Тестирование распределенных систем: обзор тестирования надежности и удобства использования
В последние годы некоторые крупные производители и их клиенты нанадежность системы, теперь будет распределена надежность Краткое изложение теста системы резюмируется следующим образом, и мы надеемся, что оно послужит отправной точкой. Вы также можете оставлять сообщения в комментариях.
существоватьраспределенная В системе нужно учитывать два показателя: доступность и индекс. надежность. Часто для измерения качества системы используются два показателя. Как правило, эти два показателя также используются при оценке производительности системы. При системном тестировании/интеграционном тестировании, особенно крупномасштабная распределенная системе необходимо учитывать эти два показателя.
Теоретический обзор
надежность системы
Под надежностью системы понимается система, работающая в определенное время и в определенных условиях работы.,Возможность выполнения указанной функции или вероятности. Проще говоря,То есть система может работать непрерывно и стабильно.,Возможность не прерываться или не выходить из строя из-за внутренних неисправностей или внешнего вмешательства.
индекс надежности
Как количественно оценить надежность системы, то есть как определить, является ли одна большая система более надежной, чем другая? С этой целью в отрасли определены следующие основные показатели оценки надежности, характеризующие надежность системы.
Ø MTTF(Mean Time To Failure,среднее время до отказа),Указывает среднее время, в течение которого ожидается эксплуатация единицы хранения. Это время, в течение которого обычно предоставляются услуги.
Ø MTTR(Mean Time To Repair,среднее время ремонта),Указывает среднее время, необходимое для ремонта неисправной детали.
Ø MTBF(Mean Time Between Failures,среднее время между отказами),Представляет среднее время между каждым сбоем компонента системы. Другими словами: время между отказами. Вообще говоря,Если среднее время безотказной работы больше,означает, что в фиксированном временном окне,Тем меньше происходит системных сбоев. MTBF можно использовать в часах (MTBF in часов) и лет (MTBF in лет), чтобы выразить. MTBF компонента системы можно рассчитать двумя способами: во-первых, путем накопления значений MTTF и MTTR, во-вторых, путем деления длины наблюдаемого временного окна на количество сбоев, произошедших в этом окне; получать. Например, если среднее время безотказной работы компонента системы составляет 1 год, его физический смысл означает, что компонент выходит из строя в среднем один раз в год.
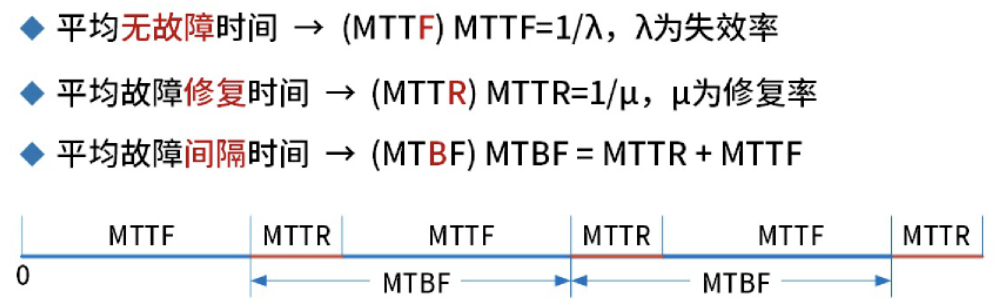
При оценке производительности системы обычно используется среднее время между отказами. (MTBF) и среднее время ремонта (MTTR) соответственно представляют надежность и доступность компьютерных систем.,Большой показатель MTBF и небольшой показатель MTTR указывают на высокую надежность и доступность системы.。
хранилищенадежность системыиндекс
В некоторых крупномасштабных системных испытаниях надежности и проблем также используются следующие три индикатора для систем хранения: AFR, FIT и PPM, которые вместе с тремя вышеуказанными индикаторами измеряют надежность системы.
AFR(Annual Failure Rate,среднегодовая интенсивность отказов),Указывает среднее количество сбоев системных дисков в течение года. можно найти,AFR является обратной величиной MTBF.
