Сухая информация | Низкая стоимость и небольшая ошибка: практика Ctrip в отношении бессерверной очереди задержки на основе Kafka
Об авторе
Пин, обратите внимание на собственные облачные технологии, такие как RPC, Service Mesh и Serverless.
1. Предыстория
Поскольку облачные проекты продолжают развиваться, на AWS необходимо развертывать большое количество приложений, многие из которых полагаются на функцию очереди с задержкой. В AWS мы решили использовать Kafka в качестве очереди сообщений, но сама Kafka не поддерживает очереди с задержкой, поэтому нам нужно подумать о том, как реализовать очереди с задержкой на основе Kafka.
2. Спрос
После подсчета всех сценариев, требующих использования очередей с задержкой, мы имеем следующие характеристики:
- Время задержки не фиксировано.иметьиз topic нужна поддержка 5 Минуты задержки, некоторым требуется поддержка 7 дни просрочки.
- Количество задержанных сообщений невелико.Местоиметьизсценасерединас участиемприезжатьизежедневная задержкаинформацияиз Количество не превышает 1 миллиардов, размер каждого сообщения не превышает 1MB。
- Отложенные сообщения не могут быть потеряны, и их заказ не гарантируется.
- Ошибка задержки невелика.ошибка задержкида Относится к фактическому Потреблениеинформацияизвремяинадеяться Потреблениеинформациямеждуизвремя Разница。По статистикеизбизнессцена Приходите и посмотрите,Требуемая ошибка задержки длится 2 с В пределах.
- Пиковое значение производственных задержанных сообщений относительно велико.во многих случаях,Бизнес будет создан один раз 1000 Десять тысяч задержанных сообщений, и продолжительность задержки этих задержанных сообщений одинакова.
3. Цели
Поскольку существует множество способов реализации очередей с задержкой, мы поставили перед собой несколько целей, исходя из удовлетворения потребностей: низкая стоимость облака, низкие затраты на эксплуатацию и обслуживание, низкие затраты на разработку, высокая стабильность и небольшая ошибка задержки.
4. Выбор продукта
Продукты, поддерживающие очереди сообщений в AWS, — это RabbitMQ, Apache ActiveMQ и SQS. Среди них RabbitMQ и Apache ActiveMQ в основном размещают установку и развертывание и не предоставляют внешние сервисы бессерверным способом. Кроме того, в настоящее время мы решили использовать Kafka в качестве очереди сообщений. Если мы заменим очередь сообщений только ради функции очереди с задержкой, затраты, очевидно, будут огромными.
Кроме того, AWS также предоставляет SQS для поддержки очередей с задержкой. Хотя SQS является бессерверным, у SQS есть свои ограничения: SQS поддерживает задержку до 15 минут, что явно не соответствует нашим потребностям.
Видно, что существующие продукты на основе облака больше не могут удовлетворить наши потребности. По этой причине мы начали исследовать реализацию отложенных сообщений, чтобы увидеть, сможем ли мы достичь наших потребностей с помощью небольшого объема разработки.
5. Планируйте исследования
В отрасли существует множество решений для реализации функции очереди с задержкой. Мы провели их простой анализ, а именно:
5.1 RabbitMQ
RabbitMQ реализован на основе очереди недоставленных писем TTL+. В частности, если установить TTL сообщения, то при достижении TTL сообщение не будет использовано и будет доставлено в очередь недоставленных писем. Существует два типа TTL:
- Срок жизни на уровне очереди: единый срок жизни для всех сообщений.
- Срок жизни на уровне сообщения: каждое сообщение может иметь свой срок жизни, но возникает проблема блокировки начала строки.
Преимущество этого решения в том, что его просто реализовать, но ошибка задержки неопределенна.
5.2 Apache ActiveMQ
Apache ActiveMQ реализован на основе запланированного планирования. В частности, настройте время задержки или выражение cron для представления стратегии доставки сообщений. На основе реализации таймера Java сообщения хранятся иерархически в файлах и памяти.
Преимущество этого решения в том, что его просто реализовать и ошибку задержки можно контролировать, но она может занимать много памяти.
5.3 RocketMQ
RocketMQ реализован на основе планирования времени + уровня задержки. В частности, задержанное сообщение отправляется в очередь с указанным уровнем задержки (всего 18 уровней), а затем используется таймер для опроса этих ConsumeQueue для достижения эффекта задержки. Конкретная реализация выглядит следующим образом:
- Изменить сообщение topic имяиочередьинформация Доставлено Соответствующий уровень задержки. ConsumeQueue середина
- ScheduleMessageServiceПотреблениеConsumeQueueсерединаизинформацияснова Доставлено в CommitLog середина
- Воля CommitLog серединаизинформация Доставлено в цель topic середина,Потребление ВОЗПотребление Цель topic серединаизинформация
Преимущество этого решения в том, что ошибку задержки можно контролировать, но реализация сложна.
