[Третья годовщина ES] Победите ElasticSearch и Kibana (Учебное пособие начального уровня для няни-2)
Предисловие
Инструмент визуализации аналитики с открытым исходным кодом для Elasticsearch, который взаимодействует с данными, хранящимися в Elasticsearch.
1.Что такое Кибана?
Kibana — это бесплатное и открытое интерфейсное приложение, созданное на основе Elastic Stack, которое предоставляет возможности поиска и визуализации данных, проиндексированных в Elasticsearch. Хотя Kibana часто рассматривается как инструмент сопоставления для Elastic Stack (ранее ELK Stack, для Elasticsearch, Logstash и Kibana), Kibana также можно использовать в качестве пользовательского интерфейса для мониторинга, управления и защиты кластера Elastic Stack. это центр встроенных решений, построенных на Elastic Stack. Сообщество Elasticsearch разработало Kibana в 2013 году, и теперь Kibana превратилась в окно в Elastic Stack, портал для пользователей и компаний.
2.Для чего используется Кибана?
Тесная интеграция Kibana с Elasticsearch и более широким стеком Elastic делает его идеальным для поддержки следующих сценариев:
- Ищите, просматривайте и визуализируйте Elasticsearch Данные индексируются в,Анализируйте данные, создавая гистограммы, круговые диаграммы, таблицы, гистограммы и карты. Представления информационной панели объединяют эти визуальные элементы.,и поделитесь им через браузер,для предоставления аналитического представления в режиме реального времени огромных объемов данных,Обеспечивает поддержку для следующих случаев использования.:
- Обработка и анализ журналов
- Метрики инфраструктуры и мониторинг контейнеров
- Мониторинг производительности приложений (APM)
- Анализ и визуализация геопространственных данных
- анализ безопасности
- бизнес-анализ
- Отслеживайте, управляйте и защищайте экземпляры Elastic Stack с помощью веб-интерфейса.
- Централизуйте доступ к встроенным решениям, созданным на основе Elastic Stack, для приложений наблюдения, безопасности и корпоративного поиска.
3. Установите Кибану
3.1 Загрузите и разархивируйте Кибану
Скачанная версия Elasticsearch — 7.6.1. Здесь выбираем ту же версию 7.6.1.
Примечание. Версия Kibana и версия Elasticsearch должны быть согласованы.
Скачать адрес:https://www.elastic.co/cn/downloads/past-releases#kibana
Подобно tomcat, просто распакуйте его напрямую. Структура его каталогов следующая:
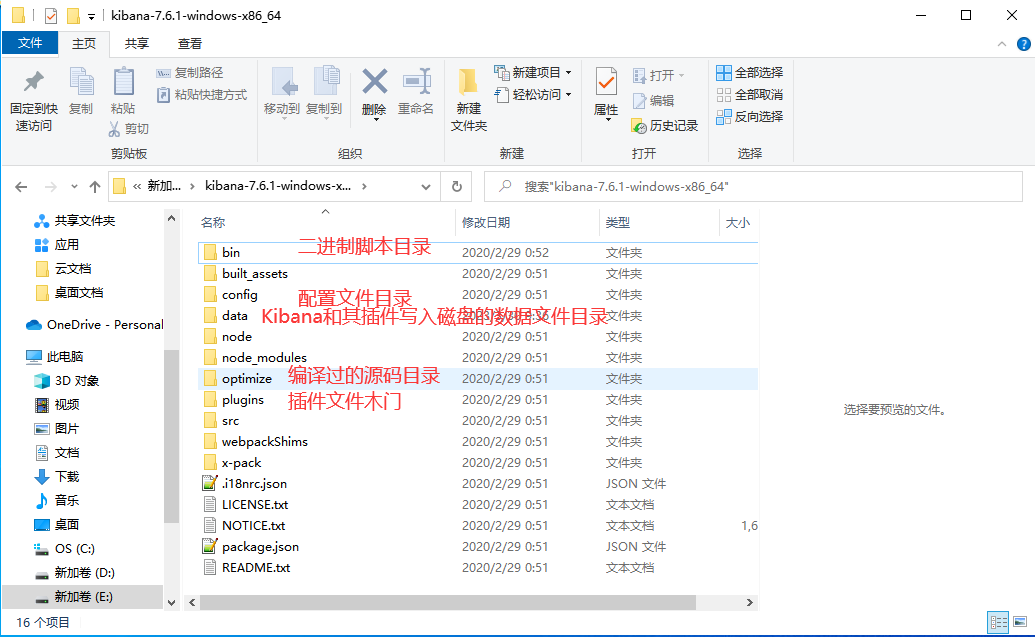
3.2 Запуск Кибаны
1. Откройте каталог bin напрямую с помощью cmd.,и начатьkibana:kibana.bat Или дважды щелкните kibana.bat , как показано на рисунке ниже:
3.3 Доступ к Кибане
URL-адрес посещения: 127.0.0.1:5601 или localhost:5601. , как показано на рисунке ниже:
3.4 Китайская страница Кибана
1. Войдите в папку конфигурации Kibana config/kibana.yml, откройте ее и измените следующим образом:
i18n.locale: "zh-CN"2. Сохраните и перезапустите Кибану.,Посетите Кибану снова,Интерфейс стал китайским, как показано на рисунке ниже:
3.4 Соединение Kibana
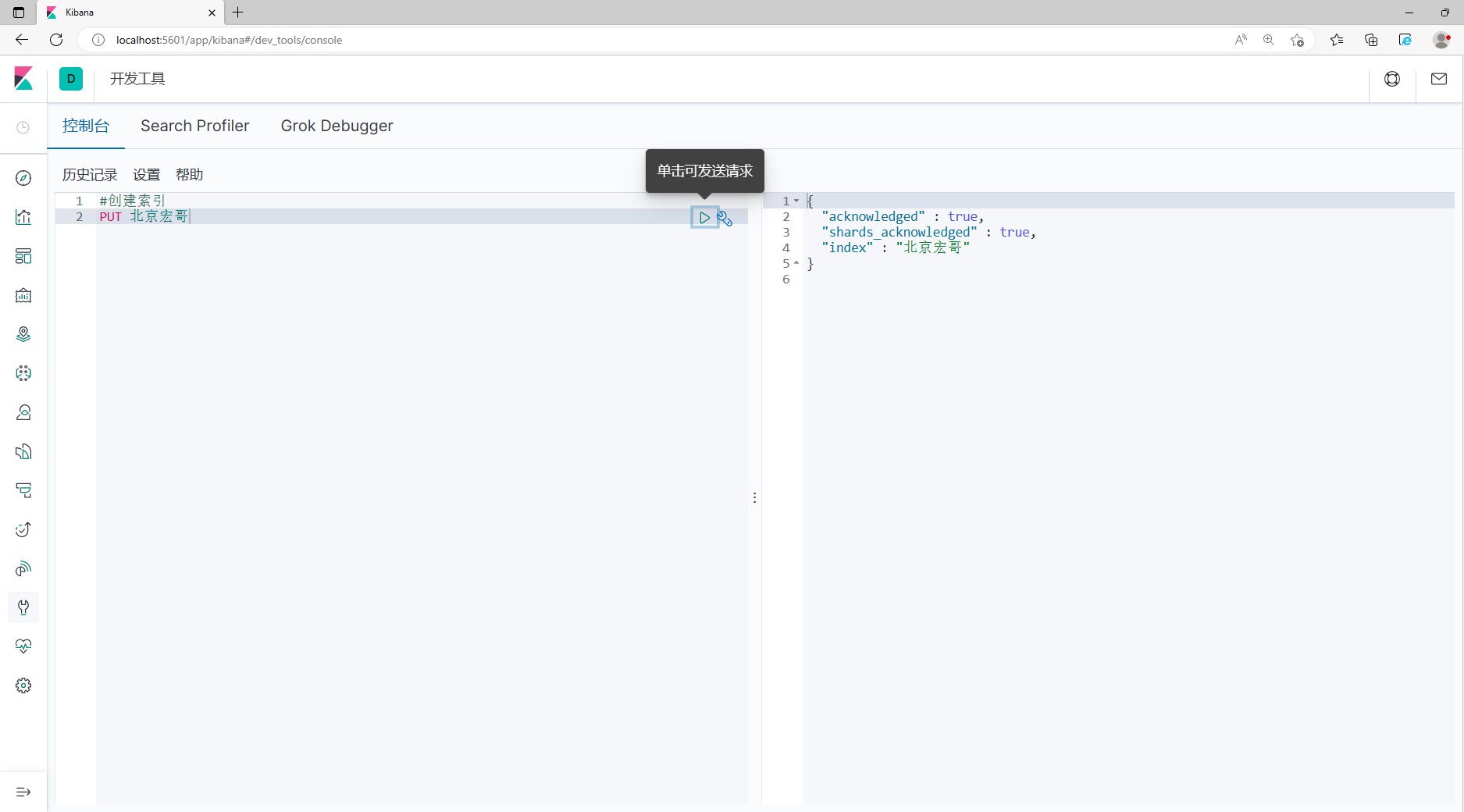
1. Войдите в папку конфигурации Kibana config/kibana.yml, откройте ее и измените следующим образом:
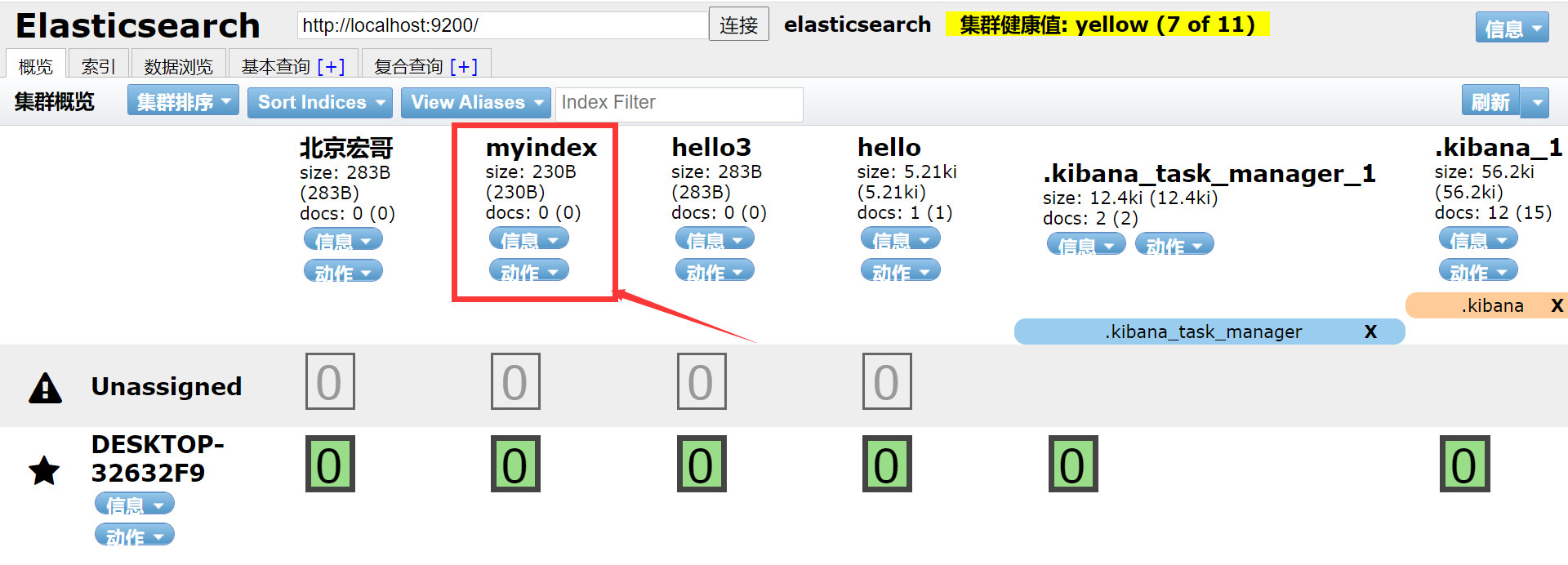
elasticsearch.hosts: ["http://localhost:9200"]2.Сохранить,Перезагрузить эсиKibana,Проверить статус соединения,существоватьKibanaСоздать индекс:Пекин Хонге, как показано на рисунке ниже:
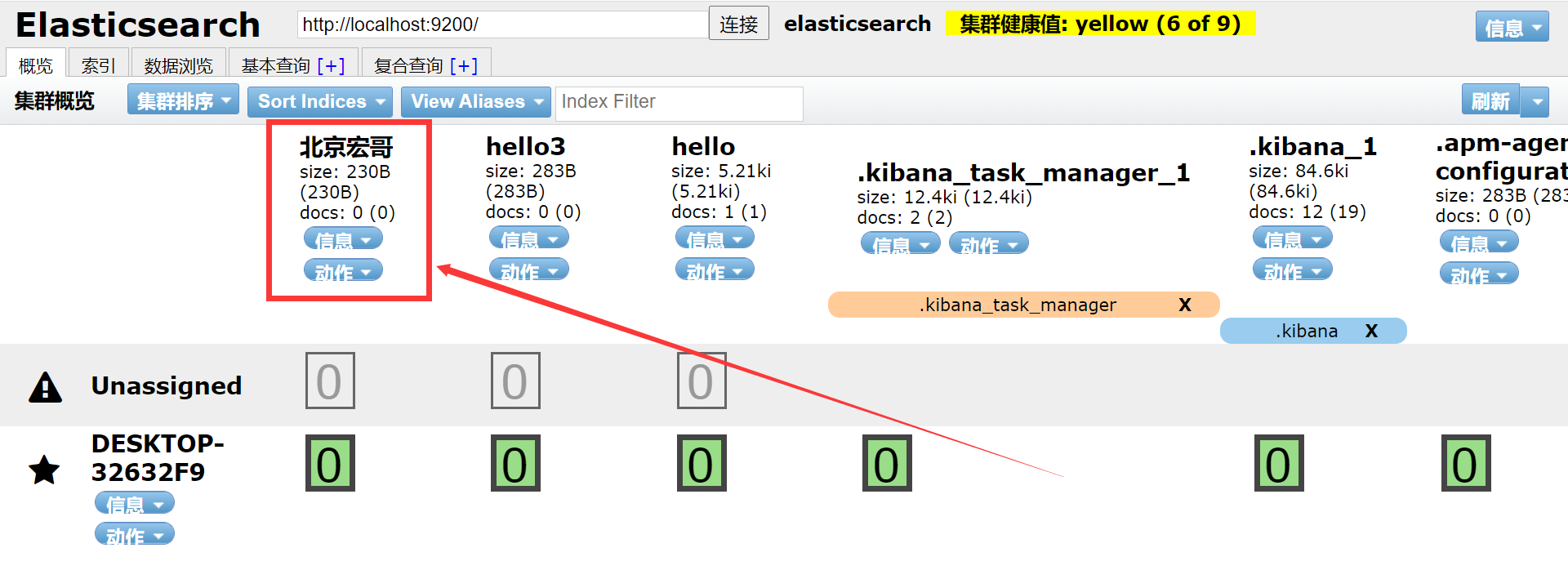
3. Проверьте, успешно ли оно выполнено в ES, как показано на рисунке ниже:
3.5 Использование Кибаны
1. Найдите консоль на домашней странице, как показано на рисунке ниже:
2. Войдите в консоль для отладки и используйте ее, как показано на рисунке ниже:
4.Основные функции Elasticsearch
4.1 Индексные операции
4.1.1 Создать индекс
1. Индекс программного обеспечения ES можно сравнить с концепцией таблицы в MySQL. Создание индекса аналогично созданию таблицы. После завершения запроса Kibana вернет результаты ответа и статус запроса справа.
#Создать индекс
PUT myindex
2. При повторном создании индекса Kibana вернет результат ответа справа, включая информацию об ошибке.