AFR: Годовая частота отказов, также известная как годовая вероятность отказа жесткого диска, обычно используется для отражения вероятности отказа устройства в течение года. Интуитивно можно понять, что чем ниже AFR, тем выше надежность. Система, поскольку AFR связана с системой, тесно связана с надежностью данных. Показатель составляет 1,20 Вт-часа. Ниже приведена формула расчета AFR:
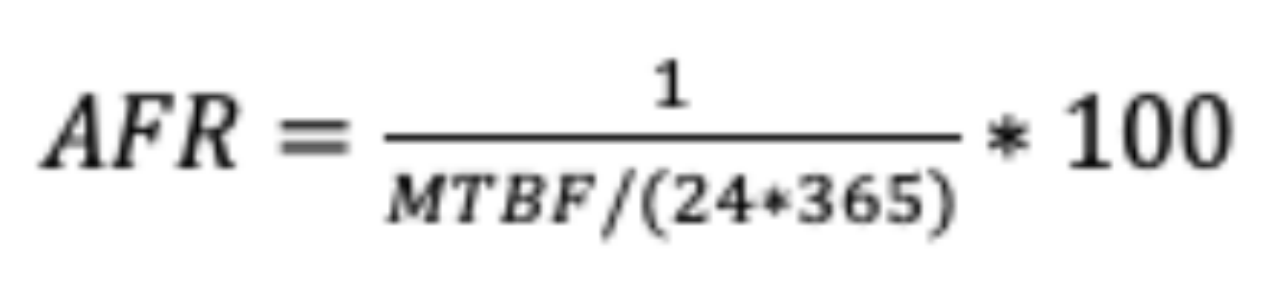
FIT(Failures In Time)
FIT представляет собой количество отказов, ожидаемых за один миллиард часов работы. Чем ниже значение FIT, тем выше надежность изделия при длительной эксплуатации.
Индикатор FIT особенно подходит для продуктов, требующих высоких гарантий надежности.,Например, аэрокосмическая электроника и медицинское оборудование. Например,Электронный компонент имеет FIT 5.,Означает, что в среднем за миллиард часов работы можно ожидать 5 отказов.,Подходит для приложений, требующих чрезвычайно высокой надежности.
PPM(Parts Per Million)
PPM, или частей на миллион, измеряет количество дефектных продуктов, которые могут возникнуть на миллион единиц продукта. Это ключевой показатель качества производства, который помогает производителям количественно определять уровень дефектов в производственном процессе.
PPM широко используется в обрабатывающих отраслях со строгим контролем качества, например, в производстве полупроводников. Например, если на линии по производству чипов показатель PPM равен 50, это означает, что 50 из каждого миллиона произведенных чипов могут быть бракованными.
Доступность системы
Доступность Под системой понимается способность системы нормально работать в течение определенного времени. это измеряемая стабильность системы и один из важных показателей надежности. Система с высокой доступностью означает, что система может быть доступна в случае необходимости с высокой вероятностью, независимо от сбоя оборудования, ошибок программного обеспечения, ошибок оператора или других непредсказуемых ситуаций.
Доступность системы обычно страдает от системных ошибок.、проблемы инфраструктуры、Влияние множества факторов, таких как вредоносные атаки и нагрузка на систему.。Для повышения доступности системы,Могут быть приняты различные меры,Например, обеспечение поддержки аварийного переключения на физическом уровне системы. разумный механизм обработки исключений.、Оптимизировать стратегии использования ресурсов、Разработайте более эффективные стратегии для обновлений среды выполнения, обработки нестабильных сетевых подключений и т. д.
показатели доступности
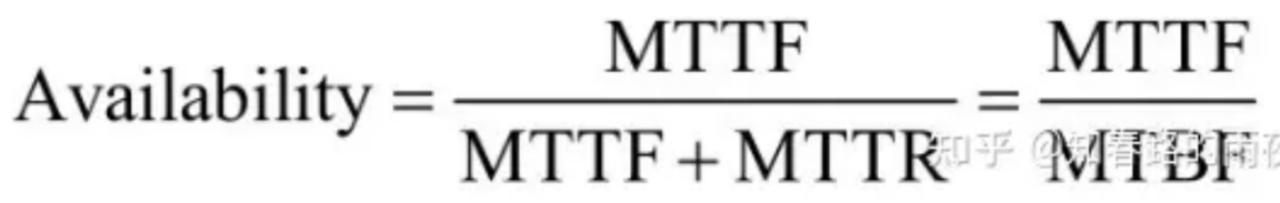
Показатели доступности и надежности
В практических приложениях обычно MTTR очень мал, поэтому обычно учитывают MTBF ~ MTTF.
>>> Надежность можно измерить соотношением MTTF/(1+MTTF).
