Три способа создания развертывания кластера Hadoop Cluster_hadoop
Создание кластера Hadoop (суперподробно)
1. Кластерное планирование
Установите VMware и используйте три виртуальные машины Ubuntu18.04 для создания кластера. Ниже приведен план для каждой виртуальной машины:
имя хоста | IP | пользователь | HDFS | YARN |
|---|---|---|---|---|
hadoopWyc | Будет определено | wyc | NameNode、DataNode | NodeManager、ResourceManager |
hadoopWyc2 | Будет определено | wyc | DataNode、SecondaryNameNode | NodeManager |
hadoopWyc3 | Будет определено | wyc | DataNode | NodeManager |
2. Конфигурация сети
Сначала я создал новую виртуальную машину Ubuntu в VMware с памятью 8 ГБ (просто установите системную память Ubuntu по умолчанию) и пространством на жестком диске 20 ГБ. После завершения создания нового выполните следующие операции.

обычнопользователь Пожалуйста, помните об этом после входа в системуIPадрес,Оно понадобится вам позже! ! !
Сначала войдите в систему под root-пользователем, а затем работайте под root-пользователем.
su root #Loginroot пользовательСемейное ведро Jetbrains 1 год 46, стабильная послепродажная гарантия
Пока нет ссылки на установку пароля root-пользователя. Ubuntu18.04 установил пароль root (начальный пароль)
2.1 Изменить имя хоста
vim /etc/hostname #Изменить файлВыполните приведенную выше команду, чтобы открыть файл «/etc/hostname».,Содержимое удалить,и изменен на“hadoopWyc”(Вы можете изменить то, что хотите, в соответствии с вашими потребностямиимя хоста), сохраните и выйдите из редактора vim, перезапустите Linux, чтобы увидеть имя хост меняется.

2.2 Просмотр информации о сети виртуальной машины
2.2.1 Нажмите на редактор виртуальной сети в редакторе VMware.

2.2.2 Выберите сеть VMnet8 и нажмите «Настройки NAT».


Запишите маску подсети, шлюз и три предыдущих атрибута IP-адреса на рисунке выше. Они будут полезны в следующих шагах, и разные компьютеры будут разными.
2.2.3 Получите номер сетевой карты виртуальной машины Ubuntu
ifconfig
2.2.4 Настройка статической сети
vim /etc/network/interfacesДобавить к исходному контенту
auto ens33 # Номер сетевой карты, вот ens33
iface ens33 inet static # Установить статический IP
address 192.168.153.136 # IP-адрес машины — это IP-адрес, отображаемый после входа в систему. адрес
netmask 255.255.255.0 # Маска подсети, просто получите маску подсети VMware
gateway 192.168.153.2 # Шлюз также является только что полученным шлюзом.
dns-nameserver 192.168.153.2 # DNS, то же самое, что и шлюз
Вышеупомянутое содержимое устанавливается в соответствии с соответствующими компьютерами. Оно должно соответствовать IP-адресу подсети, маске подсети и шлюзу в VMware, иначе вы не сможете получить доступ к Интернету. Сохраните и выйдите из редактора vim, затем перезапустите Ubuntu, чтобы изменения вступили в силу.
3. Установите ssh-сервер.
apt-get install openssh-serverЕсли при установке виртуальной машины вы отметили опцию установки ssh, это будет выглядеть так, как показано на рисунке ниже. Просто продолжайте делать это.

После установки используйте следующую команду для входа в систему:
ssh localhostДополнение: ssh localhost = ssh <текущийпользователь>@localhost -p 22 -i ~/.ssh/id_rsa
В первый раз появится запрос на вход по SSH. Просто введите «да», а затем введите локальный пароль, как будет предложено.

Но в этом случае вам придется вводить пароль каждый раз при входе в систему. Теперь настройте вход по SSH без пароля. Сначала выйдите из SSH, используйте ssh-keygen для генерации ключа и добавьте ключ в авторизацию.
exit # Выйти по SSH localhost
cd ~/.ssh/
ssh-keygen -t rsa # Появится подсказка, просто нажмите Enter.
cat ./id_rsa.pub >> ./authorized_keys # Добавить авторизацию
Теперь используйте «ssh localhost» для входа в систему по ssh без ввода пароля.

