Точная конструкция системы тестирования
1. Болевые точки функционального тестирования
1.1 Объем и эффект испытаний
После тестирования версии разработчики часто говорят, что масштаб воздействия относительно велик. Давайте сделаем основную ссылку или сделаем полную регрессию. Почему возврат занимает так много времени? и т. д.
После завершения теста тестировщик часто говорит, что тест гарантирует, что все тестовые примеры выполняются на месте и нет ничего, что нельзя было бы рассмотреть.
После изменения кода Оценка масштаба воздействия,а такжетест После завершенияиз оценка покрытия Это сложная проблема. В настоящее время большинство людей полагаются на личный опыт и деловые знания, чтобы судить о приблизительном объеме.
Этот метод оценки в основном основан на субъективном суждении и не имеет подкрепления данными. Есть надежда, что систематические инструменты смогут предоставить объективные данные и провести количественную оценку на основе этих данных.
1.2 Стоимость и эффективность тестирования
Итераций продукта становится все больше, и изменения кода будут влиять на существующие функции продукта. Помимо автоматического тестирования, основанного на CI, также важна ручная регрессия, и необходимо учитывать ее стоимость и эффективность.
Чтобы обеспечить качество, идеальное регрессионное тестирование охватывает весь процесс. Однако, если изменения вносятся за пять минут, а возвращаются через два часа, стоимость тестирования будет огромной, и будет много недействительных тестов.
Идеальный регрессионный тест охватывает измененный контент и использует ограниченное количество операций для выявления всех проблем.
Если это возможно установить подвариант кода взаимосвязь использованияиз сопоставления, При изменении кода рекомендуется использовать соответствующие варианты использования, чтобы сделать тест более эффективным. Возврат с точностью,Сокращение затрат,Повышайте эффективность.
1.3 Сотрудничество в области тестирования и разработки
- в настоящий момент Bug Процесс обработки: тестexecutestvariant использования,Обнаружить Bug Отправить Дзен Тао, напоминание Дзен Дао развивать, улучшать понимание и воспроизведение Bug , удаленная отладка решает проблему.
На протяжении всего процесса может потребоваться много времени, чтобы понять, воспроизвести и исправить ошибки на основе описаний ошибок, представленных студентами-испытателями.
Если тест сможет найти код с ошибками и передать его обратно в разработку путем выполнения сценариев использования, разработка и исправление ошибок будут происходить намного быстрее, а совместная работа между разработкой и тестированием станет намного проще.
- требуется разработка тестов для оказания помощи в анализе открытого кода в дополнение к тестварианту. использование;развивание требует покрытия кода для оптимизациикода (удалить nousecode и т. д.)
В настоящее время, после получения отчета о покрытии, большинству тестировщиков приходится просить разработчиков дополнить варианты использования кода, который в отчете окрашен в красный цвет, поскольку они не знакомы с кодом.
Если в отчет о покрытии можно добавить функцию аннотации, разработчик может использовать аннотации, чтобы сообщить тестировщику, какие бизнес-сценарии и варианты использования необходимо добавить в этот код, что может повысить эффективность.
