эксплуатации и технического обслуживания、Синий кит и т. д.
Автор этой статьи:Менеджер по продуктам и решениям Jiawei Blue Whale по эксплуатации и техническому обслуживанию Чжан Минь, генеральный директор линейки продуктов Blue Whale Platform Чжоу Цзунпей
Полный текст состоит из 6500 слов, а предполагаемое время чтения — 14 минут.
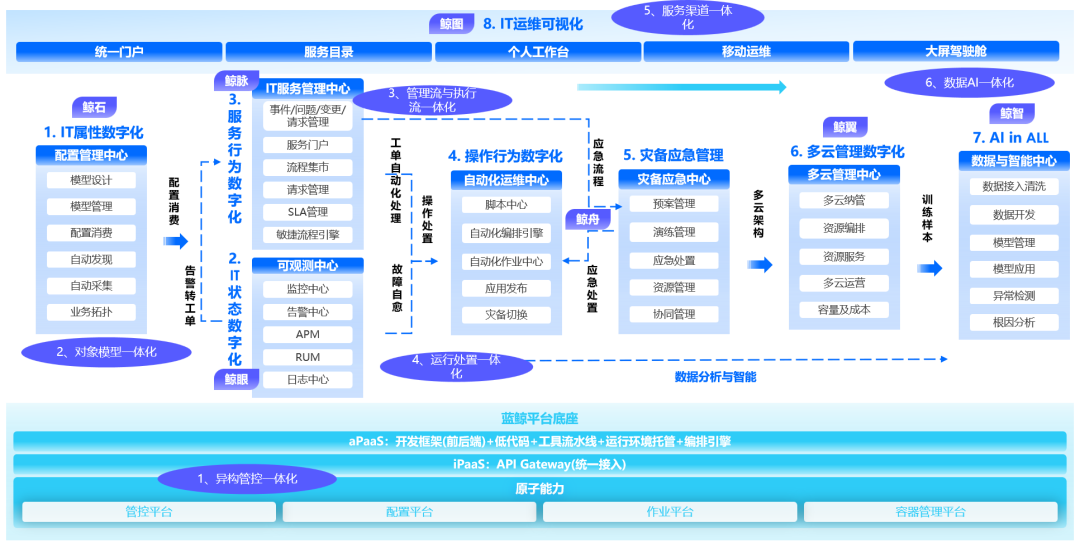
Позиционирование данных и интеллектуальных технологий в бизнесе по эксплуатации и техническому обслуживанию.
Применение данных и интеллектуальных технологий в сфере эксплуатации и технического обслуживания в последние годы вступило в «стадию практического совершенствования». Как сторона предложения, так и сторона спроса постепенно осознали, что «данные и интеллектуальная» эксплуатация и обслуживание имеют свои границы и условия. «ИИ поддерживает эксплуатацию и техническое обслуживание» звучит шире, чем «ИИ подрывает эксплуатацию и техническое обслуживание»; мы рады видеть, что Стороны А и Стороны Б больше ориентированы на практические бизнес-сценарии: технические средства, основанные на данных и интеллекте, для дополнения и улучшения; комплексная эксплуатация и техническое обслуживание.
Возвращаясь к сути бизнеса, на сложность эксплуатации и обслуживания влияют сценарии управления и технические объекты. Поэтому мы возвращаемся к определению интегрированной эксплуатации и обслуживания: интеграции ролей, процессов, действий (объектов) и систем инструментов. с точки зрения бизнеса по эксплуатации и техническому обслуживанию. Бесперебойная бизнес-операция, высокоскоростная работа процессов и эффективная поддержка инструментов являются основными проверками интеграции эксплуатации и обслуживания. Интеграция эксплуатации и обслуживания — это не просто комплексные инструменты и полные технические функции одного инструмента. , но оно должно быть интегрировано в бизнес-дизайн и всю систему. Таким образом, данные и интеллект — это своего рода производительность, особенно в сценариях интеграции данных и анализа высокого порядка, что приводит к общему улучшению.
Позиционирование больших данных эксплуатации и обслуживания в эксплуатации и техническом обслуживании: в системах с несколькими источниками данных можно реализовать анализ источников данных в таких измерениях, как конфигурация, эксплуатация, эксплуатация и процесс, а также улучшить возможности эксплуатации и обслуживания, такие как производительность, наблюдение. интеграция и анализ операций. Например: в соответствии с наблюдаемой архитектурой универсального замкнутого цикла данных и функций сбор, очистка, хранение, обнаружение и потребление данных являются самозамкнутыми, и продукт имеет встроенные возможности обработки больших данных. Однако, поскольку источники данных поступают из различных профессиональных инструментов мониторинга, требования к доступу к данным, унифицированным метаданным и маркировке данных становятся выше. Поэтому для управления и обработки необходимы эксплуатация и обслуживание больших данных.
Позиционирование технологии искусственного интеллекта в эксплуатации и обслуживании. Благодаря машинному обучению, обработке естественного языка, большим языковым моделям и другим технологиям искусственного интеллекта ИИ in Все это направлено на поддержку возможностей исходной системы эксплуатации и обслуживания, а также на улучшение возможностей эксплуатации и обслуживания, таких как управление отказами, оптимизация обслуживания, экономия средств и повышение безопасности. Например: В центре событий аварийной сигнализации комплексной эксплуатации и технического обслуживания ядром является доступ к аварийным сигналам, стандартизация и расширение, Конвергенция. сигналов тревоги、щит、делегат、Создать событие、Автоматизированная утилизация,Когда шкала достигает определенного уровня, количество сигналов тревоги,Такие алгоритмы, как сходство текста, необходимы для интеллектуального агрегирования сигналов тревоги.,Или интеллектуальное агрегирование на основе графов.,Это может привести к дальнейшему обновлению на исходной основе.
Краткое описание: Операция и обслуживание больших данных и ИИ являются техническими возможностями, и ядро должно применяться к бизнес-сценариям эксплуатации и обслуживания. Существует три основных основы: базовая система эксплуатации и обслуживания предоставляет данные и возможности, платформа данных и ИИ; обеспечивает возможности обработки данных и обучения моделей, а система эксплуатации и обслуживания обеспечивает возможности обработки данных и обучения моделей, а инженеры-алгоритмы и команды обеспечивают организационную поддержку.
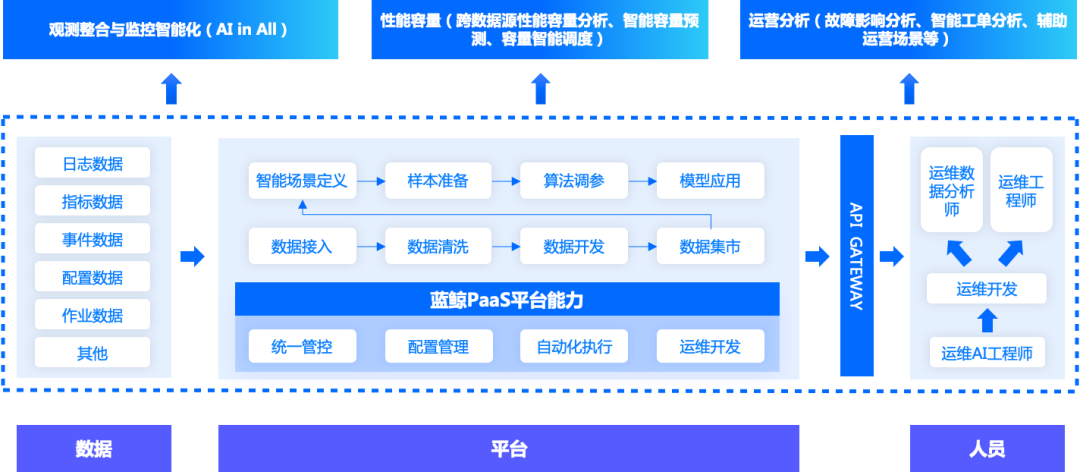
Рисунок 1. Данные и интеллектуальная бизнес-архитектура
Практика сценариев эксплуатации и обслуживания анализа больших данных
Во-первых, первоначально определите область данных по эксплуатации и техническому обслуживанию, которую можно условно разделить на 5 областей:
1. Область конфигурации: основная информация, технические параметры и информация о корреляции различных типов электронного информационного оборудования в системах управления ИТ-активами и управлении конфигурацией, включая ПК, серверы, устройства хранения данных, сетевое оборудование, оборудование безопасности, вспомогательное оборудование и среду компьютерного зала. Оборудование, пакетное программное обеспечение и прикладное системное программное обеспечение и т. д.
