Сверхподробное руководство по Kafka — объясняется все, от развертывания до разработки и принципов.
Прежде чем говорить о Kafka, предполагается, что вы имеете некоторые знания об очередях сообщений. Знайте режим очереди сообщений (режим «точка-точка», режим публикации/подписки), а также знайте преимущества очереди сообщений. Если вы не знаете, это не имеет значения. Зайдите в Baidu или Google для поиска. соответствующую подробную информацию. Итак, давайте дальше поговорим о Кафке.
Почему стоит выбрать Кафку
Существует множество промежуточных программ для обмена сообщениями. Такие как ActiveMQ, RabbitMQ, RocketMQ, Kafka. Итак, какие факторы вы обычно учитываете при выборе модели? Давайте сравним характеристики этих промежуточных программ.
характеристика | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
Производительность одной машины | Десять тысяч уровней, пропускная способность на порядок ниже, чем у RocketMQ и Kafka | Уровень 10 000, пропускная способность такая же, как у ActiveMQ. | Уровень 100 000, может поддерживать высокую пропускную способность | Уровень 100 000, высокая пропускная способность. Подходит для сбора журналов, вычислений в реальном времени и других сценариев. |
Влияние количества тем на пропускную способность | Количество тем может достигать сотен или тысяч, а пропускная способность немного снизится. Это главное преимущество RocketMQ: на одной машине он может поддерживать большое количество тем. | Когда количество тем увеличивается с десятков до сотен, пропускная способность «значительно падает». Поэтому на одной и той же машине Kafka старается следить за тем, чтобы количество тем не было слишком большим. Если вы хотите поддерживать масштабные темы, вам нужно добавить больше машинных ресурсов. | ||
Своевременность | уровень мс | Микросекундный уровень, это основная особенность RabbitMQ, задержка самая низкая. | уровень мс | Задержка в уровне В течение мс |
Доступность | Высокий, основанный на архитектуре «главный-подчиненный» для достижения высокой доступности. | То же, что ActiveMQ | Очень высокая, распределенная архитектура | Очень высокий, также распределенный |
надежность сообщения | Меньше вероятность потери данных | После оптимизации и настройки параметров можно добиться нулевых потерь. | Как и RocketMQ, он также может обеспечить нулевую потерю сообщений. | |
Поддержка функций | Функции в области MQ чрезвычайно полны. | Разработанный на основе Erlang, он обладает мощными возможностями параллелизма, чрезвычайно хорошей производительностью и низкой задержкой. | MQ имеет относительно полные функции, распределён и обладает хорошей масштабируемостью. | Функция относительно проста, в основном поддерживает простые функции MQ. Она широко используется для вычислений в реальном времени и сбора журналов в области больших данных и является стандартом де-факто. |
Краткое изложение плюсов и минусов
「ActiveMQ」
- Преимущества: Очень зрелый и мощный, используется во многих компаниях и проектах отрасли.
- Недостатки: Иногда вероятность потери сообщения мала. Более того, сообществ и отечественных приложений становится все меньше. Официальное сообщество теперь имеет. ActiveMQ Сопровождения 5.x становится все меньше и меньше, а выпуск версии занимает всего несколько месяцев. Редко используется в сценариях крупномасштабной пропускной способности.
「RabbitMQ」
- Плюсы: развитие языка erlang,Чрезвычайно хорошая производительность,Задержка очень низкая. Пропускная способность достигает 10 000 уровней,MQ имеет относительно полные функции. И интерфейс управления с открытым исходным кодом великолепен.,Это отлично работает. Сообщество относительно активно,Несколько частей версии публикуются почти каждый месяц. Некоторые отечественные интернет-компании в последние годы стали чаще использовать RabbitMQ.
- Недостатки: RabbitMQ имеет более низкую пропускную способность, поскольку механизм его реализации относительно тяжелый. Более того, динамическое расширение кластера RabbitMQ будет очень хлопотным, но я думаю, это нормально. На самом деле, это главным образом проблема, вызванная самим языком Erlang. Трудно читать исходный код, сложно настраивать и контролировать.
「RocketMQ」
- Достоинства: Интерфейс прост и удобен в использовании.,И в конце концов, это было применено в больших масштабах на Alibaba.,Гарантия бренда Alibaba. Обработка десятков миллиардов сообщений ежедневно,Возможность достижения крупномасштабной пропускной способности,Производительность тоже очень хорошая,распределенное расширение тоже очень удобно,С обслуживанием сообщества все в порядке,Надежность и доступность хороши.,Он также может поддерживать большое количество тем.,Поддержка сложных бизнес-сценариев MQ.
- Недостатки: активность сообщества относительно средняя, документация относительно проста, а интерфейс не соответствует стандартным спецификациям JMS. В некоторых системах для переноса требуется модификация большого количества кода. Существует также технология, представленная Alibaba. Вы должны быть готовы к риску потерять сообщество, если от этой технологии откажутся.
「Kafka」
- Преимущества: он предоставляет только меньше основных функций.,Но обеспечивает сверхвысокую пропускную способность,Задержка уровня мс,Чрезвычайно высокая Доступность и надежность,А распределенный можно расширять как угодно. В то же время для Kafka лучше всего поддерживать меньшее количество тем.,Гарантировано превышениевысокий Пропускная способность。
- Недостатки: Существует возможность повторного потребления сообщений. Это окажет очень незначительное влияние на точность данных. В области сбора больших данных и журналов это незначительное влияние можно игнорировать.
Из приведенного выше резюме мы знаем, что Kafka можно использовать для более простых очередей сообщений (если вам этого достаточно). А если вам требуется более высокая пропускная способность, то Kafka — ваш наиболее подходящий выбор.
Что такое Кафка
Kafka — это, по сути, контейнер для хранения данных.,Первоначально разработано корпорацией LinkedIn.,и в2011Открытый исходный код в начале года。2012Год10месяц сApache Выпускники инкубатора. Цель этого проекта — предоставить единую платформу с высокой пропускной способностью и низкой задержкой для обработки данных в реальном времени.
Kafka — распределенная очередь сообщений.。KafkaПри сохранении сообщения согласноTopicКлассифицировать,Человек, отправляющий сообщение, называется продюсером.,Получатель сообщения называется Consumer,Кроме того, кластер Kafka состоит из нескольких экземпляров Kafka.,Каждый экземпляр (сервер) называется брокером.