2. Общее решение
2.1 Архитектура
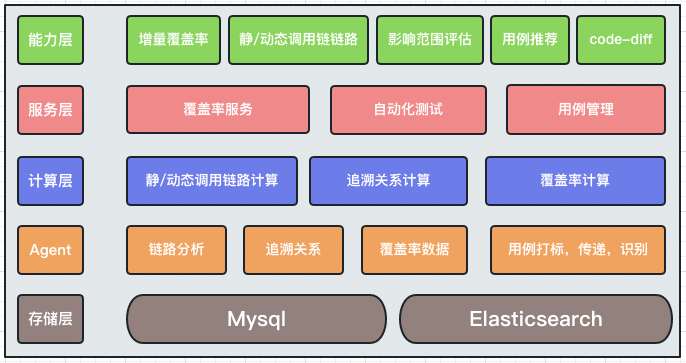
2.2 Диаграмма последовательности UML
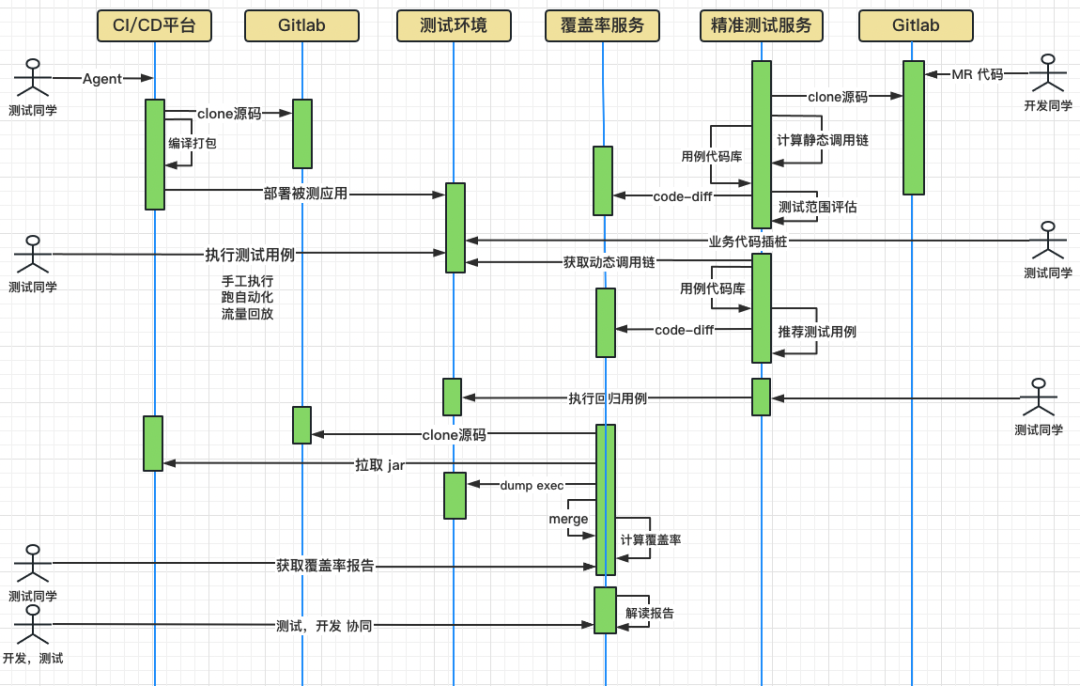
2.3 Двусторонняя и прямая отслеживаемость
Суть **упреждающей трассировки** заключается в том, чтобы связать тестовые сценарии с кодом и создать базу кода вариантов использования. Это основа для рекомендации вариантов использования регрессии и является главным приоритетом.
Основная связь между тестовыми примерами и кодом Динамическая цепочка вызовов,чтобы получить Динамическая цепочка нужны вызовы Agent Внедрите в приложение и соберите данные времени выполнения приложения.
У компании есть наблюдаемая платформа на основе OpenTelemetry, которая может предоставлять динамические ссылки на вызовы и предоставлять нам базовые возможности для создания базы кода вариантов использования.
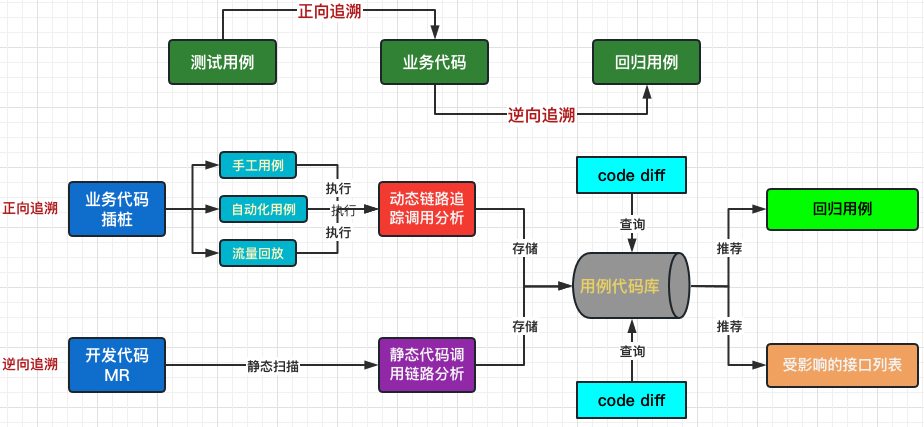
2.3.1 Создание базы кода вариантов использования
Благодаря возможности генерировать динамические ссылки на вызовы вы можете создавать База кода варианта использования Понятно,База кода варианта Строительство может осуществляться тремя способами.