2. Область состояния: производительность программного и аппаратного обеспечения оборудования, состояние, события, журналы, сигналы тревоги и практические данные, собранные с помощью ИТ-мониторинга, автоматизированной эксплуатации и обслуживания, мониторинга безопасности и т. д.
3. Домен процесса: связанные данные записи, генерируемые при выполнении бизнес-процесса в процессе управления эксплуатацией и обслуживанием.
4. Область эксплуатации: данные процесса выполнения операции и данные аудита операции, такие как автоматизированные операции, самовосстановление неисправностей и организация этапов устранения.
5. Область знаний: опыт обработки инцидентов, связанных с неисправностями, и другие соответствующие базы знаний, существующие в форме тем знаний, указателей ключевых слов, контента и т. д.
Необходимо определить несколько вопросов, лежащих в основе структуры управления данными:
Как спроектировать логику и связь между данными эксплуатации и технического обслуживания?
Каково позиционирование платформы эксплуатации и обслуживания больших данных?
Как продолжать строить сценарии потребления данных?
Как интегрировать данные и ИИ?
Ключевая логика:
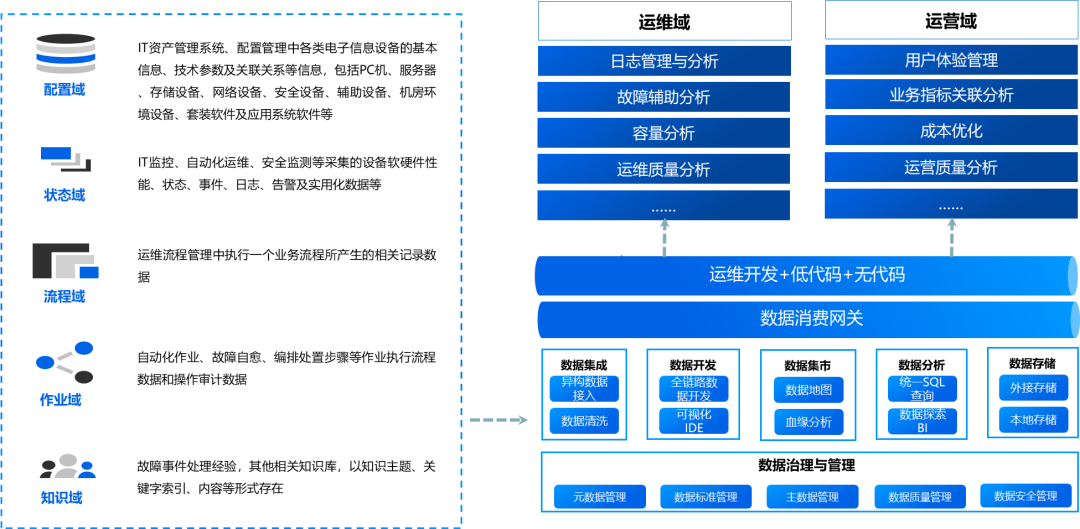
Рисунок 2. Архитектура управления, основанная на данных эксплуатации и технического обслуживания.
Вот несколько практических рекомендаций:
1. Сценарий потребления фокусируется на высокопроизводительных возможностях эксплуатации и обслуживания, которые повышают производительность, интеграцию наблюдения и операционный анализ, особенно при интеграции наблюдения, текущая наблюдаемость в основном сосредоточена на анализе и позиционировании неисправностей на основе структуры управления данными, маркировки данных. может быть завершена унификация, расчет агрегации данных, информационная плоскость ассоциации данных, приложение модели искусственного интеллекта и т. д. Например, одна из сцен наблюдения может расширять трассировку, журнал, метрику, представление сцены, ассоциацию базы знаний, анализ ассоциации изменений событий и т. д. на основе перспективы тревоги для формирования предварительного сценария анализа интеграции наблюдений:
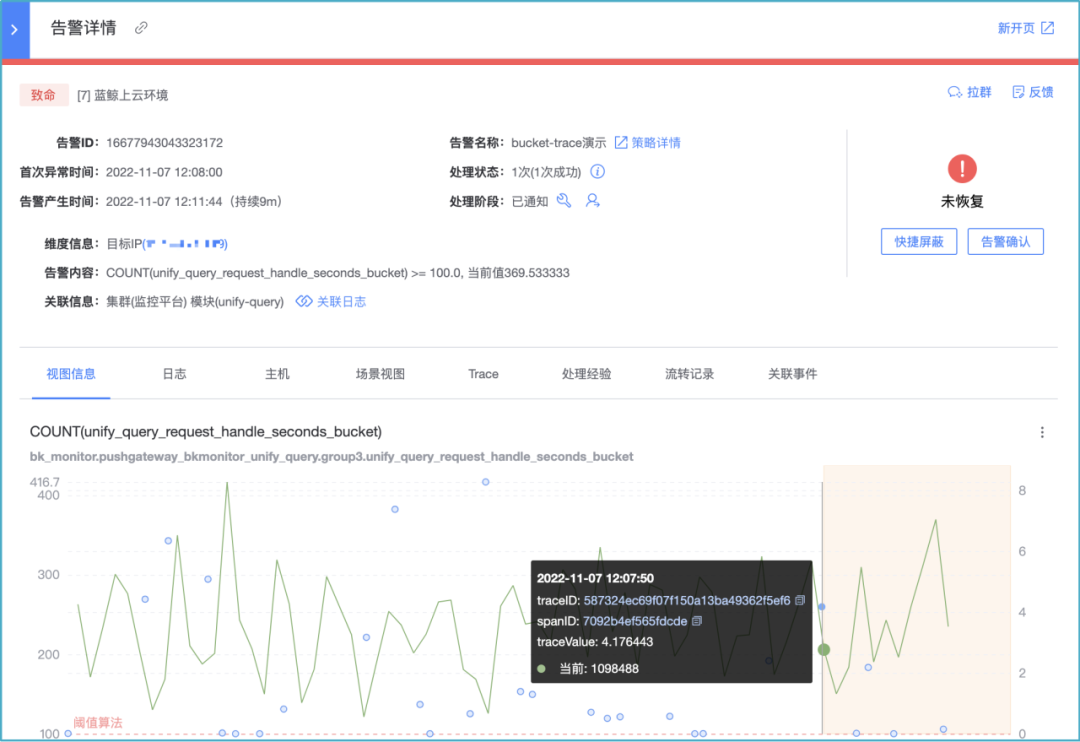
Рисунок 3: Пример сцены наблюдения с точки зрения тревоги
2. Техническая ценность в основном отражается в сложных и крупномасштабных требованиях к очистке, разработке и хранению данных; расчеты ассоциации данных между источниками данных для реализации ассоциации образцов данных и источников данных, а также реализации разработки и применения; Модели AIOps.
3. Управление данными использует профессиональную децентрализованную модель управления, основанную на потреблении. Профессиональная децентрализация означает, что CMDB, Metric, Trace, Log и т. д. используются в профессиональных инструментах управления, а управление на основе потребления основано на вызовах сценариев, а затем на доступе к данным. Теги, связанные вычисления и т. д. поддерживают приложения сценариев, основанные на данных.
Что касается прикладной архитектуры самой платформы данных эксплуатации и технического обслуживания, то основные функции, которые должна иметь платформа данных эксплуатации и технического обслуживания, включают сбор данных и доступ к ним, очистку и обработку данных, хранение данных, разработку данных, исследование данных, витрины данных и т. д. ., и он должен иметь возможности мета-управления, а также возможности самостоятельного управления и обслуживания, такие как данные, качество и безопасность данных. В процессе управления данными эксплуатации и технического обслуживания мы должны не только обращать внимание на «стабильность», «безопасность» и «надежность», но также обращать внимание на «опыт», «эффективность» и «выгоду».