Композиционная архитектура Кафки

Из диаграммы архитектуры выше мы получаем несколько слов:
- Производитель. Производитель сообщений — это клиент, который отправляет сообщения брокеру Kafka;
- Потребитель: потребитель сообщений, клиент, который получает сообщения от брокера Kafka;
- Тема: можно понимать как очередь;
- Группа потребителей (CG): это метод, используемый Kafka для реализации широковещательной (отправки всем потребителям) и одноадресной рассылки (отправки любому потребителю) тематического сообщения. Тема может иметь несколько CG. Сообщение топика будет копировать (не совсем копировать,является концептуальным) для всей компьютерной графики,Но каждая часть будет отправлять сообщения только одному потребителю в CG. Если вам нужно реализовать трансляцию,Пока у каждого потребителя есть независимая CG. Для достижения одноадресной передачи все потребители должны находиться в одной группе CG. Используя CG, потребителей также можно свободно группировать без необходимости многократной отправки сообщений по разным темам;
- Брокер: сервер Kafka является брокером. Кластер состоит из нескольких брокеров. Один брокер может работать с несколькими темами;
- Раздел: для достижения масштабируемости очень большая тема может быть распределена между несколькими брокерами (т. е. серверами). Тема может быть разделена на несколько разделов, и каждый раздел представляет собой упорядоченную очередь. Каждому сообщению в разделе будет присвоен упорядоченный идентификатор (смещение). Kafka гарантирует только то, что сообщения будут отправляться потребителям в том порядке, в котором они указаны в разделе, и не гарантирует порядок темы в целом (среди нескольких разделов);
- Смещение: файлы хранилища Kafka именуются в соответствии с именем offset.kafka. Преимущество использования смещения в качестве имени заключается в том, что его легче найти. Например, если вы хотите найти местоположение по адресу 2049, просто найдите файл 2048.kafka. Конечно, первое смещение — 00000000000.kafka.
Операция Kafka в Linux
Вы можете подумать: если я установлю Kafka под Windows, все будет кончено. Зачем мне использовать его под Linux? Однако фактическое производство промежуточного программного обеспечения, такого как Kafka, должно быть развернуто в Linux. Мы, как разработчики, можем мало знать, как его развертывать, но изучить это всегда полезно.
скачать
скачатьадрес:http://kafka.apache.org/downloads
Мы выбираем это скачать

Автономное развертывание
Скопируйте сжатый пакет загрузки в Linux и разархивируйте его:

Исправлятьconfig/server.properties

Измените конфигурацию Zookeeper.
Запустить Кафку


Примечание. Если вы настроите отдельный Zookeeper,Zookeeper необходимо запустить до Запустить Кафку. Если у вас есть опыт использования докера,Вы можете использовать docker-compose для быстрого создания кластера zk.
Обнаружил, что есть процесс Кафки

Порт 9092.