4. Установите среду Java
Hadoop3.1.3 требует JDK версии 1.8 и выше.,Нажмите ссылку справа, чтобы загрузить версию, соответствующуюJDK:jdk-8u162-linux-x64.tar.gz(Код извлечения:ik9p)。
Мы можем подключиться к виртуальной машине через Xshell, имя хоста — это IP-адрес, показанный при входе в систему только что.,Порт по умолчанию 22,Выберите учетную запись и пароль для входа и введите свое имя и пароль для входа (если он не установлен выше, включите службу .ssh).,Здесь вы не сможете подключиться к виртуальной машине)

Щелкните маленький зеленый значок выше, и мы откроем Xftp, который может напрямую передавать локальные файлы на виртуальную машину.

Люди, которые входят в Xshell с помощью обычного пользователя, сообщают об ошибке, что локальные файлы не могут быть перенесены на виртуальную машину:

Есть два решения:
- Xдолжен войти в систему как root,Откройте Xftp еще раз (таким образом Xftp также откроется от пользователя root).,есть все разрешения),Однако Xshall не может подключиться к виртуальной машине при входе в систему с правами root.,ссылка:Xshell использует root-пользователя для подключения к Linux Можетрешать
- ссылка:Когда Xftp передает файлы на виртуальную машину, он продолжает показывать ошибку состояния и не может быть передан.
После размещения файла в любом каталоге выполните следующую команду:
cd /usr/lib
mkdir jvm # Создайте каталог для хранения файлов JDK.Затем перейдите в папку, где находится jdk-8u162-linux-x64.tar.gz, и распакуйте JDK в только что созданную папку jvm.
tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #Извлекаем JDK в только что созданную jvm-папкуПосле распаковки файла JDK в каталоге /usr/lib/jvm появится файл jdk1.8.0_162. Далее мы начинаем устанавливать переменные среды.
vim ~/.bashrcДобавьте следующий контент в начало открытого файла
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib:${
JRE_HOME}/lib
export PATH=${
JAVA_HOME}/bin:$PATHСохраните и выйдите из редактора vim и выполните следующую команду, чтобы конфигурация файла .bashrc вступила в силу:
source ~/.bashrcЗатем используйте следующую команду, чтобы проверить успешность установки:
java -versionЕсли информация о версии Java отображается, как показано ниже, это означает, что установка прошла успешно:

5. Установите Hadoop3.1.3.
hadoop-3.1.3.tar.gz (Код извлечения: x2vu) вы можете нажать, чтобы загрузить здесь, загрузить и загрузить его в соответствующее место, использовать следующую команду для его установки и предоставить права доступа к папке такие же, как при установке Java:
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local # Разархивируйте его в /usr/local
cd mv ./hadoop-3.1.3/ ./hadoop # Измените имя файла на Hadoop
sudo chown -R rmc0924 ./hadoop # Изменить разрешения,Какой сейчас логин пользователя,Дайте ему права пользователяПосле распаковки используйте следующую команду, чтобы проверить, прошла ли установка успешно. Если установка прошла успешно, отобразится информация о версии Hadoop.
cd /usr/local/hadoop
./bin/hadoop versionКак показано на рисунке:

6. Клонировать виртуальную машину
После описанных выше шагов Ubuntu с именем HadoopWyc была настроена. Теперь выйдите из виртуальной машины. Клонируйте эту виртуальную машину в две другие виртуальные машины с именами HadoopWyc2 и HadoopWyc3 соответственно.

В следующем окне подсказки выберите «Текущий статус виртуальной машины», «Создать полный клон», назовите клонированную виртуальную машину, выберите местоположение и дождитесь завершения клонирования.


Итоговая виртуальная машина выглядит так:

Выполните шаги 2.1 и 2.2, чтобы изменить две виртуальные машины HadoopWyc2 и HadoopWyc3. хоста и соответствующие им статические IP-адреса в качестве резервной копии. Наконец, мы можем завершить исходную таблицу:
имя хоста | IP | пользователь | HDFS | YARN |
|---|---|---|---|---|
hadoopWyc | 192.168.153.136 | wyc | NameNode、DataNode | NodeManager、ResourceManager |
hadoopWyc2 | 192.168.153.137 | wyc | DataNode、SecondaryNameNode | NodeManager |
hadoopWyc3 | 192.168.153.138 | wyc | DataNode | NodeManager |
7. Добавьте сопоставление IP-адресов узлов всем трем виртуальным машинам.
Откройте файл хостов и добавьте три отношения сопоставления между IP и хостами:
vim /etc/hosts192.168.153.136 hadoopWyc 192.168.153.137 hadoopWyc2 192.168.153.138 hadoopWyc3

8. Построение кластера
Теперь кластер Hadoop официально настроен. Во-первых, нам все равно нужно открыть три виртуальные машины в VMware, а затем использовать Xshall для подключения этих трех виртуальных машин.
Три машины проверяют друг друга, чтобы проверить, смогут ли они выполнить проверку связи успешно.

