[Третья годовщина ES] ES Query — массовый поиск данных, глубокая оптимизация разбиения на страницы
фон
В последнее время условия запросов в реальных проектах становятся все более сложными, и фильтрация MySQL больше не поддерживает их. Мы планируем заменить все поисковые фильтры на запросы es. Учитывая эту ситуацию, в этой статье исследуются преимущества и недостатки четырех запросов: from-size, search_after, прокрутки API, search_after (PIT).
From - размер обычного подкачки
использовать from + size Перевернуть страницу
fromНе указано, значение по умолчанию 0, определяет, что нужно пропуститьhitsномер, по умолчанию 0。sizeНе указано, значение по умолчанию 10. Определите, что необходимо вернутьhitsМаксимальное количество.

Программа используется проста и имеет большое количество страниц, которые нужно перелистывать. from больше или size В особенно крупных случаях возникнут серьезные проблемы с перелистыванием страниц. ES Одна страница по умолчанию Запросмаксимальный пределmax_result_window до 10000 。

Причина проблемы с глубоким переворачиванием страниц: ES Он использует распределенную архитектуру. При хранении данных они распределяются по разным местам. shard середина. При запросе, если from Если значение слишком велико, начальная точка подкачки будет слишком глубокой. каждый shard При запросе, from Все данные и запросы из предыдущих локаций size Общее количество возвращается вcoordinator。дляcoordinatorДавайте поговорим,Значительно приведет к увеличению скорости использования памяти и ЦП.,Особенно в сценариях с высоким уровнем параллелизма.,Приводит к снижению производительности или отказу узла.
например ЕС делиться 4 индивидуальныйshard,И каждыйиндивидуальныйshardнет копии。если Пагинация Размер 10, хочу занять 11 место содержимое страницы. тогда соответствующий from = 100,size = 10。
Процесс запроса ES:
- Каждыйиндивидуальный
shardобщее местосуществовать Данные загружаются в память исортировать,Тогда возьми первые 110,вернуться вcoordinator。 - Каждыйиндивидуальный
shardВсеосуществлять Вышеописанная операция。 - наконец
coordinatorВоля 110 * 4 = 440 Отсортируйте данные, а затем возьмите 10 Данные возвращаются.
Можно обнаружить, что если положение from слишком глубоко, неизбежно возникнут следующие проблемы:
- вернуться в
coordinatorЗначение слишком велико,Актуальная потребность 10частей данных,но датьcoordinator440 часть данных coordinator需要处理Каждыйиндивидуальныйshardперед возвращением 11 страниц результатов. Но нужно только первое 11 содержание страницы, но для предыдущего 44 Содержимое страницы сортируется, тратится память и cpu ресурсы.
преимущество
- Реализация относительно проста.
- Вы можете указать любой разумный номер страницы для реализации запроса перехода на страницу.
недостаток
- Запрос Пагинацияограничено
max_result_windowнастраивать,Неограниченное перелистывание страниц невозможно. - Производительность пагинации запроса нестабильна,Чем дальше вы идете назад, тем медленнее перелистываете страницы.,Сохранить глубокую проблему перелистывания страниц.
перейти к коду
func SearchTaskSampleByQuery(ctx context.Context, query *elastic.BoolQuery, page *common_base.PageReq) (int64, []es.TaskSample, error) {
var taskSampleList []es.TaskSample
esClient, err := olivere7.Get(config.EsNameSrv)
if err != nil {
return 0, taskSampleList, constant.Errorf(constant.CodeErrEsSearchFail, "SearchTakSample get es client error: %w", err)
}
search := esClient.Search().Index(имя индекса)
search.Query(elastic.NewBoolQuery().Must(query))
// сортировать
search.Sort("id", false)
// Пагинация
if page != nil {
from := page.PageSize * (page.PageNum - 1)
search.From(str.StringToInt(fmt.Sprint(from)))
search.Size(str.StringToInt(fmt.Sprint(page.PageSize)))
}
search.TrackTotalHits(true)
// осуществлять
esResult, err := search.Pretty(true).Do(ctx)
if err != nil {
return 0, taskSampleList, constant.Errorf(constant.CodeErrEsSearchFail, "SearchTaskSampleByQuery Do error: %w", err)
}
// преобразование данных запроса es
return parseEsSearchTaskSampleResult(ctx, esResult)
}Прокрутка страниц запроса
Большие пакеты запросов к документам могут выполняться эффективно. Запросы курсора берут данные моментального снимка в определенный момент времени. Любые изменения индекса после инициализации запроса им игнорируются. Эта функция достигается за счет сохранения старых файлов данных, в результате чего получается то же индексированное представление, что и при его инициализации.