- Одноклассники выполняют вариант теста вручную использования,Один вариант использования соответствует нескольким запросам,Просьба дать ссылку на настройку.
- Запускайте автоматизированные сценарии. Один сценарий соответствует нескольким запросам, и для каждого запроса требуется одна ссылка на вызов.
- Запись и воспроизведение трафика — это непосредственно один запрос и одна вызывающая ссылка.
Волявариант использования. Его настроенная ссылка на использование сохраняется в виде снимка из хранилища объектов ESили для последующего изменения. Использование рекомендуется предоставить базовые библиотеки Единственная хлопотная вещь здесь — это База. кода варианта использованияизподдерживать。
Новые функции каждой версии в основном проверяются путем тестирования. В процессе тестирования варианты ее использования связываются с кодом, что служит основой для последующих рекомендаций по вариантам использования.
Старая функция от База кода варианта вариант выхода мобильного телефона на мобильный телефон Использование проводит автоматизированный или ручной метод тестирования потока, т. е. на базе кода варианта Техническое обслуживание особенно важно.
Вы можете установить цикл для каждого снимка. После этого цикла рекомендуемые варианты использования потребуют ручного вмешательства, чтобы проанализировать, являются ли они пригодными для использования.
о База кода варианта использованияиз Строитьв настоящий моментвозвращатьсясуществовать В разработке......
2.3.2 Рекомендации по тестированию
База построена кода варианта После использования необходимо продолжить Рекомендации по тестированию。
Используйте существующую возможность клонирования компиляции, чтобы протестировать ветку и главный код, получить дифференциальный код, а затем проверить вызывающую ссылку на основе дифференциального кода, чтобы вычислить область, которую необходимо протестировать.
На этом этапе, хотя диапазон испытаний и может быть рекомендован, точность может быть неудовлетворительной.
Например, при изменении базового или общедоступного кода, поскольку эти коды связаны со многими вариантами использования, система будет рекомендовать большое количество избыточных вариантов использования, что влияет на эффективность тестирования.
Так как же повысить точность рекомендаций? Создание рекомендаций на уровне метода приведет к появлению избыточных вариантов использования и повлияет на точность рекомендаций следующим образом:
public static void fun(int a){
if(a == 0){
System.out.println("Прошло a=0 из Филиал");
}else if(a == 1){
System.out.println("Прошло a=1 из Филиал");
}else{
System.out.println("Прошло Не а=0 и не а=1 из Филиал");
}
}
Предполагается, что метод fun имеет три варианта использования:
- Вариант использования 1: передать a = 0
- Вариант использования 2: передать a = 1
- Вариант использования 3: передать a = x
При изменении кода в ветви a = 0, если стратегия рекомендаций точна на уровне метода, будут рекомендованы эти три варианта использования.
Но на самом деле варианты использования 2 и 3 не будут затронуты вообще, что приведет к созданию избыточных вариантов использования.
так,существовать Учреждать База кода варианта использованиеиз, пришло время Волявариант использование связано с веткой кода кода,
При выполнении анализа ветвей получаются условия ветвей для выполнения вариантов использования и блоки кода, соответствующие ветвям. При рекомендации расчет разностного кода также должен быть точным относительно того, какие ветки изменились.