>>> Доступность можно измерить соотношением MTBF/(1+MTBF).
>>> Ремонтопригодность можно измерить как 1/(1+MTTR).
На самом деле индекс При измерении надежности мы обычно также имеем «тысячечасовую надежность», которую обычно записывают как R. То есть, какова вероятность надежности системы, если она проработает тысячу часов. Противоположностью этого показателя является «процент отказов». Сумма «тысячечасовой надежности» и «интенсивности отказов» равна 1.
Например: для крупномасштабных распределенных систем [каждый тип компонента должен нормально работать и предоставлять услуги одновременно, чтобы все в целом могло предоставлять нормальные услуги внешнему миру. Для крупномасштабных распределенных систем каждый тип компонента считается нормальным, если он предоставляет внешние услуги. Для компонентов/кластеров распределенной системы, если существует проблема с определенным экземпляром развертывания, но компонент все еще может предоставлять внешние услуги. компонент считается нормальным], через 1000 часов работы два компонента вышли из строя один за другим, то есть произошло два отказа. Так
Частота отказов: 2/1000=0,002, надежность R: 1-2/1000=0,998.
Обзор распределенного тестирования надежности и доступности
На основе вышеизложенного мы разрабатываем обзор тестирования надежности и доступности, соответствующий распределенным системам.
В крупномасштабных распределенных системах несколько копий одного и того же компонента обычно развертываются в одной области сети в разных регионах. То есть каждый узел физически рассредоточен и логически образует целостную систему посредством внешней настройки.
Целью тестирования надежности обычно является имитация различных неисправностей или создание различных аварийных ситуаций, чтобы увидеть, может ли система предоставлять нормальные услуги и сколько времени потребуется на восстановление.
Уведомление: Здесь смоделирована неисправность.,В момент сбоя, пока система все еще может предоставлять внешние услуги, симптомы сбоя (такие как снижение производительности, увеличение задержки запроса) не обязательно требуют разработки ремонта, но для Когда время сбоя истекло и система не восстановилась или показатели после восстановления не достигли ожидаемых, тогда студентам-исследователям необходимо ее отремонтировать.
Надежность узла
Узел: это один сервер. Несколько серверов соединены через сеть, образуя кластер.
В общем, о Надежности тест узла, общее отключение.
Уведомление:Обычно,Произойдет кратковременная потеря производительности. Узел отключения здесь деактивирован.,основнойсосредоточиться В число пунктов входят: влияние на систему и время восстановления.
Практическая работа
шаг:
1. Распределенная система развернута, и сервер подключен к системе мониторинга, либо вы можете войти на каждую машину на сервере и запустить команду мониторинга через командную строку. [В последнем случае необходим метод агрегирования данных, одобренный командой]
2. Инициировать большое количество запросов в среде в течение определенного периода времени; длительность должна быть завершена после шага 5. Примечание. Запрошенный адрес предпочтительно является адресом открытой службы, то есть после появления узла система может автоматически; передать запрос на доступный адрес службы на узле.
3. В течение этого периода времени выключите узел [отключить узел];
4. Обратите внимание на показатели серверного мониторинга: изменения кривых показателей производительности:
① Сможет ли он восстановиться после падения. Если его можно восстановить, это доказывает, что система может переключить запрос на узел с нормальным обслуживанием. При этом следует обратить внимание на время восстановления [это видно со стороны, эффективное время запроса на передачу по всему звену ответа системы].
② Если все запросы не могут быть обработаны, например: все имеют тайм-аут или прямую ошибку, а продолжительность очень велика, это означает, что система не передала запрос на действительный узел [Вы можете проверить журнал сервера во-первых: в запросе на планирование передачи, точка удаления узла отказа]
5. Включите узел [Включить узел]. В основном это касается:
① Может ли служба на «новом узле» запускаться автоматически, и может ли система перенаправлять запросы на этот «новый узел», то есть может ли узел правильно присоединиться к среде и предоставлять услуги.
② После добавления «нового узла» показатели производительности системы могут быть восстановлены до первого уровня, а общие требования должны быть практически такими же.
Уведомление:Этот метод должен хорошо контролироватьсяКоличество «массовых запросов», как правило, должно быть достаточным для обнаружения проблемы и не перегружать систему.,Не делать“Испытание на усталость”、“Тестирование узких мест”Йо。Что касается“Для запросов «массового запроса» обычно рекомендуется выбирать для тестирования часто используемые интерфейсы и функции в реальной системе.,Вы можете рассматривать только запись и только чтение.,Также возможно совмещать чтение и письмо.
