[Tianqiong OS] Виртуальная таблица: новая парадигма интеграции озер и хранилищ нового поколения, которая поддерживает чрезвычайно быстрые запросы
Предисловие
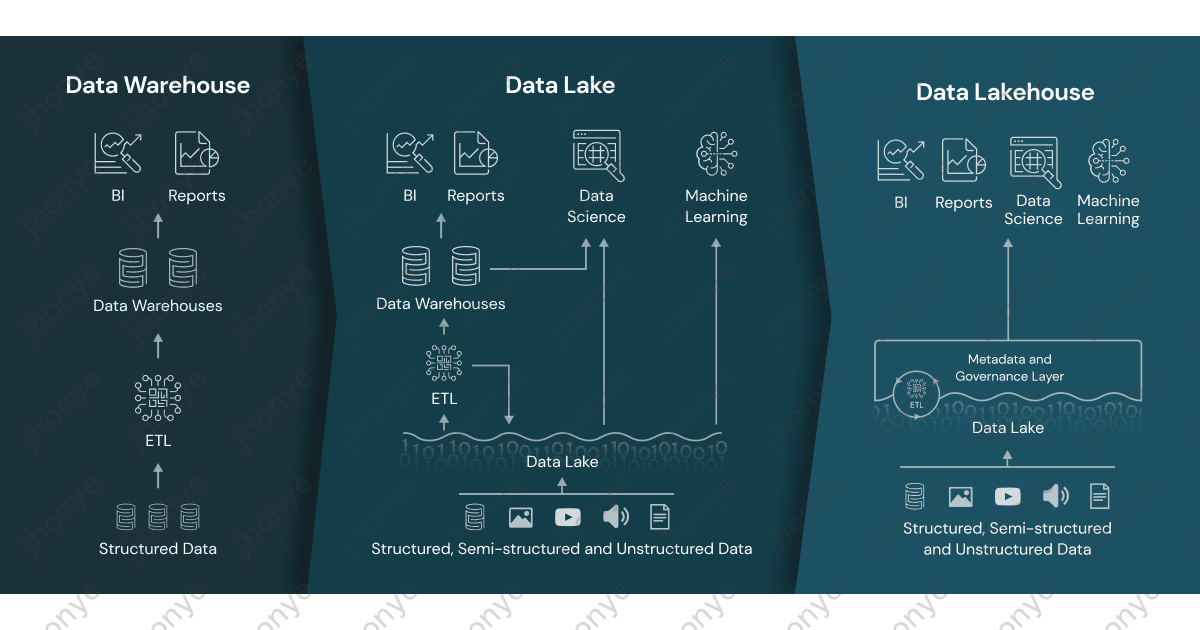
Lakehouse — популярная в последние годы концепция больших данных. Она объединяет озеро данных (Data Lake) с. Lake)ихранилище данных(Data Склад), чтобы предоставить предприятиям более мощное и гибкое решение для управления данными. Гартнер В описании технологической кривой Lakehouse является очень важной технологией. Ожидается, что она выйдет на период плато через 2–5 лет, а в Китае – от 5 до 10 лет.
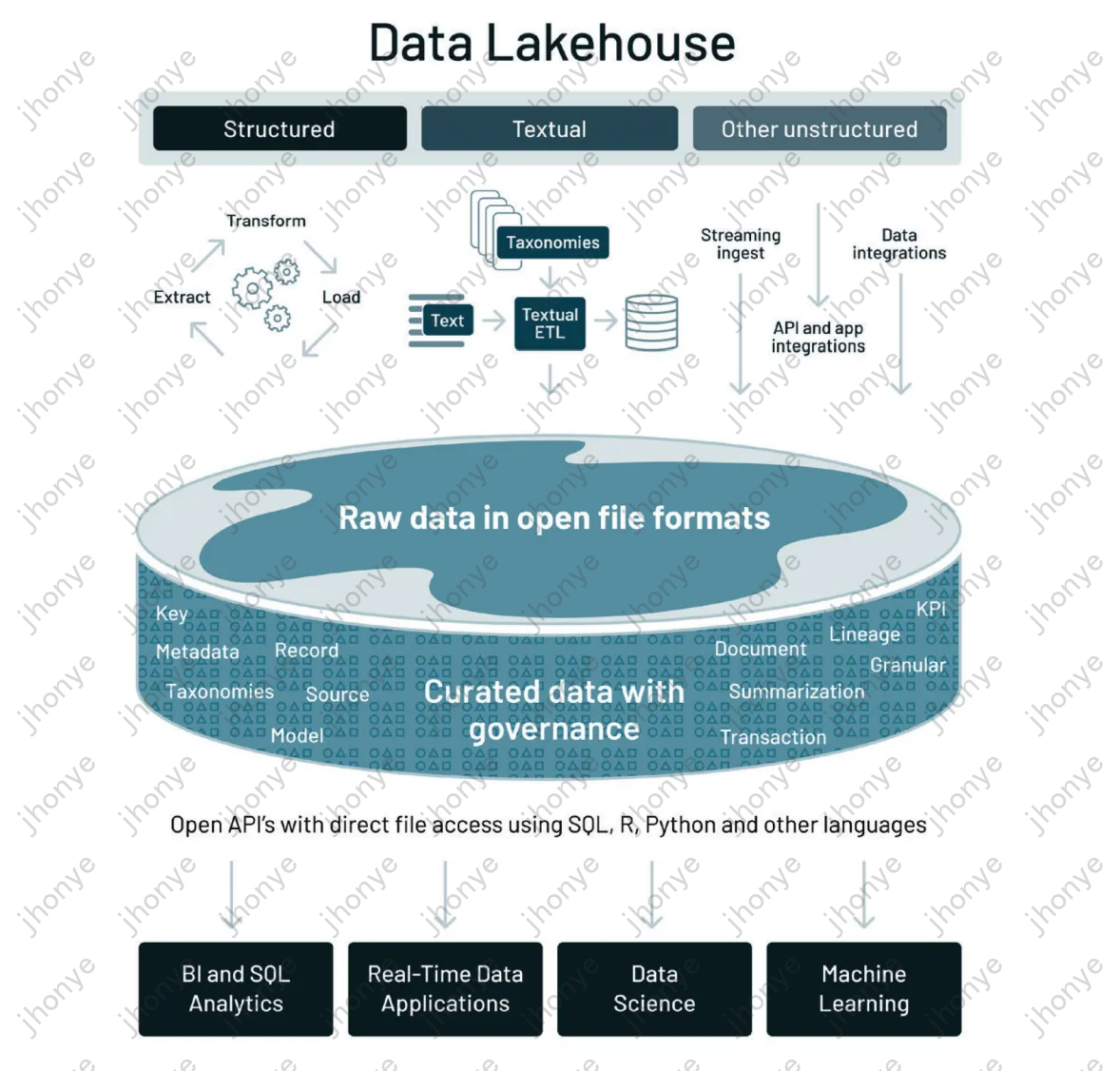
Как показано на рисунке 1, интегрированное озеро и хранилище — это решение, которое позволяет одновременно реализовать множество сценариев с помощью набора архитектур. Несколько источников данных управляются унифицированным образом, а услуги предоставляются через унифицированные входы и выходы. поддержка анализа SQL, онлайн-приложений, анализа данных, машинного обучения и других сценариев. Сегодня существует множество интегрированных продуктов для озерных складов. Все они имеют превосходную архитектуру и технологии. Ниже представлены два основных направления интегрированных озерных складов:
Интегрированная архитектура озера и склада на основе озера данных, представленного DeltaLake [1]
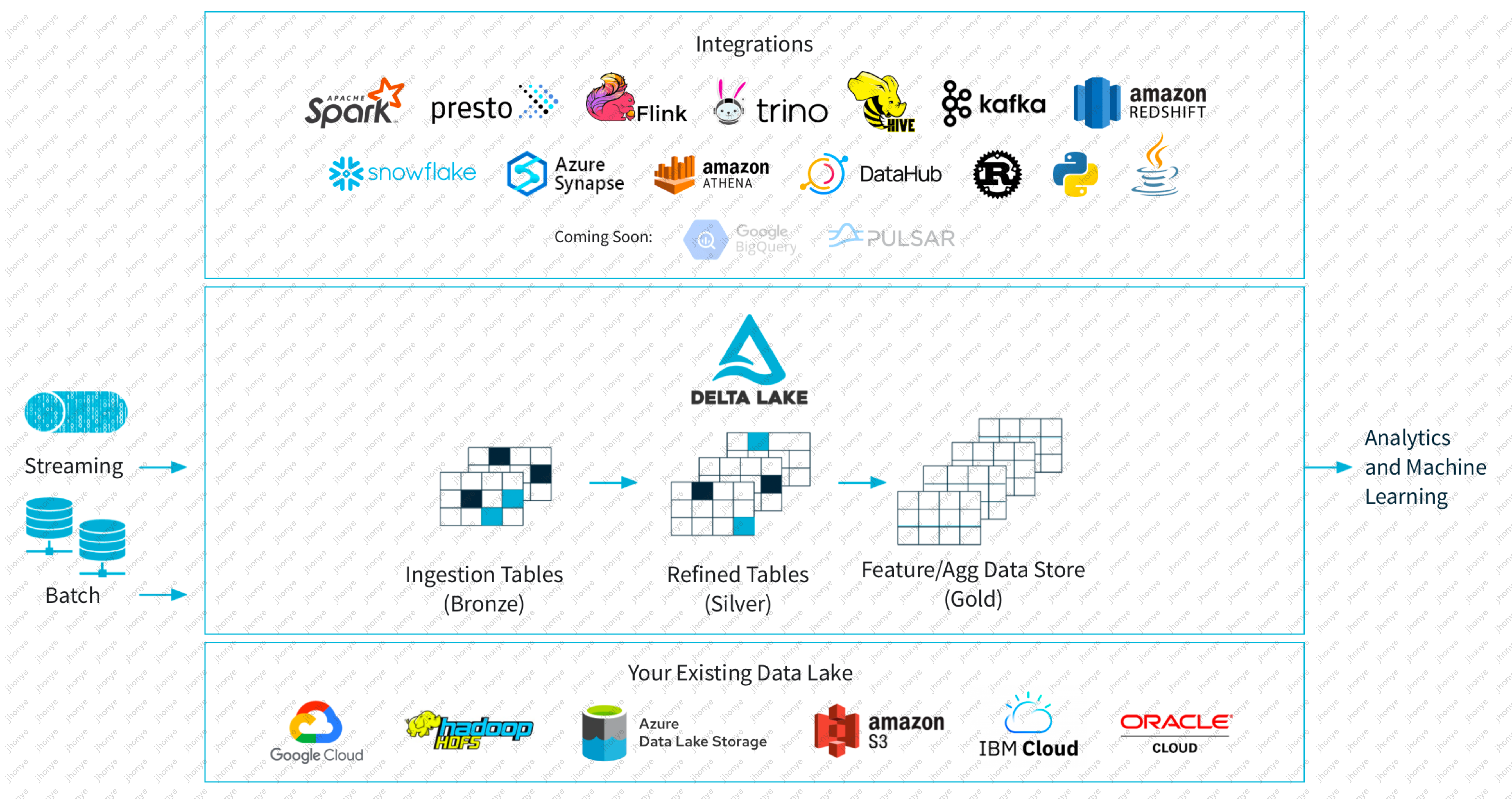
Как показано на рисунке 2, DataLake служит центральным озером данных, собирая потоковые и пакетные источники данных слева и предоставляя возможности анализа и машинного обучения справа. В настоящее время многие известные поставщики облачных технологий поддерживают DeltaLake, который является открытым. среда хранения, поддерживающая стыковку. Все распространенные в отрасли вычислительные механизмы, такие как Spark, Presto и т. д., объединены в систему, подобную базе данных.
Как показано на рисунке 3, схема интегрированной архитектуры озера и хранилища Databricks. Движок потоковых пакетных вычислений в основном опирается на Spark, а хранилище основано на DeltaLake. Конечно, Databricks не просто сшивает, а сделал множество оптимизаций. для Spark и разработала движок C++ Native, а также проделала большую работу по интеграции для достижения текущего состояния интеграции озера и хранилища. Кроме того, Databricks также активно использует искусственный интеллект и поддерживает множество сценариев искусственного интеллекта с текущей оценкой в 43 миллиарда долларов США; .
