Структуры нейронных сетей — CNN, RNN, LSTM, Трансформер! !
Предисловие
Эта статья начнется с темы «Что такое CNN?». Что такое РНН? Что такое ЛСТМ? Что такое Трансформатор? Четыре вопроса, краткое введение в нейронную структуру сети.
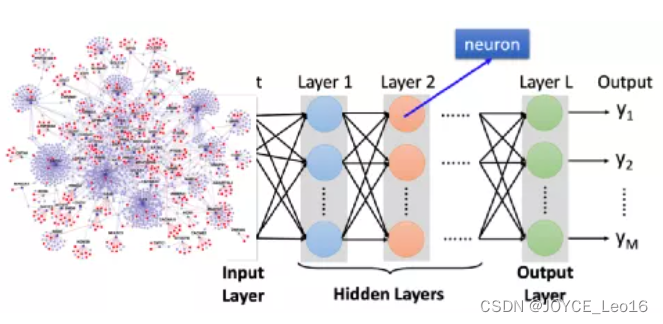
нерв Структура сети
1. Что такое CNN
Сверточная нейронная сеть (CNN):Эффективно обрабатывайте многомерные изображения с помощью операций свертки и объединения.данные,Уменьшите вычислительную сложность,И извлеките ключевые характеристики для идентификации и классификации.
Структура сети
- Сверточный слой:Используется для извлечения локальных особенностей изображений.。
- Слой пула:Используется для значительного уменьшения величины параметра,Реализация уменьшения размерности данных。
- Полностью связный слой:Используется для вывода желаемых результатов。
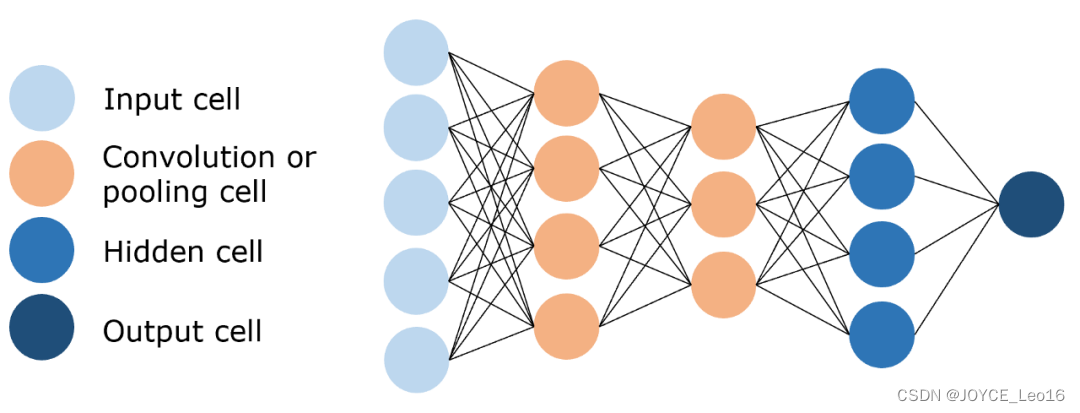
Сверточная нейронная сеть (CNN)
решать проблемы
- Особенности извлечения:Операция свертки извлекает особенности изображения,Например, края, текстуры и т. д.,Сохраните особенности изображения.
- Уменьшение размерности данных:Операция объединения значительно уменьшает величину параметра.,Реализация уменьшения размерности данных,Значительно сократить объем вычислений,Избегайте переобучения.
Принцип работы
- Сверточный слой:Извлекайте локальные объекты изображения с помощью фильтрации ядра свертки.,Предварительное извлечение признаков выполняется аналогично первичной зрительной коре.
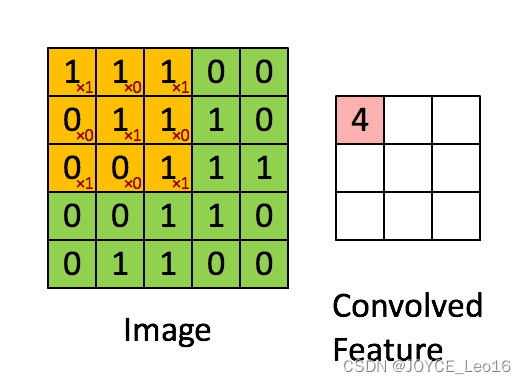
Используйте фильтр (ядро свертки) для фильтрации каждой небольшой области изображения, чтобы получить значения функций этих небольших областей.
- Слой пула:Понижение разрешения Реализация уменьшения размерности данных,Значительно сократить объем вычислений,Избегайте переобучения.

Исходный размер — 20×20, который уменьшается до 10×10, чтобы получить карту объектов размером 2×2.
- Полностью связный слой:обрабатывается сверточным слоем и слоем пуладанныеввод в Полностью связный слой, получите конечный желаемый результат.

Полностью связный слой
LeNet-5: известный как «Hello World» среди сверточных нейронных сетей, это алгоритм CNN, предложенный лауреатом премии Тьюринга Яном Лекуном в 1998 году для решения проблемы распознавания рукописного текста.

LeNet-5 представляет сверточные слои, слои пула и полностью связный Слой и другие ключевые компоненты создают эффективную и мощную сеть распознавания изображений, которая обеспечивает основу для последующей нейронной свертки. Был заложен фундамент для развития сети.
- Входной слой:INPUT
- три Сверточный слой:C1、C3иC5
- Две Слой пула: S2 и S4
- один Полностью связный слой:F6
- Выходной слой:OUTPUT

Входной слой - сверточный слой - слой объединения - сверточный слой - слой объединения - сверточный слой - Полностью связный слой - выходной слой
Практическое применение
- Классификация изображений:Может сэкономить много затрат на рабочую силу,Эффективно классифицируйте изображения,Точность классификации может достигать95%+。Типичный сценарий: поиск изображений.
- Целевое позиционирование:Может находить объекты на изображениях,и определить местоположение и размер цели。Типичный сценарий: автономное вождение.
- Целевая сегментация:Простое пониманиеодин Классификация на уровне пикселей。Типичный сценарий: обрезка видео.
- Распознавание лиц:Очень популярное приложение,Можно идентифицировать, даже если вы носите маску。Типичный сценарий: аутентификация личности.
2. Что такое РНН?
Рекуррентная нейронная сеть (RNN): нейронная сеть, которая обрабатывает данные последовательности и хранит историческую информацию для принятия более обоснованных решений о предстоящих событиях, используя предыдущие прогнозы в качестве контекстных сигналов.
Структура сети
- Входной слой:получать входные данныеданные,и передать его на скрытый слой. Ввод не просто статичен,Также содержит историческую информацию в последовательности.
- Скрытый уровень: основная часть, фиксирующая временные зависимости.。Вывод скрытого слоя зависит не только от текущего ввода,возвращатьсяЗависит от скрытого состояния в предыдущий момент.
- Выходной слой:Сгенерируйте окончательный результат прогнозирования на основе выходных данных скрытого слоя.。

Рекуррентная нейронная сеть (RNN)
решать проблемы
- Последовательность обработки данных:RNNможетОбработка нескольких входов, соответствующих нескольким выходамситуация,Особенно подходит для данных последовательности,например временной ряд, речь или текст,где каждый выходОтносится как к текущим, так и к предыдущим вводам。
- Круговое соединение:RNNКруговое соединение делаетсетьможетЗахват корреляций между входными данными,При этом используется предыдущая входная информация для влияния на последующий результат.
Принцип работы
- Входной слой:Сначала сопоставьте предложения“what time is it ? » выполните сегментацию слов, а затем введите их по порядку.

Разделенные предложения
- Скрытый слой:во время этого процесса,Мы замечаем, что все предыдущие входные данные влияют на последующие результаты. Круговой скрытый слой учитывает не только текущий ввод,Он также объединяет всю предыдущую входную информацию.,Способность использовать историческую информацию для влияния на будущие результаты.。
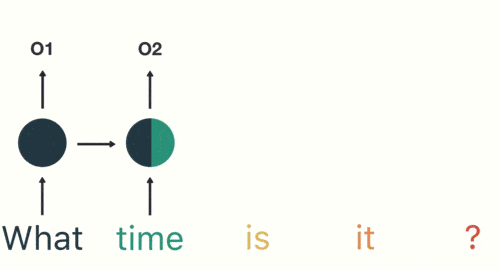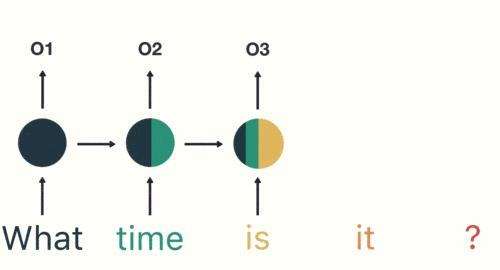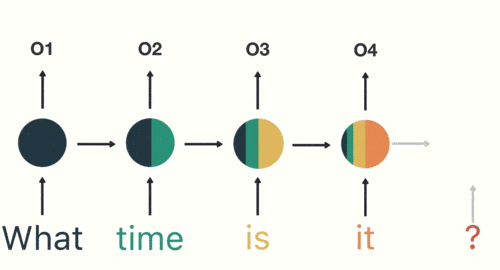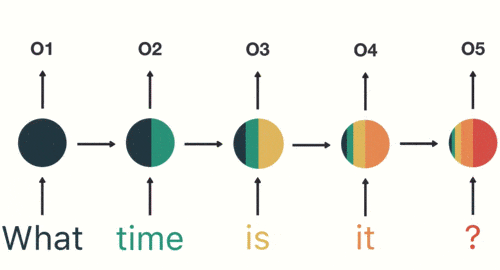
Все предыдущие входные данные влияют на последующие результаты
- Выходной слой:Генерация окончательных результатов прогнозирования:Asking for the time。

Вывод: Спросить время
Сценарии применения
(1) Обработка данных
- Текстовые данные:Обрабатывать временные отношения слов или символов в тексте,и выполнить классификацию или перевод текста.
- Голосовые данные:Обработка временной информации в речевых сигналах,и преобразовать его в соответствующий текст.
- Данные временного ряда:Характеристики временных рядов обработкиданные,Например, цены на акции, изменение климата и т. д.
- Видеоданные:Обрабатывать последовательности видеокадров,Извлекайте ключевые особенности из видео.
(2)Практическое применение
- Генерация текста:Заполните пробелы или предсказания под данным текстом.одинслово。Типичный сценарий: генерация диалога.
- Машинный перевод:Изучите правила конвертации между языками,и автоматически переводить。Типичный сценарий: онлайн-перевод.
- Распознавание голоса:Преобразование речи в текст。Типичный сценарий: голосовой помощник.
- Теги видео:Разбейте видео на серию ключевых кадров.,и генерирует текстовое описание, соответствующее содержимому, для каждого кадра。Типичный сценарий: создание видеосводки.
3. Что такое ЛСТМ
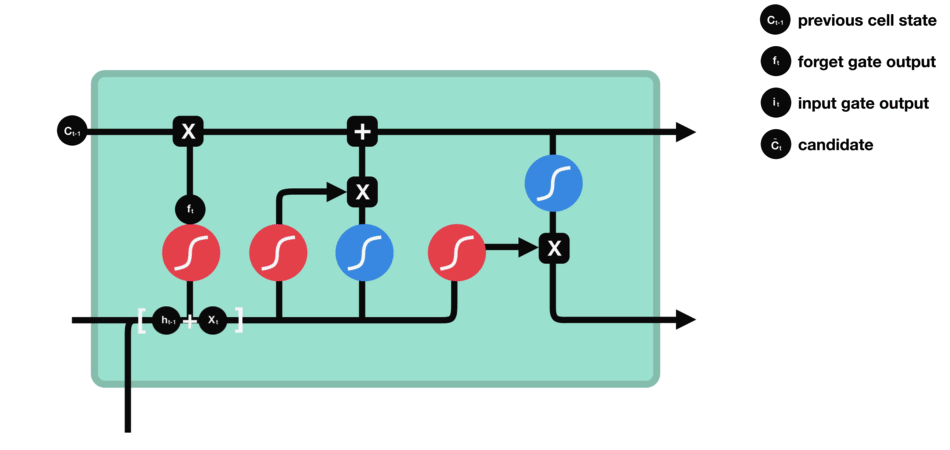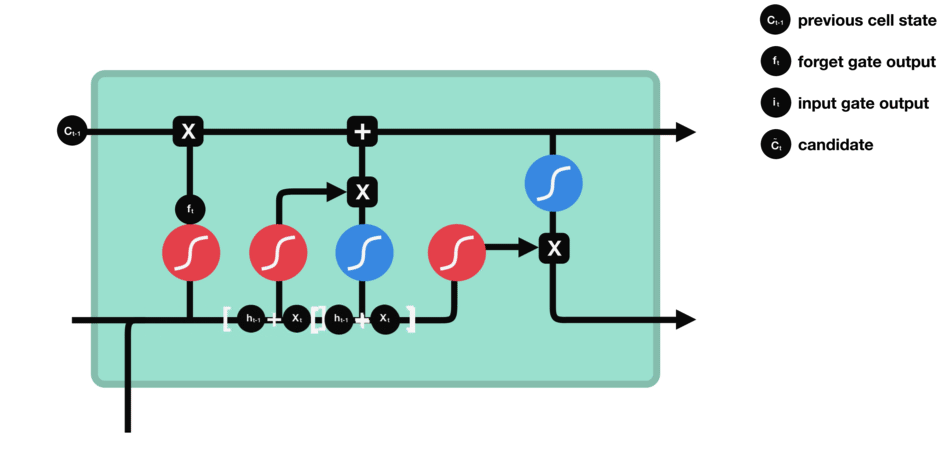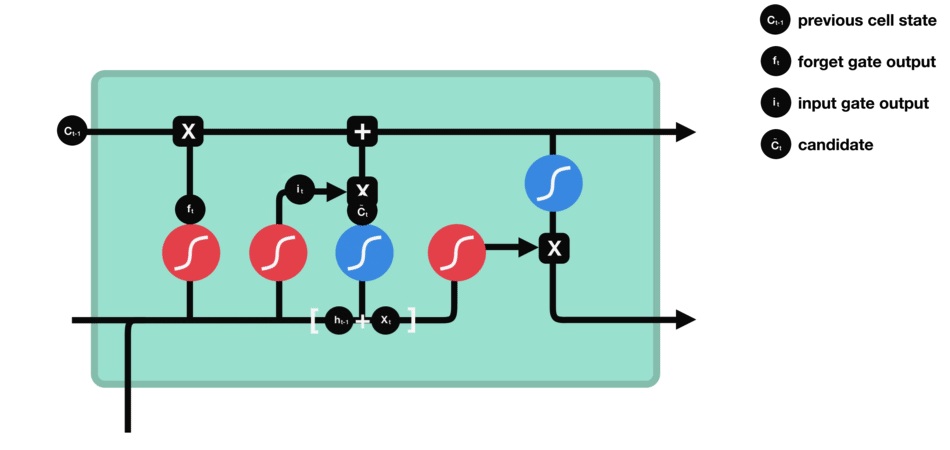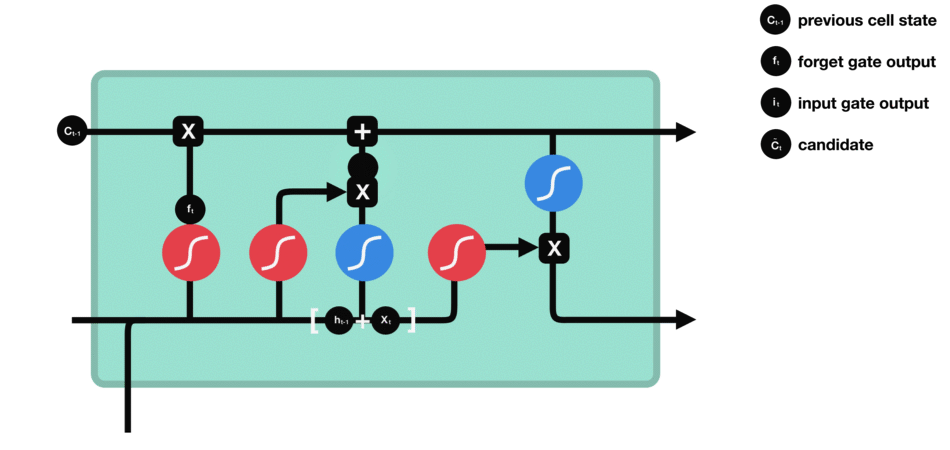
Сеть долгосрочной краткосрочной памяти (LSTM): особый вид нейронной петли. сеть,Решите проблему исчезновения градиента, введя блоки памяти и механизмы вентилирования.,Это приводит к более эффективной обработке и запоминанию долговременной зависимой информации.(алгоритм оптимизации RNN)
Структура сети
- Состояние ячейки:Отвечает за сохранение долговременной зависимой информации.。
- Конструкция ворот:каждыйLSTMВ одном глазу содержитсятри Дверь:входные ворота、Забудьте о воротах и выходных воротах.
- **Ворота забыть:**Определяет, какая информация удаляется из состояния ячейки.
- **Входной шлюз:**Определяет, какая новая информация добавляется в состояние ячейки.
- **Выходной шлюз: **Определяет выходную информацию на основе состояния ячейки.

Сеть долгосрочной краткосрочной памяти (LSTM)
решать проблемы
- Кратковременная память:RNNнеуловимыйи Использование долгосрочных зависимостей в последовательностях,Это ограничивает его производительность при выполнении сложных задач.
- Исчезающие/взрывающиеся градиенты:существоватьRNNВ процессе обратного распространения ошибки,Градиенты могут исчезать (становиться очень маленькими) или взрываться (становиться очень большими) с течением времени.
Принцип работы
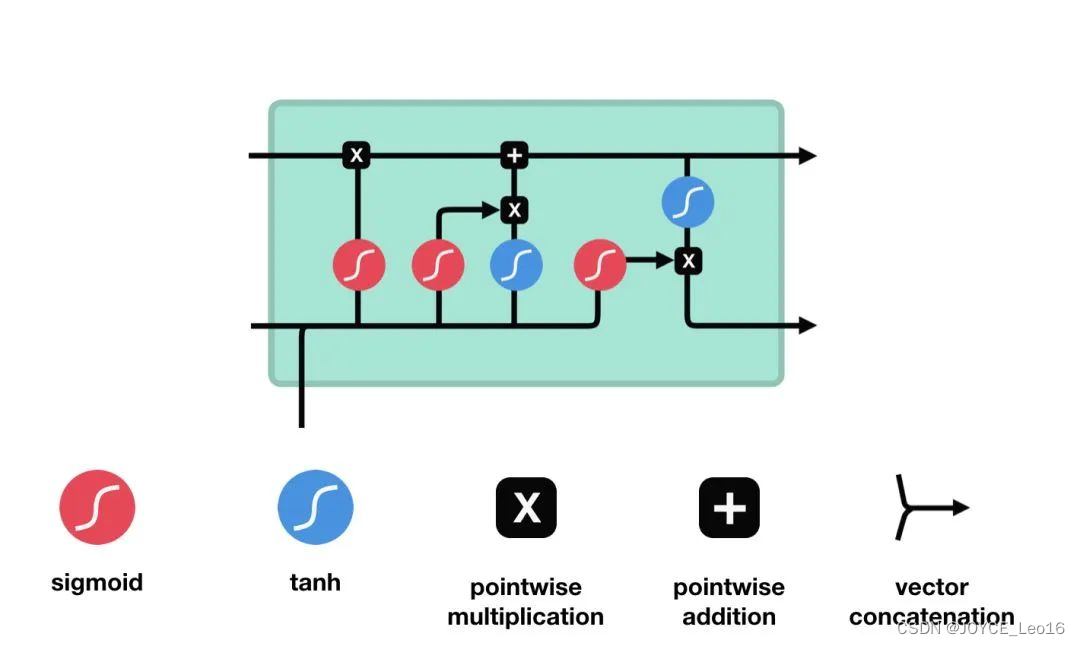
Клеточная структура и операции LSTM
- Входной вентиль: определяет, какую новую информацию следует добавить в блок памяти.
Он состоит из функции активации сигмовидной кишки и функции активации танга. Сигмовидная функция определяет, какая информация важна, а функция tanh генерирует новую информацию-кандидат.
Входные ворота (функция активации сигмовидной кишки + функция активации танха)
- Ворота забывания: определяет, какую старую информацию следует забыть или удалить из блока памяти.
Ворота забывания состоят только из функции активации сигмовидной кишки.
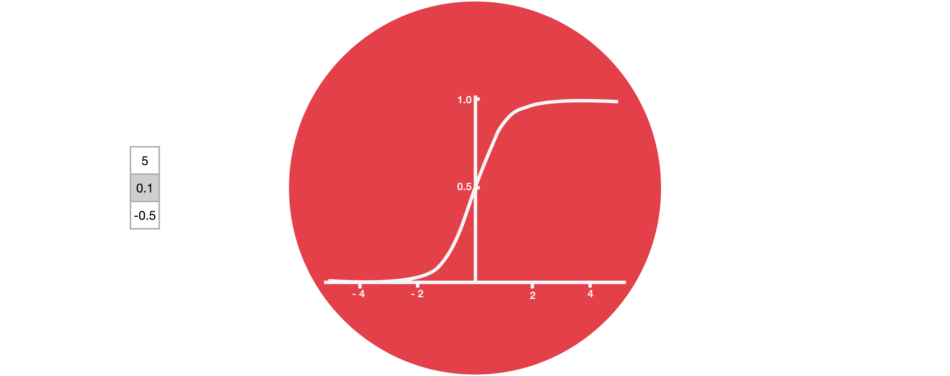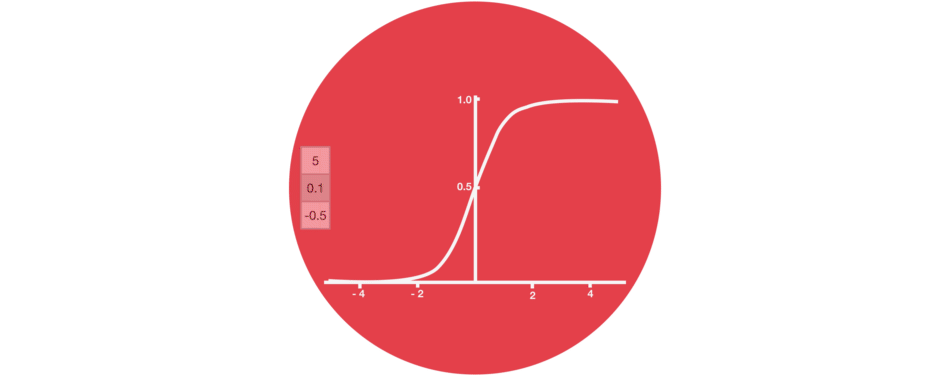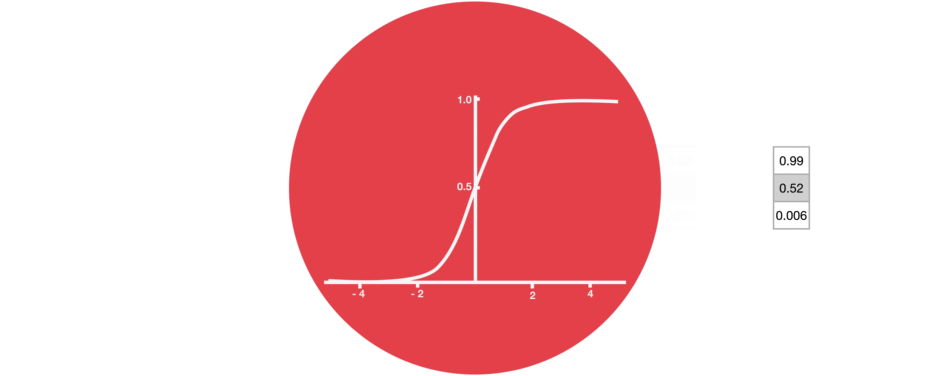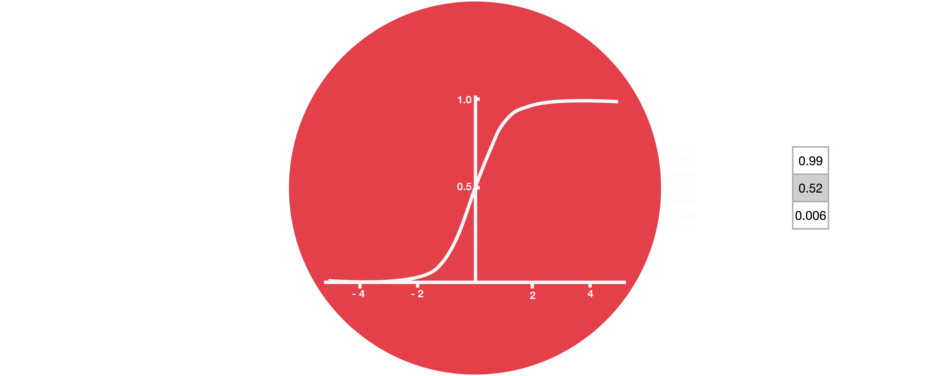
функция активации сигмовидной кишки (диапазон 0~1)

Ворота забывания (функция активации сигмовидной кишки)
- Выходной вентиль: определяет, какая информация в блоке памяти должна быть выведена в скрытое состояние текущего временного шага.
Выходной вентиль также состоит из функции активации сигмовидной мышцы и функции активации Танха. Сигмовидная функция определяет, какая информация должна быть выведена, а функция tanh обрабатывает состояние блока памяти при подготовке к выводу.

Выходной вентиль (функция активации сигмовидной кишки + функция активации tanh)
Сценарии применения
(1) Машинный перевод
Описание приложения:
- LSTM используется в машинном переводе для автоматического перевода предложений исходного языка в предложения целевого языка.
Ключевые компоненты:
- Кодировщик:одинLSTMсеть,Отвечает за получение предложений исходного языка и их кодирование в вектор контекста фиксированной длины.
- Декодер:ДругойодинLSTMсеть,Генерируйте переведенные предложения на целевом языке на основе векторов контекста.
процесс:
- Ввод исходного языка:Сегментируйте предложения исходного языка на слова и преобразуйте их в последовательности векторов слов.。
- кодирование:Используйте кодировщикLSTMОбрабатывать векторные последовательности слов исходного языка,Выходной вектор контекста.
- Инициализируем декодер:Используйте вектор контекста в качестве декодераLSTMначальное скрытое состояние。
- декодирование:декодерLSTMПошаговое создание последовательностей слов на целевом языке,Пока не будет создано полное переведенное предложение.
- Вывод на целевом языке:Волядекодер Сгенерированная последовательность слов преобразуется в предложение целевого языка.。
оптимизация:
- Сравнивая сгенерированное переведенное предложение с реальным целевым предложением.,Оптимизация параметров модели LSTM с использованием алгоритма обратного распространения ошибки,улучшить качество перевода.
(2) Анализ настроений

Описание приложения:
- LSTM используется для анализа настроений текста, чтобы определить его эмоциональную тенденцию (положительную, отрицательную или нейтральную).
Ключевые компоненты:
- Сеть ЛСТМ:Получайте текстовые последовательности и извлекайте эмоциональные особенности。
- Уровень классификации:в соответствии сLSTMИзвлеченные функции для классификации настроений。
процесс:
- Предварительная обработка текста:Разделить текст на слова、Операции предварительной обработки, такие как удаление стоп-слов.
- Текстовое представление:Преобразование предварительно обработанного текста в последовательность векторов слов.。
- Извлечение функций:использоватьLSTMсетьобработка словавекторпоследовательность,Извлекайте эмоциональные характеристики из текста.
- Эмоциональная классификация:ВоляLSTMизвлеченные функцииввод вслой классификации,Получите эмоциональные тенденции.
- Выход:Эмоциональная направленность выходного текста(позитивный、отрицательный или нейтральный).
оптимизация:
- Сравнивая прогнозируемые тенденции настроений с истинными ярлыками.,Оптимизация параметров модели LSTM с использованием алгоритма обратного распространения ошибки,повысить точность анализа настроений.
4. Что такое трансформатор
Трансформатор: нейронная структура, основанная на механизме самообслуживания сети,Благодаря параллельным вычислениям и многоуровневому извлечению признаков,Эффективно решает проблему зависимости длинных последовательностей,Достигнуты прорывы в таких областях, как обработка естественного языка.
Структура сети
Он состоит из четырех частей: входная часть (встраивание ввода-вывода и кодирование положения), многоуровневый кодер, многоуровневый декодер и выходная часть (выходной линейный уровень и Softmax).

Трансформаторная архитектура
Входная часть:
- Слой внедрения исходного текста:Воля Лексическое числовое представление в исходном тексте преобразуется ввекторвыражать,Улавливайте связи между словами.
- Датчик положения:为输入последовательность的каждыйместоположение создать местоположениевектор,Чтобы Модель могла понять информацию о положении в последовательности.
- Целевой слой внедрения текста (используется в декодере):Воля目标文本中的词汇数字выражать转换为векторвыражать。
Часть кодировщика:
- Он состоит из N слоев кодера.
- Каждый уровень кодера состоит из двух структур соединения подуровней:Нет.один Подуровень представляет собой подуровень самообслуживания с несколькими головками.,Второй подуровень представляет собой полносвязный подуровень с прямой связью. За каждым подуровнем следует уровень нормализации и остаточное соединение.
Часть декодера:
- Он состоит из N слоев декодера.
- Каждый уровень декодера состоит из трех структур соединения подуровней:Нет.один Подуровеньодин Замаскированный подслой самообслуживания с несколькими головами,Второй подуровень представляет собой подуровень самообслуживания с несколькими головками (от кодера к декодеру).,Третий подуровень представляет собой полностью связный подуровень с прямой связью. За каждым подуровнем следует уровень нормализации и остаточное соединение.
Раздел вывода:
- Линейный слой:Волядекодер Выходвектор Преобразование в окончательные выходные размеры。
- Слой Softmax:Воля Выходные данные линейного слоя преобразуются в распределение вероятностей.,чтобы сделать окончательные прогнозы.
решать проблемы
- Проблемы долгосрочной зависимости:существовать处理长последовательность输入时,Традиционная Рекуррентная нейронная сеть (RNN) столкнется с долгосрочными проблемами зависимости,То есть трудно уловить долгосрочные зависимости в последовательностях. Трансформатор Модель через механизм самообслуживания,Возможность присвоить разную важность каждому элементу последовательности в разных позициях.,Это эффективно фиксирует зависимости на расстоянии.
- Проблемы параллельных вычислений:традиционныйRNNМодельсуществовать计算时需要按照последовательность的顺序依次进行,Невозможно реализовать параллельные вычисления,что приводит к снижению эффективности вычислений. Модель трансформатора использует структуру кодера-декодера.,Разрешить модели кодировать входную последовательность,Затем декодируйте выходную последовательность,Это обеспечивает возможность параллельных вычислений,Значительно увеличена скорость обучения Модели.
- Проблема извлечения признаков:TransformerМодельчерез механизм самовниманияимногослойныйнерв Структура сети,Способность эффективно извлекать богатую информацию о функциях из входных последовательностей.,Обеспечьте лучшую поддержку для последующих задач.
Принцип работы
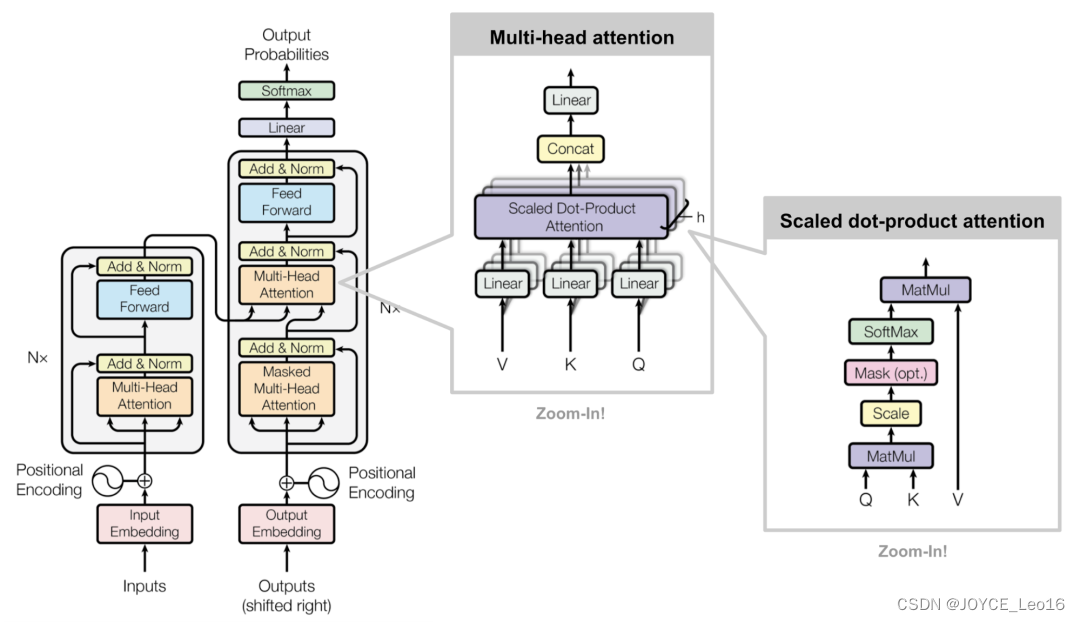
TransformerПринцип работы
- Введите линейное преобразование:Для вводаQuery(Запрос)、Key(ключ)иValue(ценить)вектор,Во-первых, они отображаются в разные подпространства посредством линейного преобразования. Параметры этих линейных преобразований — это то, что Модель должна изучить.
- Разделить длинно:После линейного преобразования,Векторы запроса, ключа и значения разбиваются на несколько заголовков. Каждая голова производит расчеты внимания самостоятельно.
- Масштабирование внимания к скалярному произведению:существоватькаждый Внутри головы,Используйте масштабированное скалярное произведение внимания, чтобы вычислить оценку внимания между запросом и ключом. Эта оценка определяет при создании выходных данных,Модельдолженсосредоточиться — Часть вектора значений.
- Внимание: приложение веса:Воля Рассчитанные веса внимания применяются кValueвектор,Получите взвешенный промежуточный результат. Этот процесс можно понимать как фильтрацию и фокусировку входной информации на основе весов внимания.
- Сплайсинг и линейное преобразование:Воля Взвешенное выходное соединение всех головоксуществовать Вместе,Затем окончательный вывод внимания Multi-Head получается посредством линейного преобразования.
Прочтите это для подробностей:алгоритм нейронной сети —— Разбираемся с Трансформером в одной статье ! ! _Блог о нейронных сетях и трансформаторах-CSDN
BERT
BERT — это предварительно обученная языковая модель, основанная на Transformer. Ее самым большим нововведением является введение двунаправленного кодировщика Transformer, который позволяет модели учитывать как переднюю, так и заднюю контекстную информацию входной последовательности.
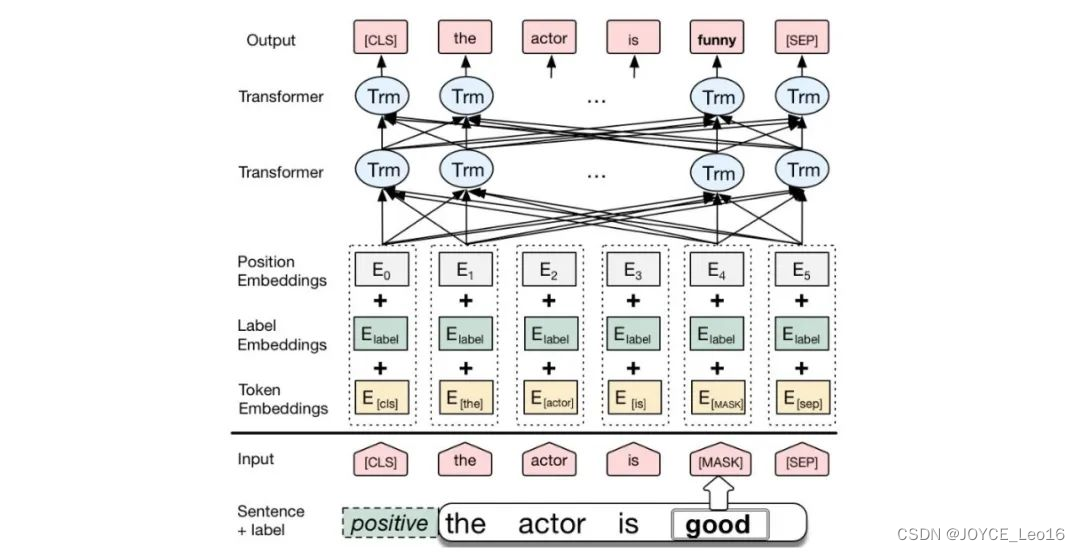
БЕРТ-архитектура
1. Входной слой (Внедрение):
- Встраивание токенов: преобразуйте слова или подслова в векторы фиксированной размерности.
- Встраивание сегментов: используется для различения разных предложений в паре предложений.
- Position Внедрения: поскольку сама модель Transformer не способна обрабатывать порядок последовательности, необходимо добавить встраивания позиций, чтобы предоставить информацию о положении слов в последовательности.
2. Уровень кодирования (трансформаторный кодер):
- Модель BERT использует двунаправленный кодировщик Transformer для кодирования.
3. Выходной уровень (предварительно обученные слои для конкретных задач):
- MLMВыходной слой: используется для прогнозирования замаскированных слов. на этапе обучения,Модель будет случайным образом маскировать некоторые слова во входной последовательности.,и попытайтесь предсказать эти слова на основе контекста.
- NSPВыходной слой: используется для определения того, являются ли два предложения парой непрерывных предложений. на этапе обучения,Модель получит на вход пары предложений.,и попытайтесь предсказать, является ли второе предложение продолжением первого предложения.
GPT
GPT также представляет собой предварительно обученную языковую модель, основанную на Transformer. Его самым большим нововведением является использование одностороннего кодировщика Transformer, который позволяет модели лучше захватывать контекстную информацию входной последовательности.

Архитектура GPT
1. Встраивание входных данных:
- Преобразуйте входные слова или символы в векторные представления фиксированной размерности.
- Вложения слов, внедрения позиций и т. д. могут быть включены для предоставления семантической информации и позиционной информации слов.
2. Уровень кодирования (трансформаторный кодер):
- GPTМодель использует односторонний кодировщик Transformer для кодирования и генерации.
3. Выходной слой (Output Linear и Softmax):
- Уровень линейного вывода преобразует выходные данные последнего блока декодера преобразователя в вектор размером со словарь.
- Softmaxфункция преобразует выходной вектор в распределение вероятностей.,чтобы сделать выбор словаря или сгенерировать следующее слово.
Ссылка: Architect предлагает вам поиграть с ИИ.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