Как использовать эту пагинацию,Не для данных запроса в реальном времени,но дляЗапрос большого количества данных (даже всех данных) одновременно)。

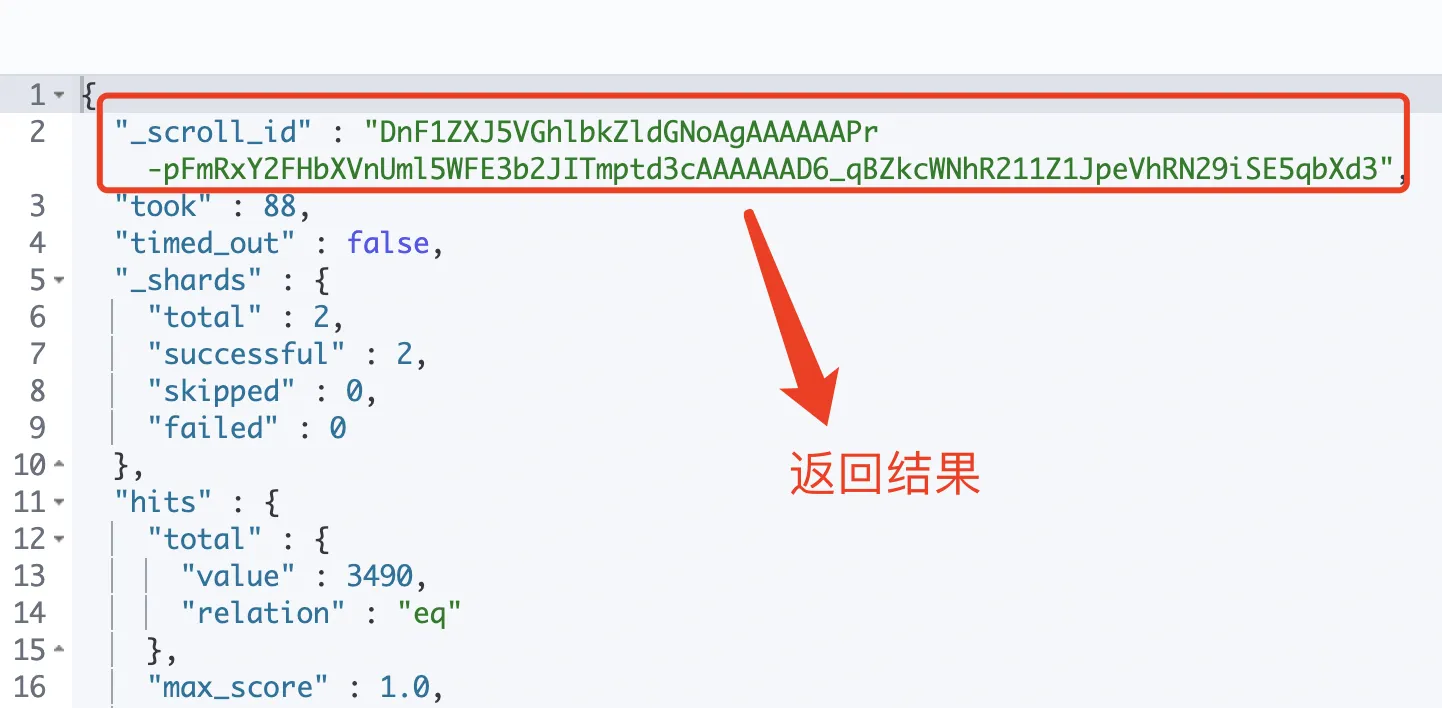

специфическийиспользоватьметод:
- При первом запросе появляется
scrollIdи кэшировать все результаты поиска, соответствующие условиям поиска. Обратите внимание, что это только кэшируетсяdoc_id, не все данные документа действительно кэшируются, данные извлекаются из существованияfetchэтап завершен. - В последующих запросах вам необходимо использовать информацию, возвращенную предыдущим запросом.
scrollIdиscrollesСделай этот снимок(search контекст) эффективное время кэшированных результатов 。

Получение ES разделено на два этапа: запрос и выборка. Этап запроса более эффективен и запрашивает только те идентификаторы документов, которые соответствуют условиям. Фаза выборки выполняет глобальную сортировку на координирующем узле на основе результатов каждого сегмента, а затем, наконец, вычисляет результаты.
Запрос прокрутки ищет только те, которые соответствуют условиям doc_id (Официально рекомендуется doc_id Сортировка, потому что сам кэш doc_id , если сортировка по другим полям увеличит объем запроса), отсортируйте их и сохраните в поиске контекст, но он не извлекает все данные. Вместо этого он считывает документы размера каждый раз при прокрутке и возвращает следующий документ, прочитанный в этот раз, и статус контекста, чтобы сообщить, какой документ из какого фрагмента необходимо начать чтение в следующий раз.
преимущество
- Поиск на основе снимков данных может эффективно обеспечить согласованность данных.
- Запросы не ограничены index.max_result_window.
недостаток
- Результаты запроса не отображаются в реальном времени, и изменения данных не будут отражены в снимке.