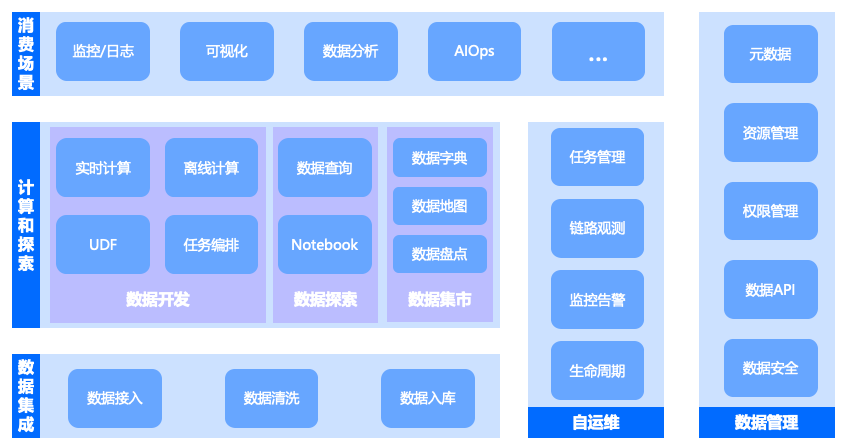
Рисунок 4. Функциональная архитектура эксплуатации и обслуживания платформы больших данных.
Практика сценариев эксплуатации и обслуживания ИИ
Возможности анализа данных и алгоритмов и принятия решений являются основными возможностями реализации сценариев AIOps. На основе высококачественных унифицированных данных по эксплуатации и техническому обслуживанию с малой задержкой, предоставляемых платформой данных по эксплуатации и техническому обслуживанию, интеллектуальная платформа анализа и принятия решений может использовать подходящие алгоритмы и модели искусственного интеллекта для вынесения разумных суждений или выводов в соответствии с потребностями различные сценарии и управлять платформой автоматического управления и контроля для выполнения операций по эксплуатации и техническому обслуживанию.
Таким образом, основным модулем платформы интеллектуального анализа и принятия решений является платформа искусственного интеллекта/машинного обучения. Подобно общеотраслевой платформе машинного обучения, она должна иметь базовые функции, такие как интеграция и расчет данных, разработка и обучение моделей, развертывание моделей и логические выводы. Однако для поддержки сценариев AIOps платформе необходимо добавить некоторые функции в области эксплуатации и обслуживания для эффективной разработки алгоритмов и моделей, которые адаптируются к различным сценариям интеллектуальной эксплуатации и обслуживания.
Прежде всего, интеллектуальная платформа анализа и принятия решений должна создать модель данных эксплуатации и технического обслуживания, систему индикаторов и график знаний. Эта функция ориентирована на масштабируемые сценарии искусственного интеллекта, опирается на платформу данных эксплуатации и обслуживания и использует метод циклической итерации «сбор, управление, применение и сбор». Благодаря постоянным попыткам реализовать сценарии AIOps выявляются, дополняются и улучшаются проблемы с качеством данных.
Во-вторых, конечными пользователями платформы интеллектуального анализа и принятия решений является персонал по эксплуатации и техническому обслуживанию. Поэтому необходимо иметь возможности низкопорогового моделирования сцен на основе процессов и использовать графическое моделирование в стиле мастера. Таким образом, алгоритмы, которые сложно понять персоналу по эксплуатации и техническому обслуживанию, можно превратить в «компоненты», а сложный процесс настройки параметров во время обучения модели можно превратить в «регулировку чувствительности», тем самым популяризируя зрелые сценарии ИИ среди большего числа предприятий. быстро.
Наконец, концепция DevOps в области эксплуатации и обслуживания может быть внедрена в процесс разработки алгоритмов и моделей для ускорения разработки сценариев ИИ.
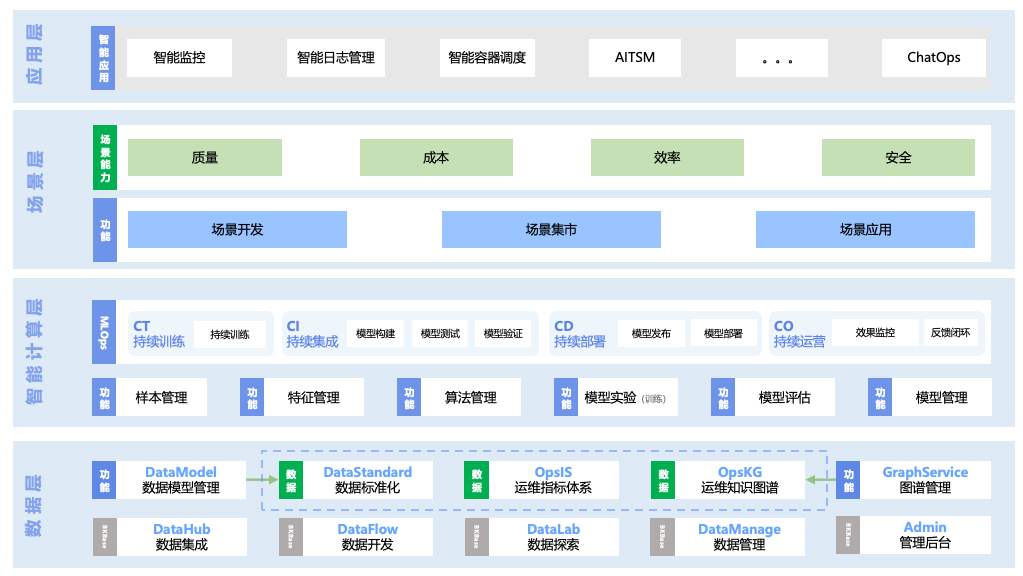
Рисунок 5. Функциональная архитектура платформы искусственного интеллекта.
Обнаружение аномалий индикатора
Обнаружение аномалий Индикатор является основой для построения других сценариев интеллектуальной эксплуатации и обслуживания. Он относится к единому сценарию. Результаты обнаружения аномалий будут использоваться для последующей Конвергенции. сигналов Обеспечьте важные входные данные для таких сценариев, как температура, местонахождение неисправности и самовосстановление неисправности. Индикаторы обычно делятся на бизнес-показатели (такие как посещения, скорость ответа, время ответа и т. д.) и показатели производительности (ЦП, память, операции ввода-вывода, сетевой трафик и т. д.), при этом несколько независимых или реляционных показателей могут быть агрегированы для формирования различных показателей. многомерные показатели. аномалий индикатор. Вот подробное введение в блок производительности «Обнаружение». аномалий индикатора。
Производительность Обнаружение аномалий индикатора может использовать общую схему обнаружения аномалий с использованием извлечения признаков временных рядов и глубокого байесовского обучения.,Учитывает характеристики разных типов кривых (периодические, устойчивые, разреженные).,Он может удовлетворить потребности в обнаружении аномалий в данных временных рядов, таких как машинные индикаторы и бизнес-индикаторы.
Процесс обнаружения общего индикатора «Обнаружение аномалий» разделен на две части: извлечение аномальных закономерностей и контролируемое обнаружение аномалий:
① На этапе извлечения аномальных закономерностей на основе теории вероятностей, теории экстремальных значений, теории остатков и т. д. из данных временных рядов извлекаются признаки, которые могут характеризовать аномальные закономерности данных во многих аспектах.
② На этапе контролируемого обнаружения аномалий используется глубокая байесовская модель, основанная на активном обучении, которая может изучать неизвестные закономерности аномалий и некоторые пользовательские предпочтения на основе отзывов пользователей при обнаружении аномалий.