Поэтому сначала сопоставьте условия ветвления кода, представленного на этот раз, с условиями ветвления вариантов использования в библиотеке вариантов использования. Если совпадения согласованы, сравните содержимое ветки на наличие изменений.
Если есть изменение, необходимо дать рекомендацию. Если изменений нет, это означает, что оно не затронуто и никаких рекомендаций не требуется.
2.4 Обратная трассировка двусторонней трассировки
В процессе исследований и разработок разработчик извлекает ветку Feature_xxx из мастера для разработки. После завершения разработки выполняется самотестирование, выбрасывается дым, а затем отправляется на тестирование.
Содержание теста включает новые требования, а также оценку влияния теста на развитие на основе личных способностей, опыта и деловых знаний.
Эти методы оценки не являются объективными, не имеют подкрепления данными и склонны к пропускам или расширению объема теста.
2.4.1 Цели
На основе изменений в коде разработки, включая изменения SQL, рассчитываются все затронутые интерфейсы Dubbo и Rest-интерфейсы, а также находятся соответствующие варианты функционального использования.
2.4.2 Процесс реализации
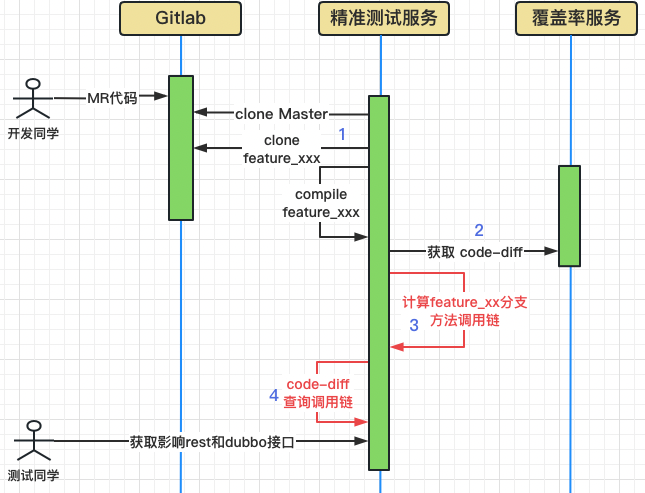
Во-первых, после разработки кода MR тщательно протестируйте главный код ветки клона службы, а также клонируйте и скомпилируйте код ветки, чтобы подготовиться к следующему этапу получения различий кода.
Во-вторых, чтобы получить разницу между кодом основной ветки и кодом тестовой ветки, помимо изменений в коде JAVA, учитываются также изменения SQL, и эти изменения также повлияют на бизнес.
Затем ASM анализирует байт-код класса кода тестовой ветки и генерирует цепочку вызовов статических методов для каждого класса. ASM предоставляет нам удобную возможность обработки байт-кода.
Чтобы получить доступ к классам в файле классов, вам необходимо переопределить метод visit() класса ClassVisitor ASM.
Чтобы получить доступ к методам в файле класса, вам необходимо переписать метод visitMethod() класса ClassVisitor ASM, чтобы проанализировать взаимосвязь вызовов методов.
Чтобы получить доступ к аннотациям в файле класса, вам необходимо переопределить метод visitAnnotation() класса ClassVisitor ASM.
По сравнению с интерфейсом Rest, чтобы получить путь запроса, путь запроса записывается в аннотации класса + метода, поэтому вам необходимо проанализировать аннотацию класса, чтобы получить путь запроса.
Например, такие аннотации, как @RestController и @Controller в Spring.
По сравнению с интерфейсом Dubbo, чтобы узнать поставщиков и потребителей услуг Dubbo, вам также необходимо проанализировать аннотации, такие как @DubboService и @Service.
При идентификации интерфейса Dubbo следует отметить два момента:
- Аннотация @Service должна быть совместима с версиями Dubbo apache(3.x) и Alibaba(2.x).
- Совместим с методом конфигурации XML Dubbo.