- поддерживать
scroll_idи исторические снимки, а также должны обеспечитьscroll_idвремя жизни, что является огромной нагрузкой на сервер.
перейти к коду
// ScrollTaskSample прокрутить автономный запрос
func ScrollTaskSample(ctx context.Context, query *elastic.BoolQuery, scrollId, scrollTime string) (int64, []es.Sample, error) {
var sampleList []es.Sample
esClient, err := olivere7.Get(config.EsNameSrv)
if err != nil {
return 0, sampleList, constant.Errorf(constant.CodeErrEsSearchFail, "SearchSampleByQuery get es client error: %w", err)
}
search := esClient.Scroll().Index(SampleIndex)
search.Query(elastic.NewBoolQuery().Must(query))
// сортировать
search.Sort("id", false)
search.Size(1000)
// хиты версии 7.0
search.TrackTotalHits(true)
// При первом вызове передайте пустую строку ScrollId, scrollTime 5s, получать esResult.ScrollId
// Для последующих вызовов введите esResult.ScrollId, 5m, Пока длина массива попаданий не станет 0
search.ScrollId(scrollId)
// время моментального снимка
search.Scroll(scrollTime)
// осуществлять
esResult, err := search.Pretty(true).Do(ctx)
if err != nil {
return 0, sampleList, constant.Errorf(constant.CodeErrEsSearchFail, "SearchSampleByQuery Do error: %w", err)
}
return parseEsSearchSampleResult(ctx, esResult)
}Поиск_после пейджинга