существовать Практическая работав процессе,Вы можете остановить узел,Вы также можете припарковать несколько узлов. Сколько из них разумно?,Это зависит от количества узлов в среде,Вам также следует подумать, сможет ли система продолжать работать после остановки нескольких узлов.,То есть максимальное количество простоев обычно не превышает (n+1)/2 узлов.,Это большинство принципов компьютерных систем. Какой конкретно узел деактивировать?,Зависит от развертывания системы,и характеристики самой системы,Также обратите внимание на контрольные точки отключения и т. д.
Дополнение: Для «согласованности» в распределенных системах, то есть запросы на запись хранят данные на разных узлах, как правило, при проектировании системы мы будем учитывать, такие как: методы многократного избыточного хранения, дизайн гарантии согласованности данных и т. д. Никаких дальнейших объяснений.
надежность сети
Аппаратный сбой: подключение устройства, сбой линии (повреждение, падение и т.п.) ==> Этот момент нужно учитывать для больших СХД, а также выборочно учитывать некоторые постоянные требования к программному обеспечению.
Сбой программного обеспечения: сетевой шторм, конфликт IP, прерывание сетевого порта, потеря конфигурации коммутатора, сбой сетевой карты, потеря пакетов с задержкой и т. д.
Практическая работа
и Надежность узласходство,Просто замените шаг 2,Замените симулированным сбоем сети.
Примечание. Обязательно контролируйте масштабы ошибок, то есть контроль радиуса того, что все называют «тестированием хаоса».
Как правило, для работы определенного тестируемого компонента необходимо строго контролировать объем сетевых сбоев и ориентироваться на определенные IP-адреса и даже порты на этих узлах. В противном случае, после того, как будут затронуты зависимые компоненты, тестируемая система будет затронута из-за проблем самих зависимых компонентов, что сделает тест достаточно неточным, потребует ненужных затрат времени на обнаружение проблемы и даже игнорирует глубоко укоренившиеся проблемы. неисправности.
Для полной системы/полной среды необходимо гарантировать, что каждая ошибка будет привязана к узлу. Здесь основное внимание уделяется взаимодействию всей системы. Такая ситуация относительно редка. Поскольку этот момент строго демонстрируется при проектировании архитектуры распределенной системы, а также отражается на сетевой диаграмме развертывания каждого компонента, каждый компонент обычно учитывает соображения отказоустойчивости. На такую работу уходит много времени, а выходные данные уже теоретически доступны, поэтому больше пользы команде это не принесет.
надежность системы
Тест надежности системы в основном проверяет четыре показателя
Ø Зрелость: относится к способности системы избегать сбоев из-за ошибок.
Ø Отказоустойчивость: способность системы поддерживать заданный уровень производительности в случае сбоя системы или нарушения определенных интерфейсов.
Ø Легкость восстановления: в случае сбоя системы возможность восстановить заданный уровень производительности и восстановить непосредственно затронутые данные.
Ø Соответствие: способность системы соответствовать стандартам, соглашениям и протоколам, связанным с надежностью.
Память
Механизм защиты от протечек Память (cgroup), Проблема протечек Память под высоким давлением, Стабильная работа системы при высокой заполняемости Память
Дополнение: Вообще требуется, чтобы программа не утекала. Если ожидаемым результатом в определенном сценарии является утечка Память, то мы ориентируемся Вопрос в том, действительно ли «Память» слита, и как эти утечки «Память» влияют на производительность. Последние больше касаются известных проблем и последствий системы.
CPU
Система стабильно работает при высокой загрузке процессора. Общие ожидания: после того, как ЦП поднимется, может ли он выйти из строя? После того как ЦП выйдет из строя, сможет ли он вернуться в исходное состояние и т. д.
Различные инструменты для испытаний под давлением
использовать Различные инструменты для испытаний под Этот тест может генерировать нагрузку на различные показатели тестируемой системы [ЦП, Память, чтение и запись на диск, сетевая карта и т. д.]. Это похоже на «испытание на усталость», в основном основное внимание уделяется на:системасуществовать Большое количество запросов【склонность к крайностям】Вниз,Как ведет себя система?,и это выступление,Примет ли это команда.
Практическая работа
Обычно это фокусируется на собственных делах компонента в распределенной среде. Обычно учитываются характеристики компонентов системы и некоторые специальные сценарии, чтобы определить, достигает ли система ожидаемых целей.
Ниже приведены два сценария проверки [в реальном тестировании их больше, чем эти два]
Возобновить этапы проверки после резкого увеличения трафика:
1. Распределенная система развернута и сервер подключен к системе мониторинга;
2. Инициировать пакет запросов в среде на определенный период времени, который должен завершиться после шага 5;
Уведомление: Запрос здесь, как правило, представляет собой функциональный интерфейс, который подвержен проблемам Память и ЦП в этом компоненте. Например: Редис Мгновенное увеличение ЦП, вызванное написанием больших ключей и команд дампа, разработано на основе характеристик этого компонента.
3. Время идет,Загрузка ЦП и Памяти увеличилась.,Допуск к следующему шагу,Например: загрузка ЦП на каждом узле достигла 50 %.,Память занимает примерно половину;
4. Добавляем пакет запросов, которые вместе с запросами на шаге 2 образуют большой пакет запросов ==> В целом система выдерживает максимальный трафик, то есть "экстремальное тестирование";
На данный момент сосредоточьтесь на: ЦП и Память занимают максимальное количество системных ресурсов. Посмотрите, может ли система выйти из строя.
① Сервер приостановлен, а клиентские запросы имеют тайм-аут или прямую ошибку и не могут быть восстановлены ===》Это зависит от ситуации и в большинстве случаев не будет принято.
② Произошло всего несколько тайм-аутов или ошибок, общий ответ задерживается, но система не вышла из строя и продолжает предоставлять услуги. ===》Если задержка находится в пределах ожидаемого диапазона, это идеальное состояние и система надежна. Если задержка превысит установленный срок, вам придется найти членов команды для устранения проблемы.
5. Постепенно уменьшайте объем запроса до объема запроса, указанного на шаге 2, или сразу остановите запрос. В это время сосредоточьтесь на следующем:
① Можно ли уменьшить процессор и Память системы? Сколько времени на это потребуется?
Этапы проверки роста лестницы трафика:
1. Распределенная система развернута и сервер подключен к системе мониторинга;
2. Инициируйте пакет запросов в среде на определенный период времени. Обратите внимание, что каждый раз добавляется новый трафик запросов давления. Количество новых запросов трафика является постоянным, обеспечивая линейный рост лестницы запросов;
В настоящее время сосредоточьтесь на: Есть ли какое-либо увеличение количества шагов ЦП и Память на каждом узле системы?,Когда объем параллелизма достигает,Кривые индикаторов CPU и Память вошли в плоскую зону [Этот трафик может быть точкой перегиба при текущем масштабе развертывания, рекомендованном системой] Вы также можете увидеть его здесь,Индикаторы задержки ответа системы при различных запросах трафика.
Как правило, он прекращается, когда вы видите, что количество ошибок в запросах начинает увеличиваться. Эта сумма запроса является суммой запроса, которая является узким местом системы.
3. Перезапуск. Шаг 2. При достижении узкого места системы начать спуск по лестнице:
На данный момент сосредоточьтесь на: ЦП на каждом узле системы.、Есть ли у Память еще и понижающий шаг? Уменьшается ли соответствующая задержка ответа системы.
стабильность системы
При выполнении теста надежности системы обойти тест стабильности системы невозможно. Это наиболее распространенный метод тестирования.
Раньше мы обычно создавали специальную среду для проведения долгосрочных стресс-тестов общих функций или интерфейсов и регулярно проверяли показатели производительности.
Практическая работа
1. Распределенная система развернута и сервер подключен к системе мониторинга;
2. Инициировать пакет запросов в среде на 7*24 часа или дольше;
Уведомление: Обычно считается, что количество запросов здесь способно выдержать систему.,или Объем запроса достигает определенного системного порога,Если загрузка ЦП достигает 70%, Память занимает 50% и т. д.;,Приоритет отдается возможностям системы, а также часто используемым функциям и интерфейсам.
3. Регулярно проверяйте различные показатели нагруженной системы.
сосредоточиться наPoint: Увеличился или увеличился ЦП всей системы за такой длительный период времени. Это самый интуитивно понятный и распространенный способ узнать, давно ли работает система и стабильна ли она. системы Один из методов тестирования.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