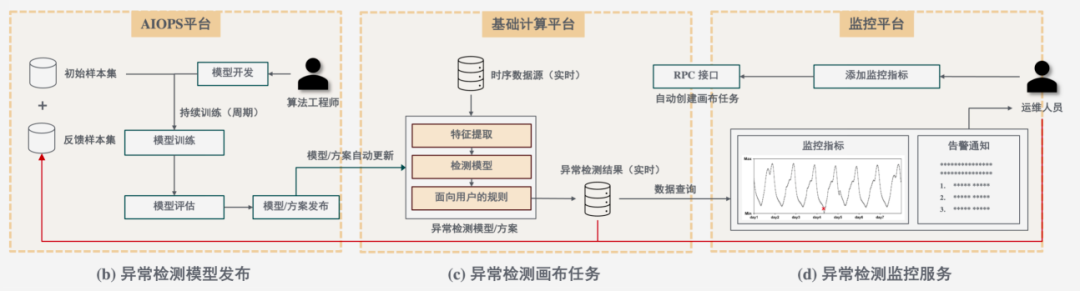
Рисунок 6: Модель обнаружения аномалий
один Обнаружение аномалий Индикатор может быть интегрирован в продукты мониторинга. Когда загрузка ЦП внезапно падает, а использование диска внезапно падает, общее общее обнаружение. аномалий Алгоритм индикатора может обнаруживать выбросы,Детали тревоги могут отображаться в центре тревог. Включая содержимое сигналов тревоги,и связанные с ними размеры. Как показано ниже,При обнаружении отклонения от нормы,будет отмечен (красный квадрат).
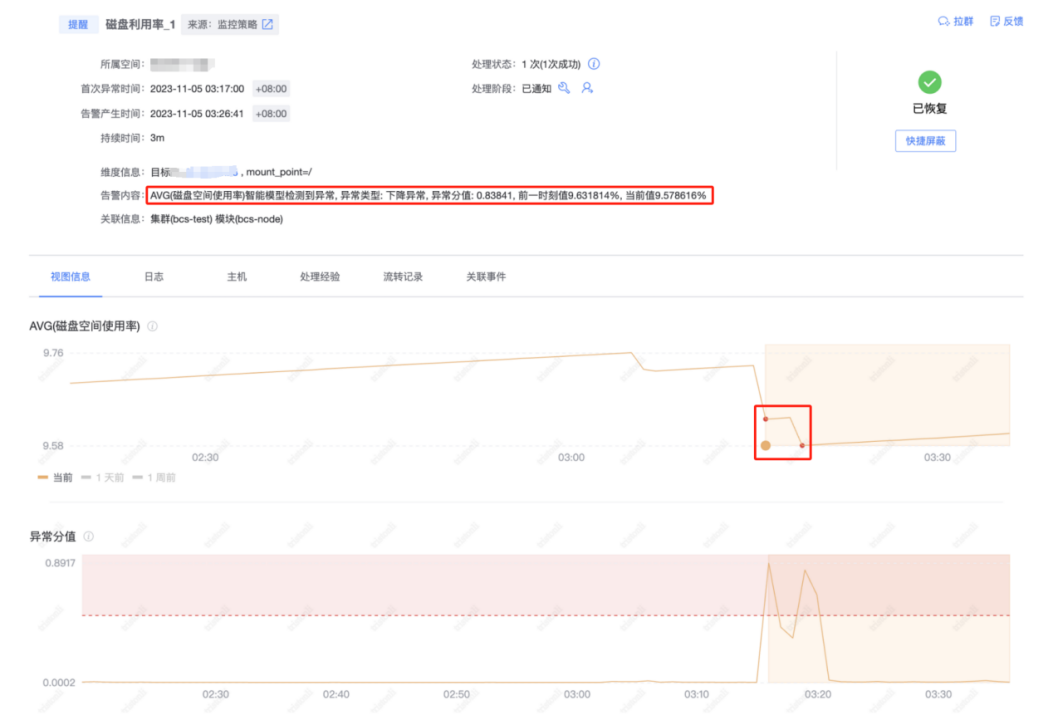
Рисунок 7. Приложение модели обнаружения аномалий.
Прогнозирование данных временных рядов
В сфере эксплуатации и обслуживания ИТ,Тестовые информационные системы,Будет генерировать большое количество данных временных рядов различных типов.,Например, количество онлайн-пользователей, загрузка процессора хоста и т. д. Используйте историческое время,Данные последовательности предсказывают тенденцию изменения данных в будущем.,Он может удовлетворить потребности в прогнозировании времени различных крупных онлайн-бизнесов, таких как процессор, использование диска, количество людей в сети и т. д.,Обеспечьте пользователям точную и мощную поддержку данных для принятия важных решений (например, управление ресурсами, аварийные сигналы и т. д.).
Прогнозирование данных временных рядов — это метод прогнозирования временных рядов, основанный на Transformer.,Трансформатор — наиболее успешная архитектура модели последовательности.,Он имеет очень существенные преимущества в обработке естественного языка (НЛП), распознавании речи и компьютерном зрении. Модель прогнозирования временных рядов на основе трансформатора,Связанные сценарии, которые широко используются, включают оценку транспортных потоков, управление энергопотреблением, финансы и другие области. В области эксплуатации и технического обслуживания он в основном прогнозирует данные долгосрочных временных рядов.,Например, прогнозирование мощности ресурсов (например, процессора сервера, памяти), прогнозирование затрат и т. д.
В рамках проекта разрабатывается набор служб прогнозирования временных рядов на основе модели Transformer, которая объединяет трансферное обучение и постепенное обучение.,Он работает путем нормализации показателей временных рядов на разных частотах.,чтобы гарантировать возможность совместного использования моделей в нескольких исходных системах,Используйте модель Трансформатора, основанную на байесовской оценке, для создания прогнозируемых предельных распределений.,В то же время в процесс обучения модели вводятся трансферное обучение и постепенное обучение, чтобы избежать риска отклонения концепции.,Обеспечьте долгосрочную прогнозирующую эффективность модели.
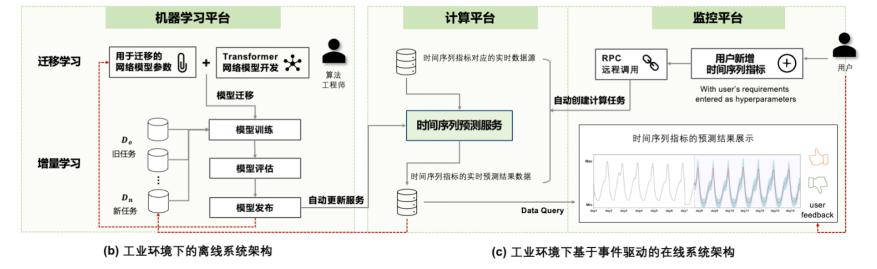
Рисунок 8: Модель обнаружения данных временных рядов
Прогнозирование данных временных Алгоритм рядов может быть интегрирован в такие сценарии, как анализ инвентаризации активов платформы управления конфигурацией, а также анализ мощности и прогнозирование платформы управления мощностью для анализа и прогнозирования будущей мощности ключевых приложений ИТ-системы, поддержки отображения отчетов и оказания помощи. клиентов в планировании ресурсов. На рисунке ниже показан сценарий эластичного расширения и сокращения бизнеса на платформе управления мощностью с использованием Прогнозирования. данных временных Модель рядовAI прогнозирует и анализирует загрузку ЦП кластера бизнес-серверов,И объединитесь с системой автоматизации для выполнения задач расширения и сжатия.,Обеспечивая стабильность бизнеса,Стоимость снижена на 30%.