на основеозеро данныхиз Озеро и склад интегрированывозник из хранилища озер,Затем поддержите сцену хранилища данных с более высокой производительностью.,Например, предварительная организация данных、индекс、Кэширование и т. д.
Интегрированная архитектура озера и склада на основе хранилища данных, представленного Snowflake [2]
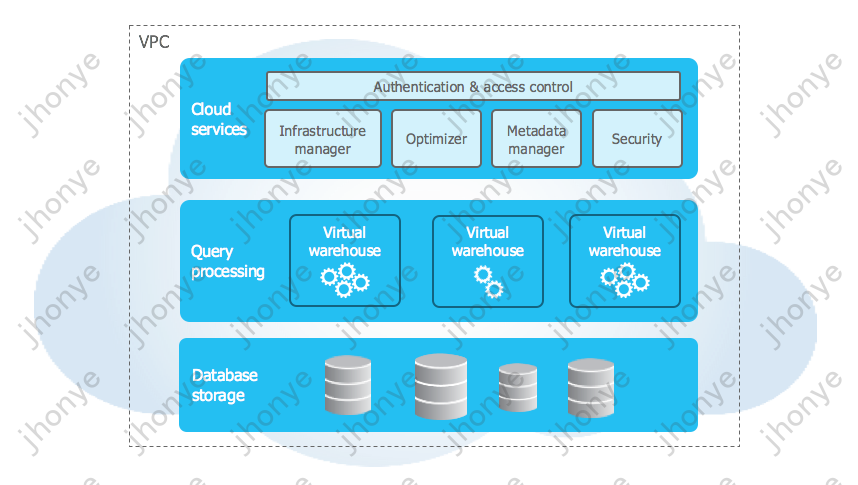
Как показано на рисунке 5, это архитектурная схема Snowflake, в которой Cloud Services является резидентом, Запрос Processing Гибкая, База данных Storage почти бесконечен. В настоящее время в отрасли имеется множество озер данных/хранилищ. данные используют упругий расчетресурсизплан,Эффект снижения затрат и повышения производительности по-прежнему хорош в большинстве сценариев, в то же время он имеет практически неограниченное облачное хранилище и поддерживает различные другие форматы с открытым исходным кодом.,Snowflake также можно использовать в качестве озера данных.
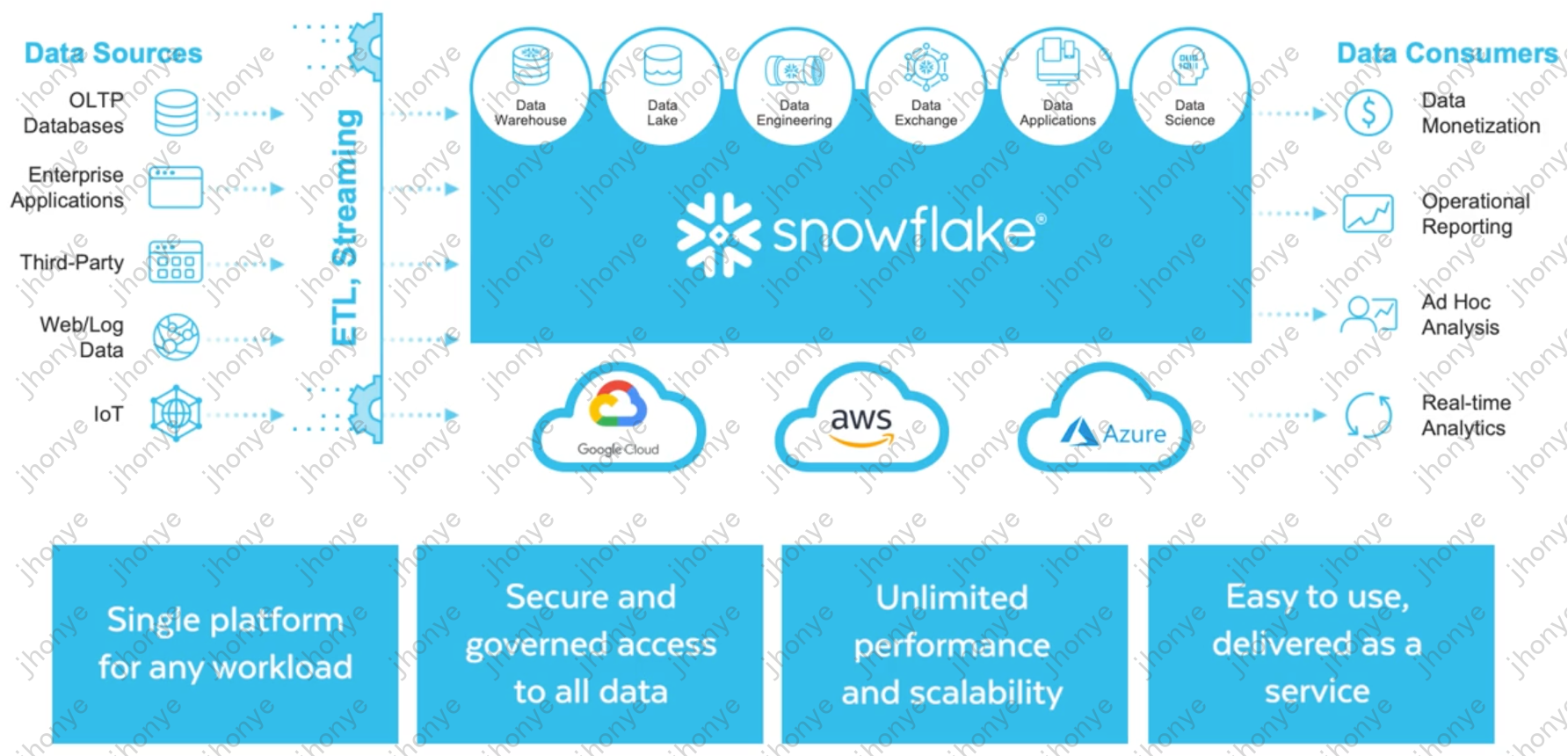
нравиться Рисунок 6,Snowflake — центральное хранилище данных (озеро и склад в одном),Объедините источники данных слева,Предоставляет возможности обслуживания справа; поддерживает развертывание несколькими поставщиками облачных услуг;,Способность поддерживать разнообразные нагрузки аналогична отечественному HSAP и обладает высокой производительностью.,Вся экология и система очень полны и удобны для пользователя.,Пиковая оценка почти в 40 миллиардов долларов.,Сегодня близко16 миллиардов Доллар(Кажется, это не сделаноAIВ настоящее время он не пользуется популярностью у инвесторов.)。
на основехранилище Интеграция озера данных и хранилища данных начинается с преимуществ высокопроизводительных хранилищ, а затем расширяет открытость для поддержки большего количества других форматов хранения. Чтобы сбалансировать затраты, оно поддерживает разделение хранения и вычислений, упругий. расчетждать。
Так какова же тенденция следующего поколения по интеграции озер и складов?
