Сводка исключений, встречающихся в ежедневном процессе разработки кластера и решений больших данных Spark
Оригинал / Чжу Цзицянь
Во время разработки больших данных Spark я столкнулся со многими проблемами, и эти проблемы и решения были записаны. Хорошая память не так хороша, как плохое письмо. Когда эти ошибки и идеи решения записаны, в следующий раз, когда вы столкнетесь с ними, вы сможете быстро отреагировать, основываясь на предыдущих ошибках. Конечно, если другие также столкнутся с соответствующими проблемами, также доступно. чтобы помочь.
Эта запись будет продолжать обновляться.
1. Возникает java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.<init>()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator
Создайте следующий код Scala в новом проекте, чтобы подключиться к кластеру Hbase и определить, существует ли определенная таблица в Hbase.
//Офлайн Hbase
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","192.168.1.200")
conf.set("hbase.zookeeper.property.clientPort","2181")
// Создать соединение HBase
val connection = ConnectionFactory.createConnection(conf)
val hbaseAdmin = connection.getAdmin
val tables = Set("SYSTEM_LOG")
val synTable = TableName.valueOf(tableName)
val tableExist = hbaseAdmin.tableExists(synTable)Во время выполнения теста произошло следующее исключение:
Exception in thread "main" org.apache.hadoop.hbase.DoNotRetryIOException: java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator
Проверка показала, что hbase-client, spark-core и многие другие зависимые пакеты, представленные в maven, содержат пакет com.google.guava, что приведет к конфликтам между различными пакетами guava, что приведет к попытке доступа к методу com. Ошибка .google.common.base.Stopwatch.Exception.
Мы можем проверить проблему конфликта пакетов com.google.guava с помощью подключаемого модуля maven maven-help.,Введение и использование плагина maven-help,Я представил это в другом блоге——Maven Вспомогательный плагин — реализация проблемы конфликта зависимостей Maven одним щелчком мыши
Переключитесь на столбец [Анализатор зависимостей] в maven, введите конфликтующий пакет guava в поле поиска, и появится сообщение, от каких пакетов зависит guava. Когда несколько пакетов компонентов зависят от одного и того же пакета, но разных версий, легко возникают различные конфликты. возникают в течение длительного времени. Красная часть указывает на конфликтующие версии пакета зависимостей ——
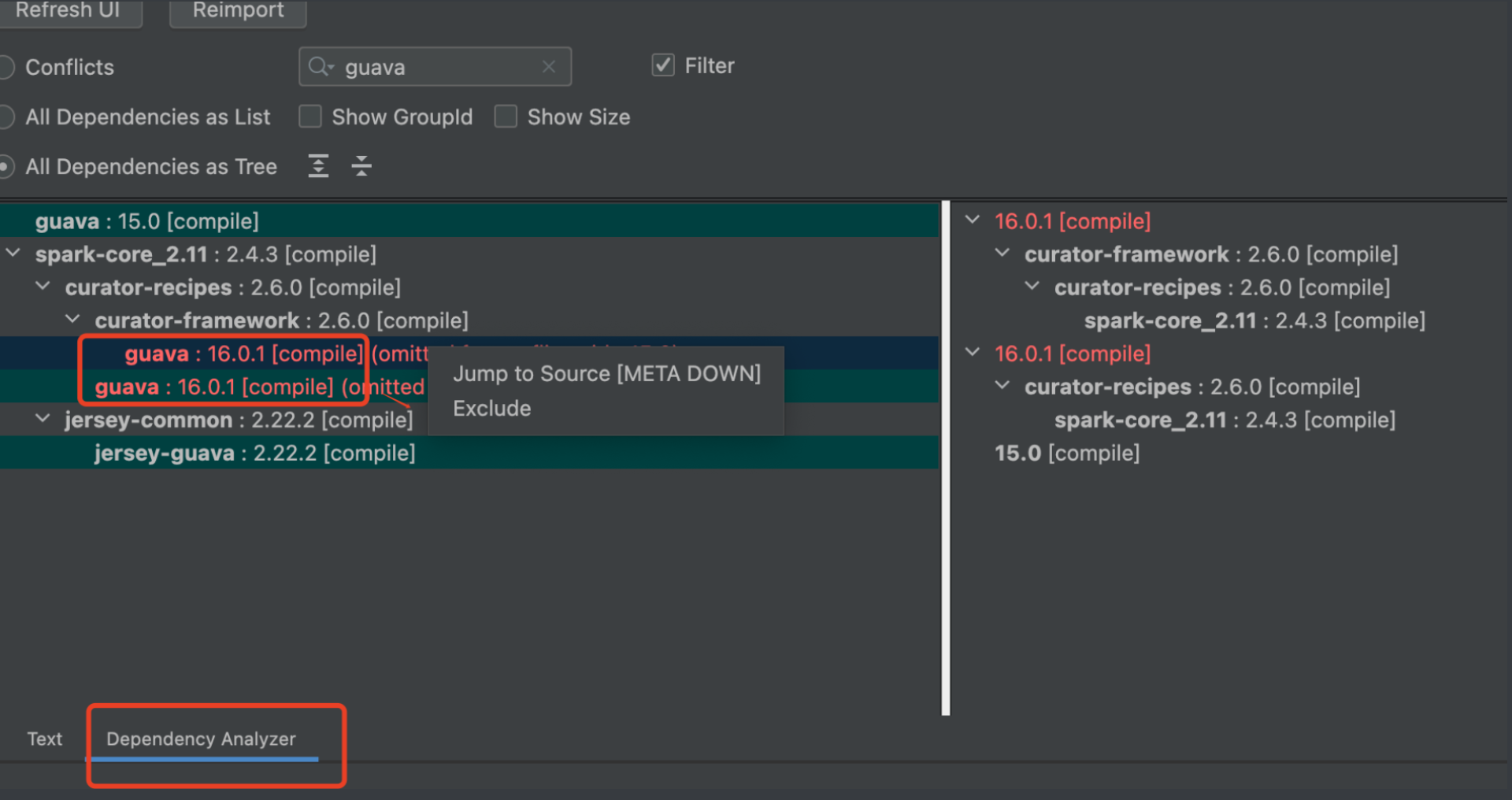
Выберите пакет, который хотите удалить, щелкните правой кнопкой мыши и выберите «Исключить», чтобы выполнить исключение одним щелчком мыши.
Наконец, добавьте отдельно пакет com.google.guava. Моя база данных — версия 1.x, и установка версии guava-15 может решить проблему.