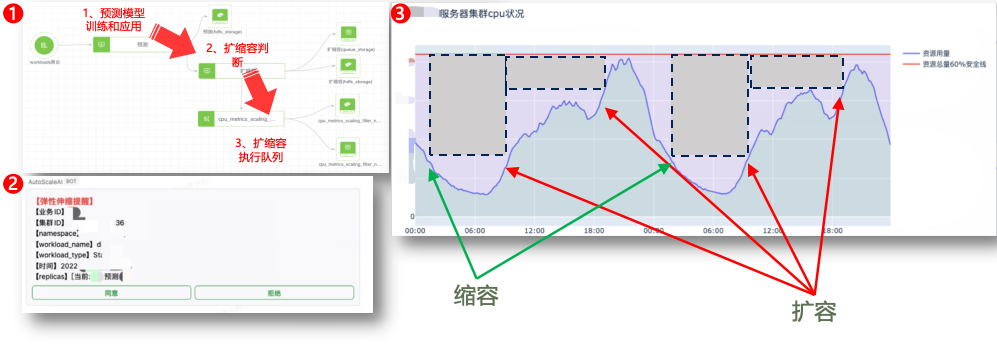
Рисунок 9: Применение модели обнаружения данных временных рядов
Многомерная детализация
Менеджерам бизнес-систем необходимо отслеживать большое количество индикаторов, чтобы понимать и поддерживать доступность системы. Обычно эти индикаторы включают в себя некоторые измерения. Например, индикатор, связанный с количеством вызовов микросервиса, может включать поставщика услуг (Интернет). Service Провайдер, интернет-провайдер), бизнес-информация об услугах и другие аспекты. Объединив различные измерения для суммирования показателей, можно полностью отобразить состояние системы в реальном времени с разной степенью детализации и под разными углами. Однако из-за проблемы комбинаторного взрыва измерений системным менеджерам обычно приходится фильтровать и концентрировать внимание на сводных значениях показателей по определенным комбинациям измерений, методами суммирования этих показателей могут быть суммирование, усреднение и т. д. Суммарное значение отфильтрованного индикатора также называется SLI. (Service Level Индикатор). При обнаружении аномалии в SLI для диагностики аномалии необходимо выяснить измерение, которое фактически вызвало аномалию в SLI, и комбинацию элементов в этом измерении. Этот процесс еще называют Многомерной. детализация。
на основе Многомерная На рисунке ниже показан процесс метода позиционирования первопричины многомерной индексной аномалии методом детализации и байесовской сети, который инициируется обнаруженной аномалией SLI. Многомерная Алгоритм детализации включает в себя два основных этапа: построение сопоставления измерений и детализация измерений. Сопоставление измерений строится для указания формулы расчета между каждым из наиболее детализированных показателей и SLI, формируемым в результате агрегирования. Эта формула расчета настраивается пользователем.,Пользователи могут настроить любой метод расчета индикатора SLI в соответствии с потребностями своего бизнеса. Требования пользователя к методам расчета индикатора SLI включают, помимо прочего, типы подсчета.,Тип суммы,тип усреднения,Найдите оптимальный тип,Найдите форму квантиля и пропорциональную форму. Детализация ненормальных размеров,Это значит использовать значение каждого наиболее детализированного индикатора в качестве входных данных.,Наконец, выясните размеры и соответствующие комбинации элементов, которые действительно вызывают отклонения в агрегированных показателях SLI. В связи с проблемой комбинаторного взрыва,Необходимо полностью изучить характеристики аномальных размеров.,Это достигается за счет разработки эвристических методов поиска.
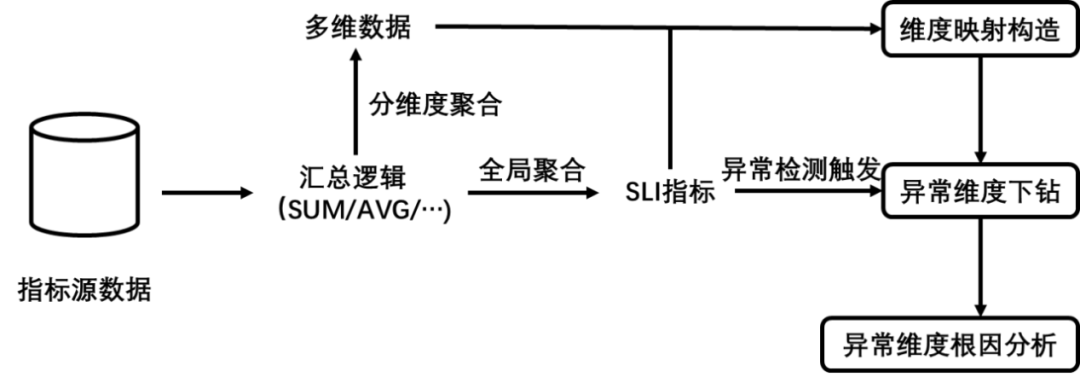
Рисунок 10: Многомерная детализация Логика модели
В некоторых случаях после детализации конкретных аномальных размеров необходимо дополнительно уточнить причинно-следственную связь между этими аномальными размерами. Окончательно выявленные размеры аномалий и их причинно-следственные связи будут предоставлены пользователям, чтобы помочь им в анализе первопричин сбоев в системе и быстром реагировании и восстановлении.
В политике сигналов тревоги с одним индексом в сценарии мониторинга, если полная информация об измерении не настроена, может оказаться невозможным точно определить, какое измерение вызвано текущей аномалией при тревоге. Функция детализации размеров может автоматически анализировать аномальную информацию о размерах и помогать в обнаружении проблем. Если обнаруживается аномалия в количестве людей, подключенных к сети для определенного бизнеса, путем детализации аномалии в этот момент времени предоставляются конкретные аномальные параметры (например, провинция пользователя, версия клиента и т. д.), а также конкретные значения измерений (включая сортировку), которые, скорее всего, будут ненормальными.
Рекомендации по корреляции индикаторов
В производственной среде системным менеджерам онлайн-систем необходимо управлять большим количеством объектов эксплуатации и обслуживания (например, ключевыми показателями производительности и другими показателями, описывающими возможности служб приложений, базовыми физическими объектами, такими как серверы, общедоступные и пользовательские компоненты), чтобы поддерживать доступность системы. Среди них каждый объект эксплуатации и обслуживания будет предоставлять системным менеджерам большое количество индикаторов мониторинга, позволяющих отслеживать состояние системы в режиме реального времени со всех аспектов. Обычно количество таких индикаторов мониторинга может достигать сотен или тысяч, и по мере развития наблюдаемости системы это число будет только расти. Большое количество индикаторов мониторинга утомляет системных администраторов от наблюдения и анализа, что существенно влияет на эффективность обнаружения и диагностики неисправностей.
Алгоритм «Рекомендации по корреляции индикаторов» разрабатывает метод рекомендации индикаторов мониторинга, основанный на аномальной частоте совпадения и случайном блуждании. Он состоит из двух основных частей: построения взаимосвязей показателей и рекомендаций по ключевым показателям. Чтобы построить индексную взаимосвязь, мы сначала рассчитываем частоту аномального совпадения и сходство кривых между парами показателей мониторинга.,Затем установите связь между показателями на основе частоты аномального совпадения.,и использовать обрезку сходства кривых,Избегайте лишних рекомендаций,Наконец, установите диаграмму взаимосвязи между показателями. Рекомендации по ключевым индикаторам используют алгоритм случайного блуждания для анализа диаграммы взаимосвязей индикаторов, полученной на предыдущем шаге.,Определить рекомендуемые рейтинги показателей мониторинга.
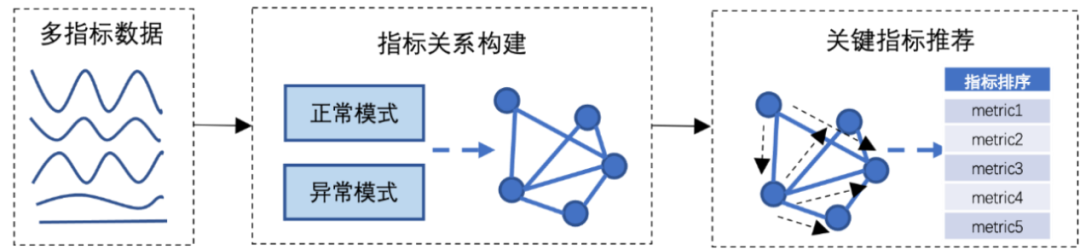
Рисунок 11: Рекомендации по корреляции индикаторов Модель
Политика сигналов тревоги с одним индикатором, настроенная для мониторинга, может предупреждать только об аномалиях одного индикатора. При устранении неполадок вам может потребоваться объединить связанные индикаторы, чтобы вручную определить основную причину. Функция рекомендации связанных индикаторов будет рекомендовать соответствующие индикаторы на основе наличия одновременных отклонений от нормы и формы кривой при возникновении тревоги. Как показано на рисунке ниже, была обнаружена аномалия в использовании дискового пространства сервера. По рекомендации связанных индикаторов были обнаружены 7 других связанных индикаторов на уровне [операционной системы] (показаны только 3 примера), и там. были аномалии схожей формы или в одно и то же время.