Развертывание кластера
Если нам нужно развернуть кластер Kafka, нам нужно настроить несколько брокеров.
> cp server.properties config/server.properties config/server-1.properties
> cp server.properties config/server.properties config/server-2.properties
редактировать Конфигурационный файл
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
broker.idАтрибут — это имя каждого узла в кластере.,Это имя уникальное и постоянное. Далее нам просто нужно запустить два новых узла:
> bin/kafka-server-start.sh config/server-1.properties &
...
> bin/kafka-server-start.sh config/server-2.properties &
...
Теперь создайте копию как3новыйtopic:my-lvshen-topic
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-lvshen-topic
Команда запускаdescribe topicsПосмотреть кластерtopicинформация
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-lvshen-topic
Topic:my-lvshen-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-lvshen-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Ниже приводится объяснение выходной информации: Первая строка дает сводную информацию обо всех разделах.,Каждая строка ниже дает информацию о разделе. Потому что у нас есть только один раздел,Итак, есть только одна строка。LeaderЯвляется ли узел ответственным за все операции чтения и записи для данного раздела?。Каждый узел является лидером случайно выбранного частичного раздела.。
Replicasдакопировать Список узлов журнала разделов,Независимо от этих узловдаLeaderвозвращатьсядапросто живи。
isrдагруппа「синхронный」Replicas,даReplicasподмножество списка,он живет и на него указываютLeader。
Командная операция
Создать тему
Введите команду в каталог установки
bin/kafka-topics.sh --zookeeper 192.168.42.128:2181/kafka --create --topic LVSHEN-TOPIC --partitions 1 --replication-factor 1

Создалtopic:「LVSHEN_TOPIC」。
Просмотр информации о теме
bin/kafka-topics.sh --zookeeper 192.168.42.128:2181/kafka --describe --topic LVSHEN-TOPIC

Данные о производстве производителя
bin/kafka-console-producer.sh --broker-list 192.168.42.128:9092 --topic LVSHEN-TOPIC

Потребитель получает данные
bin/kafka-console-consumer.sh --bootstrap-server 192.168.42.128:9092 --topic 'LVSHEN-TOPIC'

Kafka Tool
Если вам слишком сложно использовать команды для просмотра,Мы можем использовать инструменты для просмотра(помещениеда Ваша производственная среда и ваша локальная среда были связаны)。Вот рекомендуемый инструмент「Kafka Tool」。

Как показано на рисунке, брокеры, темы и потребители будут отображаться слева, а соответствующая конкретная информация будет отображаться справа.
Способ SpringBoot по умолчанию для разработки Kafka Demo
Здесь я использую SpringBoot для разработки, а затем напишу демо-версию Java.
Импорт Maven
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.4.3.RELEASE</version>
</dependency>
Конфигурационный файл
## kafka ##
spring.kafka.bootstrap-servers=192.168.42.128:9092
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.consumer.group-id=test
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
#Определить тему
spring.kafka.topic=lvshen_demo_test
spring.kafka.listener.missing-topics-fatal=false
класс продюсера
@Component
@Slf4j
public class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${spring.kafka.topic}")
private String topic;
/**
* Отправить сообщение Кафке
*
* @param jsonString
*/
public void send(String jsonString) {
ListenableFuture future = kafkaTemplate.send(topic, jsonString);
future.addCallback(o -> log.info("Сообщение Kafka отправлено успешно:" + jsonString), throwable -> log.error("Не удалось отправить сообщение Кафки:" + jsonString));
}
}
Категория потребителя
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = "${spring.kafka.topic}")
public void listen(ConsumerRecord<?, ?> record) {
log.info("topic={}, offset={}, message={}", record.topic(), record.offset(), record.value());
}
}
тест
@Test
public void testDemo() throws InterruptedException {
log.info("start send");
kafkaProducer.send("I am Lvshen");
log.info("end send");
// Спите 10 секунд, чтобы у слушателя было достаточно времени, чтобы прослушать данные темы.
Thread.sleep(10);
}

Как показано выше, о потреблении консоли получены данные:
c.l.d.k.kafka.consumer.KafkaConsumer : topic=lvshen_demo_test, offset=1, message=I am Lvshen
Kafka Tool также показывает, что сообщение было получено:

Разработка пользовательской демо-версии Kafka
Если вы не хотите использоватьapplication.propertiesвkafkaконфигурация,Мы можем принять второй метод разработки.
определение Конфигурационный файл
config/kafka-config.properties
#consumer
kafka.bootstrapServers=192.168.42.128:9092
kafka.groupId=bootKafka
kafka.enableAutoCommit=true
kafka.autoCommitIntervalMs=100
kafka.sessionTimeoutMs=15000
#producer
kafka.retries=1
kafka.batchSize=16384
kafka.lingerMs=1
kafka.bufferMemory=1024000
Класс конфигурации
@Component
@ConfigurationProperties(prefix="kafka")
@PropertySource(value = {"classpath:config/kafka-config.properties"}, encoding = "utf-8")
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class KafkaConfigProperties {
private String bootstrapServers;
private String groupId;
private String enableAutoCommit;
private String autoCommitIntervalMs;
private String sessionTimeoutMs;
private String retries;
private String batchSize;
private String lingerMs;
private String bufferMemory;
}
//документ Класс конфигурации
@Component("kafkaConfigurations")
@EnableKafka
public class KafkaConfiguration {
@Autowired
private KafkaConfigProperties kafkaConfigProperties;
/**
* ConcurrentKafkaListenerContainerFactory — это инженерный класс, который создает прослушиватели Kafka. Здесь настраиваются только потребители.
*/
@Bean
public ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setPollTimeout(1500);
factory.setMissingTopicsFatal(false);
return factory;
}
/**
* Создайте потребительскую фабрику на основе параметров, заполненных в ConsumerProps.
*/
@Bean
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerProps());
}
/**
* Создайте фабрику производителей на основе параметров, заполненных senderProps.
*/
@Bean
public ProducerFactory<Integer, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(senderProps());
}
/**
* kafkaTemplate реализует такие функции, как отправка и получение Kafka.
*/
@Bean("kafkaTemplates")
public KafkaTemplate<Integer, String> kafkaTemplate() {
KafkaTemplate template = new KafkaTemplate<>(producerFactory());
return template;
}
/**
* Параметры конфигурации потребителя
*/
private Map<String, Object> consumerProps() {
Map<String, Object> props = new HashMap<>();
// адрес подключения
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaConfigProperties.getBootstrapServers());
// GroupID
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaConfigProperties.getGroupId());
// Отправлять ли автоматически
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// Частота автоматических отправок
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, kafkaConfigProperties.getAutoCommitIntervalMs());
// Настройка таймаута сеанса
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, kafkaConfigProperties.getSessionTimeoutMs());
// Как десериализуются ключи
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
// Как десериализуются значения
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
/**
* Конфигурация производителя
*/
private Map<String, Object> senderProps() {
Map<String, Object> props = new HashMap<>();
// адрес подключения
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaConfigProperties.getBootstrapServers());
// Повторить, 0 означает отключение механизма повтора.
props.put(ProducerConfig.RETRIES_CONFIG, kafkaConfigProperties.getRetries());
// Контролируйте размер пакета в байтах
props.put(ProducerConfig.BATCH_SIZE_CONFIG, kafkaConfigProperties.getBatchSize());
// Отправка пакетов с задержкой в 1 миллисекунду. Включение этой функции может эффективно сократить количество отправок сообщений производителем, тем самым увеличивая параллелизм.
props.put(ProducerConfig.LINGER_MS_CONFIG, kafkaConfigProperties.getLingerMs());
// Общий объем памяти, доступный производителю для буферизации записей, ожидающих отправки на сервер.
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, kafkaConfigProperties.getBufferMemory());
// Как сериализуются ключи
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
// Как сериализуются значения
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
}
Получить слушателя
@Component
@Slf4j
public class DemoListener {
/**
* Объявите идентификатор потребителя как демонстрационный и отслеживайте тему, имя которой — theme.quick.demo.
*/
@KafkaListener(id = "demo", topics = "topic.quick.demo")
public void listen(String msgData) {
log.info("demo receive : "+msgData);
}
}
тест
@Test
public void testDemoDepth() throws InterruptedException {
log.info("start send");
kafkaTemplate.send("topic.quick.demo", "this is a test for depth kafka");
log.info("end send");
// Спите 10 секунд, чтобы у слушателя было достаточно времени, чтобы прослушать данные темы.
Thread.sleep(500000);
}