развивался с годами,Многие концепции больших данных и возможности инфраструктуры имеют множество расширений.,В замешательстве из-за Хуцанаиз Вы можете прочитать этостатья:Как понять интеграцию озера и склада? [5]
«Вместе долго надо делить, долго делить надо объединять» — старая пословица, которая передает важную философскую концепцию: развитие вещей часто циклично, и слияния и разделения неизбежны. За последние несколько лет развития больших данных структура также была разделена и объединена. Большинство компаний имеют большой «исторический долг». Вышеупомянутые два продукта являются лучшими в отрасли, но у этих двух архитектур все еще есть некоторые проблемы с неполной поддержкой сцен, а стоимость переноса «исторического долга» на эти продукты немалая. В настоящее время, после непрерывной итерации этих интегрированных озерных и складских продуктов, они сами также будут иметь «исторический долг», который не позволит архитектуре развиваться в лучшем направлении. В конце концов, придется разработать новый продукт. и может потребоваться еще одна миграция данных.
В последние несколько лет центральное хранилище основывалось на многомерном моделировании и решении проблем с хранилищами данных. данные очень популярны, в них загружаются все данные и хранится огромный объем (ЗБ) данных, но сейчас это центральное хранилище многих компаний отрасли; данные на одно-два поколения отстают от основных технологий,Когда необходимы итеративные обновления, снижение затрат и повышение эффективности, мы сталкиваемся с затруднениями из-за невозможности миграции. Тогда, даже если потребовалось немало усилий, чтобы переехать в вышеупомянутый самый продвинутый «Central Lake Warehouse Integrated»,,Нет ли необходимости обновляться в будущем? Во многих случаях требований бизнеса на самом деле достаточно.,Модернизация технологий, снижение затрат и повышение эффективности весьма привлекательны для сотрудников бэк-офиса.,Но это бесполезно для сотрудников стойки регистрации.,Их сложно продвигать без достаточной «привлекательности».
Основываясь на вышеизложенных соображениях, мы пришли к выводу, что принятие изменений является лучшим выбором в настоящее время. Так что же представляет собой интегрированная архитектура «озеро-склад» следующего поколения? Данные, появившиеся за последние два года Концепция Fabric довольно популярна за рубежом, а также станет популярной внутри страны, и ее можно будет использовать в качестве нашей ссылки. Создав Виртуализацию данныхслой[3]Проверьте днослойгетерогенныйизвычислить、Хранитсявиртуализация,Обеспечить единый вход/выход, все рабочие процессы пользователей находятся в одной системе;,Вы можете мигрировать в любое время в соответствии с бизнес-приоритетами.,Поток данных станет более плавным: от неэффективного к эффективному,Эффективность технологических обновлений и итераций также будет выше.
Узнать больше Data Fabric пожалуйстассылкастатья:Следующее поколение архитектуры технологий больших данных: Data Fabric?
По сравнению с двумя вышеупомянутыми превосходными интегрированными архитектурами озер и хранилищ в архитектуре Data Fabric по-прежнему отсутствуют два ключевых момента:
- Возможность интеграции разнородных фреймворков:Отсутствие единых разрешений для внешних источников данных、Унифицированное управление данными практически не реализовано.,Плохая совместимость с SQL.,Он просто поддерживает внешние источники данных и поддержку внешнего вида.
- Уровень виртуализации:В сочетании с гетерогенной структурой, отсутствие активной коллекции、Генерация глобальных метаданных,В основном прозрачен для пользователей,подвержен ошибкам,Много ручной работы.
После перехода к технической архитектуре Data Fabric Tianqiong Big Data также абстрагирует способность уровня виртуализации интегрировать разнородные структуры в хранилищах и вычислениях. Поскольку в настоящее время мы интегрируем механизмы, подобные базам данных, мы используем «Tianqiong OS-Virtual Table» для унификации таблиц. всех двигателей.
Ключевые слова в этой статье:Небесные большие данные、Тяньцюн ОС、Data Фабрика, архитектура больших данных, интегрированное озеро и склад, защита от неоднородности, Виртуализация данных、хранилище данныхобновление、Чрезвычайно быстрый запрос、Сценарий экстремальной скорости отчета、Benchmark、SSB、TPC-H、OLAP、Просмотр/материализованный вид、интеграция данных、федеративный запрос
Что такое виртуальная таблица ОС Tianqiong?
Виртуальная таблица ОС Tianqiong — это особый метод реализации уровня виртуализации архитектуры больших данных Data Fabric, именуемый в дальнейшем виртуальной таблицей.
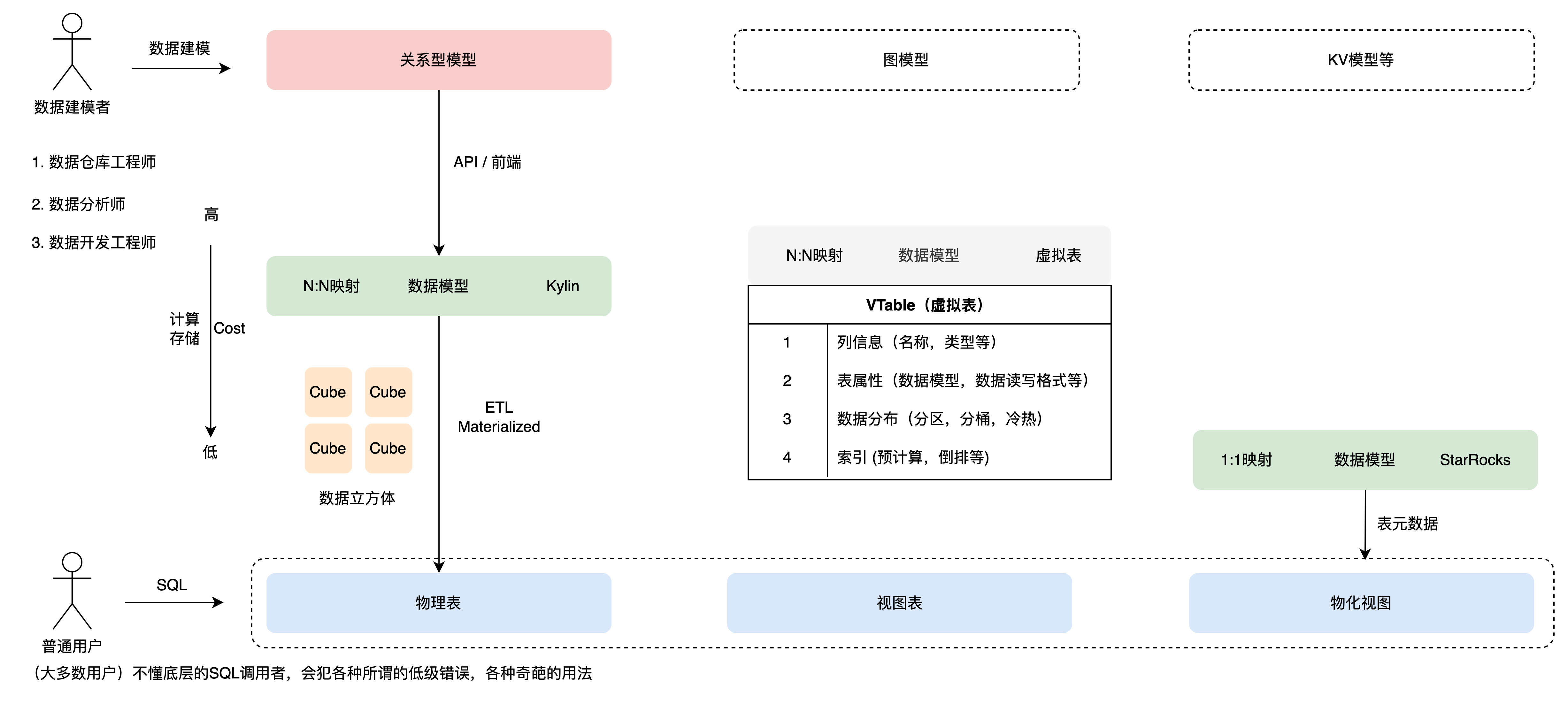
Как показано на рисунке 7, в отрасли существует множество моделей данных, определяемых продуктом, которые используются для описания атрибутов данных и связей. Реализованные в настоящее время виртуальные таблицы также имеют аналогичную логику.
