Технологии, связанные с большими моделями: почему необходимо изменение ранга
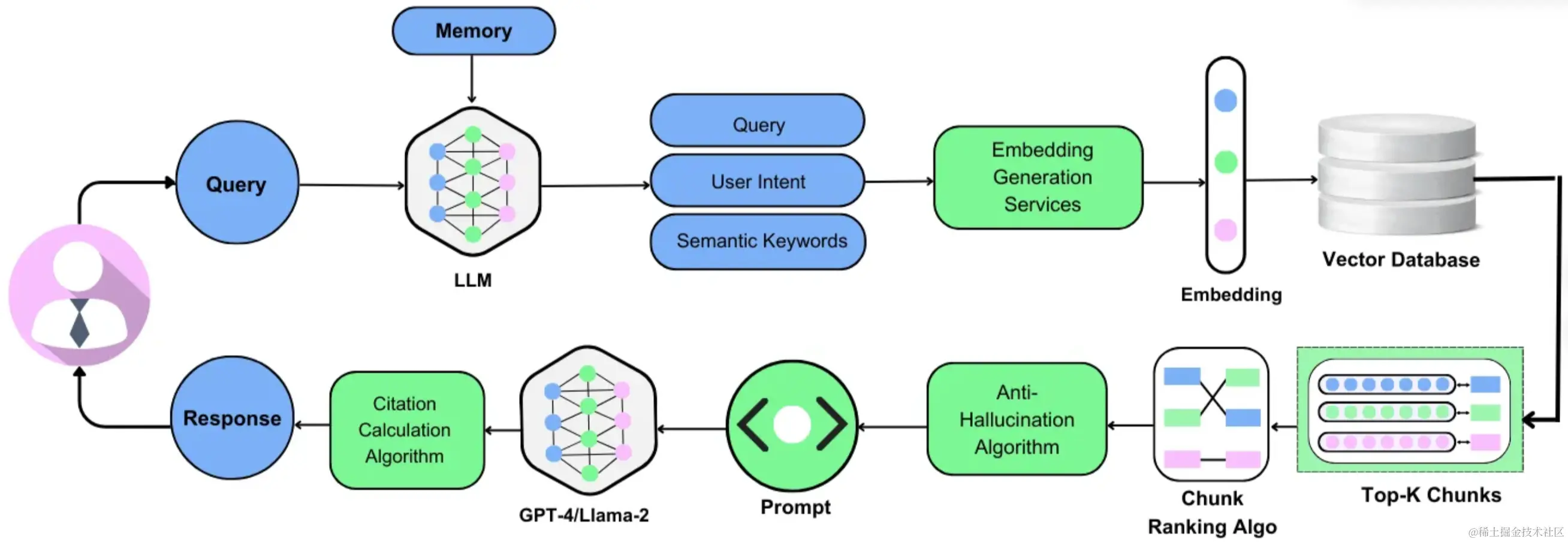
В RAG (RetrivalAugmented Generation) векторный поиск модели внедрения может помочь улучшить эффект генерации текста, но для этого все еще требуется
переранжируйте модель для дальнейшей оптимизации результатов поиска и улучшения качества генерации. Преимущество этой двухэтапной комбинации моделей поиска и переранжирования состоит в том, что обе модели могут быть полностью использованы.
Преимущества предоставления более точных и релевантных результатов. В этой статье кратко проанализировано, что такое двухэтапный поиск и почему изменение ранжирования так важно, а также его сравнение с традиционным полнотекстовым поиском ES.
По сравнению с тем, почему у него есть преимущество.
Что такое двухэтапный поиск?
Двухэтапный поиск состоит из этапа поиска и этапа уточнения. Этот метод хорошо сочетает производительность и скорость поиска, поэтому он широко применяется в процессе RAG.
На этапе поиска обычно используется векторный метод интенсивного поиска для поиска фрагментов, семантически схожих с вопросом пользователя, путем извлечения семантических векторов вопросов пользователя и корпуса базы знаний.
При извлечении семантических векторов обычно используется структура двойного кодировщика для обработки огромного массива базы знаний в автономном режиме с целью извлечения вопросов пользователя в режиме реального времени.
Семантические векторы вопросов и использование векторных баз данных для семантического поиска. В этом процессе извлечение семантического вектора корпуса базы знаний выполняется статически и в автономном режиме, а модель извлекается.
Между вопросами пользователя и смысловыми векторами корпуса базы знаний отсутствует информационное взаимодействие. Преимуществом этого метода является высокая эффективность, но он также ограничивает верхний предел производительности семантического поиска.