Слушатель отслеживает данные в Kafka.
Механизм хранения Кафки
После приведенного выше описания,мы нашли「Partition」очень важно。на самом деле「Partition」также можно разделить на「Segment」。Что касается того, чтода「Segment」,Подробности будут приведены ниже.
Как хранятся файлы в разделе:

Каждый раздел (каталог) эквивалентен гигантскому файлу, который равномерно распределен на несколько сегментов (сегментов) файлов данных одинакового размера. Но каждый сегмент Количество файловых сообщений не обязательно одинаково. Этот вид характеристики удобен. segment Файл удаляется быстро. (По умолчанию размер каждого файла составляет 1 ГБ).
Каждый раздел должен поддерживать только последовательное чтение и запись. Жизненный цикл сегментного файла определяется параметрами конфигурации сервера.
Преимущество этого метода в том, что он позволяет быстро удалять ненужные файлы и эффективно улучшать использование диска.
Хорошо, это краткое введение в Kafka. Если вы хотите узнать больше, вы можете посетить официальный сайт, чтобы узнать больше о нем.
Почему Кафка так хорошо работает?
Быстрое чтение и письмо
Kafka будет записывать данные на диск последовательно, и большинство дисков, которые мы используем, являются механическими. Механическая структура серебряной пластины требует больше всего времени для изучения. Таким образом, произвольный ввод-вывод на жестком диске потребляет много ресурсов. Если это последовательный ввод-вывод, производительность значительно повысится.
MMFile
KafkaДанные недав реальном времениписатьдиск(「Memory Mapped Files」),Он использует все преимущества современных операционных систем.«Пейджинговое хранилище»Приходи и заберивысокийI/Oэффективность。Операционная система сама выберет подходящее время для записи данных на жесткий диск.。Но это также было бы ненадежно,написать「mmap」Данные в действительности ненаписатьжесткий диск,Операционная система фактически записывает данные на жесткий диск, когда программа активно вызывает сброс.
KafkaПредоставляется параметр——producer.typeконтролироватьда Нетдаинициативаflush,еслиKafkaнаписать「mmap」сразу послеflushа затем вернутьсяProducerВызов синхронный (sync);писать「mmap」Вернитесь сразу послеProducerНе звонятflushВызов асинхронный (async)。
нулевая копия
Когда потребитель запрашивает у брокера информацию,「kafka」использовать нулевая копия(zero-copy) , установить прямое сопоставление между дисковым пространством и памятью, данные больше не копируются в «буфер пользовательского режима», а напрямую копируются в буфер сокета.

Общее чтение и запись происходит следующим образом: будет происходить переключение между пользовательским режимом и режимом ядра, и это переключение также занимает относительно много времени.
Если вы используете нулевую копию, она не пройдет через пользовательский режим.

О нулевой Подробное описание копия вы можете посмотреть в другой моей статье: [Использована нулевая копия технологии Kafka, конечно быстро].