Наконец, запросите цепочку вызовов статического метода через код различия, чтобы получить затронутую цепочку вызовов, а затем проследите ее до входа в цепочку вызовов, а именно до интерфейса Dubbo и интерфейса Rest.
2.4.3 Взаимодействие с платформой
При тестировании вам нужно всего лишь заполнить адрес Git и тестовую ветку приложения, участвующего в процессе тестирования версии, нажать кнопку и подождать несколько минут, чтобы получить результаты.
Шаг 1. Добавьте основную информацию Git и нажмите «Выполнить».
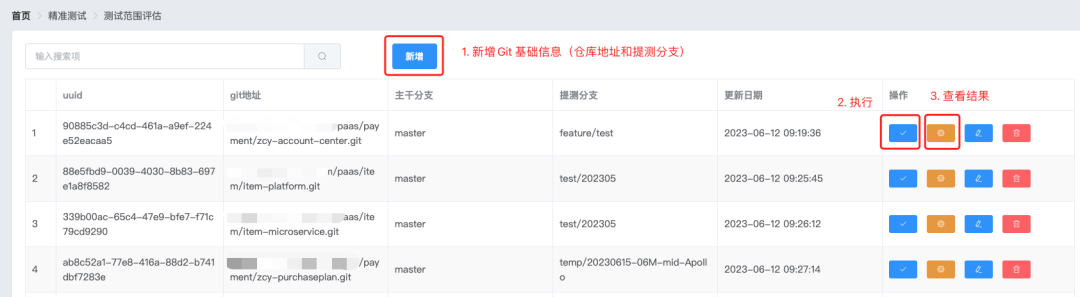
Шаг 2: Проверьте результаты
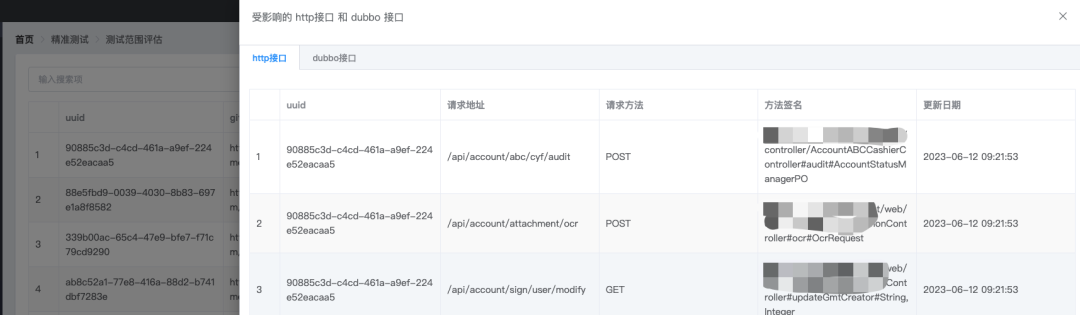
В настоящее время мы получили затронутый интерфейс Dubbo и интерфейс Rest. Мы все еще рассматриваем стратегию установления связи между интерфейсом и тестовым примером.
Мы надеемся, что рассчитанный интерфейс Dubbo и интерфейс Rest смогут напрямую генерировать наборы вариантов использования регрессии, напрямую выполнять автоматизацию интерфейса и сосредоточиться на тестировании новых функций.
Есть несколько моментов, которые необходимо объяснить в отношении цепочки вызовов, анализируемой с помощью статического кода:
- Поскольку анализ представляет собой статический код,такнапример, полиморфизм、динамический прокси、aop Для этого требуется кодruntimeизтуниспользоватьцепьв. настоящий момент не может быть распознан и его необходимо объединить с Динамической цепочка вызовов для анализа.
- При анализе следует использовать статический код, полученный из метода, цепочку настройки использования, аналогичную статическому тесту.,Недостаточно точно,Его также необходимо совместить с Динамической цепочка вызовов, для упрощения используйте метод объединения динамических и статических вызовов.