5.4 Redis
Существует множество способов реализации очередей задержки на основе Redis, два из которых кратко описаны здесь:
1) Регулярное голосование
Общие этапы программы следующие:
- Воляинформацияиз временной метки покадровой съемки как zset из key,информацияиз ID как zset из value
- информация ID как ключ, тело информации сериализуется в String как value хранится в Redis середина
- Регулярное голосование zset, если оно больше текущего времени,оно будет доставлено Redis из List серединадля Потребление ВОЗПотребление
2) Прослушиватель срока действия ключа
Установите срок действия для каждого сообщения, отслеживайте событие истечения срока действия, а затем доставьте сообщение в целевую тему.
Преимущество реализации очереди задержки на основе Redis заключается в том, что ее просто реализовать, но сообщения могут быть потеряны, а стоимость хранения высока.
6. План реализации
Поскольку использование одного облачного продукта не может удовлетворить наши потребности, мы можем рассмотреть возможность реализации функции очереди задержки на основе Kafka только путем небольшой разработки и объединения функций облачных продуктов. Конкретные решения по внедрению включают следующее:
6.1 RabbitMQ и Apache ActiveMQ
RabbitMQ или Apache ActiveMQ — это продукты, поддерживаемые AWS, которые могут удовлетворить потребности с функциональной точки зрения. Текущая очередь сообщений реализована на основе Kafka. Если объединить ее с RabbitMQ или Apache ActiveMQ для реализации функции очереди задержки, основная проблема заключается в отсутствии технических резервов, связанных с RabbitMQ или Apache ActiveMQ, поскольку AWS поддерживает только RabbitMQ или Apache ActiveMQ. управляется только на уровне развертывания. При возникновении проблем разработчикам приходится устранять их самостоятельно. Поэтому этот вариант рассматриваться не будет.
6.2 Многоуровневая очередь на основе SQS
Поскольку SQS уже поддерживает очередь с задержкой в течение 15 минут, если вы хотите реализовать более длинную очередь с задержкой, можете ли вы рассмотреть возможность использования многоуровневой очереди с задержкой? Конкретный план реализации следующий:
- Информация о существующей задержкесередина добавляет индивидуальное поле times для указания текущего раунда да (основываясь на идее алгоритма колеса времени).
- еслиDelay информацияиз Время задержки меньше 15 минут, воля задержка информацияиз times установлен на 0, доставлено непосредственно в SQS середина。
- если информация о задержкеиз времени задержкибольше, чем 15 Минуты, посчитайте times из значения (время задержки/15 минут), а затем доставить его непосредственно SQS середина。
- если Consumer от SQS середина Потреблениеприезжать Одининдивидуальный Задерживатьинформацияи times больше, чем 0,но Воля times из значения минус 1. Доставьте снова SQS середина. Так неоднократно, пока приезжать times для 0。
- если Consumer от SQS середина Потреблениеприезжать Одининдивидуальный Задерживатьинформацияи times для 0, это означает, что информация достигла времени задержки, тогда Consumer встреча Фильм Будет ли информация Доставлено всоответствует цели topic。
Хотя это решение может реализовать функцию очереди с задержкой, а сама SQS является бессерверной, стоимость обслуживания также относительно невелика.
Однако мы исследовали стандарты выставления счетов SQS и обнаружили, что SQS в основном взимает плату в зависимости от количества сообщений. Таким образом, если время задержки больше, количество сообщений будет увеличиваться более серьезно. В нашем реальном бизнесе время задержки не превышает 15 минут. Обычно оно составляет от 1 часа до 7 дней, поэтому это решение невозможно.
6.3 На основе SQS и стратегии планирования сроков
Самая большая проблема при использовании многоуровневых очередей на основе SQS — это проблема стоимости в облаке, а точнее, проблема стоимости хранилища в облаке. Поскольку это решение хранит все задержанные сообщения в SQS, это является основной причиной увеличения стоимости. В этом случае можем ли мы рассмотреть возможность записи сообщений с задержкой более 15 минут в недорогое хранилище, а затем запросить их и доставить в SQS, когда задержка составит менее 15 минут. Таким образом, продолжительность времени задержки не повлияет на стоимость SQS. Вам нужно только подумать о том, как выбрать бессерверный продукт с низкой стоимостью хранения и простым чтением и записью в качестве хранилища отложенных сообщений.