Как настроить размер экрана в PR. Учебное пособие по настройке размера видео в PR [подробное объяснение]
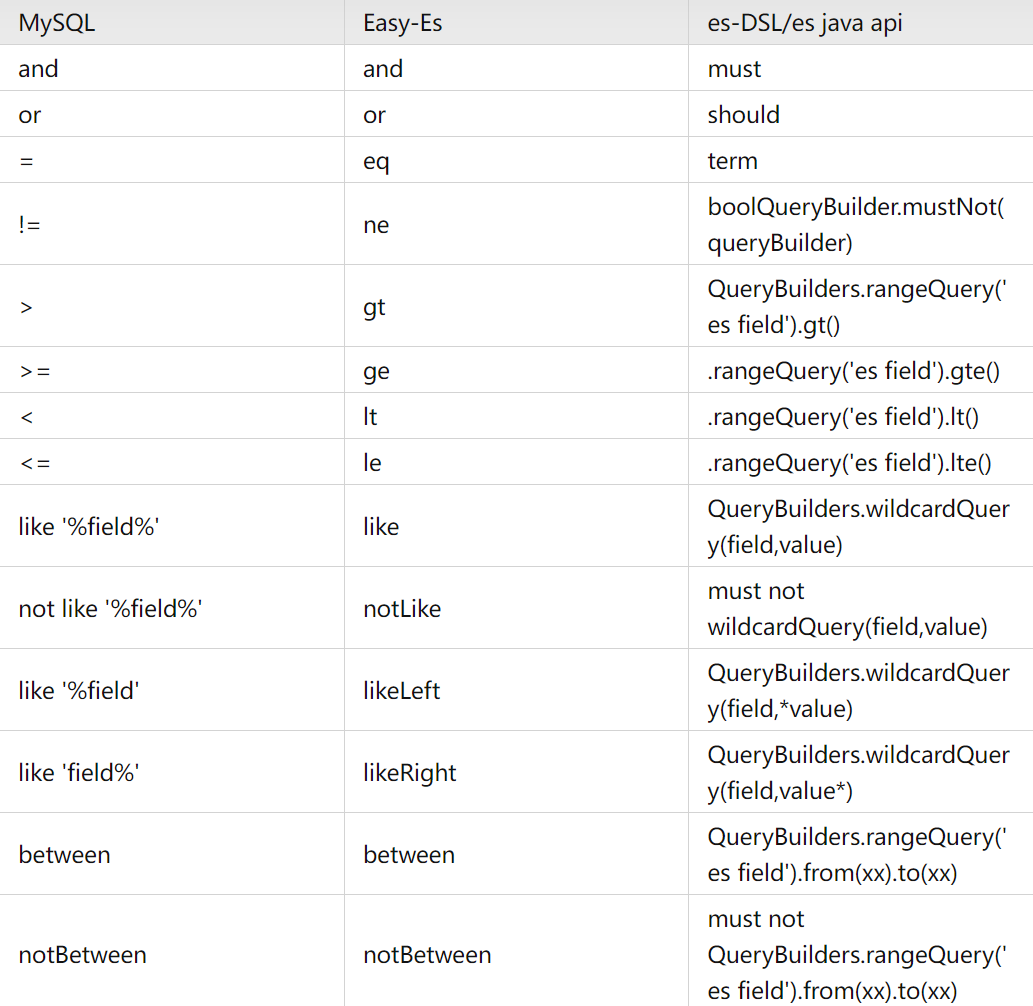
Элегантный и мощный: упростите операции ElasticSearch с помощью easy-es

Проект аутентификации по микросервисному токену: концепция и практика

【Java】Решено: org.springframework.http.converter.HttpMessageNotWritableException.
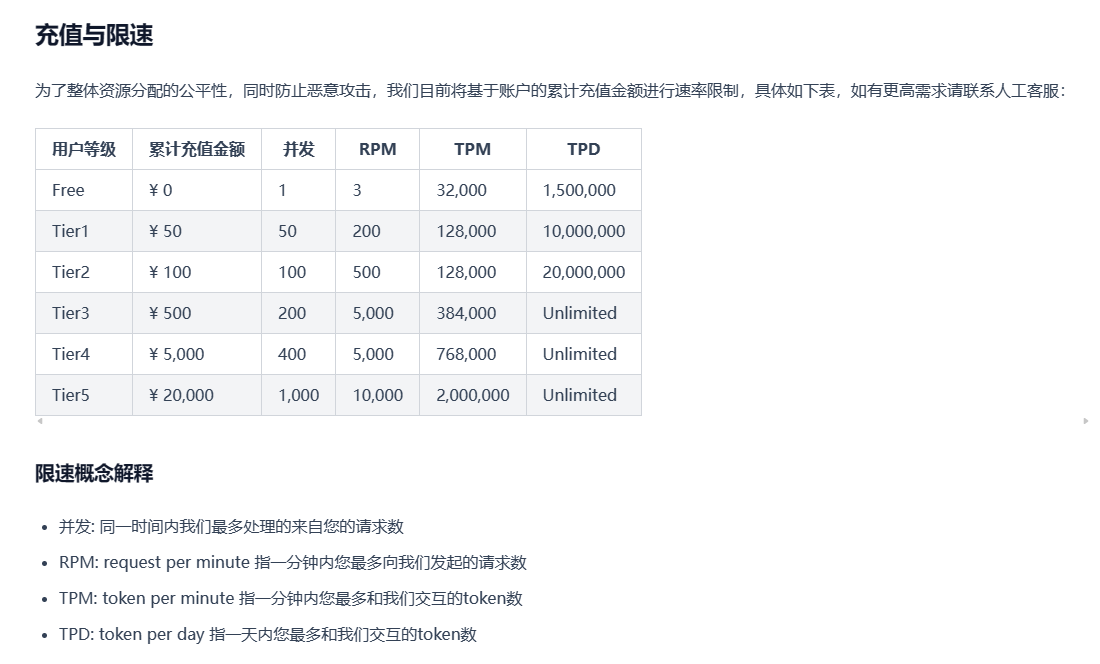
Изучите Kimi Smart Assistant: как использовать сверхдлинный текст, чтобы открыть новую сферу эффективной обработки информации
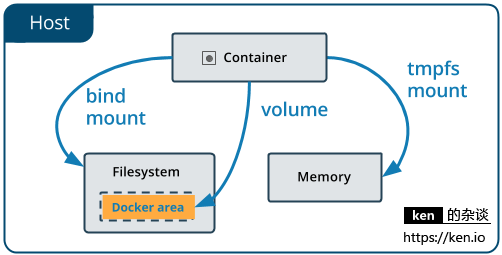
Начало работы с Docker: использование томов данных и монтирования файлов для хранения и совместного использования данных