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>15.0</version>
</dependency>2. org.apache.hadoop.hbase.NamespaceNotFoundException: происходит СИСТЕМА
При создании таблицы с пространством имен, например при создании таблицы с именем SYSTEM:SYSTEM_LOG, возникает следующее исключение: вызвано: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.NamespaceNotFoundException) : org.apache.hadoop.hbase.NamespaceNotFoundException: СИСТЕМА в org.apache.hadoop.hbase.master.HMaster.ensureNamespaceExists(HMaster.java:2090) по адресу org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1270) по адресу org.apache.hadoop.hbase. master.MasterRpcServices.createTable(MasterRpcServices.java:399) по адресу org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:42436) по адресу org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2033) по адресу org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:107) по адресу org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:130) по адресу org.apache.hadoop.hbase. ipc.RpcExecutor$1.run(RpcExecutor.java:107) по адресу java.lang.Thread.run(Thread.java:748)
На данный момент пространство имен SYSTEM не было создано в Hbase заранее, поэтому вам необходимо сначала его создать, напрямую войти на сервер Hbase и выполнить следующие инструкции через оболочку hbase:
create_namespace 'SYSTEM'После успешного выполнения, как показано на рисунке ниже:

В это время запустите код еще раз, и никакой ошибки не будет. Затем проверьте инструкции по списку оболочки hbase и убедитесь, что таблица SYSTEM:SYSTEM_LOG с пространством имен создана нормально.
3. В каталоге bin искры возникает исключение при запуске искровой оболочки. Не удалось инициализировать сеанс Spark.
java.io.FileNotFoundException: File does not exist: hdfs://hadoop1:9000/spark-logs
В каталоге bin Spark при запуске собственного скрипта spark-shell внезапно возникает ошибка. Информация об исключении следующая:
main ERROR org.apache.spark.repl.Main - Failed to initialize Spark session. java.io.FileNotFoundException: File does not exist: hdfs://hadoop1:9000/spark-logs at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1309) at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
Причина этой проблемы в том, что в hdfs нет каталога Spark-Logs.
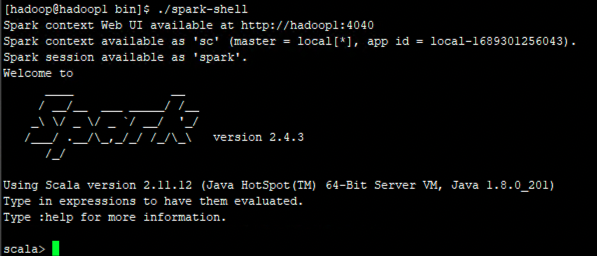
Таким образом, после того, как я попытался запустить команду hdfs dfs -mkdir/spark-logs на главном компьютере Hadoop, был создан каталог /spark-logs. Затем, когда я выполнил spark-shell, я смог нормально войти в интерфейс командной строки scala. - —
4. Проблема с локальной библиотекой кустов удаленных запросов Scala, показывающей только библиотеку по умолчанию.