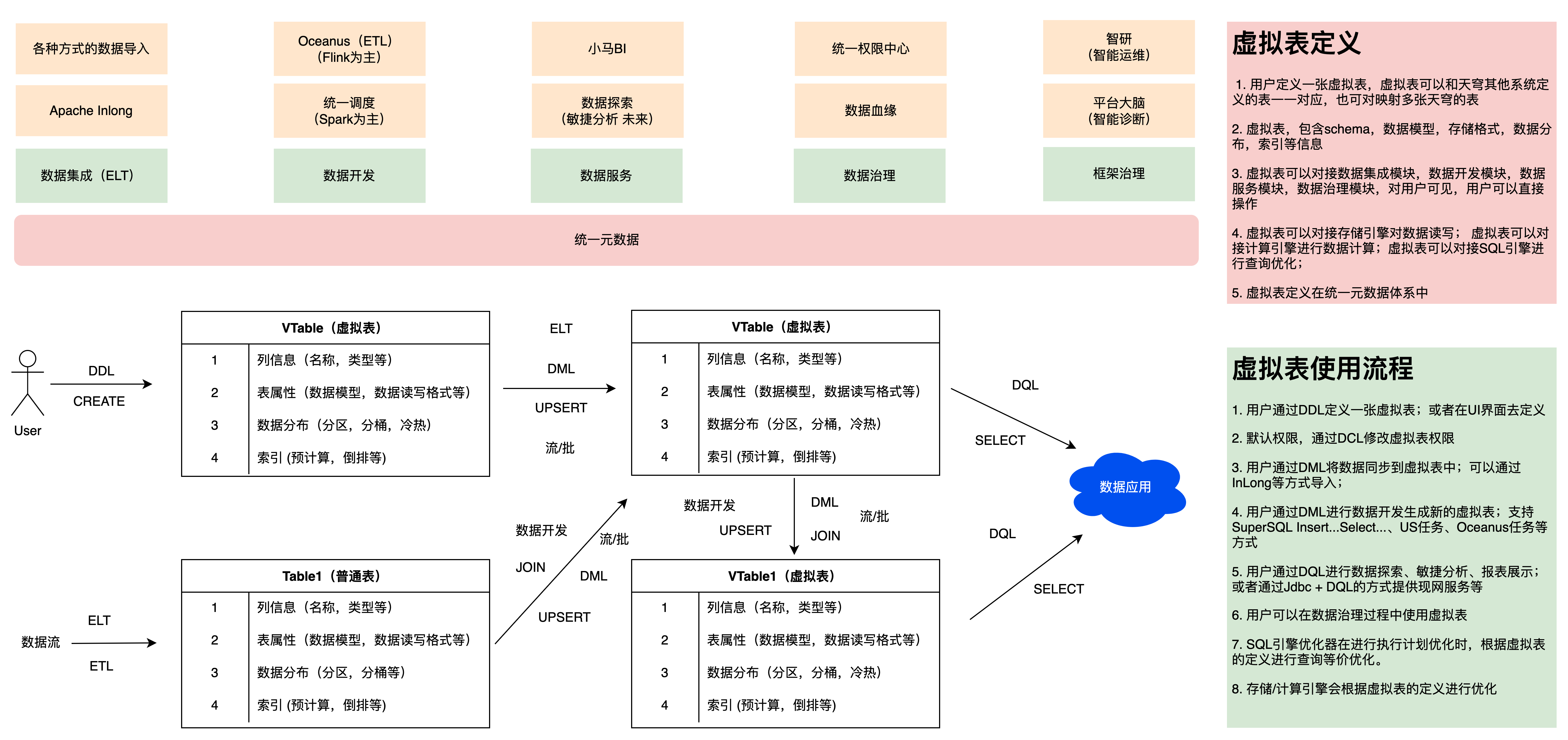
нравиться Рисунок 8,Пользователи могут использовать виртуальный стол так же, как таблицу хранилища данных Sky Dome.,виртуальный стол защищает гетерогенные вычисления и гетерогенные хранилища,Обеспечивает унифицированный вход/выход SQL-запроса.
В настоящее время пользователи могут ставить виртуальный стол данныхизновыйизмодель стола Приходитьиспользовать,В настоящее время пользователи должны указывать ключевое слово VIRTUAL при создании таблицы. Мы обнаружили, проанализировав SQL пользователя,Пользователи имеют четкие ожидания относительно стабильности своих запросов.,Вот несколько примеров бизнес-сценариев, в которых пользователи балансируют производительность и затраты:
- Если требуется, чтобы ответ на запрос 99-го процентиля был на уровне миллисекунд, будет использоваться непосредственно механизм OLAP (StarRocks, Hemers и т. д.). (Гетерогенность + чрезвычайно высокая стоимость)
- Если требуется, чтобы ответ на запрос 99-го процентиля был в течение 10 секунд, будет использоваться такая архитектура, как режим предварительного нагрева Presto + Alluxio. (изоморфный + высокая стоимость)
- Если пользователя не слишком беспокоит время ответа на запрос, для адаптивного запроса будет использоваться автоматический режим. (Высокая производительность + низкая стоимость)
- Если у пользователя есть какие-либо требования ко времени ответа на запрос, будет указан режим Presto и для запроса будет использоваться эластичный кластер Presto. (Высокая производительность + средняя стоимость)
- Если это длительная и трудоемкая работа, такая как ETL, Spark будет напрямую предназначен для расчета. (Высокая стабильность + низкая стоимость)
Поэтому в настоящее время пользователям необходимо удовлетворять конкретные потребности, указывая соответствующую модель таблицы в DDL.,Например, если вам нужна максимальная производительность запросов, выберите виртуальный стол по умолчанию., если хотите низкую стоимость, выбирайте Тяньционхранилище данные нативные часы, если вы хотите добиться высокой производительности и низкой стоимости, выбирайте адаптивный горячий и холодный виртуальный стол (дальнейшую поддержку мы будем дальше абстрагировать и улучшать в последующей эволюции виртуальный); способность стола достичь полностью адаптивного баланса производительности и стоимости.
Преимущества:абстрактныйвиртуальный столслой,Позвольте пользователям не беспокоиться о базовой гетерогенной системе.,Сосредоточьтесь на своем бизнесе,Повышение фоновой адаптивной эффективности,Для достижения цели снижения затрат и повышения эффективности.
Инновационные моменты: нижний слой щита + единая семантика + Интеграция + база данных + Адаптивная оптимизация.
Заявлены патенты на:《Что-то вродена основевиртуальный столсуществоватьхранилище данныхиспользуется в системе Неоднородность экранаразницаи Ускорение запросовизметод》、«Метод ускорения запросов к гетерогенным горячим и холодным хранилищам за счет интеграции механизма SQL и сопоставления метаданных»
Какова текущая производительность виртуальных столов?
Никакой специальной настройки параметров, по сравнению с обычными механизмами OLAP.