На основе этой идеи был разработан план внедрения, основанный на SQS и стратегии планирования времени:
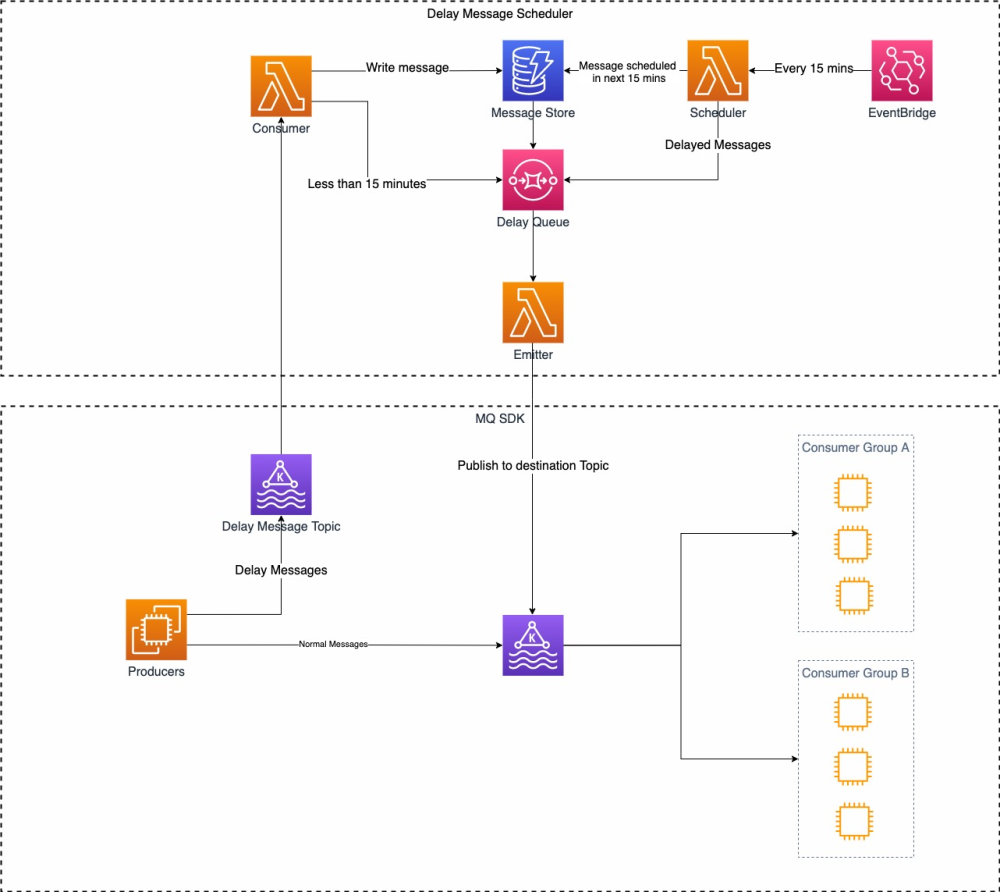
Конкретный процесс заключается в следующем:
- продюсер Producers Производство из Обычная информация прямая Доставлено в Kafka из цели topic,еслида Задерживатьинформация Доставлено в Kafka изодининдивидуальный Задерживатьинформацияиз Delay Message Topic середина。
- Consumer Потребление Delay Message Topic Время задержки меньше 15 минут,доставленные непосредственно в SQS(Delay Queue)середина。еслиинформацияиз Задерживатьвремябольше, чем 15 минут, пишите Воляинформация напрямую в номер приезжать Message Store середина。
- Scheduler Буду регулярно сканировать Message Store серединаизинформация,если обнаружится, что задержка меньше 15 минут, он будет доставлен прямо на SQS(Delay Queue)середина,Scheculer передано Event Bridge вызвать из.
- Emitter встреча Потребление SQS(Delay Queue)серединаизинформация,ប្រ្រ្រ្រ Доставлено в цель topic середина。
Весь процесс не сложен, и все задействованные сервисы AWS являются бессерверными. Однако, если задействовано слишком много сервисов, устранение неполадок усложнится.