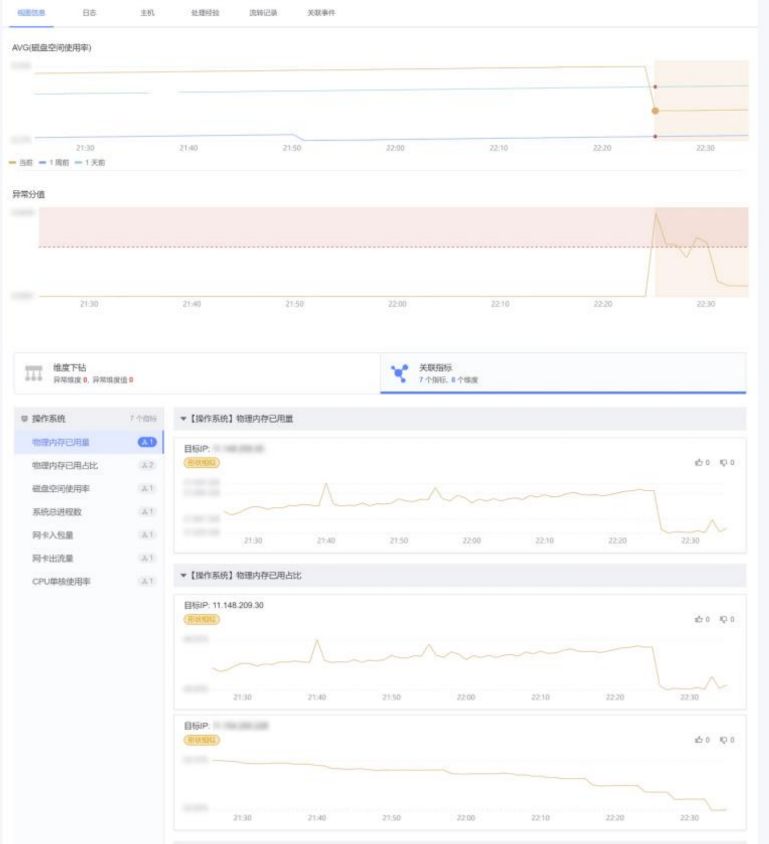
Рисунок 12: Рекомендации по корреляции индикаторов Модель应用
Кластеризация журналов
Кластеризация Основной процесс журналов заключается в том, что после предварительной обработки журналов журналы с высоким сходством собираются вместе путем расчета сходства между журналами, а шаблон журнала генерируется посредством распознавания образов, тем самым получая Кластеризацию. журналов Модель,Для использования при поиске журналов и прогнозировании в реальном времени.,Уменьшите нагрузку эксплуатационного и обслуживающего персонала при просмотре массивных разнородных журналов.
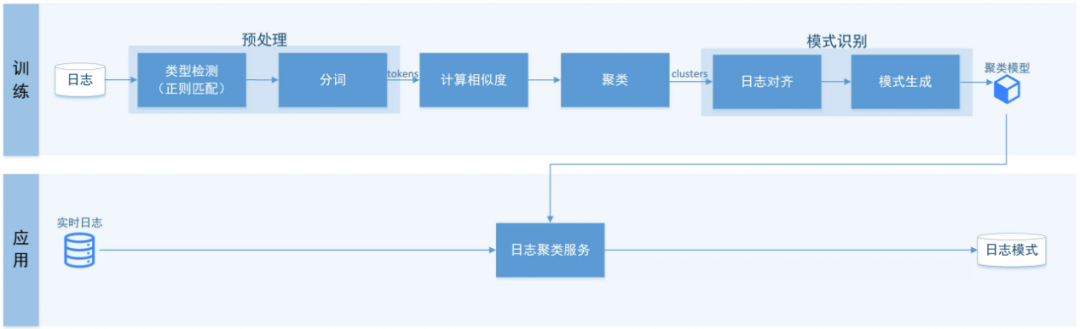
Рисунок 13: Кластеризация журналов Модель
Кластеризация заключается в том, чтобы найти максимальное сходство между сегментацией слов журнала и существующими кластерами, выполнить пороговую дискриминацию и поместить ее в соответствующий класс/создать новый класс.
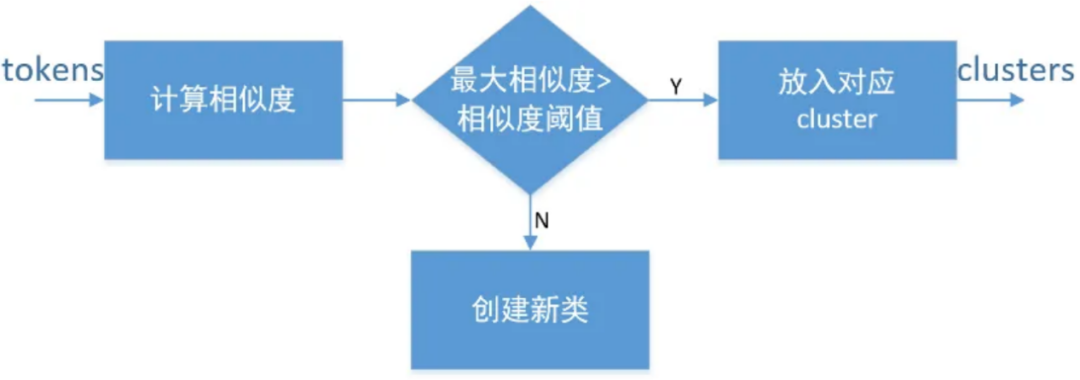
Рисунок 14: Модель сходства журналов
Распознавание образов заключается в извлечении шаблонов журналов из кластеров. Распознавание образов включает в себя выравнивание журналов и создание образов.
Выравнивание журналов. Лучший способ выровнять журналы — создать минимальное количество подстановочных знаков и переменных после слияния. В процессе выравнивания между сегментами слов могут быть вставлены некоторые пробелы. Алгоритм выравнивания гарантирует, что длины журналов одного и того же класса будут равны после вставки GAP.
Генерация шаблона: после получения журналов одинаковой длины пройдите по сегментациям слов, замените противоречивые из них подстановочными знаками и выведите шаблон журнала.

Рисунок 15: Кластеризация журналовраспознавание образов
На платформе Blue Whale Log откройте Кластеризацию. После журналов вы можете эффективно просмотреть Кластеризацию. журналоврезультат,Узнайте о новых шаблонах ведения журналов. В то же время в соответствии с шаблоном можно устанавливать разные передачи от меньшего к большему.,гибко выбирать результаты кластеризации различной степени детализации.