SSB Benchmark
Подготовка данных:
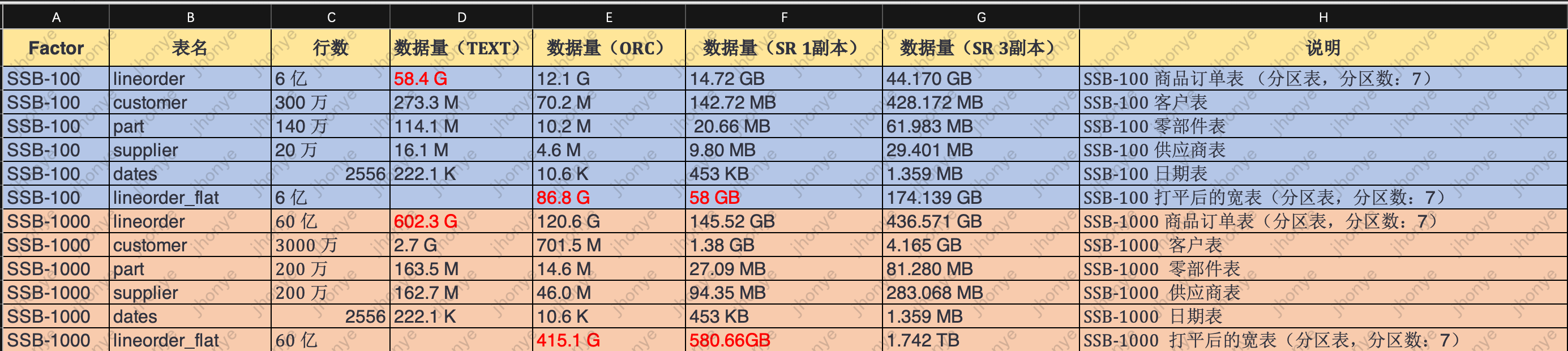
Данные испытаний в широкой таблице 600 миллионов:

проиллюстрировать:
- Когда нагрузка на кластер виртуальных таблиц невелика, производительность запросов к одной таблице аналогична ответу на основной запрос OLAP в сообществе.
- В условиях высокого параллелизма и высокой нагрузки ответ виртуальной таблицы составляет не более 2 секунд.
- Приведенные выше данные показывают, что виртуальные таблицы могут легко обрабатывать сценарии отчетов с объемами данных запроса в 600 миллионов уровней.
Данные испытаний в широкой таблице на 6 миллиардов:
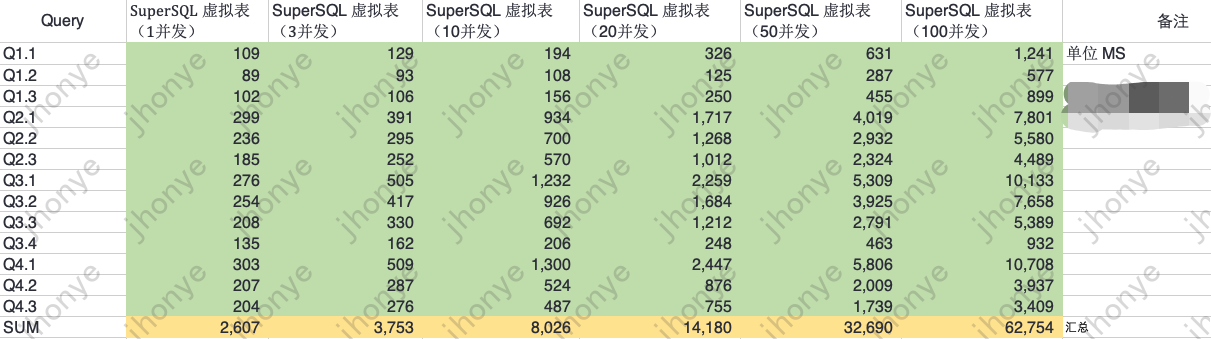
проиллюстрировать:
- Когда нагрузка на кластер виртуальных таблиц невелика, производительность запроса одной таблицы с десятикратным объемом данных (6 миллиардов) в основном ниже 300 мс.
- В условиях высокого параллелизма и высокой нагрузки время ответа на 6 миллиардов запросов составляет в среднем не более 6 секунд.
- Приведенные выше данные показывают, что виртуальных таблиц достаточно для обработки сценариев отчетов с объемом данных запроса в 6 миллиардов уровней.
Тестовые данные модели 600 миллионов звезд (многотабличное соединение):
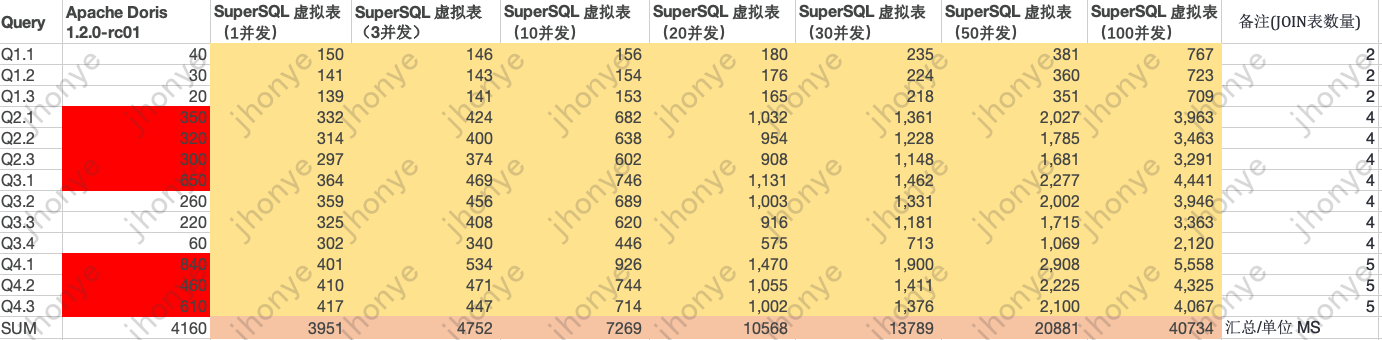
проиллюстрировать:
- Когда нагрузка на кластер виртуальных таблиц невелика, запросы JOIN для нескольких таблиц звездообразной модели выполняются на уровне миллисекунд, что сопоставимо с обычным OLAP.
- В случае высокого параллелизма и высокой нагрузки запрос JOIN многотаблицы звездообразной модели занимает в среднем менее 4 секунд.
- Приведенные выше данные объясняют виртуальный стол Отвечайте на запросы с легкостью Объем данныхсуществовать600 миллионовуровеньиз Гибкий анализ、Adhoc、витрина данныхАнализ запросовждатьсцена。
Тестовые данные модели 6 миллиардов звезд (многотабличное соединение):
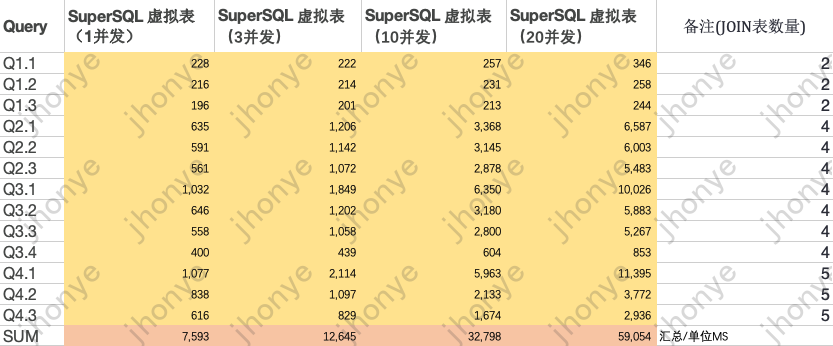
проиллюстрировать:
- Когда нагрузка на кластер виртуальных таблиц невелика, объем данных увеличивается в 10 раз (6 миллиардов), а запросы JOIN для нескольких таблиц звездообразной модели выполняются на уровне миллисекунд.
- В случае среднего параллелизма и высокой нагрузки объем данных увеличился в 10 раз (6 миллиардов), а многотабличный запрос JOIN звездообразной модели занимал в среднем менее 5 секунд.
- Приведенные выше данные объясняют виртуальный стол Также достаточно, чтобы ответить на запросы Объем данныхсуществовать6 миллиардовуровеньиз Гибкий анализ、Adhoc、витрина анализ запросов данных и другие сценарии.