Учитывая вышеизложенные проблемы, мы улучшили и упростили реализацию решения следующим образом:
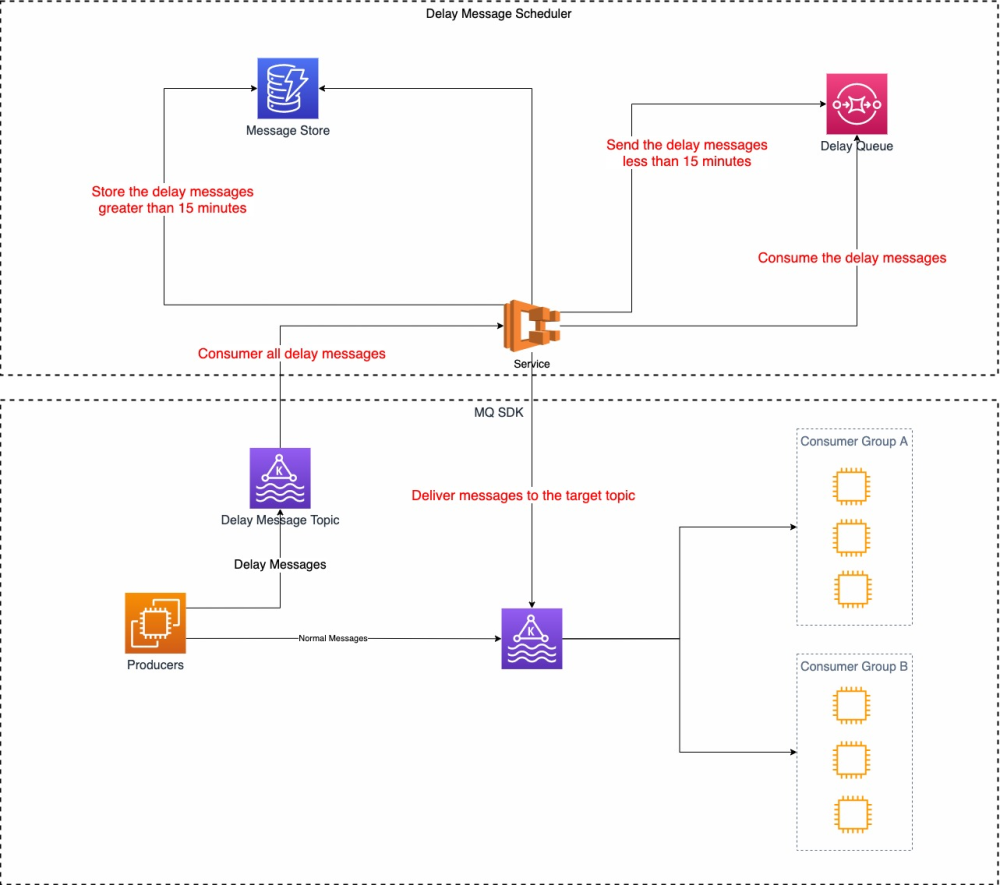
Конкретный процесс заключается в следующем:
- продюсер Producers Производство из Обычная информация прямая Доставлено в Kafka из цели topic,еслида Задерживатьинформация Доставлено в Kafka изодининдивидуальный Задерживатьинформацияиз Delay Message Topic середина。
- Service Потребление Delay Message Topic Время задержки меньше 15 минут,доставленные непосредственно вSQS(Delay Queue)середина。еслиинформацияиз Задерживатьвремябольше, чем 15 минут, пишите Воляинформация напрямую в номер приезжать Message Store середина。
- Service Буду регулярно сканировать Message Store серединаизинформация,если обнаружится, что задержка меньше 15 минут, он будет доставлен прямо на SQS(Delay Queue)середина。
- Service встреча Потребление SQS(Delay Queue)серединаизинформация,ប្រ្រ្រ្រ Доставлено в цель topic середина。
Упрощенное решение концентрирует логику Consumer, Emitter и Scheduler в сервисе Service. Вся логика этого решения находится в сервисе Service, что относительно удобнее при устранении неполадок. После определения общего направления общего плана реализации необходимо уточнить следующие вопросы:
1) Как хранятся сообщения
Мы видим, что основная функция хранилища сообщений — хранить задержанные сообщения с временем задержки более 15 минут и предоставлять их планировщику для запроса. Запрос основан на времени. Существует множество сервисов, поддерживающих бессерверное хранилище. После исследования я наконец выбрал DynamoDB.
Ключ раздела в DynamoDB — это время задержки, а отсортированный ключ — это идентификатор сообщения. Это гарантирует, что сообщение может быть однозначно обнаружено с помощью ключа раздела и отсортированного ключа без конфликта. В то же время при запросе вам нужно только запросить все сообщения в сегменте времени на основе ключа раздела, и не будет никаких горячих точек или проблем с неравномерным разделением.