#Создаем дубликат индекса
ПОСТАВИТЬ мойиндекс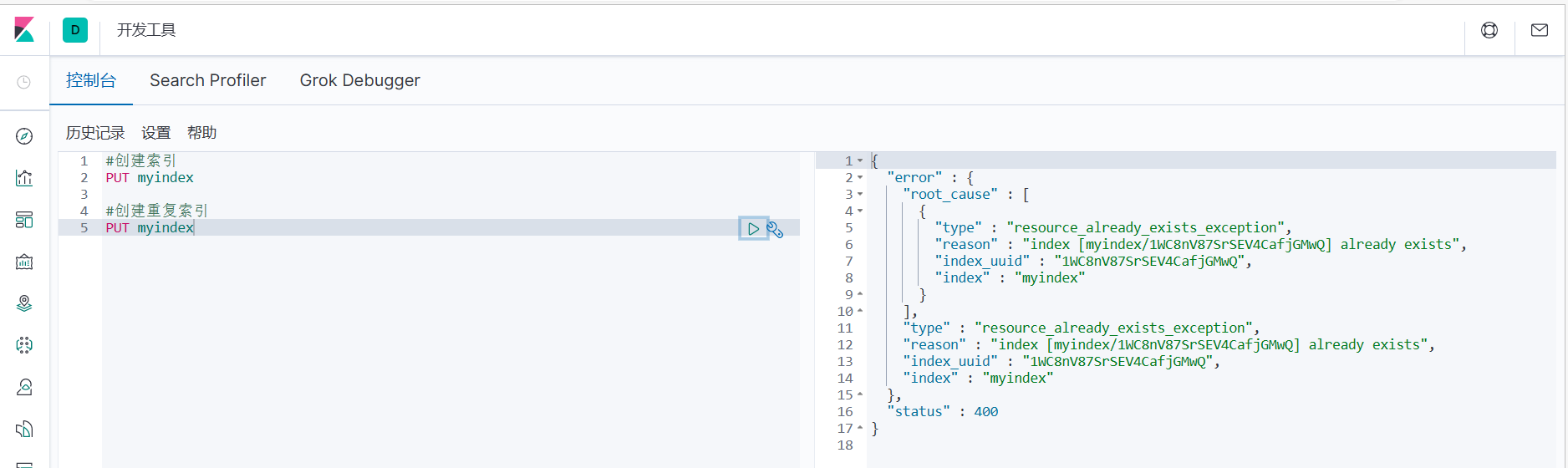
4.1.2 Запрос указанного индекса
1. Запросите указанный индекс по имени индекса. Если он найден, будет возвращена подробная информация об индексе.
#Запрашиваем указанный индекс
ПОЛУЧИТЬ мой индекс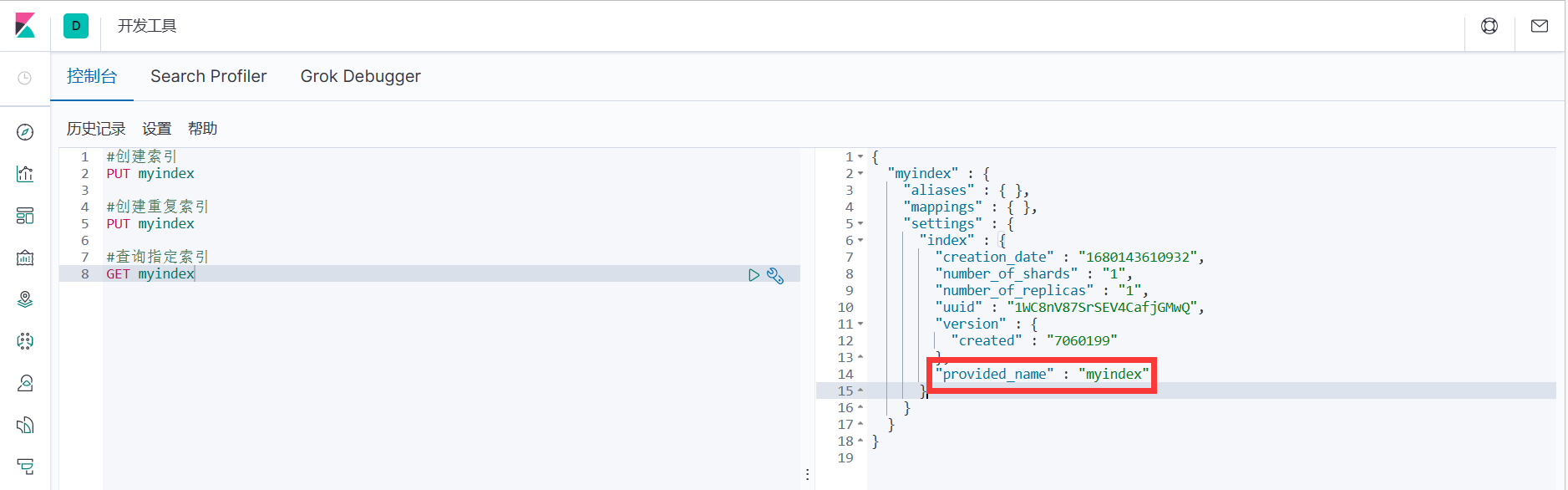
2. Если запрошенный индекс не существует, будет возвращено сообщение об ошибке.
#Индекс запроса не существует
ПОЛУЧИТЬ мой индекс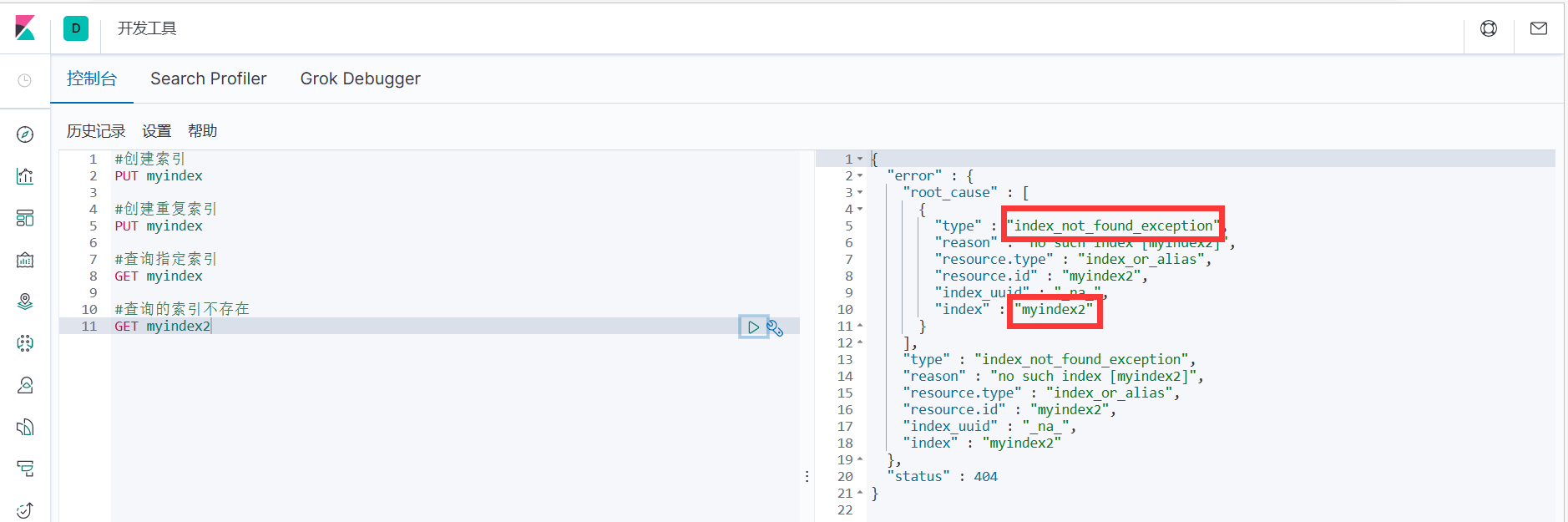
4.1.3 Запрос всех индексов
1. Для удобства вы можете запросить все текущие данные индекса. _cat в пути запроса здесь означает просмотр, а индексы означают индексы, поэтому общий смысл заключается в просмотре всех индексов на текущем ES-сервере, точно так же, как отображение таблиц в MySQL.
#Запрашиваем все текущие данные индекса
GET_cat/индексы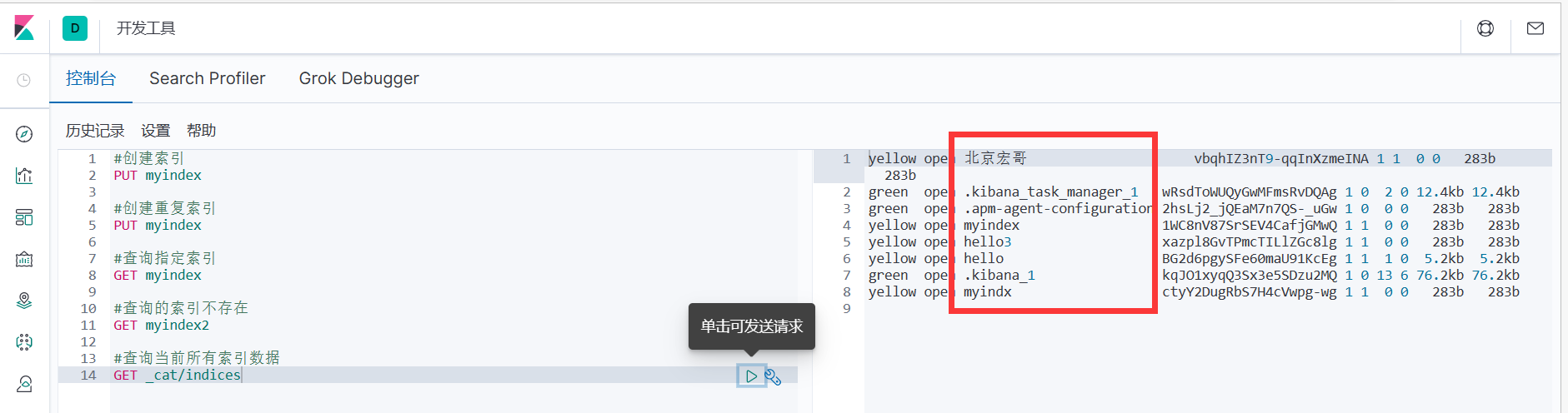
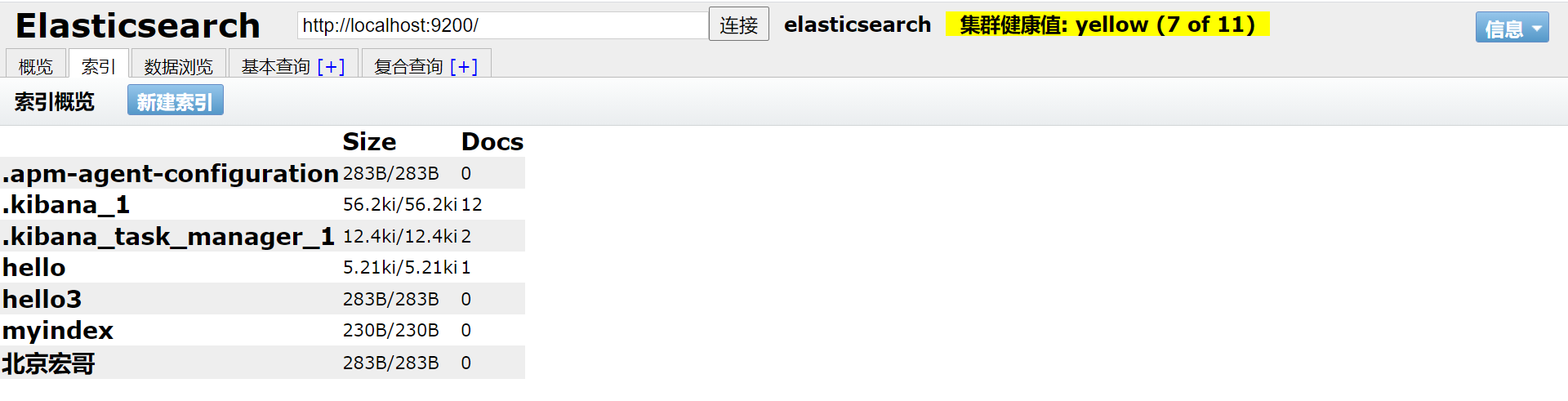
2. Результаты запроса здесь представляют информацию о состоянии индекса. Результаты в последовательных данных следующие:
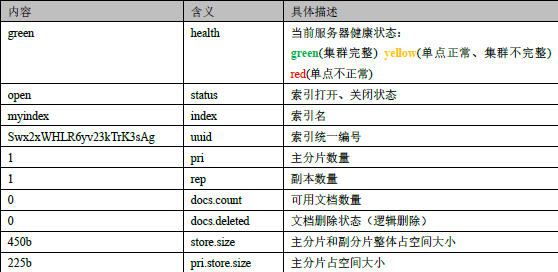
4.1.4 Удаление индекса
1. Удалить указанный существующий индекс
#Удалить указанный существующий индекс
УДАЛИТЬ мой индекс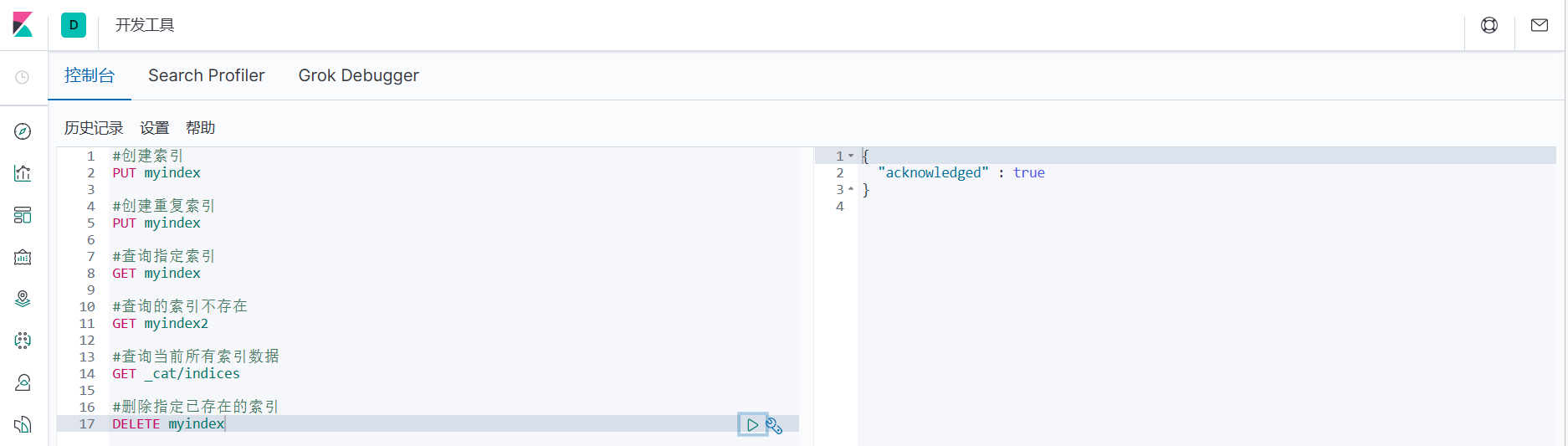
2. Если вы удалите несуществующий индекс, будет возвращено сообщение об ошибке.
#Удалить указанный индекс, который не существует
УДАЛИТЬ мойindex3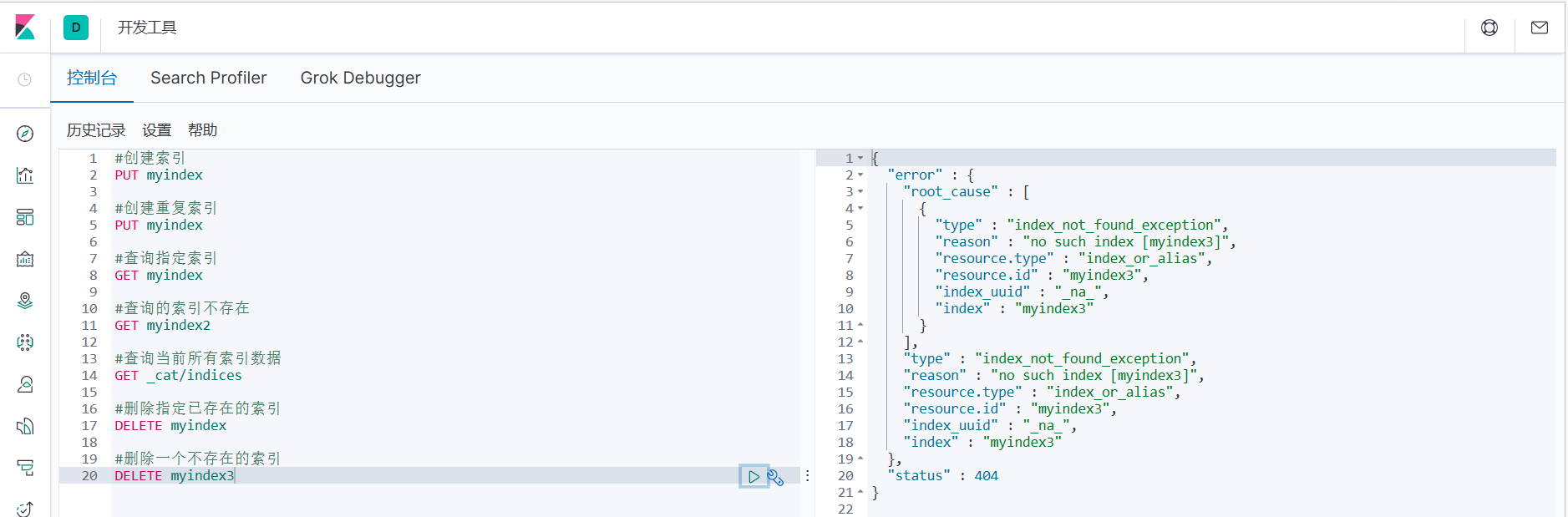
4.2 Работа с документом
Документ — это наименьшая единица поиска данных в программном обеспечении ES. Он не опирается на предопределенные шаблоны, поэтому документ можно сравнить со строкой данных типа JSON в таблице. Мы знаем, что в реляционных базах данных поля должны быть определены заранее, прежде чем их можно будет использовать. В Elasticsearch поля очень гибкие. Иногда мы можем игнорировать поле или добавлять новое поле динамически.