TPC-H Benchmark
Подготовка данных:
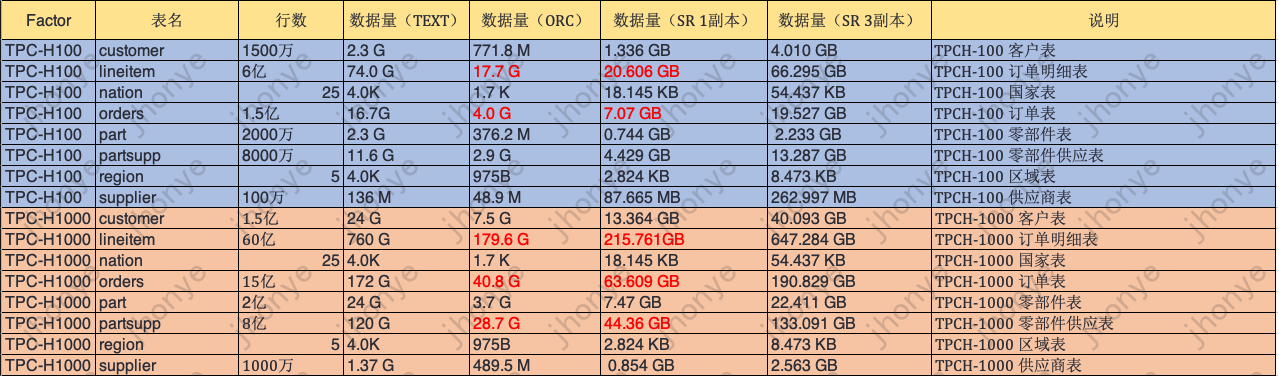
600 миллионов тестовых данных:
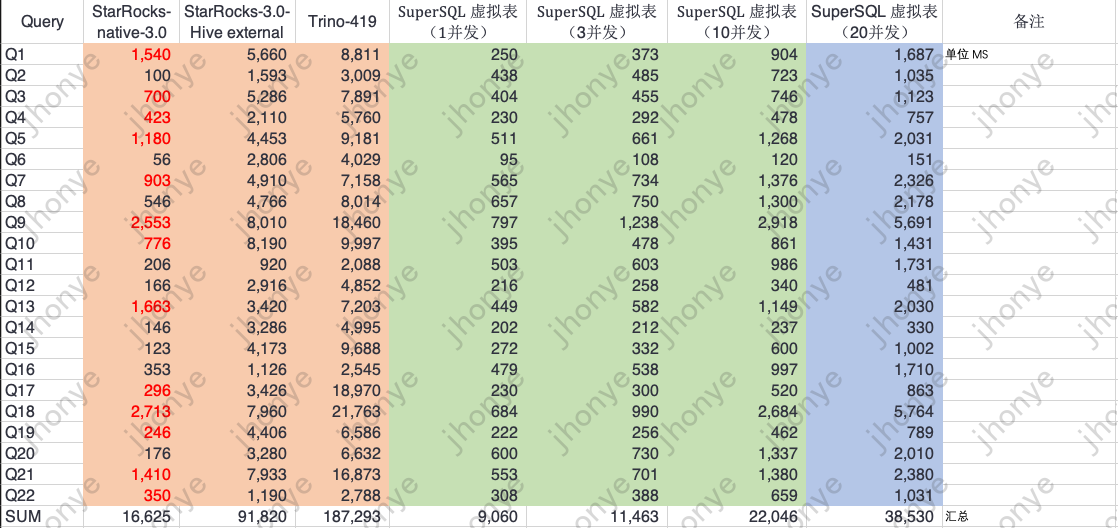
проиллюстрировать:
- Многотабличный запрос JOIN выполняется почти на уровне миллисекунд, что похоже на основной OLAP. Это намного лучше, чем StarRocks/Trino, напрямую запрашивающий данные озера.
- Приведенные выше данные объясняют виртуальный стол Отвечайте на запросы с легкостью Объем данныхсуществовать600 миллионовуровеньиз Гибкий анализ、Adhoc、витрина анализ запросов данных и другие сценарии.
6 миллиардов тестовых данных:
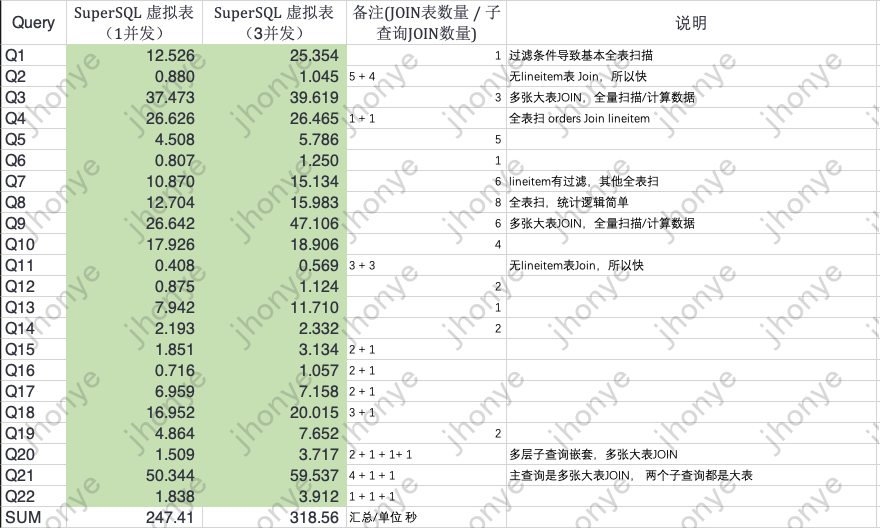
проиллюстрировать:
- Когда объем данных увеличивается в 10 раз (6 миллиардов), сложные многотабличные запросы JOIN могут быть возвращены почти за 1 минуту, но нагрузка на кластер высока и начинает влиять на другие запросы.
- Приведенные выше данные показывают, что виртуальные таблицы не рекомендуются для сложных многотабличных запросов JOIN с большими объемами данных и не рекомендуются для сценариев задач ETL.
Судя по приведенным выше сводным данным, виртуальные таблицы сопоставимы с основными механизмами OLAP.
В каких сценариях использование виртуальных столов весьма выгодно?
Подходит для сценария 1:хранилище данныхADSслой,Сценарий отчета,Онлайн-сервисы и т. д.
Визуализация данных является неотъемлемой частью процесса анализа данных и принятия решений.,Это делает данные более значимыми и информативными.,Помогите людям лучше понять и использовать ценность данных. Сейчас в отрасли существует множество продуктов для визуализации данных.,Среди них отчет BI является наиболее часто используемым инструментом.,промышленностьмейнстримизBIПродукты отчета включают в себяXiaoma BI (продукт BI для внутренней сети)、 Тенсент Облако BI、Alibaba Cloud Quick BI、Отчет Фанруана、Tableau и т. д., все они поддерживают такие функции, как настройка подключения к источникам данных, отображение отчетов, простые вычисления и т. д.
Когда пользователи подключают отчеты,Из-за традиционного ответа на запрос хранилища данных, стабильности и других причин,Данные будут предварительно обработаны и импортированы в такие платформы, как StarRocks и Mysql.,Затем выберите соответствующий драйвер для подключения. По таким причинам, как производительность отображения отчетов и т. д.,Как правило, не отображайте и не рассчитывайте слишком много данных.,Вторичные расчеты на основе этих данных также будут проходить быстрее.,Опыт использования по-прежнему в порядке.
Однако в описанном выше процессе все еще есть некоторые проблемы. Во-первых, пользователю необходимо подать заявку на экземпляр Mysql или кластер StarRocks. Во-вторых, пользователь должен управлять списком задач по импорту и экспорту данных. настройте его в приложении для создания отчетов, чтобы убедиться в правильности всего процесса; кажется, что затраты на ресурсы, затраты на управление и затраты на использование относительно высоки.
Так в чем же решение? Текущий пони БИ Поддержана настройка SuperSQL (Tianqiong Big Dataхранилище). унифицированный портал данных) в качестве источника данных для подключения к данным таблицы TDW, пользователям не нужно использовать хранилища Tianqiong Данные таблицы предварительно обрабатываются, а затем импортируются в данные (хранилища), такие как StarRocks и Mysql. Однако некоторые ограничения все же существуют. Например, запросы с количеством секций более 10 в настоящее время не поддерживаются, поскольку SuperSQL использует их. presto/spark + Небохранилище данныххранилище Таким образом предоставляются службы запросов. Если сканируется слишком много данных, ответ отчета может быть слишком медленным, и небо станет хранилищем. Хранилище данных обычно является общим, что в некоторых случаях может привести к тому, что время ответа на запрос превысит ожидания пользователя.
Как упоминалось выше, роль виртуальных таблиц в сценариях отчетности по-прежнему очень очевидна. Пользователи могут использовать Xiaoma BI. Стыковка небесного хранилища данныхвиртуальный стол,Наслаждайтесь производительностью ответа на запросы на уровне миллисекунд.,Нет необходимости передавать данные туда и обратно,Мне это тоже не очень нравится.Объем данных Влияние(6 миллиардов/1TBОбъем данныхиз Вы также можете запроситьсуществовать Возврат через миллисекунды);нравиться Если данные несуществоватьвиртуальный стол, вы можете использовать SQL (вставьте into ... select ...) метод импорта данных в виртуальные таблицы, который удобен, а также значительно повышается эффективность раннего и последующего обслуживания. То же самое касается и онлайн-сервисов.
Подходит для сценария 2: хранилище данных DW уровень, разработка данных, Adhoc, гибкий анализ и т. д.
промышленностьхранилище Архитектура данных обычно основана на многоуровневой конструкции. Данные сначала интегрируются в уровень ODS, а затем после предварительной обработки импортируются в уровень DW (ETL). Уровень DW можно подразделить в зависимости от сложности бизнеса. Наконец, предоставьте внешние услуги уровню ADS. витрина Концепция данных может охватывать уровень DW и уровень ADS. Пользователи, не занимающиеся разработкой данных, обычно используют соответствующую витрину в соответствии со своим бизнесом. данные для анализа и запроса.
Когда разработчики данных определяют, что определенная витрина данных или определенная модель данных будут часто запрашиваться или требовать быстрого ответа на запрос, они передадут ее в другие механизмы OLAP, такие как предварительные вычисления Kylin, широкотабличный запрос Clickhouse, StarRocks Adhoc и т. д. Однако эти гетерогенные механизмы вызывают множество проблем, таких как согласованность данных, несовместимость запросов SQL, применение ресурсов кластера и высокие затраты на управление.
Так в чем же решение? виртуальный стол。первыйвиртуальный столиззвездная схемаиз Отличная производительность запросов, связанных с несколькими таблицами,600 миллионы сцен в основном в миллисекундах, во-вторых виртуальный; стол и TDW интегрированы. Пользователям не требуется выполнять специальное обслуживание, и они могут использовать хранилище Sky Dome. данных Используйте ту же таблицувиртуальный стол Наконец, SQL имеет лучшую совместимость и удовлетворяет пользователей; частьSQL запрашивает все данные.
Конечно, если объем ваших данных меньше 6 миллиардов штук на 1 ТБ, весь процесс интеграции, производства, анализа и применения данных можно выполнять на виртуальных таблицах. В будущем мы будем балансировать затраты и производительность за счет адаптивного горячего и холодного доступа. решения для удовлетворения требований пользователей во всех сценариях.
Поддерживаемый сценарий 3: адаптивный к горячему и холодному режиму.
Хотя нынешняя виртуальная таблица очень хороша с точки зрения производительности, ее стоимость также относительно высока. Для большинства пользователей по-прежнему существует необходимость сбалансировать производительность и стоимость.
Так в чем же решение? Разделение хранения и вычислений + эластичные вычисления + адаптивное отопление и охлаждение.
Данные, которые пользователи должны часто запрашивать, постоянно меняются, обычно в течение последних 30 дней, поэтому последующие виртуальные таблицы будут поддерживать перемещение данных, которые пользователи запрашивают нечасто или которые требуют активного охлаждения, в более дешевое хранилище. кэшируйте или переместите его в горячее хранилище для обработки запроса. Конечно, если нет необходимости в производительности запроса, вы также можете выполнить запрос напрямую.
Последующие виртуальные таблицы будут поддерживать другие модели таблиц, такие как таблицы озера данных типа Iceberg. Хотя производительность запросов будет хуже, чем у текущей виртуальной таблицы, она будет более экономичной, дешевле в хранении и более гибкой в вычислениях. Фактически, обновление метода организации данных дает лучший эффект, чем повышение вычислительной мощности. Интранет-бизнес сократил затраты на десятки миллионов после перехода на хранилище озера данных Iceberg.
Поддерживаемый сценарий 4: Небохранилище данныхобновление
Хранилища данных Tianqiong поддерживают бизнес различных BG в компании на протяжении многих лет.,Были достигнуты очень хорошие бизнес-результаты. На начальном этапе для поддержки пользователей, перешедших с Oracle,Разработано множество функций,Однако из-за огромного прогресса в области информационных технологий и национальной инициативы по де-IOE,Большая часть этой работы стала историческим долгом. В настоящее время Tianqiong Big Data активно помогает пользователям в обновлении THive.,Когда пользовательский SQL остается неизменным,Сократите затраты на хранение и улучшите производительность запросов.
Как упоминалось ранее, пользователям очень сложно выполнить обновление без достаточного «искушения». Такие проблемы, как ошибки каналов передачи данных, остановки бизнеса и избыточные ресурсы, вызванные миграцией, весьма серьезны. Кроме того, как показывает сценарий 3, недостаточно быть совместимым только с SQL и вычислениями. Необходимо также обновить метод организации данных. Если мы сможем виртуализировать уровни вычислений и хранения и разрешить пользователям работать только с виртуальными таблицами, а пользователи смогут вносить изменения и адаптивные обновления один за другим с течением времени, то миграцию можно будет осуществлять медленно в течение длительного периода времени, и бизнес не будет Под предпосылкой затронутых, мы будем продолжать сокращать затраты и повышать эффективность.
Поддерживаемый сценарий 5: интеллектуальное материализованное представление.
Предварительные вычисления всегда были актуальны в области больших данных, поскольку по мере увеличения объема данных производительность запросов во многих сценариях не может удовлетворить потребности пользователей. Основные решения для предварительных вычислений включают ETL, материализованные представления, Cube, StarTree и т. д. Среди них материализованные представления, Cube и StarTree поддерживают перезапись и ускорение на уровне механизма SQL, а также диапазон возможностей материализованных представлений. > Cube > StarTree。
Возможности перезаписи SQL материализованных представлений упомянуты выше, но пользователям по-прежнему сложно переписывать SQL для повышения эффективности, поскольку изучение взаимосвязи между созданием и перезаписью материализованных представлений занимает много времени, и это непросто для обычных пользователей. пользователи, чтобы начать работу. Более того, заранее вычисленная скорость расширения хранилища также сильно преувеличена. Если таблица создает 10 материализованных представлений, в крайнем случае стоимость хранения этой таблицы может увеличиться в 10 раз. В конце концов, после оценки пользователи вручную удалили некоторые малоиспользуемые материализованные представления, а затраты на управление также оказались очень высокими.
Так в чем же решение? Последующая функция виртуальной таблицы будет поддерживать получение исторического потока SQL пользователя, а затем рекомендовать некоторые экономически эффективные материализованные представления на основе виртуальной таблицы. Интранет уже поддерживает функцию рекомендации материализованных представлений, а затем адаптивно устранять материализованные представления с низким уровнем. использование и низкая производительность; просмотр и поддержка обновлений в реальном времени для обеспечения согласованности материализованных представлений и базовых таблиц.
будущие целевые сценарии
Мы надеемся, что пользователи смогут использовать большие данные Tianqiong простым, легким и эффективным способом. Подключаясь к виртуальным таблицам SuperSQL +, он сможет обрабатывать различные нагрузки на запросы и адаптивно балансировать производительность и стоимость.
Как использовать виртуальные таблицы?
Синтаксис создания таблицы (DDL):
use test;
CREATE VIRTUAL TABLE IF NOT EXISTS `ssb_lineorder_flat` (
`LO_ORDERDATE` INT COMMENT "",
`LO_ORDERKEY` BIGINT COMMENT "",
`LO_LINENUMBER` INT COMMENT "",
`LO_CUSTKEY` INT COMMENT "",
`LO_PARTKEY` INT COMMENT "",
`LO_SUPPKEY` INT COMMENT "",
`LO_ORDERPRIORITY` STRING COMMENT "",
`LO_SHIPPRIORITY` INT COMMENT "",
`LO_QUANTITY` INT COMMENT "",
`LO_EXTENDEDPRICE` INT COMMENT "",
`LO_ORDTOTALPRICE` INT COMMENT "",
`LO_DISCOUNT` INT COMMENT "",
`LO_REVENUE` INT COMMENT "",
`LO_SUPPLYCOST` INT COMMENT "",
`LO_TAX` INT COMMENT "",
`LO_COMMITDATE` INT COMMENT "",
`LO_SHIPMODE` STRING COMMENT "",
`C_NAME` STRING COMMENT "",
`C_ADDRESS` STRING COMMENT "",
`C_CITY` STRING COMMENT "",
`C_NATION` STRING COMMENT "",
`C_REGION` STRING COMMENT "",
`C_PHONE` STRING COMMENT "",
`C_MKTSEGMENT` STRING COMMENT "",
`S_NAME` STRING COMMENT "",
`S_ADDRESS` STRING COMMENT "",
`S_CITY` STRING COMMENT "",
`S_NATION` STRING COMMENT "",
`S_REGION` STRING COMMENT "",
`S_PHONE` STRING COMMENT "",
`P_NAME` STRING COMMENT "",
`P_MFGR` STRING COMMENT "",
`P_CATEGORY` STRING COMMENT "",
`P_BRAND` STRING COMMENT "",
`P_COLOR` STRING COMMENT "",
`P_TYPE` STRING COMMENT "",
`P_SIZE` INT COMMENT "",
`P_CONTAINER` STRING COMMENT ""
)
PARTITION BY RANGE(`LO_ORDERDATE`)
(
PARTITION p1 VALUES LESS THAN (19930101),
PARTITION p2 VALUES LESS THAN (19940101),
PARTITION p3 VALUES LESS THAN (19950101),
PARTITION p4 VALUES LESS THAN (19960101),
PARTITION p5 VALUES LESS THAN (19970101),
PARTITION p6 VALUES LESS THAN (19980101),
PARTITION p7 VALUES LESS THAN (19990101)
)
CLUSTERED BY(`LO_ORDERKEY`) SORTED BY(`LO_ORDERDATE`,`LO_ORDERKEY`) INTO 120 BUCKETS;Синтаксис операции с разделом (DDL):
use test;
alter table test.ssb_lineorder_flat add partition par_name4 VALUES IN (20230804);
alter table test.ssb_lineorder_flat add partition part_20230103 VALUES LESS THAN (20230103);
alter table test.depts01 drop partition (par_name4);
alter table test.depts02 drop partition (part_20230103);Синтаксис записи (DML):
use test;
-- insert into виртуальный стол select from Небохранилище таблица данных (несколько таблиц/сценарий ETL)
INSERT OVERWRITE ssb_lineorder_flat SELECT * FROM benchmark_ssb_lineorder_flat_raw;
INSERT OVERWRITE ssb_lineorder_flat
SELECT `LO_ORDERDATE` , `LO_ORDERKEY` , `LO_LINENUMBER` , `LO_CUSTKEY` , `LO_PARTKEY` , `LO_SUPPKEY` , `LO_ORDERPRIORITY` , `LO_SHIPPRIORITY` , `LO_QUANTITY` , `LO_EXTENDEDPRICE` , `LO_ORDTOTALPRICE` , `LO_DISCOUNT` , `LO_REVENUE` , `LO_SUPPLYCOST` , `LO_TAX` , `LO_COMMITDATE` , `LO_SHIPMODE` , `C_NAME` , `C_ADDRESS` , `C_CITY` , `C_NATION` , `C_REGION` , `C_PHONE` , `C_MKTSEGMENT` , `S_NAME` , `S_ADDRESS` , `S_CITY` , `S_NATION` , `S_REGION` , `S_PHONE` , `P_NAME` , `P_MFGR` , `P_CATEGORY` , `P_BRAND` , `P_COLOR` , `P_TYPE` , `P_SIZE` , `P_CONTAINER`
FROM (
SELECT lo_orderkey,lo_linenumber,lo_custkey,lo_partkey,lo_suppkey,lo_orderdate,lo_orderpriority,lo_shippriority,lo_quantity,lo_extendedprice,lo_ordtotalprice,lo_discount,lo_revenue,lo_supplycost,lo_tax,lo_commitdate,lo_shipmode
FROM benchmark_ssb_lineorder_1000_raw
) l
INNER JOIN benchmark_ssb_customer_1000_raw c ON (c.C_CUSTKEY = l.LO_CUSTKEY)
INNER JOIN benchmark_ssb_supplier_1000_raw s ON (s.S_SUPPKEY = l.LO_SUPPKEY)
INNER JOIN benchmark_ssb_part_1000_raw p ON (p.P_PARTKEY = l.LO_PARTKEY);Синтаксис запроса (DQL):
use test;
--Q1.1
SELECT sum(lo_extendedprice * lo_discount) AS `revenue`
FROM ssb_lineorder_flat
WHERE lo_orderdate >= '19930101' and lo_orderdate <= '19931231'
AND lo_discount BETWEEN 1 AND 3 AND lo_quantity < 25;
--Q1.2
SELECT sum(lo_extendedprice * lo_discount) AS revenue
FROM ssb_lineorder_flat
WHERE lo_orderdate >= '19940101' and lo_orderdate <= '19940131'
AND lo_discount BETWEEN 4 AND 6 AND lo_quantity BETWEEN 26 AND 35;
--Q1.3
SELECT sum(lo_extendedprice * lo_discount) AS revenue
FROM ssb_lineorder_flat
WHERE weekofyear(lo_orderdate) = 6
AND lo_orderdate >= '19940101' and lo_orderdate <= '19941231'
AND lo_discount BETWEEN 5 AND 7 AND lo_quantity BETWEEN 26 AND 35;
--Q2.1
SELECT sum(lo_revenue), year(lo_orderdate) AS year_col, p_brand
FROM ssb_lineorder_flat
WHERE p_category = 'MFGR#12' AND s_region = 'AMERICA'
GROUP BY year(lo_orderdate), p_brand
ORDER BY year(lo_orderdate), p_brand;
--Q2.2
SELECT
sum(lo_revenue), year(lo_orderdate) AS year_col, p_brand
FROM ssb_lineorder_flat
WHERE p_brand >= 'MFGR#2221' AND p_brand <= 'MFGR#2228' AND s_region = 'ASIA'
GROUP BY year(lo_orderdate), p_brand
ORDER BY year(lo_orderdate), p_brand;
--Q2.3
SELECT sum(lo_revenue), year(lo_orderdate) AS year_col, p_brand
FROM ssb_lineorder_flat
WHERE p_brand = 'MFGR#2239' AND s_region = 'EUROPE'
GROUP BY year(lo_orderdate), p_brand
ORDER BY year(lo_orderdate), p_brand;
--Q3.1
SELECT
c_nation,
s_nation,
year(lo_orderdate) AS year_col,
sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_region = 'ASIA' AND s_region = 'ASIA' AND lo_orderdate >= '19920101'
AND lo_orderdate <= '19971231'
GROUP BY c_nation, s_nation, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q3.2
SELECT c_city, s_city, year(lo_orderdate) AS year_col, sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_nation = 'UNITED STATES' AND s_nation = 'UNITED STATES'
AND lo_orderdate >= '19920101' AND lo_orderdate <= '19971231'
GROUP BY c_city, s_city, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q3.3
SELECT c_city, s_city, year(lo_orderdate) AS year_col, sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_city in ( 'UNITED KI1' ,'UNITED KI5') AND s_city in ('UNITED KI1', 'UNITED KI5')
AND lo_orderdate >= '19920101' AND lo_orderdate <= '19971231'
GROUP BY c_city, s_city, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q3.4
SELECT c_city, s_city, year(lo_orderdate) AS year_col, sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_city in ('UNITED KI1', 'UNITED KI5') AND s_city in ('UNITED KI1', 'UNITED KI5')
AND lo_orderdate >= '19971201' AND lo_orderdate <= '19971231'
GROUP BY c_city, s_city, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q4.1
SELECT year(lo_orderdate) AS year_col, c_nation, sum(lo_revenue - lo_supplycost) AS profit
FROM ssb_lineorder_flat
WHERE c_region = 'AMERICA' AND s_region = 'AMERICA' AND p_mfgr in ('MFGR#1', 'MFGR#2')
GROUP BY year(lo_orderdate), c_nation
ORDER BY year(lo_orderdate) ASC, c_nation ASC;
--Q4.2
SELECT year(lo_orderdate) AS year_col,
s_nation, p_category, sum(lo_revenue - lo_supplycost) AS profit
FROM ssb_lineorder_flat
WHERE c_region = 'AMERICA' AND s_region = 'AMERICA'
AND lo_orderdate >= '19970101' and lo_orderdate <= '19981231'
AND p_mfgr in ( 'MFGR#1' , 'MFGR#2')
GROUP BY year(lo_orderdate), s_nation, p_category
ORDER BY year(lo_orderdate) ASC, s_nation ASC, p_category ASC;
--Q4.3
SELECT year(lo_orderdate) AS year_col, s_city, p_brand,
sum(lo_revenue - lo_supplycost) AS profit
FROM ssb_lineorder_flat
WHERE s_nation = 'UNITED STATES'
AND lo_orderdate >= '19970101' and lo_orderdate <= '19981231'
AND p_category = 'MFGR#14'
GROUP BY year(lo_orderdate), s_city, p_brand
ORDER BY year(lo_orderdate) ASC, s_city ASC, p_brand ASC; Обзор
В этой статье описывается, как большие данные Tianqiong основаны на Data Fabric Методология архитектуры для построения первого этапа архитектуры больших данных следующего поколения посредством внедрения виртуальных технологий. стол Приходитьнижний слой щита Разнородность для удовлетворения потребностей бизнеса и достижения цели снижения затрат пользователей и повышения эффективности использования. Две основные интегрированные архитектуры «озеро-склад» в настоящее время относительно популярны и превосходны. Однако текущие бизнес-сценарии больших данных Tianqiong очень сложны. Их можно использовать во многих бизнес-сценариях, но есть еще много сценариев, которые не могут быть реализованы. потребности, а именно Нам нужен набор интегрированных озер и складов с более общими возможностями для удовлетворения потребностей снижения затрат и повышения эффективности, то есть Tianqiong OS-виртуальный стол。
Краткосрочные цели, которых хотят достичь виртуальные столы:
- Поддержка хранилища небесного купола данных Чрезвычайно быстрый запроссцена
- один кусочек SQL Запросить небесное хранилище данные Все данные, нет островов данных, опыт Интеграция
- Обеспечьте удобство выполнения запросов (скорость, стабильность, согласованность и т. д.) по цене, указанной пользователем.
- Небохранилище данных Безболезненное обновление
ссылка
[3] Виртуализация данных Wikipedia Связь
[4] Виртуализация данныхпродукт denodo Связь
[5] Серия статей об архитектуре больших данных: как понять интеграцию озер и складов?



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