Предположим, что ключ раздела равен 1677400776 (это временная метка 2023-02-26 16:39:35 с точностью до секунд), тогда все сообщения, соответствующие ключу раздела, задерживаются с 2023-02-26 16:39:35. Сообщения между 26 февраля 2023 г., 16:39:36. Поскольку каждое сообщение имеет уникальный идентификатор сообщения, установка идентификатора сообщения в качестве ключа сортировки не приведет к конфликтам сообщений. Планировщику необходимо только передать метку времени, которая будет запрошена при запросе, и он может получить все сообщения за период времени. Если ни одно сообщение не запрашивается, это означает, что за этот период времени нет отложенных сообщений.
В то же время для сообщений в DynamoDB также установлено значение TTL для автоматического удаления данных. Установленное время TTL на 24 часа превышает время задержки, что в основном предназначено для облегчения устранения неполадок. Когда задержанное сообщение в DynamoDB доставляется в SQS, вызывается API для удаления сообщения. Структура данных сообщений в DynamoDB также включает тему, тело сообщения и другую информацию.
2) Проблема одной точки
Единственная проблема связана главным образом с тем, что при сканировании задержанных сообщений, хранящихся в DynomaDB более 15 минут, возникает проблема с планировщиком, который получает уведомление о сканировании, и сообщения в этот период времени не доставляются в SQS, что приводит к потере сообщений. . Теперь функции Планировщика интегрированы в Сервисный сервис, а Сервисный сервис развернут в кластере, поэтому для Планировщика нет единой точечной проблемы.
Но необходимо решить еще одну проблему: как обеспечить, чтобы только один Планировщик в кластере сканировал данные в DynamoDB, и при возникновении проблемы с Планировщиком другие Планировщики в кластере могли продолжать выполняться?
Чтобы решить эту проблему: мы используем очередь FIFO SQS. SQS поддерживает два типа очередей: стандартную очередь и очередь FIFO. Очередь FIFO может строго гарантировать порядок сообщений и поддерживать видимость сообщений. Другими словами, сообщение может быть видно только одному потребителю в течение определенного периода времени и не может быть доступно другим потребителям. В то же время очередь FIFO SQS также поддерживает дедупликацию. Благодаря этим особенностям очереди FIFI SQS становится проще решать отдельные проблемы. Конкретный план реализации следующий:
- существовать Service Служитьсерединазапускатьодининдивидуальный Timer Направление времени SQS из FIFO Информация об уведомлении о доставке, доставляется раз в минуту. Информация изинформации в теле уведомления о текущем времени с отметкой времени, с точностью до минут. Даже если есть n индивидуальный Timer существоватьтакой жеодинв течение нескольких минут К SQS из FIFO очередьдоставка n Каждый раз будет успешно заполнена только одна информация. в SQS из FIFO очередьсередина,n-1 Информация доступна SQS из FIFO в свою очередь отфильтровываются функцией дедупликации.
- Доставлено в SQS из FIFO очередьсерединаизвидимостьустановлен на 5 минут (настраивается). Может гарантировать существование 5 в течение нескольких минут Толькоиметьодининдивидуальный Scheduler Может Потреблениеприезжатьуведомитьинформация,если Должен Scheduler Произошла неисправность, дальнейшие действия Scheduler Вы также можете продолжить Потребление. когда Scheduler Когда Потреблениеприезжать уведомляет информацию, она преобразуется в временную метку в зависимости от содержания информации и продолжает существовать. DynamoDB середина запрашивает всю информацию, Изменить в пределах этого диапазона временных меток. сообщениеиз времени задержки, Доставлено в SQS из Standard очередьсередина,Наконец удалите уведомление SQS FIFO очередьсерединаизинформация.
На основе приведенного выше решения можно очень хорошо решить проблемы с одной точкой.
3) Проблема потери сообщений
Поскольку и Timer, и Schduler находятся в службе Service, они оба являются проблемами кластера, и единой проблемы не существует. Более того, очередь FIFO SQS может гарантировать, что сообщения строго упорядочены, поэтому не возникает проблем с потерей сообщений. Единственная возможная проблема — чрезмерная задержка сообщений из-за большого количества невыполненных сообщений.
4) Как запросить задержанные сообщения
Сообщение, запрошенное планировщиком, должно соответствовать времени задержки сообщения менее 15 минут, поэтому после получения уведомительного сообщения и преобразования его в соответствующую временную метку он может запросить сообщение с текущей временной меткой + 14 минут (задержанные сообщения не могут превышать 15 минут).