8.1 Узел входа без пароля по SSH
Узел HadoopWyc должен иметь возможность входа на каждый узел HadoopWyc2 и HadoopWyc3 через SSH без пароля. Сначала сгенерируйте открытый ключ узла HadoopWyc. Если он был сгенерирован ранее, его необходимо удалить и создать заново. Выполните следующие операции на HadoopWyc:
cd ~/.ssh
rm ./id_rsa* # Удалить ранее сгенерированный открытый ключ
ssh-keygen -t rsa # Когда вы встретите сообщение, просто нажмите Enter.
Затем дайте узлу HadoopWyc возможность войти в систему через SSH без пароля. Выполните следующую команду на узле HadoopWyc:
cat ./id_rsa.pub >> ./authorized_keysИспользуйте следующую команду для проверки:
ssh hadoopWycДальше будетhadoopWycОткрытый ключ наhadoopWyc2&3узел:
scp ~/.ssh/id_rsa.pub hadoopWyc2:/home/wyc
scp ~/.ssh/id_rsa.pub hadoopWyc3:/home/wycгде scp безопасен сокращение для копии,существоватьLinuxИспользуется в удаленном копировании。осуществлятьscpпопросит ввести данныеhadoopWyc2&3пользовательпароль,После завершения ввода отобразится сообщение о завершении передачи:

Затем на узле HadoopWyc2 добавляем к авторизации полученный публичный ключ:
mkdir ~/.ssh # Если папка не существует, сначала создайте ее
cat /home/wyc/id_rsa.pub >> ~/.ssh/authorized_keys
rm /home/wyc/id_rsa.pub # Просто добавь этоудалитьТакже выполните указанную выше команду на узле HadoopWyc3. После выполнения,существоватьhadoopWycузел上就Может无密码登录hadoopWyc2&3узел,Выполните следующую команду на узле HadoopWyc:
ssh hadoopWyc2Войдите в HadoopWyc2 в HadoopWyc. Ввод команды в этот момент эквивалентен ее выполнению на виртуальной машине HadoopWyc2.