- Статический анализ — это анализ одного приложения.,На данный момент речь не идет о транс-следуетиспользоватьиспользовать,Перекрестный ответиспользовать Его также необходимо совместить с Динамической цепочка вызовов выполняет анализ всей ссылки.
3 Покрытие
Во время тестирования используйте покрытие кода Jacoco, чтобы подсчитать, какой объем кода покрывается тестом. Обратите внимание, что это статистика того, сколько кодов было протестировано, и она не может доказать достоверность результатов тестирования.
Если в самом коде есть ошибка, Jacoco сам не сможет ее найти. Требуется тестирование для проверки бизнес-логики на основе бизнес-сценария.
Однако Jacoco может сказать нам, сколько кода было протестировано, а что не было протестировано, можно проанализировать и нужно ли выполнять дополнительные тестовые примеры.
В рамках микросервисной архитектуры одно и то же приложение будет развернуто на разных узлах, а запросы будут отправляться на разные узлы в соответствии с определенными стратегиями. При сборе данных о покрытии необходимо учитывать все узлы.
На всем этапе исследований и разработок используются различные типы испытаний для обеспечения качества продукта. Чтобы гарантировать, что собранные данные о покрытии являются максимально полными, данные о покрытии необходимо собирать на разных этапах исследований и разработок.
Native Jacoco поддерживает только объединение данных покрытия одного и того же кода и не поддерживает объединение данных покрытия изменений кода.
То есть, если код изменен разработчиком в процессе тестирования, две данные о покрытии, собранные до и после модификации, не могут быть объединены.
Результатом слияния всегда являются самые последние собранные данные о покрытии, а данные о покрытии до изменения кода будут отброшены.
Подводя итог, я считаю, что студенты-испытатели могут понять болевые точки неполного сбора данных о покрытии в текущей гибкой модели:
- Несколько узлов для одного приложения (Несколько экземпляров) из Покрытиеданные Как совместитьи。
- Различные этапы исследований и разработок (единица, дым, система, регресс) из Покрытиеданные Как совместитьи。
- обзор Отправлять после каждого изменения кода,Как объединить несколько развертываний.
3.1 Статистика покрытия
Объединив различные платформы внутри компании, мы создали платформу покрытия для сбора данных о покрытии и получения отчетов в процессе тестирования. Конкретный процесс выглядит следующим образом:
первый,clone&compile master и ветка тестирования, мастер После загрузки кода ветки весь цикл версий фиксируется, что позволяет избежать путаницы данных, вызванной кодом разработки.
Затем платформа CI/CD сохраняет данные о покрытии. Поскольку приложение будет развертывать несколько экземпляров, мы также поддерживаем объединение данных о покрытии нескольких экземпляров для создания окончательного файла покрытия.
Далее, поскольку мы выполняем инкрементное покрытие кода (конечно, мы также поддерживаем полное покрытие), мы берем код разницы между основной и тестовой ветвями.
Наконец, используйте исходный код src, байт-код класса и исполняемый файл для создания отчета.
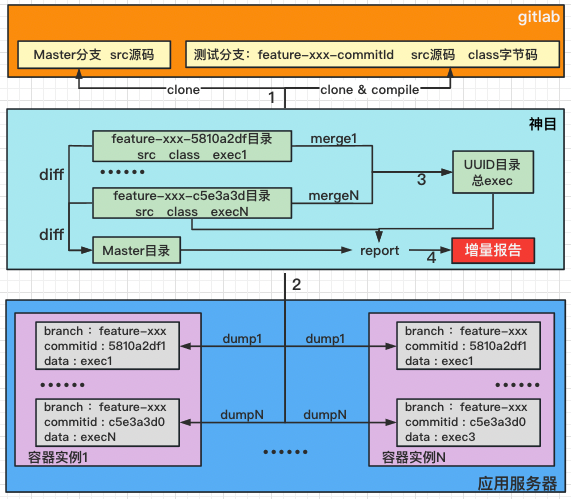
Самый важный момент здесь — если код изменится, мы будем его разрабатывать каждый раз. commit код clone&compile и сбросить свои Покрытые данные для объединения,
Наконец используйте последнюю версию commit коди master Выполните дополнительную статистику покрытия.