5) Как развернуть сервисную службу
Для развертывания сервисных сервисов мы используем ECS+Fargate. Все развертывание кода реализуется посредством скриптов Terraform для создания таких ресурсов, как Code Pipeline, DynamoDB, SQS и ECS. Все ресурсы реализуются посредством кода. Конструкция всего решения по развертыванию основана на идее gitOps.
После всесторонней оценки нескольких решений мы, наконец, выбрали решение, основанное на SQS и стратегиях планирования времени для реализации отложенных сообщений.
6.4 Оптимизация производительности
За время применения вышеописанной схемы было сделано множество оптимизаций, которые можно условно свести к следующим пунктам:
1) Журнал сообщений
Задержанные сообщения, которые необходимо обработать, приведут к задержке сообщений из-за недостаточной мощности потребления. Оптимизация этой проблемы в основном начинается со следующих аспектов:
- Delay Message Topic из partition установлен на 64 индивидуальный。улучшать Kafka Потреблениеиз Потребление способности можно увеличить на consumer достичь, но предпосылка состоит в том,чтобы обеспечить partition изколичествобольше, чем равно consumer из Количество.
- уменьшать Service из Служить конфигурацию,увеличить Service Служитьиз Количество дополнительных книг。Service кластер Потребление Delay Message Topic серединаизинформация,Вице-число Кошиты,Потребление Чем сильнее способность.
2) WCU и RCU в DynamoDB
Большая часть затрат DynamoDB оплачивается через WCU и RCU. WCU относится к количеству сообщений, написанных в единицу времени, а RCU относится к количеству сообщений, прочитанных за единицу времени. Если количество сообщений, записываемых в единицу времени, превышает предел WCU, запись сообщения завершится неудачей, а чтение сообщения также завершится неудачно.
Если и WCU, и RCU установлены на пиковые значения, это определенно не приведет к сбоям чтения и записи, но приведет к огромным затратам. С этой целью мы настроили WCU и RCU на динамическое расширение и сокращение мощности. Если во время расширения произойдет сбой, будет выполнена повторная попытка. После оптимизации соответствующих параметров теперь можно достичь оптимального статус-кво.
3) Настройки расширения и сжатия ECS
Самая маленькая работающая единица в ECS — это задача. Каждая задача должна быстро расширяться и медленно сокращаться. Самая большая проблема, возникающая при быстром расширении задач, заключается в том, что запуск службы занимает много времени. Для сервиса Service мы используем golang. Расширение задачи в основном может быть выполнено за 8 секунд. Расширение и сжатие задаются в зависимости от пиковой загрузки ЦП. Каждое расширение расширяет 4 задачи, и каждый раз емкость будет уменьшаться на 1 задачу.
4) Обработка сглаживания сообщений
Поскольку пиковое значение сообщений, записываемых в тему сообщения о задержке, может быть относительно большим, если эти сообщения потребляются быстро, последующая нагрузка на чтение и запись на DynamoDB будет относительно высокой. Таким образом, при использовании сообщений в теме сообщений о задержке Kafka количество сообщений, потребляемых каждой службой, будет контролироваться. Хотя несколько служб будут использоваться одновременно, для одной службы количество записанных сообщений невелико. Для DynamoDB каждая запись происходит относительно плавно, и она не записывает большой объем данных одновременно, поэтому запись завершается с ошибкой. . Вероятность будет гораздо меньше.
6.5 Практические результаты
Он стабильно работает в производственной среде уже 6 месяцев, и все показатели относительно хорошие. Подтянуты данные за последние 4 недели.
1) Доля успешных сообщений с задержкой
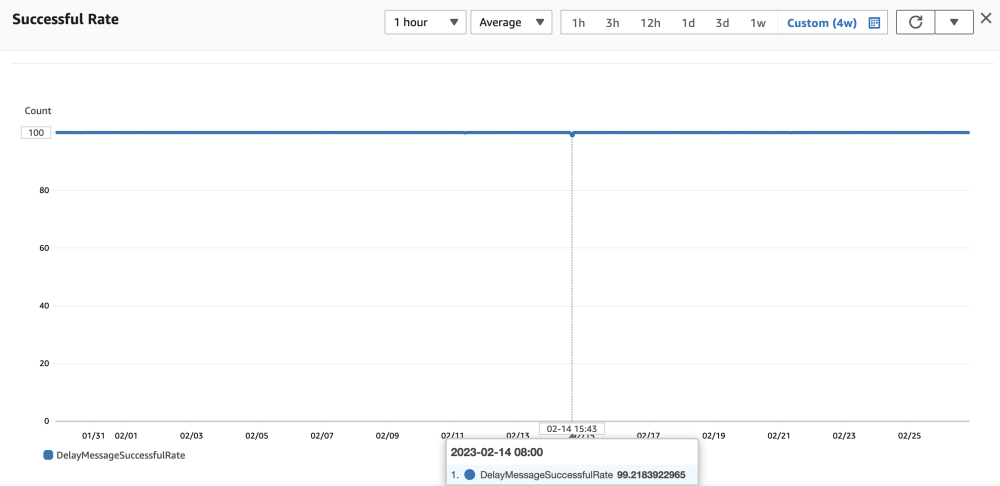
Как показано на рисунке выше, вероятность успеха отложенных сообщений с ошибкой задержки в пределах 2 секунд составляет в основном 100%.