Использование Python для реализации автоматической публикации статей в публичном аккаунте WeChat
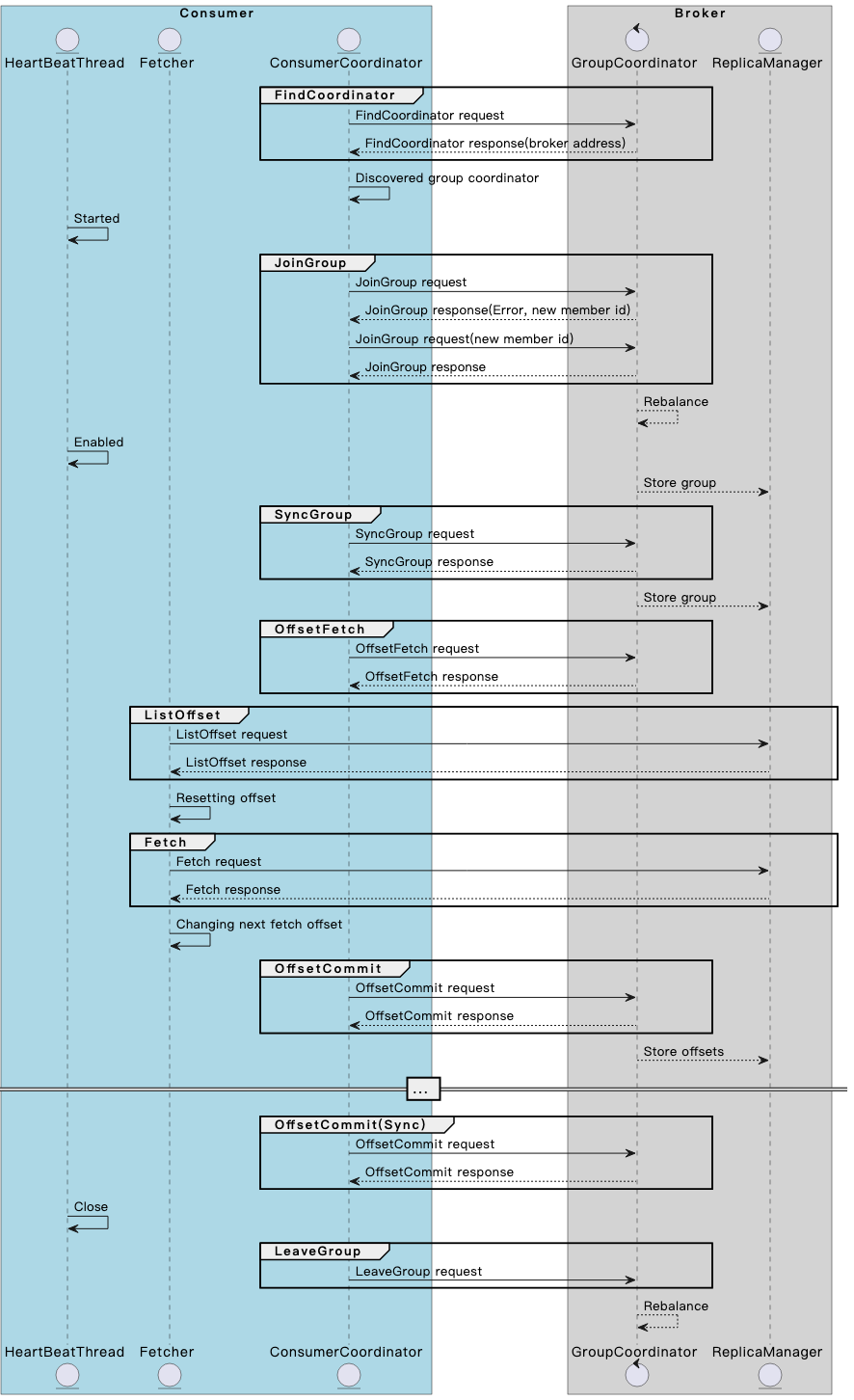
Разберитесь в механизме и принципах взаимодействия потребителя и брокера Kafka в одной статье.
Spring Boot — использование Resilience4j-Circuitbreaker для реализации режима автоматического выключателя_предотвращения каскадных сбоев