Для решения проблемы информационного взаимодействия на этапе доработки принимается структура кросс-кодировщика. Изменение порядка моделей позволяет пользователям задавать вопросы и создавать базы знаний.
Информационное взаимодействие между корпусами, тем самым выявляя более точные семантические связи, верхний предел производительности алгоритма очень высок. Однако недостатком этого подхода является то, что он требует оперативного (онлайн)
Получение семантической связи между вопросами пользователя и корпусом базы знаний неэффективно и не позволяет обрабатывать весь корпус базы знаний в реальном времени.
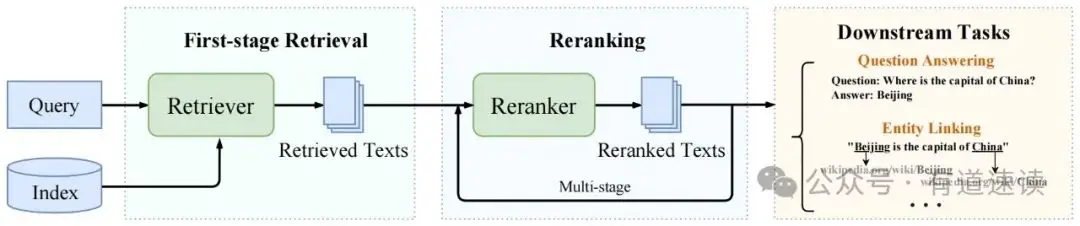
Таким образом, сочетая преимущества поиска и мелкозернистости, двухэтапный поиск может быстро извлечь фрагменты текста, связанные с вопросом пользователя, и поместить правильные релевантные фрагменты вперед, насколько это возможно.
столбцы при фильтрации клипов низкого качества. Этот метод позволяет хорошо оценить эффект и эффективность поиска и имеет огромную прикладную ценность.
Если говорить проще: первый этап реализует отзыв документов через модель внедрения, а второй этап реализует семантику вопросов пользователей и сортировку отозванных документов.
Зачем нам нужна модель реранга?
Повышение точности. Хотя модель внедрения может извлекать похожие фрагменты текста путем расчета сходства векторов, это может оказаться невозможным из-за сложности и неоднозначности семантики.
Есть некоторые избыточные или нерелевантные результаты. Модель переранжирования может дополнительно уточнять и оптимизировать результаты на этой основе, повышая точность и релевантность сгенерированного текста.
Семантическое сопоставление: модель переранжирования может выполнять сопоставление текста на основе более обширной семантической информации, такой как синтаксическая структура, семантическая ассоциация и контекстная информация, для лучшего понимания.
смысл текста и выбрать наиболее релевантный контент для генерации.
Персонализированная настройка: модель переоценки можно персонализировать в соответствии с предпочтениями и потребностями пользователя, что еще больше повышает адаптируемость полученных результатов и удовлетворенность пользователей, что полезно для
Это особенно важно для приложений в конкретных областях или сценариях.
Преимущества двухэтапных моделей поиска и переранжирования
Повышение точности: векторный поиск модели внедрения позволяет быстро отфильтровать похожие тексты, а модель переранжирования еще больше повышает точность поиска и генерации на этой основе.
свойства, что приводит к более качественному результату.
Экономия вычислительных ресурсов. Модель переранжирования работает с меньшим набором текста, отфильтрованным с помощью модели внедрения, что сокращает объем вычислений и повышает эффективность и производительность.
Гибкость: двухэтапный подход позволяет гибко обрабатывать различные типы запросов и запросов, позволяя при этом выбирать и корректировать различные модели переранжирования в соответствии с конкретными задачами и т. д.
Масштабируемый.
Сравнение с технологией elasticsearch
Ограничения эластичного поиска. По сравнению с традиционными инструментами поиска текста, такими как эластичный поиск, метод сопоставления ключевых слов может иметь семантический дрейф и недостаточную точность.
проблема. В некоторых сложных задачах традиционная технология поиска не может полностью удовлетворить потребности.
В сочетании с преимуществами RAG: по сравнению с эластичным поиском, двухэтапный поиск RAG уделяет больше внимания семантическому сопоставлению, что позволяет лучше понять текстовое содержимое и контекст, тем самым улучшая
Обеспечивает более точную и качественную генерацию текста. Сочетая модели глубокого обучения и функции данных из нескольких источников, RAG имеет явные преимущества в создании качества и релевантности текста.
Адаптивность: RAG можно гибко настраивать в соответствии с конкретными сценариями и потребностями, адаптируясь к различным требованиям задач, повышая практичность и адаптируемость генерируемого текста, оставаясь при этом традиционным;
Технологии текстового поиска трудно добиться таких точных персонализированных настроек.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