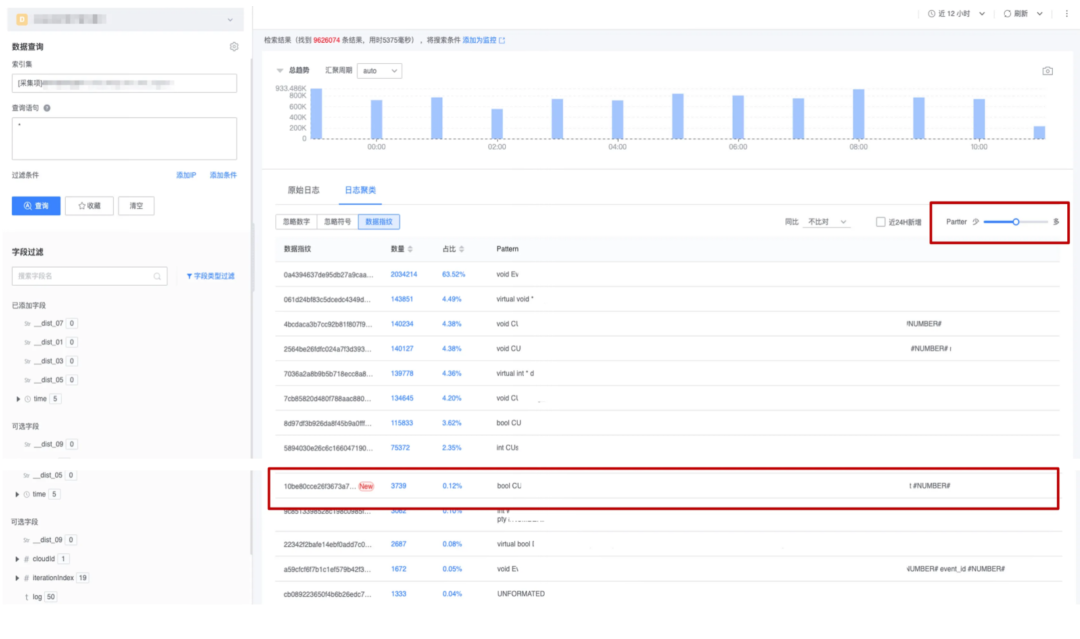
Рисунок 16: Кластеризация журналов Сценарии применения
Журнал обнаружения аномалий
Журнал обнаружения аномалии — относительно сложный сценарий. В этом решении используется сочетание автономного обучения с холодным запуском и онлайн-обучения с использованием кластеризации. журналов, возможность одиночной сцены. Обучение автономному холодному запуску заключается в предварительной обработке выборок журналов автономного холодного запуска, расчете сходства между журналами, сборе журналов с высокой степенью сходства вместе и создании шаблонов журналов посредством распознавания шаблонов для получения кластеризации. журналов Модель,Для онлайн-обучения в качестве модели холодного запуска онлайн-обучение анализирует журналы в реальном времени в потоковом режиме;,Быстрое сопоставление существующих шаблонов журналов,Новый режим журнала используется для несовпадающих журналов.,Это новый тип журнала.
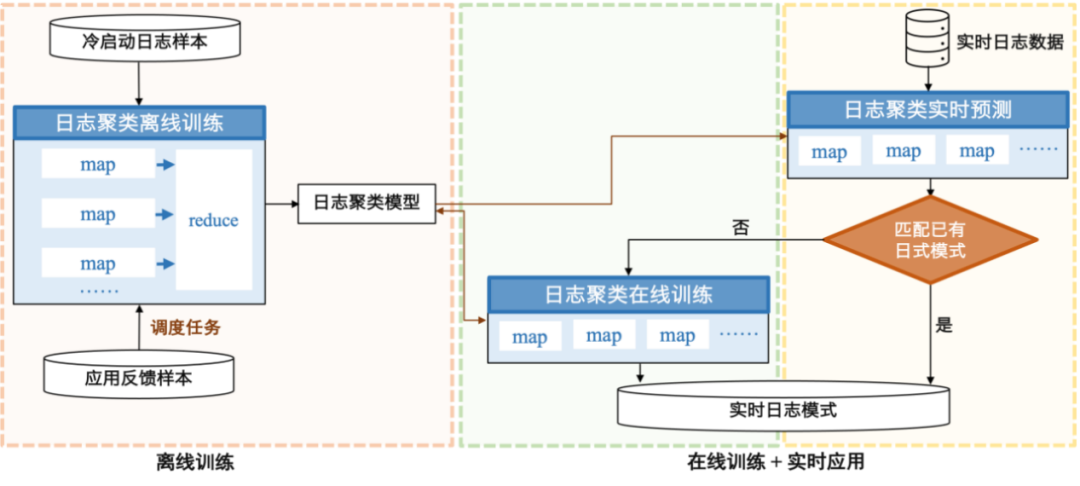
Рисунок 17: Журнал обнаружения аномалий Модель
При обнаружении нового шаблона с использованием модели шаблона журнала выдается сигнал об исключении. Когда в журнале появляется новый шаблон отклонения от нормы/ошибки, вы можете немедленно получить сигнал тревоги и просмотреть соответствующий шаблон и содержимое журнала.
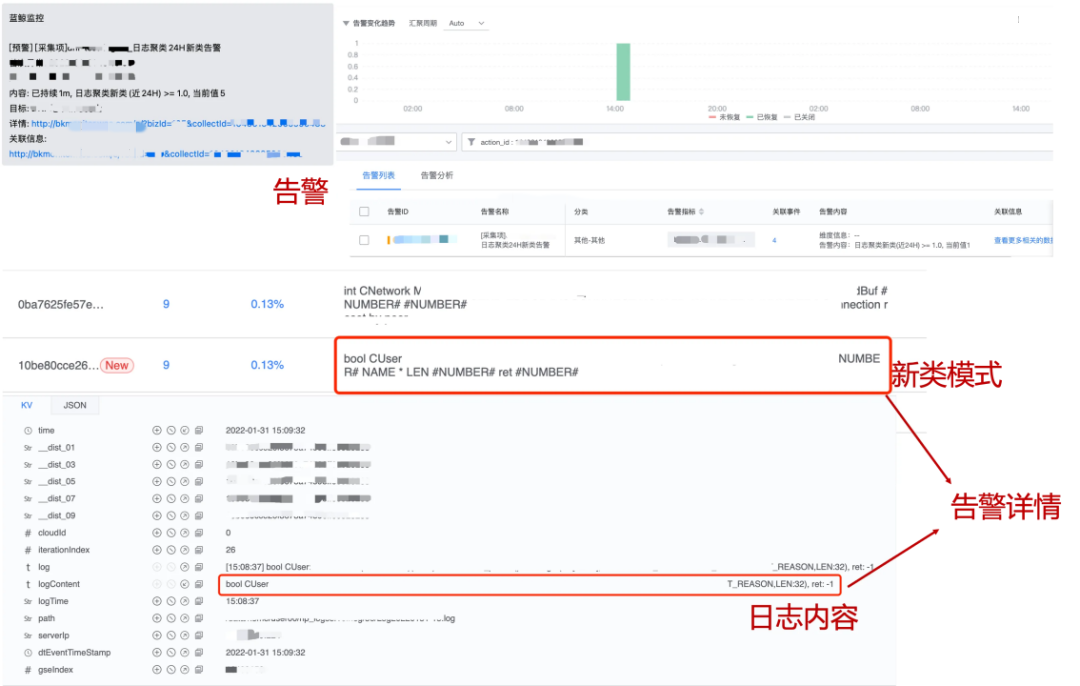
Рисунок 18: Журнал обнаружения аномалий Модель应用
Конвергенция сигналов тревоги
В системе мониторинга эксплуатации и технического обслуживания Конвергенция сигналов подразумевает анализ, объединение и отбрасывание аварийной информации.,Таким образом можно уменьшить масштаб тревожной информации.,Это имеет большое значение для снижения нагрузки на эксплуатацию и обслуживание сети.
В системе мониторинга эксплуатации и технического обслуживания сигналы тревоги можно разделить на шумовые сигналы, сигналы о событиях и сигналы о неисправностях. По частоте возникновения тревог и статистическим методам различают шумовые и нешумовые тревоги. Шумовые тревоги относятся к часто возникающим в истории тревогам. В зависимости от количества нешумовых сигналов тревоги и диапазона задействованных индикаторов они подразделяются на сигналы тревоги событий и сигналы неисправности. Неисправность имеет более важные сигналы тревоги и включает более широкий диапазон индикаторов.