3.2 Отчет о покрытии
Чтобы снизить порог,Мы постарались максимально быстро заполнить статистику, не увеличивая при этом рабочую нагрузку.,Получить отчет о закрытии.
При разработке первой версии она не была подключена к платформе CI/CD, что только увеличивало нагрузку на студентов-испытателей.
собирать Покрытиенеобходимая информацияизкод Git информация, информация о ветке, фиксация Студентам-испытателям приходится заполнять информацию вручную, что не очень удобно для пользователя.
так Мы разбираемся Понятновесь процесс,Провести весь процесс оптимизации,В конце концов, студентам от тестирования оптимизации до завершения статистики нужно всего два шага:
3.2.1 Инъекционный агент
Благодаря поддержке платформы CI/CD мы можем внедрить агент одним щелчком мыши. Нам нужно только передать jar-файл агента и параметры платформе CI/CD, и платформа поможет нам создать образ для агента и завершить его. инъекция.
3.2.2 Создание отчетов
Собственный Jacoco должен выполнять операции дампа и слияния отдельно перед созданием отчетов. Мы выполнили эти шаги вместе.
Просто начните с CI/CD Получить платформу Git информация, информация о ветке, фиксация информацию, а затем выполнить свалка, опять merge ,наконец отчет, вы можете получить отчет о покрытии одним щелчком мыши.
Конечно, здесь еще есть простор для оптимизации. Например, нам сейчас нужен исходный код и скомпилированный байт-код в процессе подсчета данных о покрытии.
Мы клонируем или извлекаем исходный код напрямую и компилируем его локально после получения исходного кода.
Потенциальная проблема здесь в том, что компиляция занимает очень много времени и ресурсов. После тестирования, в основном на машине 4C8G, когда четыре приложения компилируются одновременно, загрузка ЦП взлетает до 95%.
Наше решение этой проблемы — напрямую использовать jar, скомпилированный на платформе CI/CD, и напрямую распаковать его в файл байт-кода.
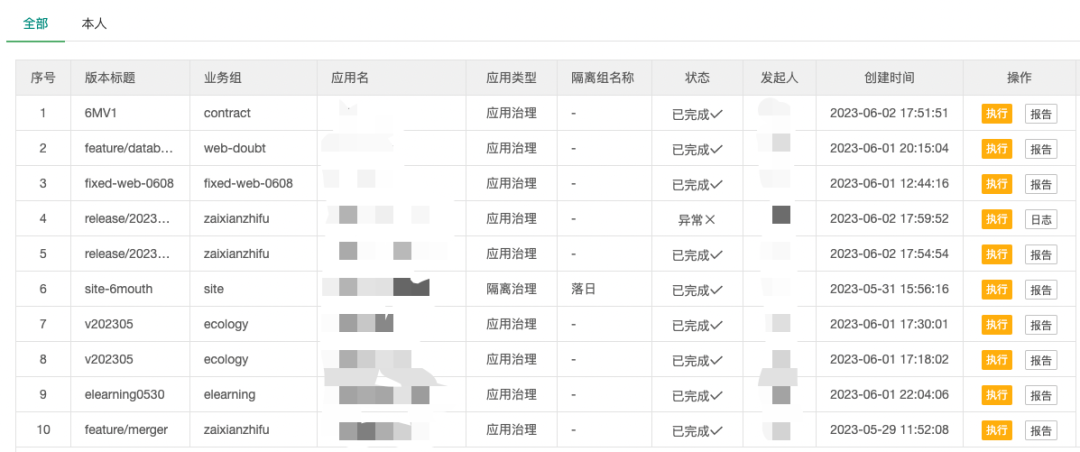
Ниже представлена платформа покрытия. После того, как тест внедрит агент в платформу CI/CD, вам нужно будет заполнить всего несколько полей (в центре внимания — имя приложения и среда управления), чтобы собрать отчет о покрытии.