4.2.1 Создание документов
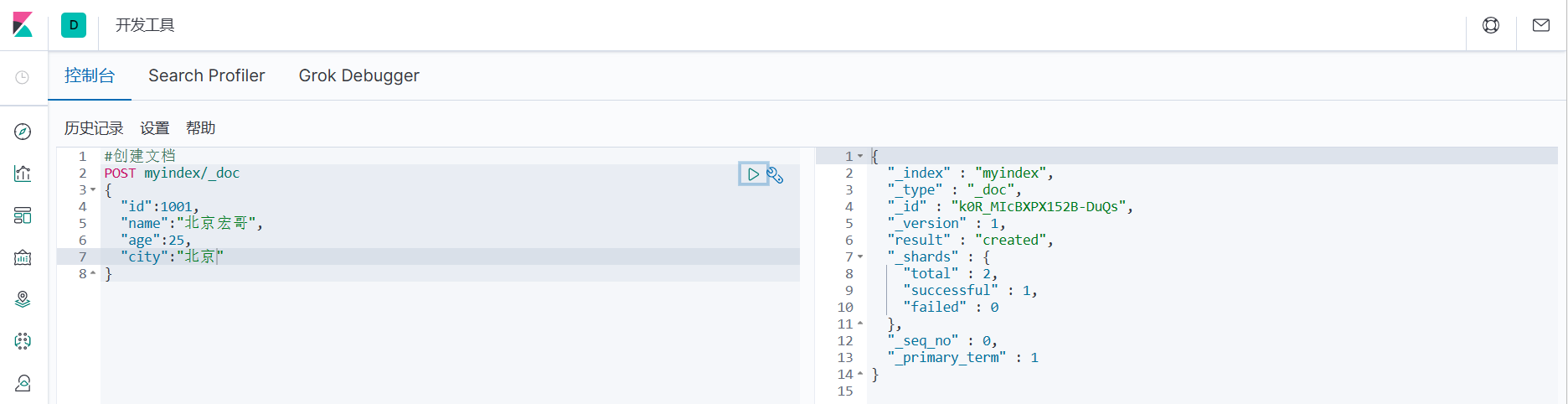
1. Индекс создан. Далее создаем документ и добавляем данные. Документы здесь можно сравнить с данными таблицы в реляционной базе данных, а формат добавленных данных — формат JSON.
#Создать документ
POST myindex/_doc
{
"id":1001,
"name":"Пекин Хонге",
"age":25,
"city":"Пекин"
}
2. Поскольку уникальный идентификатор данных здесь не указан, запрос PUT не может использоваться. Можно использовать только запрос POST, и для данных будет сгенерирован случайный уникальный идентификатор. В противном случае будет возвращено сообщение об ошибке
#Создать документ
PUT myindex/_doc
{
"id":1001,
"name":"Пекин Хонге",
"age":25,
"city":"Пекин"
}
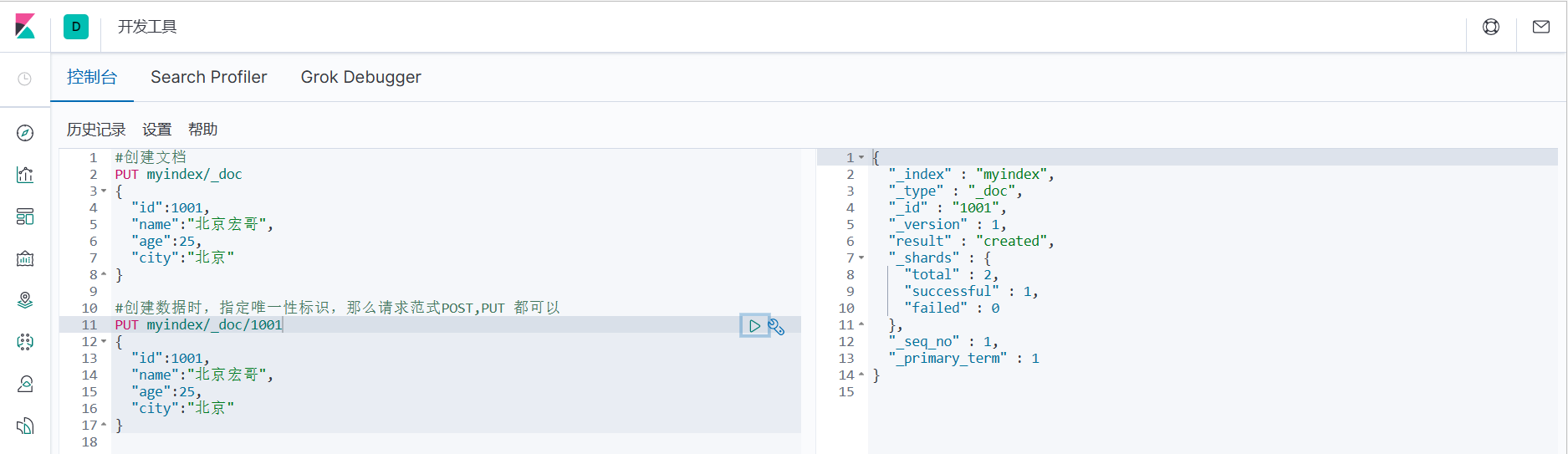
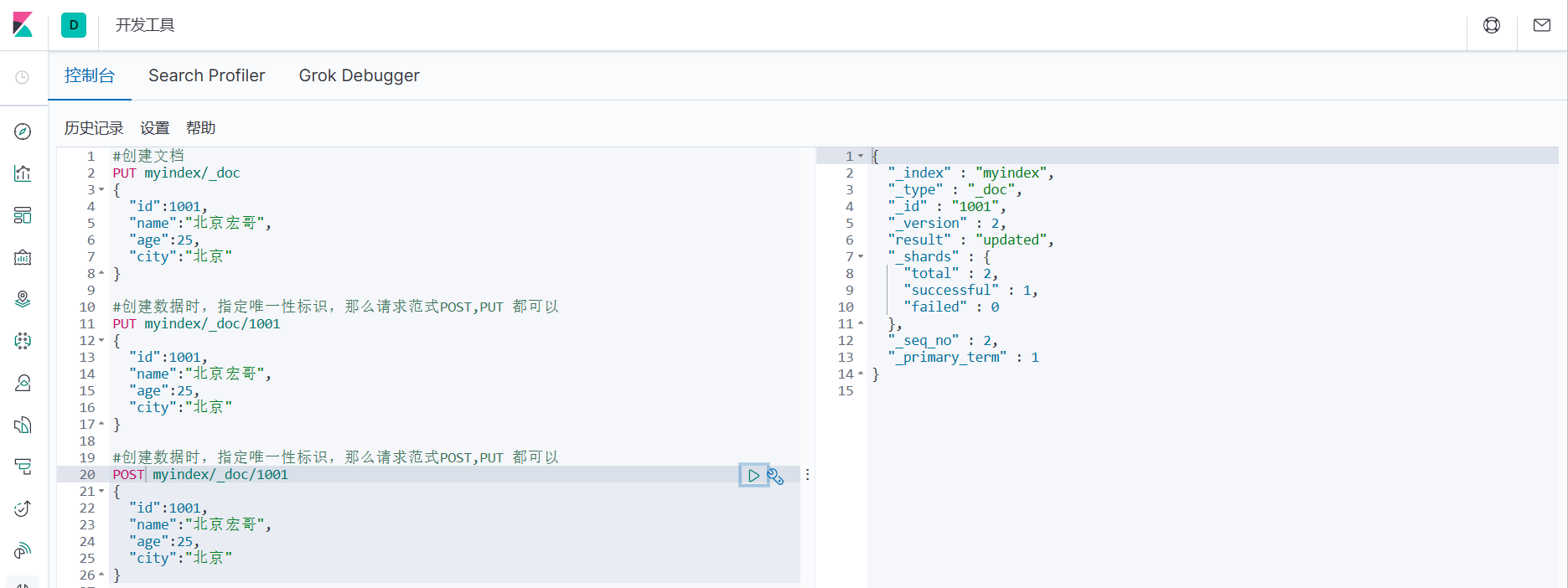
3. Если при создании данных вы указываете уникальный идентификатор, парадигма запроса может быть POST или PUT.
#При создании данных,Укажите уникальный идентификатор,Затем запросите парадигмуPOST,PUT все будет в порядке
PUT myindex/_doc/1001
{
"id":1001,
"name":"Пекин Хонге",
"age":25,
"city":"Пекин"
}
POST myindex/_doc/1001
{
"id":1001,
"name":"Пекин Хонге",
"age":25,
"city":"Пекин"
}
4.2.2 Запрос документов
1. Соответствующий документ можно запросить по уникальному идентификатору.
#Запрашиваем документ с указанным идентификатором
ПОЛУЧИТЬ myindex/_doc/1001?pretty=true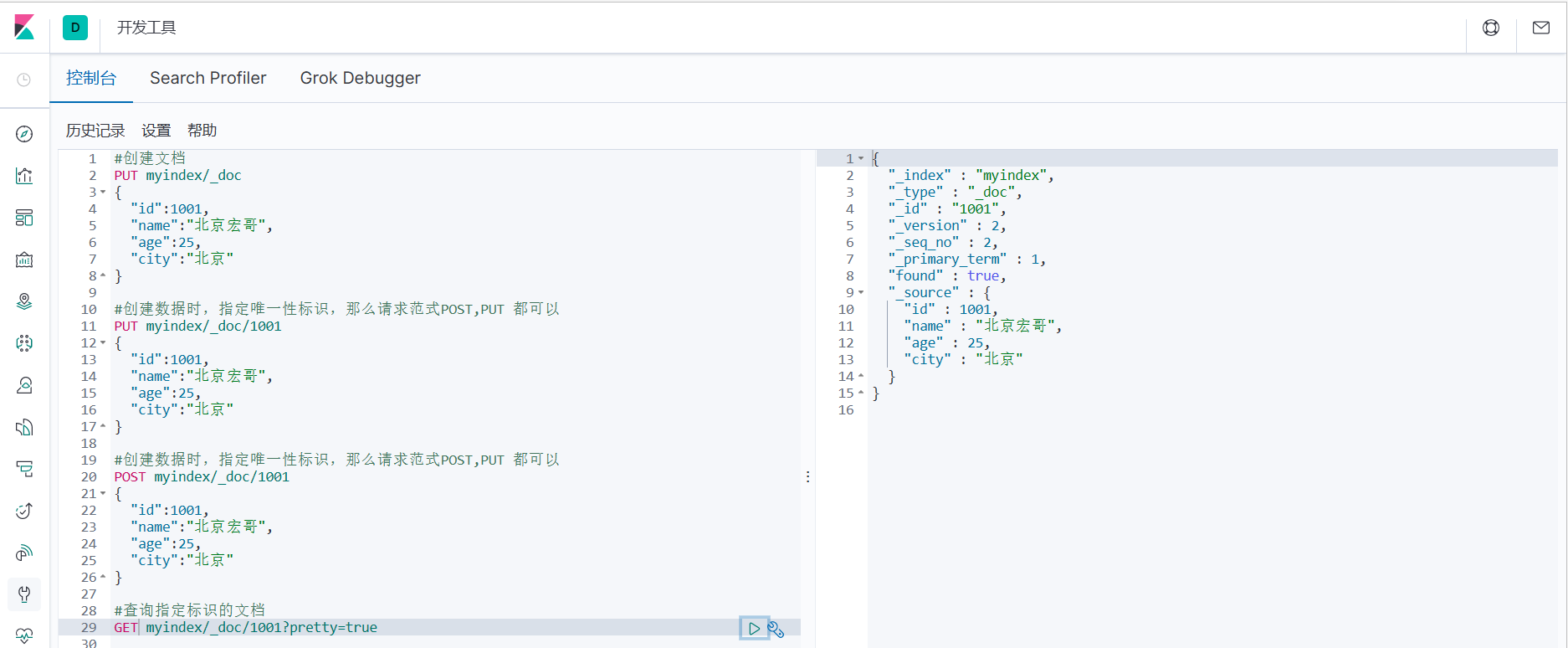
4.2.3 Изменение документов
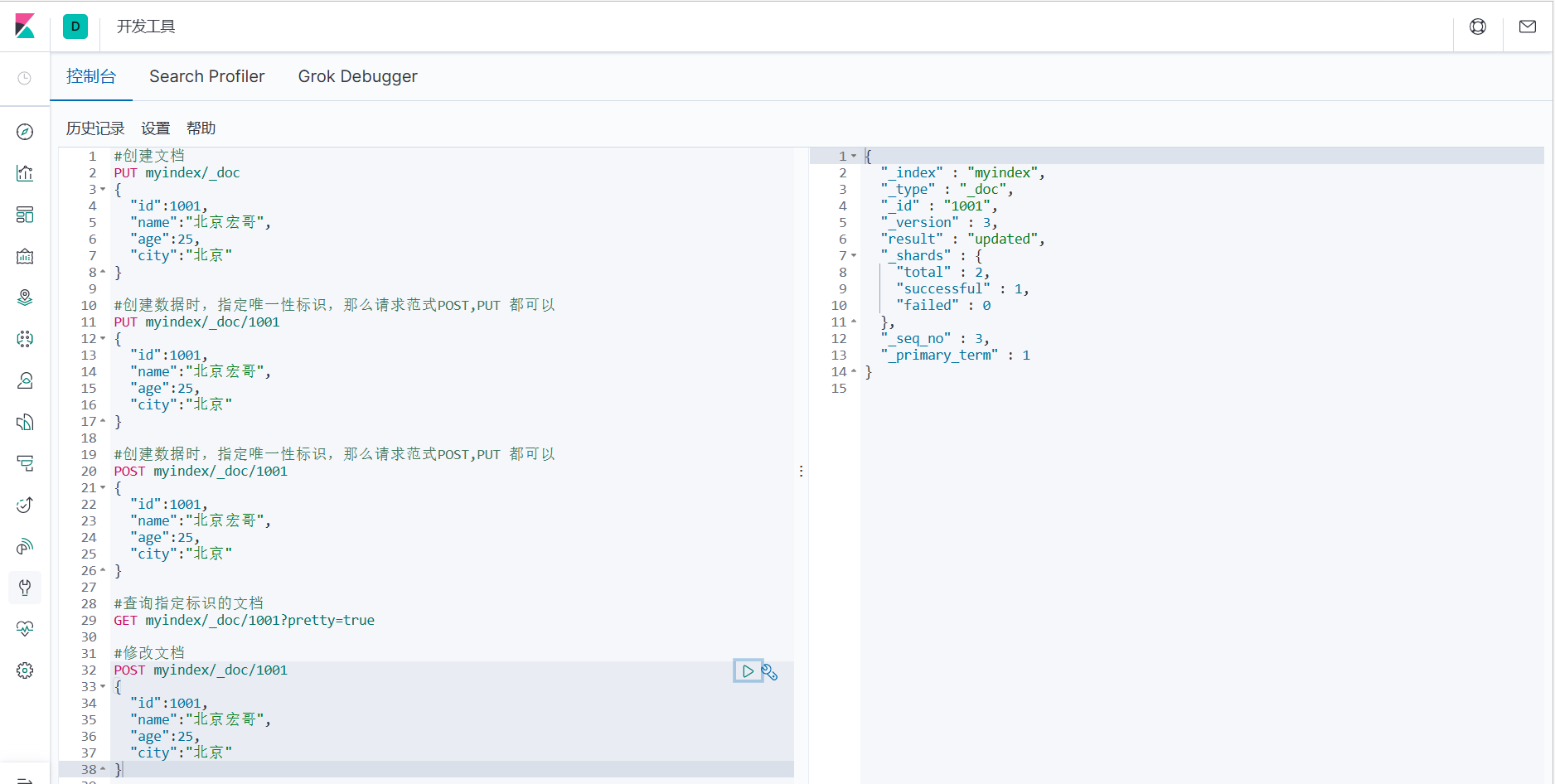
1. Изменение документа по сути аналогично добавлению нового документа. Если он существует, измените его, если он не существует, добавьте его.