Конвергенция совокупных размеров сигналов Звук в основном основан на анализе часто встречающихся наборов элементов для определения размеров агрегации сигналов тревоги. Например, сигналы тревоги группируются по определенной службе, определенному хосту или определенному поду, что помогает пользователям быстро определить масштаб воздействия или основную причину сигналов тревоги. Иерархический анализ Конвергенции сигналов Для классификации сигналов тревоги используется контролируемый метод. Предполагается, что общие типы сигналов тревоги включают уровень приложений, уровень обслуживания, уровень хоста, уровень центра обработки данных и т. д. Потому что, вообще говоря, чем ниже уровень, тем больше сигналов тревоги и тем больше. заинтересованный пользователь имеет низкий уровень, поэтому используйте Конвергенцию высокого уровня. сигналов Сигнал тревоги низкого уровня уведомит пользователей о самом высоком уровне воздействия.
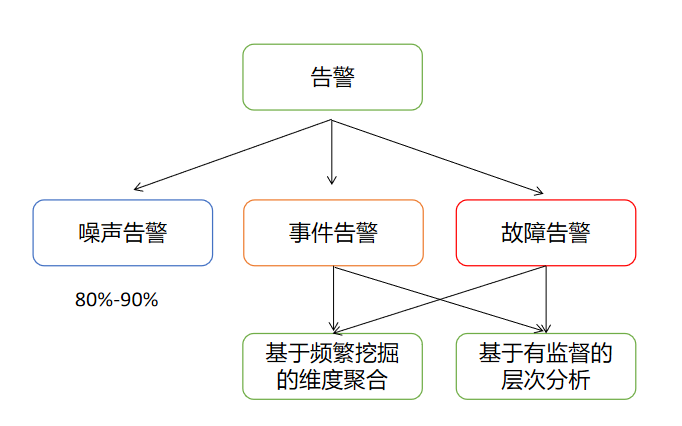
Рис. 19. Пример логики кластеризации сигналов тревоги.
Коэффициент шумоподавления после конвертации сигналов показан на рисунке ниже.,Общий коэффициент шумоподавления достигает 98,4%.,Коэффициент шумоподавления определенного сервиса составляет 84,6%.
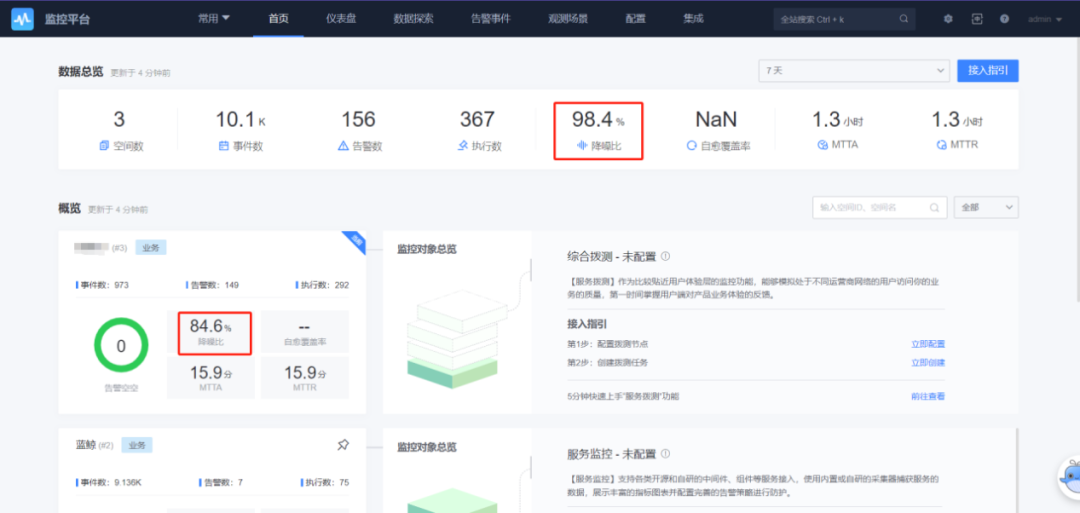
Рисунок 20: Сценарий применения кластеризации сигналов тревоги
Приложение большой языковой модели
Для нас модель большого языка изменила модель взаимодействия между людьми и системой эксплуатации и технического обслуживания в области эксплуатации и технического обслуживания. Сценарии включают интеллектуальные вопросы и ответы, предложения по устранению неполадок, статистический анализ данных и т. д.
Обеспечивает целенаправленные основные компетенции:
- Система управления корпусом: предоставляет пользователям возможность написания корпуса, управления корпусом и организации процессов;
- Центр расширенной оркестрации: он объединяет корпус, большую модель, базу знаний, автоматизацию и другие функции, обеспечивая очень гибкий метод оркестрации;
- Центр обучения моделям: поддерживает множественное и пакетное обучение, предоставляет функции настройки параметров и предоставляет эффективный метод обучения моделей, который позволяет быстро обучать высококачественные модели роботов. Доступ к статьям базы знаний, накопленным при эксплуатации и техническом обслуживании → Профессиональная консультация пользователя → Обобщение и вывод данных из базы знаний, автоматическое получение соответствующей информации, такой как сигналы тревоги, активы, журналы, комплексный анализ, профессиональное руководство и, наконец, помощь в решении проблем.
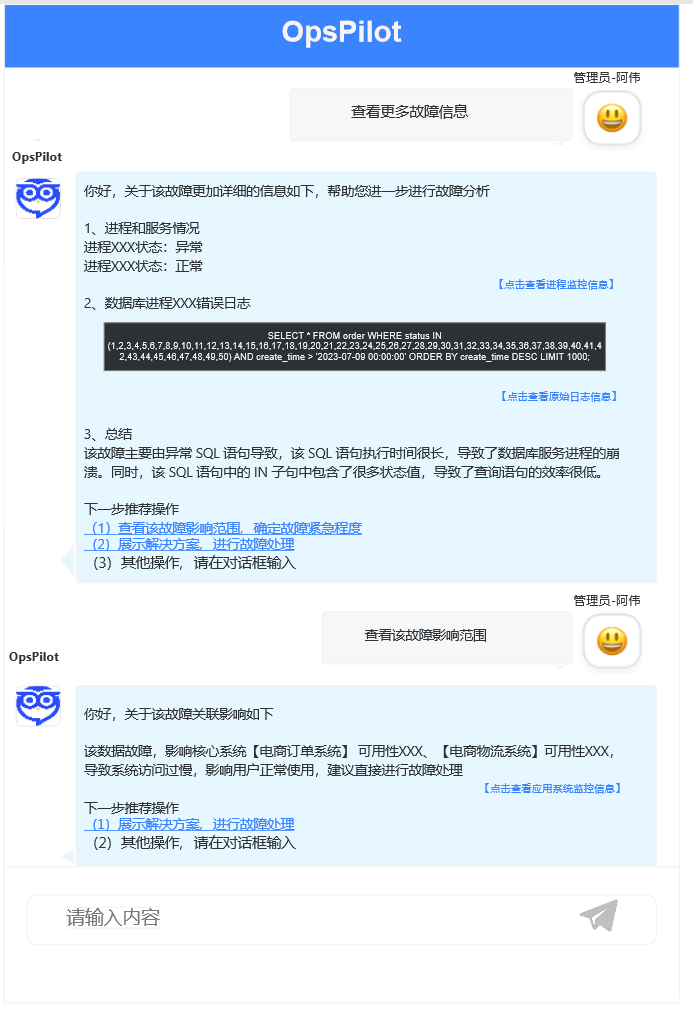
Рис. 21. Интеллектуальное взаимодействие вопросов и ответов Fault.
Являясь ведущим в отрасли поставщиком платформенных, интегрированных и цифровых интеллектуальных решений для эксплуатации и обслуживания, Jiawei Blue Whale твердо привержена предоставлению нашим клиентам зрелых бизнес-практик и передовой технологической архитектуры.
В этом выпуске мы совместно обсуждали контент, связанный с «цифровым интеллектом». Чтобы просмотреть контент, связанный с «интеграцией» и «платформизацией», нажмите «Рекомендации серии» ниже.
Наконец, вы можете поговорить с Цзявэй Синим Китом в любое время!
Резюме: Вышеуказанное представляет собой авторский анализ данных, а также интеллектуальную эксплуатацию и обслуживание. Добро пожаловать для обсуждения и обмена, спасибо!



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