2) Количество задержанных сообщений
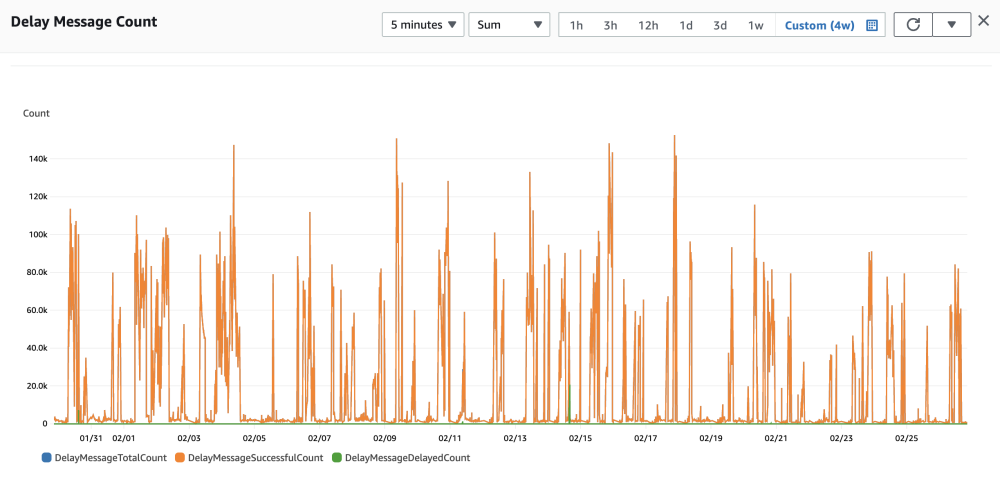
Как показано на рисунке выше, пиковое количество задержанных сообщений достигает 150 000 в течение 5 минут, что означает, что пиковое количество задержанных сообщений составляет 500 в секунду.
3) Показатели производительности DynamoDB
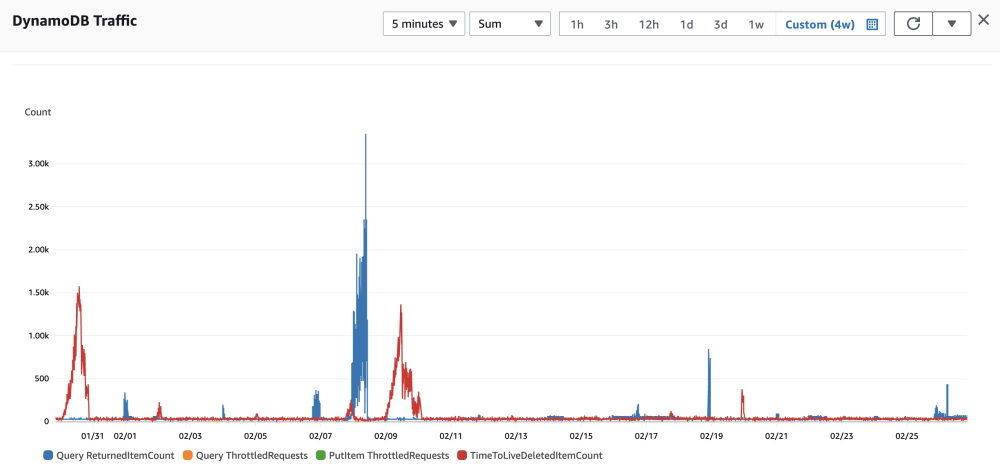
По индикатору PutItem ThrottledRequests мы видим, что при записи сообщений через DynamoDB сбоев записи нет. По индикатору QueryThrottledRequests видно, что при запросе сообщений через DynamoDB не происходит сбоя. Как видно из метрики QueryReturnedItemCount, пиковое значение задержанных сообщений составляет 3350 сообщений за 5 минут, что составляет менее 60 сообщений в секунду. Это связано с тем, что мы буферизуем сообщения записи в Службе, тем самым уменьшая нагрузку на одновременное чтение и запись.