#Изменить документ
POST myindex/_doc/1001
{
"id":1001,
"name":"Пекин Хонге",
"age":25,
"city":"Пекин"
}
4.2.4 Удаление документов
1. Удаление документа не приведет к его немедленному удалению с диска, он просто будет помечен как удаленный (надгробие).
#Удалить документ
DELETE myindex/_doc/1001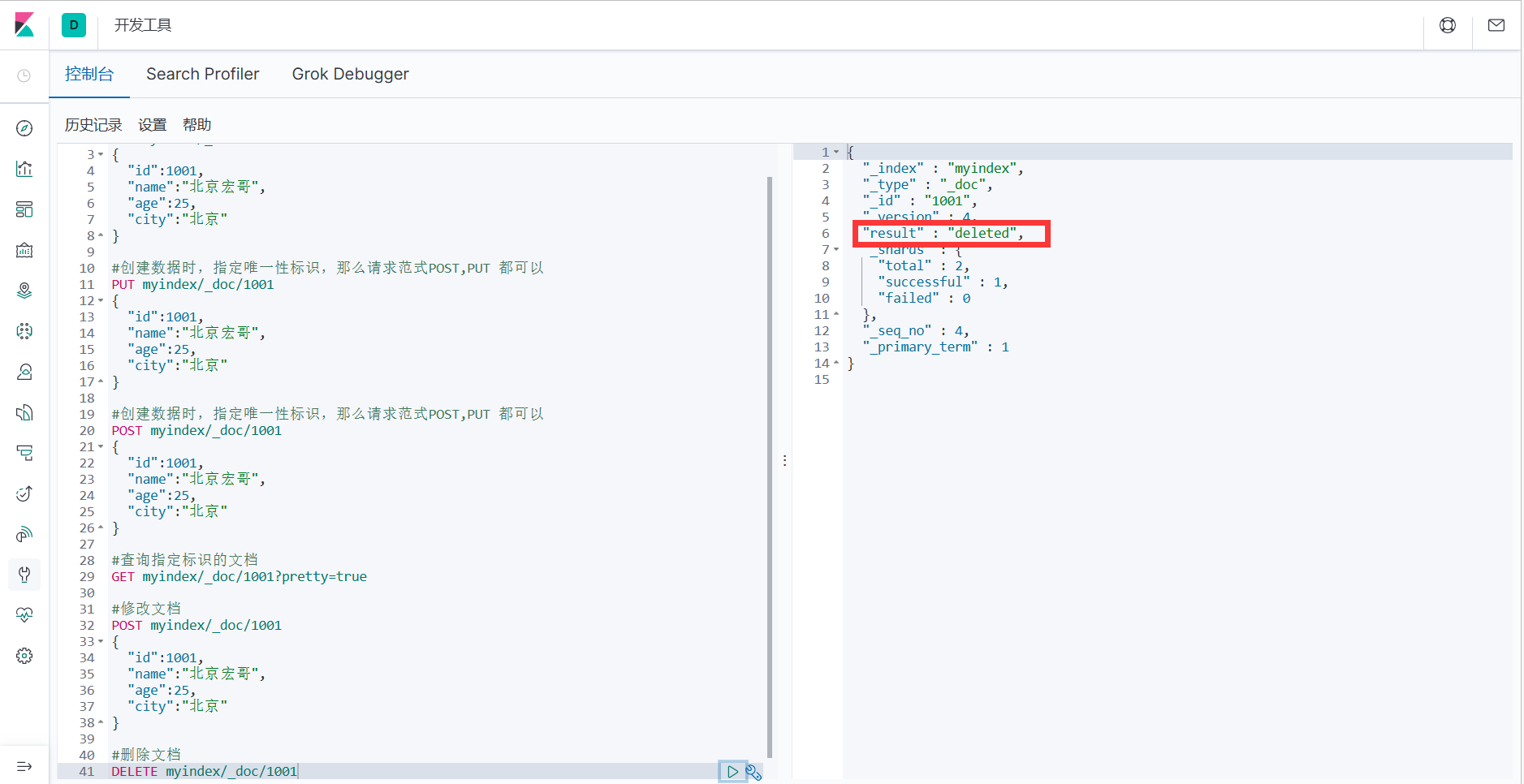
4.2.5 Запрос всех документов
#Запросить все документы
GET myindex/_search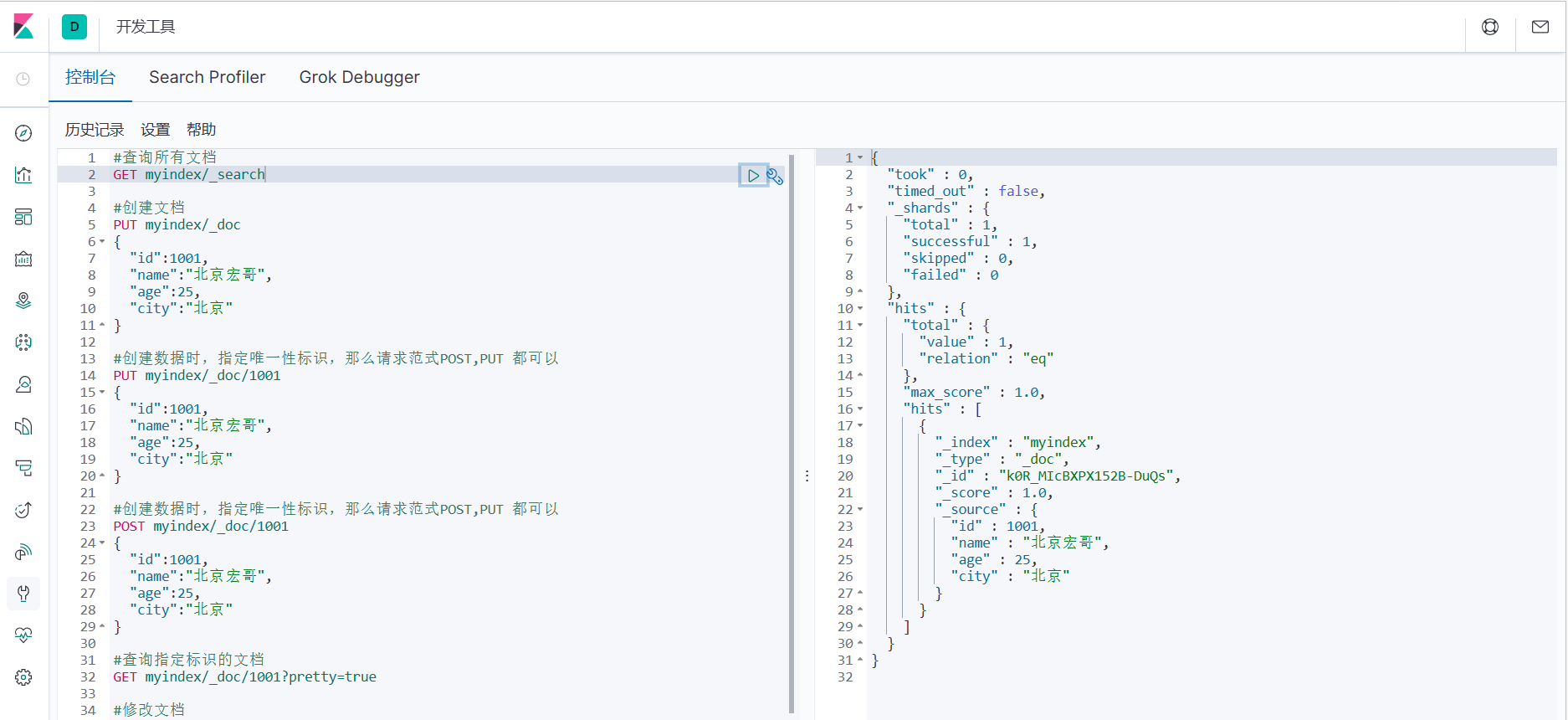
4.3 Поиск данных
1. Чтобы облегчить демонстрацию, заранее подготовьте несколько фрагментов данных.
4.3.1 Запрос всех документов
#Запросить все документы
GET myindex/_search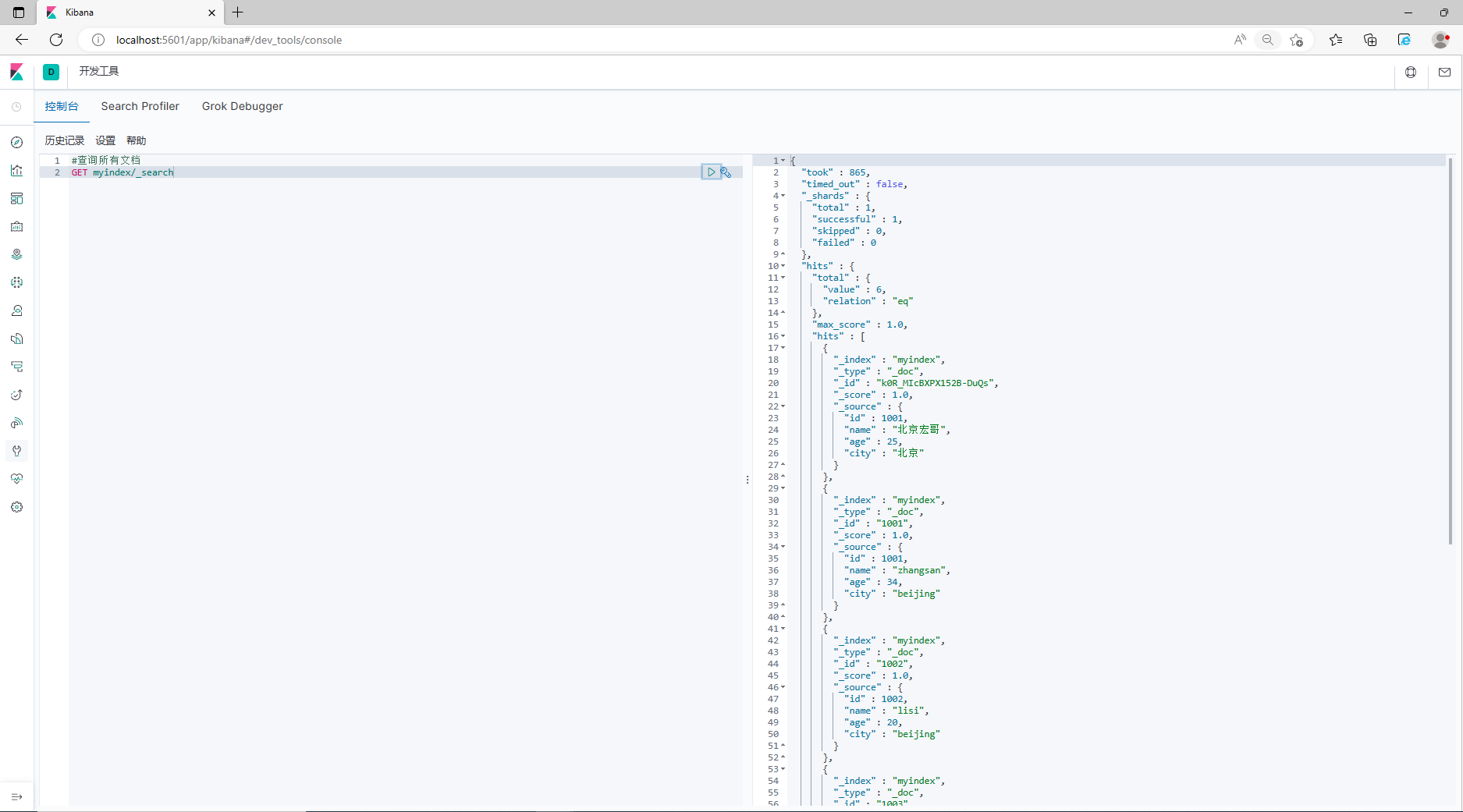
4.3.2 Сопоставление документов запроса
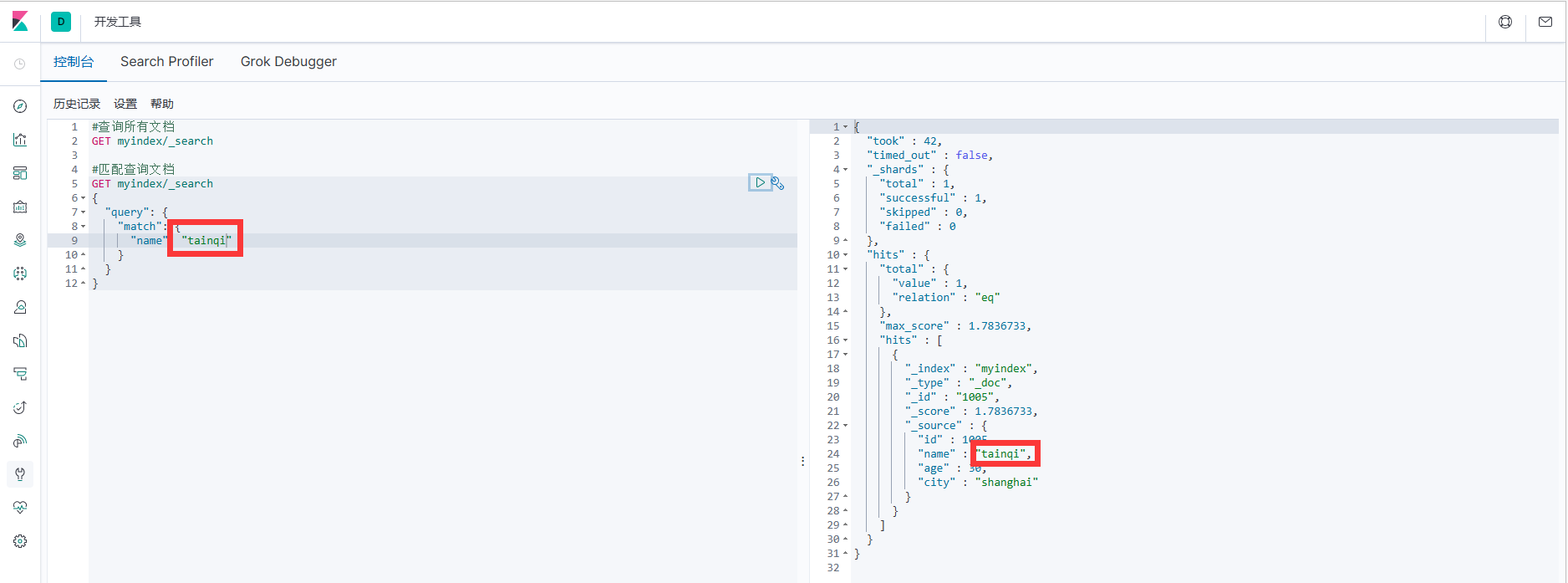
Запрос здесь указывает, что атрибут имени в данных объекта JSON в данных документа — tianqi.