3.3 Оптимизация отчета
Отчет Жакоко Роднойиз существования не очень читабелен,Одноклассники по тестированию на самом деле просто хотят знать, какие из них охвачены,Какой код не распространяется,
Мне не совсем понятны показатели цикломатической сложности и покрытия инструкций, и я не обращаю на них особого внимания. Поэтому мы оптимизировали отчет следующим образом:
- Удалить элементы индикатора цикломатической сложности Cxty и инструкции.
- Воля пропустите% Изменить на покрытое% и китайское покрытие дисплея
- Используйте трехмерную кольцевую диаграмму, чтобы показать конкретный охват каждого индикатора.
Эффект следующий:
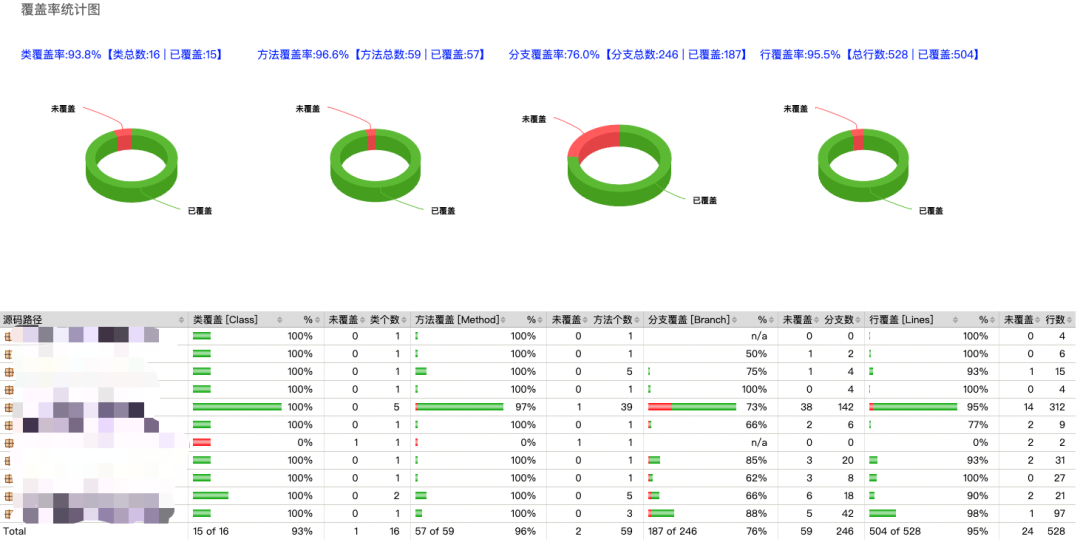
В будущем мы продолжим оптимизировать отчет для облегчения интерпретации результатов тестирования и разработки, включая следующее:
- Исходная кодовая страница отчета для идентификации,Какой код новый из,Какой код изменен из.
- существование добавлена исходная страница отчета в области тестирования и разработать рабочий механизм для облегчения бизнес-интерпретации и варианты использования Пополнить。
4. Подведение итогов и планирование
До сих пор мы выполняли обратную трассировку, то есть оценку объема тестирования, чтобы решить проблему. Что измерять из проблемы, также сделал дополнительный код Покрытиеиспользовать для ее решения Как прошел тест? проблема.
В будущем, с одной стороны, мы продолжим совершенствовать и оптимизировать существующие возможности, а также будем совершенствовать всю систему прецизионного контроля, включая следующее:
- Улучшите прямую прослеживаемость в точной тестовой системе.,Дополняющая способность,дальнейшее разрешение Что измерять,Помогите студентам-тестировщикам выполнить тест максимально эффективно.
- Внедрите эти возможности в процесс исследований и разработок,Постарайтесь выполнить тест точно, не воспринимая ничего во время процесса.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