Введите выход, чтобы выйти
8.2 Настройка среды кластера
При настройке режима кластера вам необходимо изменить файлы конфигурации в каталоге «/usr/local/hadoop/etc/hadoop», включая рабочие файлы, core-site.xml, hdfs-site.xml, mapred-site.xml и сайт пряжи.
8.2.1 Изменение рабочего файла
vim workersСодержимое этого файла может указывать определенные узлы в качестве узлов данных. По умолчанию используется localhost. Мы удаляем его и изменяем на HadoopWyc2 и HadoopWyc. Конечно, вы также можете добавить к нему HadoopWyc, чтобы узел HadoopWyc можно было использовать как узел имени и узел данных. В этой статье HadoopWyc будет добавлен вместе в качестве узла данных.
hadoopWyc
hadoopWyc2
hadoopWyc38.2.2 Изменение файла core-site.xml
vim core-site.xmlfs.defaultFS: укажите адрес связи файловой системы протокола hdfs узла имени. Вы можете указать хост + порт. Hadoop.tmp.dir: каталог, в котором хранятся некоторые временные файлы во время работы кластера Hadoop.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopWyc:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>8.2.3 Изменение файла hdfs-site.xml
vim hdfs-site.xmldfs. Secondary.http.address: информация о работающем узле вторичного узла-имя должна храниться на другом узле, отличном от узла-имя. dfs.replication: настройка номера реплики HDFS, по умолчанию — 3. dfs.namenode.name.dir: место хранения данных namenode и место хранения метаданных. dfs.datanode.data.dir: место хранения данных узла данных и расположение блоков блоков.
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoopWyc2:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>8.2.4 Изменение файла mapred-site.xml
vim mapred-site.xmlMapreduce.framework.name: укажите структуру Mapreduce как режим пряжи. mapreduce.jobhistory.address: укажите адрес и порт сервера истории. mapreduce.jobhistory.webapp.address: просмотр веб-адреса записей заданий Mapreduce, запущенных сервером истории. Вам необходимо запустить эту службу.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoopWyc:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoopWyc:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>8.2.5 Изменение файла Yarn-site.xml
vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopWyc</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>8.3 Распространение файлов
После изменения пяти вышеуказанных файлов скопируйте файлы Hadoop с узла HadoopWyc на каждый узел. Выполните следующую команду на узле HadoopWyc:
cd /usr/local
sudo rm -r ./hadoop/tmp # удалить Hadoop временные файлы
sudo rm -r ./hadoop/logs/* # удалить файл журнала
tar -zcf ~/hadoop.master.tar.gz hadoop # Сначала сжать, а потом копировать
cd ~
scp hadoop.master.tar.gz hadoopWyc2:/home/
scp hadoop.master.tar.gz hadoopWyc3:/home/
существовать其他hadoopWyc2&3узел将接收的压缩文件解压出来,и предоставить разрешения,Команда выглядит следующим образом:
sudo rm -r /usr/local/hadoop # Удалить старый (если он существует)
sudo tar -zxf /home/hadoop.master.tar.gz -C /usr/local
sudo chown -R wyc /usr/local/hadoop
8.4 Инициализация Hadoop
Инициализацию HDFS можно выполнить только на главном узле.
cd /usr/local/hadoop
./bin/hdfs namenode -format
Если во время процесса инициализации вы видите информацию в красном поле выше, если она успешно отформатирована, это означает, что инициализация прошла успешно.
8.5 Запуск кластера Hadoop
Выполните следующую команду на узле HadoopWyc:
cd /usr/local/hadoop
./sbin/start-dfs.sh
./sbin/start-yarn.sh
./sbin/mr-jobhistory-daemon.sh start historyserver
#Таким образом, мы можем открыть WEB сервера истории на порту 19888 соответствующего компьютера. Интерфейс пользовательского интерфейса. Вы можете просмотреть статус выполненных работ
Посмотреть процессы, запущенные каждым узлом, можно через jps. Если он запущен правильно согласно настройкам в этой статье, вы увидите на узле HadoopWyc следующие процессы:

Процесс узла HadoopWyc2:

Процесс узла HadoopWyc3:
Когда Hadoop-3.1.0 запускает кластер Hadoop, может быть сообщено о следующей ошибке:
root@hadoopWyc3:/usr/local/hadoop# ./sbin/start-dfs.sh
Starting namenodes on [hadoopWyc]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoopWyc2]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.ссылка:решать Hadoop запускать ERROR: Attempting to operate on hdfs namenode as root метод решать
На данный момент полностью распределенное развертывание Hadoop завершено.
Заявление об авторских правах: Содержание этой статьи было добровольно предоставлено пользователем Интернета.,Мнения, выраженные в данной статье, принадлежат исключительно автору. Этот сайт предоставляет только услуги по хранению информации.,нет собственности,Никакая соответствующая юридическая ответственность не предполагается. Если вы обнаружите на этом сайте какое-либо подозрительное нарушение авторских прав/незаконный контент,, Пожалуйста, отправьте электронное письмо на Сообщите, после проверки этот сайт будет немедленно удален.
Издатель: Лидер стека программистов полного стека, укажите источник для перепечатки: https://javaforall.cn/219152.html Исходная ссылка: https://javaforall.cn


Учебное пособие по SpringBoot (14) | SpringBoot интегрирует Redis (наиболее полный во всей сети)
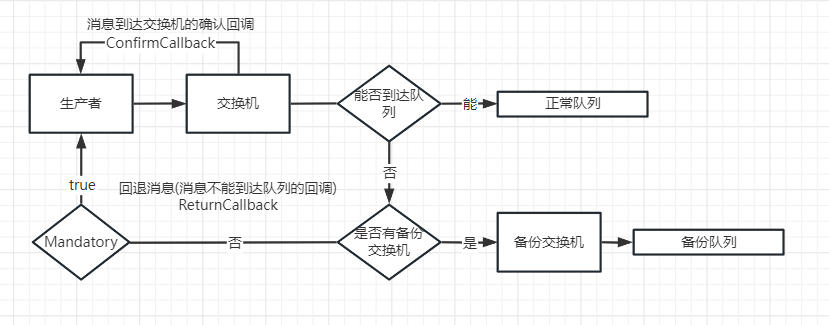
Подробное объяснение механизма подтверждения выпуска сообщений RabbitMQ.