#Документ запроса на совпадение
GET myindex/_search
{
"query": {
"match": {
"name": "tainqi"
}
}
}
4.3.3 Сопоставление полей запроса
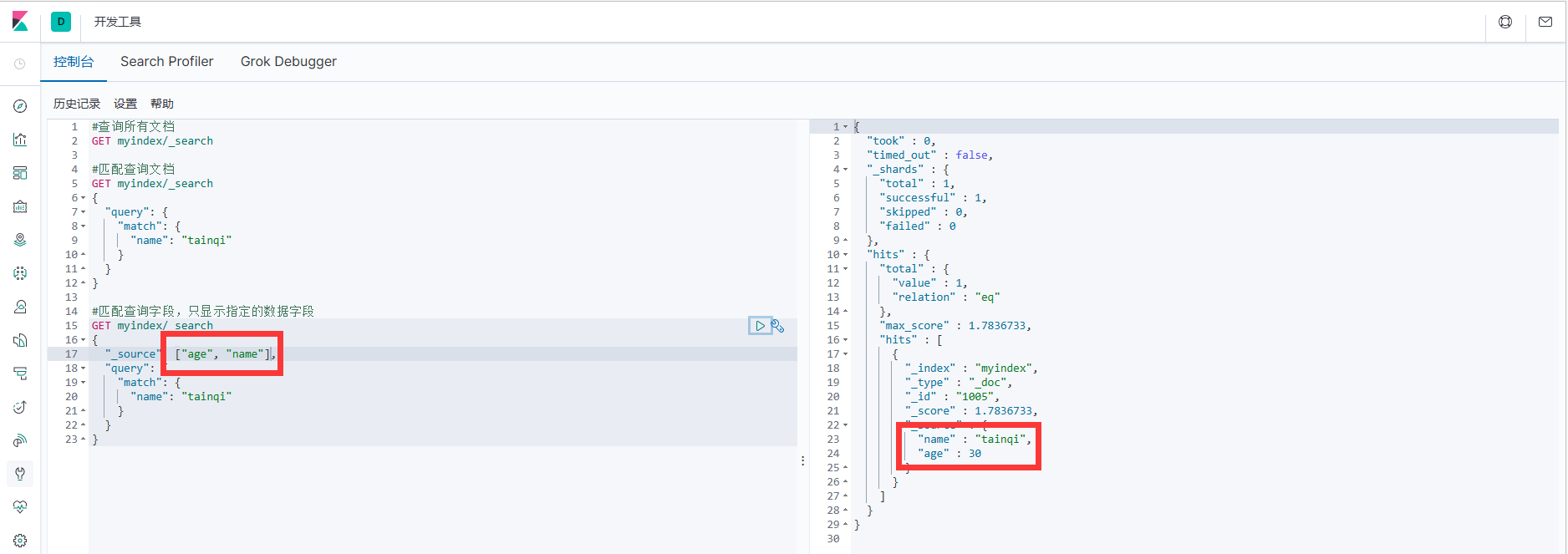
По умолчанию Elasticsearch в результатах поиска,будет сохранен в документесуществовать_source Все поля возвращаются. Если мы хотим получить только некоторые поля, мы можем добавить _source фильтрация
#Поле запроса соответствие, отображать только указанные поля данных
GET myindex/_search
{
"_source": ["age", "name"],
"query": {
"match": {
"name": "tainqi"
}
}
}
4.4 Агрегированный поиск
Агрегация позволяет пользователям выполнять статистический анализ документов ЭП, аналогичный группировке в реляционных базах данных. Конечно, существует множество других агрегаций, таких как максимальное значение, среднее значение и т. д.
4.4.1 Среднее значение
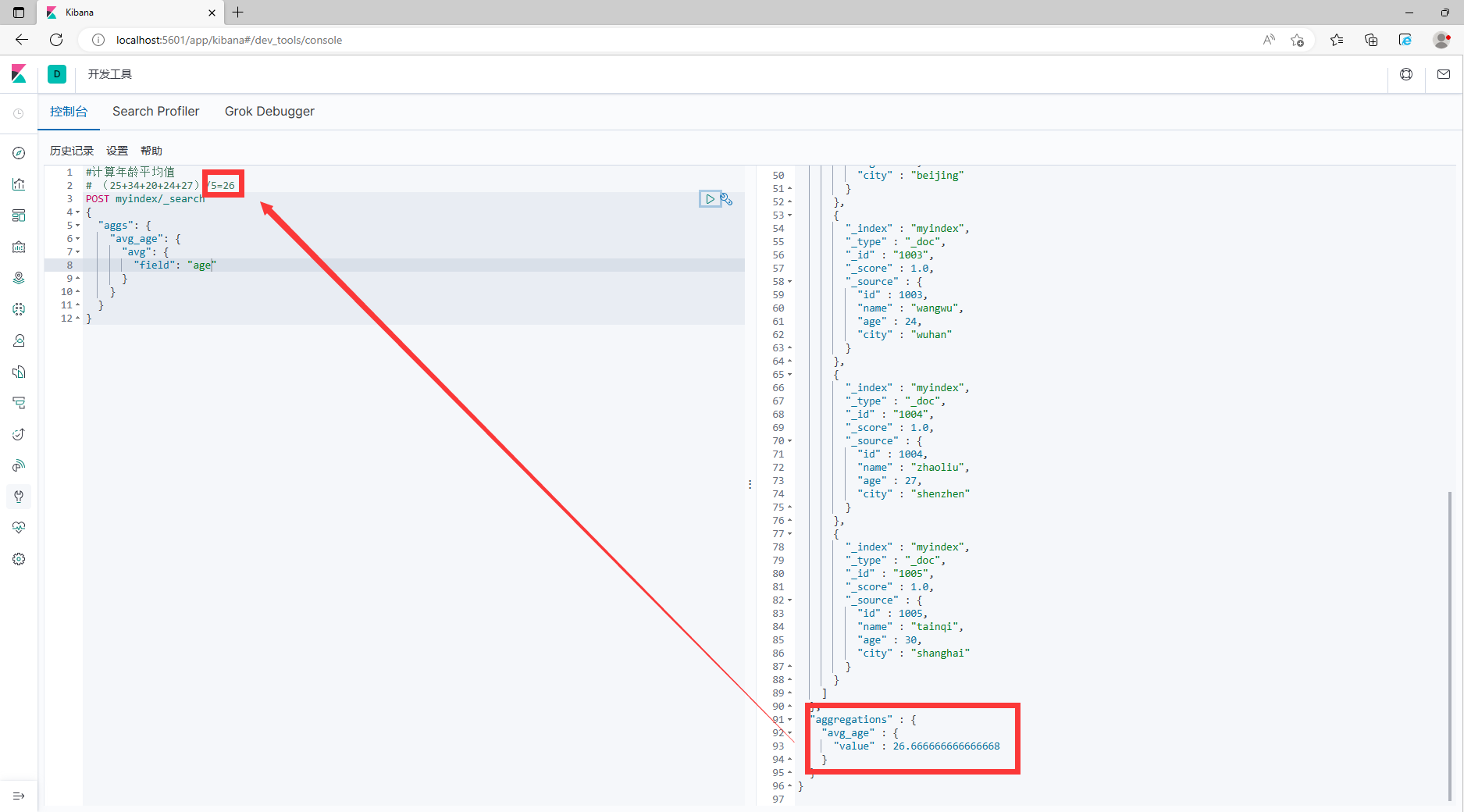
#Рассчитать средний возрастценить
# (25+34+20+24+27)/5=26
POST myindex/_search
{
"аггс": {
"avg_age": {
"среднее": {
"поле": "возраст"
}
}
}
}
4.4.2 Суммирование
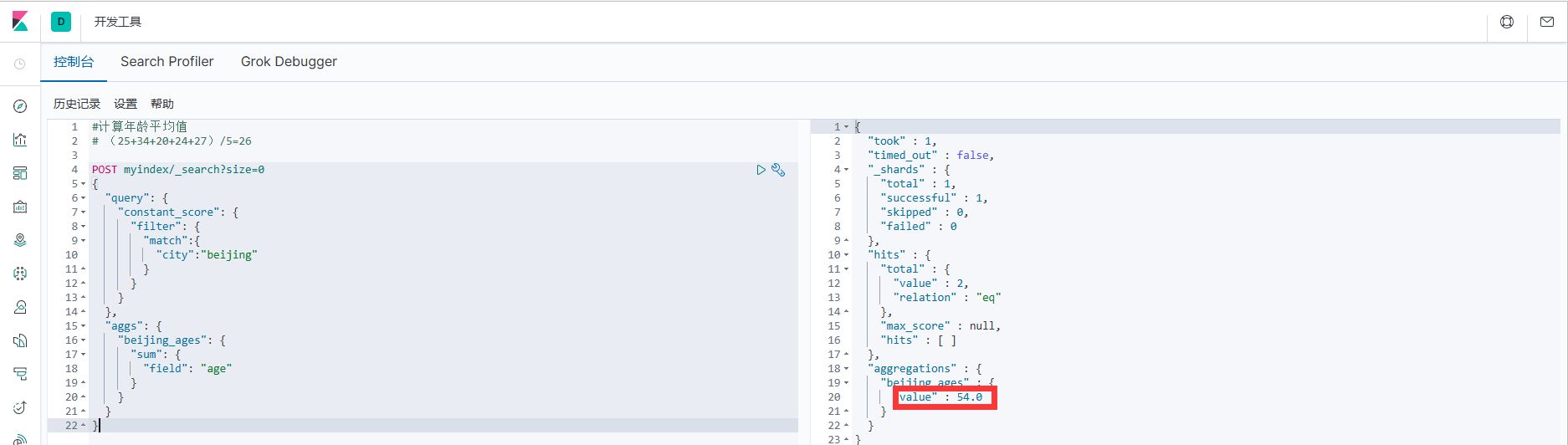
1. Например, сначала запросите город: Пекин, а затем сложите возраст.
POST myindex/_search?size=0
{
"query": {
"constant_score": {
"filter": {
"match":{
"city":"beijing"
}
}
}
},
"aggs": {
"beijing_ages": {
"sum": {
"field": "age"
}
}
}
}
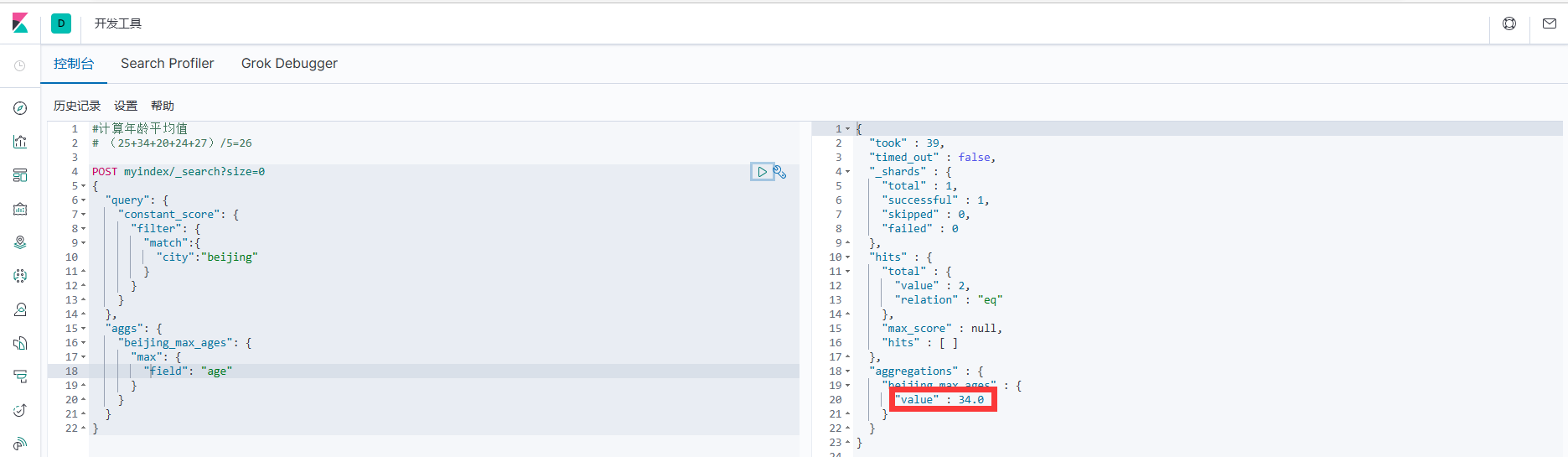
4.4.3 Максимальное значение
1. Например, сначала запросите город: Пекин, а затем сравните его возраст, чтобы найти самый старый возраст.
POST myindex/_search?size=0
{
"query": {
"constant_score": {
"filter": {
"match":{
"city":"beijing"
}
}
}
},
"aggs": {
"beijing_max_ages": {
"max": {
"field": "age"
}
}
}
}
4.4.4 TopN
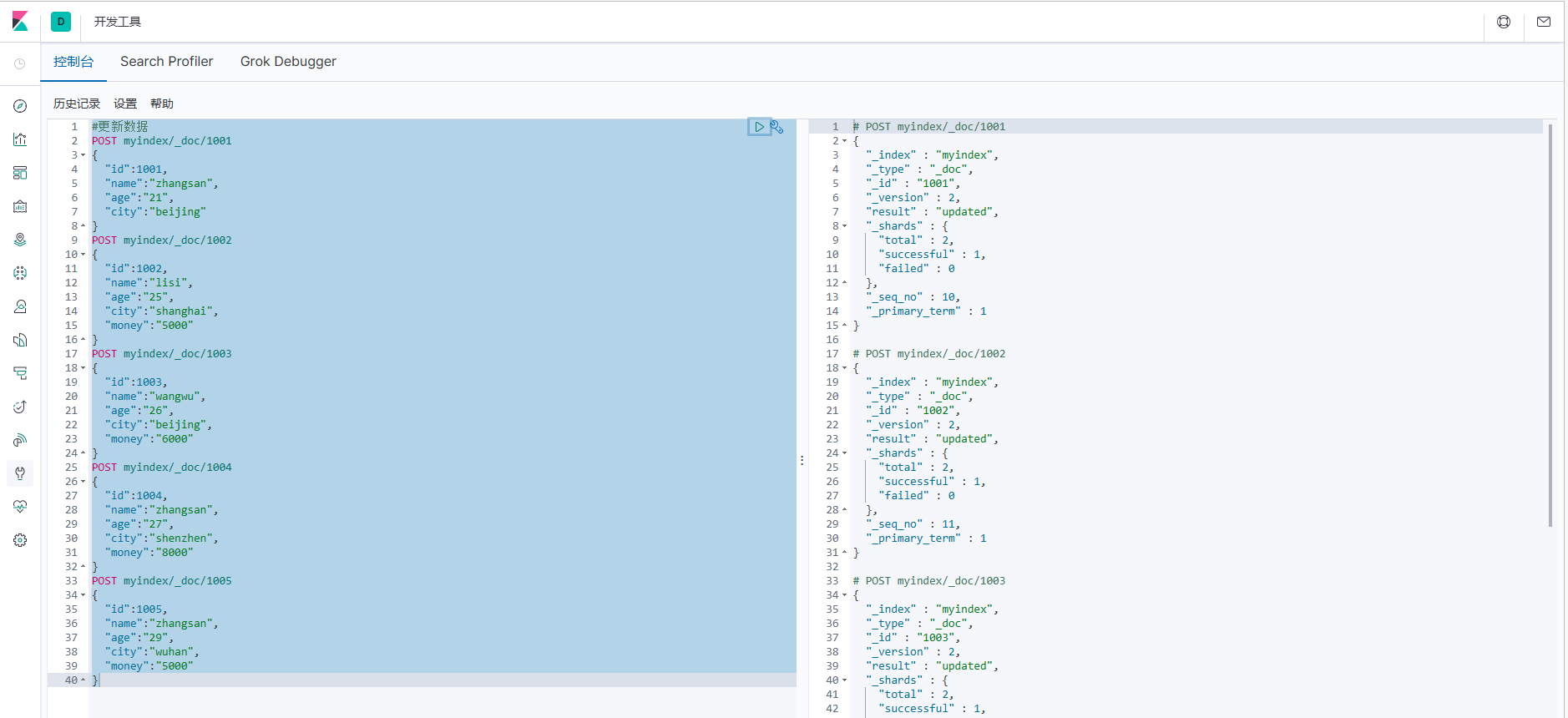
1. Сначала брат Хун обновит предыдущие данные, чтобы облегчить последующие демонстрации.
#Обновить данные
POST myindex/_doc/1001
{
«идентификатор»: 1001,
"name":"Чжансан",
"возраст":"21",
"город":"Пекин"
}
ПОСТ мойиндекс/_doc/1002
{
«идентификатор»: 1002,
"name":"лиси",
"возраст":"25",
"город":"Шанхай",
"деньги":"5000"
}
ПОСТ мойиндекс/_doc/1003
{
«идентификатор»: 1003,
"name":"ванву",
"возраст":"26",
"город":"Пекин",
"деньги":"6000"
}
ПОСТ мойиндекс/_doc/1004
{
«идентификатор»: 1004,
"name":"чжаолю",
"возраст":"27",
"город":"Шэньчжэнь",
"деньги":"8000"
}
ПОСТ мойиндекс/_doc/1005
{
"идентификатор": 1005,
"name":"тяньци",
"возраст":"29",
"город":"Ухань",
"деньги":"5000"
}
2. Запросить 3 записи по _key в порядке возрастания.
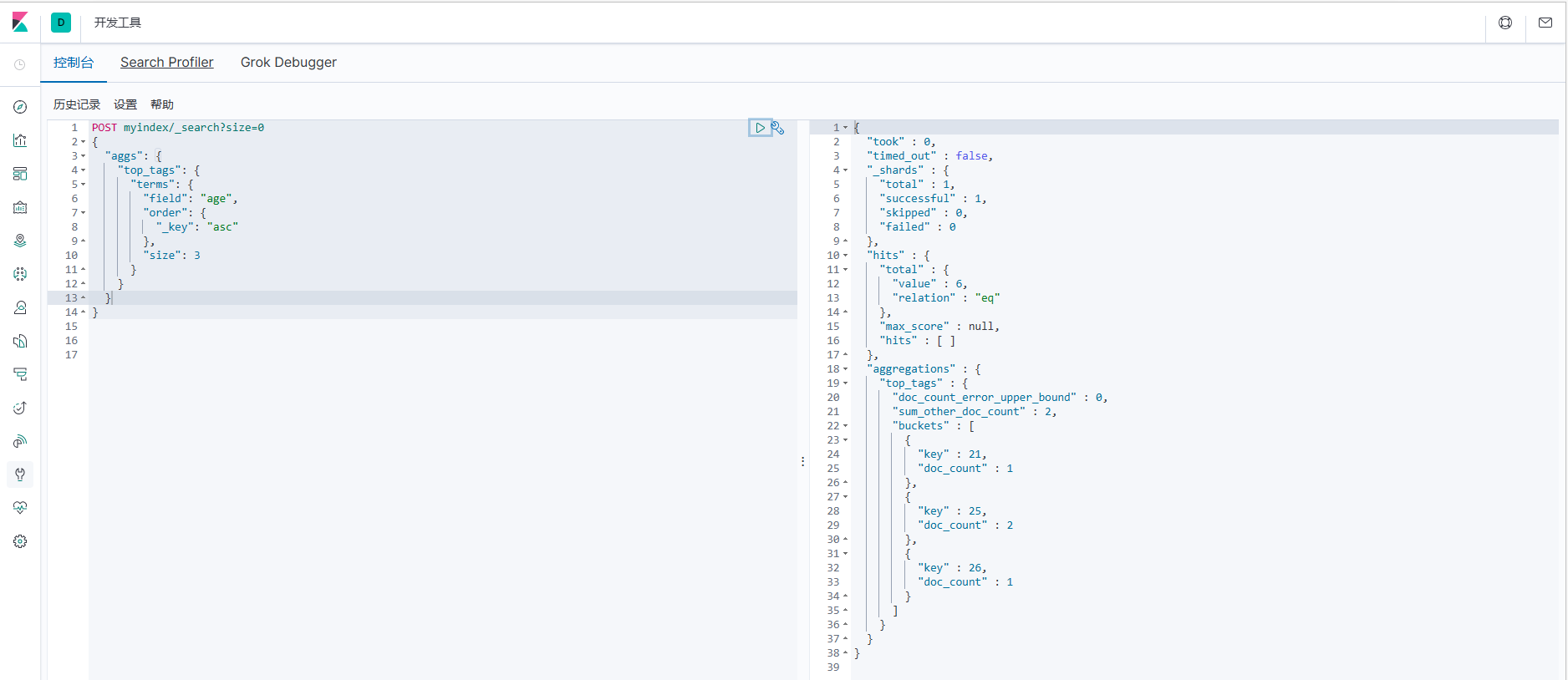
4.5 Шаблон индекса
Ранее мы установили некоторую информацию о конфигурации для индекса, но мы установили ее для одного индекса. В реальной разработке нам может потребоваться создать более одного индекса, но каждый индекс имеет более или менее общие черты. Например, когда мы проектируем реляционную базу данных, мы обычно проектируем некоторые часто используемые поля для каждой структуры таблицы, такие как время создания, время обновления, информация примечаний и т. д. Когда elasticsearch создает индекс, он вводит концепцию шаблонов. Сначала вы можете установить некоторые общие шаблоны. При создании индекса elasticsearch сначала установит индекс в соответствии с созданным вами шаблоном.
Elasticsearch предоставляет множество шаблонов настроек по умолчанию, поэтому, когда мы создаем новый документ, мы можем автоматически установить для вас некоторую информацию, выполнить некоторые преобразования полей и т. д.
Индексы можно создавать с использованием предопределенных шаблонов, называемых шаблонами индексов. Настройки шаблона включают настройки и сопоставления.
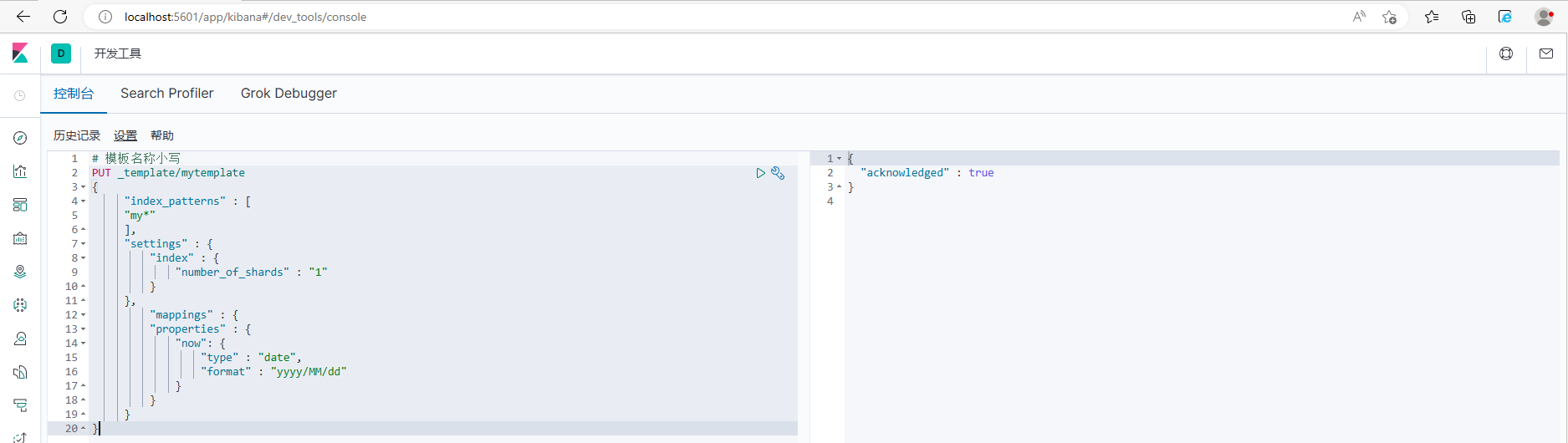
4.5.1 Создать шаблон
# Название шаблона в нижнем регистре
PUT _template/mytemplate
{
"index_patterns" : [
"my*"
],
"settings" : {
"index" : {
"number_of_shards" : "1"
}
},
"mappings" : {
"properties" : {
"now": {
"type" : "date",
"format" : "yyyy/MM/dd"
}
}
}
}
4.5.2 Просмотр шаблонов
# Посмотреть шаблон
GET /_template/mytemplate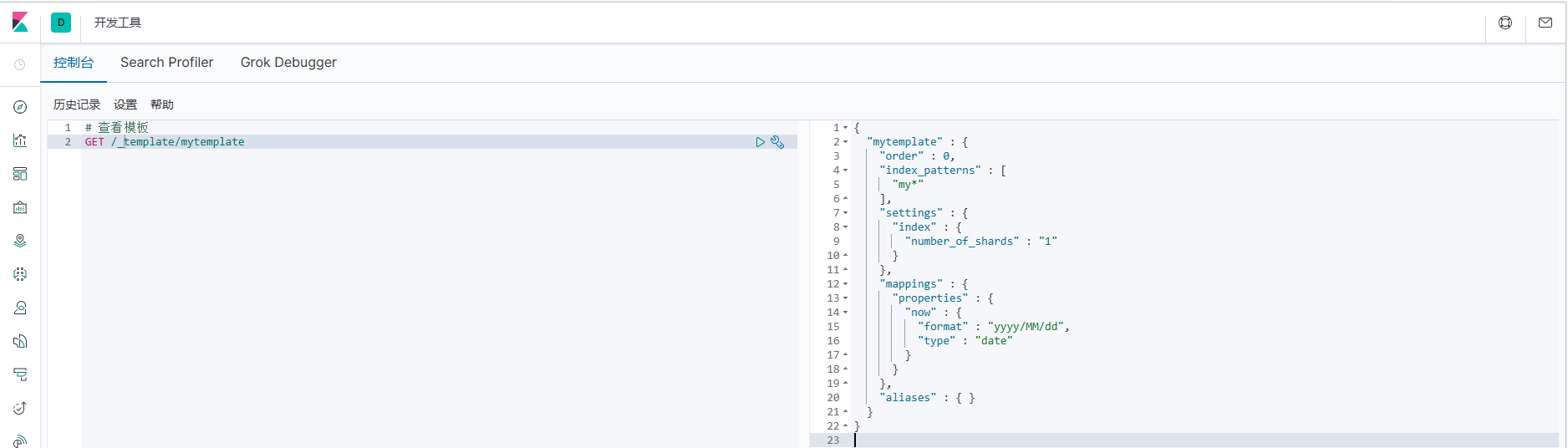
4.5.3 Проверка существования шаблона
#Шаблон проверки
HEAD /_template/mytemplate
4.5.4 Создать индекс
#Создать индекс
PUT mytest
4.5.5 Индекс запроса
#Индекс запроса
ПОЛУЧИТЬ мой тест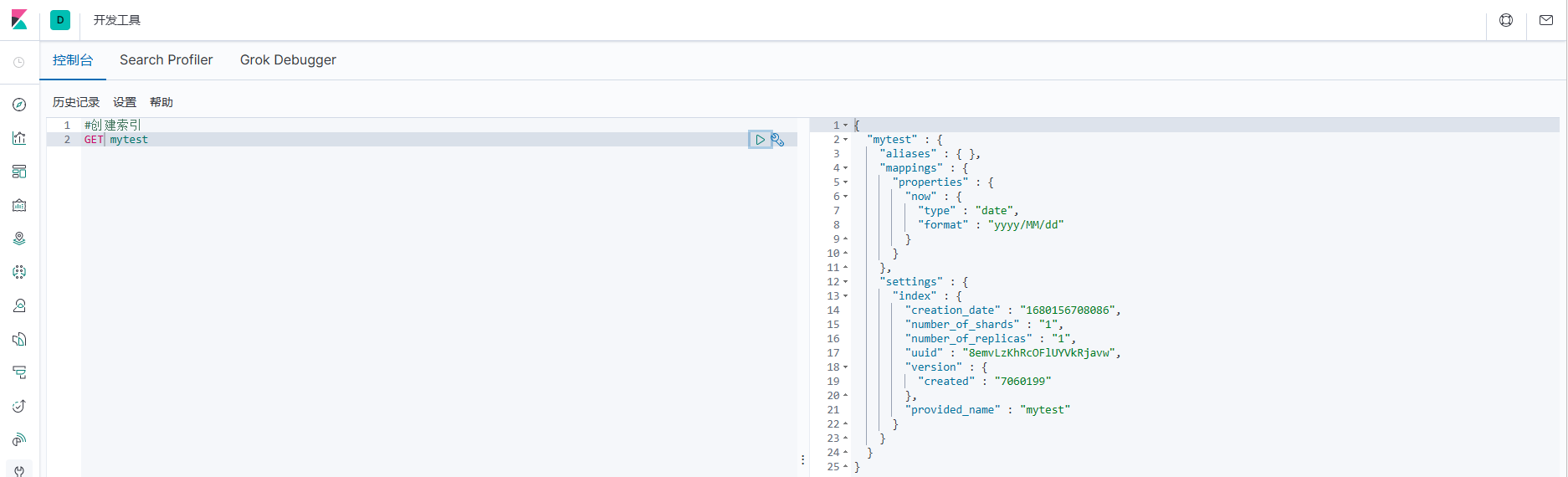
4.5.6 Удаление шаблона
#Удалить шаблон
DELETE /_template/mytemplate
4.6 Сегментация китайских слов
Когда мы воспользуемся официальным плагином сегментации слов Elasticsearch по умолчанию, мы обнаружим, что его эффект сегментации на китайских словах не очень хорош, а эффект после сегментации слов часто не тот, который нам нужен.
GET _analyze
{
"analyzer": "chinese",
"text": ["Я студент"]
}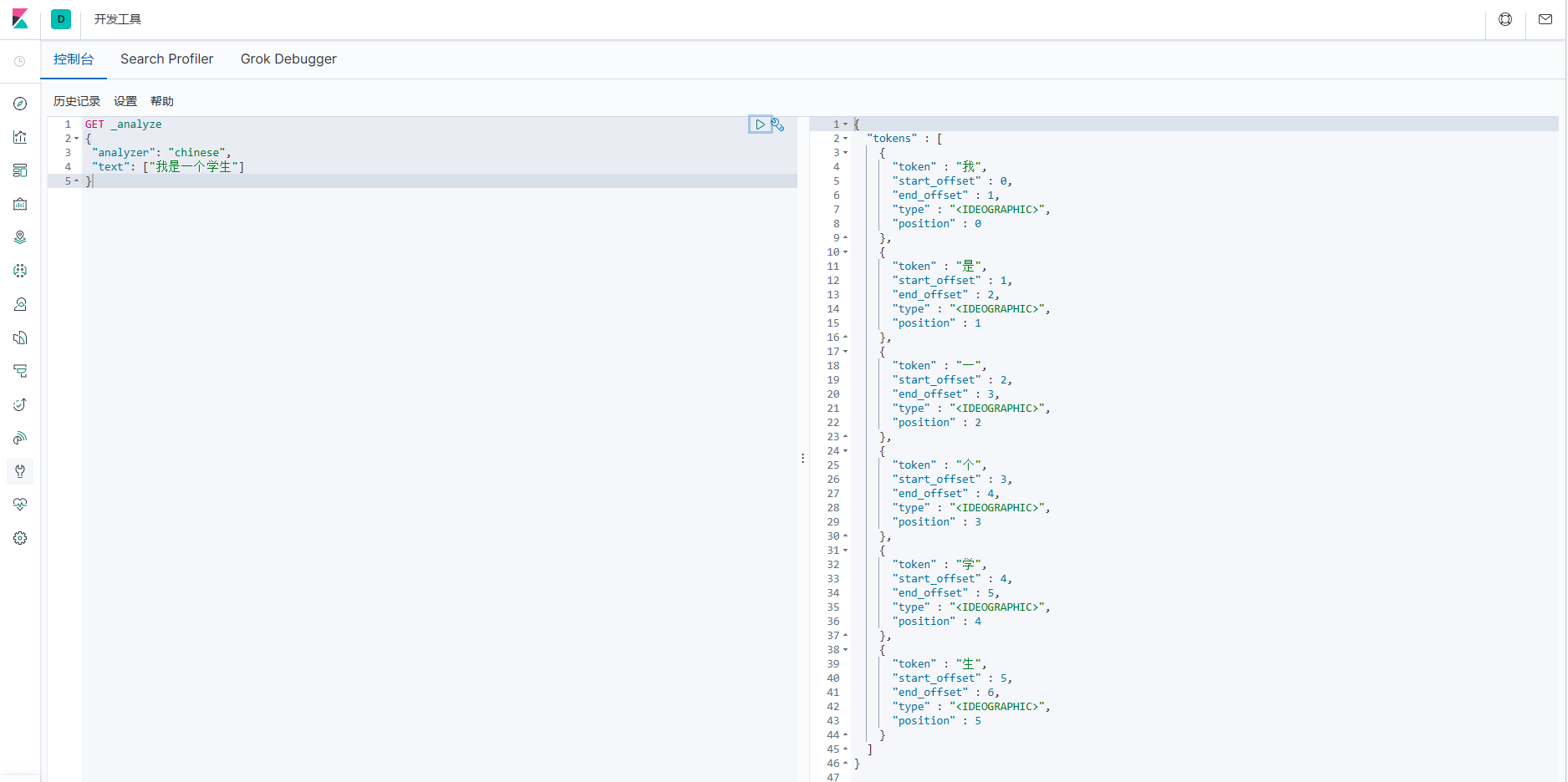
Чтобы лучше выполнять поиск и запросы на китайском языке, необходимо интегрировать хороший плагин для разбиения по словам в Elasticsearch, а плагин для разбиения по словам IK — это плагин, используемый для поддержки китайского языка. Это было описано в предыдущей статье и здесь повторяться не будет.
4.7 Оценка документа
Механизм оценки Lucene и ES представляет собой формулу, основанную на частоте слов и обратной частоте слов в документе, называемую формулой TF-IDF.
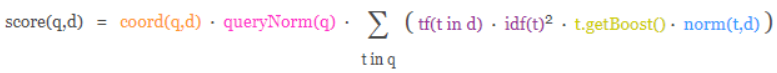
Формула принимает запрос в качестве входных данных, использует различные методы для определения оценки каждого документа и, наконец, объединяет каждый фактор с помощью формулы, чтобы получить окончательную оценку документа. Этот комплексный процесс рассмотрения представляет собой процесс рассмотрения, в ходе которого мы надеемся, что соответствующие документы будут возвращены в первую очередь. В Lucene и ES эта корреляция называется оценкой.
Учитывая, что связь между содержимым запроса и документами относительно сложна, в формулу необходимо ввести множество параметров и условий. Но наиболее важными из них на самом деле являются два алгоритмических механизма.
- TF (частота термина) Частота термина: сколько раз каждый термин в тексте поиска встречается в тексте запроса. Чем больше вхождений, тем более релевантным будет этот термин и тем выше будет оценка.
- IDF (обратная частота документов) Обратная частота документов: сколько раз каждый термин в тексте поиска встречается во всех документах во всем индексе. Чем больше раз он встречается, тем менее важным и нерелевантным он является, и оценка будет ниже.
4.7.1 Механизм подсчета очков
Далее давайте на примере кратко проанализируем механизм оценки документа:
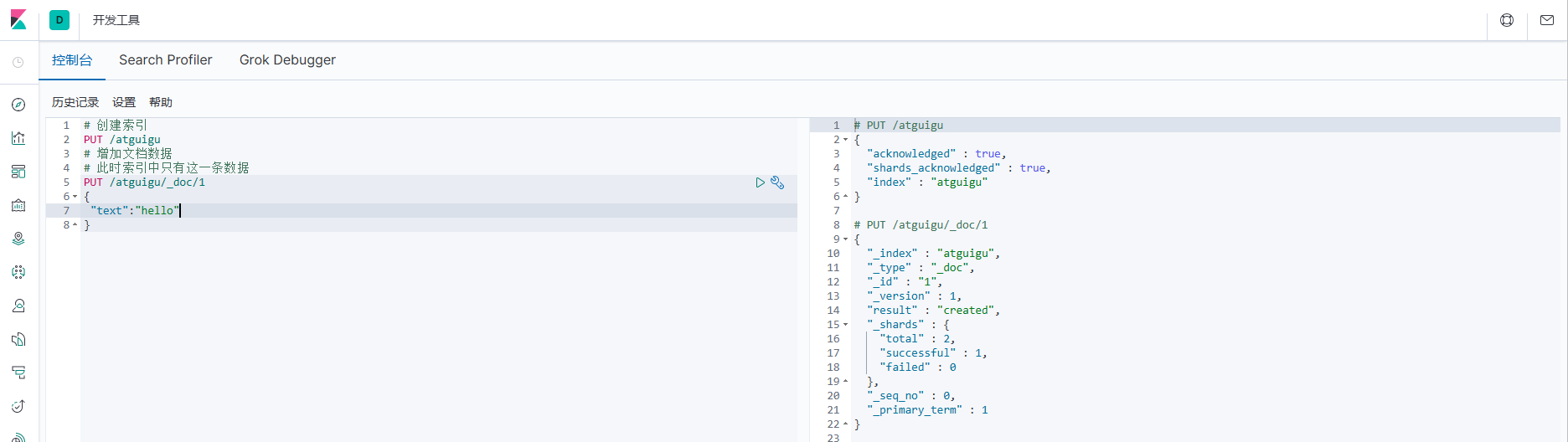
1. Сначала подготовьте исходные данные
# Создать индекс
PUT /atguigu
# Добавить данные документа
# В настоящее время в индексе есть только этот фрагмент данных
PUT /atguigu/_doc/1
{
"text":"hello"
}
2. Запрос условий соответствия данных документа
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}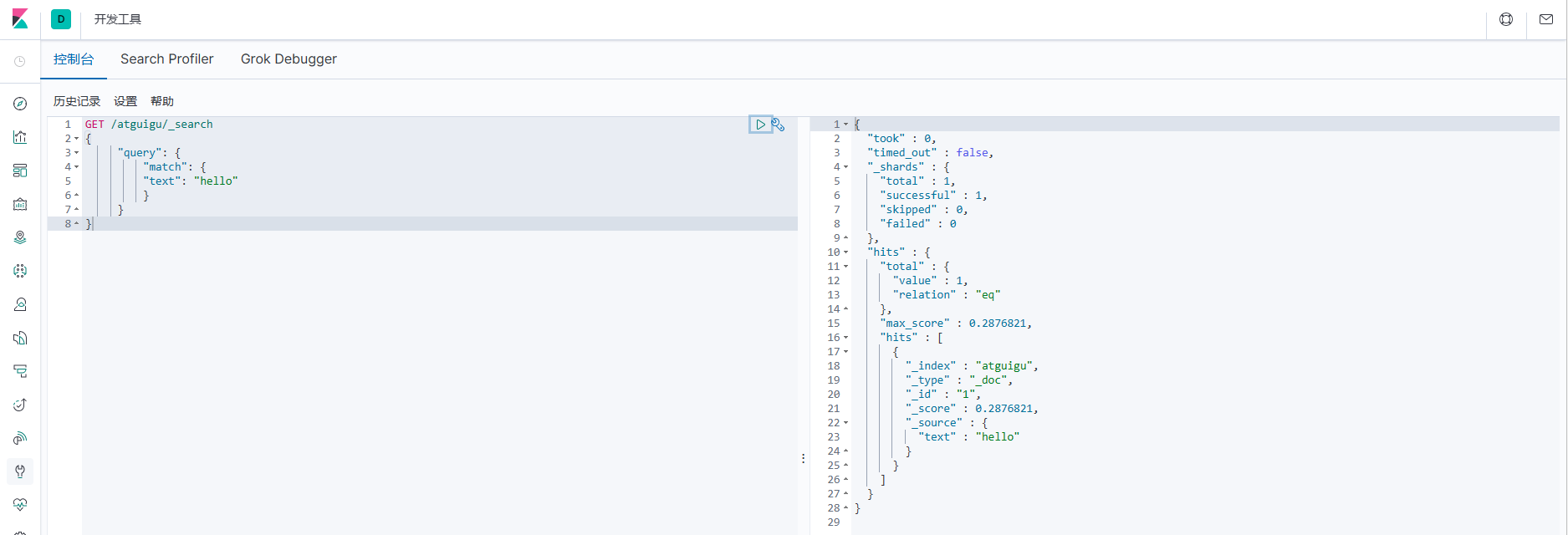
Оценка документа здесь: 0,2876821. Странно, что в настоящее время в индексе есть только одни данные документа, и данные документа могут напрямую соответствовать условиям запроса. Почему оценка такая низкая? Это результат расчета по формуле, давайте посмотрим
1. Анализ процесса оценки данных документа.
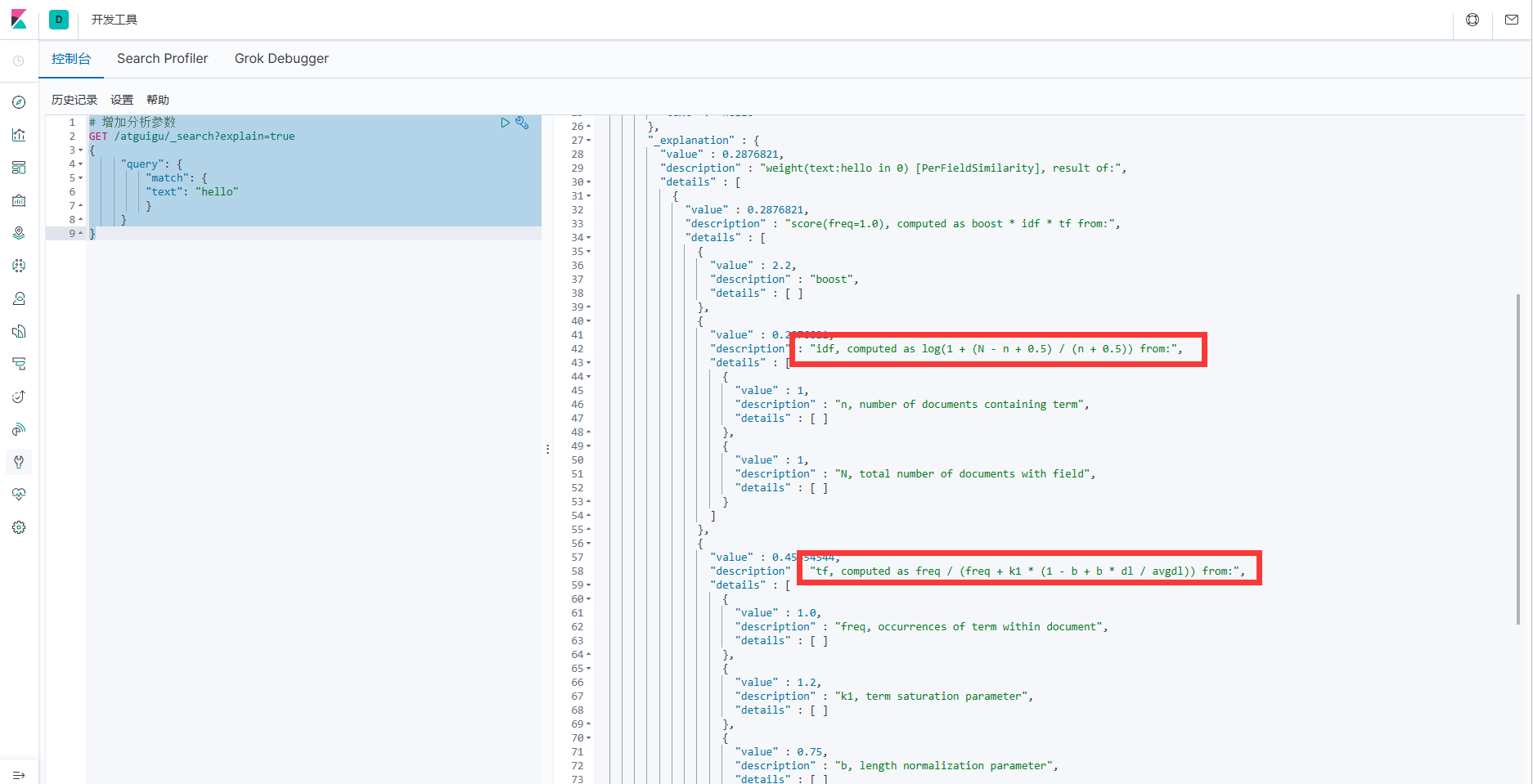
# Добавить параметры анализа
GET /atguigu/_search?explain=true
{
"query": {
"match": {
"text": "hello"
}
}
}2. После выполнения вы обнаружите, что в механизме подсчета очков есть 2 важных этапа: расчет значения TF и значения IDF.
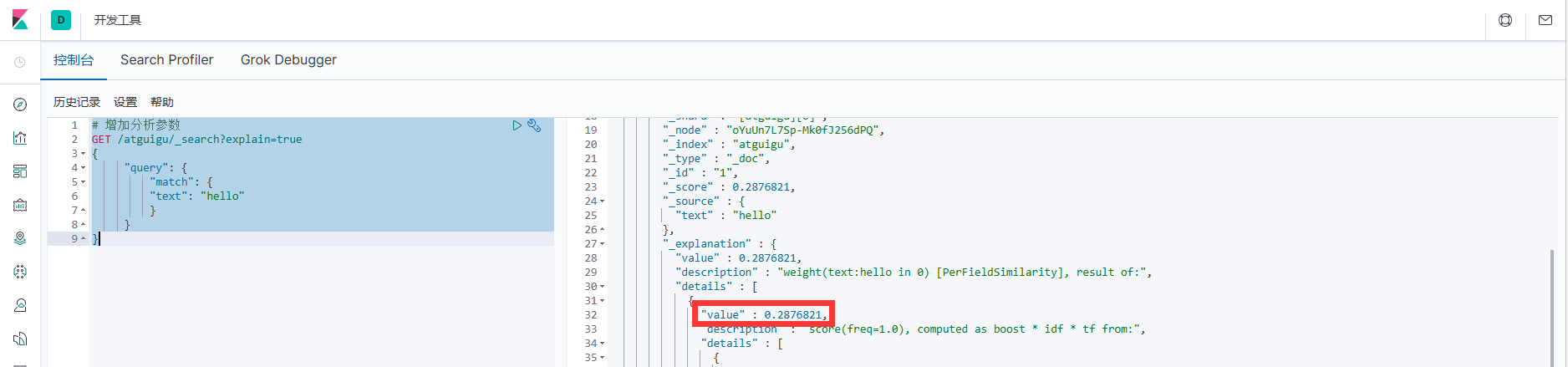
3. Итоговый результат:
4. Рассчитайте значение ТФ
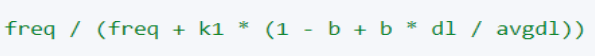
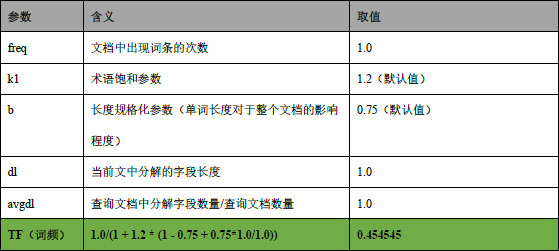
5. Рассчитать значение IDF
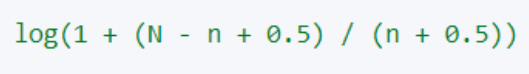

Примечание: здесь log — логарифм с основанием e.
6. Подсчитайте оценку документа
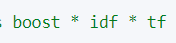

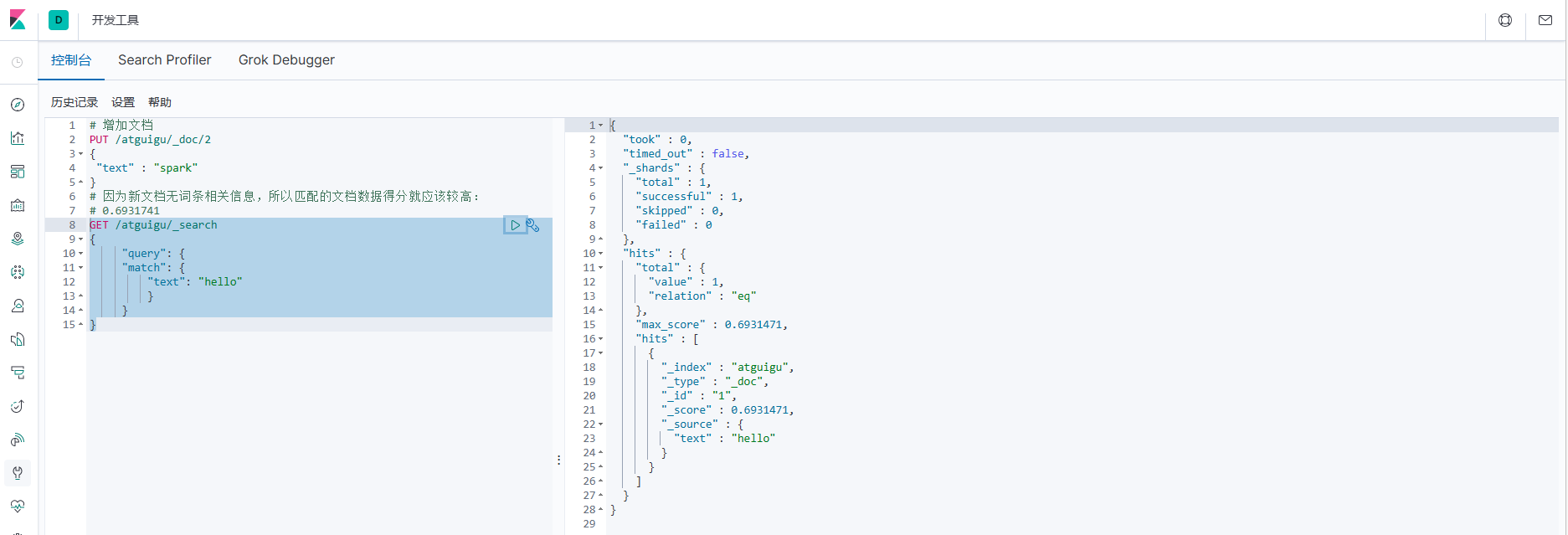
7. Добавьте новые документы и результаты тестов. !.Добавить несвязанный документ
# Добавить документацию
PUT /atguigu/_doc/2
{
"text" : "spark"
}
# Поскольку новый документ не содержит информации, связанной с записью, оценка данных соответствующего документа должна быть выше:
# 0.6931741
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}
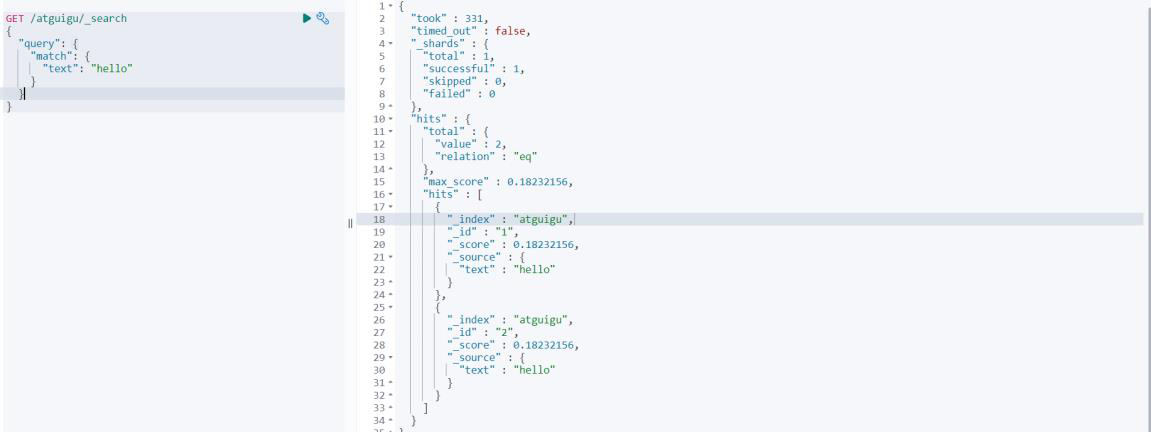
ii. Добавьте идентичный документ.
# Добавить документацию
PUT /atguigu/_doc/2
{
"text" : "hello"
}
# Поскольку новый документ содержит информацию, связанную с термином, а этот термин содержится в нескольких файлах, это не кажется очень важным, и оценка станет ниже.
# 0.18232156
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}
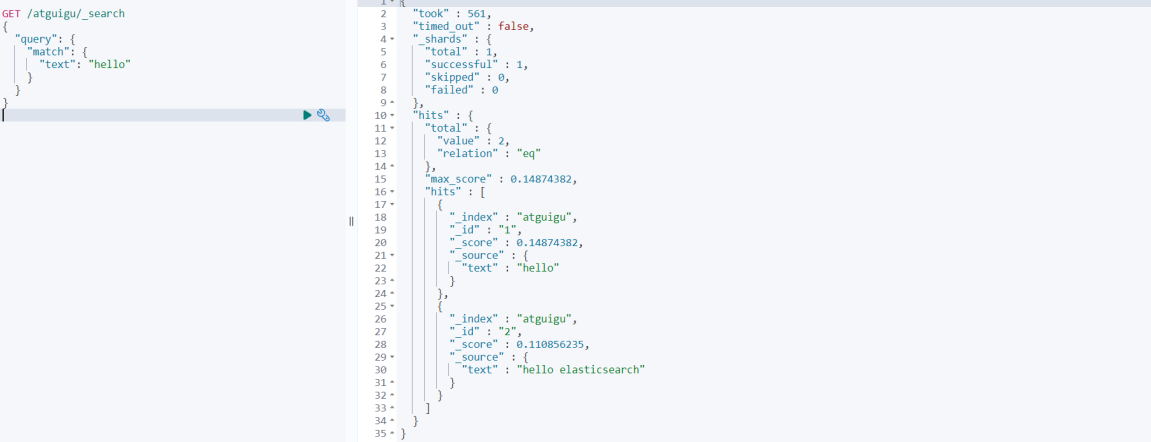
iii Добавьте документ, который содержит записи, но имеет больше контента.
# Добавить документацию
PUT /atguigu/_doc/2
{
"text" : "hello elasticsearch"
}
# Поскольку в новом документе содержится информация, относящаяся к записи, но только ее часть, Запрос Оценка документов станет ниже.
# 0.14874382
GET /atguigu/_search
{
"query": {
"match": {
"text": "hello"
}
}
}
3.7.2 Случай
нуждаться:
Содержимое запроса, содержащее слова «Hadoop», «Elasticsearch» и «Spark» в заголовке документа.
Расставьте приоритеты для контента «Spark»
1. Подготовьте данные
# Подготовьте данные
PUT /testscore/_doc/1001
{
"title" : "Hadoop is a Framework",
"content" : "Hadoop Это базовая структура больших данных»
}
PUT /testscore/_doc/1002
{
"title" : "Hive is a SQL Tools",
"content" : "Hive это SQL инструмент"
}
PUT /testscore/_doc/1003
{
"title" : "Spark is a Framework",
"content" : "Spark это Распределенная вычислительная машина"
}2. Запрос данных
# Подготовьте данные
PUT /testscore/_doc/1001
{
"title" : "Hadoop is a Framework",
"content" : "Hadoop Это базовая структура больших данных»
}
PUT /testscore/_doc/1002
{
"title" : "Hive is a SQL Tools",
"content" : "Hive это SQL инструмент"
}
PUT /testscore/_doc/1003
{
"title" : "Spark is a Framework",
"content" : "Spark это Распределенная вычислительная машина"
}На этом этапе вы обнаружите, что результаты Spark не размещаются вверху.
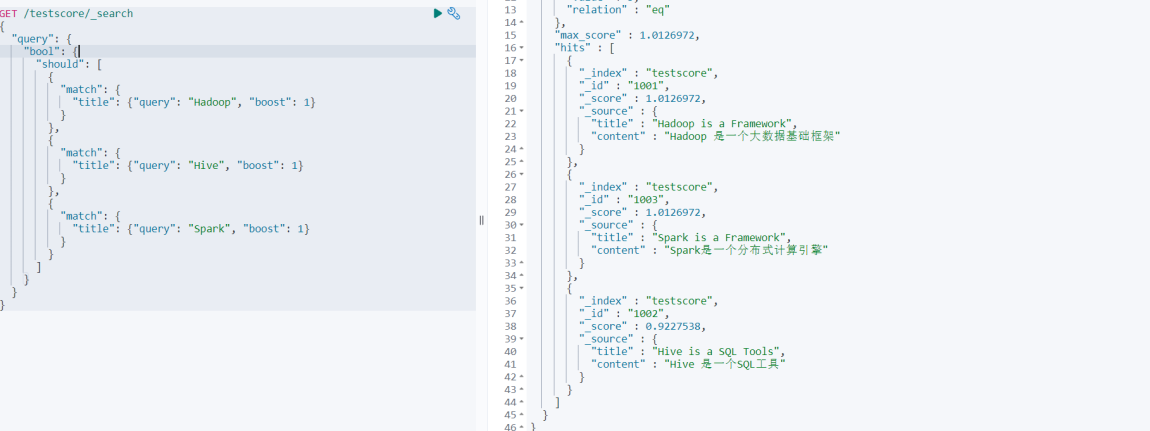
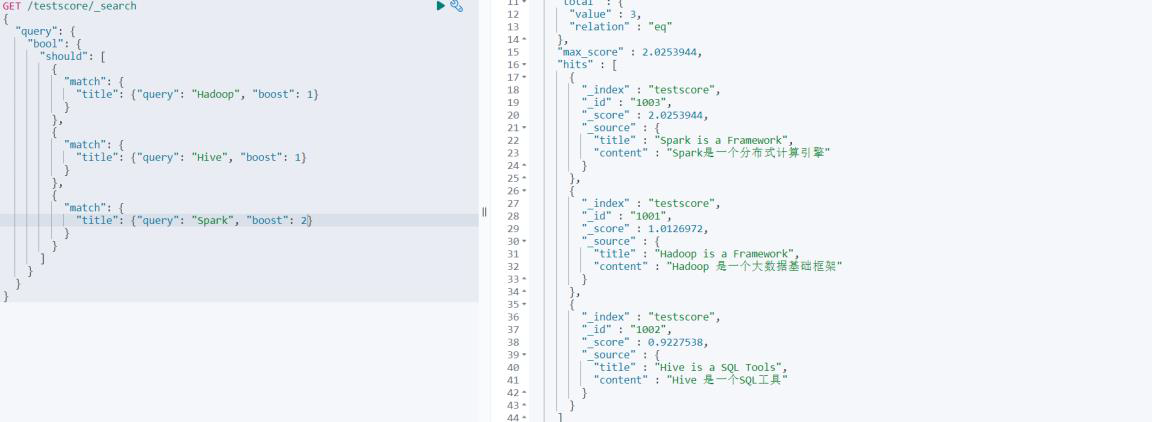
На этом этапе мы можем изменить увеличение параметра веса запроса Spark, чтобы увидеть разницу в результатах запроса.
# Запрос документов В заголовке присутствуют «Hadoop», «Elasticsearch», «Spark».
GET /testscore/_search?explain=true
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {"query": "Hadoop", "boost": 1}
}
},
{
"match": {
"title": {"query": "Hive", "boost": 1}
}
},
{
"match": {
"title": {"query": "Spark", "boost": 2}
}
}
]
}
}
}
5. Резюме
[ElasticSearch] Ошибка запуска Kibana: кажется, что другой экземпляр Kibana переносит индекс....
Another Kibana instance appears to be migrating the index. Waiting for that migration to complete. If no other Kibana instance is attempting migrations, you can get past this message by deleting index .kibana_1 and restarting Kibana.
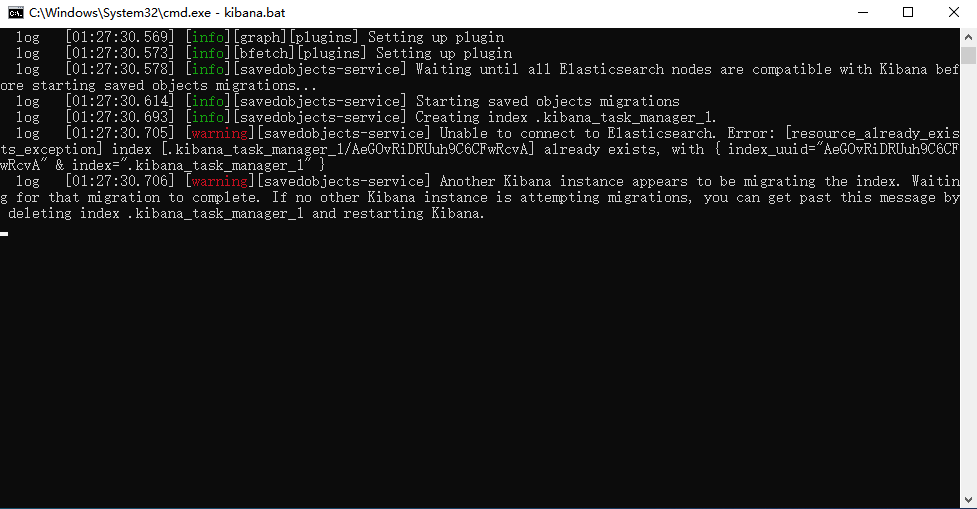
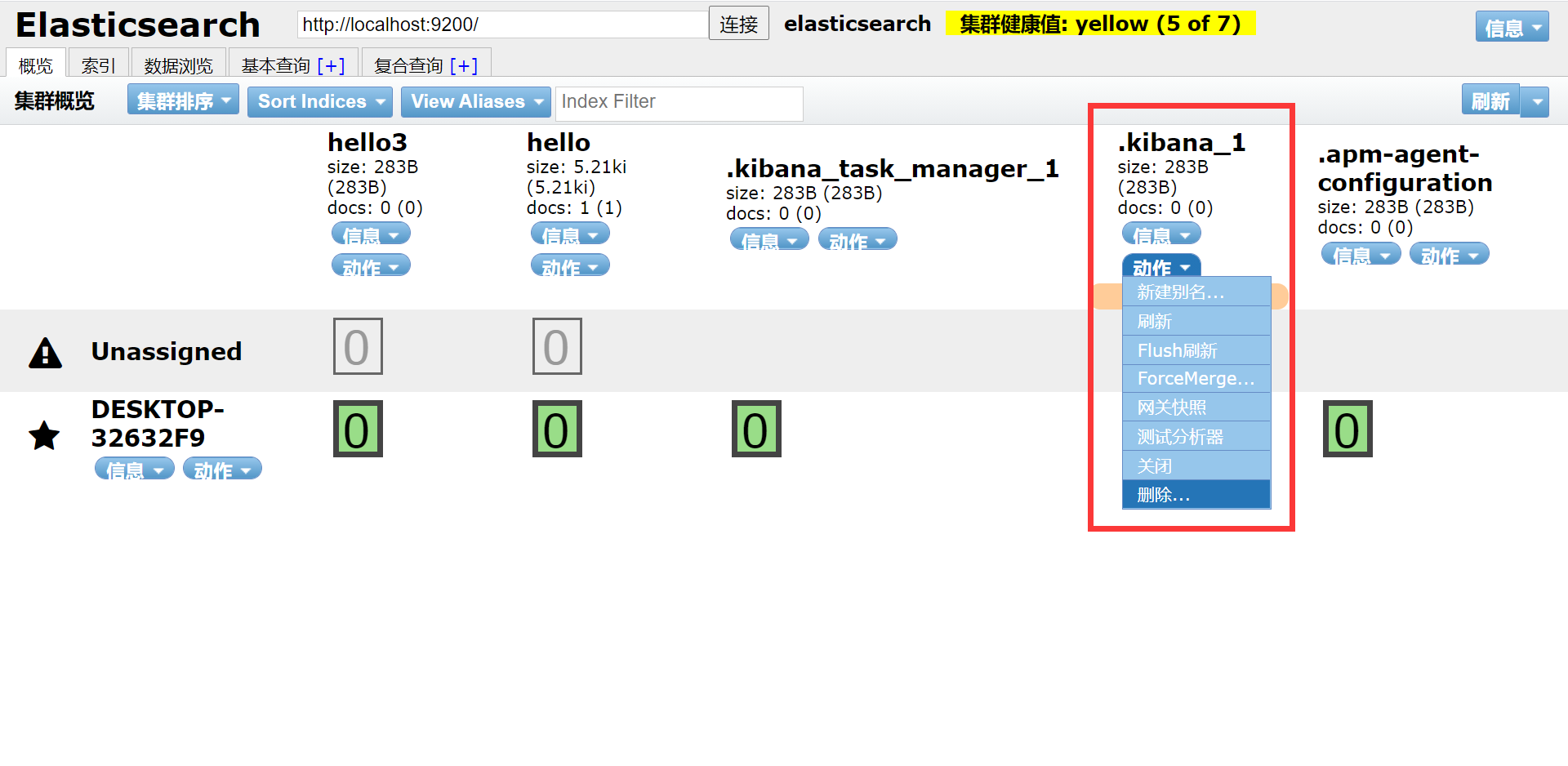
Решение: удалите неправильный индекс.
Используйте плагин головного клиента, чтобы удалить узлы kibana_1 и .kibana_task_manager_1 и перезапустить их.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