13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS

Руководство по загрузке, установке и использованию SVN «Рекомендуемая коллекция»

Интерфейс PHPforwarding_php отправляет запрос на получение

Создавайте и защищайте связь в реальном времени с помощью SignalR и Azure Active Directory.

ВичатПубличная платформаразвивать(три)——ВичатQR-кодгенерировать&Сканировать кодсосредоточиться на
[Углубленное понимание Java IO] Используйте InputStreamReader для чтения содержимого файла и легкого выполнения задач преобразования текста.

сравнение строк PHP
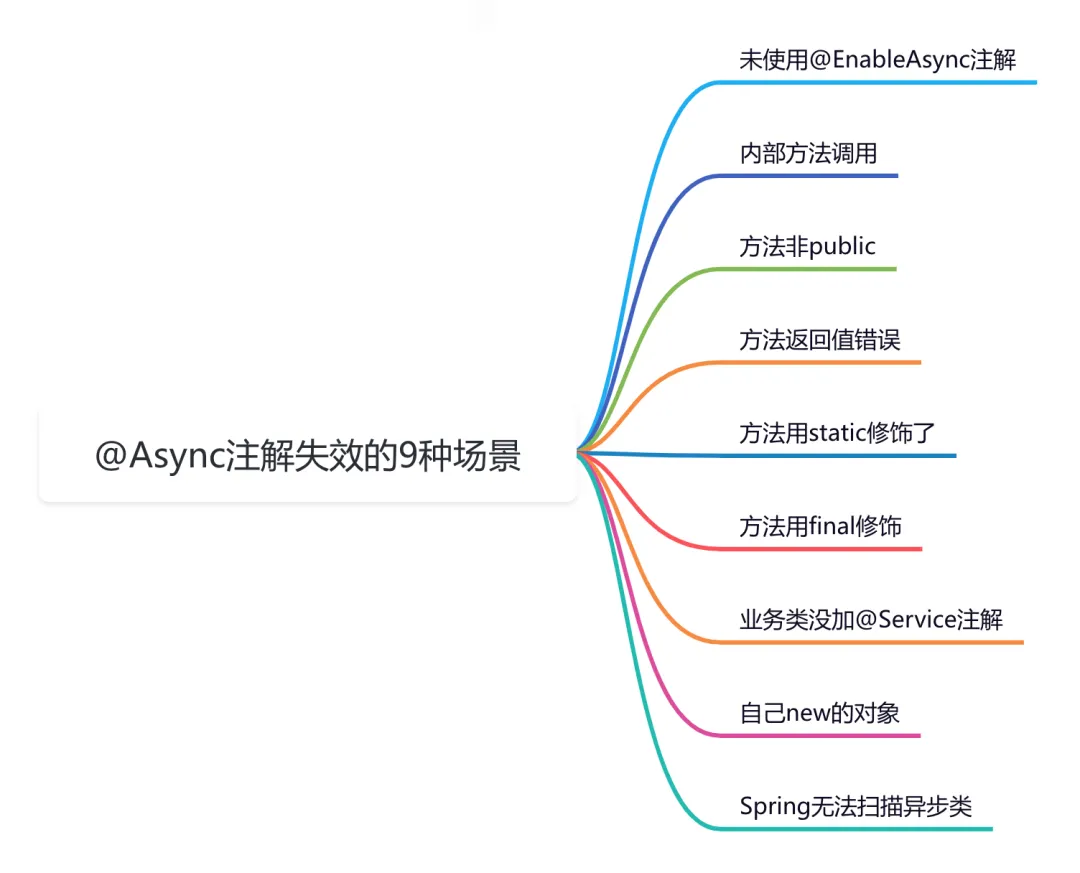
9 сценариев асинхронного сбоя @Async

Эффективная обработка запланированных задач: углубленное изучение секретов библиотеки APScheduler на Python

Рекомендации по облегченному артефакту развязки внутренних компонентов Spring Event (событие Spring)
Go: Лесоруб-лесоруб на колесах Введение