search_after Запрос: Использовать Последнюю часть запроса данные для вашего следующего запроса. Потому что данные на каждой странице зависят от последней части предыдущей страницы. данных, поэтому запросы на переход к странице не могут быть выполнены.

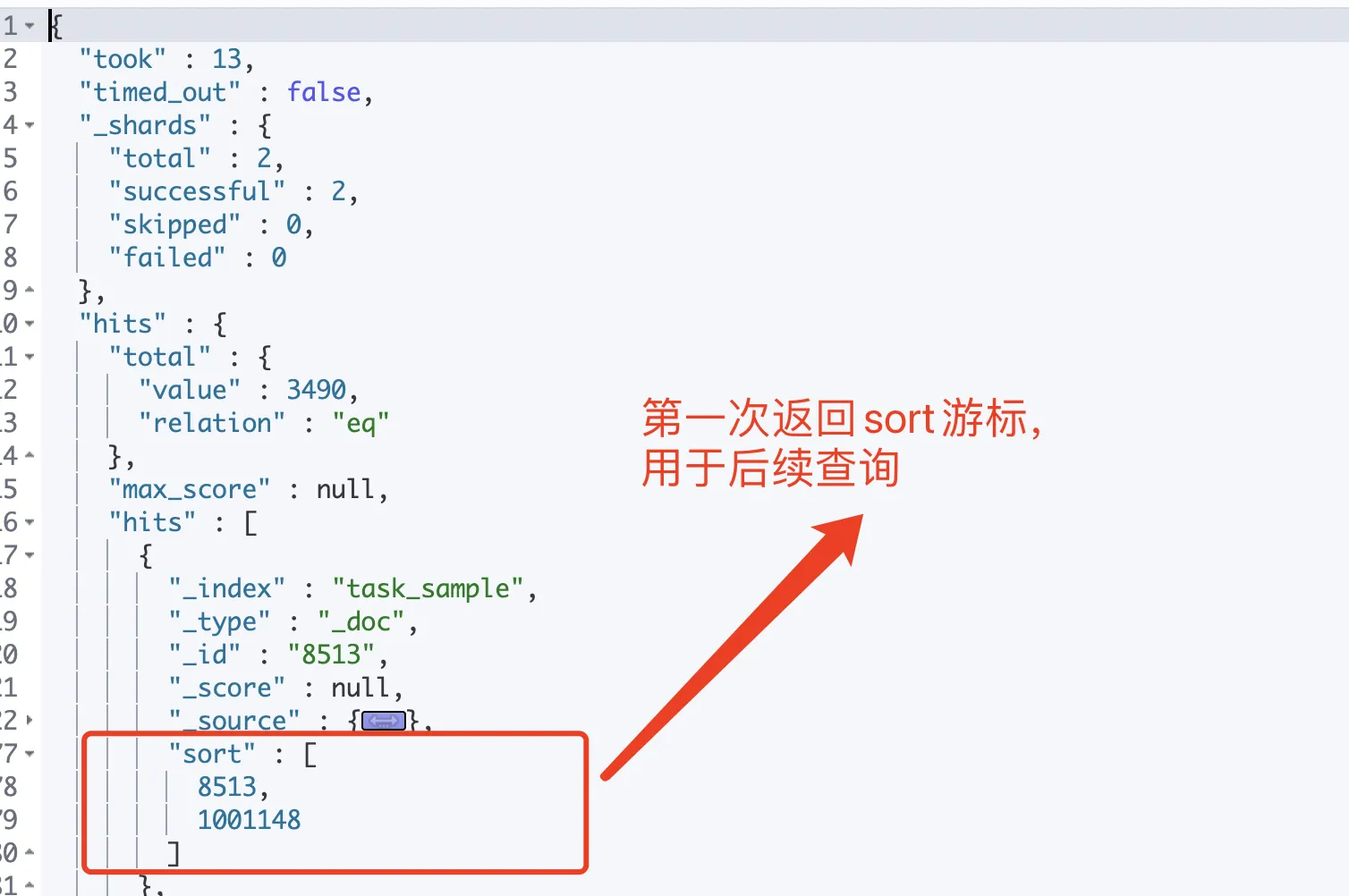
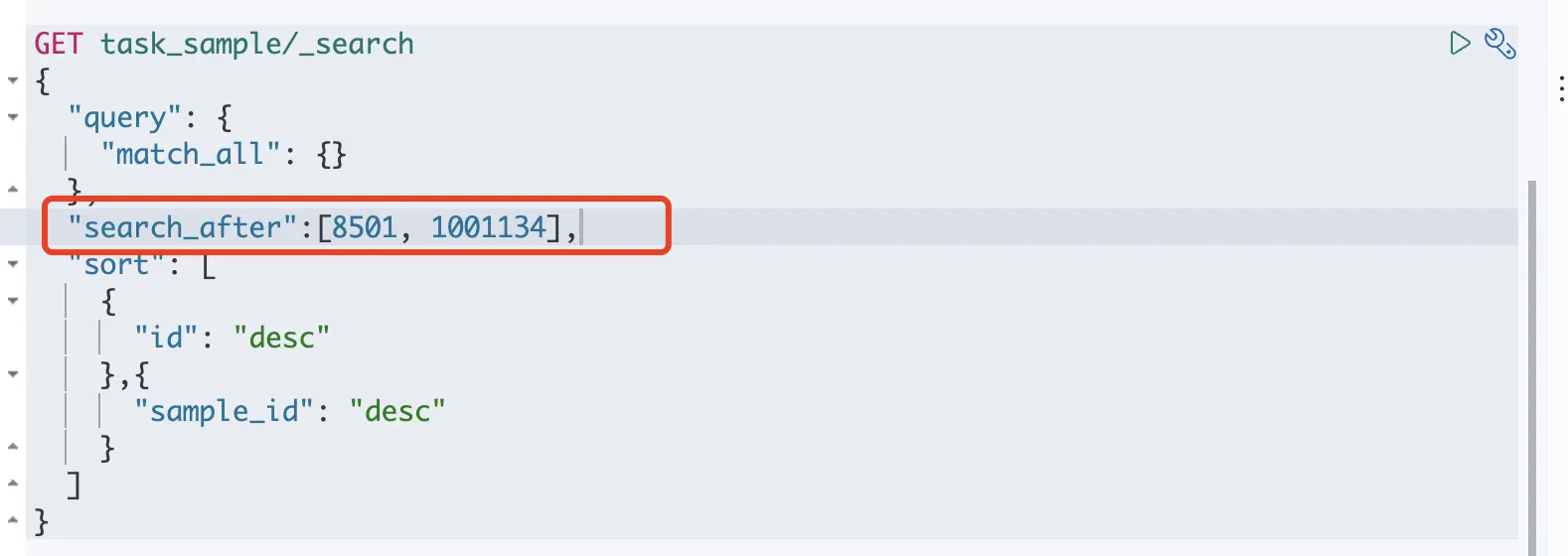
специфическийиспользоватьметод:
- По первому запросу приходит сообщение, содержащее
sortмассив отсортированных значений - существуют Следующий запрос может вернуть результат предыдущего запроса
sortЗначение сортировки используется для ввода параметров для захвата данных на следующей странице.
например ЕС делиться 4 индивидуальныйshard,И каждыйиндивидуальныйshardнет копии。если Пагинация Размер 10, хочу занять 11 место содержимое страницы. Соответствующий from = 100,size = 10.
Процесс запроса ES:
- Каждыйиндивидуальный
shardв соответствии сsortкурсор,Возьмите 10 образцов, соответствующих условиям.,вернуться вcoordinator. - Каждыйиндивидуальный
shardВсеосуществлять Вышеописанная операция。 - наконец
coordinatorВоля 10 * 4 = 40 Отсортируйте данные, а затем возьмите 10 Данные возвращаются.
преимущество
- Запрос без сохранения состояния,Может предотвратить существование во время запроса,Изменения данных не могут быть своевременно отражены в запросах.
- ненужныйподдерживать
scroll_id,Снимок подтверждения не требуется,Таким образом, можно избежать потребления больших объемов ресурсов. - Запросы не ограничены index.max_result_window.