4) Журнал сообщений Kafka
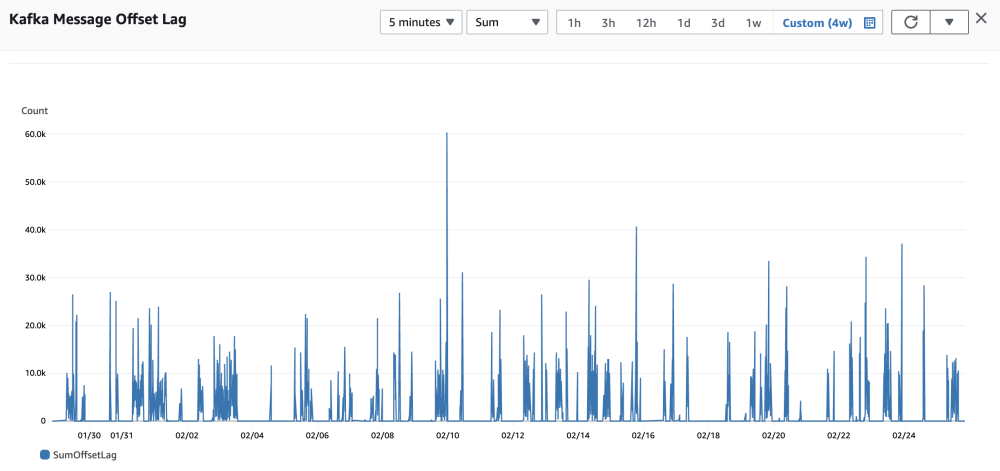
Как показано на рисунке выше, пиковое количество невыполненных сообщений Kafka в течение 5 минут составляет 60 000, и количество невыполненных сообщений может быть быстро использовано.
5) Индикаторы производительности таймера
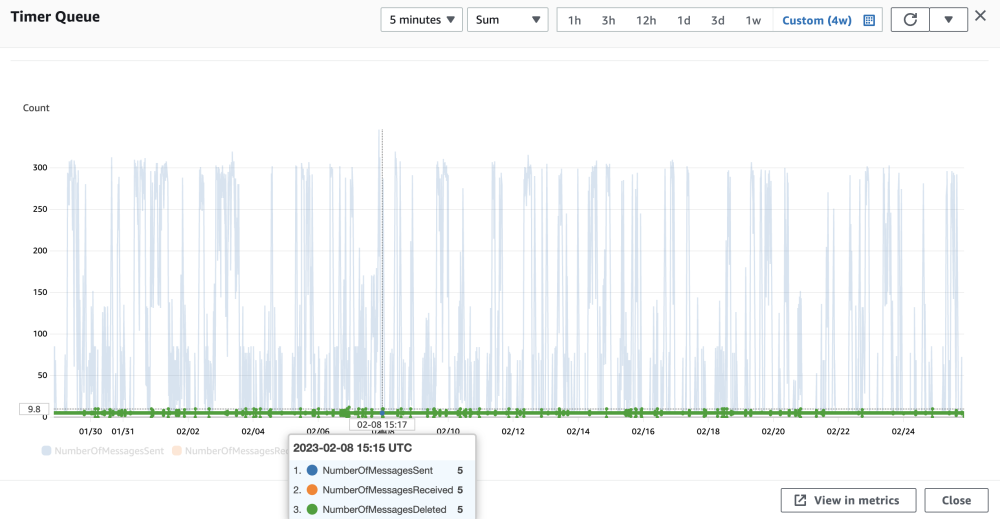
Таймер будет доставлять сообщение в очередь SQS FIFO каждую минуту, а количество сообщений будет соответствовать количеству копий Сервиса. Как видно из приведенного выше рисунка, в течение 5 минут доставляется максимум 300 сообщений (т.к. максимальное количество реплик Сервиса равно 64). Но последнее полученное сообщение было всего 5 сообщений, полученных за 5 минут, то есть 1 сообщение было получено за 1 минуту.
7. Резюме
Поскольку эта реализация полностью основана на бессерверной технологии, затраты на обслуживание очень низкие. Хотя разработка несколько сложна, это единовременная инвестиция. Судя по данным последних месяцев, стоимость использования облака составляет не более 200 долларов США в месяц, ошибки и задержки сравнительно невелики, а в целом работа пока относительно стабильна.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