На этот раз полностью поймите протокол ZooKeeper.

Реализуйте загрузку файлов с использованием минимального WEB API.

Демо1 Laravel5.2 — генерация и хранение URL-адресов
Spring boot интегрирует Kafka и реализует отправку и потребление информации (действительно при личном тестировании)
Мысли о решениях по внутренней реализации сортировки методом перетаскивания

Междоменный доступ к конфигурации nginx не может вступить в силу. Междоменный доступ к странице_Page

Как написать текстовый контент на php

PHP добавляет текстовый водяной знак или водяной знак изображения к изображениям – метод инкапсуляции
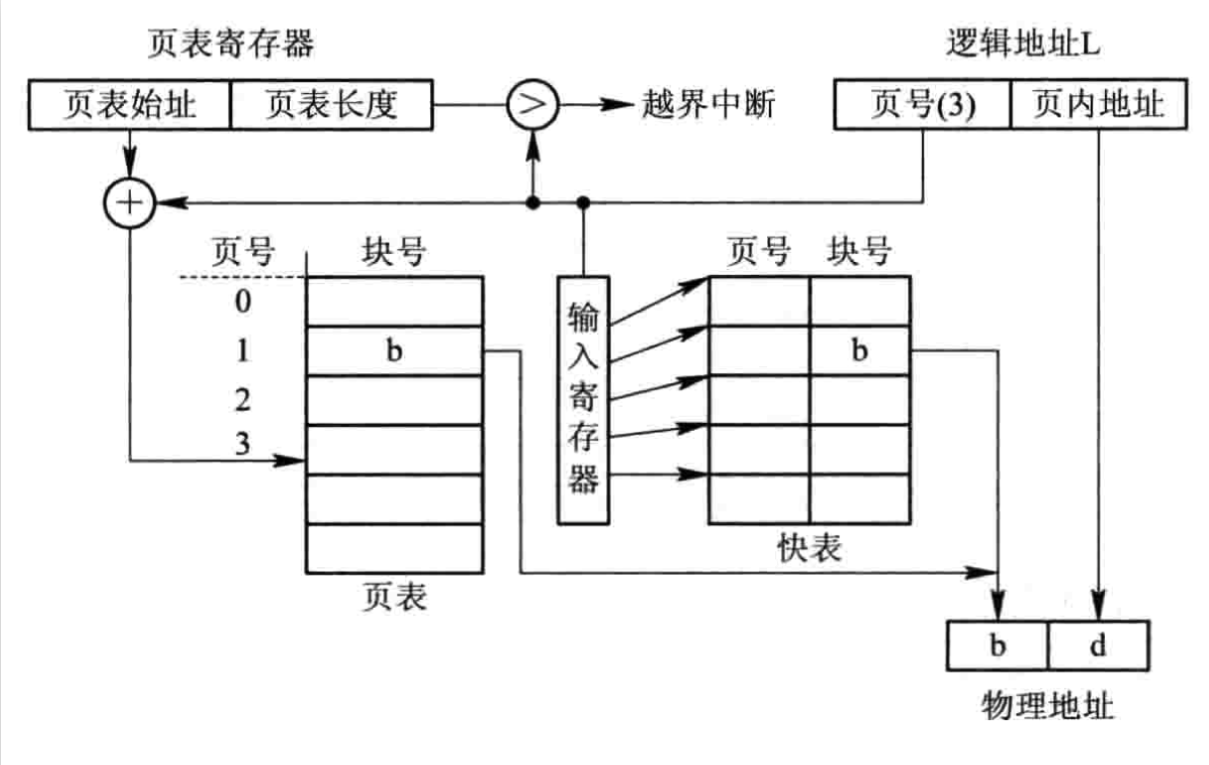
Интерпретация быстрой таблицы (TLB)

Интерфейс WeChat API (полный) — оплата WeChat/красный конверт WeChat/купон WeChat/магазин WeChat/JSAPI