недостаток
- потому что Запрос без сохранения состояния,Поэтому существующие изменения во время запроса могут привести к несоответствиям на страницах.
- сортировать Приказ можетсуществоватьосуществлятьизменения во время,Зависит от обновления индекса и удаления.
- Для сортировки необходимо указать хотя бы одно уникальное поле.
- Он не подходит для запросов перехода на большие страницы или полного экспорта. Запрос перехода на N-ю страницу эквивалентен многократному выполнению N поисков по es. after,Полный экспортсуществоватьв течение короткого периода времениосуществлять Много повторений Запрос。
перейти к коду
// SearchAfterTaskSample Запрос курсора Пагинация
func SearchAfterTaskSample(ctx context.Context, query \*elastic.BoolQuery, sortFlag \*[]interface{}) (int64, []es.Sample, error) {
var sampleList []es.Sample
esClient, err := olivere7.Get(config.EsNameSrv)
if err != nil {
return 0, sampleList, constant.Errorf(constant.CodeErrEsSearchFail, "SearchSampleByQuery get es client error: %w", err)
}
search := esClient.Search()
search.Query(elastic.NewBoolQuery().Must(query))
// сортировать
search.Sort("id", false)
if sortFlag != nil {
// search\_after
search.SearchAfter(sortFlag...)
}
// хиты версии 7.0
search.TrackTotalHits(true)
// осуществлять
esResult, err := search.Pretty(true).Do(ctx)
if err != nil {
return 0, sampleList, constant.Errorf(constant.CodeErrEsSearchFail, "SearchSampleByQuery Do error: %w", err)
}
// Курсор следующей страницы sortFlag := &esResult.Hits.Hitslen(esResult.Hits.Hits)-1.Sort
return parseEsSearchSampleResult(ctx, esResult)
}Поиск_после (PIT) пейджинга!

существовать После 7.10 версия, официальная ES Метод прокрутки для глубокой пагинации больше не рекомендуется, но рекомендуется использовать с PIT. search_after наводить справки.

PIT можно рассматривать как упрощенное представление, в котором хранится состояние индексных данных. Создайте момент времени (PIT), чтобы гарантировать, что индексный статус определенной точки события сохраняется во время процесса поиска. При использовании PIT все последующие запросы в search_after основаны на представлении PIT, что может эффективно обеспечить согласованность данных.

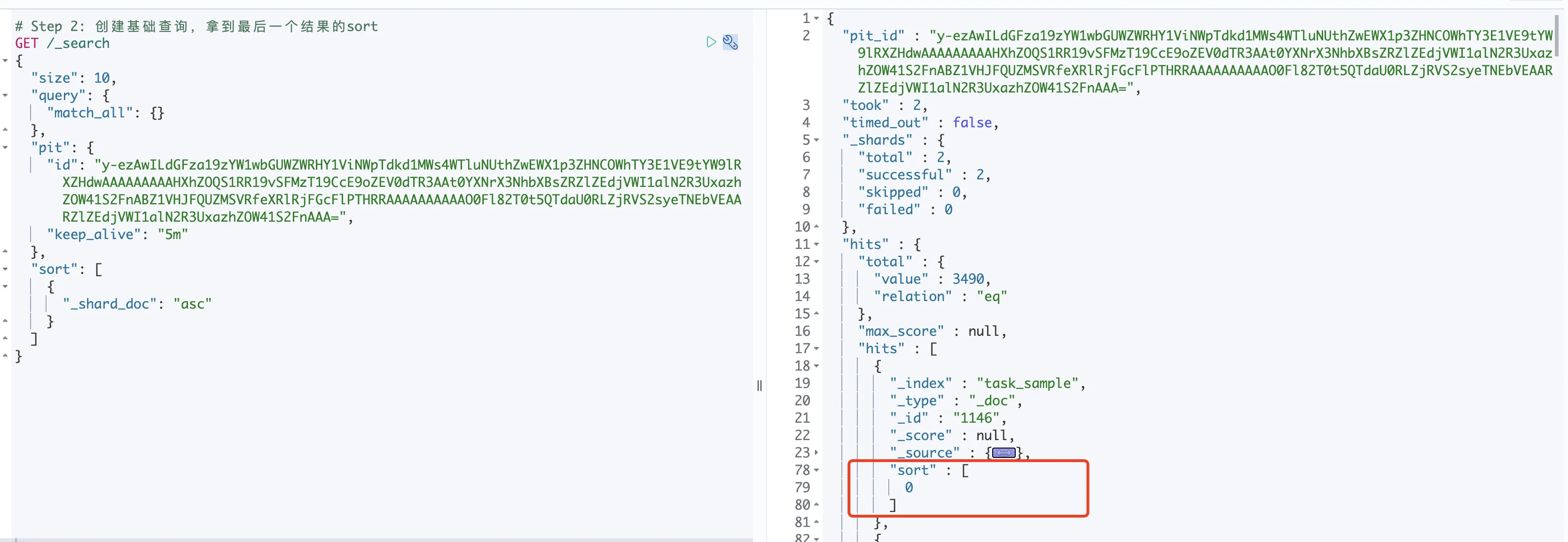
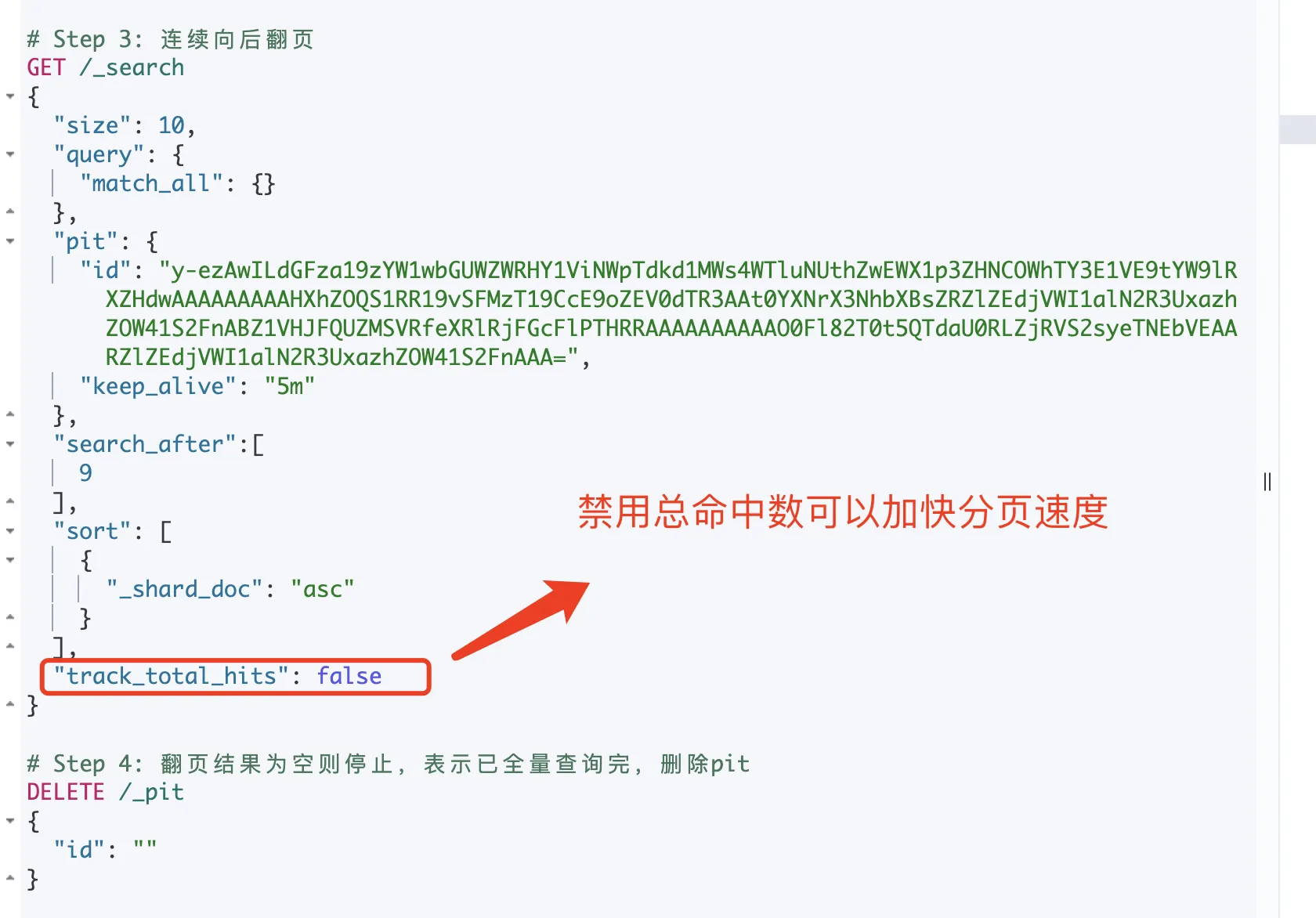
преимущество
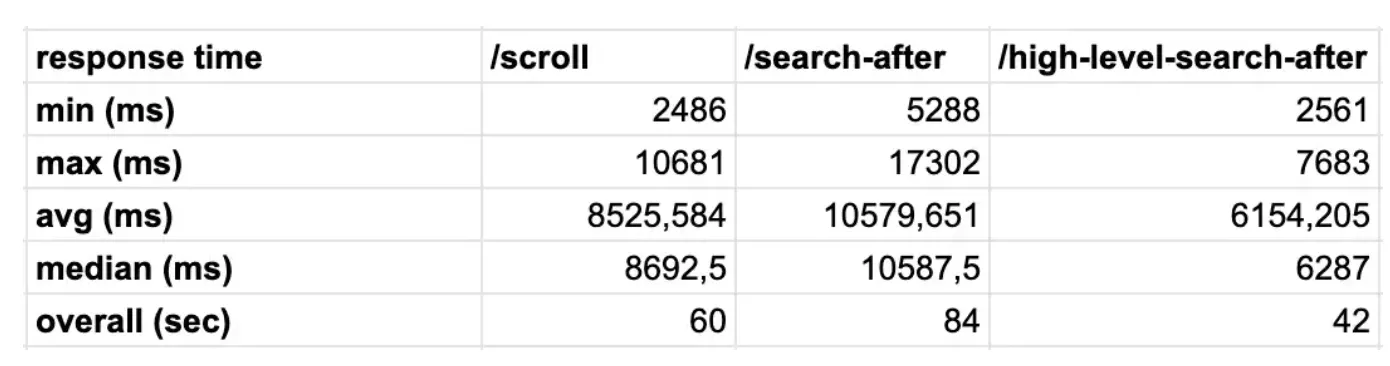
Эффект от запроса Пагинация точно такой же, как и от Прокрутки.,но средний Запрос Повышение эффективности30%。Цитируемый текст: Elasticsearch Scroll API против поиска после с PIT
По сравнению с прокруткой также была оптимизирована память и упрощен процесс es-запроса:
- Шаг 1. Пользователь отправляет запрос dsl.
- Шаг 2. ES получает ссылку на память сегмента (фактически ссылку на объект ReaderContext, указывающую на данные в определенном состоянии сегмента сегмента).
- Шаг 3. ES запрашивает результат из шарда на основе dsl
- scroll Принцип прямойосуществлять Первый、два、три шага,Затемсуществоватькеш-памятьresult Создайте курсор для всех результатов одновременно, а затем шаг за шагом возвращайте результаты посредством перемещения курсора.
- Принцип Пита заключается в том, чтобы сначала выполнить второй шаг и кэшировать ссылку на память сегмента, а затем выполнить первый и третий шаги. Затем пользователь постепенно извлекает данные, отправляя dsl и указывая после этого поиск.
Видно, что частота повторного использования кеша уpit выше, чем у прокрутки: например, если поступает 1 миллион запросов на прокрутку, в памяти необходимо кэшировать 1 миллион результатов запросов на прокрутку. Однако ссылки на сегментную память в кэше ямы на самом деле могут повторно использоваться во многих запросах, и само собой разумеется, что потребление памяти будет ниже.
Он подходит для таких сценариев, как получение больших пакетных данных, обработка данных не в реальном времени, миграция данных или изменение индексов.
недостаток
Запрос не может отражать характер данных в реальном времени. Созданный исторический снимок данных не будет отражать изменения данных в снимке.
перейти к коду
// CreatePit Создать момент времени
func CreatePit(ctx context.Context, indexName, aliveTime string) (string, error) {
esClient, err := olivere7.Get(config.EsNameSrv)
if err != nil {
return "", constant.Errorf(constant.CodeErrEsSearchFail, "get es client error: %w", err)
}
openRsp, err := esClient.OpenPointInTime(indexName).KeepAlive(aliveTime).Pretty(true).Do(ctx)
if err != nil {
return "", err
}
return openRsp.Id, nil
}
// ClosePit время закрытия
func ClosePit(ctx context.Context, pit string) (bool, error) {
esClient, err := olivere7.Get(config.EsNameSrv)
if err != nil {
return false, constant.Errorf(constant.CodeErrEsSearchFail, "get es client error: %w", err)
}
closeResp, err := esClient.ClosePointInTime(pit).Pretty(true).Do(ctx)
if err != nil {
return false, err
}
return closeResp.Succeeded, nil
}
// SearchAfter Курсорный запрос
func SearchAfter(ctx context.Context, query *elastic.BoolQuery, sortFlag []interface{},
pit, aliveTime string) (*elastic.SearchResult, error) {
esClient, err := olivere7.Get(config.EsNameSrv)
if err != nil {
return nil, constant.Errorf(constant.CodeErrEsSearchFail, "get es client error: %w", err)
}
search := esClient.Search()
// Каждая настройка размера тяги
search.Size(10)
search.Query(elastic.NewBoolQuery().Must(query))
// сортировать
search.Sort("_shard_doc", true)
// доставка в определенный момент
if len(pit) > 0 {
pointTime := &elastic.PointInTime{
Id: pit,
KeepAlive: aliveTime,
}
search.PointInTime(pointTime)
}
// Прохождение курсора
if len(sortFlag) != 0 {
// search_after
search.SearchAfter(sortFlag...)
}
// осуществлять
esResult, err := search.Pretty(true).Do(ctx)
if err != nil {
return nil, constant.Errorf(constant.CodeErrEsSearchFail, "SearchAfter Do error: %w", err.Error())
}
return esResult, nil
}Подвести итог
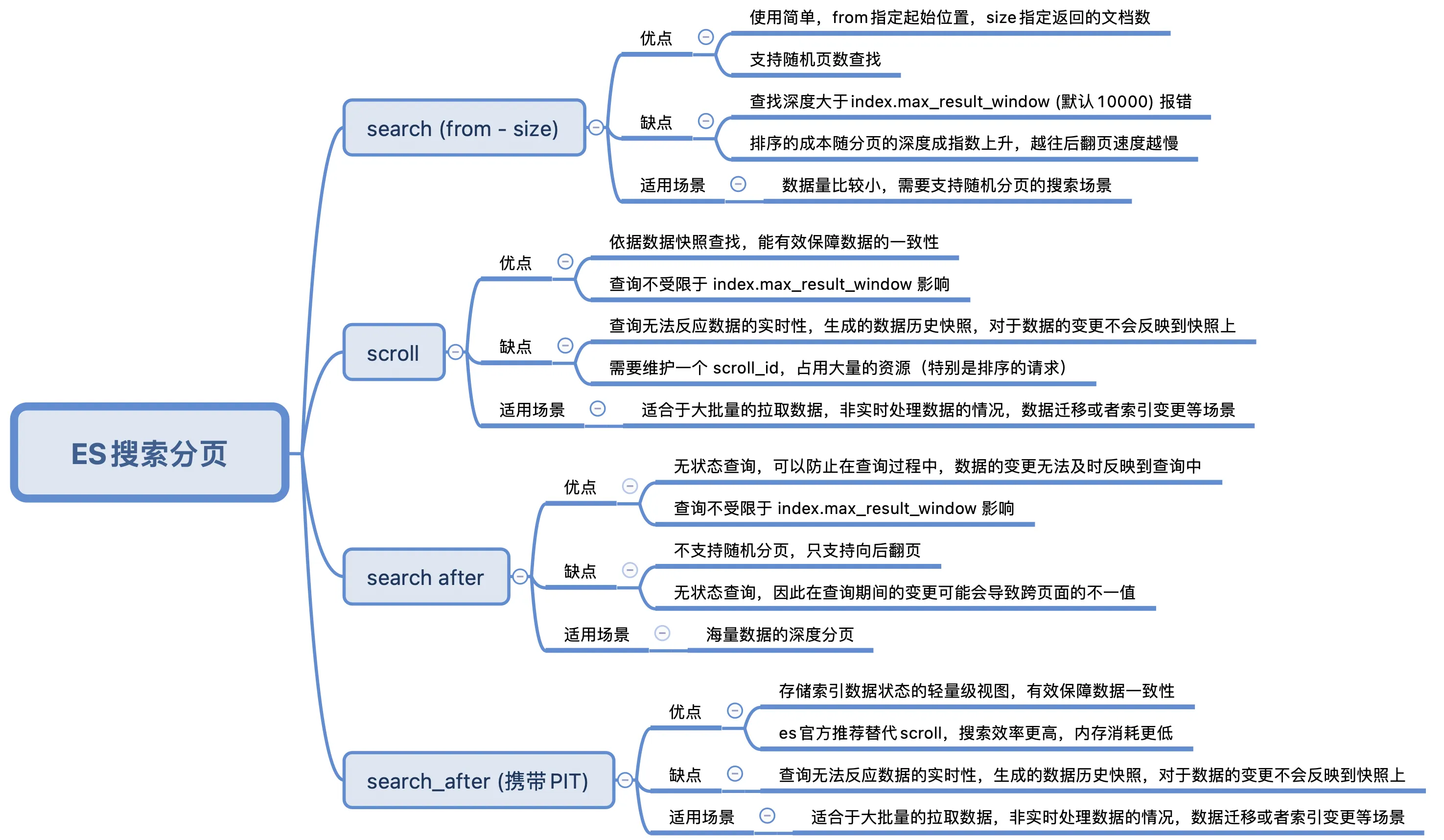
- Объем данных проекта относительно невелик и может допускать серьезные проблемы. - size。
- Проектам не обязательно поддерживать случайное перелистывание страниц.,Скользящая сцена, похожая на водопадную диаграмму,Массивные данные,Рекомендуется использовать search_after.
- При извлечении данных большими пакетами, обработке данных не в режиме реального времени, миграции данных или изменении индекса рекомендуется использовать search_after (PIT).
Ссылки:
- https://www.elastic.co/guide/en/elasticsearch/reference/master/paginate-search-results.html#scroll-search-context
- https://www.elastic.co/guide/en/elasticsearch/reference/current/point-in-time-api.html
- https://km.woa.com/group/35929/articles/show/528932?ts=1673403220
- https://cloud.tencent.com/developer/article/1825190



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
