Т1, самая крупная отечественная модель - Кими, может без какого-либо давления анализировать два миллиона контекстов.

Два миллионера? Как?
Я написал статью некоторое время назад:#GPT4-Турбор 128к? Недостаточно? Недостаточно!Помнить GPT4-T Количество параметров контекста 128к, вот и все 100 10 000 английских символов, 50 Десять тысяч иероглифов кандзи, Кими как это сделать double из?
Действительно ли это возможно?
Есть ли конец расширению контекста?
Упоминалось в предыдущей статье RAG технология, т.е. Улучшения генеративного поиска,это может пройти API Звоните, запрашивайте страницы или читайте файлы, оптимизируйте извлекаемые данные, уменьшайте сортировку текста или тегов, сохраняя при этом необходимую информацию, затем используйте разделитель текста для преобразования документа в абзацы и блоки кода, определите размер каждого абзаца, затем выполните семантическую индексацию; и сохраняются в базе данных векторов; перед ответом на пользовательский контент блоки абзацев, семантически соответствующие первоначальному запросу пользователя, выбираются и вставляются в подсказку.
На просторечии это означает сегментацию, анализ, взвешивание и вставку контекстных подсказок в подсказки. Итак: если длину контекста можно бесконечно расширять, имеет ли технология RAG смысл?
Принцип Кими,Официальный сайт объясняет:# Kimi Chat Объявление результатов длиннотекстового стресс-теста «иголка в стоге сена»
«Игла» здесь — это ядро «большой контекстной подсказки», ядро, которое нам нужно извлечь и проанализировать:
Есть интересные данные:
1. GPT-4 Turbo (128К) имеет плохую точность, когда длина корпуса превышает 72К и предложение («игла») скрыто в заголовке текста. (Это также то, что мы упоминали ранее)
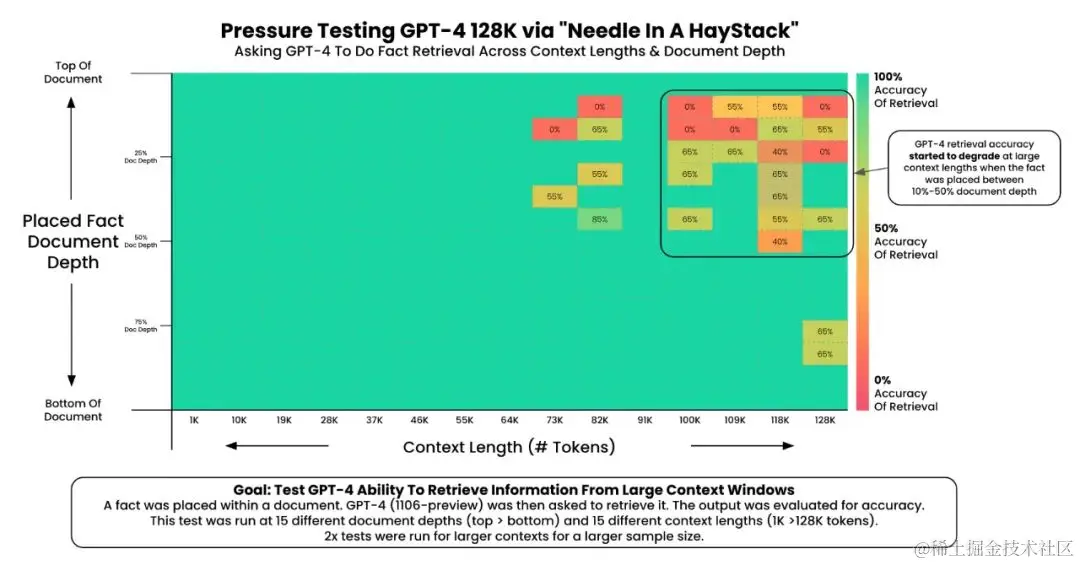
2. Кажется, что Клод 2.1 имеет низкую точность после того, как длина корпуса превышает 20 КБ, и точность особенно низкая, когда предложение (игла) спрятано в передней части корпуса.

Результаты испытаний Кими Чата в эксперименте «Иголка в стоге сена» следующие:

Результаты тестов Кими на удивление хороши!
Итак... что именно Кими сделал правильно?
Чиновник ничего вразумительного не сказал, но в итоге дал такое заключение:

Конкретные детали технической реализации лежат в основе большого количества сложных инженерных оптимизаций и инновационных алгоритмов. Это также является основным техническим барьером команды Кими и неизвестно.
Ответ внутреннего участника:
думать:
Каким будет будущий конкурс крупных моделей? Два момента:
1. Точность данных – различные отрасли
2. Вычислительная мощность и возможности синтаксического анализа — здесь даже контекстный анализ большого текста!



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