Вначале мой код локального Scala для удаленного подключения к Spark для запроса библиотеки hive был написан так:
val spark = SparkSession
.builder()
.master("spark://192.168.1.99:7077")
.appName("YourAppName")
.enableHiveSupport() // Включить поддержку Hive
.getOrCreate()
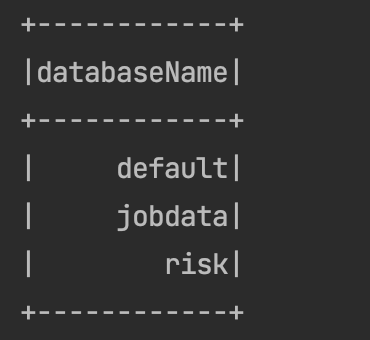
spark.sql("show databases").show()После выполнения этого кода можно найти только библиотеку куста по умолчанию, другие библиотеки найти невозможно.

Просто добавьте в код строку .config("hive.metastore.uris","thrift://hadoop1:9083").
val spark = SparkSession
.builder()
.master("spark://192.168.1.99:7077")
.config("hive.metastore.uris","thrift://hadoop1:9083")
.appName("YourAppName")
.enableHiveSupport() // Включить поддержку Hive
.getOrCreate()
spark.sql("show databases").show()Выполните его еще раз, и вы сможете нормально найти все библиотеки кустов——
Эта проблема засела у меня надолго, когда я впервые изучил spark-sql. Спросить совета было не у кого, поэтому я долго возился и изучал ее сам и, наконец, разобрался. Когда я это сделал, я почувствовал необъяснимое счастье.
5. Таблица HBase сопоставляется с таблицей Hive как внешняя таблица, а целочисленный столбец отображается как NULL.
При сопоставлении структуры таблицы HBase с Hive для создания внешней таблицы Hive созданный оператор изначально выглядит следующим образом:
CREATE EXTERNAL TABLE test(
ROW_KEY string,
PK string,
count1 int,
count2 int,
count3 int,
count4 int,
count5 int,
count6 int
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,INFO:PK,INFO:count1,INFO:count2,INFO:count3,INFO:count4,INFO:count5,INFO:count6")
TBLPROPERTIES ("hbase.table.name" = "test");Сценарий может работать нормально, но при входе в Hive HIve запрашивает, что все поля, соответствующие целым числам, имеют значение NULL. В нормальных условиях они должны быть числами 0 или отличными от 0. Это указывает на проблему при создании внешней таблицы Hive. ——

Позже он был изменен следующим образом, и Hive можно сопоставить со значением байтового целочисленного поля Hbase как обычно:
CREATE EXTERNAL TABLE test(
ROW_KEY string,
PK string,
count1 int,
count2 int,
count3 int,
count4 int,
count5 int,
count6 int
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,INFO:PK,INFO:count1#b,INFO:count2#b,INFO:count3#b,INFO:count4#b,INFO:count5#b,INFO:count6#b",'serialization.format'='1')
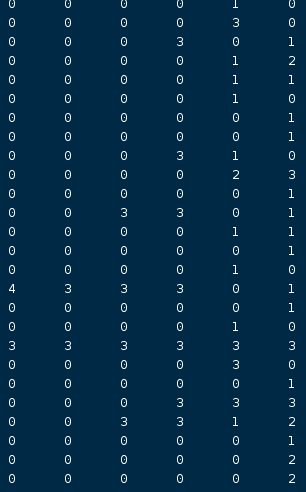
TBLPROPERTIES ("hbase.table.name" = "test");Снова запросите Hive и обнаружите, что доступны значения, соответствующие целым числам — —
Это правильное время,
6. Просмотр журналов методов foreach и foreachPartition RDD.
Журналы этих двух методов,Со стороны водителя его не видно.,То есть,даже если ты это сделаешьdriverжурнал выполнения>spark.log,Вы не можете просмотреть журналы метода в spark.log.
Когда я впервые играл в эту игру, я использовал println для печати журналов в foreach и foreachPartition и обнаружил, что журналы никогда не печатались.
Позже я обнаружил, что журналы foreach и foreachPartition необходимо просматривать в Spark Web.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