Преобразование Java-объекта в json string_complex json-строки в объект

Примените сегментацию слов jieba (версия Java) и предоставьте пакет jar

matinal: Самый подробный анализ управления разрешениями во всей сети SAP. Все управление разрешениями находится здесь.
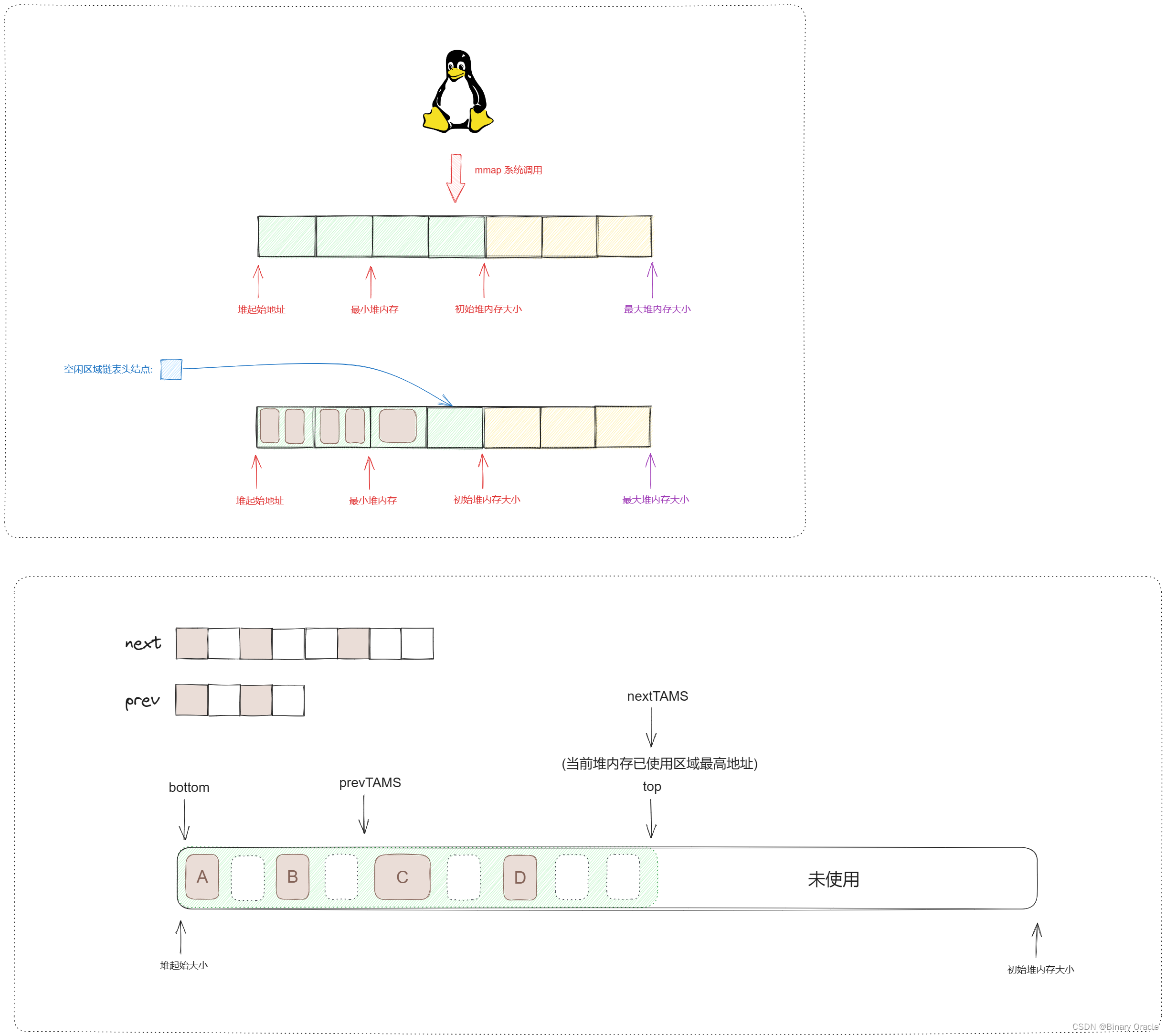
Коротко расскажу обо всем процессе работы алгоритма сборки мусора G1 --- Теоретическая часть -- Часть 1
[Спецификация] Результаты и исключения возврата интерфейса SpringBoot обрабатываются единообразно, поэтому инкапсуляция является элегантной.

Интерпретация каталога веб-проекта Flask

Что такое подробное объяснение файла WSDL_wsdl

Как запустить большую модель ИИ локально
Подведение итогов десяти самых популярных веб-фреймворков для Go
5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам
