[Третья годовщина ES] Победа над ElasticSearch (учебник начального уровня для няни-1)
В статье будут представлены: роль ElasticSearch, среда для построения elasticsearch (Windows/Linux), построение кластера ElasticSearch, установка и использование плагина визуального клиента elasticsearch-head, установка и использование ИК. сегментатор слов; операции ElasticSearch, представленные в этой главе, основаны на форме Restful (с использованием формы HTTP-запроса).
1. Введение в ElasticSearch
Elaticsearch, называемый es, es, представляет собой широкомасштабируемую распределенную полнотекстовую поисковую систему с открытым исходным кодом, которая может хранить и извлекать данные практически в реальном времени; Он обладает хорошей масштабируемостью и может быть расширен до сотен серверов для обработки данных уровня PB. es также разработан на Java и использует Lucene в качестве ядра для реализации. Присутствуют все возможности индексирования и поиска, но его цель — скрыть сложность Lucene с помощью простого RESTful API, тем самым упрощая полнотекстовый поиск. Простой.
1.1 Варианты использования ElasticSearch
- В начале 2013 года GitHub отказался от Solr и принял ElasticSearch для поиска на уровне петабайтов. «GitHub использует ElasticSearch для поиска по 20 ТБ данных, включая 1,3 миллиарда файлов и 130 миллиардов строк кода».
- Википедия:запускатькelasticsearchядро на основепоиск Архитектура
- SoundCloud: «SoundCloud использует ElasticSearch для предоставления услуг мгновенного и точного поиска музыки для 180 миллионов пользователей»
- Baidu: Baidu в настоящее время широко использует ElasticSearch для анализа текстовых данных, сбора различных индикаторных данных и пользовательских данных на всех серверах Baidu. Благодаря многомерному анализу и отображению различных данных он помогает обнаруживать и анализировать аномалии экземпляров или аномалии бизнес-уровня. . В настоящее время охватывая более 20 направлений бизнеса внутри Baidu (включая Casio, облачный анализ, сетевые альянсы, прогнозы, библиотеки, прямые счета, кошельки, контроль рисков и т. д.), один кластер может иметь максимум 100 машин и 200 ES-узлов. и импортирует данные объемом более 30 ТБ каждый день
- Sina использует ES для анализа и обработки 3,2 миллиарда журналов в реальном времени
- Alibaba использует ES для создания собственной системы сбора и анализа журналов.
- Tencent Cloud Elasticsearch Service (ES) — это полностью управляемый облачный сервис ELK, основанный на движке с открытым исходным кодом. Он объединяет функции X-Pack, уникальное высокопроизводительное ядро собственной разработки, сегментацию слов QQ, проверку кластера и управление одним щелчком мыши. обновление и другие выгодные возможности, представляя максимальную экономическую эффективность самостоятельно разработанного Tencent сервера Xinghai. Помогает вам легко управлять кластерами и эксплуатировать их, а также эффективно создавать анализ журналов, мониторинг эксплуатации и обслуживания, поиск информации, анализ данных и другие сервисы.
1.2 Сравнение ElasticSearch и solr
- Solr использует Zookeeper для распределенного управления, а сам Elasticsearch имеет распределенные функции координации и управления;
- Solr поддерживает больше форматов данных, а Elasticsearch поддерживает только формат файлов json;
- Solr официально предоставляет больше функций, в то время как сам Elasticsearch больше фокусируется на основных функциях, а многие расширенные функции предоставляются сторонними плагинами;
- Solr Работайте лучше, чем традиционные поисковые приложения Elasticsearch,Но вЗначительно менее эффективен, чем Elasticsearch, при обработке поисковых приложений в реальном времени.
2. Установка ElasticSearch (Windows)
Загрузите сжатый пакет:
Официальный адрес ElasticSearch: https://www.elastic.co/products/elasticsearch
2.1 Установка
Уведомление:es разработан на Java и использует Lucene в качестве ядра. Вам необходимо настроить среду Java! (jdk1.8 или выше)
Подобно tomcat, просто распакуйте его напрямую. Структура его каталогов следующая:
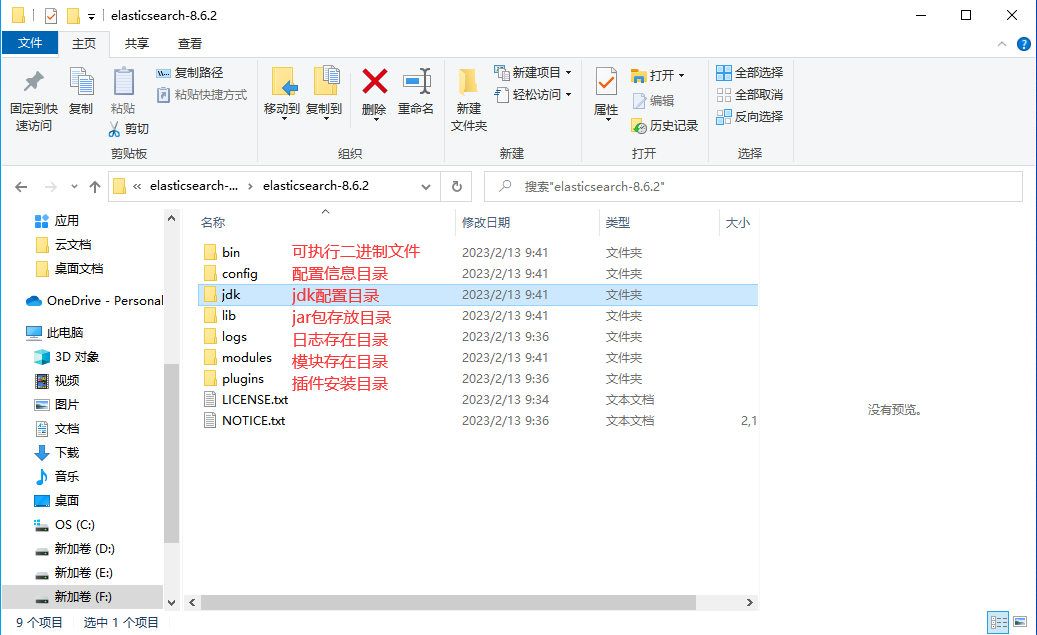
2.2 Изменение файла конфигурации
- Измените файл conf\jvm.options.
Будет #-Xms4g
#-Xmx4g изменен на:
-Xms340m
-Xmx340m
В противном случае его нельзя будет использовать, поскольку на виртуальной машине недостаточно памяти.- Измените файл conf\elasticsearch.yml.
Добавьте в конец elasticsearch-5.6.8\config\elasticsearch.yml:
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1
Цель состоит в том, чтобы позволить ES поддерживать междоменные запросы.2.3 Запуск
Нажмите elasticsearch.bat в каталоге bin под ElasticSearch, чтобы начать. Информация журнала, отображаемая на консоли, выглядит следующим образом:
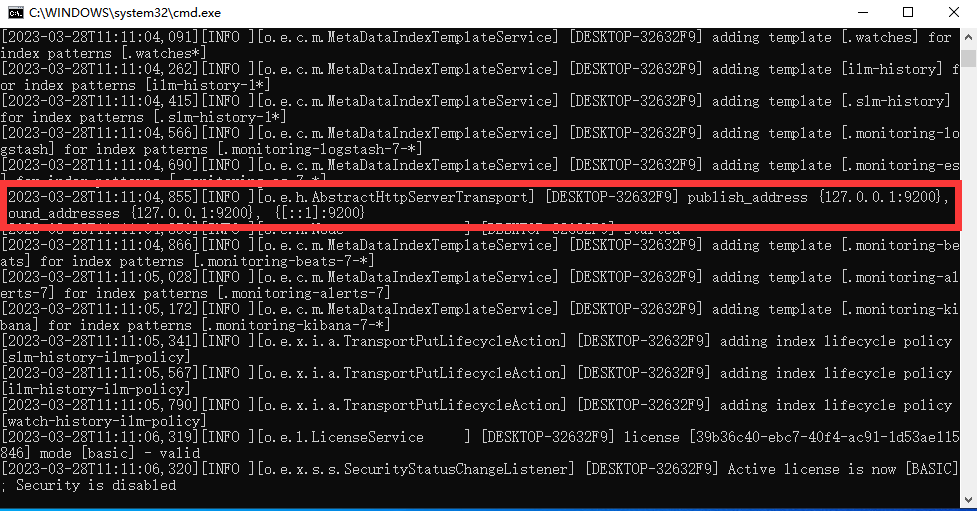
Примечание. 9300 — это порт связи TCP, кластеры es используют TCP для связи, а 9200 — это порт протокола HTTP.
Мы можем получить доступ в браузере:
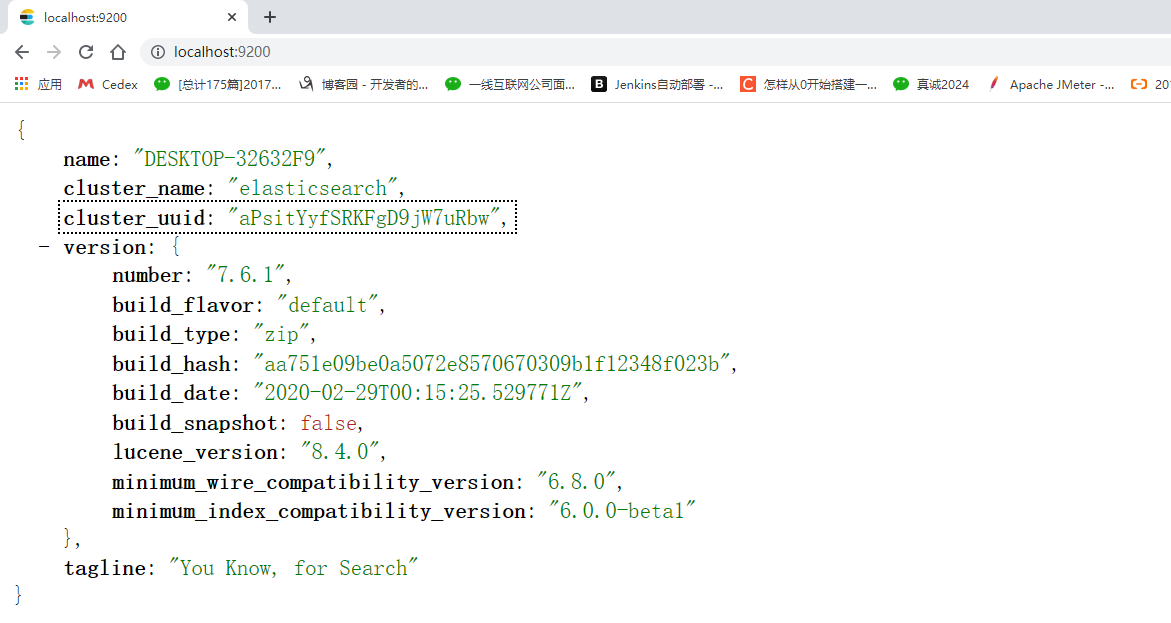
2.4 Установка графических плагинов
Как видно из вышеизложенного, ElasticSearch отличается от собственного графического интерфейса Solr. Мы можем установить головной плагин ElasticSearch, чтобы добиться эффекта графического интерфейса и просматривать индексные данные. Существует два способа установки плагинов: онлайн-установка и локальная установка. В этом документе для установки головного плагина используется метод локальной установки. В версиях elasticsearch-5-* и выше необходимо установить node и выполнить команду для установки head.
- скачатьheadплагин:https://github.com/mobz/elasticsearch-head
Загрузите сжатый пакет и разархивируйте его.
- скачатьnode.js:https://nodejs.org/en/download/
Дважды щелкните, чтобы установить, и введите node -v через cmd, чтобы просмотреть номер версии.

- ВоляgruntУстановитьдля глобальных команд , Grunt — это инструмент для создания проектов, основанный на Node.js.
Введите в cmd:
npm install -g grunt -cli
-g представляет глобальную (globle) переменную, позволяющую клиенту grunt-cli использовать глобальную установку.
Результат выполнения следующий:
Поскольку вы обращаетесь к чужому серверу, если скорость загрузки низкая, вы можете переключиться на зеркало Taobao.
npm install -g cnpm –registry=https://registry.npm.taobao.org Для последующего использования вам нужно всего лишь изменить npm xxx Заменить на cnpm xxx Вот и все
Проверьте, прошла ли установка успешно
npm config get registry
Уведомление:Требуется для последующего использования ВоляnpmЗаменить наcnpm。
- запускатьhead
Войдите в каталог головного плагина, откройте cmd и введите:
>npm install
>grunt server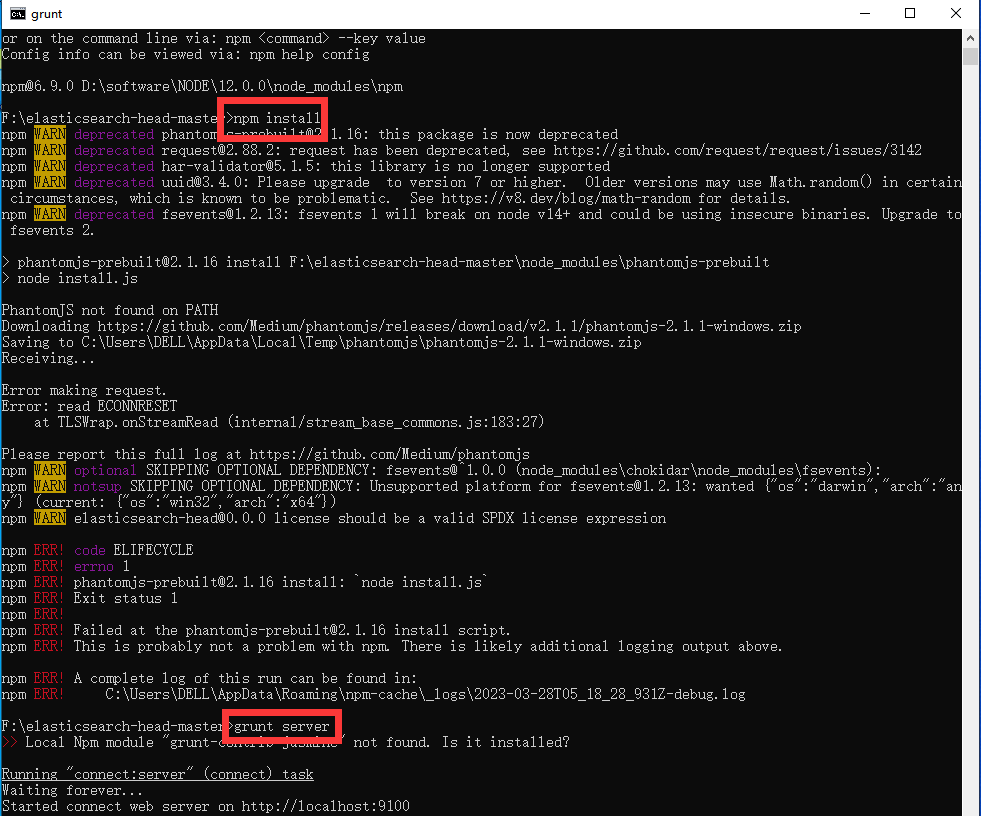
Откройте браузер и введите http://localhost:9100Вот и все
3.Концепции, связанные с ES
3.1 Обзор (важно)
Elasticsearch ориентирован на документы, что означает, что он может хранить целые объекты или документы. Однако это не только Он не только сохраняет, но и индексирует содержимое каждого документа, чтобы сделать его доступным для поиска. В Elasticsearch вы можете индексировать, искать, сортировать и фильтровать документы вместо строк и столбцов данных. Elasticsearch сравнивается с традиционными реляционными базами данных следующим образом:
Relational DB ‐> Databases ‐> Tables ‐> Rows ‐> Columns Elasticsearch ‐> Indices ‐> Types ‐> Documents ‐> Fields
3.2 Основные концепции
1) индекс индекс-
Индекс — это набор документов, имеющих схожие характеристики. Например,Вы можете иметь индекс данных о клиентах,Индекс в другой каталог продукции,Также имеется индекс для данных заказа. Индекс идентифицируется по имени (все буквы должны быть строчными).,И когда мы хотим проиндексировать, искать, обновлять и удалять документы, соответствующие этому индексу,Это имя необходимо использовать. в кластере,Можетк Определите столько индексов, сколько захотите。Можно сравнить с базой данных в MySQL.
2) тип типа
В индексе вы можете определить один или несколько типов. Тип — это логическая классификация/разделение вашего индекса, семантика которого полностью зависит от вас. Обычно тип определяется для документов, имеющих общий набор полей. Например, предположим, что вы управляете платформой для ведения блогов и храните все свои данные в индексе. В этом индексе вы можете определить один тип для пользовательских данных, другой тип для данных блога и, конечно же, другой тип для данных комментариев. Сравнимо с таблицами в MySQL.
3) Поля поля
Оно эквивалентно полю в таблице данных, которое классифицирует данные документа по различным атрибутам.
4) Картирование
Картирование заключается в наложении некоторых ограничений на способ и правила обработки данных.,Например, тип данных поля, значение по умолчанию, анализатор, индексировано ли оно и т. д.,Их можно установить в сопоставлении,Другие — это некоторые настройки правил использования для обработки данных в es, также называемые сопоставлением.,Обработка данных по оптимальным правилам значительно повышает производительность,Поэтому необходимо установить отображение,И нам нужно подумать о том, как наладить картографирование, чтобы добиться более высокой производительности.。Эквивалентно процессу создания таблицы в MySQL, настройке первичных ключей, внешних ключей и т. д.
5) документ документ
Документ — это базовая единица информации, которую можно индексировать. Например, у вас может быть документ для определенного клиента, документ для определенного продукта и, конечно же, вы также можете иметь документ для определенного заказа. Документация в формате JSON (Javascript Object Notation), а JSON — это универсальный формат взаимодействия с данными в Интернете. В индексе/типе вы можете хранить столько документов, сколько захотите. Обратите внимание: хотя документ физически существует в индексе, документ должен быть проиндексирован/присвоен тип индекса. Вставка в индексную базу данных осуществляется на основе документов, что аналогично строке данных в базе данных.
6) кластер-кластер
Кластер организован одним или несколькими узлами, которые совместно хранят все данные и обеспечивают функции индексации и поиска. Кластер идентифицируется уникальным именем, которое по умолчанию — «elasticsearch». Это имя важно, поскольку узел может присоединиться к кластеру, только указав его имя.
7) узел-узел
Узел — это сервер в кластере. Как часть кластера, он хранит данные и участвует в функциях индексирования и поиска кластера. Как и в случае с кластером, узел также идентифицируется по имени. По умолчанию это имя является именем случайного персонажа комиксов Marvel. Это имя будет присвоено узлу при его запуске. Это имя очень важно для работы по управлению, поскольку в ходе этого процесса управления вы будете определять, какие серверы в сети каким узлам в кластере Elasticsearch соответствуют. Узел может присоединиться к указанному кластеру, настроив имя кластера. По умолчанию каждый узел должен присоединиться к кластеру под названием «elasticsearch». Это означает, что если вы запустите несколько узлов в своей сети и предполагаете, что они могут обнаруживать друг друга, они автоматически сформируются и присоединятся к кластеру под названием «elasticsearch». В кластере вы можете иметь столько узлов, сколько захотите. Более того, если в вашей сети в настоящее время нет узлов Elasticsearch и вы запускаете узел, по умолчанию будет создан и добавлен кластер под названием «elasticsearch».
8) Шардинг и репликация shards&replicas
Индекс может хранить большие объемы данных, выходящие за пределы аппаратных ограничений одного узла. Например, индекс с 1 миллиардом документов занимает 1 ТБ дискового пространства, и ни один узел не имеет такого большого дискового пространства, или один узел обрабатывает поисковые запросы, и ответ слишком медленный; Чтобы решить эту проблему, Elasticsearch предоставляет возможность разделить индекс на несколько частей, которые называются шардами. При создании индекса вы можете указать желаемое количество сегментов. Каждый шард сам по себе также является полнофункциональным и независимым «индексом», который можно разместить на любом узле кластера. Шардинг важен по двум основным причинам: 1) Позволяет разделить/расширить емкость контента по горизонтали. 2) Позволяет выполнять распределенные параллельные операции на шардах (потенциально на нескольких узлах), тем самым повышая производительность/пропускную способность. Распределение сегмента и то, как его документы объединяются обратно в поисковые запросы, полностью управляются Elasticsearch и прозрачны для вас как пользователя. В сетевой/облачной среде сбои могут произойти в любой момент, когда определенный шард/узел каким-либо образом отключается или исчезает по какой-либо причине. В этом случае очень полезно иметь механизм аварийного переключения. Для этой цели Elasticsearch позволяет создавать одну или несколько копий шарда. Эти копии называются реплицированными шардами или просто репликами. Репликация важна по двум основным причинам: Обеспечивает высокую доступность в случае сбоя сегмента/узла. По этой причине важно отметить, что сегменты-реплики никогда не размещаются на том же узле, что и исходный/основной сегмент. Масштабируйте объем/пропускную способность поиска, поскольку поиск может выполняться параллельно во всех репликах. Таким образом, каждый индекс можно разделить на несколько сегментов. Индекс также может быть реплицирован 0 раз (то есть без репликации) или несколько раз. После репликации каждый индекс имеет основной сегмент (исходный сегмент, используемый в качестве источника репликации) и сегмент-реплику (копию основного сегмента). Количество шардов и репликации можно указать во время создания индекса. Вы можете динамически изменять количество репликаций в любой момент после создания индекса, но не сможете впоследствии изменить количество шардов. По умолчанию каждый индекс в Elasticsearch сегментирован с помощью 5 основных сегментов и 1 реплики. Это означает, что если у вас есть хотя бы два узла в вашем кластере, ваш индекс будет иметь 5 основных сегментов и 1 реплику. Еще 5 реплицированных сегментов (1 полная копия). ), что в общей сложности дает 10 шардов на индекс.
4. Работа клиента ElasticSearch
Вышеуказанная часть является теоретической частью. В реальной разработке существует три основных способа выступать в качестве клиента эс-сервиса:
- Использование плагина elasticsearch-head
- Прямой доступ с использованием интерфейса Restful, предоставляемого elasticsearch.
- Доступ с использованием API, предоставляемого elasticsearch.
4.1 Прямой доступ через интерфейс Restful
Нам нужно использовать http-запросы и ввести два инструмента тестирования интерфейса: почтальон и тестер Talend API.
- Talend API testerУстановить:
Это плагин для Chrome, загрузка не требуется;
- PostmanУстановить:
PostmanОфициальный сайт:https://www.getpostman.com
4.2 Используйте тестер Talend API для выполнения клиентских операций.
1) Синтаксис интерфейса Elasticsearch
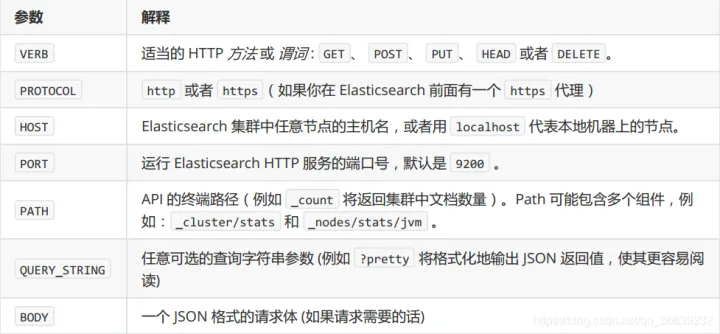
curl ‐X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' ‐d '<BODY>'в:
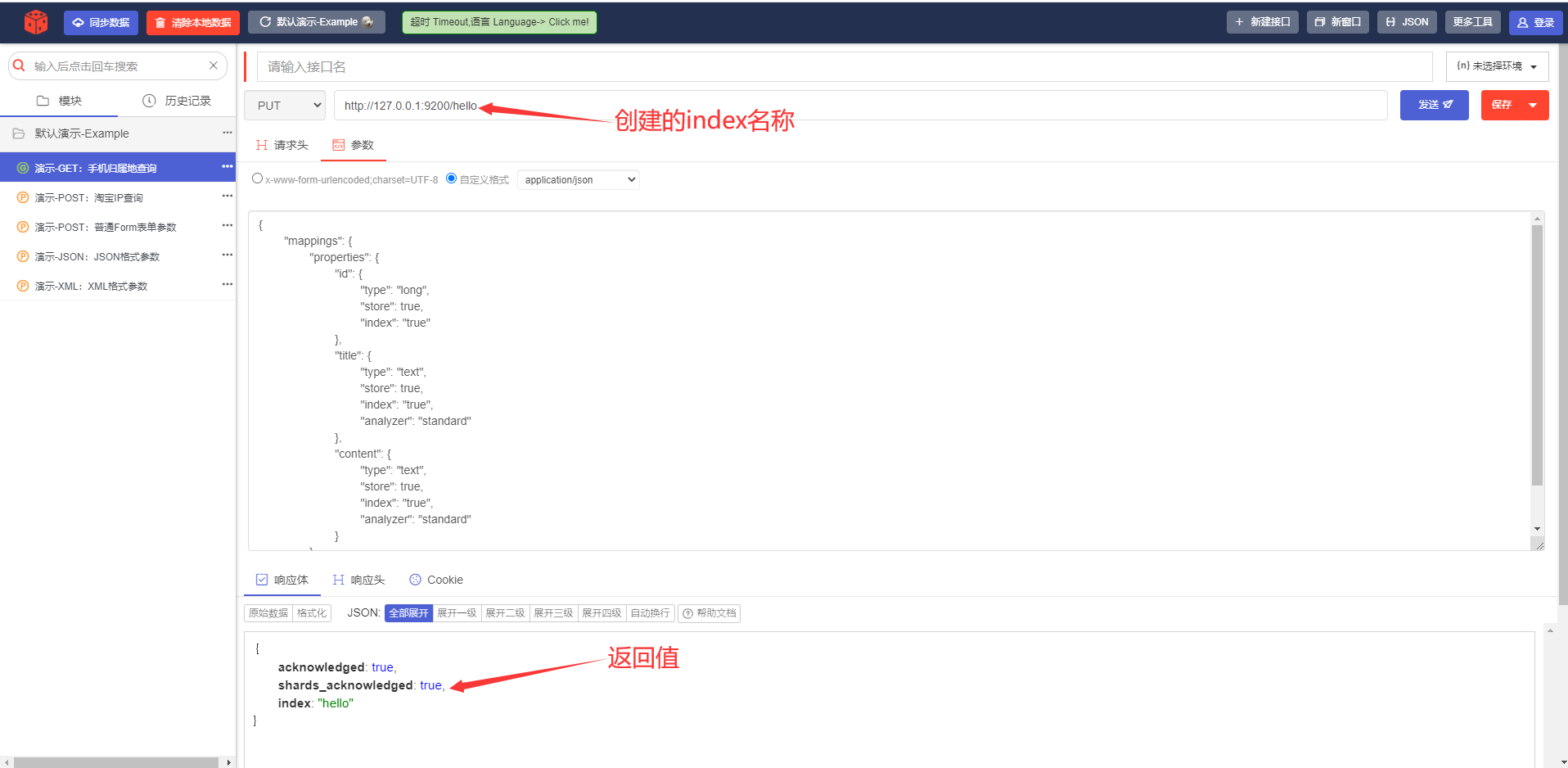
2) Создайте индекс библиотеки индексов и добавьте сопоставление ------ PUT
PUTТело запроса:
статья: тип типа; эквивалент определения полей в этой таблице, определенных ниже в этой библиотеке индексов. Поля не индексируются по умолчанию; анализатор: токенизатор использует стандартный токенизатор
{
"mappings": {
"properties": {
"id": {
"type": "long",
"store": true,
"index": "true"
},
"title": {
"type": "text",
"store": true,
"index": "true",
"analyzer": "standard"
},
"content": {
"type": "text",
"store": true,
"index": "true",
"analyzer": "standard"
}
}
}
}
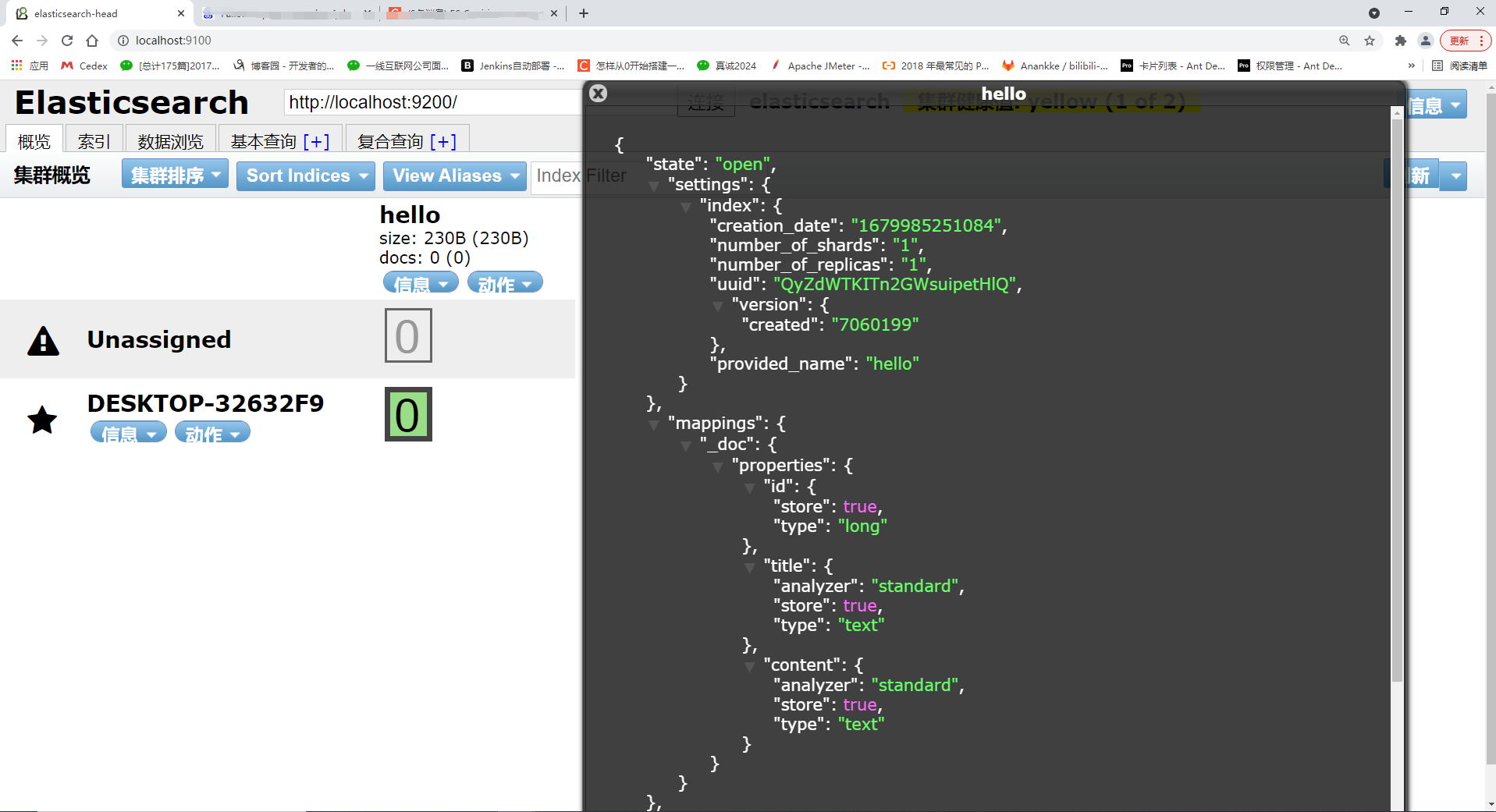
Посмотреть в инструменте визуализации elasticsearch-head:
3) Сначала создайте индекс, затем добавьте сопоставление ---- PUT
Мы можем установить информацию о сопоставлении при создании индекса или, конечно, мы можем сначала создать индекс, а затем установить сопоставление. На предыдущем шаге не задавайте информацию о сопоставлении, напрямую используйте метод put для создания индекса, а затем установите информацию о сопоставлении.

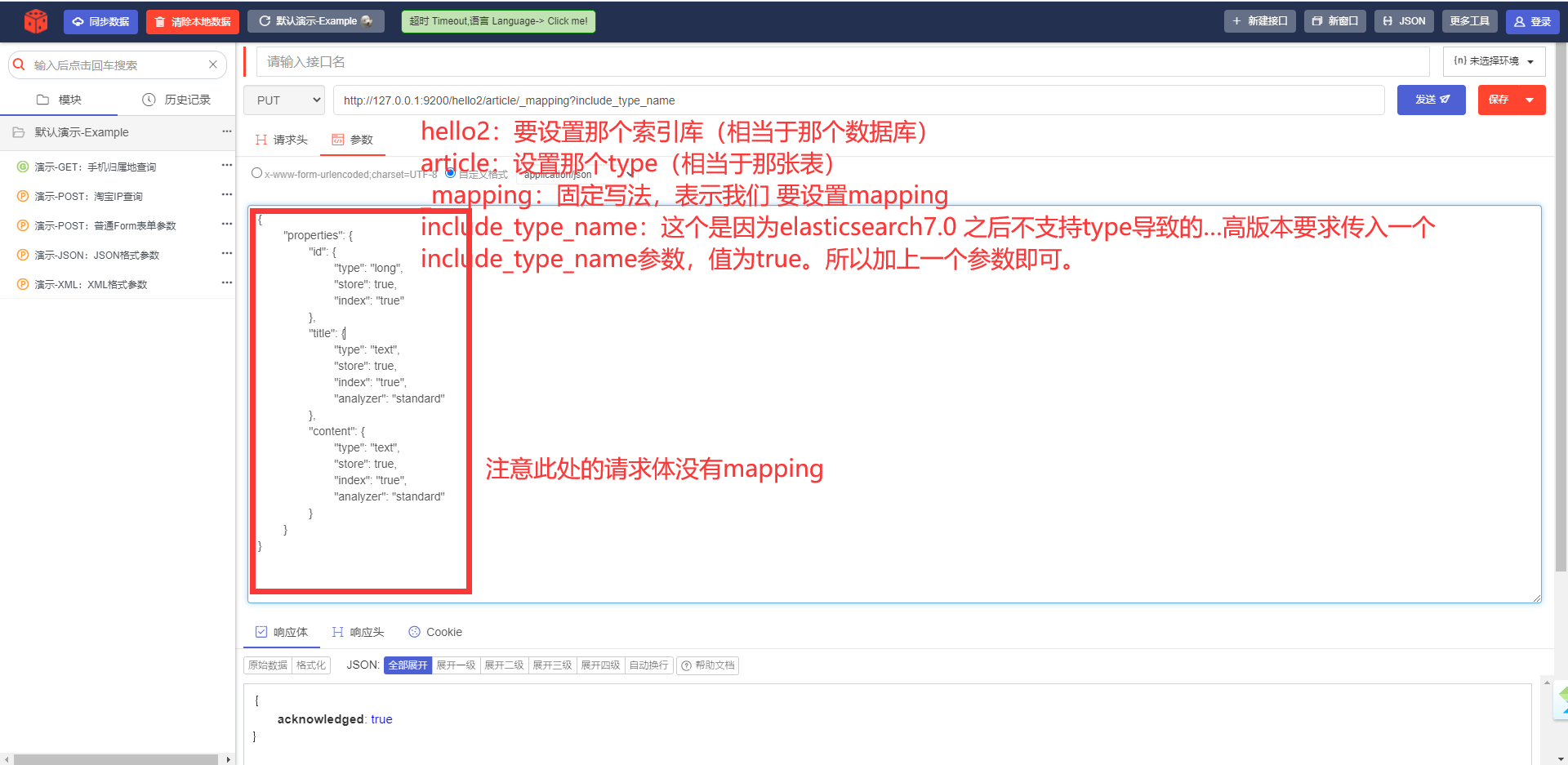
PUT http://127.0.0.1:9200/hello2/article/_mapping?include_type_nameТело запроса:
{
"properties": {
"id": {
"type": "long",
"store": true,
"index": "true"
},
"title": {
"type": "text",
"store": true,
"index": "true",
"analyzer": "standard"
},
"content": {
"type": "text",
"store": true,
"index": "true",
"analyzer": "standard"
}
}
}
4) Удалить индексный индекс ---- УДАЛИТЬ
URL-адрес запроса:
DELETE http://127.0.0.1:9200/hello2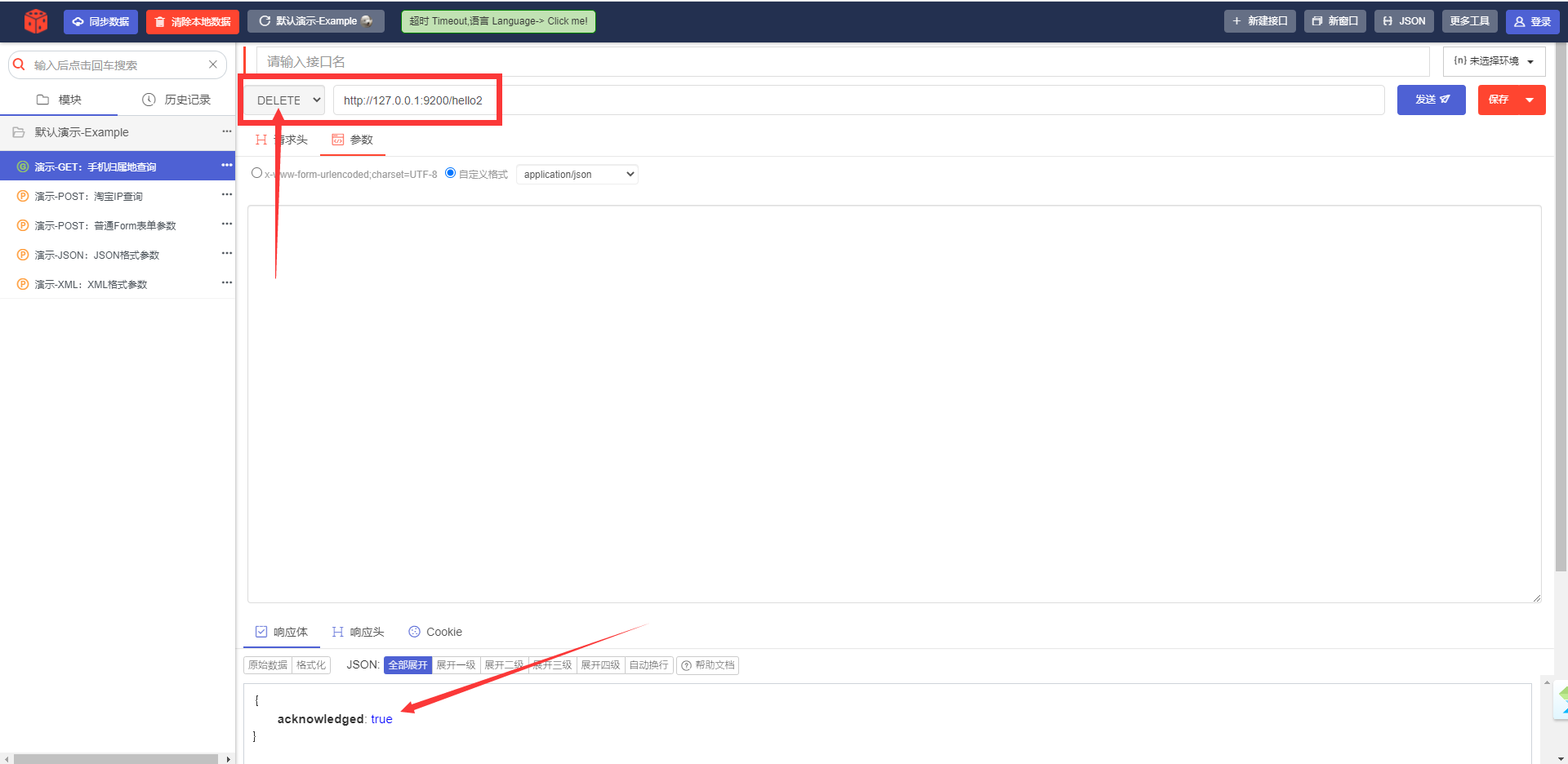
5) Создайте документ-документ (добавьте содержимое в индексную библиотеку) --- POST
URL-адрес запроса:
POST http://127.0.0.1:9200/hello/_doc/1Тело запроса:
{
"id": 1,
"title": «ElasticSearch — это поисковый сервер на основе Lucene»,
"content": «Он предоставляет распределенную многопользовательскую полнотекстовую поисковую систему на основе RESTful. веб-интерфейс. Elasticsearch, разработанный на Java и выпущенный с открытым исходным кодом на условиях лицензии Apache, в настоящее время является популярной поисковой системой корпоративного уровня. Разработанный для использования в облачных вычислениях, он обеспечивает поиск в реальном времени, является стабильным, надежным, быстрым и простым в использовании. "
}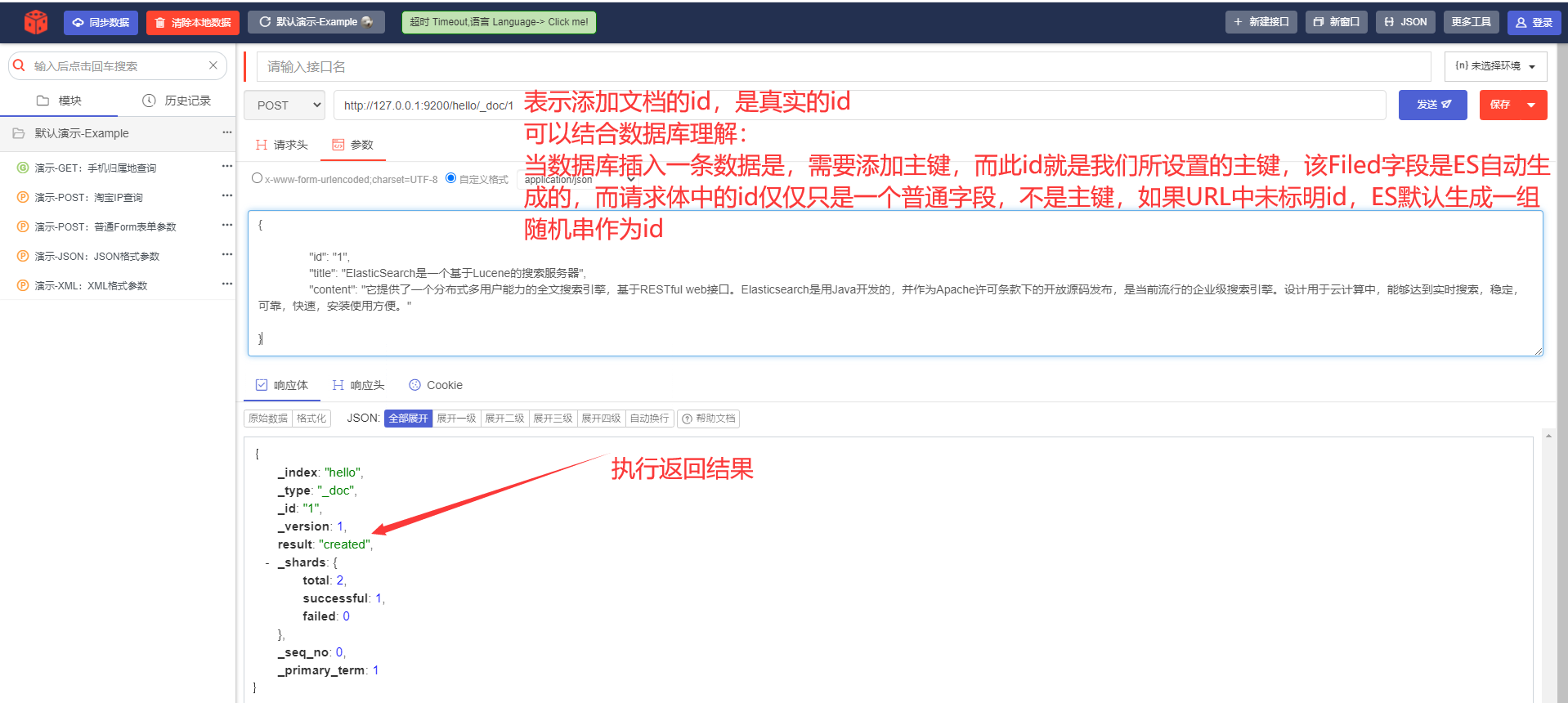
Посмотреть в elasticsearch-head:
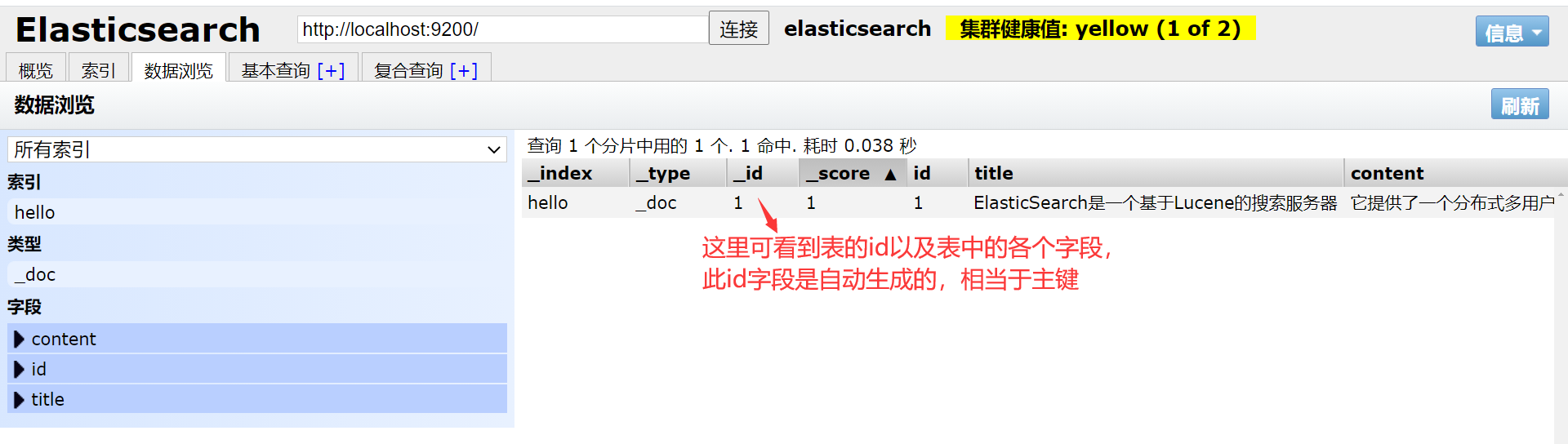
Обратите внимание, что обычно мы присваиваем одно и то же значение _id и id.
6) Изменить содержимое документа ---- POST.
URL-адрес запроса:
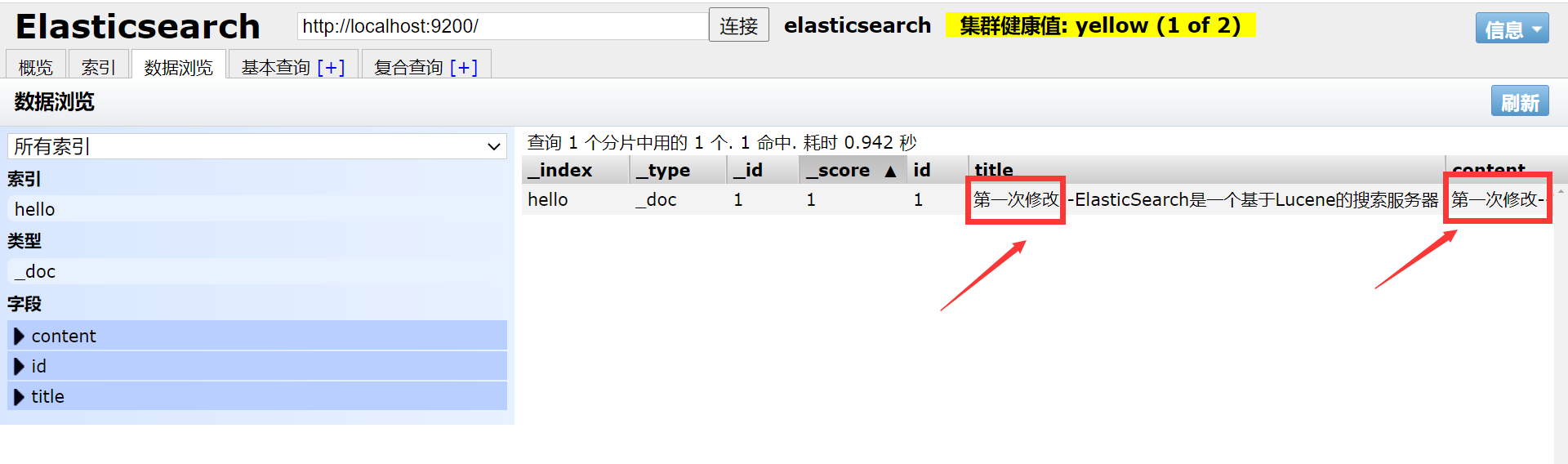
POST http://127.0.0.1:9200/hello/_doc/1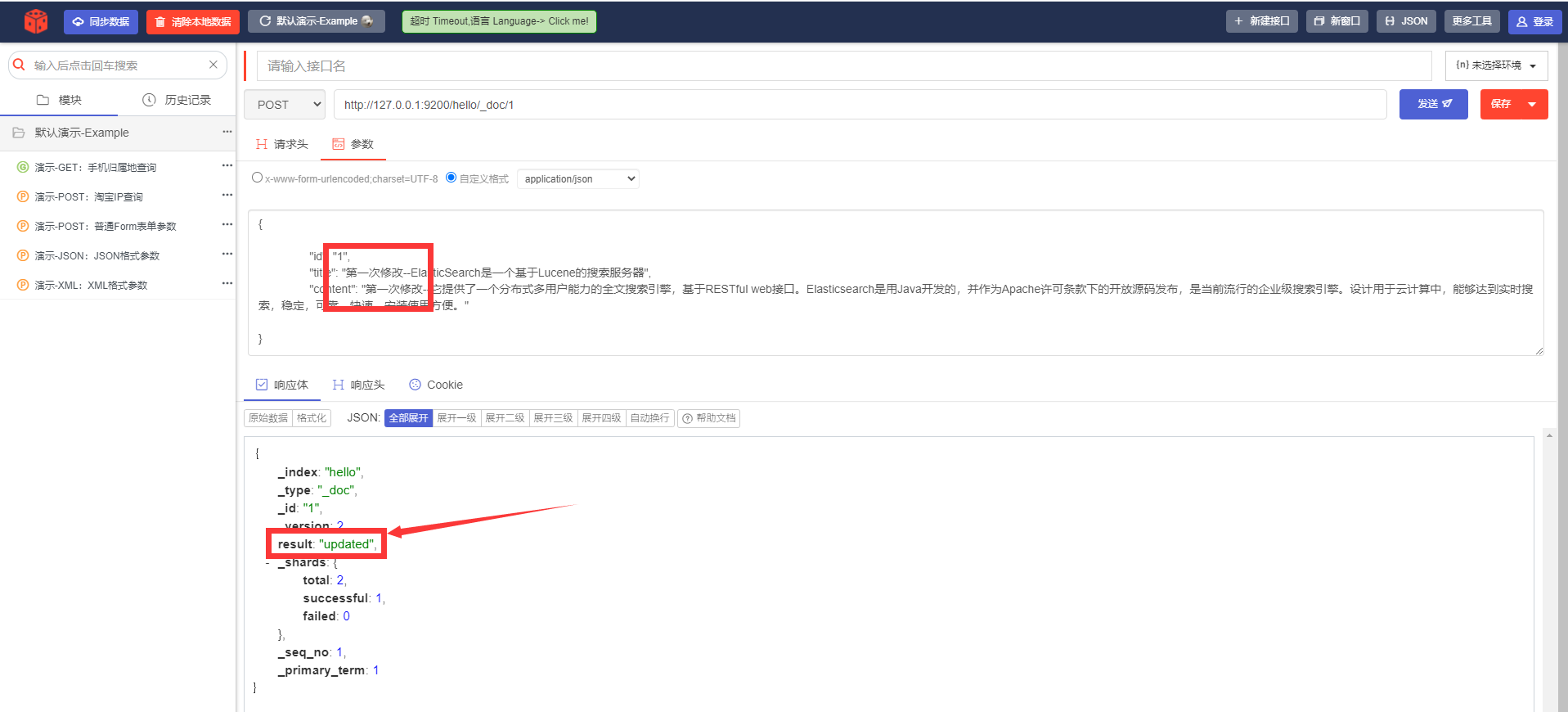
Посмотреть в elasticsearch-head:
7) Удалить документ---УДАЛИТЬ.
URL-адрес запроса:
DELETE http://127.0.0.1:9200/hello/_doc/1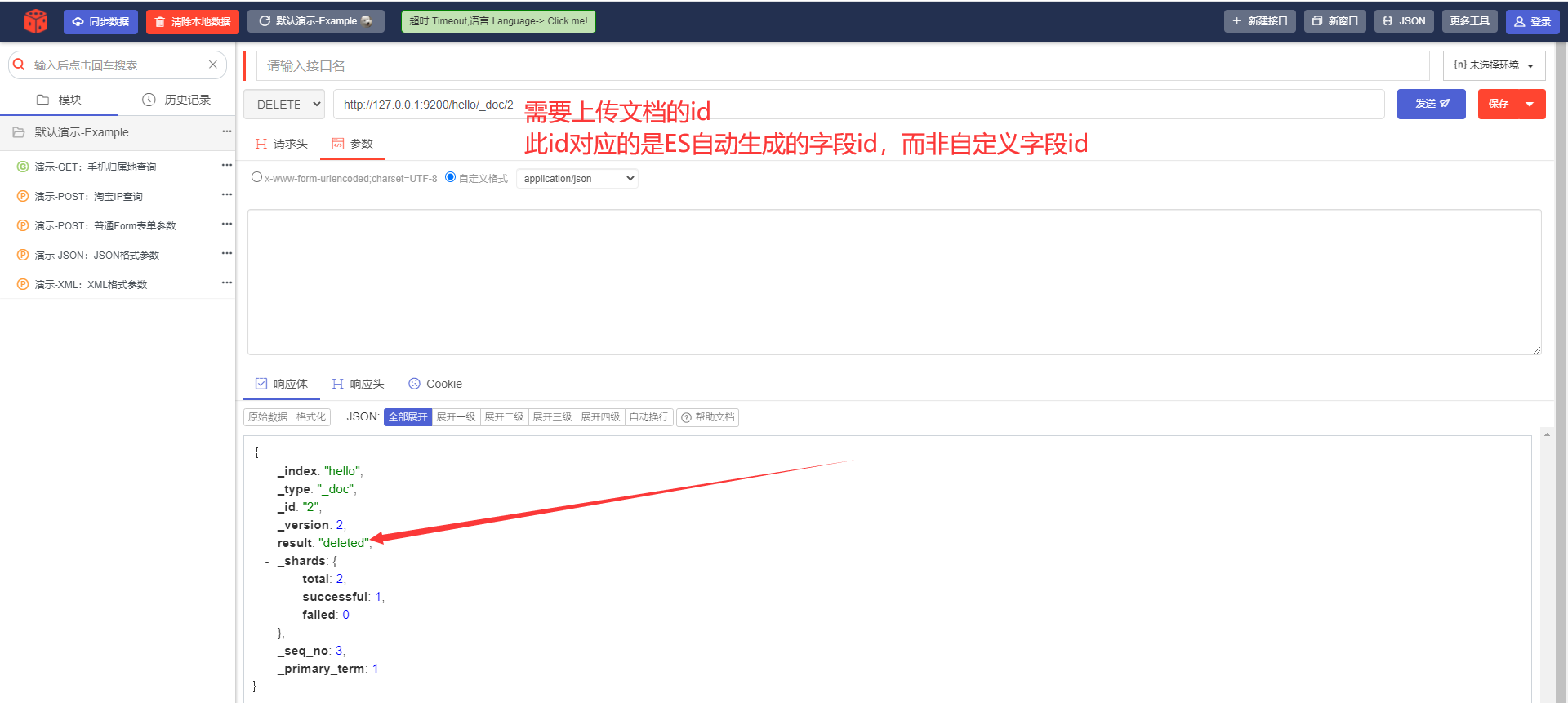
8) Запрос документа----- ПОЛУЧИТЬ
Существует три способа запроса документов:
- Запрос по идентификатору;
- Поиск по ключевым словам
- Сначала сегментируйте слова в соответствии с входным содержимым, а затем выполните запрос.
i. Запрос на основе идентификатора.
URL-адрес запроса:
GET http://127.0.0.1:9200/hello/_doc/1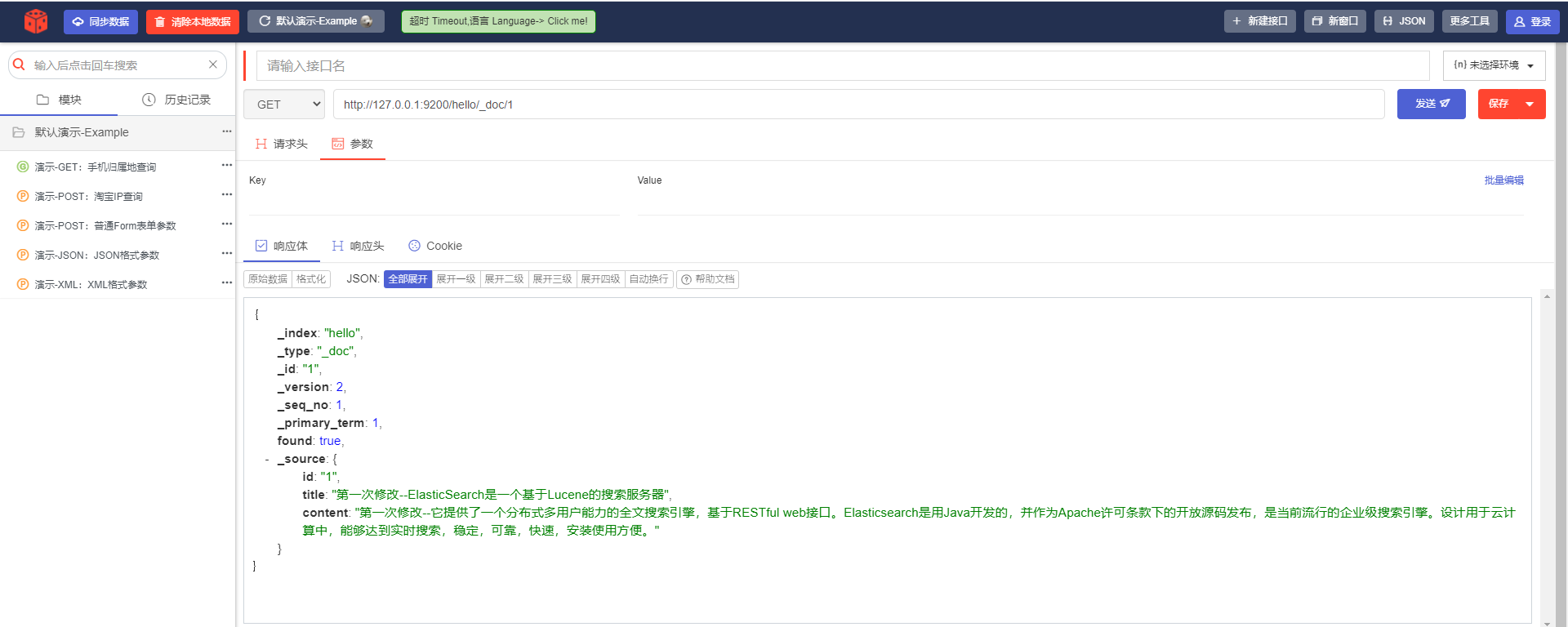
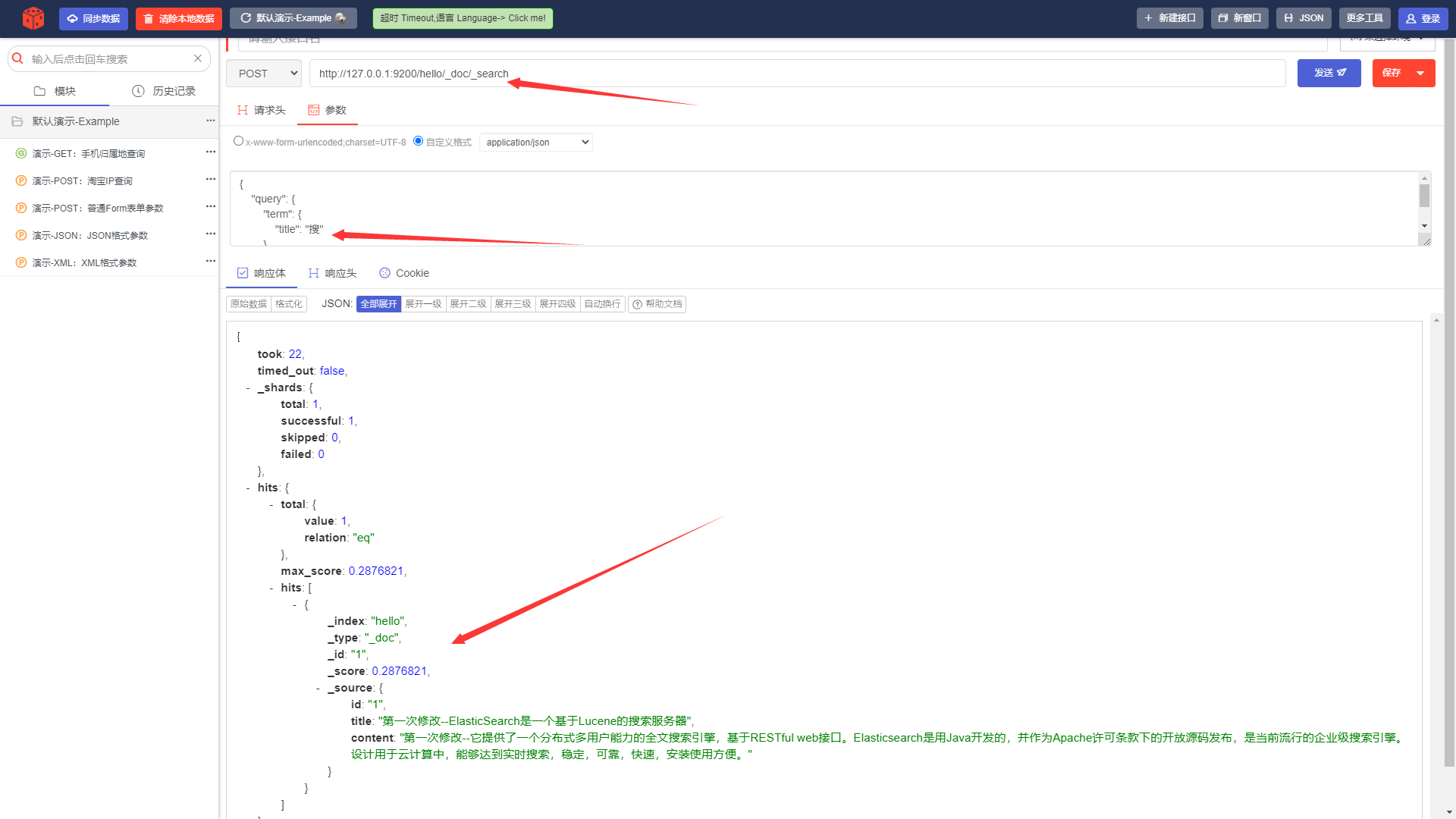
ii. Запрос на основе запроса ключевых слов.
URL-адрес запроса:
POST http://127.0.0.1:9200/hello/_doc/_searchТело запроса:
{
"query": {
"term": {
"title": "поиск"
}
}
}
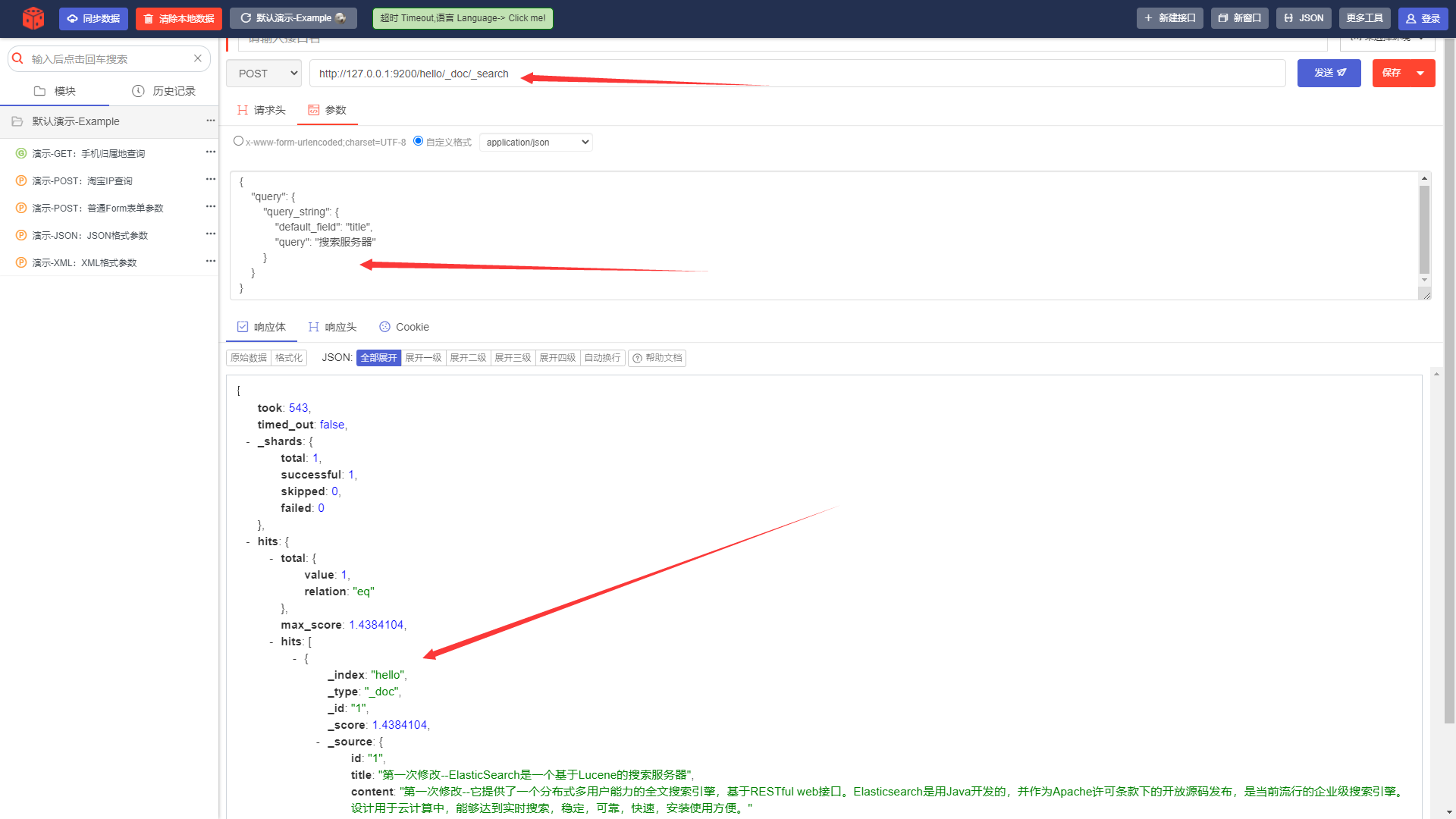
iii. Запрос запроса документа-строки.
URL-адрес запроса:
POST http://127.0.0.1:9200/hello/_doc/_searchТело запроса:
{
"query": {
"query_string": {
"default_field": "title",
"query": «Поисковой сервер»
}
}
}Указать: По какому полю запрашивать; Каков контент, который будет запрошен; Сначала он сегментирует содержимое запроса, а затем запросит
4.3 Использование elasticsearch-head для операций ES-клиента
Инструмент http-запросов интегрирован в elasticsearch-head для предоставления обзорных запросов:
5. Интегрированное использование сегментатора слов IK и Elasticsearch.
Приведенный выше сегментатор слов использует стандартный сегментатор слов, который не очень удобен для сегментации китайских слов. Например, сегментация слова «Я программист» выглядит так:
GET http://127.0.0.1:9200/_analyze?analyzer=standard&pretty=true&text=Я программист
"tokens":[
{"token": "Я", "start_offset": 0, "end_offset": 1, "type": "<IDEOGRAPHIC>",…},
{"token": "да", "start_offset": 1, "end_offset": 2, "type": "<IDEOGRAPHIC>",…},
{"token": "режим", "start_offset": 2, "end_offset": 3, "type": "<IDEOGRAPHIC>",…},
{"token": "последовательность", "start_offset": 3, "end_offset": 4, "type": "<IDEOGRAPHIC>",…},
{"token": "член", "start_offset": 4, "end_offset": 5, "type": "<IDEOGRAPHIC>",…}
]Мы надеемся получить причастия: Я, программа, программист.
Существует множество сегментаторов слов, поддерживающих китайский язык, например сегментатор слов, Paoding Jieniu и сегментатор Ansj. Обратите внимание на использование сегментатора IK ниже.
5.1 Установка сегментатора слов ИК
1)скачатьадрес:https://github.com/medcl/elasticsearch-analysis-ik/releases
2) Разархивируйте, скопируйте разархивированную папку elasticsearch в elasticsearch-5.6.8\plugins и переименуйте папку в Analysis-ik (также доступны другие имена, цель не дублировать имя)
3) Перезагрузите сегментатор слов IK в запуске ElasticSearch, Вот и все
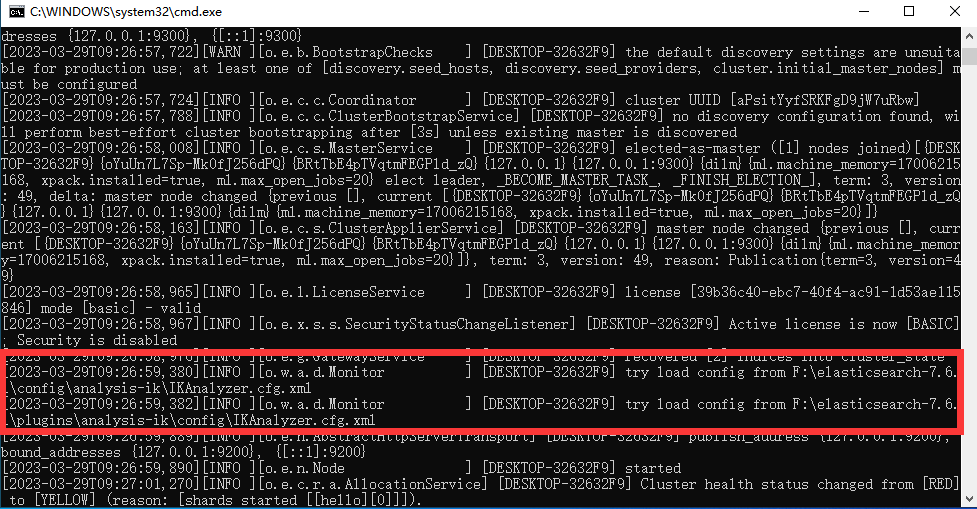
5.2IK тест сегментатора слов
Для чего нужен этот сегментатор слов IK? Зачем его использовать?
Вы должны знать, что компьютеры были разработаны Соединенными Штатами, и многие из их вещей на самом деле очень недружелюбны по отношению к китайцам.
По поводу сегментации слов, то есть разделения китайского или другого абзаца на ключевые слова.
Например, «Я китаец», на сколько слов его можно разделить?
Согласно китайскому иероглифическому языку, он разделен на пять частей: «Я», «Да», «Китайский», «Китай» и «китайский».
Другими словами, пользователи могут искать данные «Я китаец», введя указанные выше пять слов.
Сегментация китайских слов по умолчанию рассматривает каждый символ как слово, которое будет разделено на «I», «Да», "середина", "страна" и "люди".
Это явно не соответствует требованиям, поэтому для решения этой проблемы используется китайский сегментатор слов ik.
①анализ: в переводе это означает анализ, и здесь можно понять составляющие слова.
②Анализатор: относится к сегментатору слов, мы используем ik_max_word.
- ik_max_word — это наиболее детализированное подразделение.
- ik_smart наименее сегментирован.
Это два алгоритма сегментации слов, предоставляемые сегментатором слов ik. Что касается того, как конкретно их реализовать, нам необходимо изучить его алгоритмы.
Вы можете сравнить приведенные выше модификации кода и обнаружите, что с помощью ik_smart можно разделить только на три слова: «Я», «Да», «Китайский».
Очевидно, здесь уместнее использовать ik_max_word.
IK обеспечивает два вида сегментации слов: ik_smart и ik_max_word.
Среди них ik_smart — наименьшее сегментирование, а ik_max_word — самое детальное деление.
Проверьте это ниже:
- Минимальная сегментация: Введите адрес в браузере:
1) Версия es — 5.4.2. Чтобы просмотреть эффект токенизатора, вы можете напрямую указать токенизатор и слова запроса в URL-адресе. Метод — GET, как показано ниже:
Пример 1:
GET http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=ЯсерединакитайскийПример 2:
GET http://127.0.0.1:9200/_analyze?analyzer=standard&text=End users and developers looking for free JDK versions2) es6.4.3 Чтобы проверить эффект сегментации слов, вы можете использовать метод GET или POST, но сегментатор слов и слова запроса необходимо записать в теле в виде json.
Пример 1:
POST http://localhost:9200/_analyze?pretty=trueТело запроса:
{
"analyzer": "ik_smart",
"text": "Я китаец"
}Пример 2:
POST http://localhost:9200/_analyze?pretty=trueТело запроса:
{
"analyzer": "standard",
"text": "End users and developers looking for free JDK versions"
}Результаты возврата:
{
"tokens": [
{
"token": "Я",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "да",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "Китайский",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}- Тончайшая сегментация: Введите адрес в браузере:
1) Версия es — 5.4.2. Чтобы просмотреть эффект токенизатора, вы можете напрямую указать токенизатор и слова запроса в URL-адресе. Метод — GET, как показано ниже:
Пример 1:
GET http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=Ясерединакитайский2) es6.4.3 Чтобы проверить эффект сегментации слов, вы можете использовать метод GET или POST, но сегментатор слов и слова запроса необходимо записать в теле в виде json.
Пример 1:
POST http://localhost:9200/_analyze?pretty=trueТело запроса:
{
"analyzer": "ik_max_word",
"text": "Я китаец"
}Результаты возврата:
{
"tokens": [
{
"token": "Я",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "да",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "Китайский",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "Китай",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "Китайский",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}Сегментатор слов 5.3IK добавляет собственную конфигурацию
Брат Хун сказал: «Я китаец» Заменить на“ЯПекин Хонге", используйте IK обеспечивает два вида сегментации слов: ik_smart и После ik_max_word. я обнаружил, что в возвращаемых результатах нет никакой разницы, и он не считал, что «Брат Хун» — это слово. Что мне делать? Сначала брат Хун подумал, что это более высокая версия. сегментатор слов больше не может различать (IK обеспечивает два вида сегментации слов: ik_smart и ik_max_word.),Но тогда я подумал, что это невозможно,Затем я проверил официальные документы и обнаружил, что между ними есть разница, и она не имеет никакого отношения к версии. Но ИК думает, что это не то слово,Такое слово, которое нуждается в себе,Его нужно добавить в сам словарь ИК.
1) Сначала найдите файл конфигурации IK, расположенный по адресу ik/config/IKAnalyzer.cfg.xml. Здесь вы можете добавить свой собственный расширенный словарь и словарь стоп-слов.
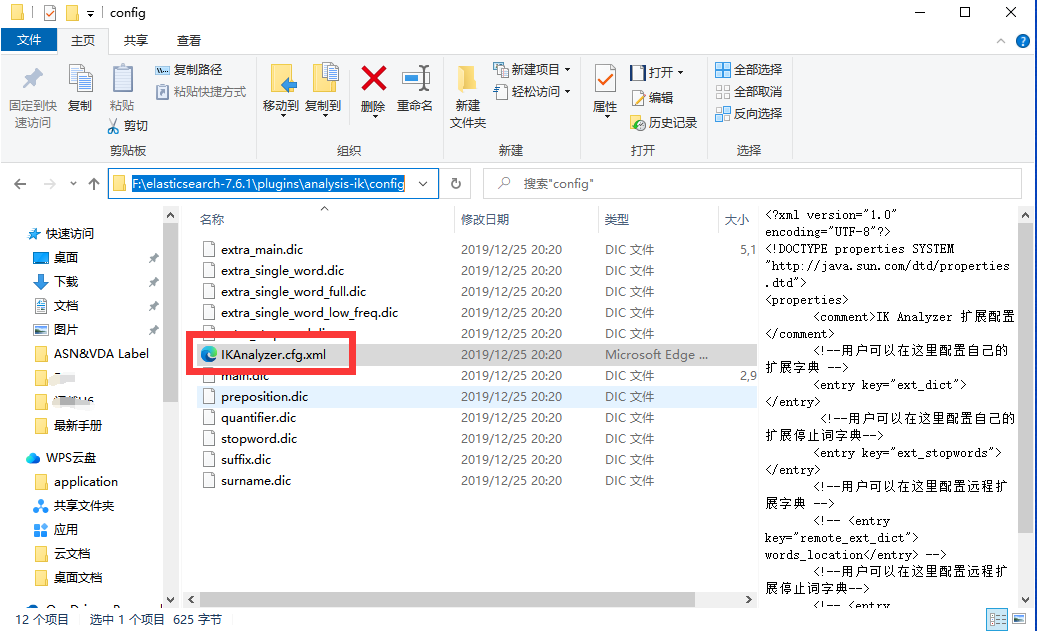
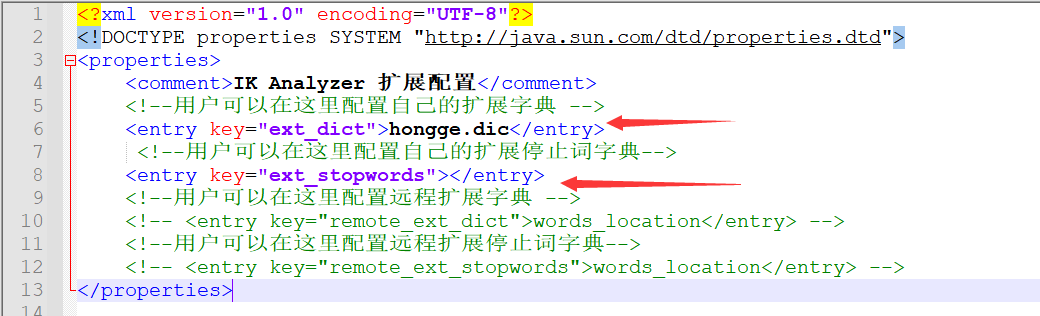
2) Откройте файл и добавьте сюда свой собственный расширенный словарь и словарь стоп-слов.
3) Добавьте свой словарь и создайте файл: hongge.dic.
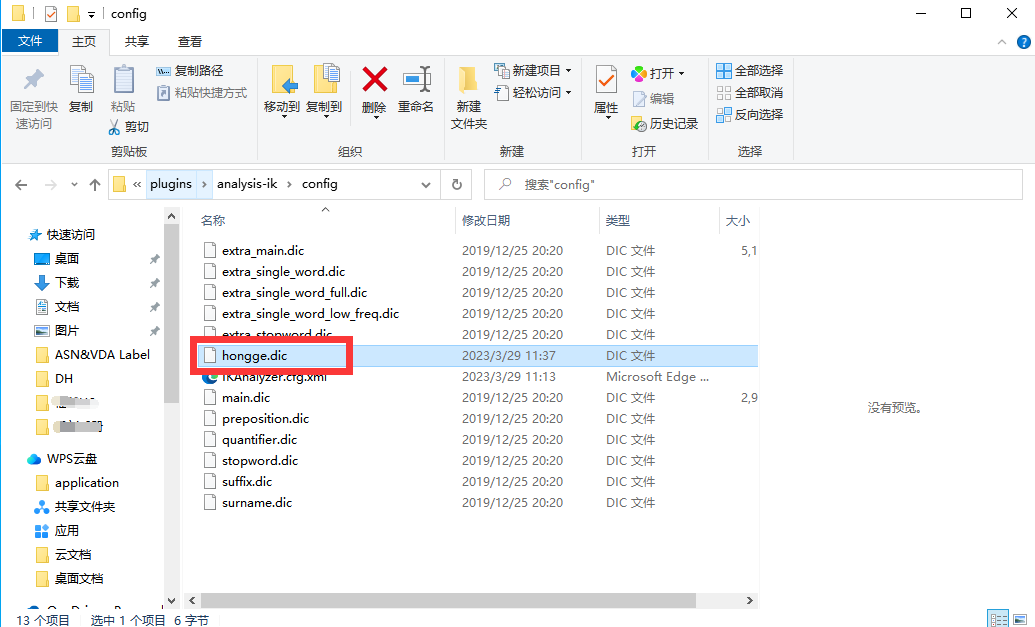
4) Введите свои слова: Брат Хонг, сохраните и перезапустите ES
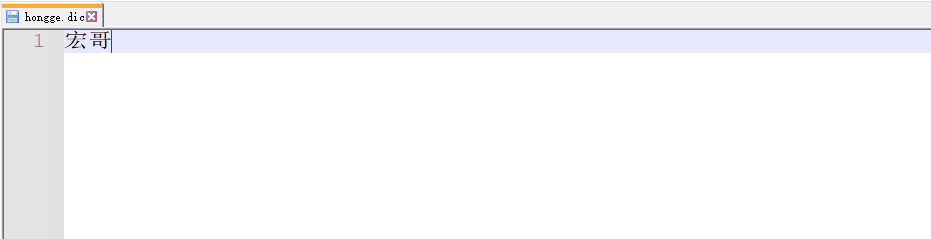
5) После модификации,Я обнаружил, что «Брат Хун» превратилось в одно слово.,Повторное тестирование Результаты возврата:
{
"tokens": [
{
"token": "Я",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "да",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": «Пекин»,
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": «Брат Хун»,
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
}
]
}6)до модификации Результаты возврата:
{
"tokens": [
{
"token": "Я",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "да",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": «Пекин»,
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": «макро»,
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 3
},
{
"token": «старший брат»,
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 4
}
]
}6.Кластер ElasticSearch
ES-кластер представляет собой Тип P2P (с использованием gossip Протокол) распределенной системы, помимо управления статусом кластера, все остальные запросы могут быть отправлены на любой узел кластера. Этот узел может узнать, на какие узлы ему необходимо пересылать, и напрямую взаимодействовать с этими узлами. Таким образом, с точки зрения сетевой архитектуры и конфигурации сервисов конфигурация, необходимая для построения кластера, чрезвычайно проста. существовать Elasticsearch 2.0 Раньше в беспрепятственной сети все конфигурации были идентичны. cluster.name узлы автоматически назначаются кластеру. 2.0 После версии, исходя из соображений безопасности, чтобы избежать проблем, вызванных слишком случайной средой разработки, из 2.0 Начиная с версии 1, метод автоматического обнаружения по умолчанию был изменен на одноадресный метод. Укажите адреса нескольких узлов в конфигурации, ES Считайте это сплетнями router роль для завершения обнаружения кластера. Поскольку это всего лишь ES Внутри очень маленькая функция, поэтому gossip router Роли не нужно настраивать индивидуально, каждая ES Можно использовать узлы. Таким образом, в одноадресном кластере каждый узел настроен с тем же списком узлов, что и routerВот и все。
Количество узлов в кластере не ограничено. Как правило, если имеется 2 или более узлов, его можно рассматривать как кластер. В целом с точки зрения высокой производительности и высокой доступности.
Учтите, что количество узлов в общем кластере составляет 3 и более.
6.1 Настройка кластера (Windows)
1) Подготовьте три сервера elasticsearch:
2) Измените конфигурацию каждого сервера.
Измените файл конфигурации \comf\elasticsearch.yml:
#Узел узел 1:
http.cors.enabled: true
http.cors.allow-origin: "*"
#Информация о конфигурации узла 1:
#Имя кластера, гарантированно уникальное
cluster.name: my-elasticsearch
#Имя узла должно быть другим
node.name: node-1
#Должен быть IP-адрес локального компьютера
network.host: 127.0.0.1
#Номер сервисного порта должен быть разным на одном компьютере
http.port: 9201
#Номера межкластерных портов связи на одной машине должны быть разными
transport.tcp.port: 9301
#Настройте кластер на автоматическое обнаружение установленного IP-адреса машины
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#Узел узел 2:
http.cors.enabled: true
http.cors.allow-origin: "*"
#Информация о конфигурации узла 1:
#Имя кластера, гарантированно уникальное
cluster.name: my-elasticsearch
#Имя узла должно быть другим
node.name: node-2
#Должен быть IP-адрес локального компьютера
network.host: 127.0.0.1
#Номер сервисного порта должен быть разным на одном компьютере
http.port: 9202
#Номера межкластерных портов связи на одной машине должны быть разными
transport.tcp.port: 9302
#Настройте кластер на автоматическое обнаружение установленного IP-адреса машины
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#Узел узел 3:
http.cors.enabled: true
http.cors.allow-origin: "*"
#Информация о конфигурации узла 1:
#Имя кластера, гарантированно уникальное
cluster.name: my-elasticsearch
#Имя узла должно быть другим
node.name: node-3
#Должен быть IP-адрес локального компьютера
network.host: 127.0.0.1
#Номер сервисного порта должен быть разным на одном компьютере
http.port: 9203
#Номера межкластерных портов связи на одной машине должны быть разными
transport.tcp.port: 9303
#Настройте кластер на автоматическое обнаружение установленного IP-адреса машины
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]3) Запустите каждый сервер узла.
Вы можете запустить elasticsearch.bat под каждым сервером отдельно. Я использую командный файл под Windows:
Создайте новый файл elasticsearch_cluster_start.bat и добавьте следующее содержимое:
Формат: начало «Имя файла, который необходимо запустить» "путь к файлу" &выражатьзапускатьAПродолжить выполнение после。
start "elasticsearch.bat" "F:\Soft\ES-cluster\cluster01\bin\elasticsearch.bat" &
start "elasticsearch.bat" "F:\Soft\ES-cluster\cluster02\bin\elasticsearch.bat" &
start "elasticsearch.bat" "F:\Soft\ES-cluster\cluster03\bin\elasticsearch.bat"В этой главе я не буду вдаваться в подробности пакетной обработки Windows.
4) Кластерное тестирование
Пока вы подключаетесь к любому узлу кластера, метод его работы практически такой же, как и у автономной версии, меняется только структура хранения.
Добавление индексов и сопоставлений
PUT http://127.0.0.1:9201/helloТело запроса:
{
"mappings": {
"properties": {
"id": {
"type": "long",
"store": true,
"index": "not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index": true,
"analyzer": "ik_smart"
},
"content": {
"type": "text",
"store": true,
"index": true,
"analyzer": "ik_smart"
}
}
}
}Результаты возврата:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "hello"
}Добавить документ
POST http://127.0.0.1:9201/hello/_doc/1Тело запроса:
{
"id": 1,
"title": «ElasticSearch — это поисковый сервер на основе Lucene»,
"content": «Он предоставляет распределенную многопользовательскую полнотекстовую поисковую систему на основе RESTful. веб-интерфейс. Elasticsearch, разработанный на Java и выпущенный с открытым исходным кодом на условиях лицензии Apache, в настоящее время является популярной поисковой системой корпоративного уровня. Разработанный для использования в облачных вычислениях, он обеспечивает поиск в реальном времени, является стабильным, надежным, быстрым и простым в использовании. "
}Возвращаемое значение:
{
"_index": "hello",
"_type": "article",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"created": true
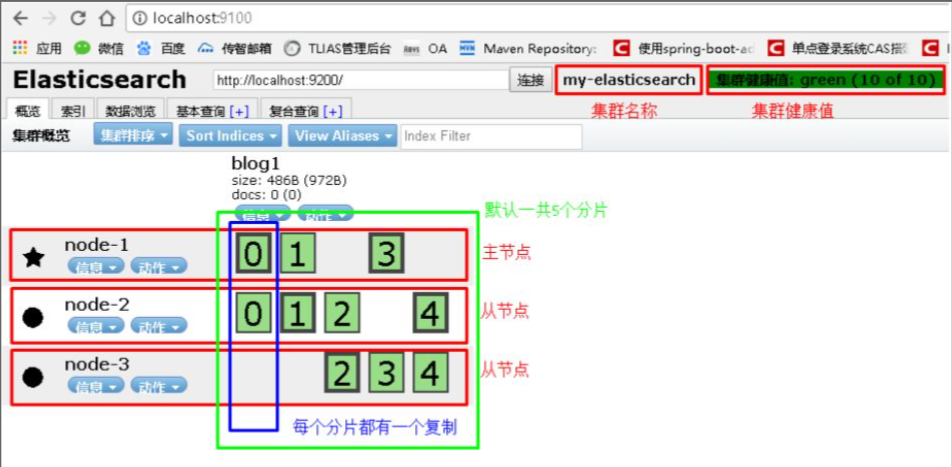
}Посмотреть в elasticsearch-head:

7. Установка ElasticSearch (Linux)
1) Убедитесь, что у вас установлена среда Java.
Вы можете напрямую скопировать файл в Windows, не используя «Установить», и распаковать Вот и все.
tar -zxf elasticsearch-6.3.2.tar.gz2) Изменить файл конфигурации.
- Измените файл conf\jvm.option.
Будет #-Xms2g
#-Xmx2g изменен на:
-Xms340m
-Xmx340m
В противном случае его нельзя будет использовать, поскольку на виртуальной машине недостаточно памяти.- Измените файл conf\elasticsearch.yml.
#Добавьте в конец elasticsearch-5.6.8\config\elasticsearch.yml:
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1
Цель состоит в том, чтобы позволить ES поддерживать междоменные запросы.3) Старт
Примечание. Прямой запуск пользователем root не поддерживается в среде Linux (причина — проблемы безопасности).
- Добавить пользователя:
[root@coderxz bin]# useradd rxz -p rongxianzhao
[root@coderxz bin]# chown -R rxz:rxz /usr/local/elasticsearch/*
[root@coderxz bin]# su rxz- осуществлять:
#Примечание: для выполнения переключитесь на пользователя без полномочий root.
[rxz@coderxz bin]$ ./elasticsearch- Проверьте текущий статус:
Проверьте, запущен ли он: jps (Команда для отображения pid всех процессов Java)
ps aux|grep elasticsearch
[root@coderxz ~]# curl -X GET 'http://localhost:9200'4) Настройте порт доступа к внешней сети 9200. Вам необходимо открыть порт сервера.
Измените файл конфигурации config/elasticsearch.yml. сеть.хост: 0.0.0.0
5) Фоновый запуск
Если вы находитесь на сервере Установить Elasticsearch,И вы хотите разрабатывать на своей локальной машине,В это время,Скорее всего, вам придется закрыть терминал,позволятьElasticsearchпродолжай бежать。Самый простой способ — использоватьnohup。Нажмите сначалаCtrl + C,Остановите работающий в данный момент Elasticsearch.,Вместо этого запустите Elasticsearch, используя команду ниже.
nohup ./bin/elasticsearch&8. Резюме
Обратите внимание на совместимость различных версий ES и Java. Лучше всего использовать ту, которая идет в комплекте. И разница в правилах синтаксиса, используемых версией ES.
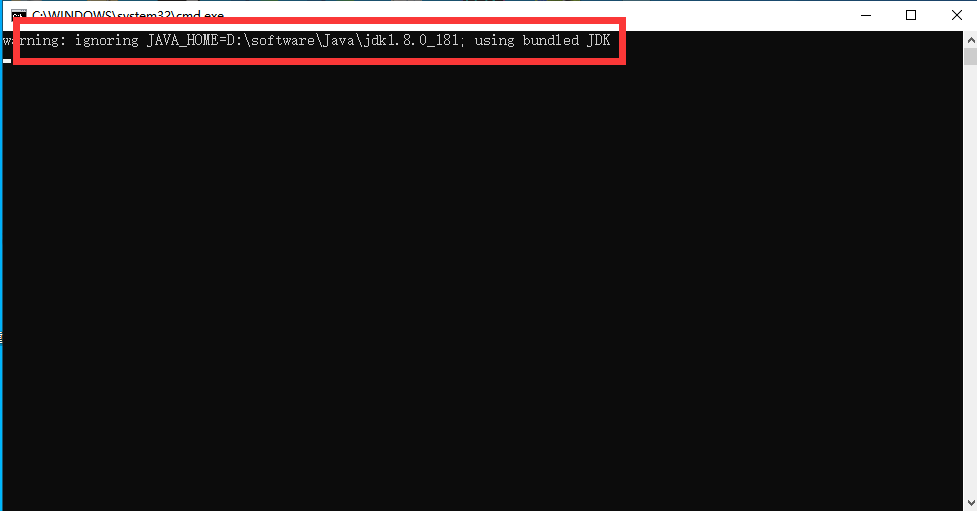
8.1 Ошибка запуска ES
Elasticsearch-8.6.2 сообщает об ошибке при запуске. Вам необходимо использовать встроенную среду Java вместо настроенной по умолчанию среды Java. Наконец, происходит сбой или требуется использование других версий Java.
Решение:
1. Отредактируйте файл elasticsearch-8.6.2\bin\elasticsearch-env.bat и закомментируйте следующий код:

2. Добавлено использование встроенного кода JDK по умолчанию.
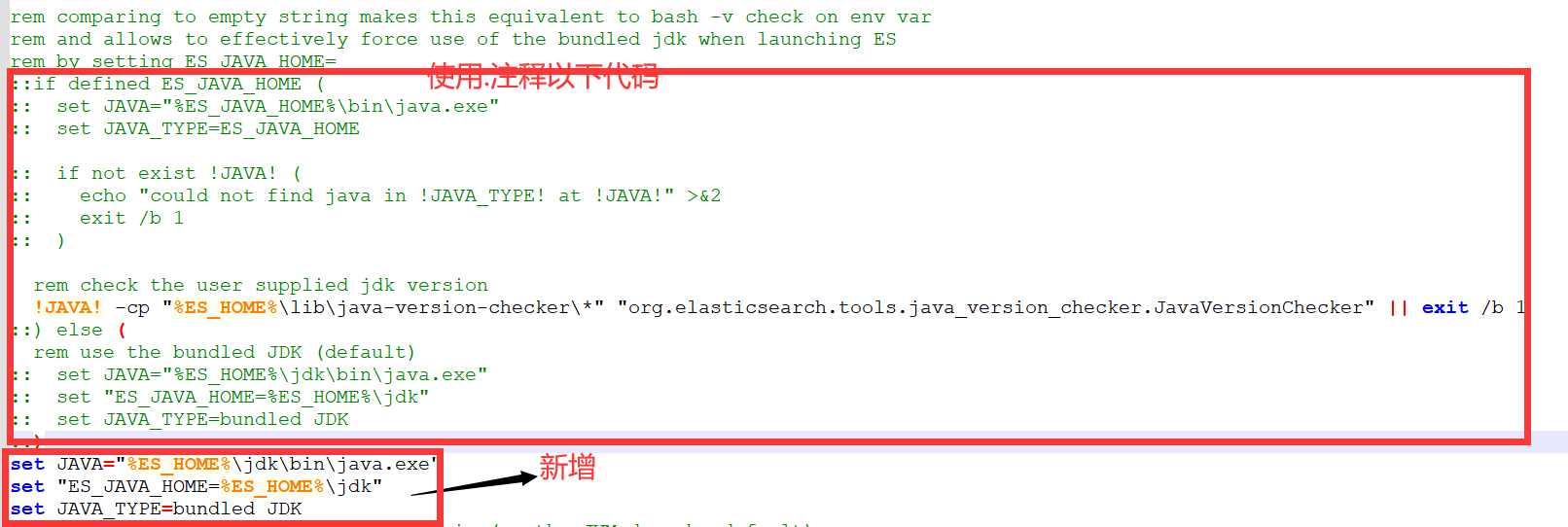
set JAVA="%ES_HOME%\jdk\bin\java.exe"
set "ES_JAVA_HOME=%ES_HOME%\jdk"
set JAVA_TYPE=bundled JDKПроблема, с которой столкнулся Хонг Ге, заключалась в сбое, и Хонг Ге использует последнюю версию локальной среды Java Хонг Ге — 1.8. Вышеуказанный метод не работает. После загрузки ES 7.6.1 он работает хорошо. Причина в том, что ES8 несовместим с версиями Java 1 и 8.
скачатьадрес:Past Releases of Elastic Stack Software | Elastic
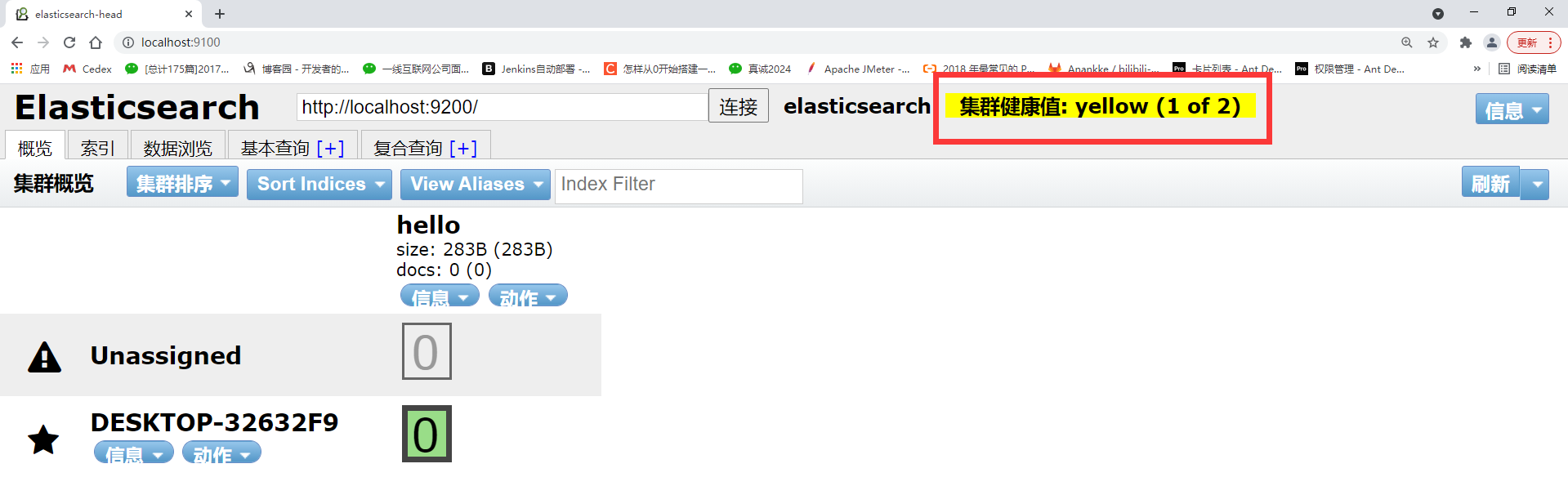
8.2ES (Elasticsearch) доступ к значению работоспособности кластера не подключен
http://localhost:9100/ продолжает запрашивать: Значение работоспособности кластера: не подключено.

Решение:
открытый путь "..\elasticsearch\config\ " вниз elasticsearch.yml файл, добавьте следующий код в конец файла:
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: "X-Requested-With, Content-Type, Content-Length, X-User"Перезапустите службы на портах 9100 и 9200.,Посетите Вот и все еще раз.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
